
Grandes problemas de textura
A ideia de renderizar texturas gigantes não é nova em si. Parece que o que poderia ser mais fácil - carregar uma textura enorme de um milhão de megapixels e desenhar um objeto com ela. Mas, como sempre, existem nuances:
- APIs de gráficos limitam o tamanho máximo de uma textura em largura e altura. Isso pode depender do hardware e dos drivers. O tamanho máximo para hoje é 32768x32768 pixels.
- Mesmo se atingirmos esses limites, a textura de 32768x32768 RGBA ocupará 4 gigabytes de memória de vídeo. A memória de vídeo é rápida, fica em um barramento largo, mas é relativamente cara. Portanto, geralmente é menos do que a memória do sistema e muito menos do que a memória do disco.
1. Renderização moderna de grandes texturas
Como a imagem não se encaixa nos limites, uma solução se sugere naturalmente - apenas quebre-a em pedaços (ladrilhos):

Várias variações dessa abordagem ainda são usadas para geometria analítica. Esta não é uma abordagem universal; requer cálculos não triviais na CPU. Cada bloco é desenhado como um objeto separado, o que adiciona sobrecarga e exclui a possibilidade de aplicação de filtragem de textura bilinear (haverá uma linha visível entre os limites do bloco). No entanto, a limitação do tamanho da textura pode ser contornada com matrizes de textura! Sim, esta textura ainda tem largura e altura limitadas, mas camadas adicionais apareceram. O número de camadas também é limitado, mas você pode contar com 2.048, embora a especificação do vulcão prometa apenas 256. Em uma placa de vídeo 1060 GTX, você pode criar uma textura contendo 32768 * 32768 * 2048 pixels. Simplesmente não será possível criá-lo, pois leva 8 terabytes e não há tanta memória de vídeo. Se você aplicar a ele o bloco de compressão de hardware BC1 , tal textura ocuparia "apenas" 1 terabyte. Ainda não cabe em uma placa de vídeo, mas direi o que fazer com ele posteriormente.
Portanto, ainda cortamos a imagem original em pedaços. Mas agora não será uma textura separada para cada ladrilho, mas apenas um pedaço dentro de uma enorme matriz de textura contendo todos os ladrilhos. Cada peça tem seu próprio índice, todas as peças são organizadas sequencialmente. Primeiro por colunas, depois por linhas e depois por camadas:
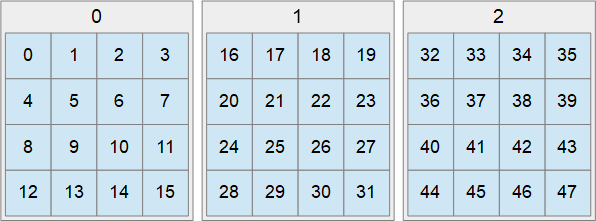
Uma pequena digressão sobre as fontes da textura de teste
Por exemplo - tirei uma imagem da Terra daqui . Aumentei seu tamanho original 43200x2160 para 65536x32768. Isso, é claro, não acrescentou detalhes, mas consegui a imagem de que precisava, que não cabe em uma camada de textura. Então eu o reduzi recursivamente pela metade com a filtragem bilinear, até obter um bloco de 512 por 256 pixels. Em seguida, bato as camadas resultantes em blocos de 512x256. Compactou-os BC1 e os gravou sequencialmente em um arquivo. Algo assim:
Como resultado, obtivemos um arquivo de 1.431.633.920 bytes, consistindo de 21845 blocos. O tamanho de 512 por 256 não é aleatório. Uma imagem compactada de 512 por 256 BC1 tem exatamente 65536 bytes, que é o tamanho do bloco da imagem esparsa - o herói deste artigo. O tamanho do bloco não é importante para a renderização.
Descrição da técnica de pintura de grandes texturas
Então, carregamos uma matriz de textura na qual os ladrilhos são colunas / linhas / camadas sequenciais.
Então, o sombreador que desenha essa mesma textura pode ter a seguinte aparência:
layout(set=0, binding=0) uniform sampler2DArray u_Texture;
layout(location = 0) in vec2 v_uv;
layout(location = 0) out vec4 out_Color;
int lodBase[8] = { 0, 1, 5, 21, 85, 341, 1365, 5461};
int tilesInWidth = 32768 / 512;
int tilesInHeight = 32768 / 256;
int tilesInLayer = tilesInWidth * tilesInHeight;
void main() {
float lod = log2(1.0f / (512.0f * dFdx(v_uv.x)));
int iLod = int(clamp(floor(lod),0,7));
int cellsSize = int(pow(2,iLod));
int tX = int(v_uv.x * cellsSize); //column index in current level of detail
int tY = int(v_uv.y * cellsSize); //row index in current level of detail
int tileID = lodBase[iLod] + tX + tY * cellsSize; //global tile index
int layer = tileID / tilesInLayer;
int row = (tileID % tilesInLayer) / tilesInWidth;
int column = (tileID % tilesInWidth);
vec2 inTileUV = fract(v_uv * cellsSize);
vec2 duv = (inTileUV + vec2(column,row)) / vec2(tilesInWidth,tilesInHeight);
out_Color = texelFetch(u_Texture,ivec3(duv * textureSize(u_Texture,0).xy,layer),0);
}
Vamos dar uma olhada neste shader. Em primeiro lugar, precisamos determinar que nível de detalhe escolher. A maravilhosa função dFdx nos ajudará com isso . Para simplificar bastante, ele retorna o valor pelo qual o atributo passado é maior no pixel vizinho. Na demonstração, desenho um retângulo plano com coordenadas de textura no intervalo 0..1. Quando este retângulo tiver X pixels de largura, dFdx (v_uv.x) retornará 1 / X. Assim, o bloco do primeiro nível cairá pixel a pixel com dFdx == 1/512. A segunda em 1/1024, a terceira em 01/2048, etc. O nível de detalhe em si pode ser calculado da seguinte forma: log2 (1.0f / (512.0f * dFdx (v_uv.x))). Vamos cortar a parte fracionária disso. Em seguida, contamos quantas peças estão em largura / altura no nível.
Vamos considerar o cálculo do resto usando um exemplo:

aqui lod = 2, u = 0,65, v = 0,37
já que lod é igual a dois, então cellsSize é igual a quatro. A imagem mostra que este nível consiste em 16 peças (4 linhas 4 colunas) - tudo está correto.
tX = int (0,65 * 4) = int (2,6) = 2
tY = int (0,37 * 4) = int (1,48) = 1,
ou seja, dentro do nível, este bloco está na terceira coluna e na segunda linha (indexação do zero).
Também precisamos das coordenadas locais do fragmento (setas amarelas na imagem). Eles podem ser facilmente calculados simplesmente multiplicando as coordenadas da textura original pelo número de células em uma linha / coluna e pegando a parte fracionária. Nos cálculos acima, eles já estão lá - 0,6 e 0,48.
Agora precisamos de um índice global para este bloco. Para isso, uso o array pré-calculado lodBase. Nele, por índice, são armazenados os valores de quantos tiles estavam em todos os níveis anteriores (menores). Adicione a ele o índice local da telha dentro do nível. Por exemplo, resulta lodBase [2] + 1 * 4 + 2 = 5 + 4 + 2 = 11. O que também está correto.
Conhecendo o índice global, agora precisamos encontrar as coordenadas do bloco em nossa matriz de textura. Para fazer isso, precisamos saber quantas peças temos em largura e altura. Seu produto é quantos ladrilhos cabem na camada. Neste exemplo, costurei essas constantes no código do sombreador, para simplificar. Em seguida, pegamos as coordenadas de textura e lemos o texel delas. Observe que sampler2DArray é usado como um amostrador . Portanto, texelFetch passamos um vetor de três componentes, na terceira coordenada - o número da camada.
Texturas não totalmente carregadas (imagens de residência parcial)
Como escrevi acima, texturas enormes consomem muita memória de vídeo. Além disso, um número muito pequeno de pixels é usado a partir dessa textura. A solução para o problema - Texturas de Residência Parcial surgiu em 2011. Sua essência é resumida - o ladrilho pode não estar fisicamente na memória! Ao mesmo tempo, a especificação garante que o aplicativo não trave, e todas as implementações conhecidas garantem que zeros sejam retornados. Além disso, a especificação garante que, se a extensão for suportada, o tamanho do bloco garantido em bytes será suportado - 64 kibytes. As resoluções dos blocos de construção na textura estão vinculadas a este tamanho:
| TAMANHO DO TEXEL (bits) | Forma do bloco (2D) | Forma do bloco (3D) |
|---|---|---|
| ? 4 bits? | ? 512 × 256 × 1 | não suporta |
| 8 bits | 256 × 256 × 1 | 64 × 32 × 32 |
| 16 bits | 256 × 128 × 1 | 32 × 32 × 32 |
| 32 bits | 128 × 128 × 1 | 32 × 32 × 16 |
| 64 bits | 128 × 64 × 1 | 32 × 16 × 16 |
| 128 bits | 64 × 64 × 1 | 16 × 16 × 16 |
Na verdade, não há nada na especificação sobre texels de 4 bits, mas sempre podemos descobrir sobre eles usando vkGetPhysicalDeviceSparseImageFormatProperties .
VkSparseImageFormatProperties sparseProps;
ermy::u32 propsNum = 1;
vkGetPhysicalDeviceSparseImageFormatProperties(hphysicalDevice, VK_FORMAT_BC1_RGB_SRGB_BLOCK, VkImageType::VK_IMAGE_TYPE_2D,
VkSampleCountFlagBits::VK_SAMPLE_COUNT_1_BIT, VkImageUsageFlagBits::VK_IMAGE_USAGE_SAMPLED_BIT | VkImageUsageFlagBits::VK_IMAGE_USAGE_TRANSFER_DST_BIT
, VkImageTiling::VK_IMAGE_TILING_OPTIMAL, &propsNum, &sparseProps);
int pageWidth = sparseProps.imageGranularity.width;
int pageHeight = sparseProps.imageGranularity.height;
A criação de uma textura tão esparsa é diferente da usual.
Primeiramente em VkImageCreateInfo em sinalizadores deve ser especificado VK_IMAGE_CREATE_SPARSE_BINDING_BIT e VK_IMAGE_CREATE_SPARSE_RESIDENCY_BIT
Em segundo lugar, amarrando via memória vkBindImageMemory não é necessário.
Você precisa descobrir quais tipos de memória podem ser usados por meio de vkGetImageMemoryRequirements . Também dirá quanta memória é necessária para carregar a textura inteira, mas não precisamos dessa figura.
Em vez disso, precisamos decidir no nível do aplicativo quantos blocos podem ser visíveis simultaneamente?
Depois de carregar alguns tiles, outros serão descarregados, pois não são mais necessários. Na demonstração, eu apenas apontei meu dedo para o céu e aloquei memória para mil e vinte e quatro blocos. Parece um desperdício, mas tem apenas 50 megabytes contra 1,4 GB de uma textura totalmente carregada. Você também precisa alocar memória no host, para teste - um buffer.
const int sparseBlockSize = 65536;
int numHotPages = 512; //
VkMemoryRequirements memReqsOpaque;
vkGetImageMemoryRequirements(device, mySparseImage, &memReqsOpaque); // memoryTypeBits. -
VkMemoryRequirements image_memory_requirements;
image_memory_requirements.alignment = sparseBlockSize ; //
image_memory_requirements.size = sparseBlockSize * numHotPages;
image_memory_requirements.memoryTypeBits = memReqsOpaque.memoryTypeBits;
Assim teremos uma textura enorme na qual apenas algumas partes serão carregadas. Vai parecer algo assim:

Gestão de ladrilhos
A seguir, usarei o termo bloco para denotar uma peça de textura (quadrados verdes escuros e cinza na figura) e o termo página para denotar uma peça em um grande bloco pré-alocado na memória de vídeo (retângulos verde claro e azul claro na figura).
Depois de criar um VkImage esparso , ele pode ser usado por meio do VkImageView no shader. Claro, isso será inútil - a amostragem retornará zeros, não há nenhum dado, mas ao contrário do VkImage usual , nada cairá e as camadas de depuração não irão comprometer. Os dados nesta textura precisarão ser não apenas carregados, mas também descarregados, uma vez que economizamos memória de vídeo.
A abordagem OpenGL, que prevê a alocação de memória pelo driver para cada bloco, não me parece correta. Sim, talvez algum alocador inteligente e rápido seja usado lá, porque o tamanho do bloco é fixo. Isso também é sugerido pelo fato de que uma abordagem semelhante é usada no exemplo de texturas residenciais esparsas em um vulcão. Mas, em qualquer caso, selecione um grande bloco linear de páginas e, no lado do aplicativo, vincule essas páginas a blocos de textura específicos e preencha-os com dados definitivamente não será mais lento.
Assim, a interface de nossa textura esparsa incluirá métodos como:
void CommitTile(int tileID, void* dataPtr); // 64
void FreeTile(int tileID);
void Flush();
O último método é necessário para agrupar o enchimento / liberação dos ladrilhos. Atualizar blocos um de cada vez é muito caro, apenas uma vez por quadro. Vamos examiná-los em ordem.
//void CommitTile(int tileID, void* dataPtr)
int freePageID = _getFreePageID();
if (freePageID != -1)
{
tilesByPageIndex[freePageID] = tileID;
tilesByTileID[tileID] = freePageID;
memcpy(stagingPtr + freePageID * pageDataSize, tileData, pageDataSize);
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = optimalTilingMem;
mbind.memoryOffset = freePageID * pageDataSize;
mbind.flags = 0;
memoryBinds.push_back(mbind);
VkBufferImageCopy copyRegion;
copyRegion.bufferImageHeight = pageHeight;
copyRegion.bufferRowLength = pageWidth;
copyRegion.bufferOffset = mbind.memoryOffset;
copyRegion.imageExtent.depth = 1;
copyRegion.imageExtent.width = pageWidth;
copyRegion.imageExtent.height = pageHeight;
copyRegion.imageOffset.x = mbind.offset.x;
copyRegion.imageOffset.y = mbind.offset.y;
copyRegion.imageOffset.z = 0;
copyRegion.imageSubresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
copyRegion.imageSubresource.baseArrayLayer = layer;
copyRegion.imageSubresource.layerCount = 1;
copyRegion.imageSubresource.mipLevel = 0;
copyRegions.push_back(copyRegion);
return true;
}
return false;
Primeiro, precisamos encontrar um bloco livre. Eu simplesmente percorro a matriz dessas mesmas páginas e procuro a primeira, que contém o esboço número -1. Este será o índice da página gratuita. Eu copio os dados do disco para o buffer temporário usando memcpy. A origem é um arquivo mapeado na memória com um deslocamento para um bloco específico. Além disso, pelo ID do bloco, considero sua posição (x, y, camada) na matriz de textura.
Em seguida, começa a coisa mais interessante - preencher a estrutura VkSparseImageMemoryBind . É ela quem liga a memória do vídeo ao azulejo. Seus campos importantes são:
memória . Este é um objeto VkDeviceMemory . É pré-alocado memória para todas as páginas.
memoryOffset . Este é o deslocamento em bytes da página de que precisamos.
Em seguida, precisaremos copiar os dados do buffer temporário para essa memória recém-ligada. Isso é feito usando vkCmdCopyBufferToImage .
Como copiaremos muitas seções de uma vez, neste local apenas preencheremos a estrutura, com uma descrição de onde e onde copiaremos. Aqui, bufferOffset é importante , o que indica o deslocamento já no buffer de preparação. Nesse caso, coincide com o deslocamento na memória de vídeo, mas as estratégias podem ser diferentes. Por exemplo, divida os ladrilhos em quentes, quentes e frios. Os quentes estão na memória de vídeo, os quentes estão na RAM e os frios estão no disco. Então, o buffer de teste pode ser maior e o deslocamento será diferente.
//void FreeTile(int tileID)
if (tilesByTileID.count(tileID) > 0)
{
i16 hotPageID = tilesByTileID[tileID];
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.memory = optimalTilingMem;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = VK_NULL_HANDLE;
mbind.memoryOffset = 0;
mbind.flags = 0;
memoryBinds.push_back(mbind);
tilesByPageIndex[hotPageID] = -1;
tilesByTileID.erase(tileID);
return true;
}
return false;
É aqui que separamos a memória do ladrilho. Para fazer isso, atribua a memória VK_NULL_HANDLE .
//void Flush();
cbuff = hostDevice->CreateOneTimeSubmitCommandBuffer();
VkImageSubresourceRange imageSubresourceRange;
imageSubresourceRange.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
imageSubresourceRange.baseMipLevel = 0;
imageSubresourceRange.levelCount = 1;
imageSubresourceRange.baseArrayLayer = 0;
imageSubresourceRange.layerCount = numLayers;
VkImageMemoryBarrier bSamplerToTransfer;
bSamplerToTransfer.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bSamplerToTransfer.pNext = nullptr;
bSamplerToTransfer.srcAccessMask = 0;
bSamplerToTransfer.dstAccessMask = VK_ACCESS_TRANSFER_WRITE_BIT;
bSamplerToTransfer.oldLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bSamplerToTransfer.newLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bSamplerToTransfer.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.image = opaqueImage;
bSamplerToTransfer.subresourceRange = imageSubresourceRange;
VkSparseImageMemoryBindInfo imgBindInfo;
imgBindInfo.image = opaqueImage;
imgBindInfo.bindCount = memoryBinds.size();
imgBindInfo.pBinds = memoryBinds.data();
VkBindSparseInfo sparseInfo;
sparseInfo.sType = VK_STRUCTURE_TYPE_BIND_SPARSE_INFO;
sparseInfo.pNext = nullptr;
sparseInfo.waitSemaphoreCount = 0;
sparseInfo.pWaitSemaphores = nullptr;
sparseInfo.bufferBindCount = 0;
sparseInfo.pBufferBinds = nullptr;
sparseInfo.imageOpaqueBindCount = 0;
sparseInfo.pImageOpaqueBinds = nullptr;
sparseInfo.imageBindCount = 1;
sparseInfo.pImageBinds = &imgBindInfo;
sparseInfo.signalSemaphoreCount = 0;
sparseInfo.pSignalSemaphores = nullptr;
VkImageMemoryBarrier bTransferToSampler;
bTransferToSampler.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bTransferToSampler.pNext = nullptr;
bTransferToSampler.srcAccessMask = 0;
bTransferToSampler.dstAccessMask = VK_ACCESS_SHADER_READ_BIT;
bTransferToSampler.oldLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bTransferToSampler.newLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bTransferToSampler.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.image = opaqueImage;
bTransferToSampler.subresourceRange = imageSubresourceRange;
vkQueueBindSparse(graphicsQueue, 1, &sparseInfo, fence);
vkWaitForFences(device, 1, &fence, true, UINT64_MAX);
vkResetFences(device, 1, &fence);
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, VK_PIPELINE_STAGE_TRANSFER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bSamplerToTransfer);
if (copyRegions.size() > 0)
{
vkCmdCopyBufferToImage(cbuff, stagingBuffer, opaqueImage, VkImageLayout::VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL, copyRegions.size(), copyRegions.data());
}
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TRANSFER_BIT, VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bTransferToSampler);
hostDevice->ExecuteCommandBuffer(cbuff);
copyRegions.clear();
memoryBinds.clear();
O trabalho principal ocorre neste método. No momento da sua chamada, já temos dois arrays com VkSparseImageMemoryBind e VkBufferImageCopy. Preenchemos as estruturas para chamar vkQueueBindSparse e chamamos. Esta não é uma função de bloqueio (como quase todas as funções do Vulkan), portanto, precisaremos esperar explicitamente que ela seja executada. Para isso, o último parâmetro é passado ao VkFence , cuja execução iremos aguardar. Na verdade, no meu caso, esperar por essa cerca não afetou de forma alguma o desempenho do programa. Mas, em teoria, é necessário aqui.
Depois de anexarmos memória aos ladrilhos, precisamos preencher as imagens neles. Isso é feito com a função vkCmdCopyBufferToImage .
Você pode preencher os dados na textura com layoutVK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL , e obtê-los em um shader com layout VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL . Portanto, precisamos de duas barreiras. Observe que em VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL traduzimos estritamente de VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL , não de VK_IMAGE_LAYOUT_UNDEFINED . Como estamos preenchendo apenas parte da textura, é importante não perdermos as partes preenchidas anteriormente.
Aqui está um vídeo de como isso funciona. Uma textura. Um objeto. Dezenas de milhares de ladrilhos.
O que permanece nos bastidores é como determinar no aplicativo como realmente descobrir qual bloco é o momento de fazer o download e o que descarregar. Na seção que descreve os benefícios da nova abordagem, um dos pontos é que você pode usar geometria complexa. No mesmo teste, eu mesmo uso a projeção ortográfica e o retângulo mais simples. E eu conto o id dos tiles analiticamente. Antidesportivo.
Na verdade, os ids de blocos visíveis são contados duas vezes. Analiticamente na CPU e honestamente no shader de fragmento. Ao que parece, por que não retirá-los do sombreador de fragmento? Mas não é tão simples. Este será o segundo artigo.