- Dispositivos incorporados e IoT.
- Análise de dados.
- Transferindo dados de um sistema para outro.
- Arquivamento de dados e (ou) embalagem de dados em contêineres.
- Armazenamento de dados em um banco de dados externo ou temporário.
- Um substituto para um banco de dados corporativo usado para fins de demonstração ou teste.
- Treinamento, domínio de iniciantes em técnicas práticas de trabalho com banco de dados.
- Prototipagem e pesquisa de extensões experimentais para SQL.
Você pode encontrar outras razões para usar este banco de dados na documentação do SQLite . Este artigo é sobre o uso de SQLite no desenvolvimento Python. Portanto, é especialmente importante para nós que este SGBD, representado por um módulo , seja incluído na biblioteca padrão da linguagem. Ou seja, verifica-se que para trabalhar com SQLite a partir de código Python, não é necessário instalar nenhum software cliente-servidor, não é necessário suportar o funcionamento de algum serviço responsável por trabalhar com o SGBD. Basta importar o módulo e começar a utilizá-lo no programa, tendo recebido o sistema de gestão da base de dados relacional à sua disposição.
sqlite3sqlite3
Importação de módulo
Acima eu disse que o SQLite é um DBMS embutido em Python. Isso significa que para começar a trabalhar com ele, basta importar o módulo correspondente sem antes instalá-lo por meio de um comando como
pip install. O comando de importação do SQLite se parece com isto:
import sqlite3 as sl
Criação de uma conexão com o banco de dados
Para estabelecer uma conexão com um banco de dados SQLite, você não precisa se preocupar com a instalação de drivers, preparação de strings de conexão e outras coisas. É muito simples e rápido criar uma base de dados e colocar à sua disposição um objeto de conexão a ela:
con = sl.connect('my-test.db')
Ao executar esta linha de código, criaremos um banco de dados e nos conectaremos a ele. O ponto aqui é que o banco de dados ao qual estamos nos conectando ainda não existe, então o sistema cria automaticamente um novo banco de dados vazio. Se o banco de dados já foi criado (digamos que seja
my-test.dbdo exemplo anterior), para conectar-se a ele, basta usar exatamente o mesmo código.

Arquivo de banco de dados recém-criado
Criação de uma mesa
Agora vamos criar uma tabela em nosso novo banco de dados:
with con:
con.execute("""
CREATE TABLE USER (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
name TEXT,
age INTEGER
);
""")
Isso descreve como adicionar uma tabela
USERcom três colunas ao banco de dados . Como você pode ver, o SQLite é um sistema de gerenciamento de banco de dados muito simples, mas possui todos os recursos básicos que você esperaria de um sistema de gerenciamento de banco de dados relacional convencional. Estamos falando sobre suporte para tipos de dados, incluindo - tipos que permitem um valor null, suporte para chave primária e incremento automático.
Se este código funcionar conforme o esperado (o comando acima, porém, não retorna nada), teremos uma tabela à nossa disposição, pronta para trabalhar com ela.
Inserindo registros em uma tabela
Vamos inserir alguns registros na tabela
USERque acabamos de criar. Isso, entre outras coisas, nos dará a prova de que a tabela foi realmente criada pelo comando acima.
Vamos imaginar que precisamos adicionar vários registros à tabela com um comando. É muito fácil fazer isso no SQLite:
sql = 'INSERT INTO USER (id, name, age) values(?, ?, ?)'
data = [
(1, 'Alice', 21),
(2, 'Bob', 22),
(3, 'Chris', 23)
]
Aqui, precisamos definir uma expressão SQL com pontos de interrogação (
?) como espaços reservados. Dado que temos um objeto de conexão de banco de dados à nossa disposição, nós, tendo preparado a expressão e os dados, podemos inserir registros na tabela:
with con:
con.executemany(sql, data)
Depois de executar este código, nenhuma mensagem de erro é recebida, o que significa que os dados foram adicionados com sucesso à tabela.
Executando consultas de banco de dados
Agora é hora de descobrir se os comandos que acabamos de executar funcionaram corretamente. Vamos executar uma consulta ao banco de dados e tentar obter
USERalguns dados da tabela . Por exemplo - obtemos registros relacionados a usuários cuja idade não excede 22 anos:
with con:
data = con.execute("SELECT * FROM USER WHERE age <= 22")
for row in data:
print(row)
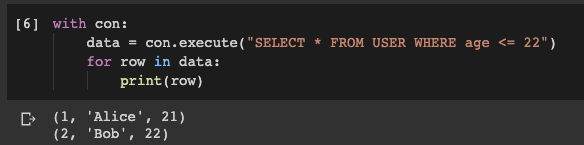
O resultado da execução de uma consulta ao banco de dados
Como você pode ver, conseguimos o que era necessário. E foi muito fácil fazer isso.
Além disso, embora o SQLite seja um DBMS simples, ele tem um suporte extremamente amplo. Portanto, você pode trabalhar com ele usando a maioria dos clientes SQL.
Estou usando o DBeaver. Vamos dar uma olhada em como fica.
Conectando-se ao banco de dados SQLite do cliente SQL (DBeaver)
Estou usando o serviço de nuvem Google Colab e desejo baixar um arquivo
my-test.dbpara o meu computador. Se você estiver experimentando o SQLite em um computador, significa que você pode se conectar a ele usando o cliente SQL sem precisar baixar o arquivo de banco de dados de algum lugar.
No caso do DBeaver, para se conectar ao banco de dados SQLite, você precisa criar uma nova conexão e selecionar SQLite como o tipo de banco de dados.
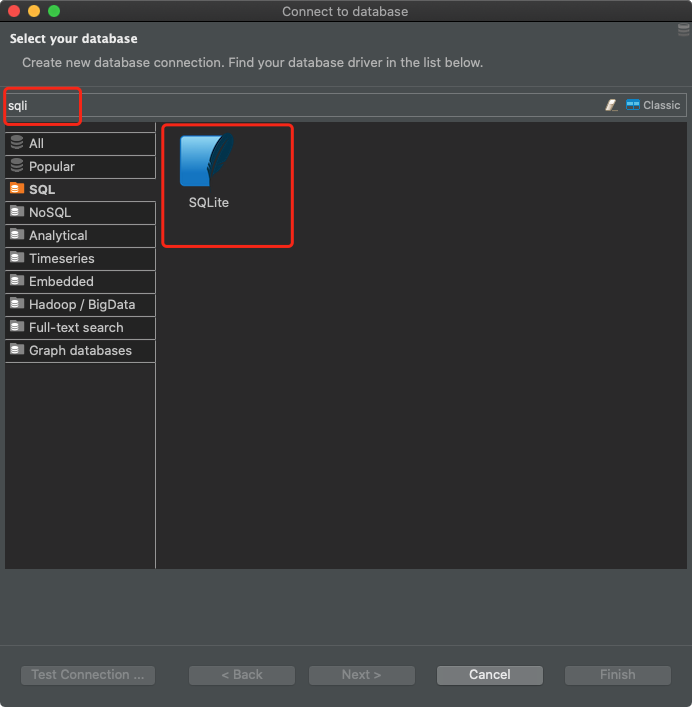
Preparando a conexão no DBeaver
Então você precisa encontrar o arquivo do banco de dados.
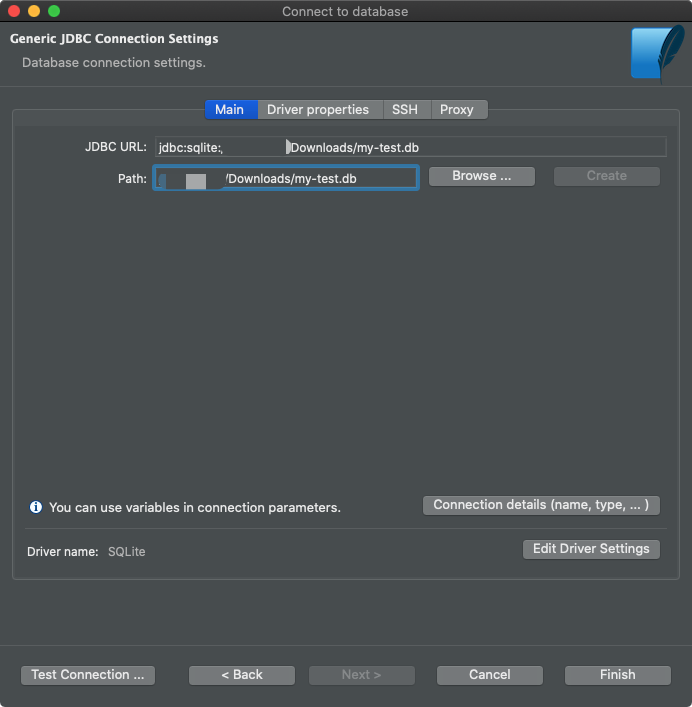
Conectando o arquivo de banco de dados
Depois disso, você pode executar consultas SQL no banco de dados. Não há nada de especial aqui, diferente de trabalhar com bancos de dados relacionais regulares.
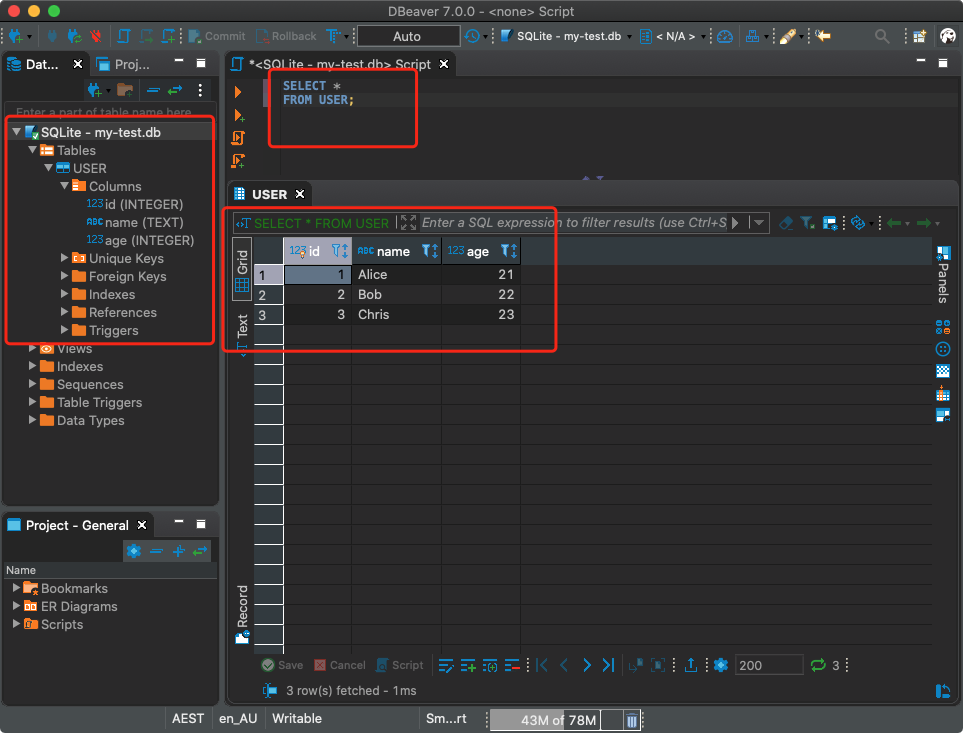
Executando consultas de banco de dados
Integração com pandas
Você acha que é aqui que encerramos nossa conversa sobre o suporte SQLite em Python? Não, ainda temos muito que conversar. Ou seja, como o SQLite é um módulo Python padrão, ele se integra facilmente com os quadros de dados do pandas.
Vamos declarar o dataframe:
df_skill = pd.DataFrame({
'user_id': [1,1,2,2,3,3,3],
'skill': ['Network Security', 'Algorithm Development', 'Network Security', 'Java', 'Python', 'Data Science', 'Machine Learning']
})
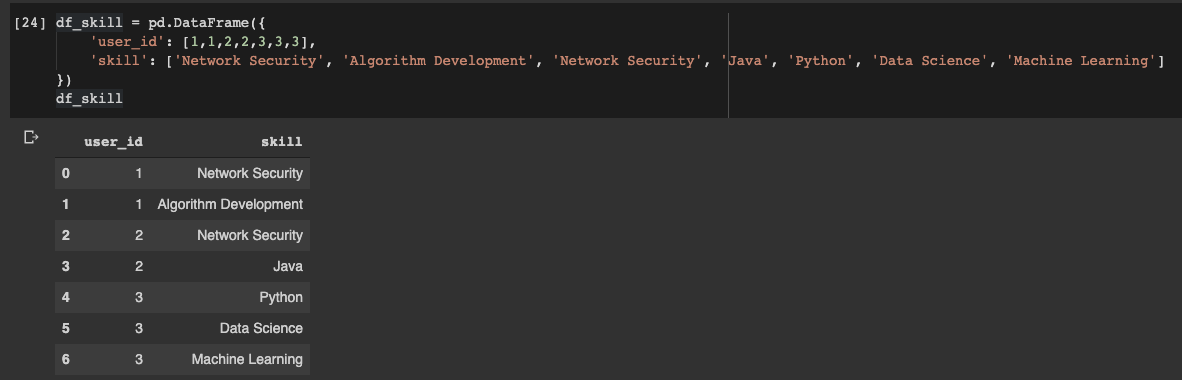
Dataframe do Pandas
Para salvar um dataframe no banco de dados, você pode simplesmente usar seu método
to_sql():
df_skill.to_sql('SKILL', con)
Isso é tudo! Nem precisamos criar uma mesa de antemão. Os tipos de dados e características dos campos serão configurados automaticamente com base nas características do dataframe. Claro, você pode personalizar tudo sozinho, se necessário.
Agora suponha que precisamos obter a união das tabelas
USERe SKILL, e escrever os dados em datafreym pandas. Também é muito simples:
df = pd.read_sql('''
SELECT s.user_id, u.name, u.age, s.skill
FROM USER u LEFT JOIN SKILL s ON u.id = s.user_id
''', con)
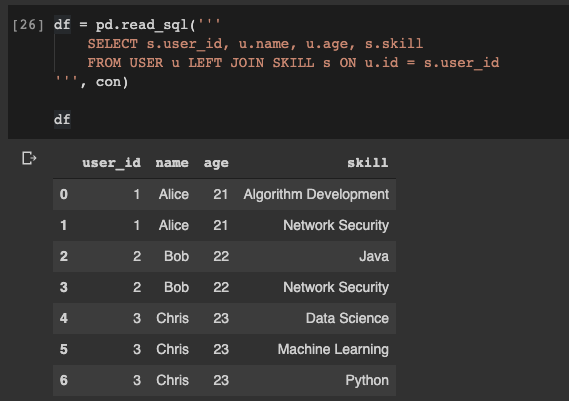
Lendo dados de um banco de dados em um dataframe do pandas
Ótimo! Agora vamos escrever o que temos em uma nova tabela chamada
USER_SKILL:
df.to_sql('USER_SKILL', con)
Claro, você pode trabalhar com essa tabela usando o cliente SQL.
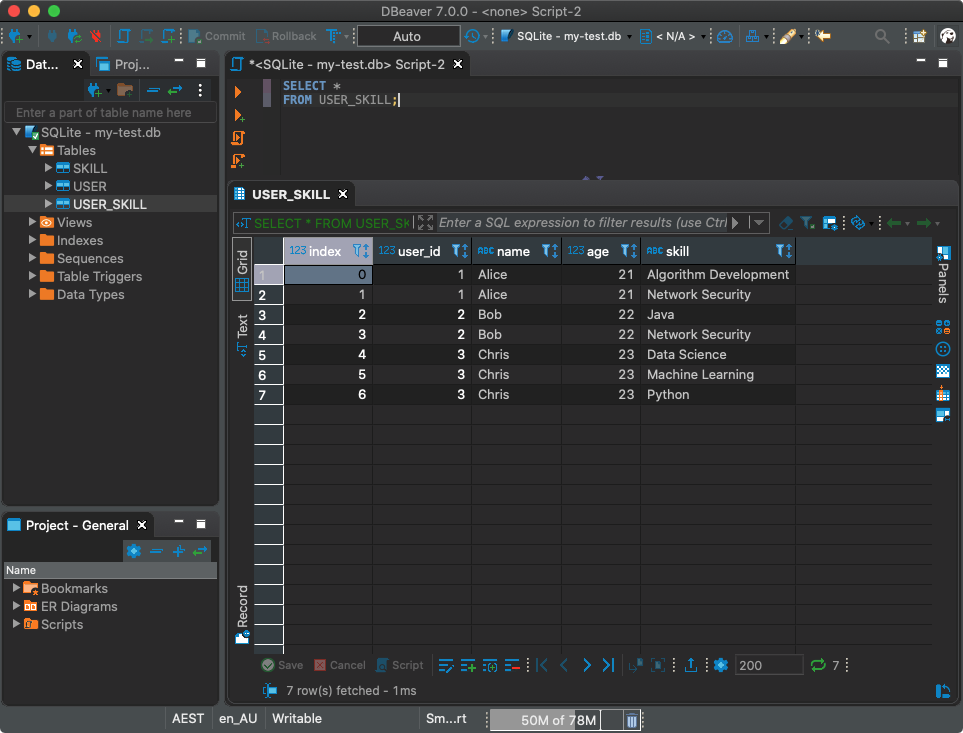
Usando um cliente SQL para trabalhar com um banco de dados
Resultado
Certamente há muitas surpresas agradáveis em Python que, a menos que você as procure especificamente, pode não notar. Ninguém escondeu esses recursos especialmente, mas devido ao fato de que muitas coisas são incorporadas ao Python, você pode simplesmente não prestar atenção a alguns desses recursos ou, tendo aprendido sobre eles de algum lugar, simplesmente esquecê-los.
Aqui, falei sobre como usar a biblioteca Python embutida
sqlite3para criar e trabalhar com bancos de dados. Obviamente, esses bancos de dados suportam não apenas a operação de adição de dados, mas também as operações de alteração e exclusão de informações. Suponho que você, tendo aprendido sqlite3, experimentará tudo sozinho.
O mais importante é que o SQLite faz um ótimo trabalho com os pandas. É muito fácil ler dados de um banco de dados, colocando-os em dataframes. A operação de salvar o conteúdo de dataframes em um banco de dados não é menos simples. Isso torna o SQLite ainda mais fácil de usar.
Convido todos que leram até aqui a fazer suas próprias pesquisas em busca de recursos interessantes do Python!
O código que demonstrei neste artigo pode ser encontrado aqui .
Você usa SQLite em seus projetos Python?
