Para a genética do trigo, uma tarefa importante é determinar a ploidia (o número de conjuntos idênticos de cromossomos localizados no núcleo da célula). A abordagem clássica para resolver esse problema é baseada no uso de métodos de genética molecular, que são caros e trabalhosos. A determinação dos tipos de planta só é possível em condições de laboratório. Portanto, neste trabalho, testamos a hipótese: é possível determinar a ploidia do trigo por métodos de visão computacional, apenas com base na imagem de uma orelha.

descrição de dados
Para resolver o problema, antes mesmo do início do workshop, foi elaborado um conjunto de dados em que a ploidia era conhecida para cada espécie de planta. No total, tínhamos 2344 fotografias de hexaplóides e 1259 tetrapróides à nossa disposição.
A maioria das plantas foi fotografada por meio de dois protocolos. O primeiro caso - em uma mesa em uma projeção, o segundo - em um prendedor de roupa em 4 projeções. As fotografias sempre tiveram uma paleta de cores verificadora de cores , necessária para normalizar as cores e determinar a escala.

Um total de 3603 fotos com 644 números originais de sementes. O conjunto de dados contém 20 espécies de trigo: 10 hexaplóides, 10 tetraplóides; 496 genótipos únicos; 10 vegetação única. As plantas foram cultivadas entre 2015 e 2018 em estufasICG SB RAS . O material biológico foi fornecido pelo Acadêmico Nikolai Petrovich Goncharov .
Validação
Uma planta em nosso conjunto de dados pode corresponder a até 5 fotografias tiradas usando diferentes protocolos e em diferentes projeções. Dividimos os dados em 3 conjuntos estratificados: treinar (amostra de treinamento), válido (amostra de validação) e segurar (amostra atrasada), em proporções de 60%, 20% e 20%, respectivamente. Na divisão, levamos em consideração que todas as fotografias de um determinado genótipo sempre apareceriam em uma subamostra. Este esquema de validação foi usado para todos os modelos treinados.
Tentando métodos clássicos de CV e ML
A primeira abordagem que usamos para resolver o problema é baseada no algoritmo existente que desenvolvemos anteriormente. O algoritmo permite extrair um conjunto fixo de diferentes características quantitativas de cada imagem. Por exemplo, o comprimento da orelha, a área dos toldos , etc. Para obter uma descrição detalhada do algoritmo, consulte Genaev et al., Morphometry of the Wheat Spike by Analyzing 2D Images, 2019 . Usando esse algoritmo e métodos de aprendizado de máquina, treinamos vários modelos para prever os tipos de ploidia.
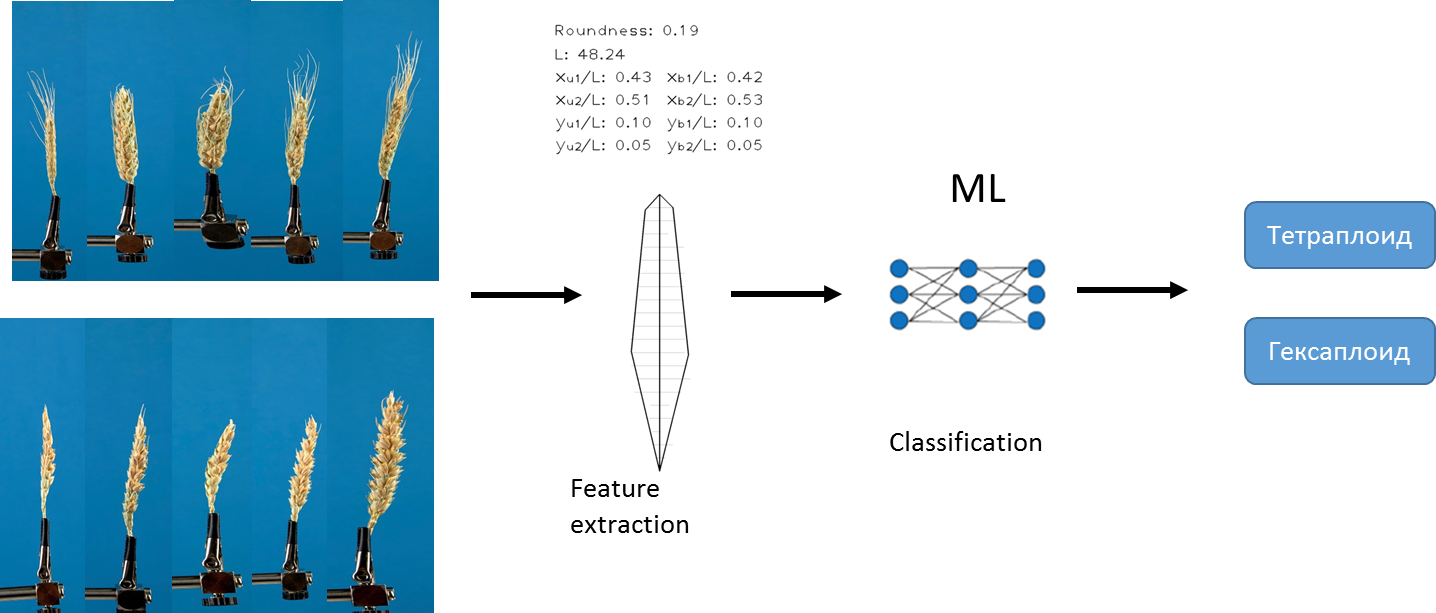
Usamos métodos de regressão logística , floresta aleatória e aumento de gradiente . Os dados foram pré- normalizados... Escolhemos a AUC como medida de precisão .
| Método | Trem | Válido | Holdout |
| Regressão Logística | 0,77 | 0,70 | 0,72 |
| Floresta aleatória | 1,00 | 0,83 | 0,82 |
| Boosting | 0,99 | 0,83 | 0,85 |
A melhor precisão na amostragem diferida foi mostrada pelo método de aumento de gradiente; usamos a implementação CatBoost.
Interpretando os resultados
Para cada modelo, recebemos uma estimativa da "importância" de cada característica. Como resultado, obtivemos uma lista de todas as nossas características, classificadas por significância e selecionamos as 10 principais características: Área de Awns, Índice de circularidade, Arredondamento, Perímetro, Comprimento da haste, xu2, L, xb2, yu2, ybm. (uma descrição de cada recurso pode ser encontrada aqui ).
Um exemplo de características importantes é o comprimento e o perímetro da orelha. As distribuições dos valores dessas características em tetraplóides e hexaplóides são mostradas nos histogramas. Pode ser visto que a distribuição para hexaplóides é deslocada para valores mais altos.

Nós agrupamos os 10 principais recursos usando o método t-SNE
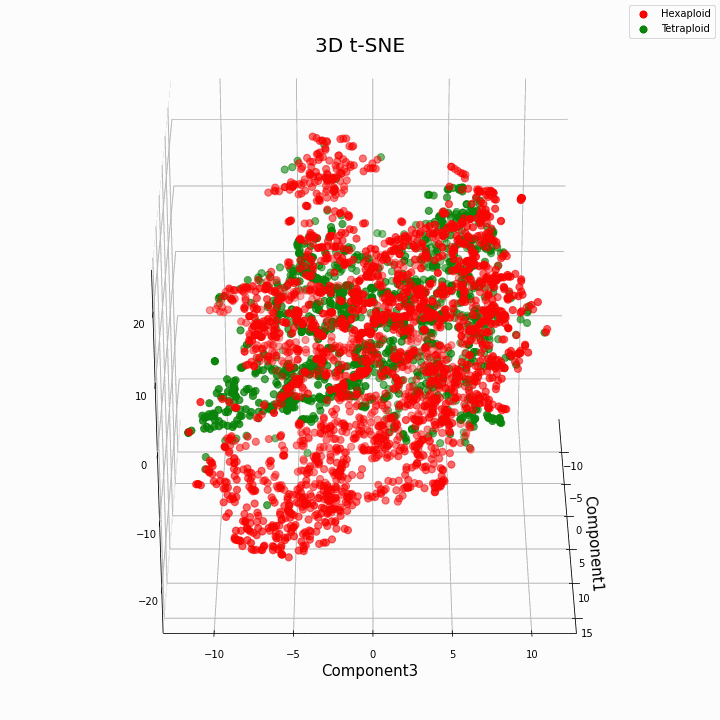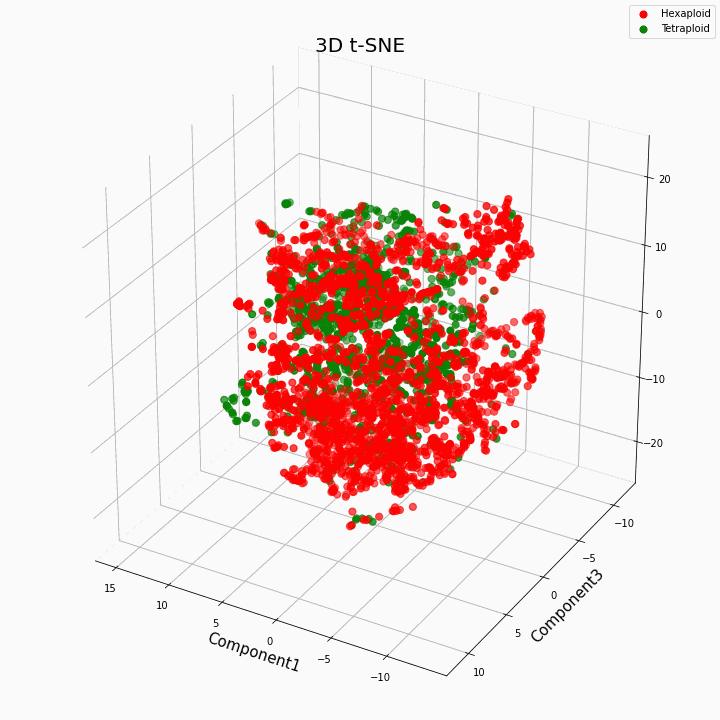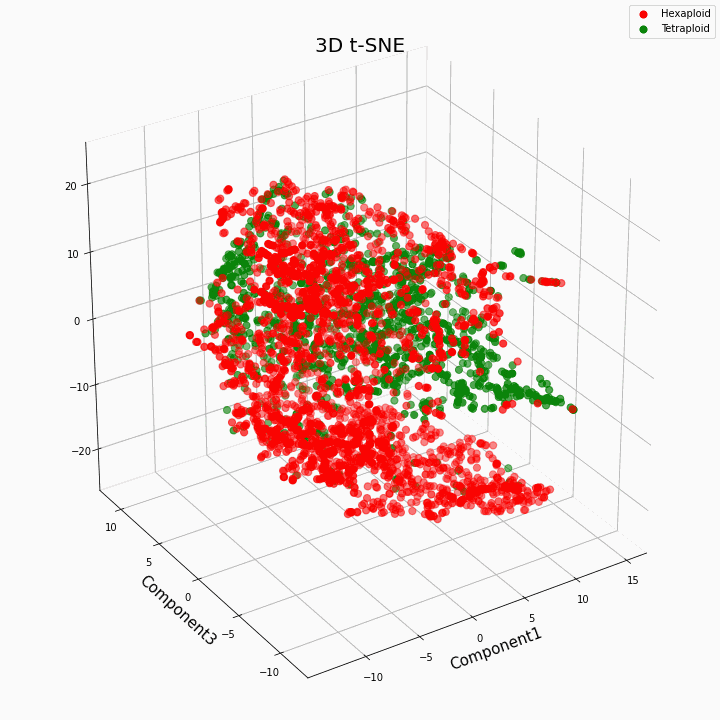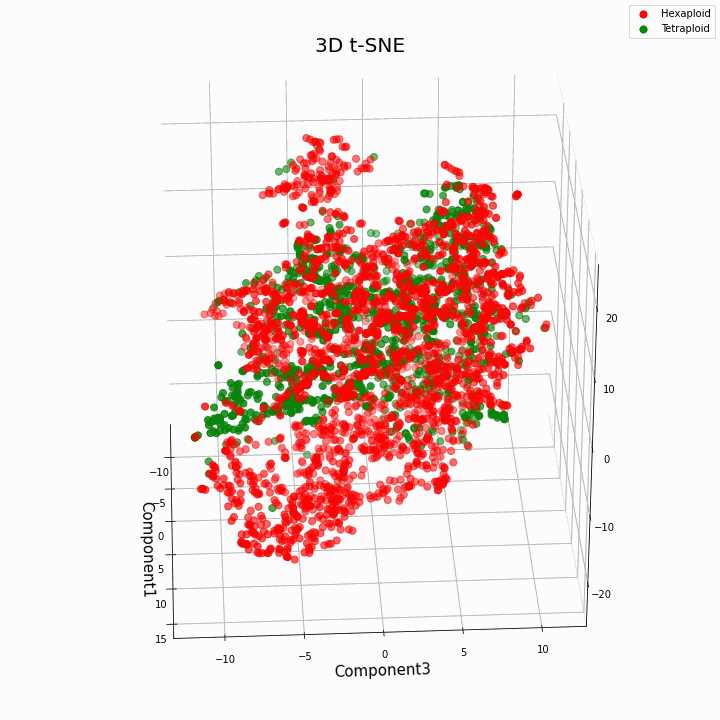
Em geral, maior ploidia fornece valores de características mais variáveis. Para hexaplóides, uma maior dispersão / variância dos valores da característica é característica. Isso porque o número de cópias de genes em hexaplóides é maior e, portanto, o número de variantes de "trabalho" desses genes aumenta.
Para confirmar nossa hipótese de maior variabilidade fenotípica em hexaplóides, aplicamos a estatística F. A estatística F fornece a significância das diferenças nas variâncias de duas distribuições. Consideramos os casos em que o valor de p é menor que 0,05 para refutar a hipótese nula de que não há diferenças entre as duas distribuições. Executamos este teste independentemente para cada característica. Condições de teste: deve haver uma amostra de observações independentes (no caso de várias imagens, não é o caso) e distribuições normais. Para cumprir essas condições, testamos uma imagem de cada orelha. Eles tiraram fotos em apenas uma projeção de acordo com o protocolo “sobre a mesa”. Os resultados são apresentados na tabela. Pode-se observar que a variância para hexaplóides e tetraplóides apresenta diferenças significativas para 7 caracteres. Além disso, em todos os casos, o valor da dispersão é maior nos hexaplóides.A maior variabilidade fenotípica em hexaplóides pode ser explicada pelo grande número de cópias de um gene.
| Name | F-statistic | p-value | Disp Hexaploid | Disp Tetraploid |
| Awns area | 0.376 | 1.000 | 1.415 | 3.763 |
| Circularity index | 1.188 | 0.065 | 0.959 | 0.807 |
| Roundness | 1.828 | 0.000 | 1.312 | 0.718 |
| Perimeter | 1.570 | 0.000 | 1.080 | 0.688 |
| Stem length | 3.500 | 0.000 | 1.320 | 0.377 |
| xu2 | 3.928 | 0.000 | 1.336 | 0.340 |
| L | 3.500 | 0.000 | 1.320 | 0.377 |
| xb2 | 4.437 | 0.000 | 1.331 | 0.300 |
| yu2 | 4.275 | 0.000 | 2.491 | 0.583 |
| ybm | 1.081 | 0.248 | 0.695 | 0.643 |
Nossos dados incluem 20 espécies de plantas. 10 trigo hexaplóide e 10 tetraplóide.
Colorimos os resultados do agrupamento de forma que a cor + forma de cada ponto corresponda a uma visualização específica.

A maioria das espécies ocupa áreas bastante compactas na carta. Embora essas áreas possam se sobrepor muito a outras. Por outro lado, dentro de uma espécie pode haver clusters claramente definidos, por exemplo, para T compactum, T petropavlovskyi.
Calculamos a média dos valores de cada espécie para 10 características, obtendo uma tabela de 20 por 10. Onde cada uma das 20 espécies corresponde a um vetor de 10 características. Para esses dados, foi construída uma matriz de correlação e realizada a análise de agrupamento hierárquico. Os quadrados azuis no gráfico correspondem a tetraplóides.

Na árvore construída, em geral, as espécies de trigo foram divididas em tetraplóides e hexaplóides. As espécies hexaplóides foram claramente divididas em dois grupos: de pêlo médio - T. macha, T. aestivum, T. yunnanense e de pêlo comprido - T. vavilovii, T. petropavlovskyi, T. spelta. A única exceção é que a única espécie selvagem poliplóide (tetraplóide) T. dicoccoides foi classificada como hexaplóide.
Ao mesmo tempo, as espécies tetraplóides incluíam o trigo hexaplóide com um tipo de espiga compacta - T. compactum, T. antiquorum e T. sphaerococcum, e a linhagem isogênica artificial ANK-23 de trigo comum.
Tentando CNN

Para resolver o problema de determinação da ploidia do trigo a partir da imagem de uma espiga, treinamos uma rede neural convolucional da arquitetura EfficientNet B0 com pesos pré-treinados no ImageNet. CrossEntropyLoss foi usado como uma função de perda; Otimizador de Adam; o tamanho de um lote é 16; as imagens foram redimensionadas para 224x224; a taxa de aprendizagem foi alterada de acordo com a estratégia fit_one_cycle com um lr inicial = 1e-4. Treinamos a rede por 10 épocas, aplicando os seguintes aumentos aleatoriamente: rotações de -20 +20 graus, alterando o brilho, contraste, saturação, espelhamento. O melhor modelo foi escolhido de acordo com a métrica AUC , cujo valor foi calculado ao final de cada época.
Como resultado, a precisão na amostra diferida AUC = 0,995 , que corresponde à precisão_score= 0,987 e um erro de 1,3%. O que é um resultado muito bom.
Conclusão
Este trabalho é um bom exemplo de como uma equipe de 5 alunos e 2 curadores pode resolver um problema biológico urgente e obter novos resultados científicos em poucas semanas.
Gostaria de expressar minha gratidão a todos os participantes de nosso projeto: Nikita Prokhoshin , Alexei Prikhodko , Evgeny Zavarzin , Artem Pronozin , Anna Paulish , Evgeny Komyshev, Mikhail Genaev .
Koval Vasily Sergeevich e Kruchinina Yulia Vladimirovna por atirar em espigas de milho.
Nikolai Petrovich Goncharov e Afonnikov Dmitry Arkadyevich pelo material biológico fornecido e ajuda na interpretação dos resultados.
Ao Centro de Matemática da Universidade Estadual de Novosibirsk e ao Instituto de Citologia e Genética da SB RAS pela organização do evento e pelo poder computacional.

PS Estamos planejando preparar a segunda parte do artigo, onde falaremos sobre a segmentação da espiga e a seleção de espigas individuais.