
Com a transição para o auto-isolamento em março deste ano, nós, como muitas empresas, colocamos todos os nossos eventos de mercearia online. Bem, você se lembra desta foto maravilhosa sobre webinars com macacos. Nos últimos seis meses, apenas no tópico de data centers, pelos quais minha equipe é responsável, acumulamos cerca de 25 webinars gravados de 2 horas, 50 horas de vídeo no total. O problema que surge em pleno crescimento é como entender em qual vídeo procurar respostas para certas perguntas. O catálogo, as tags, uma breve descrição são bons, bem, finalmente descobrimos que existem 4 vídeos de duas horas sobre o assunto, e depois? Assistir no retrocesso? É possível de alguma forma diferente? E se você agir de uma forma elegante e tentar estragar a IA?
Spoiler para os impacientes : não consegui encontrar um sistema milagroso completo ou montá-lo no meu joelho, e então não haveria sentido neste artigo. Mas no final de vários dias (ou melhor, noites) de pesquisa, consegui um MVP funcionando, sobre o qual quero falar. O objetivo do artigo é examinar o nível de interesse neste assunto, obter conselhos de pessoas experientes e, talvez, encontrar alguém que tenha o mesmo problema.
O que eu quero fazer
À primeira vista, tudo parecia simples - você pega um vídeo, passa-o pela rede neural, obtém um texto e procura um fragmento no texto que descreva o tópico de interesse. Seria ainda mais conveniente pesquisar todos os vídeos do catálogo de uma vez. Na verdade, foi inventado para carregar transcrições do texto junto com os vídeos há muito tempo, o Youtube e a maioria das plataformas educacionais sabem fazer isso, embora seja claro que as pessoas lá editam esses textos. Você pode escanear rapidamente o texto com seus olhos e entender se há uma resposta para a pergunta desejada. Provavelmente, pela conveniente funcionalidade, não faria mal nenhum poder cutucar o local de interesse do texto e ouvir o que o palestrante diz e mostra ali, também não é difícil se houver uma marcação das palavras no tempo, onde estão no texto. Bem, eu estava sonhando com possíveis direções de desenvolvimento, vamos conversar no final,e agora vamos tentar simplesmente implementar a cadeia da forma mais eficiente possível
arquivo de vídeo -> fragmento de texto -> pesquisa de texto difusa .
A princípio pensei que, como tudo é tão simples, e esse caso já foi discutido em todas as conferências de IA por 4 anos, esses sistemas deveriam existir prontos. Algumas horas de pesquisa e leitura de artigos mostraram que não era esse o caso. O vídeo é utilizado principalmente para a busca de rostos, carros e outros objetos visuais (máscaras / capacetes), e áudio - músicas, faixas, bem como o tom / entonação do locutor, como parte de soluções para call centers. Conseguimos encontrar apenas esta menção ao sistema Deepgram . Mas ela, infelizmente, não tem suporte para o idioma russo. Além disso, a Microsoft tem uma funcionalidade muito semelhante no Streams , mas em nenhum lugar eu encontrei uma menção de suporte para o idioma russo, aparentemente, ele também não está lá.
Ok, vamos reinventar. Não sou um programador profissional (e, a propósito, aceitarei com prazer críticas construtivas sobre o código), mas de vez em quando escrevo algo “para mim”. As redes neurais que podem converter fala em texto são chamadas (surpresa surpresa), fala em texto . Se você encontrar um serviço público de fala para texto, poderá usá-lo para “digitalizar” a fala em todos os webinars e, em seguida, fazer uma pesquisa difusa no texto - uma tarefa mais fácil. Confesso que a princípio não pensei em “subir na nuvem”, queria recolher tudo localmente, mas depois de ler este artigo sobre o Habré, decidi que o reconhecimento de voz é realmente melhor feito na nuvem.
Procurando por serviços de nuvem para voz para texto
A busca por serviços capazes de fazer discurso-para-texto mostrou que existem muitos desses sistemas, incluindo aqueles desenvolvidos na Rússia, também há provedores globais de nuvem como Google , Amazon , MS Azure entre eles . As descrições de vários serviços, incluindo os em russo , estão aqui . Em geral, as primeiras 20 linhas nos resultados do mecanismo de pesquisa serão exclusivas. Mas há outro obstáculo - gostaria de lançar este sistema em produção no futuro, isso é um custo, e trabalho para a Cisco, que globalmente tem contratos com nuvens líderes. Então, de toda a lista, decidi considerar apenas eles por enquanto.
Portanto, minha lista foi reduzida a Google , Amazon , Azure ,IBM Watson (os links para os títulos são iguais aos da tabela abaixo). Todos os serviços possuem APIs por meio das quais podem ser usados. Depois de analisar o resto das possibilidades, compilei uma pequena tabela:

O IBM Watson saiu da corrida nesta fase, já que todas as gravações que tenho em russo, foi decidido testar o resto dos provedores em um pequeno trecho do webinar. Eu configurei contas no AWS e Azure. Olhando para o futuro, direi que a Microsoft acabou sendo um osso duro de roer em termos de abertura de conta. Trabalhei em uma rede corporativa que "pousa" na Internet em algum lugar de Amsterdã, durante o processo de registro me perguntaram duas vezes se tinha certeza de que meu endereço era na Rússia, após o que o sistema exibiu uma mensagem de que a conta estava em bloqueio administrativo "esclarecimento pendente" ... Depois de 5 dias, enquanto eu escrevia este artigo, a situação não mudou, então ainda não consegui testar o Azure, o que é uma pena! Eu entendo - segurança, mas isso ainda não me permitiu experimentar o serviço. Vou tentar fazer isso mais tarde, quando a situação estiver resolvida.
Separadamente, gostaria de testar essa função no Yandex.Cloud, o reconhecimento da fala russa, em teoria, deve ser o melhor. Mas, infelizmente, na página de acesso de teste do serviço, há apenas a possibilidade de "dizer" o texto, o download do arquivo não é fornecido. Então, vamos adiar junto com Azure em segundo lugar.
Então, existem Google e Amazon, vamos testá-lo em breve! Antes de escrever qualquer código, você pode verificar e comparar tudo manualmente, ambos os provedores, além da API, possuem uma interface administrativa. Para o teste, preparei primeiro um fragmento de 10 minutos de natureza geral, se possível, com um mínimo de terminologia especializada. Mas então descobri que o Google suporta um fragmento de até 1 minuto no modo de teste, então usei esse fragmento de 57 segundos para comparar os serviços .
Com base nos resultados do trabalho, ambos os serviços emitem o texto reconhecido, você pode comparar os resultados do seu trabalho em um intervalo de um minuto.
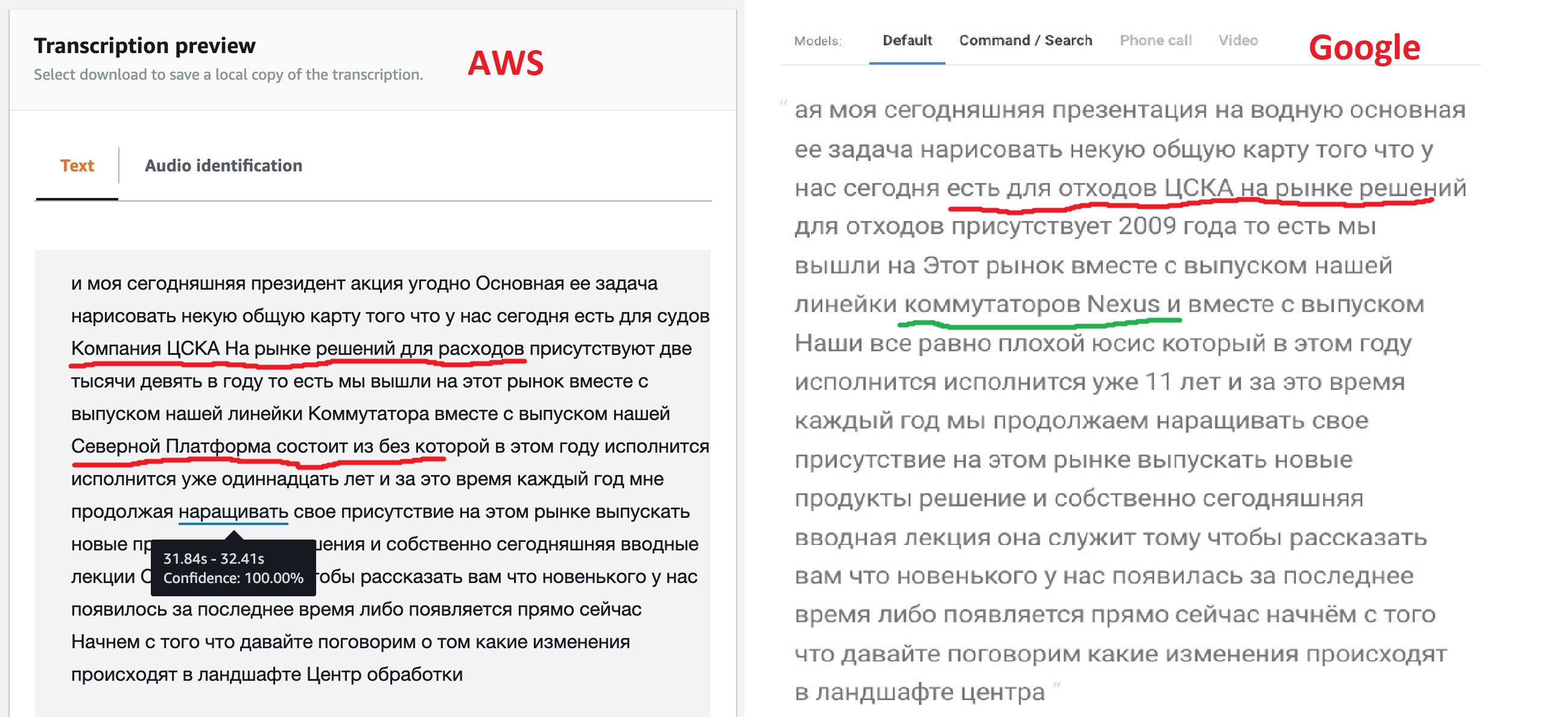
O resultado, francamente, não é o esperado, mas não é à toa que os modelos oferecem diferentes opções de customização. Como podemos ver, o motor do Google "fora da caixa" reconhecia a maior parte do texto de forma mais clara, também conseguia ver os nomes de alguns produtos, embora não de todos. Isso sugere que seu modelo permite texto multilíngue. A Amazon (mais tarde isso foi confirmado) não tem essa oportunidade - eles disseram em russo, o que significa que vamos cantar: "Kin babe lom" e ponto final!
Mas a capacidade de obter JSON com tag que a Amazon fornece parecia muito interessante para mim. Afinal, isso permitirá no futuro implementar uma transição direta para a parte do arquivo onde o fragmento desejado foi encontrado. Talvez o Google também tenha essa função, pois todas as redes neurais de reconhecimento de voz funcionam dessa forma, mas uma busca rápida na documentação não conseguiu encontrar esse recurso.

Olhando para este JSON, você pode ver que ele consiste em três seções: o texto traduzido (transcrição), uma matriz de palavras (itens) e um conjunto de segmentos (segmentos). Para uma matriz de palavras e segmentos, para cada elemento, são indicados seus tempos de início e fim, bem como a confiança da rede neural de que o reconheceu corretamente.
Ensinando uma rede neural a entender os data centers
Então, ao final dessa etapa, decidi escolher o Amazon Transcribe para novos experimentos e tentar configurar um modelo de aprendizado. E se você não conseguir um reconhecimento estável, negocie com o Google. Outros testes foram realizados em um fragmento de 10 minutos.
O AWS Transcribe tem duas opções para ajustar o que a rede neural reconhece e mais alguns recursos para pós-processamento de texto:
- Custom Vocabularies – «» , , «» , . : «, , » Word 97- . , , .. .
- Custom Language Models – «» 10 . , . , , , .
- , , -. , – , .. -, .
Então, decidi fazer minha própria palavra para o texto. Obviamente, incluirá palavras como "rede, servidores, perfis, data center, dispositivo, controlador, infraestrutura." Depois de 2-3 testes, meu vocabulário cresceu para 60 palavras. Este dicionário deve ser criado em um arquivo de texto normal, uma palavra por linha, todas em letras maiúsculas. Existe também uma opção mais complexa ( descrita aqui ) com a capacidade de especificar como a palavra é pronunciada, mas no estágio inicial decidi fazer com uma lista simples.
Antes de usar um dicionário, você precisa criá-lo. Na guia Vocabulário personalizado no Amazon Transcribe, clique em Criar vocabulário , carregue o texto do nosso arquivo, especifique o idioma russo, responda ao restante das perguntas e o processo de criação de um dicionário começa. Quando ele sairO processamento fica pronto - o dicionário pode ser usado.
A questão permanece - como reconhecer termos em "inglês"? Deixe-me lembrá-lo de que o dicionário suporta apenas um idioma. A princípio pensei em criar um dicionário separado com termos em inglês e executar o mesmo texto nele. Quando termos como Cisco , VLAN , UCS são detectadosetc. c taxa de probabilidade de 100% - considere-os para o fragmento de tempo fornecido. Mas direi de imediato que não funcionou, o analisador de inglês não reconheceu mais da metade dos termos do texto. Depois de refletir, decidi que era lógico, já que pronunciamos todos esses termos com "sotaque russo", mesmo os anglo-americanos não nos entendem da primeira vez. Isso levou à ideia de simplesmente adicionar esses termos ao dicionário russo de acordo com o princípio "como é ouvido, assim está escrito". Cisco , usies , eisiai , vilan , viikslan - afinal, dizemos isso honestamente quando nos comunicamos. Isso aumentou o dicionário em algumas dezenas de palavras, mas olhando para o futuro, melhorou a qualidade do reconhecimento em uma ordem de magnitude!
Como diz o ditado, "vem depois um pensamento bom" , o primeiro dicionário já foi criado, então resolvi criar outro, adicionando todas as abreviaturas a ele, e comparando o que acontece.
Iniciar o reconhecimento com um dicionário é tão fácil quanto, no serviço Transcrever na guia Trabalho de transcrição , selecione Criar trabalho , especifique o idioma russo e não se esqueça de especificar o dicionário que precisamos. Outra ação útil - você pode pedir à rede neural para nos fornecer vários resultados de pesquisa alternativos, o item Resultados alternativos - Sim , eu defino 3 opções alternativas. Mais tarde, quando eu fizer pesquisas de texto difuso, isso será útil.
A transmissão de um texto de 10 minutos leva de 4 a 5 minutos, para não perder tempo, resolvi escrever uma pequena ferramenta que vai facilitar o processo de comparação dos resultados. Exibirei o texto final do arquivo JSON no navegador, destacando simultaneamente a “confiabilidade” da detecção de palavras individuais pela rede neural (o mesmo parâmetro de confiança ). Tenho três opções para o texto resultante - a tradução padrão, um dicionário sem termos e um dicionário com termos. Deixe todos os três textos serem exibidos simultaneamente em três colunas. Destaco palavras com confiabilidade acima de 95% em verde, de 95% a 70% em amarelo, abaixo de 70% em vermelho. O código compilado às pressas da página HTML resultante está abaixo, os arquivos JSON devem estar no mesmo diretório que o arquivo. Os nomes dos arquivos são especificados nas variáveis FILENAME1, etc.
Código da página HTML para ver os resultados
<!DOCTYPE html>
<html lang="en">
<head> <meta charset="UTF-8"> <title>Title</title> </head>
<body onload="initText()">
<hr> <table> <tr valign="top">
<td width="400"> <h2 >- </h2><div id="text-area-1"></div></td>
<td width="400"> <h2 > 1: / </h2><div id="text-area-2"></div></td>
<td width="400"> <h2 > 2: / </h2><div id="text-area-3"></div></td>
</tr> </table> <hr>
<style>
.known { background-image: linear-gradient(90deg, #f1fff4, #c4ffdb, #f1fff4); }
.unknown { background-image: linear-gradient(90deg, #ffffff, #ffe5f1, #ffffff); }
.badknown { background-image: linear-gradient(90deg, #feffeb, #ffffc2, #feffeb); }
</style>
<script>
// File names
const FILENAME1 = "1-My_CiscoClub_transcription_10min-1-default.json";
const FILENAME2 = '2-My_CiscoClub_transcription_10min-2-Russian_only.json';
const FILENAME3 = '3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json';
// Read file from disk and call callback if success
function readTextFile(file, textBlockName, callback) {
let rawFile = new XMLHttpRequest();
rawFile.overrideMimeType("application/json");
rawFile.open("GET", file, true);
rawFile.onreadystatechange = function() {
if (rawFile.readyState === 4 && rawFile.status == "200") {
callback(textBlockName, rawFile.responseText);
}
};
rawFile.send(null);
}
// Insert text to text block and color words confidence level
function updateTextBlock(textBlockName, text) {
var data = JSON.parse(text);
let translatedTextList = data['results']['items'];
const listLen = translatedTextList.length;
const textBlock = document.getElementById(textBlockName);
for (let i=0; i<listLen; i++) {
let addWord = translatedTextList[i]['alternatives'][0];
// load word probability and setup color depends on it
let wordProbability = parseFloat(addWord['confidence']);
let wordClass = 'unknown';
// setup the color
if (wordProbability > 0.95) {
wordClass = 'known';
} else if (wordProbability > 0.7) {
wordClass = 'badknown';
}
// insert colored word to the end of block
let insText = '<span class="' + wordClass+ '">' + addWord['content'] + ' </span>';
textBlock.insertAdjacentHTML('beforeEnd', insText)
}
}
function initText() {
// read three files each to it's area
readTextFile(FILENAME1, "text-area-1", function(textBlockName, text){
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME2, "text-area-2", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME3, "text-area-3", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
}
</script>
</body></html>
Eu faço download dos arquivos asrOutput.json para todas as três tarefas, renomeio-os conforme escrito no script HTML e é isso que acontece.

É visto claramente que a adição de termos do idioma russo permitiu que a rede neural reconhecesse com mais precisão termos específicos - " perfil de serviço ", etc. E a adição da transcrição russa na segunda etapa transformou o CSKA em cisco . O texto ainda está bastante "sujo", mas para minha tarefa de pesquisa de contexto já deve ser adequado. À medida que novos webinars são adicionados e lidos, o vocabulário se expande gradualmente; esse é um processo de manutenção de tal sistema que não deve ser esquecido.
Pesquisa difusa em texto reconhecido
Provavelmente, existem uma dezena de abordagens para resolver o problema da pesquisa fuzzy, na maioria das vezes baseadas em um pequeno conjunto de algoritmos matemáticos, como, por exemplo, distância de Levenshtein. bom artigo sobre isso , mais um e mais um . Mas eu queria encontrar algo pronto, como lançado e funcionando.
De soluções prontas para busca de documentos locais, após um pouco de pesquisa, encontrei um projeto relativamente antigo SPHINX, e a possibilidade de busca de texto completo, ao que parece, está no PostgreSQL, está escrito sobre isso AQUI . Mas a maioria dos materiais, inclusive em russo, foram encontrados sobre o Elasticsearch . Depois de ler bons guias de inicialização e configuração, comoEste post ou esta lição , aqui está outra , assim como a documentação e guia de API para Python , decidi usar.
Para todos os experimentos locais, uso o Docker há muito tempo e recomendo fortemente a todos que, por algum motivo, ainda não descobriram como fazer isso. Na verdade, tento não executar nada além de ambientes de desenvolvimento, navegadores e "visualizadores" no sistema operacional local. Além da ausência de problemas de compatibilidade, etc. isso permite que você experimente rapidamente um novo produto e veja se funciona bem.
Baixamos o contêiner com Elasticsearch e o executamos com dois comandos:
$ docker pull elasticsearch:7.9.1
$ docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.9.1
Após iniciar o container,
http://localhost:9200a interface elástica aparece no endereço , podendo ser acessada por meio de um navegador ou da API REST de uma ferramenta POSTMAN. Mas encontrei um plug-in do Chrome útil .
É assim que a janela do plugin se parece com o exemplo sobre gatinhos engraçados descrito em um dos guias acima .
À esquerda está uma consulta - à direita está uma resposta, preenchimento automático, realce de sintaxe, formatação automática - o que mais é necessário para ser produtivo! Além disso, este plugin pode reconhecer o formato da linha de comando CURL no texto colado da área de transferência e formatá-lo corretamente, por exemplo, tente colar a linha
" curl -X GET $ ES_URL " e veja o que acontece. Uma coisa útil, em geral.
O que e como irei armazenar e pesquisar?Elasticsearch pega todos os documentos JSON e os armazena em estruturas chamadas índices. Pode haver quantos índices diferentes você quiser, mas um índice pode conter dados e documentos homogêneos, com uma estrutura de campos semelhante e a mesma abordagem de pesquisa.
Para investigar as possibilidades da pesquisa fuzzy, decidi baixar e pesquisar a seção frase (segmentos) do arquivo de transcrição obtido na etapa anterior. Na seção de segmentos do arquivo JSON, os dados são armazenados no seguinte formato:
- 1 (segment)
-> /
->
--> 1
---->
----> , (confidence)
--> 2
---->
----> , (confidence)
Desejo aumentar a probabilidade de uma pesquisa bem-sucedida, então carregarei todas as opções alternativas para o banco de dados para pesquisa e, a partir dos fragmentos encontrados, escolho aquele com a maior confiança total.
Para reformatar e carregar um documento JSON no Elasticsearch, uso um pequeno script Python, a lógica do script é a seguinte:
- Primeiro, examinamos todos os elementos da seção de segmentos e todas as opções alternativas de transcrição
- Para cada opção de transcrição, consideramos sua confiança de reconhecimento total, eu apenas considero a média aritmética para palavras individuais, embora, provavelmente, no futuro, isso precise ser abordado com mais cuidado
- Para cada opção de transcrição alternativa, carregue um registro do formulário no Elasticsearch
{ "recording_id" : < >, "seg_id" : <id >, "alt_id" : <id >, "start_time" : < >, "end_time" : < >, "transcribe_score" : < (confidence) >, "transcript" : < > }
Script Python que carrega registros de um arquivo JSON no Elasticsearch
from elasticsearch import Elasticsearch
import json
from statistics import mean
#
TRANCRIBE_FILE_NAME = "3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json"
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
es.indices.create(index=INDEX_NAME) # Create index for our recordings
# Open and load file
res = None
with open(TRANCRIBE_FILE_NAME) as json_file:
data = json.load(json_file)
res = data['results']
#
index = 1
for idx, seq in enumerate(res['segments']):
# enumerate fragments
for jdx, alt in enumerate(seq['alternatives']):
# enumerate alternatives for each segments
score_list = []
for item in alt['items']:
score_list.append( float(item['confidence']))
score = mean(score_list)
obj = {
"recording_id" : "rec_1",
"seg_id" : idx,
"alt_id" : jdx,
"start_time" : seq["start_time"],
"end_time" : seq ["end_time"],
"transcribe_score" : score,
"transcript" : alt["transcript"]
}
es.index( index=INDEX_NAME, id = index, body = obj )
index += 1
Se você não tem Python, não desanime, o Docker nos ajudará novamente. Eu costumo usar um contêiner com um notebook Jupyter - você pode se conectar a ele com um navegador normal e fazer o que for preciso, a única coisa que você precisa pensar em salvar os resultados, já que todas as informações são perdidas quando o contêiner é destruído. Se você não trabalhou com essa ferramenta antes, então aqui está um bom artigo para iniciantes , a propósito, você pode pular com segurança a seção sobre instalação.
Iniciamos um contêiner com um bloco de notas Python com o comando:
$ docker run -p 8888:8888 jupyter/base-notebook sh -c 'jupyter notebook --allow-root --no-browser --ip=0.0.0.0 --port=8888'
E nos conectamos a ele com qualquer navegador no endereço que vemos na tela após o lançamento bem-sucedido do script, isto é,
http://127.0.0.1:8888com a chave de segurança especificada.
Criamos um novo notebook, na primeira célula escrevemos:
!pip install elasticsearch
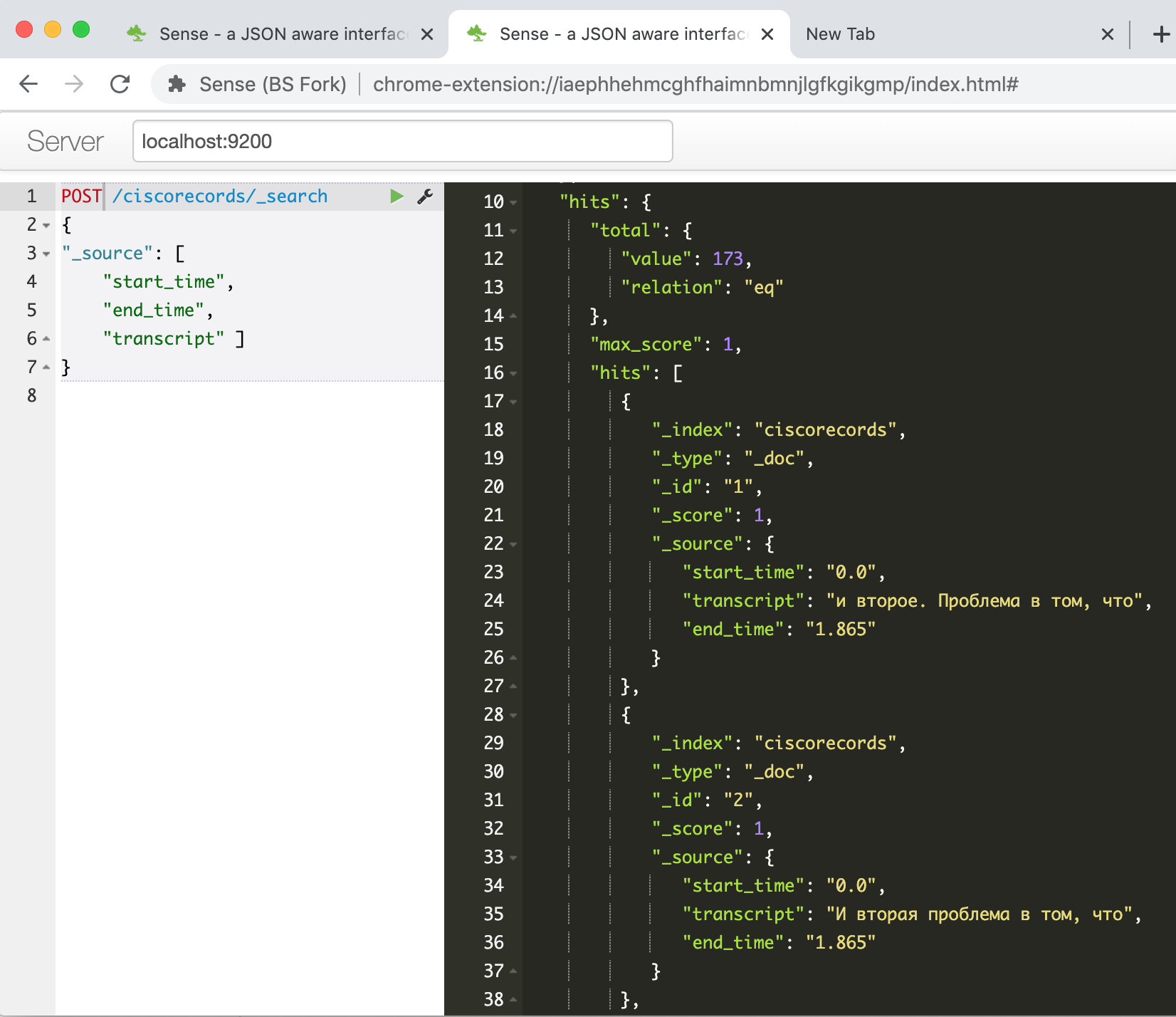
Execute, espere até que o pacote para trabalhar com ES através da API seja instalado, copie nosso script para a segunda célula e execute-o. Depois de seu trabalho, se tudo der certo, podemos verificar no console do Elasticsearch se nossos dados foram carregados com sucesso. Entramos no comando
GET /ciscorecords/_searche vemos nossos registros carregados na janela de resposta, um total de 173 peças, conforme o campo hits.total.value nos informa .
Agora é a hora de tentar a pesquisa difusa - é disso que se trata. Por exemplo, para pesquisar a frase "núcleo da rede do data center", você precisa fornecer o seguinte comando:
POST /ciscorecords/_search
{
"size" : 20,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : " ",
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
"_source": [ "transcript", "transcribe_score" ]
}
Temos até 47 resultados!

Não é de surpreender, já que a maioria deles são variações diferentes do mesmo fragmento. Vamos escrever outro script para selecionar de cada segmento um registro com o valor de confiança mais alto.
Script Python para consultar o banco de dados Elasticsearch
#####
#
# PHRASE = " "
# PHRASE = " "
PHRASE = " "
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
#
elastic_queary = {
"size" : 40,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : PHRASE,
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
}
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
#
res = es.search(index=INDEX_NAME, body = elastic_queary)
print ("Got %d Hits:" % res['hits']['total']['value'])
#
search_results = {}
for hit in res['hits']['hits']:
seg_id = hit["_source"]['seg_id']
if seg_id not in search_results or search_results[seg_id]['score'] < hit["_score"]:
_res = hit["_source"]
_res["score"] = hit["_score"]
search_results[seg_id] = _res
print ("%s unique results \n-----" % len(search_results))
for rec in search_results:
print ("seg %(seg_id)s: %(score).4f : start(%(start_time)s)-end(%(end_time)s) -- %(transcript)s" % \
(search_results[rec]))
Exemplo de saída:
Got 47 Hits:
16 unique results
-----
seg 39: 7.2885 : start(374.24)-end(377.165) -- , ..
seg 49: 7.0923 : start(464.44)-end(468.065) -- , ...
seg 41: 4.5401 : start(385.14)-end(405.065) -- . , , , , , ...
seg 30: 4.3556 : start(292.74)-end(298.265) -- , , ,
seg 44: 2.1968 : start(415.34)-end(426.765) -- , , , . -
seg 48: 2.0587 : start(449.64)-end(464.065) -- , , , , , .
seg 26: 1.8621 : start(243.24)-end(259.065) -- . . , . ...
Vemos que os resultados ficaram muito menores e agora podemos visualizá-los e selecionar o que mais nos interessa.
Além disso, como temos o horário de início e término do fragmento de vídeo, podemos fazer uma página com um player de vídeo e programaticamente "retroceder" até o fragmento de interesse.
Mas vou colocar essa tarefa em um artigo separado, se houver interesse em mais publicações sobre este tópico.
Em vez de uma conclusão
Assim, no âmbito deste artigo, mostrei como resolvi o problema de construir um sistema de busca de texto usando uma ferramenta de vídeo com gravações de webinars sobre temas técnicos. Como resultado, obtivemos o que geralmente é chamado de MVP, ou seja, o algoritmo mínimo de trabalho que permite obter um resultado e prova que o resultado é, em princípio, alcançável com as tecnologias existentes.
Ainda há um longo caminho a percorrer até o produto final, a partir de ideias que podem ser implementadas em um futuro próximo:
- Aperte o reprodutor de vídeo para que você possa ouvir, ver o fragmento encontrado
- Pense na possibilidade de edição de texto, enquanto você pode deixar uma âncora para o texto de palavras reconhecidas em 100%, edite apenas fragmentos onde a qualidade de reconhecimento "afunda"
- elasticsearch, -
- speech-to-text, Google, Yandex, Azure. –
- , «»
- BERT (Bi-directional Encoder Representation from Transformer), . – « xx yy».
- , - - . Youtube , 15-20 , ,
- – , , ,
Se você tiver dúvidas / comentários, terei prazer em respondê-los, e também ficarei feliz em ouvir sugestões para melhorar ou simplificar o processo como um todo. Este é o meu primeiro artigo técnico para o Habr, realmente espero que tenha sido útil e interessante.
Boa sorte a todos em sua busca criativa e que a Força esteja com você!