
Como são os dados?
Primeiro, vamos dar uma olhada nos dados de teste e treinamento disponíveis (dados do desafio de classificação de comentários tóxicos na plataforma kaggle.com). Nos dados de treinamento, em contraste com os dados de teste, há rótulos para classificação:
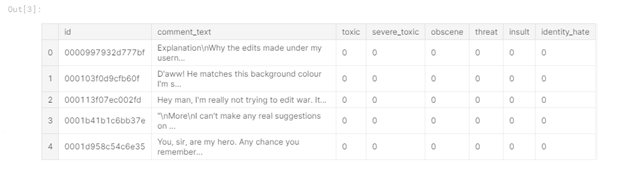
Figura 1 - Cabeça de dados do trem
Na tabela, você pode ver que nos dados de treinamento temos 6 colunas de rótulos ("tóxico", "grave_toxic", "obsceno", "ameaça" , "Insult", "identity_hate"), onde o valor "1" indica que o comentário pertence à classe, há também uma coluna "comment_text" contendo o comentário e uma coluna "id" - o identificador do comentário.
Os dados de teste não contêm rótulos de classe, pois são usados para enviar a solução:

Figura 2 - Cabeçalho de dados de teste
Extração de recursos
A próxima etapa é extrair recursos dos comentários e conduzir a análise exploratória de dados (EDA). Primeiro, vamos examinar a distribuição dos tipos de comentários no conjunto de dados de treinamento. Para isso, uma nova coluna "toxic_type" foi criada, contendo todas as classes às quais o comentário pertencia:

Figura 3 - Top-10 tipos de comentários tóxicos
A tabela mostra que o tipo predominante é a ausência de qualquer tag de classe, e muitos comentários pertencem a mais de um classe.
Vejamos também como o número de tipos é distribuído para cada comentário:

Figura 4 - Número de tipos encontrados
Observe que a situação prevalecente é quando o comentário é caracterizado por apenas um tipo de toxicidade e, muitas vezes, o comentário é caracterizado por três tipos de toxicidade e menos frequentemente o comentário é atribuído a todos os tipos.
Agora, vamos passar para o estágio de extração de recursos do texto, que geralmente é chamado de extração de recursos. Extraí os seguintes atributos:
Comprimento do comentário. Acho que os comentários raivosos provavelmente serão curtos;
Letras maiúsculas. Em comentários agressivos-emocionais, é possível que as maiúsculas sejam mais comuns em palavras;
Emoticons. Ao escrever um comentário tóxico, emoticons com cores positivas (:), etc.) provavelmente não serão usados, considere também a presença de emoticons tristes (:(, etc.);
Pontuação. Provavelmente, os autores de comentários negativos não aderem às regras de pontuação, em maior medida utilizam "!";
O número de personagens de terceiros. Algumas pessoas costumam usar os símbolos @, $, etc. ao escrever palavras ofensivas.
Os recursos são adicionados da seguinte forma:
train_data[‘total_length’] = train_data[‘comment_text’].apply(len)
train_data[‘uppercase’] = train_data[‘comment_text’].apply(lambda comment: sum(1 for c in comment if c.isupper()))
train_data[‘exclamation_punction’] = train_data[‘comment_text’].apply(lambda comment: comment.count(‘!’))
train_data[‘num_punctuation’] = train_data[‘comment_text’].apply(lambda comment: comment.count(w) for w in ‘.,;:?’))
train_data[‘num_symbols’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in ‘*&$%’))
train_data[‘num_words’] = train_data[‘comment_text’].apply(lambda comment: len(comment.split()))
train_data[‘num_happy_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-)’, ‘:)’, ‘;)’, ‘;-)’)))
train_data[‘num_sad_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-(’, ‘:(’, ‘;(’, ‘;-(’)))Análise exploratória de dados
Agora vamos explorar os dados usando os recursos que acabamos de obter. Em primeiro lugar, vamos olhar para a correlação de recursos entre si, a correlação entre recursos e rótulos de classe, a correlação entre os rótulos de classe:

Figura 5 - Correlação
Correlação indica a presença de uma relação linear entre os recursos. Quanto mais próximo de 1 o valor da correlação em módulo, mais pronunciada é a dependência linear entre os elementos.
Por exemplo, você pode ver que o número de palavras e o comprimento do texto estão fortemente correlacionados um com o outro (valor 0,99), o que significa que algum recurso pode ser removido delas, eu removi o número de palavras. Também podemos tirar mais algumas conclusões: praticamente não há correlação entre os recursos selecionados e os rótulos de classe, o recurso menos correlacionado é o número de caracteres e o comprimento do texto se correlaciona com o número de caracteres de pontuação e o número de caracteres maiúsculos.
A seguir, construiremos várias visualizações para uma compreensão mais detalhada da influência dos recursos no rótulo da classe. Primeiro, vamos ver como os comprimentos dos comentários são distribuídos:

Figura 6 - Distribuição dos comprimentos dos comentários (o gráfico é interativo, mas aqui está uma captura de tela)
Como esperado, os comentários que não foram categorizados (ou seja, normal) são muito mais longos do que os comentários marcados. Dos comentários negativos, os mais curtos são ameaças e os mais longos são tóxicos.
Agora vamos examinar os comentários em termos de pontuação. Vamos construir representações gráficas para valores médios para tornar os gráficos mais interpretáveis:

Figura 7 - Valores médios de pontuação (o gráfico é interativo, mas aqui está uma captura de tela)
Na figura você pode ver que temos três clusters.
Os primeiros - comentários normais, são caracterizados pela observância de regras de pontuação (colocação de sinais de pontuação, ":", por exemplo) e um pequeno número de pontos de exclamação.
O segundo consiste em ameaças e comentários muito tóxicos (tóxicos graves), este grupo é caracterizado pelo uso abundante de pontos de exclamação e outros sinais de pontuação são usados no nível médio.
O terceiro grupo - tóxico (tóxico), obsceno (obsceno), insultos (insulto) e odioso para com uma determinada pessoa (ódio de identidade) tem um pequeno número de pontos de pontuação e de exclamação.
Vamos adicionar um terceiro eixo para maior clareza - maiúsculas:

Figura 8 - Imagem 3D (interativa, mas aqui está uma captura de tela)
Aqui vemos uma situação semelhante - três clusters são destacados. Observe também que a distância entre os elementos do segundo cluster é maior do que a distância entre os elementos do terceiro cluster. Isso também pode ser visto no gráfico 2D:

Figura 9 - Letras maiúsculas e pontuação (interativo, aqui está uma captura de tela)
Agora vamos examinar os tipos de comentários no contexto de maiúsculas / o número de caracteres de terceiros:

Figura 10 - Letras maiúsculas e o número de caracteres de terceiros (interativo, aqui está uma captura de tela).
Como você pode ver, comentários muito tóxicos são claramente destacados - eles têm um grande número de caracteres maiúsculos e muitos caracteres de terceiros. Além disso, símbolos de terceiros são usados ativamente pelos autores de comentários que odeiam alguma pessoa.
Assim, destacar novos recursos e visualizá-los permite uma melhor interpretação dos dados disponíveis, e as visualizações acima podem ser resumidas da seguinte forma:
Comentários altamente tóxicos são separados do resto;
Comentários normais também se destacam;
Comentários tóxicos, obscenos e ofensivos são muito próximos entre si em termos das características consideradas.
Usando o DataFrameMapper para combinar texto e recursos numéricos
Agora, vamos ver como você pode usar texto e recursos numéricos juntos na regressão logística.
Primeiro, você precisa escolher um modelo para representar o texto em um formato adequado para algoritmos de aprendizado de máquina. Usei o modelo tf-idf, pois é capaz de destacar palavras específicas e tornar as palavras frequentes menos significativas (por exemplo, preposições):
tvec = TfidfVectorizer(
sublinear_tf=True,
strip_accents=’unicode’,
analyzer=’word’,
token_pattern=r’\w{1,}’,
stop_words=’english’,
ngram_range=(1, 1),
max_features=10000
)Então, se quisermos trabalhar com o dataframe fornecido pela biblioteca Pandas e os algoritmos de aprendizado de máquina da biblioteca Sklearn, podemos usar o módulo Sklearn-pandas, que serve como uma espécie de fichário entre o dataframe e os métodos Sklearn.
mapper = DataFrameMapper([
([‘uppercase’], StandardScaler()),
([‘exclamation_punctuation’], StandardScaler()),
([‘num_punctuation’], StandardScaler()),
([‘num_symbols’], StandardScaler()),
([‘num_happy_smilies’], StandardScaler()),
([‘num_sad_smilies’], StandardScaler()),
([‘total_length’], StandardScaler())
], df_out=True)Primeiro você precisa criar um DataFrameMapper como mostrado acima, ele deve conter os nomes das colunas com recursos numéricos. A seguir, criamos uma matriz de recursos, que então transferiremos para a regressão logística para treinamento:
x_train = np.round(mapper.fit_transform(numeric_features_train.copy()), 2).values
x_train_features = sparse.hstack((csr_matrix(x_train), train_texts))Uma sequência semelhante de ações também é executada no conjunto de dados de teste.
Experimento computacional
Para realizar a classificação multi-rótulo, construiremos um loop que percorrerá todas as categorias e avaliará a qualidade da classificação por validação cruzada com os parâmetros cv = 3 e pontuação = 'roc_auc':
scores = []
class_names = [‘toxic’, ‘severe_toxic’, ‘obscene’, ‘threat’, ‘identity_hate’]
for class_name in class_names:
train_target = train_data[class_name]
classifier = LogisticRegression(C=0.1, solver= ‘sag’)
cv_score = np.mean(cross_val_score(classifier, x_train_features, train_target, cv=3, scoring= ‘auc_roc’))
scores.append(cv_score)
print(‘CV score for class {} is {}’.format(class_name, cv_score))
classifier.fit(train_features, train_target)
print(‘Total CV score is {}’.format(np.mean(scores)))</source
<b> :</b>
<img src="https://habrastorage.org/webt/kt/a4/v6/kta4v6sqnr-tar_auhd6bxzo4dw.png" />
<i> 11 — </i>
, , , , , . , , , . - , “toxic”, , , ( 3). , , , .