
Vamos falar sobre uma rede neural que usa aprendizado profundo e aprendizado por reforço para jogar o Snake. Você encontrará o código no Github, análise de erros, demonstrações de IA e experimentos sob o corte.
Desde que assisti ao documentário da Netflix no AlphaGo, fico fascinado pelo aprendizado por reforço. Esse aprendizado é comparável ao aprendizado humano: você vê algo, faz algo e suas ações têm consequências. Bom ou mal. Você aprende com as consequências e ações corretas. A aprendizagem por reforço tem muitas aplicações: direção autônoma, robótica, comércio, jogos. Se você estiver familiarizado com o aprendizado por reforço, pule as próximas duas seções.
Aprendizagem por reforço
O princípio é simples. O agente aprende por meio da interação com o ambiente. Ele escolhe uma ação e recebe uma resposta do ambiente na forma de estados (ou observações) e recompensas. Este ciclo continua continuamente ou até que seja interrompido. Então, um novo episódio começa. Esquematicamente, é assim:

O objetivo do agente é obter o máximo de recompensas por episódio. No início do treinamento, o agente examina o ambiente: tenta diferentes ações no mesmo estado. À medida que o aprendizado avança, o agente pesquisa cada vez menos. Em vez disso, ele escolhe a ação mais recompensadora com base em sua própria experiência.
Aprendizagem por Reforço Profundo
O aprendizado profundo usa redes neurais para gerar resultados a partir de entradas. Com apenas uma camada oculta, o aprendizado profundo pode ampliar qualquer recurso. Como funciona? Uma rede neural é composta por camadas com nós. A primeira camada é a camada de dados de entrada. A segunda camada oculta transforma os dados usando pesos e uma função de ativação. A última camada é a camada de previsão.

Como o nome sugere, o aprendizado por reforço profundo é uma combinação de aprendizado profundo e aprendizado por reforço. O agente aprende a prever a melhor ação para um determinado estado usando estados como entradas, valores para ações como saídas e recompensas para ajustar os pesos na direção certa. Vamos escrever um Snake usando aprendizado por reforço profundo.

Definir ações, recompensas e condições
Para preparar o jogo para o agente, formalizamos o problema. Definir ações é fácil. O agente pode escolher a direção: cima, direita, baixo ou esquerda. As recompensas e o estado do espaço são um pouco mais complexos. Existem muitas soluções e uma funcionará melhor e a outra pior. Descreverei um deles abaixo e vamos tentar.
Se Snake pegar uma maçã, sua recompensa é 10 pontos. Se a cobra morrer, subtraia 100 pontos do prêmio. Para ajudar o agente, adicione 1 ponto quando a Cobra se mover para perto da maçã e subtraia um ponto quando a Cobra se afastar da maçã.
O estado tem muitas opções. Você pode pegar as coordenadas da cobra e da maçã ou a direção da maçã. É importante adicionar a localização dos obstáculos, ou seja, as paredes e o corpo da Cobra, para que o agente aprenda a sobreviver. Abaixo está um resumo das ações, condições e recompensas. Veremos mais tarde como os ajustes de estado afetam o desempenho.

Criar ambiente e agente
Adicionando métodos ao programa Snake, criamos um ambiente de aprendizagem por reforço. Os métodos são os seguintes:
reset(self), step(self, action)e get_state(self). Além disso, é necessário calcular a recompensa em cada etapa do agente. Dê uma olhada em run_game(self).
O agente trabalha com a rede Deep Q para encontrar a melhor ação. Parâmetros do modelo abaixo:
# epsilon sets the level of exploration and decreases over time
params['epsilon'] = 1
params['gamma'] = .95
params['batch_size'] = 500
params['epsilon_min'] = .01
params['epsilon_decay'] = .995
params['learning_rate'] = 0.00025
params['layer_sizes'] = [128, 128, 128]
Se você estiver interessado em ver o código, pode encontrá-lo no GitHub .
Agente joga cobra
E agora - a questão chave! O agente aprenderá a jogar? Vamos ver como ele interage com o meio ambiente. Abaixo estão os primeiros jogos. O agente não entende nada:

A primeira maçã! Mas ainda parece que a rede neural não sabe o que está fazendo.

Encontra a primeira maçã ... e depois atinge a parede. O início do décimo quarto jogo:

O agente aprende: seu caminho até a maçã não é o mais curto, mas ele encontra a maçã. Abaixo está o trigésimo jogo:

Depois de apenas 30 jogos, Snake evita colisões com ele mesmo e encontra um caminho rápido para a maçã.
Vamos brincar com o espaço
Pode ser possível alterar o espaço de estado e obter um desempenho semelhante ou melhor. Abaixo estão as opções possíveis.
- Sem direções: Não diga ao agente as direções em que o Snake está se movendo.
- Estado com coordenadas: substitua a posição da maçã (para cima, para a direita, para baixo e / ou para a esquerda) pelas coordenadas da maçã (x, y) e da cobra (x, y). Os valores das coordenadas estão em uma escala de 0 a 1.
- Direção 0 ou 1 estado.
- Estado apenas de parede: Reporta apenas se houver uma parede. Mas não sobre onde está o corpo: abaixo, acima, à direita ou à esquerda.

Abaixo estão os gráficos de desempenho para diferentes estados:
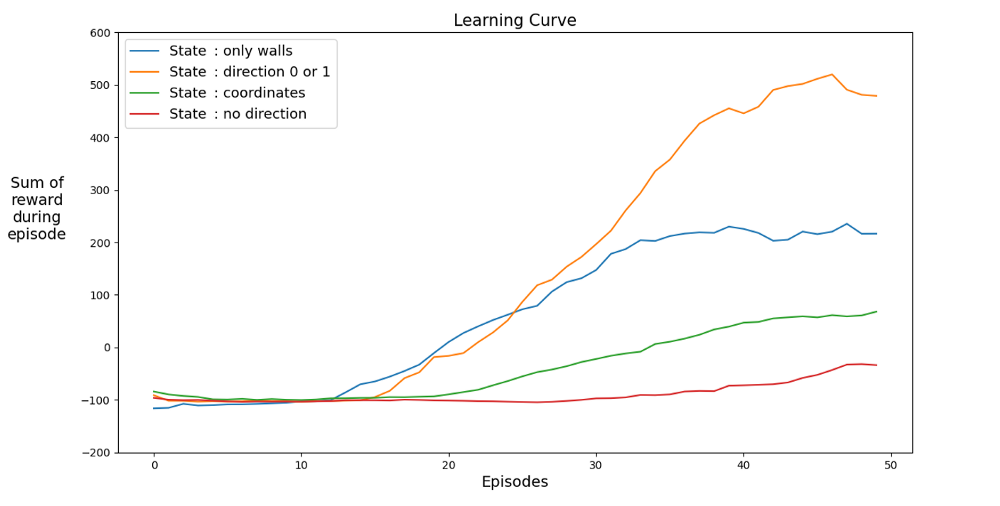
Vamos encontrar um espaço que acelere o aprendizado. O gráfico mostra as conquistas médias dos últimos 12 jogos em diferentes estados.
É claro que quando o espaço de estados possui direções, o agente aprende rapidamente, alcançando os melhores resultados. Mas espaço com coordenadas é melhor. Talvez você possa obter melhores resultados treinando a rede por mais tempo. A razão para o aprendizado lento pode ser o número de estados possíveis: 20⁴ * 2⁴ * 4 = 1.024.000. Curso 20 x 20, 64 opções de obstáculos e 4 opções de rumo atuais. Para o espaço da variante original, 3² * 2⁴ * 4 = 576. Isso é mais de 1.700 vezes menos do que 1.024.000 e, é claro, afeta o aprendizado.
Vamos brincar com prêmios
Existe uma lógica de recompensa interna melhor? Deixe-me lembrá-lo de que a cobra é premiada assim:

Primeiro erro. Andando em círculos
E se você alterasse -1 para +1? Isso pode diminuir a curva de aprendizado, mas no final a Cobra não morre. E isso é muito importante para o jogo. O agente aprende rapidamente a evitar a morte.

Em um intervalo de tempo, o agente recebe um ponto de sobrevivência.
Segundo erro. Batendo na parede
Vamos mudar o número de pontos para passar ao redor da maçã para -1. Vamos definir a recompensa para a própria maçã em 100 pontos. O que vai acontecer? O agente recebe uma penalidade para cada movimento, então ele se move para a maçã o mais rápido possível. Isso pode acontecer, mas há outra opção.

AI caminha ao longo da parede mais próxima para minimizar as perdas.
Experiência
Você só precisa de 30 jogos. O segredo da inteligência artificial é a experiência de jogos anteriores, que é levada em consideração para que a rede neural aprenda mais rápido. Em cada etapa regular, uma série de etapas de repetição (parâmetro
batch_size) são realizadas . Isso funciona tão bem porque, para um determinado par de ação e estado, a diferença na recompensa e no próximo estado é pequena.
Erro número 3. Sem experiência A experiência é
realmente importante? Vamos tirar. E leve a recompensa de 100 pontos pela maçã. Abaixo está um agente sem experiência que jogou 2500 jogos.

Embora o agente tenha jogado 2500 (!) Games, ele não joga a cobra. O jogo termina rapidamente. Caso contrário, 10.000 jogos teriam levado dias. Depois de 3000 jogos, só temos 3 maçãs. Após 10.000 jogos, as maçãs ainda são 3. É sorte ou um resultado de aprendizado?
Na verdade, a experiência ajuda muito. Pelo menos uma experiência que leve em consideração recompensas e tipo de espaço. Quantos replays você precisa por etapa? A resposta pode ser uma surpresa. Para responder a essa pergunta, vamos brincar com o parâmetro batch_size. No experimento original, foi definido como 500. Visão geral dos resultados com diferentes experiências:

200 jogos com experiência diferente: 1 jogo (sem experiência), 2 e 4. Média de 20 jogos.
Mesmo com experiência em 2 games, o agente já está aprendendo a jogar. No gráfico você vê o impacto
batch_size, o mesmo desempenho é obtido para 100 jogos se 4 for usado em vez de 2. O agente aprende a jogar Snake e consegue bons resultados, coletando de 40 a 60 maçãs em 50 jogos.
Um leitor atento pode dizer: o número máximo de maçãs em uma cobra é 399. Por que a IA não vence? A diferença entre 60 e 399 é, de fato, pequena. E isso é verdade. E há um problema aqui: a cobra não evita colisões ao voltar.
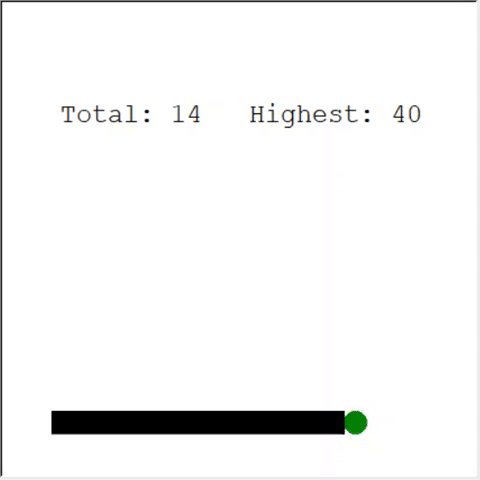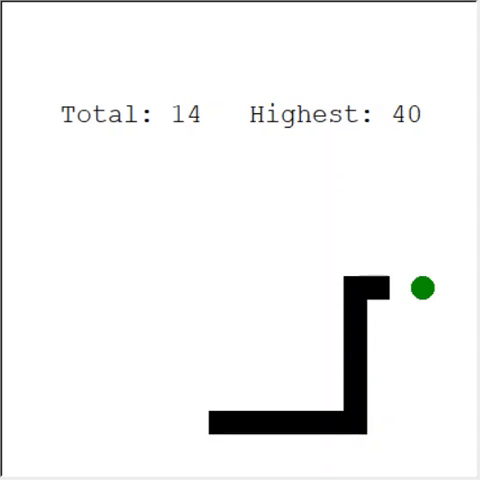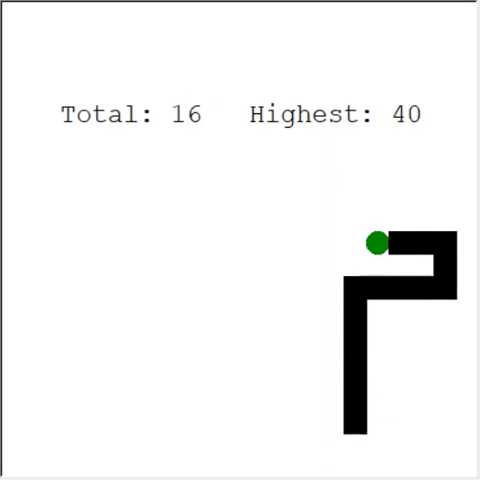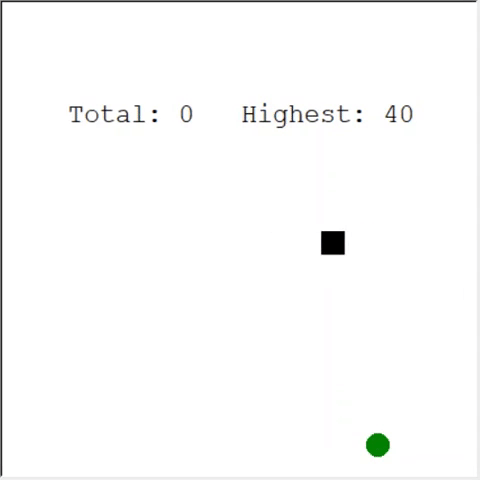
Uma maneira interessante de resolver o problema é usar a CNN para o campo de jogo. Dessa forma, a IA pode ver todo o jogo, não apenas os obstáculos próximos. Ele será capaz de reconhecer os lugares que precisam ser evitados para vencer.
Bibliografia
[1] K. Hornik, M. Stinchcombe, H. White, Multilayer feedforward networks are universal approximators (1989), Neural networks 2.5: 359–366
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
, Level Up , - SkillFactory:
- Machine Learning (12 )
- « Machine Learning Data Science» (20 )
- «Machine Learning Pro + Deep Learning» (20 )
- Data Science (12 )
E
- - (8 )
- - Data Analytics (5 )
- (6 )
- (18 )
- «Python -» (9 )
- DevOps (12 )
- Java- (18 )
- JavaScript (12 )
- UX- (9 )
- Web- (7 )
