Vamos em ordem. E imediatamente um pequeno aviso: o artigo foi escrito com base no meu discurso no Ya Subbotnik Pro para desenvolvedores front-end. Se você é um desenvolvedor de back-end, pode não descobrir nada de novo por si mesmo. Aqui, tentarei resumir minha experiência de front-end em uma grande empresa, explicar por que e como usamos o Node.js.
Vamos definir o que consideraremos como front-end neste artigo. Vamos deixar de lado as disputas por tarefas e nos concentrar na essência.
O frontend é a parte do aplicativo responsável pela exibição. Pode ser diferente: navegador, desktop, celular. Mas sempre há um recurso importante - o front-end precisa de dados. Sem um back-end que forneça esses dados, é inútil. Aqui está uma fronteira bastante clara. O backend sabe como ir aos bancos de dados, aplicar regras de negócio aos dados recebidos e dar o resultado ao frontend, que vai aceitar os dados, modelá-los e dar beleza ao usuário.
Podemos dizer que conceitualmente o back-end é necessário para o front-end receber e salvar dados. Exemplo: um típico site moderno com uma arquitetura cliente-servidor. O cliente no navegador (para chamá-lo fino, a linguagem não girará mais) bate no servidor onde o backend está sendo executado. E é claro que existem exceções em todos os lugares. Existem aplicativos de navegador complexos que não precisam de um servidor (não consideraremos este caso) e há a necessidade de executar um front-end no servidor - o que é chamado de Server Side Rendering ou SSR. Vamos começar com isso, porque este é o caso mais simples e compreensível.
SSR
O mundo ideal para o back-end é o seguinte: solicitações HTTP com dados chegam na entrada do aplicativo e, na saída, temos uma resposta com novos dados em um formato conveniente. Por exemplo JSON. APIs HTTP são fáceis de testar e entender como desenvolver. No entanto, a vida faz ajustes: às vezes a API sozinha não é suficiente.
O servidor deve responder com HTML pronto para alimentá-lo ao rastreador do mecanismo de pesquisa, renderizar uma visualização com metatags para inserção na rede social ou, mais importante, acelerar a resposta em dispositivos fracos. Assim como nos tempos antigos, quando desenvolvíamos a Web 2.0 em PHP.
Tudo é familiar e foi descrito por um longo tempo, mas o cliente mudou - motores de template do lado do cliente imperativos chegaram a ele. Na web moderna, JSX domina a bola, cujos prós e contras podem ser discutidos por um longo tempo, mas uma coisa não pode ser negada - na renderização do servidor, você não pode fazer sem código JavaScript.
Acontece que quando você precisa implementar SSR pelo desenvolvimento de back-end:
- As áreas de responsabilidade são mistas. Os programadores de back-end estão começando a se responsabilizar pela renderização.
- As línguas são misturadas. Os programadores de back-end começam a usar JavaScript.
A saída é separar o SSR do back-end. No caso mais simples, pegamos um tempo de execução JavaScript, colocamos nele uma solução autoescrita ou uma estrutura (Next, Nuxt, etc.) que funciona com o mecanismo de modelo JavaScript de que precisamos e passamos o tráfego por ele. Um padrão familiar no mundo moderno.
Portanto, já deixamos os desenvolvedores front-end no servidor um pouco. Vamos passar para uma questão mais importante.
Recebendo dados
Uma solução popular é criar APIs genéricas. Essa função é geralmente assumida pelo API Gateway, que pode pesquisar uma variedade de microsserviços. No entanto, também surgem problemas aqui.
Primeiro, o problema das equipes e áreas de responsabilidade. Um grande aplicativo moderno é desenvolvido por muitas equipes. Cada equipe está focada em seu próprio domínio de negócio, tem seu próprio microsserviço (ou mesmo vários) no back-end e suas próprias telas no cliente. Não entraremos no problema dos microfrontros e da modularidade, este é um tópico complexo separado. Suponha que as visualizações do cliente sejam completamente separadas e sejam mini-SPA (Aplicativo de página única) em um grande site.
Cada equipe possui desenvolvedores front-end e back-end. Todos estão trabalhando em seus próprios aplicativos. O API Gateway pode ser um obstáculo. Quem é o responsável por isto? Quem adicionará novos terminais? Uma superequipe de API dedicada que estará sempre ocupada resolvendo problemas para todos os outros no projeto? Qual será o custo de um erro? A queda deste portal irá derrubar todo o sistema.
Em segundo lugar, o problema de dados redundantes / insuficientes. Vamos dar uma olhada no que acontece quando dois front-ends diferentes usam a mesma API genérica.

Essas duas interfaces são muito diferentes. Eles precisam de conjuntos de dados diferentes, eles têm ciclos de lançamento diferentes. A variabilidade das versões do front-end móvel é máxima, então somos forçados a projetar a API com compatibilidade retroativa máxima. A variabilidade do cliente web é baixa; na verdade, só precisamos dar suporte a uma versão anterior para reduzir o número de bugs no momento do lançamento. Mas mesmo que a API “genérica” sirva apenas clientes da web, ainda enfrentamos o problema de dados redundantes ou insuficientes.
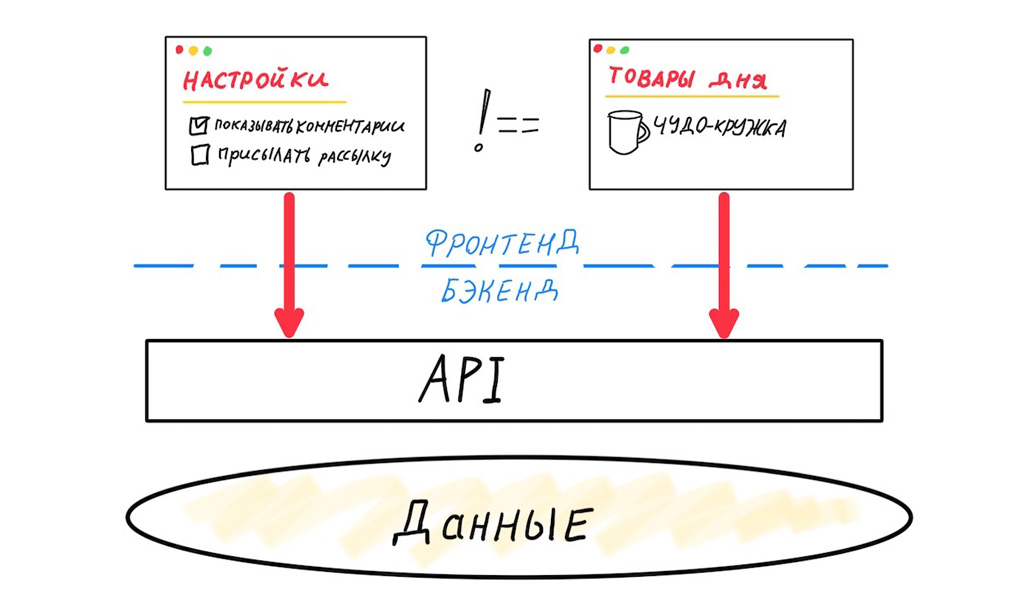
Cada mapeamento requer um conjunto separado de dados, que é desejável extrair com uma consulta ideal.
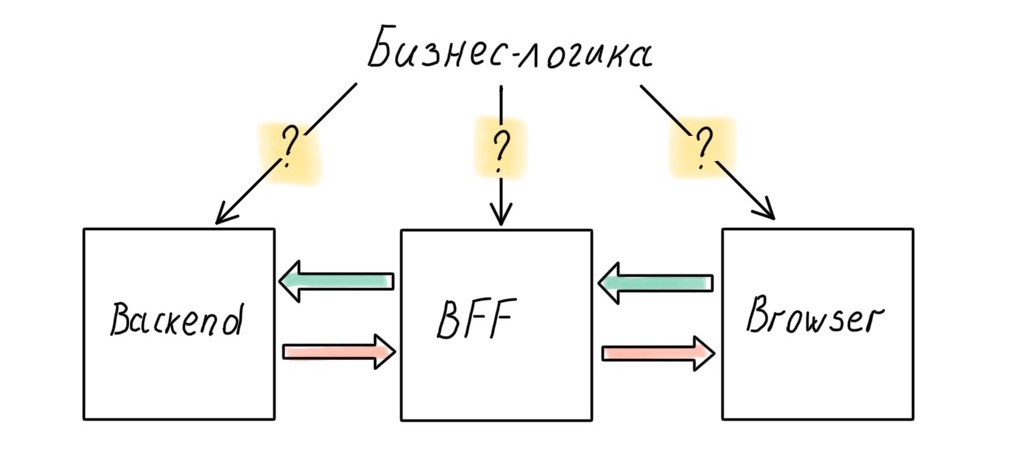
Nesse caso, uma API universal não funcionará para nós, teremos que separar as interfaces. Isso significa que você precisa de seu próprio API Gateway para cadaa parte dianteira. A palavra "cada" aqui denota um mapeamento exclusivo que opera em seu próprio conjunto de dados.

Podemos confiar a criação de tal API a um desenvolvedor de back-end que terá que trabalhar com o front-end e implementar seus desejos, ou, o que é muito mais interessante e em muitos aspectos mais eficiente, fornecer a implementação da API para a equipe de front-end. Isso vai tirar a dor de cabeça da implementação do SSR: você não precisa mais instalar uma camada que bate na API, tudo será integrado em um aplicativo de servidor. Além disso, controlando o SSR, podemos colocar todos os dados primários necessários na página no momento da renderização, sem fazer solicitações adicionais ao servidor.
Essa arquitetura é chamada de Backend For Frontend ou BFF. A ideia é simples: um novo aplicativo aparece no servidor que escuta as solicitações do cliente, pesquisa back-ends e retorna a resposta ideal. E, claro, esse aplicativo é controlado pelo desenvolvedor front-end.

Mais de um servidor no backend? Não é um problema!

Independentemente do protocolo de comunicação que o desenvolvimento de back-end prefere, podemos usar qualquer maneira conveniente de nos comunicarmos com o cliente web. REST, RPC, GraphQL - nós escolhemos a nós mesmos.
Mas o GraphQL por si só não é a solução para o problema de obter dados em uma única consulta? Talvez você não precise cercar nenhum serviço intermediário?
Infelizmente, o trabalho eficaz com GraphQL é impossível sem a cooperação próxima com os desenvolvedores de back-end que assumem o desenvolvimento de consultas de banco de dados eficientes. Ao escolher essa solução, perderemos novamente o controle sobre os dados e voltaremos ao ponto de partida.

É possível, claro, mas não é interessante (para um frontend)
Bem, vamos implementar o BFF. Claro, em Node.js. Por quê? Precisamos de uma única linguagem no cliente e no servidor para reutilizar a experiência de desenvolvedores front-end e JavaScript para trabalhar com modelos. E quanto a outros ambientes de tempo de execução?

GraalVM e outras soluções exóticas são inferiores ao V8 em desempenho e são muito específicas. Deno ainda é um experimento e não é usado na produção.
E um momento. Node.js é uma solução surpreendentemente boa para implementar o API Gateway. A arquitetura do Node permite um único interpretador JavaScript encadeado combinado com libuv, uma biblioteca de E / S assíncrona que, por sua vez, usa um pool de encadeamentos.
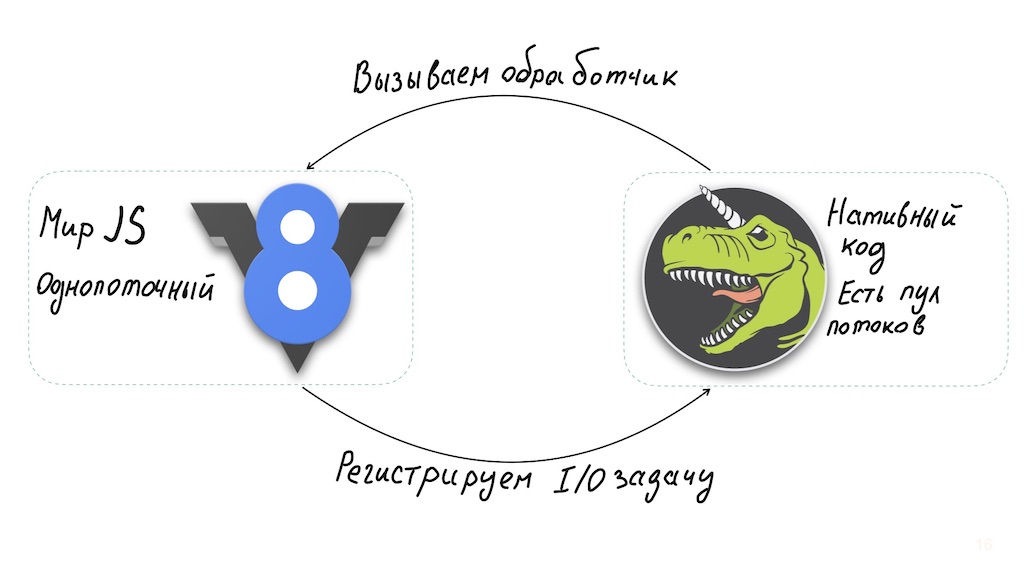
Cálculos longos no lado do JavaScript afetam o desempenho do sistema. Você pode contornar isso: execute-os em workers separados ou leve-os ao nível de módulos binários nativos.
Mas, no caso básico, o Node.js não é adequado para operações com uso intensivo de CPU e, ao mesmo tempo, funciona muito bem com E / S assíncrona, fornecendo alto desempenho. Ou seja, temos um sistema que sempre pode responder rapidamente ao usuário, independentementesobre o quão ocupado está o back-end. Você pode lidar com essa situação notificando instantaneamente o usuário para aguardar o fim da operação.
Onde armazenar a lógica de negócios
Nosso sistema agora tem três grandes partes: backend, frontend e BFF entre eles. Surge uma questão razoável (para um arquiteto): onde manter a lógica de negócios?

Obviamente, um arquiteto não quer manchar as regras de negócios em todas as camadas do sistema; deve haver uma fonte de verdade. E essa fonte é o back-end. Onde mais armazenar políticas de alto nível, se não na parte do sistema mais próxima dos dados?

Mas, na realidade, isso nem sempre funciona. Por exemplo, surge um problema de negócios que pode ser implementado de forma eficiente e rápida no nível do BFF. O design de sistema perfeito é ótimo, mas tempo é dinheiro. Às vezes, você tem que sacrificar a limpeza da arquitetura e as camadas começam a vazar.
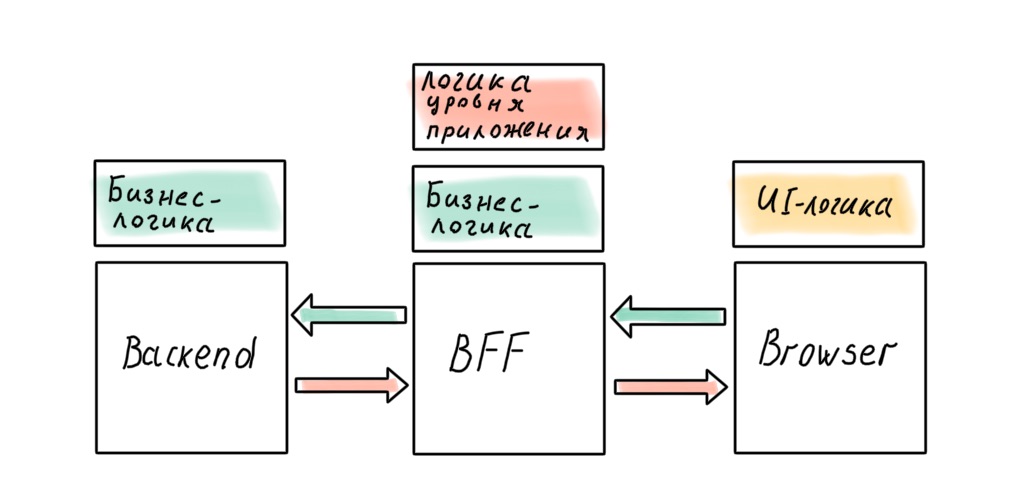
Podemos obter a arquitetura perfeita trocando o BFF em favor de um back-end Node.js "completo"? Parece que neste caso não haverá vazamentos.
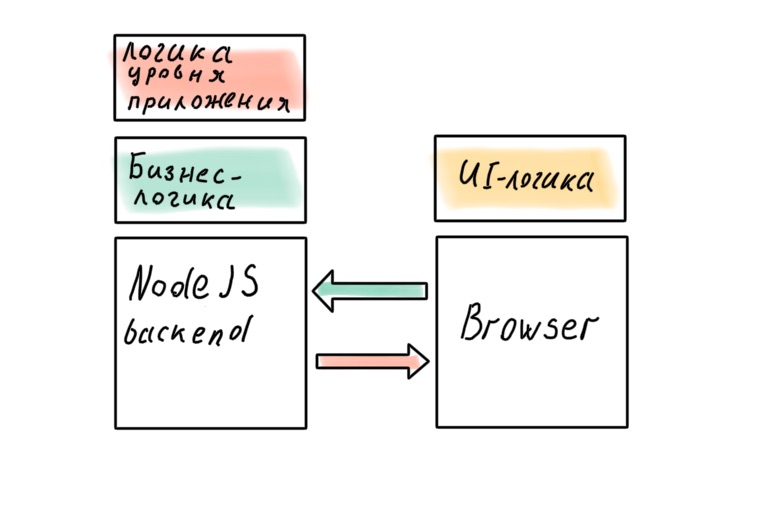
Não é um fato. Haverá regras de negócios que, se transferidas para o servidor, afetarão a capacidade de resposta da interface. Você pode resistir até o fim, mas muito provavelmente não será capaz de evitar completamente. A lógica no nível do aplicativo também penetrará no cliente: no SPA moderno, ela é espalhada entre o cliente e o servidor, mesmo no caso em que há um BFF.

Não importa o quanto tentemos, a lógica de negócios se infiltrará no API Gateway no Node.js. Vamos corrigir essa conclusão e passar para o mais delicioso - implementação!
Grande bola de lama
A solução mais popular para aplicativos Node.js nos últimos anos é o Express. Comprovado, mas de nível muito baixo e não oferece boas abordagens arquitetônicas. O padrão principal é o middleware. Uma aplicação típica no Express como um grande monte de lama (não é xingamento e é antipadrão ).
const express = require('express');
const app = express();
const {createReadStream} = require('fs');
const path = require('path');
const Joi = require('joi');
app.use(express.json());
const schema = {id: Joi.number().required() };
app.get('/example/:id', (req, res) => {
const result = Joi.validate(req.params, schema);
if (result.error) {
res.status(400).send(result.error.toString()).end();
return;
}
const stream = createReadStream( path.join('..', path.sep, `example${req.params.id}.js`));
stream
.on('open', () => {stream.pipe(res)})
.on('error', (error) => {res.end(error.toString())})
});Todas as camadas são misturadas, em um arquivo há um controlador, onde tudo está lá: lógica de infraestrutura, validação, lógica de negócios. É doloroso trabalhar com isso, você não quer manter esse código. Podemos escrever código de nível empresarial em Node.js?

Isso requer uma base de código fácil de manter e desenvolver. Em outras palavras, você precisa de arquitetura.
Arquitetura do aplicativo Node.js (finalmente)
"O objetivo da arquitetura de software é reduzir o esforço humano envolvido na construção e manutenção de um sistema."
Robert "Tio Bob" Martin
A arquitetura consiste em duas coisas importantes: camadas e as conexões entre elas. Devemos dividir nossa aplicação em camadas, evitar vazamentos de uma para outra, organizar adequadamente a hierarquia das camadas e as conexões entre elas.
Camadas
Como divido meu aplicativo em camadas? Existe uma abordagem clássica em três camadas: dados, lógica, apresentação.
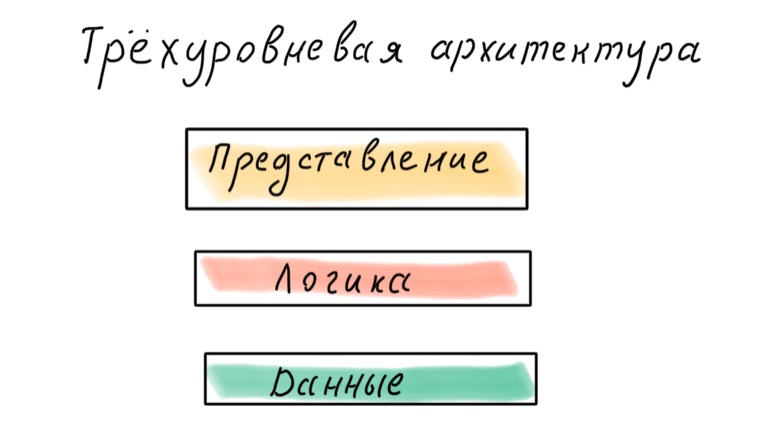
Essa abordagem agora é considerada obsoleta. O problema é que os dados são a base, o que significa que o aplicativo é projetado dependendo de como os dados são apresentados no banco de dados, e não de quais processos de negócios estão envolvidos.
Uma abordagem mais moderna pressupõe que o aplicativo tenha uma camada de domínio dedicada que funciona com a lógica de negócios e é uma representação de processos de negócios reais em código. No entanto, se nos voltarmos para o clássico Domain-Driven Design de Eric Evans , encontraremos lá o seguinte esquema de camada de aplicativo:

O que há de errado aqui? Parece que a base de um aplicativo desenvolvido com DDD deve ser um domínio - políticas de alto nível, a lógica mais importante e valiosa. Mas sob essa camada está toda a infraestrutura: camada de acesso a dados (DAL), registro, monitoramento, etc. Ou seja, políticas de um nível muito inferior e de menor importância.
A infraestrutura está no centro da aplicação e uma substituição banal do logger pode levar a uma sacudida em toda a lógica de negócios.
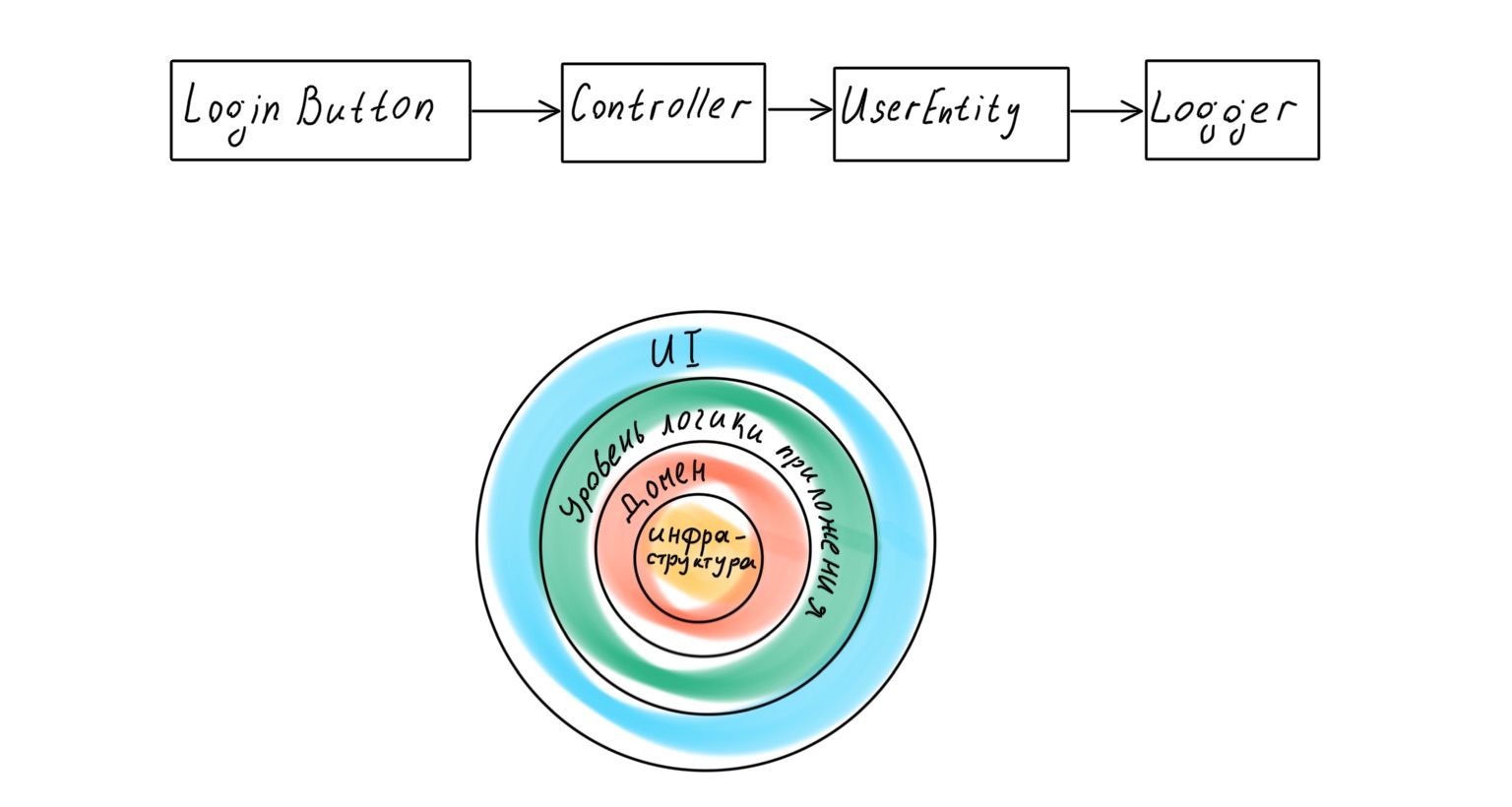
Se nos voltarmos para Robert Martin novamente, descobriremos que no livro Clean Architecture ele postula uma hierarquia de camadas diferente na aplicação, com o domínio no centro.
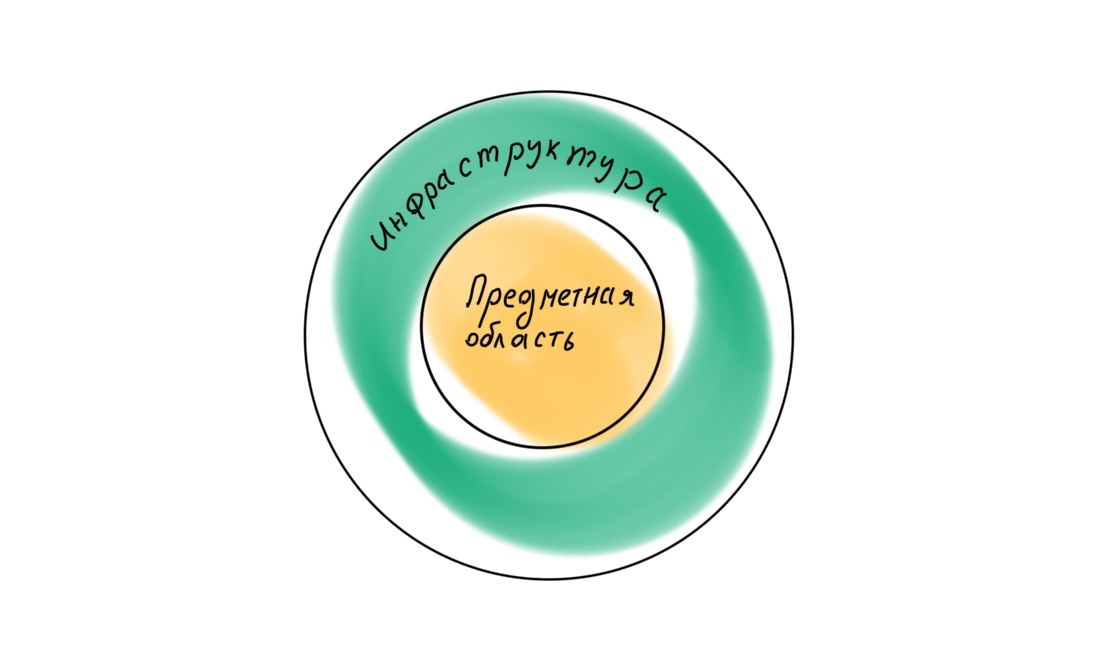
Conseqüentemente, todas as quatro camadas devem ser organizadas de maneira diferente:
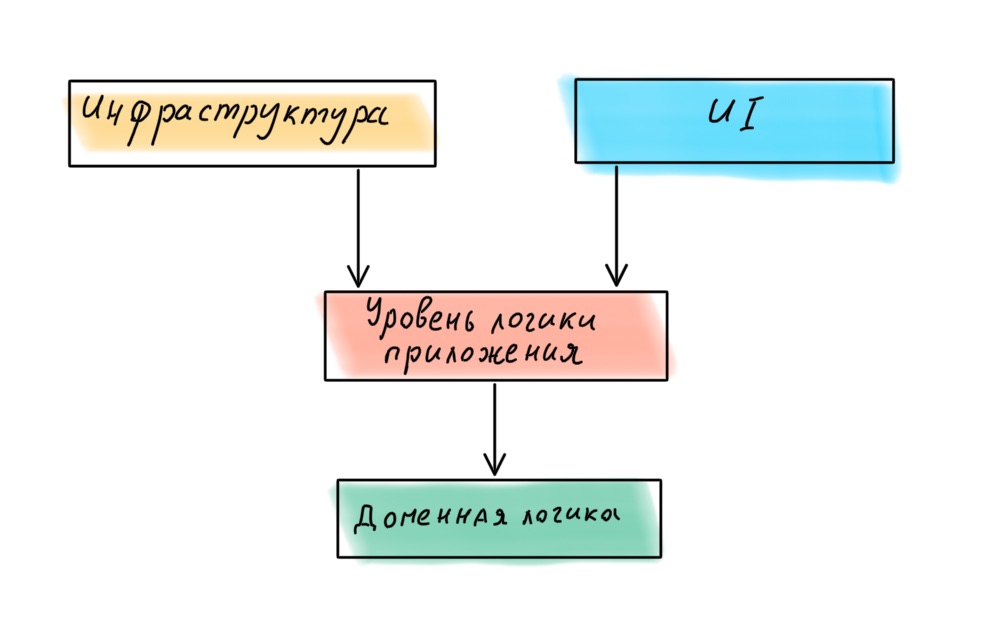
Selecionamos as camadas e definimos sua hierarquia. Agora vamos passar para as conexões.
Conexões
Vamos voltar ao exemplo com a chamada lógica do usuário. Como se livrar da dependência direta da infraestrutura para garantir a correta hierarquia de camadas? Existe uma maneira simples e conhecida de reverter dependências - interfaces.

Agora, o UserEntity de alto nível não depende do Logger de baixo nível. Pelo contrário, dita o contrato que deve ser implementado para incluir o Logger no sistema. Substituir o logger, neste caso, se resume a conectar uma nova implementação que observe o mesmo contrato. Uma questão importante é como conectá-lo?
import {Logger} from ‘../core/logger’;
class UserEntity {
private _logger: Logger;
constructor() {
this._logger = new Logger();
}
...
}
...
const UserEntity = new UserEntity();As camadas estão rigidamente conectadas. Existe um vínculo com a estrutura e implementação do arquivo. Precisamos de Inversão de Dependências, que faremos usando Injeção de Dependências.
export class UserEntity {
constructor(private _logger: ILogger) { }
...
}
...
const logger = new Logger();
const UserEntity = new UserEntity(logger);Agora o "domínio" UserEntity não sabe mais nada sobre a implementação do logger. Ele fornece um contrato e espera que a implementação esteja em conformidade com esse contrato.
Claro, gerar manualmente instâncias de entidades de infraestrutura não é a coisa mais agradável. Precisamos de um arquivo raiz no qual prepararemos tudo, teremos que arrastar de alguma forma a instância criada do logger por toda a aplicação (é vantajoso ter um, não criar muitos). Cansativo. E é aqui que os contêineres de IoC entram em ação e podem assumir o trabalho do bollerplate.
Qual seria a aparência de um contêiner? Por exemplo, assim:
export class UserEntity {
constructor(@Inject(LOGGER) private readonly _logger: ILogger){ }
}O que está acontecendo aqui? Usamos a magia dos decoradores e escrevemos a instrução: “Ao criar uma instância de UserEntity, injete em seu campo privado _logger uma instância da entidade que está no contêiner IoC sob o token LOGGER. Espera-se que esteja em conformidade com a interface ILogger. " E então o contêiner IoC fará tudo sozinho.
Selecionamos as camadas e decidimos como iremos desamarrá-las. É hora de escolher uma estrutura.
Frameworks e arquitetura
A questão é simples: mudando do Express para um framework moderno, teremos uma boa arquitetura? Vamos dar uma olhada no Nest:
- escrito em TypeScript,
- construído em cima do Express / Fastify, há compatibilidade no nível de middleware,
- declara a modularidade da lógica,
- fornece um contêiner IoC.
Parece que tem tudo o que precisamos aqui! Eles também deixaram o conceito de um aplicativo como uma cadeia de middleware. Mas e quanto à boa arquitetura?
Injeção de dependência no ninho
Vamos tentar seguir as instruções . Como no Nest o termo Entidade é geralmente aplicado a ORMs, renomeie UserEntity para UserService. O logger é fornecido pela estrutura, portanto, injetaremos o FooService abstrato.
import {FooService} from ‘../services/foo.service’;
@Injectable()
export class UserService {
constructor(
private readonly _fooService: FooService
){ }
}E ... parece que demos um passo para trás! Existe uma injeção, mas não há inversão, a dependência é
voltada para a implementação, não para a abstração.
Vamos tentar consertar. Opção número um:
@Injectable()
export class UserService {
constructor(
private _fooService: AbstractFooService
){ } }Descrevemos e exportamos este serviço abstrato em algum lugar próximo:
export {AbstractFooService};FooService agora usa AbstractFooService. Como tal, nós o registramos manualmente no IoC.
{ provide: AbstractFooService, useClass: FooService }Segunda opçao. Vamos tentar a abordagem descrita anteriormente com interfaces. Como não há interfaces em JavaScript, não será mais possível extrair a entidade necessária do IoC no tempo de execução usando reflexão. Temos que declarar explicitamente o que precisamos. Usaremos o decorador @Inject para isso.
@Injectable()
export class UserService {
constructor(
@Inject(FOO_SERVICE) private readonly _fooService: IFooService
){ } }E registrar por token:
{ provide: FOO_SERVICE, useClass: FooService }Ganhamos o framework! Mas a que custo? Desligamos bastante o açúcar. Isso é suspeito e sugere que você não deve empacotar o aplicativo inteiro em uma estrutura. Se ainda não o convenci, existem outros problemas.
Exceções
Nest é exibido com exceções. Além disso, ele sugere o uso de lançamento de exceção para descrever a lógica do comportamento do aplicativo.
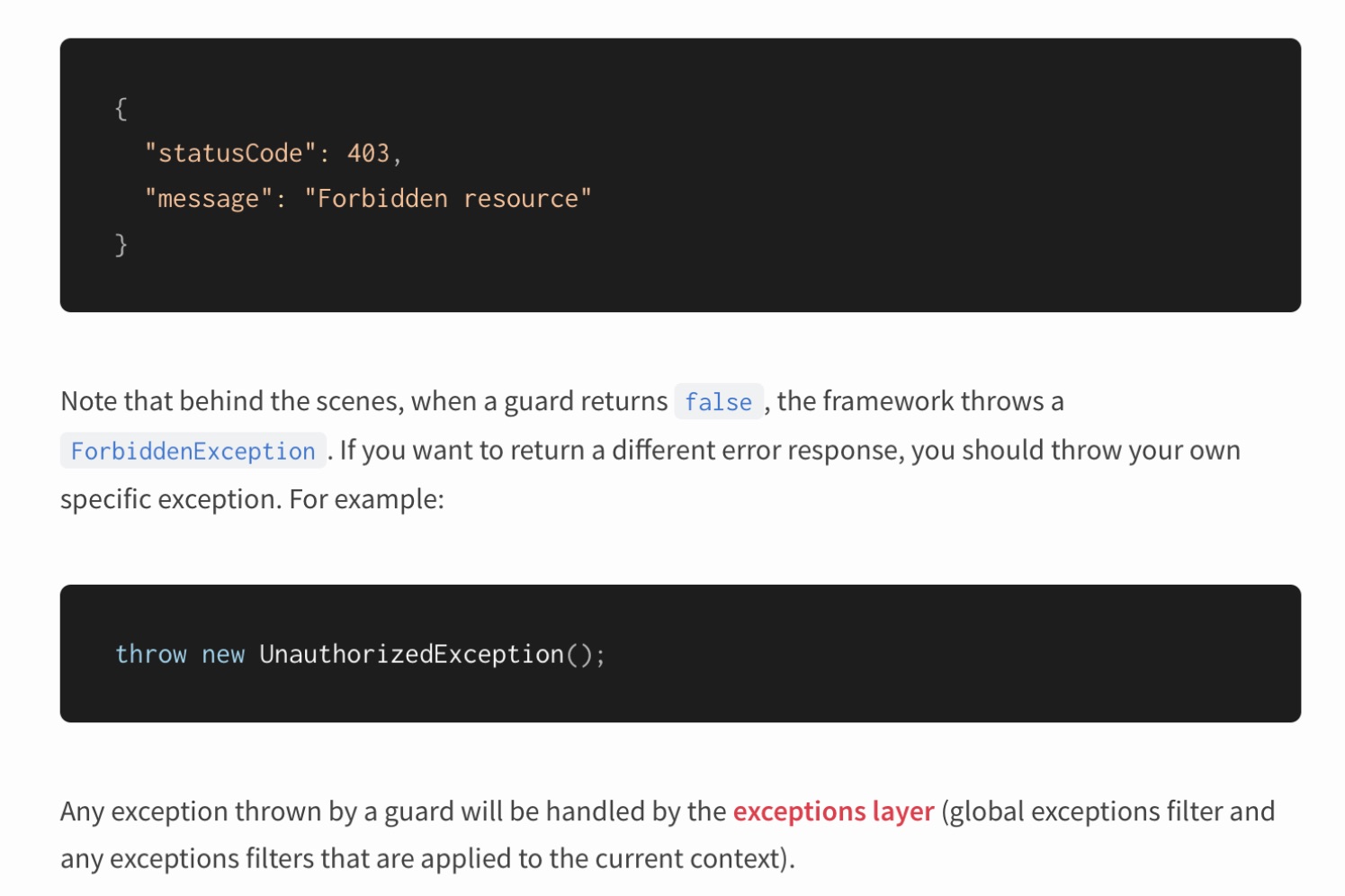
Está tudo bem aqui em termos de arquitetura? Vamos voltar aos luminares novamente:
"Se o erro for o comportamento esperado, você não deve usar exceções."As exceções sugerem uma situação excepcional. Ao escrever a lógica de negócios, devemos evitar lançar exceções. Nem que seja pelo motivo de que nem JavaScript nem TypeScript garantem que a exceção será tratada. Além disso, ofusca o fluxo de execução, iniciamos a programação no estilo GOTO, o que significa que ao examinar o comportamento do código, o leitor terá que saltar por todo o programa.
Martin Fowler

Existe uma regra simples para ajudá-lo a entender se o uso de exceções é legal:
"O código funcionará se eu remover todos os manipuladores de exceção?" Se a resposta for não, então talvez exceções sejam usadas em circunstâncias não excepcionais. "É possível evitar isso na lógica de negócios? Sim! É necessário minimizar o lançamento de exceções e, para convenientemente retornar o resultado de operações complexas, usar a mônada Either , que fornece um contêiner em um estado de sucesso ou erro (um conceito muito próximo de Promise).
O Programador Pragmático
const successResult = Result.ok(false);
const failResult = Result.fail(new ConnectionError())Infelizmente, dentro das entidades fornecidas pela Nest, muitas vezes não podemos agir de outra forma - temos que lançar exceções. É assim que o framework funciona, e esse é um recurso muito desagradável. E novamente surge a pergunta: talvez você não deva atualizar o aplicativo com um framework? Talvez seja possível separar a estrutura e a lógica de negócios em diferentes camadas arquitetônicas?
Vamos checar.
Entidades aninhadas e camadas arquitetônicas
A dura verdade da vida: tudo o que escrevemos com Nest pode ser empilhado em uma camada. Esta é a camada de aplicativo.
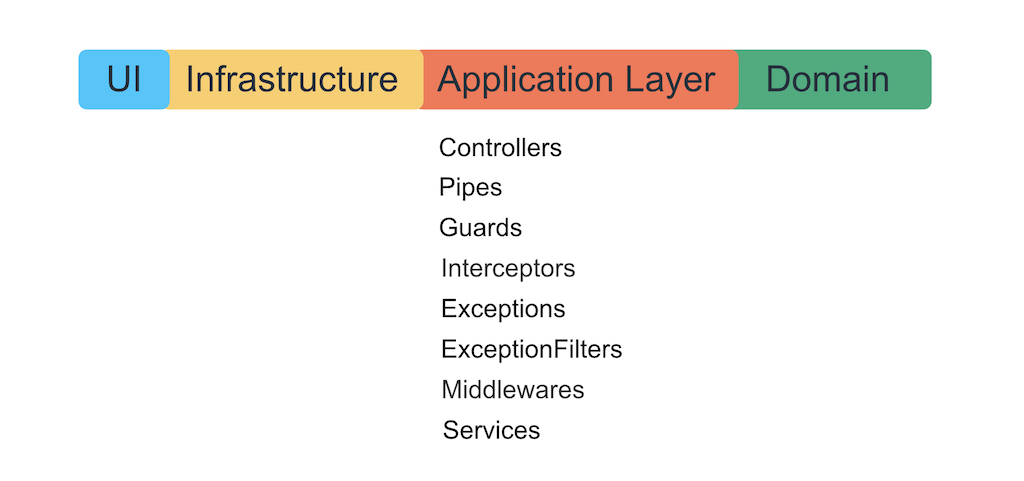
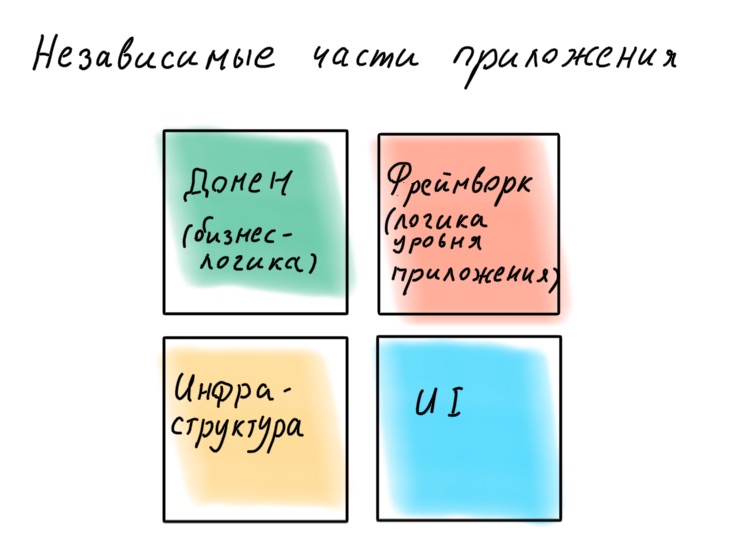
Não queremos permitir que a estrutura se aprofunde na lógica de negócios, de modo que ela não cresça com suas exceções, decoradores e contêiner IoC. Os autores da estrutura mostrarão como é ótimo escrever lógica de negócios usando seu açúcar, mas a tarefa deles é amarrá-lo a eles para sempre. Lembre-se de que uma estrutura é apenas uma maneira de organizar convenientemente a lógica no nível do aplicativo, conectar a infraestrutura e a IU a ela.

"Uma estrutura é um detalhe."
Robert "Tio Bob" Martin
É melhor projetar um aplicativo como um construtor no qual seja fácil substituir componentes. Um exemplo de tal implementação é a arquitetura hexagonal (arquitetura de porta e adaptador ). A ideia é interessante: o núcleo do domínio com toda a lógica de negócios fornece portas para comunicação com o mundo externo. Tudo o que é necessário é conectado externamente por meio de adaptadores.
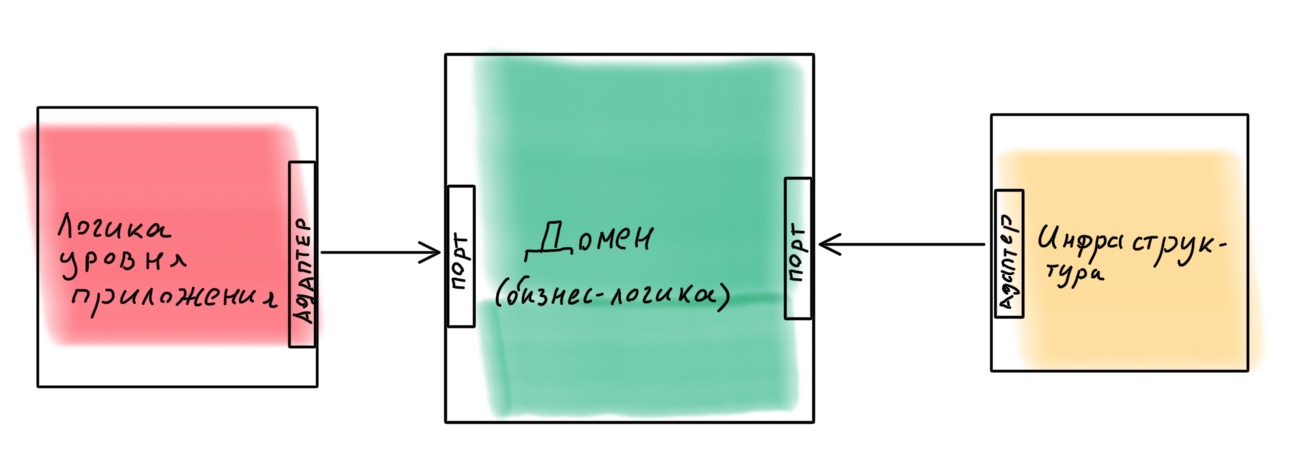
É realista implementar essa arquitetura em Node.js usando Nest como uma estrutura? Bastante. Fiz uma aula com o exemplo, se estiver interessado - pode ler o link .
Vamos resumir
- Node.js é bom para BFFs. Você pode morar com ela.
- Não existem soluções prontas.
- Frameworks não são importantes.
- Se sua arquitetura se tornar muito complexa, se você se deparar com a digitação, pode ter escolhido a ferramenta errada.
Eu recomendo estes livros:
- Robert Martin, "Clean Architecture",
- Vaughn Vernon, Domain-Driven Design Distilled,
- Khalil Stemmler, khalilstemmler.com,
- Martin Fowler, martinfowler.com/architecture.