( PNL) por Tim Dettmers, Ph.D. Aprendizado profundo (DL) é uma área com alta demanda por poder de computação, portanto, sua escolha de GPU determinará fundamentalmente sua experiência nessa área. Mas quais propriedades são importantes a considerar ao comprar uma nova GPU? Memória, núcleos, núcleos tensores? Como fazer a melhor escolha em termos de custo-benefício? Neste artigo, irei analisar em detalhes todas essas questões, equívocos comuns, dar a você uma compreensão intuitiva da GPU, bem como algumas dicas para ajudá-lo a fazer a escolha certa.
Este artigo foi escrito para fornecer vários níveis diferentes de compreensão da GPU, inclusive. nova série Ampere da NVIDIA. Você tem uma escolha:
- Se você não está interessado nos detalhes da GPU, o que exatamente torna a GPU rápida, o que é único nas novas GPUs da série NVIDIA RTX 30 Ampere, você pode pular o início do artigo, direto para os gráficos de velocidade e velocidade a um custo de US $ 1, bem como a seção de recomendações. Este é o cerne deste artigo e o conteúdo mais valioso.
- Se você estiver interessado em perguntas específicas, abordei as mais frequentes delas na última parte do artigo.
- Se você precisa de um entendimento profundo de como funcionam as GPUs e os núcleos do Tensor, sua melhor aposta é ler este artigo do início ao fim. Dependendo do seu conhecimento de assuntos específicos, você pode pular um capítulo ou dois.
Cada seção é precedida por um breve resumo para ajudá-lo a decidir se deve lê-la na íntegra ou não.
Conteúdo
GPU?
GPU,
/ L1 /
Ampere
Ampere
Ampere
Ampere / RTX 30
GPU
GPU
GPU
11 ?
11 ?
GPU-
GPU
GPU?
PCIe 4.0?
PCIe 8x/16x?
RTX 3090, 3 PCIe?
4 RTX 3090 4 RTX 3080?
GPU ?
NVLink, ?
. ?
?
?
Intel GPU?
?
AMD GPU + ROCm - NVIDIA GPU + CUDA?
, – GPU?
,
Este artigo está estruturado da seguinte forma. Primeiro, explico o que torna uma GPU rápida. Descreverei a diferença entre processadores e GPUs, núcleos tensores, largura de banda de memória, hierarquia de memória GPU e como tudo se relaciona ao desempenho em tarefas GO. Essas explicações podem ajudá-lo a entender melhor quais parâmetros de GPU você precisa. Em seguida, darei estimativas teóricas do desempenho da GPU e sua correspondência com alguns dos testes de velocidade da NVIDIA para obter dados de desempenho confiáveis sem distorções. Descreverei os recursos exclusivos das GPUs NVIDIA RTX 30 Ampere Series a serem considerados na compra. Em seguida, darei recomendações de GPU para clusters de 1-2 chips, 4, 8 e GPU. Em seguida, haverá uma seção de respostas às perguntas mais frequentes que me fizeram no Twitter.Ele também dissipará equívocos comuns e destacará vários problemas, como nuvens versus desktops, resfriamento, AMD versus NVIDIA e outros.
Como funcionam as GPUs?
Se você usa muito as GPUs, é útil entender como elas funcionam. Esse conhecimento será útil para você descobrir por que em alguns casos as GPUs são mais lentas e em outros mais rápidas. E então você pode entender se precisa de uma GPU e quais opções de hardware podem competir com ela no futuro. Você pode pular esta seção se quiser apenas algumas informações úteis sobre desempenho e argumentos para escolher uma GPU específica. A melhor explicação geral de como as GPUs funcionam está na resposta no Quora .
Esta é uma explicação geral e explica bem a questão de por que as GPUs são mais adequadas para GO do que processadores. Se estudarmos os detalhes, podemos entender como as GPUs diferem umas das outras.
As características mais importantes da GPU que afetam a velocidade de processamento
Esta seção o ajudará a pensar de forma mais intuitiva sobre o desempenho na área de GO. Esse entendimento o ajudará a avaliar você mesmo as futuras GPUs.
Núcleos tensores
Resumo:
- Os núcleos tensores reduzem o número de ciclos de clock necessários para contar multiplicações e adições em 16 vezes - no meu exemplo para uma matriz de 32 × 32 de 128 para 8 ciclos de clock.
- Os núcleos tensores reduzem a dependência de acessos repetidos à memória compartilhada, economizando ciclos de acesso à memória.
- Os núcleos do tensor são tão rápidos que a computação não é mais um gargalo. O único gargalo é a transferência de dados para eles.
Existem tantas GPUs baratas por aí hoje que quase todos podem pagar uma GPU com núcleos tensores. Portanto, eu sempre recomendo GPUs com Tensor Cores. É útil entender como eles funcionam para avaliar a importância desses módulos computacionais especializados em multiplicação de matrizes. Usando um exemplo simples de multiplicação de matrizes A * B = C, onde o tamanho de todas as matrizes é 32 × 32, mostrarei como a multiplicação se parece com e sem núcleos tensores.
Para entender isso, primeiro você precisa entender o conceito de barras. Se o processador está funcionando a 1 GHz, ele faz 10 9tiquetaques por segundo. Cada relógio é uma oportunidade para cálculos. Mas, na maioria das vezes, as operações demoram mais do que um ciclo de clock. Acontece um pipeline - para iniciar a execução de uma operação, primeiro você precisa esperar quantos ciclos de clock forem necessários para realizar a operação anterior. Isso também é chamado de operação atrasada.
Aqui estão algumas durações ou atrasos importantes de uma operação em ticks:
- Acesso à memória global de até 48 GB: ~ 200 ciclos de clock.
- Acesso à memória compartilhada (até 164 KB por multiprocessador de streaming): ~ 20 clocks.
- Multiplicação-adição combinada (SUS): 4 medidas.
- Multiplicação de matrizes em núcleos tensores: 1 ciclo de clock.
Você também precisa saber que a menor unidade de threads em uma GPU - um pacote de 32 threads - é chamada de warp. Warps geralmente funcionam de forma síncrona - todos os threads dentro do warp precisam esperar uns pelos outros. Todas as operações de memória da GPU são otimizadas para warps. Por exemplo, o carregamento da memória global leva 32 * 4 bytes - 32 números de ponto flutuante, um desses números para cada thread no warp. Um multiprocessador de streaming (equivalente a um núcleo de processador para uma GPU) pode ter até 32 warps = 1024 threads. Os recursos do multiprocessador são compartilhados entre todos os warps ativos. Portanto, às vezes precisamos de menos warps para funcionar, de modo que um warp tenha mais registradores, memória compartilhada e recursos de núcleo tensor.
Para ambos os exemplos, vamos supor que temos os mesmos recursos de computação. Neste pequeno exemplo de multiplicação de matrizes 32 × 32, usamos 8 multiprocessadores (~ 10% do RTX 3090) e 8 warps em um multiprocessador.
Multiplicação de matrizes sem núcleos tensores
Se precisarmos multiplicar as matrizes A * B = C, cada uma delas com tamanho de 32 × 32, precisamos carregar os dados da memória, que acessamos constantemente, na memória compartilhada, uma vez que os atrasos de acesso são cerca de 10 vezes menos (não 200 bares e 20 bares). Um bloco de memória na memória compartilhada é freqüentemente chamado de bloco de memória ou simplesmente bloco. O carregamento de dois números de ponto flutuante de 32 × 32 em um bloco de memória compartilhada pode ser feito em paralelo usando 2 * 32 warps. Temos 8 multiprocessadores com 8 warps cada, então, graças à paralelização, precisamos realizar uma carga sequencial da memória global para a compartilhada, o que levará 200 ciclos de clock.
Para multiplicar matrizes, precisamos carregar um vetor de 32 números da memória compartilhada A e da memória compartilhada B, realizar o CMS e, em seguida, armazenar a saída nos registradores C. Dividimos este trabalho de forma que cada multiprocessador trate de 8 produtos escalares (32 × 32 ) para calcular 8 dados de saída para C. Por que existem exatamente 8 deles (em algoritmos antigos - 4), este é um recurso puramente técnico. Para descobrir isso, recomendo a leitura do artigo de Scott Gray . Isso significa que teremos 8 acessos à memória compartilhada, custando 20 ciclos cada, e 8 operações SLS (32 paralelas), custando 4 ciclos cada. No total, o custo será:
200 ticks (memória global) + 8 * 20 ticks (memória compartilhada) + 8 * 4 ticks (CMS) = 392 ticks
Agora vamos examinar esse custo para núcleos tensores.
Multiplicação de matrizes com núcleos tensores
Os núcleos tensores podem ser usados para multiplicar matrizes 4 × 4 em um ciclo. Para fazer isso, precisamos copiar a memória para núcleos tensores. Como acima, precisamos ler os dados da memória global (200 ticks) e armazená-los na memória compartilhada. Para multiplicar matrizes 32 × 32, precisamos realizar 8 × 8 = 64 operações em núcleos tensores. Um multiprocessador contém 8 núcleos tensores. Com 8 multiprocessadores, temos 64 núcleos tensores - tantos quanto precisamos! Podemos transferir dados da memória compartilhada para núcleos tensores em 1 transferência (20 ciclos de clock) e, em seguida, realizar todas essas 64 operações em paralelo (1 ciclo de clock). Isso significa que o custo total da multiplicação da matriz em núcleos tensores será:
200 ciclos de clock (memória global) + 20 ciclos de clock (memória compartilhada) + 1 ciclo de clock (núcleos de tensor) = 221 ciclos de clock
Assim, usando kernels tensores, reduzimos significativamente o custo de multiplicação de matrizes, de 392 para 221 ciclos de clock. Em nosso exemplo simplificado, os kernels tensores reduziram o custo do acesso à memória compartilhada e das operações SNS.
Embora este exemplo siga aproximadamente a sequência de etapas computacionais com e sem kernels tensores, observe que este é um exemplo muito simplificado. Em casos reais, a multiplicação de matrizes envolve muito como grandes blocos de memória e sequências de ações ligeiramente diferentes.
No entanto, parece-me que este exemplo deixa claro porque o próximo atributo, largura de banda da memória, é tão importante para GPUs com núcleos tensores. Como a memória global é a coisa mais cara ao multiplicar matrizes com núcleos tensores, nossas GPUs seriam muito mais rápidas se pudéssemos reduzir a latência de acesso à memória global. Isso pode ser feito aumentando a velocidade do clock da memória (mais clocks por segundo, mas mais calor e consumo de energia), ou aumentando o número de elementos que podem ser transferidos por vez (largura do barramento).
Largura de banda de memória
Na seção anterior, vimos como os kernels tensores são rápidos. Eles são tão rápidos que ficam ociosos a maior parte do tempo, esperando que os dados da memória global cheguem. Por exemplo, durante o treinamento para o projeto BERT Large, onde matrizes muito grandes foram usadas - quanto maior, melhor para kernels tensores - a utilização de kernels tensores em TFLOPS foi de cerca de 30%, o que significa que 70% do tempo os kernels tensores estavam ociosos.
Isso significa que, ao comparar duas GPUs com núcleos tensores, um dos melhores indicadores de desempenho para cada uma é a largura de banda da memória. Por exemplo, a GPU A100 tem largura de banda de 1.555 GB / s, enquanto a V100 tem 900 GB / s. Um cálculo simples diz que o A100 será mais rápido do que o V100 em 1555/900 = 1,73 vezes.
Memória Compartilhada / Cache L1 / Registros
Uma vez que o fator de limitação de velocidade é a transferência de dados para a memória de núcleos tensores, devemos nos voltar para outras propriedades da GPU, que nos permitem acelerar a transferência de dados para eles. Associados a isso estão a memória compartilhada, o cache L1 e o número de registros. Para entender como a hierarquia da memória acelera as transferências de dados, é útil entender como a matriz se multiplica na GPU.
Para a multiplicação de matrizes, usamos uma hierarquia de memória que vai da memória global lenta à memória local compartilhada rápida e, em seguida, a registradores ultrarrápidos. Porém, quanto mais rápida for a memória, menor ela será. Portanto, precisamos dividir as matrizes em matrizes menores e, em seguida, multiplicar esses blocos menores na memória compartilhada local. Então, isso acontecerá rapidamente e mais perto do multiprocessador de streaming (PM) - o equivalente ao núcleo do processador. Os núcleos tensores nos permitem dar mais um passo: pegamos todos os tiles e carregamos alguns deles nos núcleos tensores. A memória compartilhada processa blocos de matriz de 10 a 50 vezes mais rápido do que a memória GPU global e os registros de núcleo tensor processam 200 vezes mais rápido do que a memória GPU global.
Aumentar o tamanho dos ladrilhos nos permite reutilizar mais memória. Escrevi sobre isso em detalhes em meu artigo TPU vs GPU . Na TPU, há um bloco muito, muito grande para cada núcleo tensor. As TPUs podem reutilizar muito mais memória a cada nova transferência da memória global, o que as torna um pouco mais eficientes no tratamento da multiplicação de matrizes do que as GPUs.
Os tamanhos dos blocos são determinados pela quantidade de memória para cada PM - o equivalente a um núcleo de processador em uma GPU. Dependendo das arquiteturas, esses volumes são:
- Volta: 96 KB de memória compartilhada / 32 KB L1
- Turing: 64 KB de memória compartilhada / 32 KB L1
- Ampere: 164 KB de memória compartilhada / 32 KB L1
Você pode ver que o Ampere tem muito mais memória compartilhada, o que permite o uso de tiles maiores, o que reduz o número de acessos à memória global. Portanto, o Ampere faz um uso mais eficiente da largura de banda da memória da GPU. Isso aumenta o desempenho em 2 a 5%. O aumento é especialmente perceptível em matrizes enormes.
Os kernels tensores de ampere têm outra vantagem - eles têm uma grande quantidade de dados comuns a vários threads. Isso reduz o número de chamadas de registro. O tamanho dos registros é limitado a 64 k por PM ou 255 por thread. Comparado com Volta, os núcleos de tensor de ampere usam 3 vezes menos registros, portanto, há mais núcleos de tensor ativos por bloco na memória compartilhada. Em outras palavras, podemos carregar 3 vezes mais núcleos tensores com o mesmo número de registradores. No entanto, como a largura de banda continua sendo um gargalo, o aumento do TFLOPS na prática será insignificante em comparação com o teórico. Novos kernels tensores melhoraram o desempenho em cerca de 1-3%.
No geral, pode-se ver que a arquitetura Ampere é otimizada para usar a largura de banda da memória de forma mais eficiente por meio de uma hierarquia aprimorada - de memória global a blocos de memória compartilhados e registradores de núcleo tensor.
Avaliação da eficácia do Ampère em GO
Resumo:
- Estimativas teóricas baseadas na largura de banda da memória e na hierarquia de memória aprimorada para GPUs Ampere prevêem aceleração de 1,78-1,87 vezes.
- A NVIDIA publicou dados sobre medições de velocidade para GPUs Tesla A100 e V100. Eles são mais de marketing, mas um modelo imparcial pode ser construído com base neles.
- O modelo imparcial sugere que, em comparação com o V100, o Tesla A100 é 1,7 vezes mais rápido no processamento de linguagem natural e 1,45 vezes mais rápido na visão computacional.
Esta seção é para aqueles que procuram se aprofundar nos detalhes técnicos de como obtive as pontuações de desempenho da GPU Ampere. Se você não estiver interessado, pode ignorá-lo com segurança.
Estimativas de velocidade teórica de amperes
Dados os argumentos acima, seria de se esperar que a diferença entre as duas arquiteturas de GPU com núcleos tensores fosse principalmente na largura de banda da memória. Benefícios adicionais vêm de maior memória compartilhada e cache L1, e uso eficiente de registradores.
A largura de banda da GPU Tesla A100 foi aumentada em 1555/900 = 1,73 vezes em comparação com o Tesla V100. Também é razoável esperar um aumento de 2-5% na velocidade devido à maior memória total e 1-3% devido à melhoria nos núcleos tensores. Acontece que a aceleração deve ser de 1,78 a 1,87 vezes.
Ampere
Digamos que temos uma única pontuação de GPU para uma arquitetura como Ampere, Turing ou Volta. É fácil extrapolar esses resultados para outras GPUs da mesma arquitetura ou série. Felizmente, a NVIDIA já conduziu benchmarks comparando o A100 e o V100 em várias tarefas relacionadas à visão computacional e compreensão da linguagem natural. Infelizmente, a NVIDIA fez todo o possível para que esses números não pudessem ser comparados diretamente - eles usaram diferentes tamanhos de pacotes e diferentes números de GPUs nos testes para que o A100 não pudesse vencer. Portanto, em certo sentido, os indicadores de desempenho obtidos são parcialmente honestos e parcialmente publicitários. Em geral, pode-se argumentar que o aumento no tamanho do pacote de dados se justifica porque o A100 tem mais memória - no entanto,para comparar arquiteturas de GPU, precisamos comparar dados imparciais de desempenho em tarefas com o mesmo tamanho de pacote de dados.
Para obter estimativas imparciais, você pode dimensionar as medições V100 e A100 de duas maneiras: levar em consideração a diferença no tamanho do pacote de dados ou considerar a diferença no número de GPUs - 1 contra 8. Temos sorte e podemos encontrar estimativas semelhantes para ambos os casos nos dados fornecidos pela NVIDIA.
Dobrar o tamanho do pacote aumenta a taxa de transferência em 13,6% em imagens por segundo (para redes neurais convolucionais, CNN). Medi a velocidade da mesma tarefa com a arquitetura Transformer no meu RTX Titan e, surpreendentemente, obtive o mesmo resultado - 13,5%. Esta parece ser uma estimativa confiável.
Ao aumentar a paralelização das redes, ao aumentar o número de GPUs, perdemos desempenho devido à sobrecarga associada às redes. Mas a GPU A100 8x tem melhor desempenho em rede (NVLink 3.0) em comparação com a GPU V100 8x (NVLink 2.0) - outro fator confuso. Se você olhar os dados da NVIDIA, você pode ver que para o processamento do SNS, o sistema com o 8º A100 tem 5% menos overhead do que o sistema com o 8º V10000. Isso significa que se a transição do 1º A10000 para o 8º A10000 oferece uma aceleração de, digamos, 7,0 vezes, então a transição do 1º V10000 para o 8º V10000 dá a você uma aceleração de apenas 6,67 vezes. Para transformadores, esse valor é de 7%.
Usando essas informações, podemos estimar a aceleração de algumas arquiteturas GO específicas diretamente dos dados fornecidos pela NVIDIA. O Tesla A100 tem as seguintes vantagens de velocidade em relação ao Tesla V100:
- SE-ResNeXt101: 1,43 vezes.
- Mascarado-R-CNN: 1,47 vezes.
- Transformador (12 camadas, tradução automática, WMT14 en-de): 1,70 vezes.
Portanto, para a visão computacional, os números são obtidos abaixo da estimativa teórica. Isso pode ser devido a dimensões de tensor menores, a sobrecarga das operações necessárias para preparar uma multiplicação de matriz como img2col ou FFT ou operações que não podem saturar a GPU (as camadas resultantes são geralmente relativamente pequenas). Também podem ser artefatos de certas arquiteturas (convolução agrupada).
A avaliação prática da velocidade do transformador é muito próxima da teórica. Provavelmente porque os algoritmos para trabalhar com grandes matrizes são muito diretos. Usarei estimativas práticas para calcular a relação custo-benefício de uma GPU.
Possíveis imprecisões de estimativas
Acima são classificações comparativas para A100 e V100. No passado, a NVIDIA degradava secretamente o desempenho das GPUs RTX para "jogos": utilização reduzida de núcleos tensores, ventoinhas de jogos adicionadas para resfriamento e transferência de dados proibida entre as GPUs. É possível que a série RT 30 também tenha deficiências desconhecidas no Ampere A100.
O que mais considerar no caso do Ampere / RTX 30
Resumo:
- O Ampere permite treinar redes com base em matrizes esparsas, o que acelera o processo de treinamento em até duas vezes.
- O treinamento de rede esparso ainda é raramente usado, mas graças a ele, o Ampere não se tornará obsoleto em breve.
- O Ampere tem novos tipos de dados de baixa precisão que tornam muito mais fácil usar a baixa precisão, mas não necessariamente aumentam a velocidade em relação às GPUs anteriores.
- O novo design da ventoinha é bom se você tiver espaço livre entre as GPUs - no entanto, não está claro se as GPUs próximas umas das outras resfriarão efetivamente.
- O design de 3 slots do RTX 3090 será um desafio para 4 compilações de GPU. As soluções possíveis são usar opções de 2 slots ou expansores PCIe.
- Os quatro RTX 3090s precisarão de mais energia do que qualquer PSU padrão no mercado pode oferecer.
O novo NVIDIA Ampere RTX 30 tem vantagens adicionais sobre o NVIDIA Turing RTX 20 - aprendizado esparso e processamento de rede neural aprimorado. O restante das propriedades, como novos tipos de dados, podem ser consideradas um simples aprimoramento de conveniência - elas aceleram as coisas da mesma maneira que a série de Turing, sem exigir programação adicional.
Aprendizagem escassa
Ampere permite que você multiplique matrizes esparsas em alta velocidade e automaticamente. Funciona assim - você pega uma matriz, corta-a em pedaços de 4 elementos, e o núcleo tensorial que suporta matrizes esparsas permite que dois desses quatro elementos sejam zero. Isso resulta em um aumento de 2x, pois os requisitos de largura de banda durante a multiplicação da matriz são reduzidos à metade.
Em minha pesquisa, trabalhei com redes de aprendizagem esparsas. O trabalho foi criticado, em particular, pelo fato de eu "reduzir os FLOPS necessários para a rede, mas não aumentar a velocidade por causa disso, porque as GPUs não podem multiplicar matrizes esparsas rapidamente." Bem - o suporte para multiplicação de matrizes esparsas apareceu em núcleos de tensores e no meu algoritmo, ou em qualquer outro algoritmo ( link, link , link , link ), trabalhando com matrizes esparsas, agora podem funcionar duas vezes mais rápido durante o treinamento.
Embora essa propriedade seja atualmente considerada experimental e o treinamento de rede esparsa não seja universalmente aplicado, se sua GPU tiver suporte para essa tecnologia, você está pronto para o futuro do treinamento esparso.
Cálculos de baixa precisão
Já demonstrei como novos tipos de dados podem melhorar a estabilidade da retropropagação de baixa fidelidade em meu trabalho. Até agora, o problema com a retropropagação estável com números de ponto flutuante de 16 bits é que os tipos de dados regulares suportam apenas o intervalo [-65.504, 65.504]. Se o gradiente ultrapassar essa lacuna, ele explodirá, gerando valores NaN. Para evitar isso, geralmente escalamos os valores multiplicando-os por um pequeno número antes de retropropagar para evitar a explosão do gradiente.
O formato Brain Float 16 (BF16) usa mais bits para o expoente, portanto, o intervalo de valores possíveis é o mesmo que em FP32: [-3 * 10 ^ 38, 3 * 10 ^ 38]. O BF16 tem menos precisão, ou seja, menos dígitos significativos, mas a precisão do gradiente ao treinar as redes não é tão importante. Portanto, o BF16 garante que você não precise escalar ou se preocupar com a explosão de gradiente. Com este formato, devemos observar um aumento na estabilidade do treinamento às custas de uma pequena perda de precisão.
O que isso significa para você: a precisão do BF16 pode ser mais consistente do que a precisão do FP16, mas a velocidade é a mesma. Com a precisão do TF32, você obtém estabilidade quase como FP32 e aceleração quase como FP16. A vantagem é que, ao usar esses tipos de dados, você pode alterar FP32 para TF32 e FP16 para BF16, sem alterar nada no código!
Em geral, esses novos tipos de dados podem ser considerados preguiçosos, no sentido de que você poderia obter todos os seus benefícios usando os tipos de dados antigos e um pouco de programação (escalar corretamente, inicializar, normalizar, usar o Apex). Portanto, esses tipos de dados não fornecem aceleração, mas facilitam o uso de baixa fidelidade no treinamento.
Novo design de ventilador e problemas de dissipação de calor
O novo design da ventoinha para a série RTX 30 tem uma ventoinha de sopro e uma ventoinha de ar. O design em si é engenhoso e funcionará de forma muito eficiente se houver espaço livre entre as GPUs. No entanto, não está claro como as GPUs se comportarão se forem forçadas umas às outras. A ventoinha será capaz de soprar o ar de outras GPUs, mas é impossível dizer como isso funcionará já que seu formato é diferente do que era antes. Se você está planejando colocar 1 ou 2 GPUs onde há 4 slots, então você não deve ter problemas. Mas se você quiser usar 3-4 GPUs RTX 30 lado a lado, primeiro eu esperaria por relatórios sobre as condições de temperatura, e então decidi se preciso de mais ventoinhas, expansores PCIe ou outras soluções.
Em qualquer caso, o resfriamento a água pode ajudar a resolver o problema do dissipador de calor. Muitos fabricantes oferecem tais soluções para placas RTX 3080 / RTX 3090, e então elas não esquentarão, mesmo se houver 4. No entanto, não compre soluções de GPU prontas se você quiser construir um computador com 4 GPUs, pois será muito difícil na maioria dos casos distribuir radiadores.
Outra solução para o problema de resfriamento é comprar expansores PCIe e distribuir as placas dentro do gabinete. Isso é muito eficaz - eu e outros alunos de pós-graduação da Vanington University usamos essa opção com grande sucesso. Não parece muito legal, mas as GPUs não esquentam! Além disso, esta opção ajudará caso você não tenha espaço suficiente para acomodar a GPU. Se você tiver espaço em seu gabinete, pode, por exemplo, comprar um RTX 3090 padrão com três slots e distribuí-los usando expansores em todo o gabinete. Assim, é possível resolver simultaneamente o problema de espaço e refrigeração de 4 RTX 3090s

. Fig. 1: 4 GPU com expansores PCIe
Cartões de três slots e problemas de energia
O RTX 3090 ocupa 3 slots, portanto, eles não podem ser usados 4 cada com os ventiladores padrão da NVIDIA. Isso não é surpreendente, pois requer 350W TDP. O RTX 3080 é apenas ligeiramente inferior, exigindo 320W TDP, e resfriar um sistema com quatro RTX 3080s será muito difícil.
Também é difícil alimentar um sistema com 4 placas de 350W = 1400W. Existem fontes de alimentação (PSUs) de 1600 W, mas 200 W para o processador e a placa-mãe podem não ser suficientes. O consumo máximo de energia ocorre apenas com carga total e, durante o HE, o processador geralmente fica com carga leve. Portanto, uma fonte de alimentação de 1600W pode ser adequada para 4 RTX 3080s, mas para 4 RTX 3090s, é melhor procurar uma fonte de alimentação de 1700W ou mais. Não existem tais PSUs no mercado hoje. PSUs de servidor ou blocos especiais para criptominadores podem funcionar, mas podem ter um formato incomum.
Eficiência da GPU no aprendizado profundo
O próximo teste incluiu não apenas comparações do Tesla A100 e Tesla V100 - eu construí um modelo que se encaixa nesses dados e quatro testes diferentes, onde Titan V, Titan RTX, RTX 2080 Ti e RTX 2080 foram testados ( link , link , link , link ).
Também dimensionei os resultados de benchmark para placas de médio porte, como RTX 2070, RTX 2060 ou Quadro RTX, interpolando os pontos de dados de teste. Normalmente na arquitetura de GPU, esses dados são escalados linearmente em relação à multiplicação da matriz e largura de banda da memória.
Eu apenas coletei dados de testes de treinamento FP16 com precisão mista, pois não vejo razão para usar o treinamento com números FP32.

Figura: 2: Desempenho normalizado pelo RTX 2080 Ti
Em comparação com o RTX 2080 Ti, o RTX 3090 funciona 1,57 vezes mais rápido com redes convolucionais, 1,5 vezes mais rápido com transformadores e custa 15% a mais. Acontece que o Ampere RTX 30 está apresentando uma melhoria significativa desde a série Turing RTX 20.
Taxa de aprendizado profundo da GPU por custo
Qual GPU teria a melhor relação custo-benefício? Tudo depende do custo total do sistema. Se for caro, faz sentido investir em GPUs mais caras.
Abaixo estão os dados de três montagens em PCIe 3.0, que uso como linha de base para o custo de sistemas com 2 ou 4 GPUs. Eu pego esse custo base e adiciono o custo da GPU a ele. Calculo este último como o preço médio entre as ofertas da Amazon e do eBay. Para o novo Ampere, utilizo apenas um preço. Juntamente com os dados de desempenho acima, isso fornece valores de desempenho por dólar. Para um sistema com 8 GPUs, considero o supermicro barebone como um padrão da indústria para servidores RTX. Os gráficos mostrados não incluem os requisitos de memória. Primeiro, você precisa pensar na memória de que precisa e, em seguida, procurar as melhores opções nos gráficos. Exemplos de dicas para memória:
- Usando transformadores pré-treinados ou treinando um pequeno transformador do zero> = 11 GB.
- Treinamento de um grande transformador ou rede convolucional em pesquisa ou produção:> = 24 GB.
- Redes neurais de prototipagem (transformador ou rede convolucional)> = 10 GB.
- Participação em concursos Kaggle> = 8 GB.
- Visão computacional> = 10 GB.
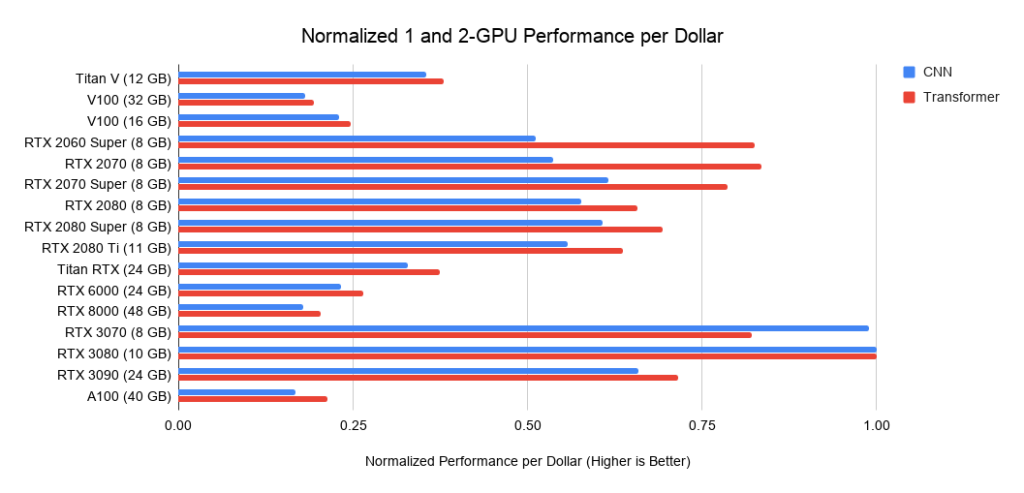
Figura:

Figura 3: Desempenho normalizado em dólares versus RTX 3080. Fig. Figura 4: Desempenho normalizado em dólares versus RTX 3080
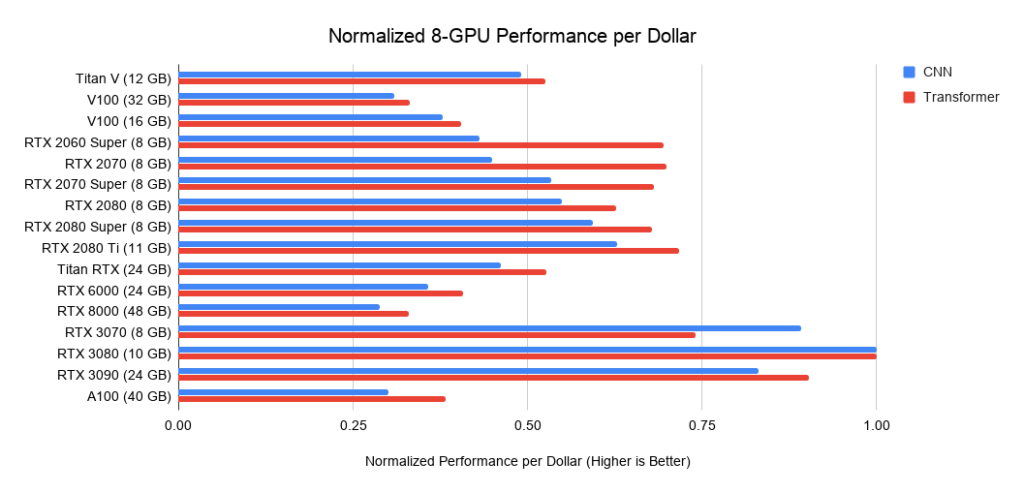
. 5: Desempenho normalizado em dólares versus RTX 3080.
Recomendações de GPU
Mais uma vez, quero enfatizar: ao escolher uma GPU, primeiro certifique-se de que ela tenha memória suficiente para suas tarefas. As etapas para escolher uma GPU devem ser as seguintes:
- , GPU: Kaggle, , , , - .
- , .
- GPU, .
- GPU - ? , RTX 3090, ? GPU? , GPU?
Algumas das etapas exigem que você pense sobre o que deseja e faça uma pequena pesquisa sobre quanta memória outras pessoas estão usando ao fazer o mesmo. Posso dar alguns conselhos, mas não posso responder totalmente a todas as perguntas nesta área.
Quando vou precisar de mais de 11 GB de armazenamento?
Já mencionei que para trabalhar com transformadores você vai precisar de pelo menos 11 GB, e ao fazer pesquisas nessa área, pelo menos 24 GB. A maioria dos modelos pré-treinados anteriores tem requisitos de memória muito altos e foram treinados em um RTX 2080 Ti ou GPU superior com pelo menos 11 GB de memória. Portanto, se você tiver menos de 11 GB de memória, iniciar alguns modelos pode se tornar difícil ou mesmo impossível.
Outras áreas que requerem grande quantidade de memória são imagens médicas, modelos avançados de visão por computador e todos com imagens grandes.
No geral, se você estiver procurando desenvolver modelos que possam superar a concorrência - seja em pesquisa, aplicações industriais ou competição Kaggle - a memória extra pode lhe dar uma vantagem competitiva.
Quando você consegue sobreviver com menos de 11 GB de memória?
As placas RTX 3070 e RTX 3080 são potentes, mas não têm memória. No entanto, para muitas tarefas, essa quantidade de memória pode não ser necessária.
O RTX 3070 é ideal para o treinamento GO. As habilidades básicas de rede para a maioria das arquiteturas podem ser adquiridas reduzindo as redes ou usando imagens menores. Se eu tivesse que aprender GO, escolheria o RTX 3070, ou mesmo alguns se eu pudesse pagar.
O RTX 3080 é o cartão com melhor custo-benefício atualmente e, portanto, ideal para prototipagem. A prototipagem requer grande quantidade de memória e a memória é barata. Por prototipagem, quero dizer prototipagem em qualquer campo - pesquisa, competições Kaggle, experimentando ideias para uma startup, experimentando com código de pesquisa. Para todas essas aplicações, o RTX 3080 é o mais adequado.
Se, digamos, eu fosse responsável por um laboratório de pesquisa ou uma startup, gastaria 66-80% do orçamento total em máquinas RTX 3080 e 20-33% em RTX 3090 com refrigeração de água confiável. RTX 3080 é mais econômico e pode ser acessado através do Slurm... Uma vez que a prototipagem precisa ser feita em modo ágil, ela precisa ser feita com modelos e conjuntos de dados menores. E o RTX 3080 é perfeito para isso. Depois que os alunos / colegas construíram um grande modelo de protótipo, eles podem implementá-lo no RTX 3090, aumentando a escala para modelos maiores.
Recomendações gerais
No geral, os modelos da série RTX 30 são muito poderosos e eu definitivamente os recomendo. Considere os requisitos de memória conforme declarado anteriormente, bem como os requisitos de energia e resfriamento. Se você tiver um slot livre entre as GPUs, não haverá problemas de resfriamento. Caso contrário, forneça às placas RTX 30 refrigeração a água, expansores PCIe ou placas eficientes com ventiladores.
No geral, eu recomendaria o RTX 3090 para qualquer pessoa que possa pagar por ele. Não só vai se adequar a você agora, mas permanecerá muito eficaz pelos próximos 3-7 anos. É improvável que nos próximos três anos a memória HBM se torne muito mais barata, então a próxima GPU será apenas 25% melhor do que o RTX 3090. Em 5-7 anos, provavelmente veremos memória HBM barata, após o que você definitivamente precisará atualizar a frota ...
Se você estiver montando um sistema a partir de vários RTX 3090s, forneça refrigeração e energia suficientes.
A menos que você tenha requisitos rígidos para vantagem competitiva, eu recomendaria o RTX 3080. Esta é uma solução mais econômica e fornecerá treinamento rápido para a maioria das redes. Se você faz os truques de memória que deseja e não se importa em escrever código extra, há muitos truques para espremer uma rede de 24 GB em uma GPU de 10 GB.
O RTX 3070 também é um ótimo cartão para treinamento e prototipagem GO, e é $ 200 mais barato que o RTX 3080. Se você não pode pagar pelo RTX 3080, então o RTX 3070 é sua escolha.
Se o seu orçamento for apertado e o RTX 3070 for muito caro para você, você pode encontrar um RTX 2070 usado no eBay por cerca de US $ 260. Ainda não está claro se o RTX 3060 será lançado, mas se o seu orçamento estiver apertado, pode valer a pena esperar. Se o preço for igual ao RTX 2060 e GTX 1060, deve custar em torno de US $ 250 a US $ 300 e deve funcionar bem.
Recomendações para clusters de GPU
O layout do cluster GPU é altamente dependente de seu uso. Para um sistema com 1.024 GPUs ou mais, o principal será a presença de uma rede, mas se você não usar mais do que 32 GPUs por vez, não há porque investir na construção de uma rede poderosa.
Em geral, os cartões RTX sob o contrato CUDA não podem ser usados em data centers. No entanto, as universidades muitas vezes podem ser a exceção a essa regra. Se você deseja obter essa permissão, vale a pena entrar em contato com um representante da NVIDIA. Se você pode usar cartões RTX, então eu recomendaria o sistema 8 GPU RTX 3080 ou RTX 3090 padrão da Supermicro (se você puder mantê-los resfriados). Um pequeno conjunto de 8 nós A10000 garante o uso eficiente de modelos após a prototipagem, especialmente se o resfriamento de servidores com 8 RTX 3090s não for possível. Nesse caso, eu recomendaria o A10000 em vez do RTX 6000 / RTX 8000, pois os A10000s são bastante econômicos e não envelhecerão rapidamente.
Se você precisa treinar redes muito grandes em um cluster de GPU (256 GPUs ou mais), eu recomendaria o sistema NVIDIA DGX SuperPOD com A10000. a partir de 256 GPUs, a rede se torna essencial. Se você deseja expandir para além de 256 GPUs, precisa de um sistema altamente otimizado para o qual as soluções padrão não funcionarão mais.
Especialmente na escala de 1.024 GPU e além, as únicas soluções competitivas no mercado continuam a ser Google TPU Pod e NVIDIA DGX SuperPod. Nessa escala, eu preferiria o Google TPU Pod, já que sua infraestrutura de rede dedicada parece melhor do que o NVIDIA DGX SuperPod - embora, em princípio, os dois sistemas sejam muito próximos. Em aplicativos e hardware, o sistema GPU é mais flexível do que o TPU, enquanto os sistemas TPU suportam modelos maiores e escalam melhor. Portanto, ambos os sistemas têm suas próprias vantagens e desvantagens.
Quais GPUs são melhores não comprar
Eu não recomendo comprar várias edições RTX Founders ou RTX Titans de uma vez, a menos que você tenha expansores PCIe para resolver seus problemas de resfriamento. Eles apenas se aquecerão e sua velocidade diminuirá drasticamente em comparação com o que é indicado nos gráficos. As quatro edições RTX 2080 Ti Founders aquecem rapidamente até 90 ° C, reduzem a velocidade do clock e funcionam mais lentamente do que um RTX 2070 normalmente resfriado.
Eu recomendo comprar um Tesla V100 ou A100 apenas em casos extremos, uma vez que eles estão proibidos de serem usados em data centers de empresas. Ou compre-os se precisar treinar redes muito grandes em enormes clusters de GPU - sua relação preço / desempenho não é ideal.
Se você pode comprar algo melhor, não opte por placas GTX 16 series. Eles não têm núcleos tensores, então seu desempenho no GO é ruim. Eu levaria um RTX 2070 / RTX 2060 / RTX 2060 Super usado em vez disso. Eles podem ser emprestados se seu orçamento for muito limitado.
Quando é melhor não comprar novas GPUs?
Se você já possui um RTX 2080 Ti ou superior, atualizar para um RTX 3090 é quase inútil. Suas GPUs já são boas e os benefícios de velocidade serão insignificantes em comparação com os problemas de energia e resfriamento adquiridos - não vale a pena.
O único motivo pelo qual eu gostaria de atualizar de quatro RTX 2080 Ti para quatro RTX 3090 é se eu estivesse pesquisando transformadores muito grandes ou outras redes que dependem muito da capacidade de computação. No entanto, se você tiver problemas de memória, deve primeiro considerar vários truques para empilhar modelos grandes na memória existente.
Se você possui um ou mais RTX 2070s, pensaria duas vezes se fosse você antes de atualizar. Estas são GPUs muito boas. Pode fazer sentido vendê-los no eBay e comprar um RTX 3090 se 8 GB não for suficiente para você - como é o caso de muitas outras GPUs. Se não houver memória suficiente, uma atualização está se formando.
Respostas a perguntas e equívocos
Resumo:
- As pistas PCIe e PCIe 4.0 são irrelevantes para sistemas de GPU dupla. Para sistemas com 4 GPUs, praticamente não.
- Resfriar o RTX 3090 e o RTX 3080 será difícil. Use refrigeradores de água ou expansores PCIe.
- NVLink é necessário apenas para clusters de GPU.
- GPUs diferentes podem ser usados no mesmo computador (por exemplo, GTX 1080 + RTX 2080 + RTX 3090), mas a paralelização eficiente não funcionará.
- Para executar mais de duas máquinas em paralelo, você precisa do Infiniband e de uma rede de 50 Gbps.
- Os processadores AMD são mais baratos do que os processadores Intel, e estes quase não apresentam vantagens.
- Apesar dos esforços heróicos dos engenheiros, a AMD GPU + ROCm dificilmente será capaz de competir com a NVIDIA devido à falta de comunidade e núcleos tensores equivalentes nos próximos 1-2 anos.
- As GPUs em nuvem são benéficas se usadas por menos de um ano. Depois disso, a versão desktop fica mais barata.
Eu preciso do PCIe 4.0?
Normalmente não. PCIe 4.0 é ótimo para um cluster de GPU. Útil se você tiver uma máquina de 8 GPU. Em outros casos, quase não apresenta vantagens. Ele melhora a paralelização e transfere dados um pouco mais rápido. Mas a transferência de dados não é um gargalo. Na visão computacional, o gargalo pode ser o armazenamento de dados, mas não a transferência de dados PCIe de GPU para GPU. Portanto, não há motivo para a maioria das pessoas usar o PCIe 4.0. Isso possivelmente irá melhorar a paralelização de quatro GPUs em 1-7%.
Eu preciso de pistas PCIe 8x / 16x?
Tal como acontece com PCIe 4.0, geralmente não. As pistas PCIe são necessárias para paralelização e transferência rápida de dados, o que quase nunca é um gargalo. Se você tiver 2 GPUs, 4 linhas são suficientes para eles. Para 4 GPUs, eu preferiria 8 linhas por GPU, mas se houver 4 linhas, isso diminuirá o desempenho em apenas 5-10%.
Como você instala quatro RTX 3090s quando cada um ocupa 3 slots PCIe?
Você pode comprar uma das duas opções para um slot ou distribuí-los usando expansores PCIe. Além de espaço, você precisa pensar imediatamente sobre refrigeração e uma fonte de alimentação adequada. Aparentemente, a solução mais fácil seria comprar 4 x RTX 3090 EVGA Hydro Coppers com um circuito de refrigeração de água dedicado. A EVGA tem feito versões de placas de cobre resfriadas a água por muitos anos e você pode confiar na qualidade de suas GPUs. Talvez existam opções mais baratas.
Os expansores PCIe podem resolver problemas de espaço e refrigeração, mas seu gabinete deve ter espaço suficiente para todas as placas. E certifique-se de que os extensores são longos o suficiente!
Como resfriar 4 RTX 3090 ou 4 RTX 3080?
Veja a seção anterior.
Posso usar vários tipos de GPU diferentes?
Sim, mas você não conseguirá paralelizar o trabalho com eficácia. Posso imaginar um sistema executando 3 RTX 3070 + 1 RTX 3090. Por outro lado, a paralelização entre quatro RTX 3070s funcionará muito rapidamente se você empinar seu modelo neles. E mais uma razão pela qual você pode precisar dele é o uso de GPUs antigas. Isso funcionará, mas a paralelização será ineficaz, pois as GPUs mais rápidas esperarão pelas GPUs mais lentas em pontos de sincronização (geralmente quando o gradiente é atualizado).
O que é NVLink e eu preciso dele?
Normalmente você não precisa do NVLink. É uma comunicação de alta velocidade entre várias GPUs. É necessário se você tiver um cluster de 128 ou mais GPUs. Em outros casos, quase não tem vantagens sobre a transferência de dados PCIe padrão.
Não tenho dinheiro nem para suas recomendações mais baratas. O que fazer?
Com certeza comprando uma GPU usada. RTX 2070 usado ($ 400) e RTX 2060 ($ 300) servirão perfeitamente. Se você não puder comprá-los, a próxima melhor opção seria uma GTX 1070 usada (US $ 220) ou GTX 1070 Ti (US $ 230). Se for muito caro, encontre uma GTX 980 Ti usada (6GB $ 150) ou GTX 1650 Super ($ 190). Se for caro também, é melhor usar os serviços em nuvem. Eles geralmente fornecem GPUs com um limite de tempo ou energia, após o qual você deve pagar. Troque os serviços até poder pagar sua própria GPU.
O que é necessário para paralelizar um projeto entre duas máquinas?
Para acelerar o trabalho paralelizando entre duas máquinas, você precisa de placas de rede de 50 Gbps ou mais. Eu recomendo instalar pelo menos EDR Infiniband - ou seja, uma placa de rede com velocidade de pelo menos 50 Gbps. Dois cartões EDR com cabo no eBay custam US $ 500.
Em alguns casos, você pode sobreviver com Ethernet de 10 Gbps, mas isso geralmente só funciona para certos tipos de redes neurais (certas redes convolucionais) ou para certos algoritmos (Microsoft DeepSpeed).
Os algoritmos de multiplicação de matrizes esparsas são adequados para qualquer matriz esparsa?
Aparentemente não. Visto que uma matriz deve ter 2 zeros para cada 4 elementos, as matrizes esparsas devem ser bem estruturadas. Provavelmente, é possível ajustar ligeiramente o algoritmo processando 4 valores como uma representação compactada de dois valores, mas isso significa que a multiplicação exata de matrizes esparsas por Ampère não estará disponível.
Preciso de um processador Intel para executar várias GPUs?
Eu não recomendo usar um processador Intel, a menos que você esteja colocando muito estresse no processador em concursos Kaggle (onde o processador é carregado com cálculos de álgebra linear). E mesmo para essas competições, os processadores AMD são ótimos. Os processadores AMD são em média mais baratos e melhores para GO. Para uma construção de 4 GPUs, Threadripper é minha escolha definitiva. Em nossa universidade, reunimos dezenas de sistemas baseados nesses processadores, e todos funcionam perfeitamente, sem qualquer reclamação. Para sistemas com 8 GPUs, eu pegaria o processador com o qual seu fabricante tem experiência. A confiabilidade do processador e do PCIe em sistemas de 8 placas é mais importante do que velocidade ou economia.
A forma da caixa é importante para o resfriamento?
Não. Normalmente as GPUs esfriam perfeitamente se houver até mesmo pequenas lacunas entre as GPUs. Caixas diferentes podem apresentar uma diferença de 1-3 ° C, e diferentes espaçamentos de carda podem fornecer uma diferença de 10-30 ° C. Em geral, se houver lacunas entre as placas, não há problema com o resfriamento. Se não houver lacunas, você precisará dos ventiladores certos (ventilador de sopro) ou de outra solução (refrigeração a água, expansores PCIe). Em qualquer caso, o tipo de caixa e seus ventiladores não importam.
O AMD GPU + ROCm alcançará o NVIDIA GPU + CUDA?
Não nos próximos dois anos. Existem três problemas: kernels tensores, software e comunidade.
Os próprios cristais de GPU da AMD são bons: excelente desempenho no FP16, excelente largura de banda de memória. Mas a ausência de núcleos tensores ou seus equivalentes leva ao fato de que seu desempenho é prejudicado em comparação com o GPU da NVIDIA. E sem a implementação de núcleos tensores no hardware, as GPUs AMD nunca serão competitivas. Segundo rumores, algum tipo de cartão para data centers com análogo de núcleos tensores está previsto para 2020, mas ainda não há dados exatos. Se eles tivessem apenas uma placa equivalente Tensor Core para servidores, isso significaria que poucas pessoas podem pagar as GPUs AMD, dando à NVIDIA uma vantagem competitiva.
Digamos que a AMD apresentará hardware com algo como núcleos tensores no futuro. Então muitos dirão: “Mas não há programas que funcionem com GPUs AMD! Como posso usá-los? " Isso é basicamente um equívoco. O software da AMD executando ROCm já está bem desenvolvido e o suporte no PyTorch é bem organizado. E embora eu não tenha visto muitos relatórios sobre o trabalho da AMD GPU + PyTorch, todas as funções do software estão integradas lá. Aparentemente, você pode escolher qualquer rede e executá-la em uma GPU AMD. Portanto, a AMD já está bem desenvolvida nessa área, e esse problema está praticamente resolvido.
Porém, com o software e a falta de núcleos tensores resolvidos, a AMD se deparará com outra: a falta de comunidade. Quando você se depara com um problema com as GPUs NVIDIA, pode pesquisar no Google por uma solução e encontrá-la. Isso aumenta a confiança nas GPUs NVIDIA. Uma infraestrutura está surgindo para facilitar o uso de GPUs NVIDIA (qualquer plataforma para GO funciona, qualquer tarefa científica é suportada). Existem vários hacks e truques que tornam muito mais fácil usar as GPUs NVIDIA (por exemplo, apex). Especialistas em GPU NVIDIA e programadores podem ser encontrados em cada arbusto, mas eu conheço muito menos especialistas em GPU AMD.
Em termos de comunidade, a situação da AMD é semelhante à de Julia vs Python. Julia tem muito potencial e muitos dirão com razão que essa linguagem de programação é mais adequada para o trabalho científico. No entanto, Julia raramente é usada em comparação com Python. Acontece que a comunidade Python é muito grande. Existem toneladas de pessoas reunidas em torno de pacotes poderosos como Numpy, SciPy e Pandas. Esta situação é semelhante à da NVIDIA vs AMD.
Portanto, é muito provável que a AMD não alcance a NVIDIA até que introduza o equivalente a núcleos tensores e uma comunidade sólida construída em torno do ROCm. A AMD sempre terá sua participação de mercado em subgrupos específicos (mineração de criptomoedas, data centers). Mas a NVIDIA provavelmente manterá o monopólio por mais dois anos.
Quando é melhor usar serviços em nuvem e quando é um computador GPU dedicado?
Uma regra simples: se você espera fazer o GO por mais de um ano, é mais barato comprar um computador com GPU. Caso contrário, é melhor usar serviços em nuvem - a menos que você tenha vasta experiência em programação em nuvem e queira aproveitar as vantagens de escalar o número de GPUs à vontade.
O ponto de inflexão exato em que as GPUs em nuvem se tornam mais caras do que possuir um computador depende muito dos serviços que estão sendo usados. É melhor calcular você mesmo. Abaixo está um exemplo de cálculo para um servidor AWS V100 com um V100, e comparando-o ao custo de um computador desktop com um RTX 3090, que tem desempenho próximo. Um RTX 3090 PC custa $ 2200 (2 GPU barebone + RTX 3090). Se você estiver nos EUA, adicione $ 0,12 por kWh para eletricidade. Compare isso a US $ 2,14 por hora por servidor na AWS.
Com 15% de reciclagem por ano, o computador usa
(350 W (GPU) + 100 W (CPU)) * 0,15 (reciclagem) * 24 horas * 365 dias = 591 kWh por ano.
591 kWh por ano dá um adicional de $ 71.
O ponto de inflexão, quando o computador e a nuvem se comparam em preço a 15% de utilização, chega por volta do 300º dia ($ 2.311 contra $ 2.270):
$ 2,14 / h * 0,15 (reciclagem) * 24 horas * 300 dias = $ 2.311
Se você calcular, que seus modelos GO durarão mais de 300 dias, é melhor comprar um computador do que usar AWS.
Cálculos semelhantes podem ser feitos para qualquer serviço em nuvem para decidir se usará seu computador ou a nuvem.
Os números comuns para a utilização do poder de computação são os seguintes:
- Computador PhD: <15%;
- Cluster de GPU em PhD Slurm:> 35%
- Grupo de pesquisa corporativa em Slurm:> 60%.
Em geral, as taxas de reciclagem são mais baixas em áreas onde pensar em ideias de ponta é mais importante do que desenvolver soluções práticas. Em algumas áreas, a taxa de utilização é menor (estudos de interpretabilidade), enquanto em outras é muito maior (tradução automática, modelagem de linguagem). Em geral, a reciclagem de carros pessoais é sempre superestimada. Normalmente, a maioria dos sistemas pessoais são reciclados de 5 a 10%. Portanto, eu recomendo fortemente que as equipes de pesquisa e empresas organizem clusters de GPU em Slurm em vez de desktops separados.
Dicas para quem tem preguiça de ler
Melhores GPUs em geral : RTX 3080 e RTX 3090.
GPUs a evitar (como pesquisador) : placas Tesla, Quadro, Founders Edition, Titan RTX, Titan V, Titan XP.
Boa relação desempenho / preço, mas caro : RTX 3080.
Boa relação desempenho / preço, mais barato : RTX 3070, RTX 2060 Super.
Tenho pouco dinheiro : compre cartões usados. Hierarquia: RTX 2070 ($ 400), RTX 2060 ($ 300), GTX 1070 ($ 220), GTX 1070 Ti ($ 230), GTX 1650 Super ($ 190), GTX 980 Ti (6GB $ 150).
Quase não tenho dinheiro : muitas startups anunciam seus serviços em nuvem. Use créditos grátis nas nuvens, mude-os em um círculo até que você possa comprar uma GPU.
Eu competir em competições Kaggle: RTX 3070.
Estou tentando vencer a competição em visão computacional, pré-treinamento ou tradução automática : 4 peças RTX 3090. Mas espere até que os especialistas confirmem que existem montagens com bom resfriamento e potência suficiente.
Estou aprendendo processamento de linguagem natural : se você não gosta de tradução automática, modelagem de linguagem ou pré-aprendizado, o RTX 3080 serve.
Comecei a fazer GO e me interessei muito: comece com o RTX 3070. Se você não ficar entediado em 6-9 meses, venda e compre quatro RTX 3080s. Dependendo do que você escolher em seguida (inicialização, Kaggle, pesquisa, GO aplicado), anos em três, venda suas GPUs e compre algo melhor (GPUs RTX de próxima geração).
Quero experimentar o GO, mas não tenho intenções sérias : o RTX 2060 Super será uma excelente escolha, porém, pode exigir a substituição do PSU. Se você possui um slot PCIe x16 em sua placa-mãe e o PSU produz cerca de 300 watts, a GTX 1050 Ti será uma excelente opção, já que não requer outros investimentos.
Cluster GPU para simulação paralela com menos de 128 GPUs : se você tiver permissão para comprar RTX para o cluster: 66% 8x RTX 3080 e 33% 8x RTX 3090 (somente se você puder resfriar bem o conjunto). Se o resfriamento não for suficiente, compre uma GPU RTX 6000 33% ou 8x Tesla A100. Se você não pode comprar uma GPU RTX, eu iria com 8 nós Supermicro A100 ou 8 nós RTX 6000.
Cluster GPU para simulação paralela com mais de 128 GPUs: Pense em carros com 8 Tesla A100. Se você precisar de mais de 512 GPUs, considere o Sistema DGX A100 SuperPOD.