epígrafe, Google / Yandex não encontrou o autor
Esta é a segunda parte do artigo “O que é claro para todos”.
Para uma melhor compreensão do algoritmo Z delineado nele, adicionarei aqui um bom exemplo dado anteriormente na discussão / comentários.
Imagine que a tarefa seja construir uma curva de uma certa função T (X) em um determinado intervalo de valores (admissíveis). É desejável fazer isso com o máximo de detalhes possível, mas você não sabe com antecedência quando será "agarrado pela mão". Você deseja gerar valores X para que a qualquer momento quando a plotagem da curva for interrompida (gerando parâmetros X em um intervalo e calculando T (X)), o gráfico resultante reflita esta função com a maior precisão possível. Levará mais tempo - o gráfico será mais preciso, mas - sempre o máximo do que é possível no momento para uma função arbitrária .
Claro que, para uma função conhecida, o algoritmo de particionamento de intervalo pode levar em consideração seu comportamento, mas aqui estamos falando de uma abordagem geral que dá o resultado desejado com "perdas" mínimas. Para um caso bidimensional, você pode dar um exemplo de exibição de um certo relevo / superfície e deseja ter certeza de que, tanto quanto possível, você exibiu o máximo de seus recursos.
O problema e os objetos da modelagem (da primeira parte) no caso geral podem ser muito diferentes: existe um modelo teórico / físico ou uma aproximação ou não (caixa preta) - haverá nuances nos modelos de construção em todos os lugares. Mas a necessidade de gerar parâmetros (incluindo o algoritmo Z) é uma parte comum e integral para todos. Existem objetos (por exemplo, tais ) quando o tempo para obtenção de T é muito longo (dias e semanas), então o algoritmo de escolha de uma nova etapa para por outro critério, não por causa da conclusão do ciclo de cálculo principal em um processo paralelo. Não faz sentido reduzir ainda mais a etapa para melhorar a busca pela próxima previsão T se a melhoria esperada for obviamente pior do que o erro do modelo e / ou erros de medição T.
Vou dar mais uma ilustração da divisão do intervalo admissível para o caso bidimensional do algoritmo Z (K = 3 no campo 64 * 64):

Os pontos destacados na figura (9 pcs.) São os pontos de partida das arestas e do meio do intervalo, eles, se necessário, são considerados fora do algoritmo Z. Você pode ver que ao longo das direções / "caminhos" horizontais e verticais que conectam esses pontos, gerados pelo algoritmo Valores Z estão faltando. Os pontos adicionais aqui são fáceis de calcular separadamente, mas com um aumento no número de pontos ao longo dessas direções / "trilhas", a representação da função melhorará (as "trilhas" se tornam mais estreitas) e a necessidade de complementar o próprio algoritmo (7 linhas são necessárias, das quais 4 operadores no loop principal em n, veja abaixo) ou não vejo como criar um cálculo separado. Além disso, neste caso, a eficiência média do algoritmo se deteriora, e não haverá melhora significativa na representação do modelo (já para n> 8, o passo no parâmetro é menor que 1/1000, ver tabela abaixo).
A segunda característica do algoritmo Z é (para o caso bidimensional) a assimetria da ordem de adição dos pontos - no eixo / parâmetro Y eles são em média mais frequentes, a imagem é alinhada ao final de cada ciclo por n.
Algoritmo Z, caso unidimensional, em linguagem VBA:
Xmax =
Xmin =
Dx = (Xmax - Xmin) / 2
L = 2
Sx = 0
For n = 1 To K
Dx = Dx / 2
D = Dx
For j = 1 To L Step 2
X = Xmin + D
Cells(5, X) = "O" ' - / T(X)
X = Xmax - D
Cells(5, X) = "O"
D = D + Sx
Next j
Sx = Dx
L = L + L
Next nAlgoritmo Z, caso 2D, linguagem VBA:
Xmax = ' 65 - , GIF
Xmin = ' 1
Ymax = ' 65
Ymin = ' 1
Dx = (Xmax - Xmin) / 2
Dy = (Ymax - Ymin) / 2
L = 2
Sx = 0
Sy = 0
For n = 1 To K ' K = 3 GIF
Dx = Dx / 2
Dy = Dy / 2
Tx = Dx
For j = 1 To L Step 2
X1 = Xmin + Tx
X2 = Xmax - Tx
Ty = Dy
For i = 1 To L Step 2
Y = Ymin + Ty
Cells(Y, X1) = "O" ' - / T(Y,X)
Cells(Y, X2) = "O"
Y = Ymax - Ty
Cells(Y, X1) = "O"
Cells(Y, X2) = "O"
Ty = Ty + Sy
Next i
Tx = Tx + Sx
Next j
Sx = Dx
Sy = Dy
L = L + L
Next nCustos computacionais:
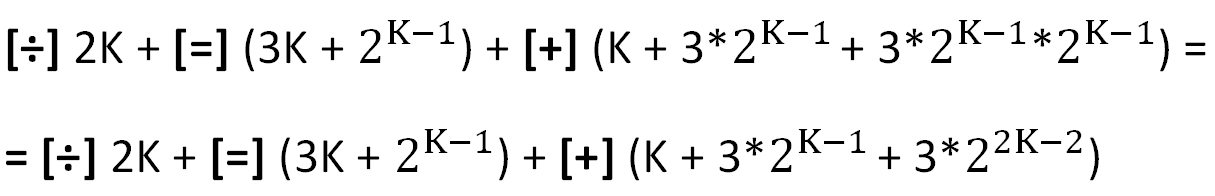
As principais operações utilizadas nos cálculos são indicadas entre colchetes (os custos de organização dos ciclos não são considerados).
Deve-se notar aqui que a operação um tanto "pesada" da divisão [÷] neste caso não é cara, porque a divisão inteira por 2 é um deslocamento de um dígito. Os custos relativos da operação de divisão e atribuição ([=], segundo termo) tendem rapidamente a zero conforme K cresce.
Total de pontos:

Custos médios:

Para os primeiros valores de K, faremos cálculos usando estas fórmulas e preencheremos a tabela:

Aqui "fração do intervalo" é o passo relativo entre os pontos no final do ciclo por n.
A última linha ("média") mostra o custo relativo por ponto - a proporção de adições / subtrações. O limite tende a 0,5625 ou 1 / 1,7777 da operação de adição.
Voltando à afirmação da primeira parte do artigo , é mostrado aqui que "o algoritmo proposto para discussão demonstra custos computacionais extremamente baixos e não acarreta nenhuma desvantagem ou dificuldade" e, em condições de uma interrupção repentina dos cálculos, tem vantagens adicionais. É aconselhável usá-lo em todas as aplicações adequadas.
Peço ajuda na distribuição e implementação tanto em software quanto em hardware.