Um desses aspectos colaterais do desenvolvimento de software é o licenciamento de código. Para alguns desenvolvedores, o licenciamento parece ser uma floresta um tanto obscura, eles tentam não entrar nisso e ou não entendem as diferenças e as regras de licença em geral, ou as conhecem um tanto superficialmente, por isso podem cometer vários tipos de violações. A violação mais comum é a cópia (reutilização) e modificação do código em violação dos direitos de seu autor.
Qualquer ajuda às pessoas começa pesquisando a situação atual - em primeiro lugar, a coleta de dados é necessária para a possibilidade de maior automação e, em segundo lugar, sua análise nos permitirá descobrir o que exatamente as pessoas estão fazendo de errado. Neste artigo, descreverei apenas esse estudo: apresentarei a você os principais tipos de licenças de software (bem como algumas raras, mas dignas de nota), falarei sobre análise de código e pesquisa de empréstimos em uma grande quantidade de dados e darei conselhos sobre como lidar adequadamente com licenças no código. e evite erros comuns.
Uma introdução ao licenciamento de código
Na Internet, e mesmo no Habré , já existem descrições detalhadas das licenças, por isso nos limitaremos a apenas um breve panorama do tema necessário para compreender a essência do estudo.
Falaremos apenas sobre licenciamento de software de código aberto. Em primeiro lugar, isso se deve ao fato de que é nesse paradigma que podemos encontrar facilmente muitos dados disponíveis e, em segundo lugar, o próprio termo "software livre"pode ser enganoso. Quando você baixa e instala um programa proprietário comum do site da empresa, é solicitado que você concorde com os termos da licença. Claro, você geralmente não os lê, mas em geral entende que se trata de propriedade intelectual de alguém. Ao mesmo tempo, quando os desenvolvedores entram em um projeto no GitHub e veem todos os arquivos de origem, a atitude em relação a eles é completamente diferente: sim, existe algum tipo de licença lá, mas é de código aberto , e o software é de código aberto , o que significa que você pode simplesmente pegar e faça o que quiser, certo? Infelizmente, nem tudo é tão simples.
Como funciona o licenciamento? Vamos começar com a divisão de direitos mais geral:
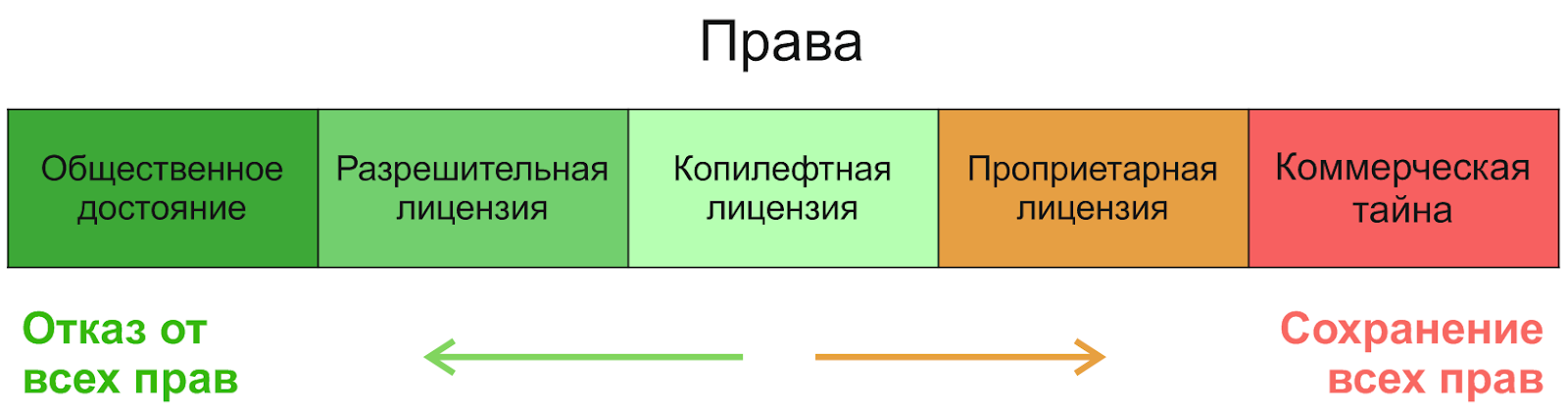
Se você for da direita para a esquerda, o primeiro será um segredo comercial, seguido de licenças proprietárias - não as consideraremos. No campo do software livre, três categorias podem ser distinguidas (de acordo com o grau de aumento das liberdades): licenças restritivas ( copyleft ), licenças não restritivas ( permissivas , permissivas) e de domínio público.(que não é uma licença, mas uma forma de concessão de direitos). Para entender a diferença entre eles, é útil saber por que eles apareceram. O conceito de domínio público é tão antigo quanto o mundo - o criador recusa completamente qualquer direito e permite que ele faça o que quiser com seu produto. Porém, curiosamente, dessa liberdade nasce a falta de liberdade - afinal, outra pessoa pode pegar tal criação, modificá-la ligeiramente e fazer “qualquer coisa” com ela - inclusive fechá-la e vendê-la. As licenças copyleft de código aberto foram criadas precisamente para proteger a liberdade - pela sua posição na imagem você pode ver que elas têm como objetivo manter um equilíbrio: permitir o uso, alteração e distribuição do produto, mas não bloqueá-lo, deixá-lo livre. Além disso, mesmo que o escritor não se importe com o cenário de fechar e vender,os conceitos de domínio público diferem de país para país e, portanto, podem criar complicações jurídicas. Para evitá-los, são utilizadas licenças permissivas simples.
Então, qual é a diferença entre licenças permissivas e copyleft? Como tudo o mais em nosso tópico, esta questão é bastante específica, e há exceções, mas se você simplificar, então as licenças permissivas não impõem restrições à licença do produto modificado. Ou seja, você pode pegar esse produto, alterá-lo e colocá-lo em um projeto sob uma licença diferente - mesmo que seja proprietária. A principal diferença do domínio público aqui é na maioria das vezes a obrigação de preservar a autoria e a menção do autor original. As licenças permissivas mais famosas são as licenças MIT, BSD e Apache .... Muitos estudos apontam para o MIT como a licença de código aberto mais amplamente usada em geral, e também observam o crescimento significativo na popularidade da licença Apache-2.0 desde seu início em 2004 (por exemplo, o estudo para Java ).
As licenças Copyleft geralmente impõem restrições à distribuição e modificação de subprodutos - você obtém um produto com certos direitos e deve “executá-lo mais adiante”, dando a todos os usuários os mesmos direitos. Isso geralmente significa um compromisso de redistribuir o software sob a mesma licença e fornecer acesso ao código-fonte. Com base nesta filosofia, Richard Stallman criou a primeira e mais popular licença copyleft, a GNU General Public License (GPL) É ela quem fornece a máxima proteção de liberdade para futuros usuários e desenvolvedores. Recomendo a leitura da história do movimento de Richard Stallman pelo software livre, é muito interessante.
Existe uma dificuldade com as licenças copyleft - elas são tradicionalmente divididas em copyleft forte e fraco . Um copyleft forte é exatamente o que está descrito acima, enquanto um copyleft fraco oferece várias concessões e exceções para desenvolvedores. O exemplo mais famoso de tal licença é a GNU Lesser General Public License (LGPL): como sua versão anterior, ele permite que você modifique e redistribua o código apenas se você mantiver esta licença, no entanto, com a vinculação dinâmica (usando-o como uma biblioteca em um aplicativo) este requisito pode ser omitido. Em outras palavras, se você quiser pegar emprestado o código-fonte daqui ou mudar algo, observe o copyleft, mas se quiser apenas usá-lo como uma biblioteca de vínculo dinâmico, você pode fazer em qualquer lugar.
Agora que descobrimos as próprias licenças, devemos falar sobre sua compatibilidade , porque é nela (ou melhor, sua ausência) que estão as violações que queremos evitar. Qualquer pessoa que já se interessou por este tópico deve ter encontrado esquemas de compatibilidade de licença semelhantes a este:

Olhando para tal esquema, qualquer desejo de entender as licenças pode desaparecer. Na verdade, existem muitas licenças de código aberto , uma lista bastante exaustiva pode ser encontrada, por exemplo, aqui . Ao mesmo tempo, como você verá a seguir nos resultados de nosso estudo, você precisa saber uma quantidade muito limitada (devido à sua distribuição extremamente desigual), e ainda menos regras que devem ser lembradas para cumprir todas as suas condições. O vetor geral desse esquema é bastante simples: na fonte de tudo está o domínio público, por trás dele existem licenças permissivas, depois um copyleft fraco e, finalmente, um copyleft forte, e as licenças são "certas" compatíveis: em um projeto de copyleft, você pode reutilizar o código sob uma licença permissiva, mas não vice-versa - tudo é lógico.
Aqui pode surgir a pergunta: e se o código não tiver uma licença? Que regras seguir então? Este código pode ser copiado? Na verdade, esta é uma questão muito importante. Provavelmente, se o código for escrito em uma cerca, então ele pode ser considerado de domínio público, e se for escrito em um papel em uma garrafa, que foi pregada em uma ilha deserta (sem copyright), então pode ser simplesmente tomado e usado. Quando se trata de plataformas grandes e estabelecidas como GitHub ou StackOverflow, as coisas não são tão simples, porque simplesmente usando-as, você concorda automaticamente com seus termos de uso. Por enquanto, vamos apenas deixar uma nota sobre isso em nossa cabeça e voltar a isso mais tarde - no final, talvez isso seja uma raridade e praticamente não haja código sem uma licença?
Declaração do problema e metodologia
Então, agora que sabemos o significado de todos os termos, vamos ser claros sobre o que queremos saber.
- Quão comum é a cópia de código em software de código aberto? Existem muitos clones no código entre os projetos de código aberto ?
- Quais são as licenças? Quais são as licenças mais comuns? O arquivo contém várias licenças de uma vez?
- Quais são os empréstimos possíveis mais comuns, ou seja, transferências de código de uma licença para outra?
- Quais são as violações mais comuns possíveis , ou seja, transições de código proibidas pelos termos da licença original ou de recebimento?
- Qual é a possível origem de fragmentos de código individuais? Qual é a probabilidade de que este trecho de código tenha sido copiado em violação?
Para realizar tal análise, precisamos:
- Crie um conjunto de dados a partir de um grande número de projetos de código aberto.
- Encontre clones de trechos de código entre eles.
- Identifique os clones que realmente podem ser emprestados.
- Para cada parte do código, determine dois parâmetros - sua licença e o tempo de sua última modificação, que é necessário para descobrir qual fragmento em um par de clones é mais antigo e qual é mais jovem e, portanto, quem poderia potencialmente copiar de quem.
- Determine quais transições possíveis entre licenças são permitidas e quais não são.
- Analise todos os dados obtidos para responder às questões anteriores.
Agora vamos examinar mais de perto cada etapa.
Coleção de dados
É muito conveniente para nós que hoje em dia seja fácil acessar muitos códigos abertos usando o GitHub. Ele contém não apenas o código em si, mas também o histórico de suas alterações, o que é muito importante para este estudo: para saber quem poderia copiar o código de quem, é necessário saber quando cada fragmento foi adicionado ao projeto.
Para coletar dados, você precisa decidir sobre a linguagem de programação estudada. O fato é que os clones são pesquisados dentro da estrutura de uma linguagem de programação: por falar em violação de licença, é mais difícil avaliar a reescrita de um algoritmo existente em outra linguagem. Esses conceitos complexos são protegidos por patentes, enquanto em nossa pesquisa estamos falando sobre cópias e modificações mais típicas. Escolhemos Java porque é uma das linguagens mais amplamente usadas e é especialmente popular no desenvolvimento de software comercial, caso em que potenciais violações de licenciamento são especialmente importantes.
Tomamos como base o existente Public Git Archive, que no início de 2018 reunia todos os projetos do GitHub que tinham mais de 50 estrelas. Selecionamos todos os projetos que têm pelo menos uma linha em Java e os baixamos com um histórico completo de alterações. Depois de filtrar projetos que foram movidos ou não estão mais disponíveis, há 23.378 projetos ocupando aproximadamente 1,25 TB de espaço no disco rígido.
Além disso, para cada projeto, despejamos a lista de garfos e encontramos pares de garfos dentro de nosso conjunto de dados - isso é necessário para uma filtragem posterior, uma vez que não estamos interessados em clones entre garfos. Havia 324 projetos no total com garfos dentro do conjunto de dados.
Encontrando clones
Para localizar clones, ou seja, partes semelhantes de código, você também precisa tomar algumas decisões. Primeiro, precisamos decidir quanto e em que capacidade estamos interessados em código semelhante. Tradicionalmente, existem 4 tipos de clones (do mais preciso ao menos preciso):
- Clones idênticos são exatamente os mesmos trechos de código que podem diferir apenas em decisões estilísticas, como recuos, linhas em branco e comentários.
- Os clones renomeados incluem o primeiro tipo, mas podem diferir adicionalmente em nomes de variáveis e objetos.
- Os clones próximos incluem todos os itens acima, mas podem conter alterações mais significativas, como adicionar, remover ou mover expressões, nas quais os fragmentos ainda são semelhantes.
- , — , ( ), ().
Estamos interessados em copiar e modificar, por isso consideramos apenas clones dos três primeiros tipos.
A segunda decisão importante é o tamanho dos clones a serem procurados. Fragmentos de código idênticos podem ser pesquisados entre arquivos, classes, métodos, expressões individuais ... Em nosso trabalho, tomamos o método como base , pois esta é a granularidade de pesquisa mais equilibrada: muitas vezes as pessoas copiam o código não em arquivos inteiros, mas em pequenos fragmentos, mas ao mesmo tempo o método - ainda é uma unidade lógica completa.
Com base nas soluções selecionadas, para encontrar clones, utilizamos o SourcererCC - ferramenta que busca clones pelo método do saco de palavras: cada método é representado como uma lista de frequência de tokens (palavras-chave, nomes e literais), após a qual tais conjuntos são comparados, e se mais do que uma certa proporção de tokens em dois métodos coincidir (esta proporção é chamada de limite de similaridade), então esse par é considerado um clone. Apesar da simplicidade deste método (existem métodos muito mais complexos baseados na análise de árvores de sintaxe de métodos e até mesmo em seus gráficos de dependência de programa), sua principal vantagem é a escalabilidade : com uma quantidade de código tão grande como o nosso, é importante que a busca por clones seja realizada muito rapidamente ...
Usamos limites de similaridade diferentes para encontrar clones diferentes e também conduzimos uma pesquisa separada com um limite de similaridade de 100%, em que apenas clones idênticos foram identificados. Além disso, um tamanho mínimo de método investigado foi definido para descartar partes triviais e genéricas de código que não podem ser emprestadas.
Essa busca levou até 66 dias de cálculos contínuos, 38,6 milhões de métodos foram identificados, dos quais apenas 11,7 milhões ultrapassaram o limite de tamanho mínimo e 7,6 milhões participaram da clonagem. Um total de 1,2 bilhões de pares de clones foram encontrados.
Hora da última modificação
Para uma análise posterior, selecionamos apenas pares de clones de projetos cruzados , ou seja, pares de fragmentos de código semelhantes encontrados em projetos diferentes. Do ponto de vista do licenciamento, não temos muito interesse em fragmentos de código dentro do mesmo projeto: é considerado uma má prática repetir o seu próprio código, mas não é proibido. No total, foram cerca de 561 milhões de pares interprojetos, ou seja, aproximadamente metade de todos os pares. Esses pares incluíram 3,8 milhões de métodos, para os quais foi necessário determinar o tempo da última modificação. Para isso, foi aplicado o comando git blame a cada arquivo (que resultou em 898 mil, pois pode haver mais de um método nos arquivos) , que dá a hora da última modificação para cada linha do arquivo.
Portanto, temos a hora da última modificação para cada linha do método, mas como determinamos a hora da última modificação de todo o método? Isso parece óbvio - você pega o tempo mais recente e o usa: afinal, ele realmente mostra quando o método foi alterado pela última vez. No entanto, para nossa tarefa, tal definição não é ideal. Vamos considerar um exemplo:
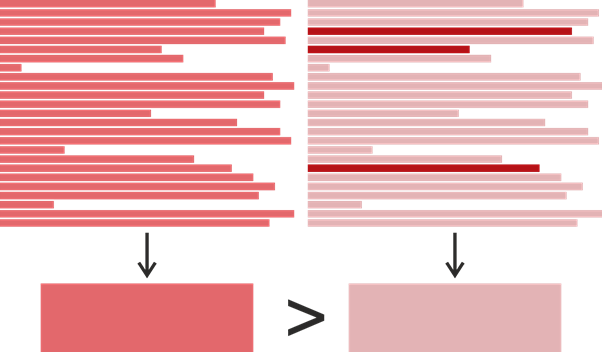
Suponha que encontramos um clone na forma de alguns fragmentos, cada um com 25 linhas. Uma cor mais saturada aqui significa um tempo de modificação posterior. Digamos que o fragmento à esquerda foi escrito em um momento em 2017 e no fragmento à direita 22 linhas foram escritas em 2015 e três foram modificadas em 2019. Acontece que o fragmento à direita foi modificado posteriormente, mas se quiséssemos determinar quem poderia copiar de quem, seria mais lógico supor o contrário: o fragmento esquerdo tomou emprestado o direito, e o direito mudou ligeiramente mais tarde. Com base nisso, definimos o horário da última modificação de um trecho de código como o horário mais frequente da última modificação de suas linhas individuais. Se, de repente, houvesse vários desses momentos, um posterior foi escolhido.
Curiosamente, o trecho de código mais antigo em nosso conjunto de dados foi escrito em abril de 1997, no início do Java, e ele encontrou um clone feito em 2019!
Definição de licenças
A segunda e mais importante etapa é determinar a licença para cada bloco. Para isso, usamos o seguinte esquema. Para começar, usando a ferramenta Ninka , foi determinada a licença especificada diretamente no cabeçalho do arquivo. Se houver uma, será considerada uma licença para cada método nela (o Ninka é capaz de reconhecer várias licenças ao mesmo tempo). Se nada for especificado no arquivo, ou não houver informações suficientes (por exemplo, apenas direitos autorais), a licença de todo o projeto ao qual o arquivo pertence foi usada. Os dados sobre ele estavam contidos no Arquivo Git Público original, com base no qual coletamos o conjunto de dados, e foram determinados usando outra ferramenta - Go License Detector . Se a licença não estiver no arquivo ou no projeto, esses métodos foram marcados comoGitHub , pois eles estão sujeitos aos Termos de Serviço do GitHub (que é onde todos os nossos dados foram baixados).
Tendo definido todas as licenças desta forma, podemos finalmente responder à questão de quais licenças são as mais populares. Encontramos 94 licenças diferentes no total . Fornecemos estatísticas para arquivos aqui para compensar possíveis distorções devido a arquivos muito grandes com vários métodos.
A principal característica desta programação é a distribuição desigual mais forte de licenças. Três áreas podem ser vistas no gráfico: duas “licenças” com mais de 100 mil arquivos, outras dez com 10-100 mil e uma longa cauda de licenças com menos de 10 mil arquivos.
Vamos primeiro considerar as mais populares, para as quais apresentamos as duas primeiras áreas em uma escala linear:
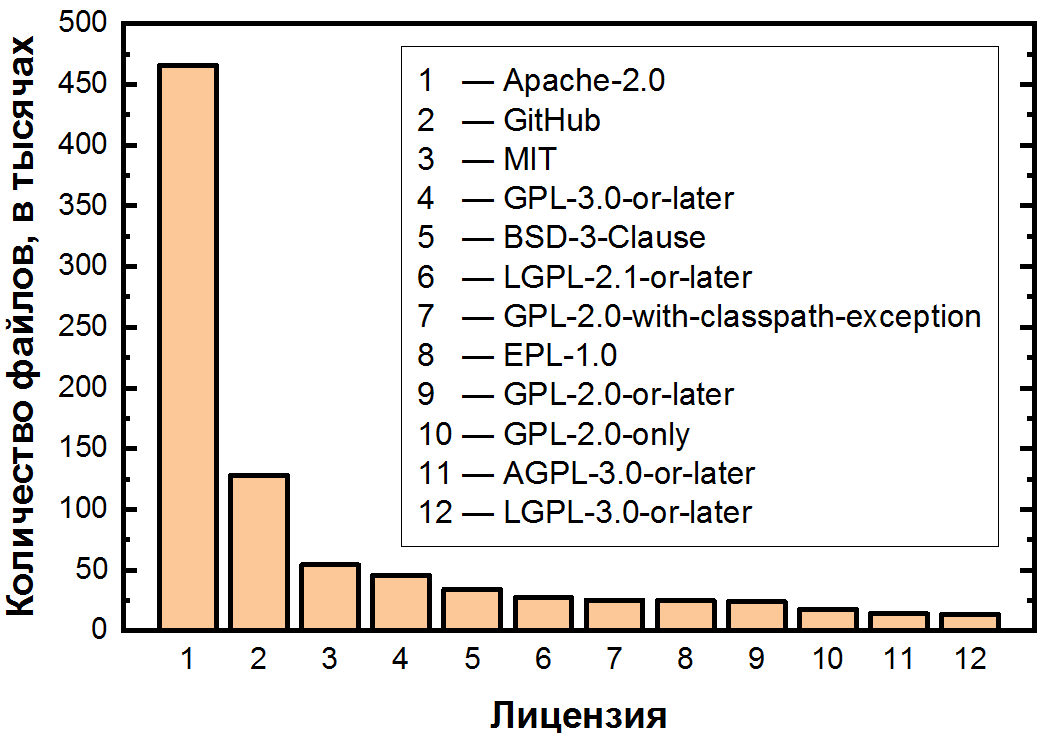
Pode-se notar irregularidades mesmo entre as licenças mais populares. Apache-2.0, a mais equilibrada de todas as licenças permissivas, ocupa o primeiro lugar por uma grande margem: cobre pouco mais da metade de todos os arquivos.
Segue-se a notória falta de licença, e ainda temos que analisá-la mais detalhadamente, uma vez que esta situação é tão comum entre repositórios de médio e grande porte (mais de 50 estrelas). Essa circunstância é muito importante, já que apenas carregar o código no GitHub não o abre.- e se há algo prático e você precisa se lembrar deste artigo, então é isso. Ao enviar seu código para o GitHub, você concorda com os termos de uso, que afirmam que seu código pode ser visualizado e bifurcado. No entanto, com exceção disso, todos os direitos sobre o código permanecem com o autor, portanto, a distribuição, modificação e até mesmo o uso requerem permissão explícita. Acontece que não apenas o código-fonte aberto não é totalmente gratuito, nem todo o código do GitHub é totalmente código-fonte aberto! E como existe muito código desse tipo (14% dos arquivos, e entre os projetos menos populares que não estão incluídos no conjunto de dados, provavelmente ainda mais), isso pode ser a causa de um número significativo de violações.
Nos cinco primeiros, também vemos as licenças permissivas já mencionadas do MIT e BSD, bem como copyleft GPL-3.0-or-later. As licenças da família GPL diferem não apenas em um número significativo de versões (não tão ruins), mas também no postscript "ou posterior", que permite ao usuário usar os termos desta licença ou de suas versões posteriores. Isso leva a outra questão: entre essas 94 licenças, há claramente "famílias" semelhantes - quais delas são as maiores?
Em terceiro lugar estão as licenças GPL - existem 8 tipos delas na lista. Essa família é a mais significativa, pois juntas cobrem 12,6% dos arquivos, perdendo apenas para o Apache-2.0 e falta de licença. Em segundo lugar, inesperadamente, BSD. Além da versão tradicional de 3 parágrafos e até mesmo das versões de 2 e 4 parágrafos, há muitolicenças específicas - apenas 11 peças. Estes incluem, por exemplo, o BSD 3-Clause No Nuclear License , que é um BSD normal com 3 cláusulas, para o qual é declarado abaixo que este software não deve ser usado para criar ou operar qualquer coisa nuclear:
Você reconhece que este software não foi projetado, licenciado ou destinado ao uso no projeto, construção, operação ou manutenção de qualquer instalação nuclear.
A mais diversa é a família de licenças Creative Commons, sobre a qual você pode ler aqui . Havia até 13 deles e também vale a pena pelo menos folhear por um motivo importante: todo o código no StackOverflow é licenciado sob CC-BY-SA.
Entre as licenças mais raras, há algumas notáveis, por exemplo,Faça o que quiser com a licença pública (WTFPL) , que cobre 529 arquivos e permite que você faça exatamente o que o nome diz com o código. Existe também, por exemplo, a Licença Beerware , que também permite que você faça qualquer coisa e incentiva o autor a comprar uma cerveja em uma reunião. Em nosso conjunto de dados, também encontramos uma variação desta licença, que não encontramos em nenhum outro lugar - a Licença Sushiware . Ela, portanto, incentiva o autor a comprar sushi.
Outra situação curiosa é quando várias licenças são encontradas em um arquivo (nomeadamente no arquivo). Em nosso conjunto de dados, existem apenas 0,9% desses arquivos. 7,4 mil arquivos são cobertos por duas licenças ao mesmo tempo, e um total de 74 pares diferentes dessas licenças foram encontrados. 419 arquivos são cobertos por até três licenças, e há 8 trios. E, finalmente,um arquivo em nosso conjunto de dados menciona quatro licenças diferentes no cabeçalho.
Possíveis empréstimos
Agora que falamos sobre licenças, podemos discutir a relação entre eles. A primeira coisa a fazer é remover os clones que não são possíveis empréstimos . Deixe-me lembrá-lo de que, no momento, tentamos levar isso em consideração de duas maneiras - o tamanho mínimo dos fragmentos de código e a exclusão de clones dentro de um projeto. Agora filtraremos mais três tipos de pares:
- Não estamos interessados em pares entre o garfo e o original (bem como, por exemplo, entre dois garfos do mesmo projeto) - para isso os recolhemos.
- Também não estamos interessados em clones entre diferentes projetos pertencentes à mesma organização ou usuário (uma vez que assumimos que o copyright é compartilhado dentro da mesma organização).
- Finalmente, ao verificar manualmente um número anormalmente grande de clones entre os dois projetos, encontramos espelhos significativos (também conhecidos como bifurcações indiretas), ou seja, projetos idênticos carregados em repositórios não relacionados.
Curiosamente, até 11,7% dos pares restantes são clones idênticos com um limite de similaridade de 100% - talvez intuitivamente pareça que deveria haver código menos absolutamente idêntico no GitHub.
Processamos todos os pares restantes após esta filtragem da seguinte maneira:
- Comparamos o tempo da última modificação de dois métodos em um par.
- , : .
- , «» «» . , 2015 MIT, 2018 — Apache-2.0, MIT → Apache-2.0.
No final, somamos o número de pares para cada empréstimo potencial e os classificamos em ordem decrescente:
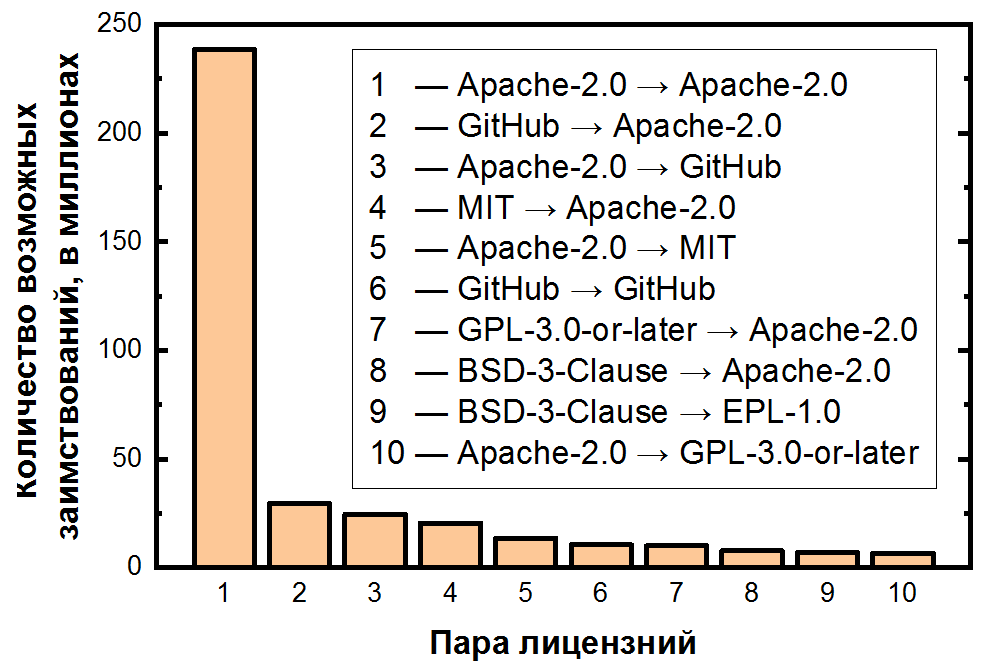
aqui a dependência é ainda mais extrema: o possível empréstimo de código dentro do Apache-2.0 é responsável por mais da metade de todos os pares de clones, e os primeiros 10 pares de licenças já cobrem mais de 80% dos clones. Também é importante observar que o segundo e o terceiro pares mais frequentes lidam com arquivos não licenciados - também uma consequência clara de sua frequência. Para as cinco licenças mais populares, você pode exibir as transições como um mapa de calor:
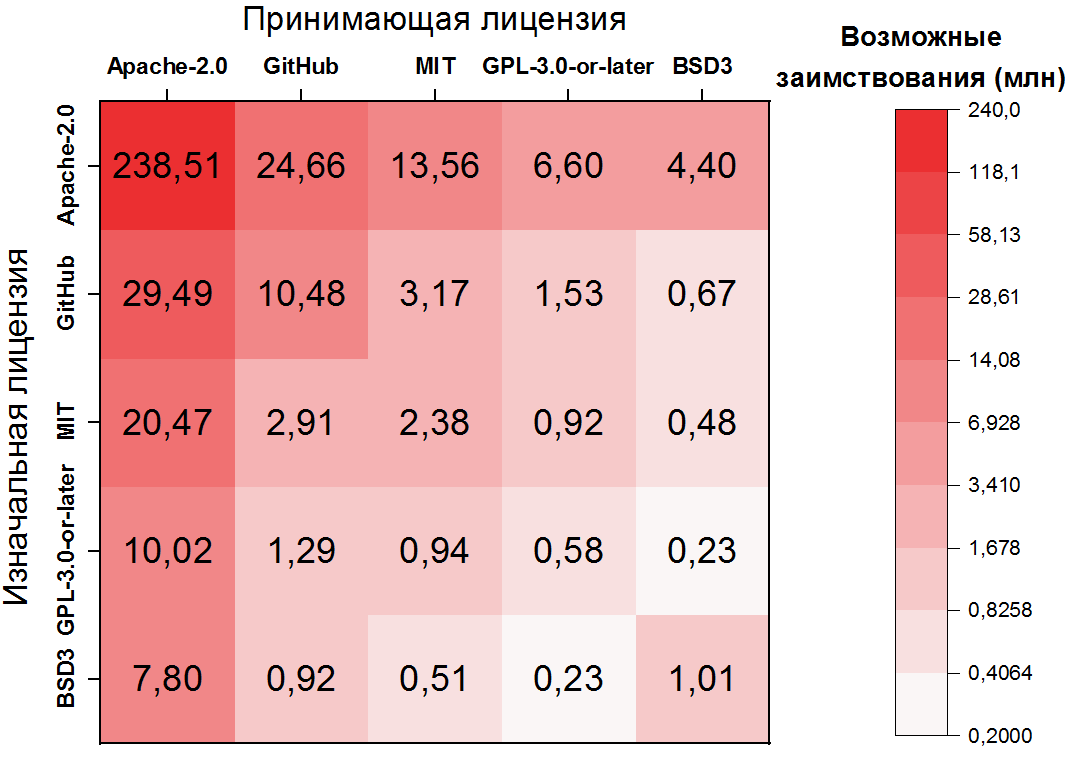
Possíveis violações de licenciamento
A próxima etapa de nossa pesquisa é identificar pares de clones que são violações em potencial , ou seja, empréstimos que violam os termos das licenças original e de host. Para fazer isso, você precisa marcar os pares de licenças mencionados acima como transições permitidas ou proibidas . Então, por exemplo, a transição mais popular ( Apache-2.0 → Apache-2.0 ) é, obviamente, permitida, mas a segunda ( GitHub → Apache-2.0 ) é proibida. Mas existem muitíssimos, existem milhares desses pares.
Para lidar com isso, lembre-se de que os primeiros 10 pares de licenças processados cobrem 80% de todos os pares de clones. Devido a esse desnível, acabou sendo suficiente marcar manualmente apenas 176 pares de licenças para cobrir 99% dos pares de clones, o que nos pareceu uma precisão bastante aceitável. Entre esses casais, consideramos quatro tipos de casais proibidos:
- Copie de arquivos sem licença (GitHub). Como já mencionado, essa cópia requer permissão direta do autor do código e assumimos que na grande maioria dos casos não é.
- Copiar para arquivos sem licença também é proibido, porque isso é essencialmente apagar, remover licenças. Licenças permissivas como Apache-2.0 ou BSD permitem que o código seja reutilizado em outras licenças (incluindo as proprietárias), mas mesmo essas requerem que a licença original seja mantida no arquivo.
- .
- (, Apache-2.0 → GPL-2.0).
Todos os outros pares raros de licenças cobrindo 1% dos clones foram marcados como permissivos (para não culpar ninguém desnecessariamente), exceto aqueles em que o código sem licença aparece (que nunca pode ser copiado).
Como resultado, após a marcação, descobriu-se que 72,8% dos empréstimos são permitidos e 27,2% proibidos. Os gráficos a seguir mostram as licenças mais violadas e as que mais violam .

À esquerda estão as licenças mais violadas, ou seja, as fontes do maior número de violações possíveis. Entre eles, o primeiro lugar é ocupado por arquivos sem licenças, o que é uma nota prática importante - você precisa monitorar especialmente de perto os arquivos sem licenças.... Alguém pode se perguntar o que a licença permissiva Apache-2.0 faz nesta lista. No entanto, como você pode ver no mapa de calor acima, ~ 25 milhões de empréstimos proibidos são empréstimos para um arquivo sem licença, portanto, isso é uma consequência de sua popularidade.
À direita estão as licenças que são copiadas com violações e, aqui, a maioria são as mesmas Apache-2.0 e GitHub.
Origem dos métodos individuais
Finalmente, chegamos ao último ponto de nossa pesquisa. Todo esse tempo conversamos sobre pares de clones, como é costume nesses estudos. No entanto, você precisa entender uma certa unilateralidade, incompletude de tais julgamentos. O fato é que se, por exemplo, um trecho do código tem 20 irmãos "mais velhos" (ou "pais", quem sabe), todos os 20 pares serão considerados empréstimos potenciais. É por isso que estamos falando sobre empréstimos "potenciais" e "possíveis" - é improvável que o autor de um método particular o tenha emprestado de 20 lugares diferentes. Apesar disso, esse raciocínio pode ser visto como um raciocínio sobre clones entre licenças diferentes.
Para evitar julgamentos incompletos, você pode olhar para a mesma imagem de um ângulo diferente. A imagem de clonagem é na verdade um gráfico direcionado: todos os métodos são vértices nele, que são conectados por arestas direcionadas do mais antigo ao mais novo (se você não levar em consideração os métodos datados no mesmo dia). Nas duas seções anteriores, vimos este gráfico do ponto de vista das arestas: pegamos cada aresta e estudamos seus vértices (obtendo esses mesmos pares de licenças). Agora vamos olhar para isso do ponto de vista dos vértices. Cada vértice (método) no gráfico possui ancestrais (clones "sênior") e descendentes (clones "juniores"). Os links entre eles também podem ser divididos em "permitidos" e "proibidos".
Com base nisso, cada método pode ser atribuído a uma das seguintes categorias, cujos gráficos são mostrados na imagem (aqui as linhas sólidas indicam empréstimo proibido e as linhas pontilhadas - permitido):

Duas das configurações apresentadas podem constituir uma violação das condições de licenciamento:
- Uma violação grave significa que o método possui ancestrais e todas as transições a partir deles são proibidas. Isso significa que se o desenvolvedor realmente copiou o código, ele o fez violando as licenças.
- Uma violação fraca significa que o método tem ancestrais e apenas alguns deles estão por trás de transições proibidas. Isso significa que o desenvolvedor pode ter copiado o código em violação da licença.
O resto das configurações não são violações:
- , , .
- — , — , .
- , , — , . , , — , . : , , , , ( , , ).
Então, como os métodos são distribuídos em nosso conjunto de dados?

Você pode ver que cerca de um terço dos métodos não têm clones, e outro terço tem clones apenas em projetos vinculados. Por outro lado, 5,4% dos métodos representam “infração leve” e 4% - “infração grave”. Embora esses números possam não parecer muito grandes, ainda existem centenas de milhares de métodos em projetos mais ou menos grandes.
TL; DR
Considerando que este artigo contém muitos números empíricos e gráficos, vamos repetir nossas principais descobertas:
- Os métodos com clones chegam a milhões e há mais de um bilhão de pares entre eles.
- , Java- 50 , 94 , : Apache-2.0 . Apache-2.0 .
- , 27,2%, .
- 35,4% , 5,4% «» , 4% «» .
?
Concluindo, eu gostaria de falar sobre por que todos os itens acima são necessários. Eu tenho pelo menos três respostas.
Primeiro, é interessante . O licenciamento é tão diverso quanto todos os outros aspectos da programação. A lista de licenças em si é bastante curiosa devido à especificidade e raridade de algumas licenças, as pessoas as escrevem e trabalham de diferentes maneiras. Isso também se aplica, sem dúvida, a clones no código e semelhança de código em geral. Existem métodos com milhares de clones e existem métodos sem um único, embora à primeira vista nem sempre seja fácil notar a diferença fundamental entre eles.
Em segundo lugar, uma análise detalhada de nossas descobertas nos permite formular várias dicas práticas :
- - . Apache-2.0, MIT, BSD-3-Clause, GPL LGPL.
- : . - , , .
- GitHub, . . — , . : - , , , , . , .
Para obter descrições claras de licenças, bem como conselhos sobre como escolher uma licença para seu novo projeto, você pode recorrer a serviços como tldrlegal ou choosealicense .
Finalmente, os dados obtidos podem ser usados para criar ferramentas . No momento, nossos colegas estão desenvolvendo uma maneira de determinar rapidamente as licenças usando métodos de aprendizado de máquina (para os quais você só precisa de muitas licenças específicas) e um plug-in IDE que permitirá aos desenvolvedores rastrear dependências em seus projetos e notar possíveis incompatibilidades com antecedência.
Felizmente, você aprendeu algo novo com este artigo. O cumprimento dos termos básicos de licenciamento não é tão complicado, e você pode fazer tudo de acordo com as regras com um mínimo de esforço. Vamos educar, educar outras pessoas e chegar mais perto do sonho do software de código aberto “certo” juntos!