Mas, como as pessoas não são computadores, elas procuram algo como " algo assim era de Ivanov ou de Ivanovsky ... não, isso não, antes, antes mesmo ... é isso! "
Mas isso ameaça o desenvolvedor com problemas terríveis - afinal, para FTS-search em PostgreSQL , são usados tipos "espaciais" de índices GIN e GiST , que não fornecem "deslizamento" de dados adicionais, exceto para um vetor de texto.
Resta apenas, infelizmente, ler todos os registros por correspondência de prefixo (há milhares deles!) E classificar ou, inversamente, ir pelo índice de data e filtrartodos os registros encontrados para o prefixo correspondem até encontrarmos os adequados (em quanto tempo haverá "rabiscos"? ..).
Ambos não são muito agradáveis para o desempenho de consultas. Ou ainda consegue pensar em algo para uma pesquisa rápida?
Primeiro, vamos gerar nossos "textos atualizados":
CREATE TABLE corpus AS
SELECT
id
, dt
, str
FROM
(
SELECT
id::integer
, now()::date - (random() * 1e3)::integer dt -- - 3
, (random() * 1e2 + 1)::integer len -- "" 100
FROM
generate_series(1, 1e6) id -- 1M
) X
, LATERAL(
SELECT
string_agg(
CASE
WHEN random() < 1e-1 THEN ' ' -- 10%
ELSE chr((random() * 25 + ascii('a'))::integer)
END
, '') str
FROM
generate_series(1, len)
) Y;
Abordagem ingênua nº 1: gist + btree
Vamos tentar lançar o índice tanto para FTS quanto para classificação por data - e se eles ajudarem:
CREATE INDEX ON corpus(dt);
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str));
Pesquisaremos todos os documentos que contenham palavras que comecem com
'abc...'
. E, primeiro, vamos verificar se não há muitos desses documentos, e o índice FTS é usado normalmente:
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*');
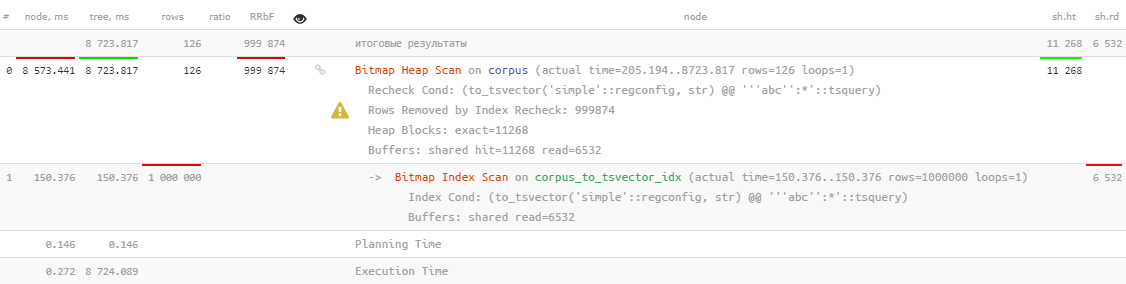
Bem ... é, claro, usado, mas leva mais de 8 segundos , o que claramente não é o que gostaríamos de gastar procurando por 126 registros.
Talvez se você adicionar classificação por data e pesquisar apenas os últimos 10 registros - será melhor?
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt DESC
LIMIT 10;

Mas não, apenas a classificação foi adicionada ao topo.
Abordagem ingênua nº 2: btree_gist
Mas há uma extensão excelente
btree_gist
que permite "deslizar" um valor escalar em um índice GiST, o que deve nos permitir usar imediatamente a classificação de índice usando o operador de distância
<->
, que pode ser usado para pesquisas kNN :
CREATE EXTENSION btree_gist;
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str), dt);
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt <-> '2100-01-01'::date DESC -- ""
LIMIT 10;
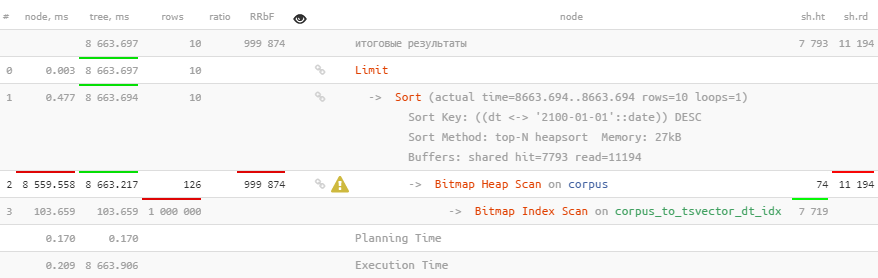
Infelizmente, isso não ajuda em nada.
Geometria para o resgate!
Mas é muito cedo para se desesperar! Vejamos a lista de classes de operadores integradas GiST - o operador de distância está
<->
disponível apenas para "geométrico"
circle_ops, point_ops, poly_ops
e, desde o PostgreSQL 13 - para
box_ops
.
Então, vamos tentar traduzir nosso problema "para o plano" - atribuímos as coordenadas de alguns pontos aos nossos pares
(, )
usados para pesquisa de modo que as palavras "prefixadas" e as datas não distantes sejam o mais próximo possível:

Nós quebramos o texto em palavras
É claro que nossa pesquisa não será totalmente em texto completo, no sentido de que você não pode definir uma condição para várias palavras ao mesmo tempo. Mas com certeza será um prefixo!
Vamos formar uma tabela de dicionário auxiliar:
CREATE TABLE corpus_kw AS
SELECT
id
, dt
, kw
FROM
corpus
, LATERAL (
SELECT
kw
FROM
regexp_split_to_table(lower(str), E'[^\\-a-z-0-9]+', 'i') kw
WHERE
length(kw) > 1
) T;
Em nosso exemplo, havia 4,8 milhões de “palavras” por 1 milhão de “textos”.
Escrevendo as palavras
Para traduzir uma palavra em sua "coordenada", vamos imaginar que este seja um número escrito em notação de base
2^16
(afinal, também queremos oferecer suporte a caracteres UNICODE). Vamos apenas anotá-lo a partir da 47ª posição fixa:
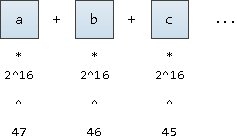
Seria possível começar da 63ª posição, isso nos dará valores um pouco menores do que os valores
1E+308
limite para
double precision
, mas então ocorrerá um estouro ao construir o índice.
Acontece que no eixo das coordenadas todas as palavras serão ordenadas:

ALTER TABLE corpus_kw ADD COLUMN p point;
UPDATE
corpus_kw
SET
p = point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
);
CREATE INDEX ON corpus_kw USING gist(p);
Nós formamos uma consulta de pesquisa
WITH src AS (
SELECT
point(
( --
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
SELECT
*
, src.ps <-> kw.p d
FROM
corpus_kw kw
, src
ORDER BY
d
LIMIT 10;

Agora temos os
id
documentos que procurávamos, classificados na ordem certa - e demorou menos de 2 ms, 4.000 vezes mais rápido !
Uma pequena mosca na pomada
O operador
<->
não sabe nada sobre a nossa ordenação ao longo de dois eixos, portanto, nossos dados necessários estão localizados apenas em um dos trimestres corretos, dependendo da classificação exigida por data:

Bem, ainda queríamos selecionar os próprios textos-documentos, e não suas palavras-chave, então vamos precisar de um índice há muito esquecido:
CREATE UNIQUE INDEX ON corpus(id);
Vamos finalizar a solicitação:
WITH src AS (
SELECT
point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
, dc AS (
SELECT
(
SELECT
dc
FROM
corpus dc
WHERE
id = kw.id
)
FROM
corpus_kw kw
, src
WHERE
p[0] >= ps[0] AND -- kw >= ...
p[1] <= ps[1] -- dt DESC
ORDER BY
src.ps <-> kw.p
LIMIT 10
)
SELECT
(dc).*
FROM
dc;

Eles nos acrescentaram um pouco
InitPlan
com o cálculo da constante x / y, mas ainda assim mantivemos dentro dos mesmos 2 ms !
Mosca na pomada # 2
Nada é gratuito:
SELECT relname, pg_size_pretty(pg_total_relation_size(oid)) FROM pg_class WHERE relname LIKE 'corpus%';
corpus | 242 MB -- corpus_id_idx | 21 MB -- PK corpus_kw | 705 MB -- corpus_kw_p_idx | 403 MB -- GiST-
242 MB de "textos" tornaram-se 1,1 GB de "índice de pesquisa".
Mas, afinal,
corpus_kw
a data e a própria palavra estão, que não usamos na própria pesquisa - então, vamos excluí-las:
ALTER TABLE corpus_kw
DROP COLUMN kw
, DROP COLUMN dt;
VACUUM FULL corpus_kw;
corpus_kw | 641 MB -- id point
Um pouco - mas agradável. Não ajudou muito, mas ainda assim 10% do volume foi recuperado.