Em nossa empresa, estamos trabalhando ativamente na auto-abstração de documentos. Este artigo não incluiu todos os detalhes e código, mas descreveu as principais abordagens e resultados usando o exemplo de um conjunto de dados neutro: 30.000 artigos de notícias sobre esportes de futebol coletados do portal de informações Sport-Express.
Portanto, o resumo pode ser definido como a criação automática de um resumo (título, resumo, anotação) do texto original. Existem 2 abordagens significativamente diferentes para este problema: extrativa e abstrativa.
Sumarização extrativa
A abordagem extrativa consiste em extrair os blocos de informação mais "significativos" do texto fonte. Um bloco pode ser um único parágrafo, sentenças ou palavras-chave.

Os métodos desta abordagem são caracterizados pela presença de uma função de avaliação da importância do bloco de informação. Classificando esses blocos em ordem de importância e escolhendo um número previamente especificado deles, formamos o resumo final do texto.
Vamos prosseguir para a descrição de algumas abordagens extrativas.
Soma extrativa com base na ocorrência de palavras comuns
Este algoritmo é muito simples de entender e implementar. Aqui, trabalhamos apenas com código-fonte e, em geral, não precisamos treinar nenhum modelo de extração. No meu caso, os blocos de informação recuperados representarão certas sentenças do texto.
Então, na primeira etapa, dividimos o texto de entrada em sentenças e cada sentença em tokens (palavras separadas), realizamos a lematização para elas (trazendo a palavra para a forma "canônica"). Esta etapa é necessária para que o algoritmo combine palavras que são idênticas em significado, mas diferem nas formas das palavras.
Em seguida, definimos a função de similaridade para cada par de sentenças. Será calculado como a razão entre o número de palavras comuns encontradas em ambas as frases e seu comprimento total... Como resultado, obtemos os coeficientes de similaridade para cada par de sentenças.
Tendo eliminado previamente as frases que não têm palavras comuns com outras, construímos um gráfico onde os vértices são as próprias frases, cujas arestas mostram a presença de palavras comuns nelas.
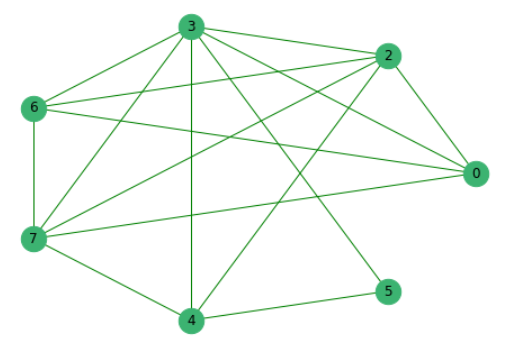
Em seguida, classificamos todas as propostas de acordo com sua importância.

Escolhendo várias sentenças com os coeficientes mais altos e depois classificando-as pelo número de sua ocorrência no texto, obtemos o resumo final.
Soma extrativa com base em representações vetoriais treinadas
Dados de notícias de texto completo coletados anteriormente foram usados para construir o próximo algoritmo.
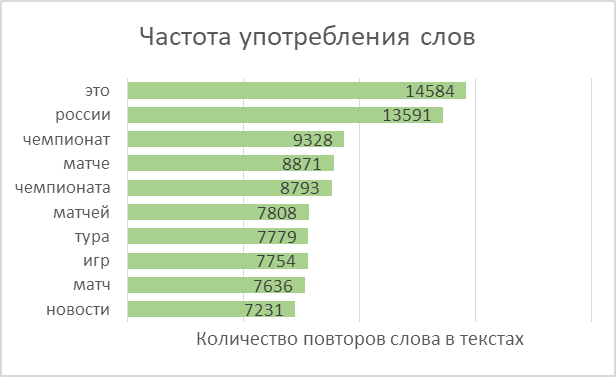
Dividimos as palavras em todos os textos em tokens e as combinamos em uma lista. No total, os textos continham 2.270.778 palavras, das quais 114.247 eram únicas.
Usando o popular modelo Word2Vec, encontraremos sua representação vetorial para cada palavra única. O modelo atribui vetores aleatórios a cada palavra e ainda, a cada etapa do aprendizado, “estudando o contexto”, corrige seus valores. A dimensão do vetor, que é capaz de "lembrar" a característica da palavra, você pode definir qualquer. Com base no volume do conjunto de dados disponível, pegaremos vetores que consistem em 100 números. Também observo que o Word2Vec é um modelo retreinável, que permite enviar novos dados para a entrada e, com base nisso, corrigir as representações vetoriais existentes de palavras.
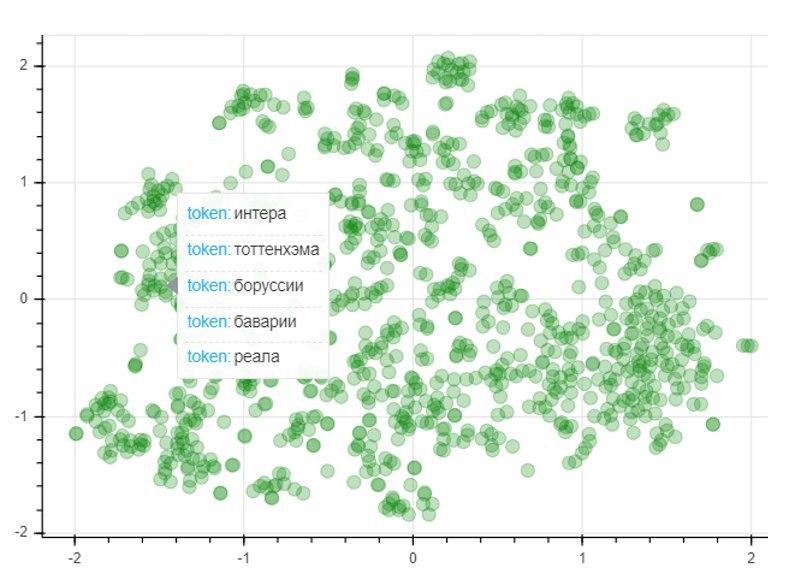
Para avaliar a qualidade do modelo, aplicaremos o método de redução de dimensionalidade T-SNE, que constrói iterativamente um mapeamento vetorial para as 1000 palavras mais usadas em um espaço bidimensional. O gráfico resultante representa a localização dos pontos, cada um dos quais corresponde a uma determinada palavra, de forma que palavras semelhantes em significado se localizam próximas umas das outras e diferentes ao contrário. Portanto, no lado esquerdo do gráfico estão os nomes dos clubes de futebol, e os pontos no canto esquerdo inferior representam os nomes e sobrenomes de jogadores de futebol e treinadores:
Depois de obter as representações vetoriais treinadas de palavras, você pode prosseguir para o próprio algoritmo. Como no caso anterior, na entrada temos um texto que dividimos em frases. Ao tokenizar cada frase, compomos representações vetoriais para elas. Para fazer isso, pegamos a razão da soma dos vetores para cada palavra na frase com o comprimento da própria frase. Vetores de palavras previamente treinados nos ajudam aqui. Se não houver palavra no dicionário, um vetor zero é adicionado ao vetor frase atual. Assim, neutralizamos a influência do surgimento de uma nova palavra ausente no dicionário no vetor geral da frase.
A seguir, compomos uma matriz de similaridade de sentenças que usa a fórmula de similaridade de cosseno para cada par de sentenças.
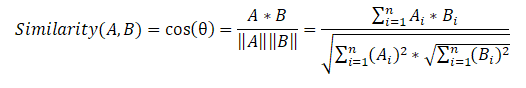
Na última etapa, com base na matriz de similaridade, também criamos um gráfico e realizamos a classificação das sentenças por importância. Como no algoritmo anterior, obtemos uma lista de sentenças ordenadas de acordo com sua importância no texto.

No final, vou representar esquematicamente e mais uma vez descrever os principais estágios da implementação do algoritmo (para o primeiro algoritmo extrativo, a sequência de ações é exatamente a mesma, exceto que não precisamos encontrar representações vetoriais de palavras, e a função de similaridade para cada par de frases é calculada com base na aparência de comum palavras):

- Dividir o texto de entrada em frases separadas e processá-las.
- Procure uma representação vetorial para cada frase.
- Calculando e armazenando semelhanças entre vetores de sentenças em uma matriz.
- Transformação da matriz resultante em um gráfico com sentenças na forma de vértices e estimativas de similaridade na forma de arestas para calcular a classificação das sentenças.
- Seleção das propostas com maior pontuação para o currículo final.
Comparação de algoritmos extrativos
Usando o microframework Flask (uma ferramenta para criar aplicações web minimalistas ), um serviço web de teste foi desenvolvido para comparar visualmente a saída de modelos extrativos usando o exemplo de uma variedade de textos de notícias de origem. Analisei o resumo gerado por ambos os modelos (recuperando as 2 frases mais significativas) para 100 artigos de notícias esportivas diferentes.

Com base nos resultados da comparação dos resultados da determinação das ofertas mais relevantes por ambos os modelos, posso oferecer as seguintes recomendações para o uso dos algoritmos:
- . , . , .
- . , , , . , , , .
Resumo abstrativo
A abordagem abstrativa difere significativamente de sua antecessora e consiste em gerar um resumo com a geração de um novo texto, resumindo de forma significativa o documento principal.
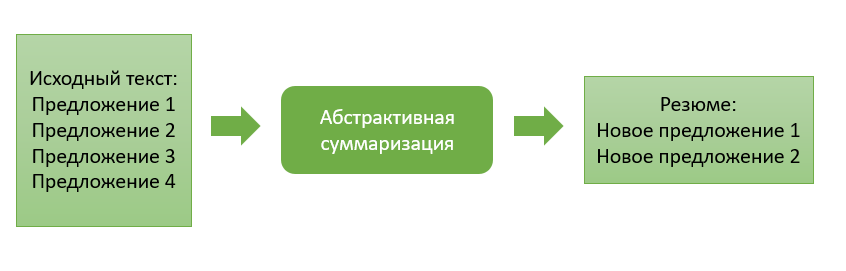
A ideia principal dessa abordagem é que o modelo seja capaz de gerar um resumo totalmente único, que pode conter palavras que não estão no texto original. A inferência de modelo é uma releitura do texto, que se aproxima da compilação manual de um resumo do texto por pessoas.
Fase de aprendizagem
Não vou me alongar sobre a justificativa matemática do algoritmo, todos os modelos que conheço são baseados na arquitetura "codificador-decodificador", que, por sua vez, é construída usando camadas LSTM recorrentes (você pode ler sobre o princípio de seu trabalho aqui ). Descreverei brevemente as etapas para decodificar a sequência de teste.
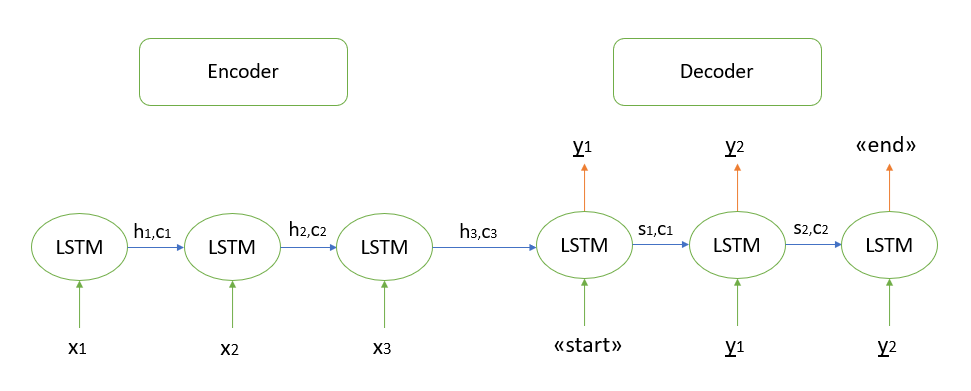
- Codificamos toda a sequência de entrada e inicializamos o decodificador com os estados internos do codificador
- Passe o token "start" como entrada para o decodificador
- Iniciamos o decodificador com os estados internos do codificador para uma etapa de tempo, como resultado, obtemos a probabilidade da próxima palavra (palavra com a probabilidade máxima)
- Passe a palavra selecionada como entrada para o decodificador na próxima etapa e atualize os estados internos
- Repita as etapas 3 e 4 até gerarmos o token "final"
Mais detalhes sobre a arquitetura "codificador-decodificador" podem ser encontrados aqui .
Implementando resumo abstrativo
Construir um modelo abstrativo mais complexo para extrair o conteúdo do resumo exigirá textos de notícias completos e suas manchetes. A manchete da notícia funcionará como um resumo, já que a modelo “não lembra bem” longas sequências de texto.
Ao limpar os dados, usamos a tradução em minúsculas e descartamos os caracteres que não sejam do idioma russo. A lematização de palavras, a remoção de preposições, partículas e outras partes do discurso não informativas terão um impacto negativo na saída final do modelo, uma vez que a relação entre as palavras em uma frase será perdida.
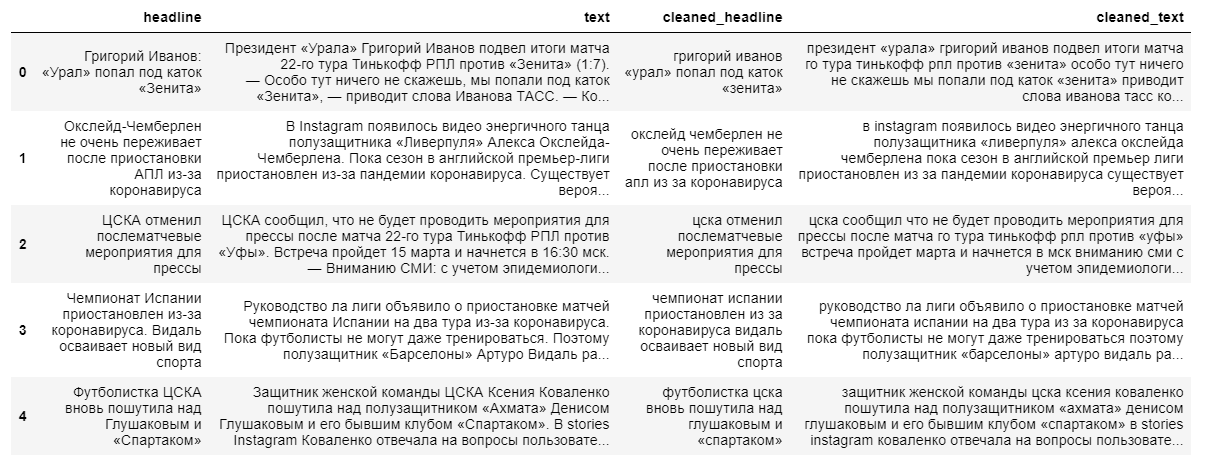
Em seguida, dividimos os textos e seus títulos em amostras de treinamento e teste na proporção de 9 para 1, após o que os transformamos em vetores (aleatoriamente).
Na próxima etapa, criamos o próprio modelo, que fará a leitura dos vetores de palavras que lhe são transmitidos e realizará seu processamento utilizando 3 camadas recorrentes do codificador LSTM e 1 camada do decodificador.
Depois de inicializar o modelo, nós o treinamos usando uma função de perda de entropia cruzada que mostra a discrepância entre o título real do alvo e aquele previsto por nosso modelo.

Por fim, geramos o resultado do modelo para o conjunto de treinamento. Como você pode ver nos exemplos, os textos-fonte e os resumos contêm imprecisões devido ao descarte de palavras raras antes de construir o modelo (descartamos para “simplificar o aprendizado”).

A saída do modelo neste estágio deixa muito a desejar. A modelo “lembra com sucesso” alguns nomes de clubes e nomes de jogadores de futebol, mas praticamente não captou o contexto em si.
Apesar da abordagem mais moderna para retomar a extração, esse algoritmo ainda é muito inferior aos modelos extrativos criados anteriormente. No entanto, para melhorar a qualidade do modelo, você pode treiná-lo em um conjunto de dados maior, mas, em minha opinião, para obter uma saída de modelo realmente boa, é necessário alterar ou, possivelmente, alterar completamente a própria arquitetura das redes neurais utilizadas.
Então, qual abordagem é melhor?
Resumindo este artigo, listarei os principais prós e contras das abordagens revisadas para extrair um resumo:
1. Abordagem extrativa:
Vantagens:
- A essência do algoritmo é intuitiva
- Facilidade relativa de implementação
Desvantagens:
- A qualidade do conteúdo pode, em muitos casos, ser pior do que o conteúdo escrito à mão por humanos
2. Abordagem
abstrativa: Vantagens:
- Um algoritmo bem implementado é capaz de produzir um resultado mais próximo da escrita de retomada manual
Desvantagens:
- Dificuldades em perceber as principais ideias teóricas do algoritmo
- Grandes custos de mão de obra na implementação do algoritmo
Não há uma resposta inequívoca para a questão de qual abordagem formará melhor o currículo final. Tudo depende da tarefa e dos objetivos específicos do usuário. Por exemplo, um algoritmo extrativo é provavelmente mais adequado para gerar o conteúdo de documentos de várias páginas, onde a extração de frases relevantes pode de fato transmitir corretamente a ideia de um texto grande.
Na minha opinião, o futuro pertence aos algoritmos abstrativos. Apesar de no momento eles estarem mal desenvolvidos e em um certo nível de qualidade de saída, eles só podem ser usados para gerar pequenos resumos (1-2 frases), vale a pena esperar por um avanço nos métodos de rede neural. No futuro, eles serão capazes de formar conteúdo para absolutamente qualquer tamanho de texto e, o mais importante, o conteúdo em si será o mais próximo possível da redação manual de um currículo por um especialista em um determinado campo.
Veklenko Vlad, analista de sistemas,
Codex Consortium