Depois de aprender sobre o KMath , decidi generalizar essa otimização para uma variedade de estruturas matemáticas e operadores definidos nelas.
KMath é uma biblioteca de matemática e álgebra computacional que faz uso extensivo de programação orientada ao contexto em Kotlin. O KMath separa as entidades matemáticas (números, vetores, matrizes) e as operações sobre elas - elas são fornecidas como um objeto separado, uma álgebra correspondente ao tipo de operandos, Álgebra <T> .
import scientifik.kmath.operations.*
ComplexField {
(i pow 2) + Complex(1.0, 3.0)
}Assim, após escrever um gerador de bytecode, levando em consideração as otimizações da JVM, você pode obter cálculos rápidos para qualquer objeto matemático - basta definir as operações sobre eles no Kotlin.
API
Para começar, era necessário desenvolver uma API de expressões para só depois proceder à gramática da linguagem e à árvore sintática. Ele também teve a ideia inteligente de definir álgebra sobre as próprias expressões para apresentar uma interface mais intuitiva.
A base de toda a API de expressão é a interface Expression <T> e a maneira mais fácil de implementá-la é definir diretamente o método invoke a partir dos parâmetros fornecidos ou, por exemplo, expressões aninhadas. Uma implementação semelhante foi integrada ao módulo raiz como referência, embora seja a mais lenta.
interface Expression<T> {
operator fun invoke(arguments: Map<String, T>): T
}Implementações mais avançadas já são baseadas no MST. Esses incluem:
- Intérprete MST,
- Gerador de classe MST.
Uma API para analisar expressões de uma string para MST já está disponível no branch dev KMath, assim como o gerador de código JVM mais ou menos final.
Vamos passar para o MST. Atualmente, existem quatro tipos de nós no MST:
- terminal:
- símbolos (ou seja, variáveis)
- números;
- operações unárias;
- operações binárias.
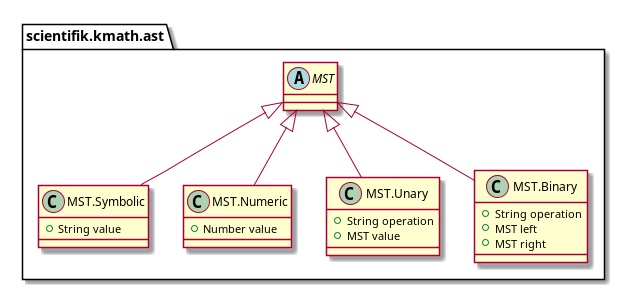
A primeira coisa que você pode fazer com isso é ignorar e calcular o resultado a partir dos dados disponíveis. Passando na álgebra de destino o ID da operação, por exemplo "+", e os argumentos, por exemplo 1.0 e 1.0 , podemos esperar o resultado se esta operação for definida. Caso contrário, quando avaliada, a expressão cairá com uma exceção.

Para trabalhar com MST, além da linguagem de expressão, existe também a álgebra - por exemplo, MstField:
import scientifik.kmath.ast.*
import scientifik.kmath.operations.*
import scientifik.kmath.expressions.*
RealField.mstInField { number(1.0) + number(1.0) }() // 2.0O resultado do método acima é uma implementação de Expression <T> que, quando chamada, causa uma travessia da árvore obtida pela avaliação da função passada para mstInField .
Geração de código
Mas isso não é tudo: ao percorrer, podemos usar os parâmetros da árvore como quisermos e não nos preocupar com a ordem das ações e a aridade das operações. Isso é usado para gerar bytecode.
A geração de código em kmath-ast é uma montagem parametrizada da classe JVM. A entrada é MST e álgebra alvo, a saída é uma instância de Expressão <T> .
A classe correspondente, AsmBuilder , e algumas outras extensões fornecem métodos para a construção obrigatória de bytecode sobre ObjectWeb ASM. Eles fazem a travessia do MST e a montagem da classe parecerem simples e ocupam menos de 40 linhas de código.
Considere a classe gerada para a expressão "2 * x" , o código-fonte Java descompilado do bytecode é mostrado:
package scientifik.kmath.asm.generated;
import java.util.Map;
import scientifik.kmath.asm.internal.MapIntrinsics;
import scientifik.kmath.expressions.Expression;
import scientifik.kmath.operations.RealField;
public final class AsmCompiledExpression_1073786867_0 implements Expression<Double> {
private final RealField algebra;
public final Double invoke(Map<String, ? extends Double> arguments) {
return (Double)this.algebra.add(((Double)MapIntrinsics.getOrFail(arguments, "x")).doubleValue(), 2.0D);
}
public AsmCompiledExpression_1073786867_0(RealField algebra) {
this.algebra = algebra;
}
}Primeiro, o método invoke foi gerado aqui , no qual os operandos foram organizados sequencialmente (uma vez que estão localizados mais profundamente na árvore), depois adicione . Após a chamada , o método de ponte correspondente foi registrado. Em seguida, o campo de álgebra e o construtor foram escritos . Em alguns casos, quando as constantes não podem ser simplesmente colocadas no pool de constantes de classe , o campo constantes , o array java.lang.Object , também é escrito .
No entanto, devido aos muitos casos extremos e otimizações, a implementação do gerador é bastante complicada.
Otimizando chamadas para Álgebra
Para chamar uma operação da álgebra, você precisa passar seu ID e argumentos:
RealField { binaryOperation("+", 1.0, 1.0) } // 2.0No entanto, essa chamada é cara em termos de desempenho: para escolher qual método chamar, o RealField executará uma instrução do switch de tabela relativamente cara e você também precisa se lembrar do boxe. Portanto, embora todas as operações MST possam ser representadas nesta forma, é melhor fazer uma chamada direta:
RealField { add(1.0, 1.0) } // 2.0Não existe uma convenção especial sobre o mapeamento de IDs de operação para métodos em implementações de Algebra <T> , então tivemos que inserir uma muleta na qual foi escrito manualmente que "+" , por exemplo, corresponde ao método add. Também há suporte para situações favoráveis quando você pode encontrar um método para um ID de operação com o mesmo nome, o número necessário de argumentos e seus tipos.
private val methodNameAdapters: Map<Pair<String, Int>, String> by lazy {
hashMapOf(
"+" to 2 to "add",
"*" to 2 to "multiply",
"/" to 2 to "divide",
...private fun <T> AsmBuilder<T>.findSpecific(context: Algebra<T>, name: String, parameterTypes: Array<MstType>): Method? =
context.javaClass.methods.find { method ->
...
nameValid && arityValid && notBridgeInPrimitive && paramsValid
}Outro grande problema é o boxe. Se olharmos as assinaturas do método Java que são obtidas após compilar o mesmo RealField, veremos dois métodos:
public Double add(double a, double b)
// $FF: synthetic method
// $FF: bridge method
public Object add(Object var1, Object var2)Claro, é mais fácil não se preocupar com boxing e unboxing e chamar o método bridge: ele apareceu aqui por causa do tipo erasure, a fim de implementar corretamente o método add (T, T): T , o tipo T no descritor do qual foi realmente apagado para java.lang .Objeto .
Chamar add diretamente de dois duplos também não é ideal, porque o valor de retorno é bauxita (há uma discussão sobre isso no YouTrack Kotlin ( KT-29460 ), mas é melhor chamá-lo para salvar dois casts de objetos de entrada em java.lang, na melhor das hipóteses .Number e seu unboxing para dobrar .
Demorou mais para resolver esse problema. A dificuldade aqui não está em criar chamadas para o método primitivo, mas no fato de que você precisa combinar na pilha os dois tipos primitivos (como double) e seus invólucros ( java.lang.Double , por exemplo) e inserir boxing nos lugares certos (por exemplo, java.lang.Double.valueOf ) e unboxing ( doubleValue ) - não havia absolutamente nenhuma necessidade de trabalhar com tipos de instrução em bytecode.
Tive ideias para pendurar minha abstração digitada em cima do bytecode. Para fazer isso, tive que me aprofundar na API ObjectWeb ASM. Acabei voltando para o back-end Kotlin / JVM, examinei a classe StackValue em detalhes(um fragmento digitado de bytecode, que em última análise leva à obtenção de algum valor na pilha de operandos), descobriu o utilitário Type , que permite operar convenientemente com os tipos disponíveis no bytecode (primitivos, objetos, arrays) e reescrever o gerador com seu uso. O problema de encaixotar ou desencaixotar o valor na pilha foi resolvido por si mesmo, adicionando um ArrayDeque que armazena os tipos que são esperados na próxima chamada.
internal fun loadNumeric(value: Number) {
if (expectationStack.peek() == NUMBER_TYPE) {
loadNumberConstant(value, true)
expectationStack.pop()
typeStack.push(NUMBER_TYPE)
} else ...?.number(value)?.let { loadTConstant(it) }
?: error(...)
}conclusões
No final, consegui fazer um gerador de código usando ObjectWeb ASM para avaliar expressões MST no KMath. O ganho de desempenho em uma passagem MST simples depende do número de nós, uma vez que o bytecode é linear e não perde tempo na seleção e recursão dos nós. Por exemplo, para uma expressão com 10 nós, a diferença de tempo entre a avaliação com a classe gerada e o interpretador é de 19 a 30%.
Depois de examinar os problemas que encontrei, tirei as seguintes conclusões:
- você precisa estudar imediatamente os recursos e utilitários do ASM - eles simplificam muito o desenvolvimento e tornam o código legível ( Type , InstructionAdapter , GeneratorAdapter );
- MaxStack , , — ClassWriter COMPUTE_MAXS COMPUTE_FRAMES;
- ;
- , , , ;
- , — , , ByteBuddy cglib.
Obrigado pela leitura.
Autores do artigo:
Yaroslav Sergeevich Postovalov , MBOU “Lyceum № 130 nomeado após Acadêmico Lavrentyev ”, membro do laboratório de modelagem matemática sob a liderança de Voytishek Anton Vatslavovich
Tatyana Abramova , pesquisador do laboratório de métodos de experimentos de física nuclear da JetBrains Research .