Olá! Nós - cientistas do laboratório de aprendizado de máquina da ITMO e a equipe principal de ML no VKontakte - estamos fazendo pesquisas conjuntas. Uma das tarefas importantes do VK é a classificação automática das postagens: é necessário não só gerar feeds temáticos, mas também identificar conteúdos indesejados. Os avaliadores estão envolvidos nesse processamento de registros. Ao mesmo tempo, o custo de seu trabalho pode ser reduzido significativamente usando um paradigma de aprendizado de máquina como o aprendizado ativo.
É sobre sua aplicação para a classificação de dados multimodais que será discutida neste artigo. Vamos falar sobre os princípios gerais e métodos de aprendizagem ativa, as peculiaridades de sua aplicação à tarefa, bem como os insights obtidos durante a pesquisa.

Introdução
— machine learning, . , , , .
, (, Amazon Mechanical Turk, .) . — reCAPTCHA, , , , — Google Street View. — .
Amazon DALC (Deep Active Learning from targeted Crowds). , . Monte Carlo Dropout ( ). — noisy annotation. , « , », .
Amazon . : / . , , . , : , . .
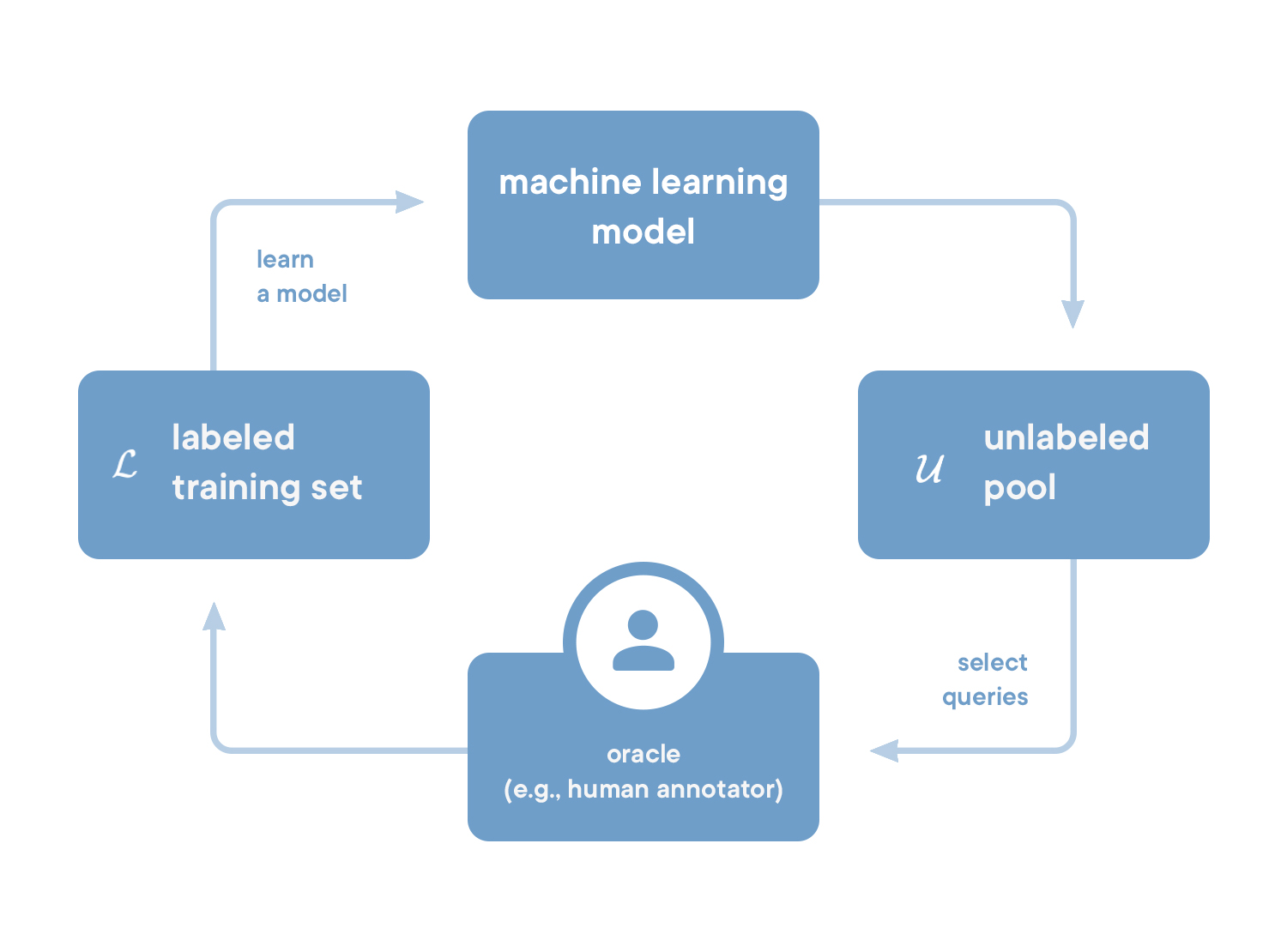
. 1. pool-based
. , , ( ). : , .
, — . (. — query). , . ( , ) .
, , .
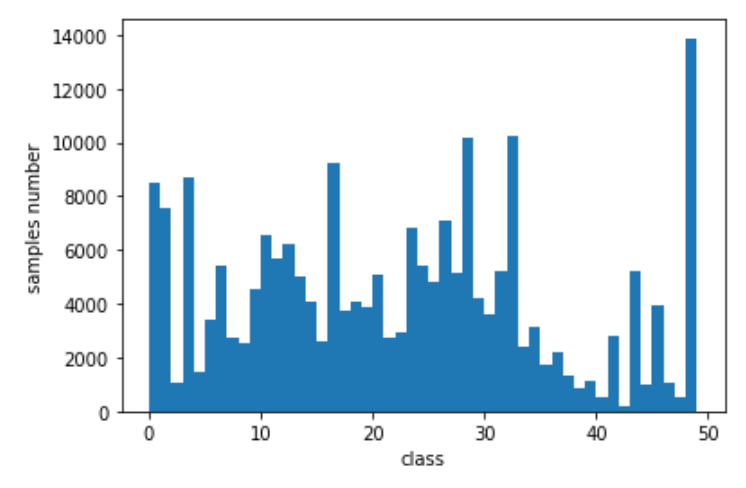
, — . ( ). ≈250 . . () 50 — — :
- , (. embedding), ;
- .
, (. . 2).
. 2 —
ML — . , .
. , . , , , . , , early stopping. , .
. residual , highway , (. encoder). , (. fusion): , .
— , . -.
, — , . , .
. , (. 3):
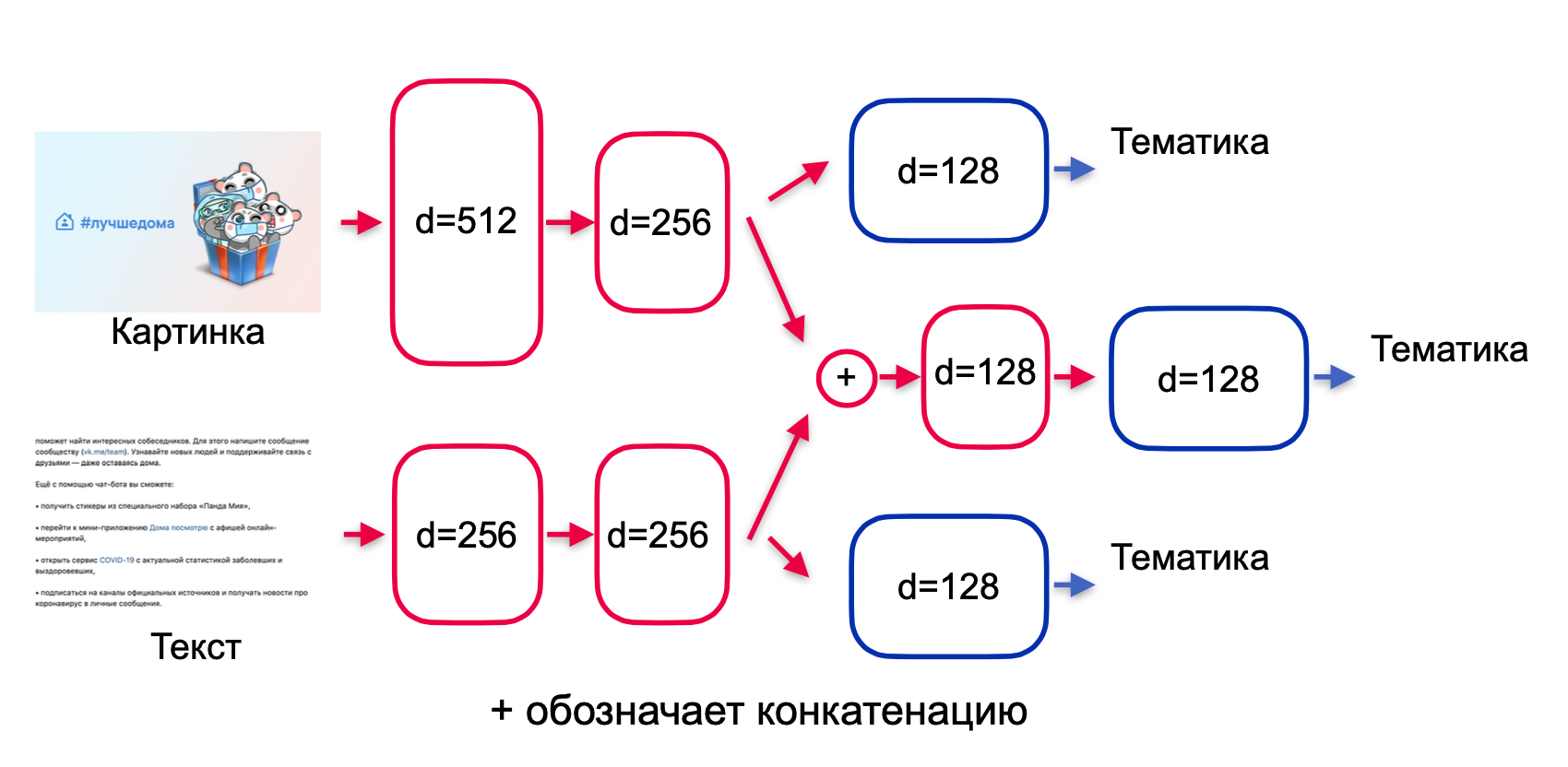
. 3.
. , . , , . , ( + ) — .
, . 3, :
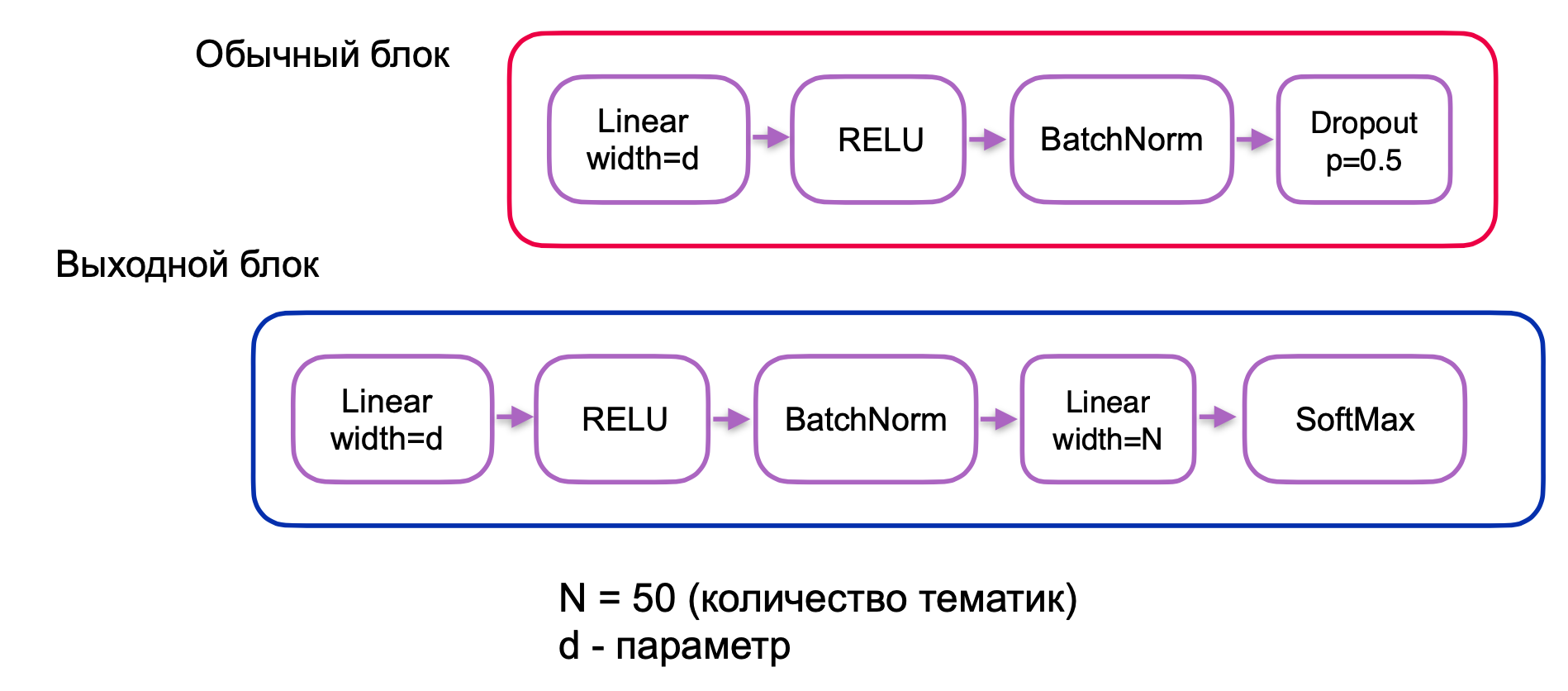
. 4.
, , . , ó , , .
, : ? :
- ;
- ;
- .
. : maximum likelihood , - . :
— ( -), — , .
Pool-based sampling
— , . pool-based sampling :
- - .
- .
- , , .
- .
- ( ).
- 3–5 (, ).
, 3–6 — .
, , :
, . , : . , , , . . , 2 000.
. , . ( ). , , . , . 20 .
. , . — , . 100 200.
, , , .
№1: batch size
baseline , ( ) (. 5).
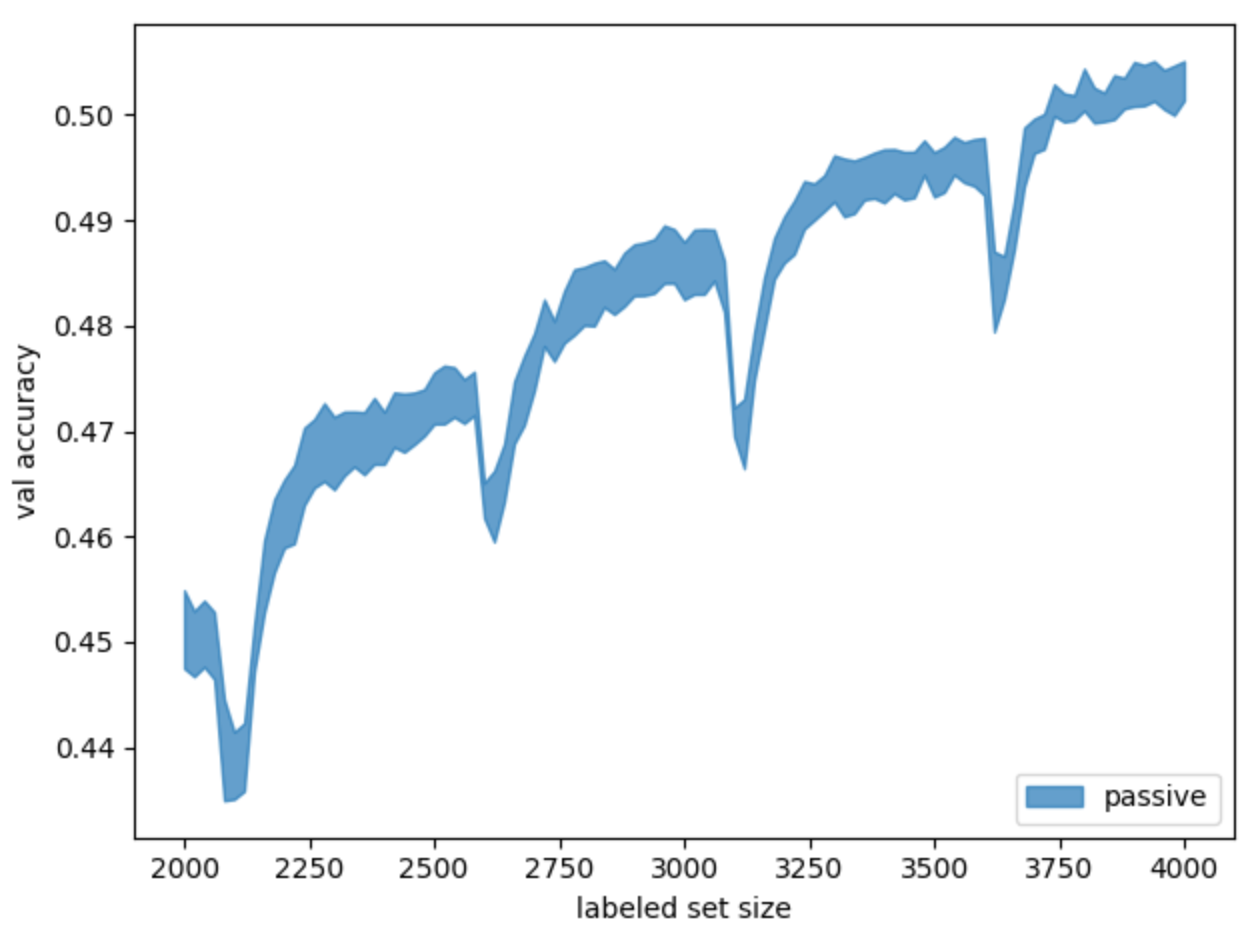
. 5. baseline- .
random state. .
. «» , , .
, (. batch size). 512 — - (50). , batch size . . :
- upsample, ;
- , .
batch size: (1).
— batch size, — .
“” (. 6).

. 6. batch size (passive ) (passive + flexible )
: c . , , batch size . .
.
Uncertainty
:
1. (. Least confident sampling)
, :
— , — , — , — , .
Esta medida pode ser entendida da seguinte forma. Digamos que a função de perda de objetos pareça... Nesse caso, o modelo escolhe um objeto onde receberá a pior estimativa do valor da função de perda. Ela aprende sobre isso e, portanto, reduz o valor da função de perda.
. , : {0,5; 0,49; 0,01}, — {0,49; 0,255; 0,255}. , (0,49) , (0,5). , ó : . , .
2. (. Margin sampling)
, , , :
— , — .
, . , . , , MNIST ( ) — , . .
3. (. Entropy sampling)
:
— - .
, , . :
- , , ;
- , .
(. 7).
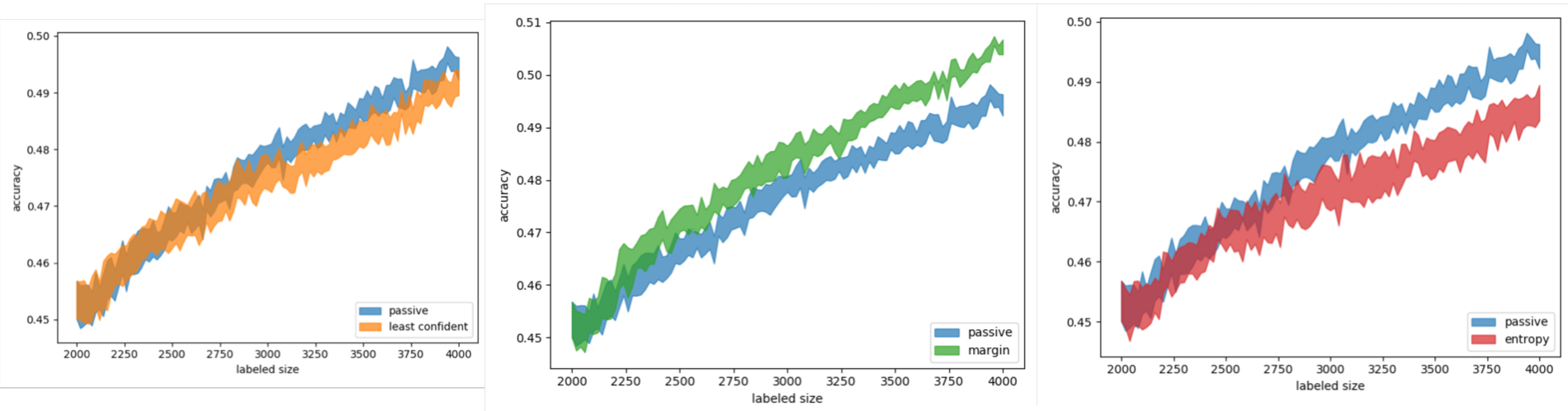
. 7. uncertainty sampling ( — , — , — )
, least confident entropy sampling , . margin sampling .
, , : MNIST. , , entropy sampling , . , .
. , — , — . , .
BALD
, , — BALD sampling (Bayesian Active Learning by Disagreement). .
, query-by-committee (QBC). — . uncertainty sampling. , . QBC Monte Carlo Dropout, .
, , — . dropout . dropout , ( ). , dropout- (. 8). Monte Carlo Dropout (MC Dropout) . , . ( dropout) Mutual Information (MI). MI , , — , . .
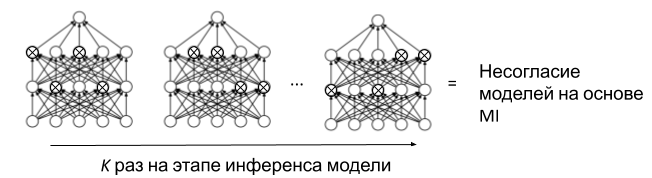
. 8. MC Dropout BALD
, QBC MC Dropout uncertainty sampling. , (. 9).
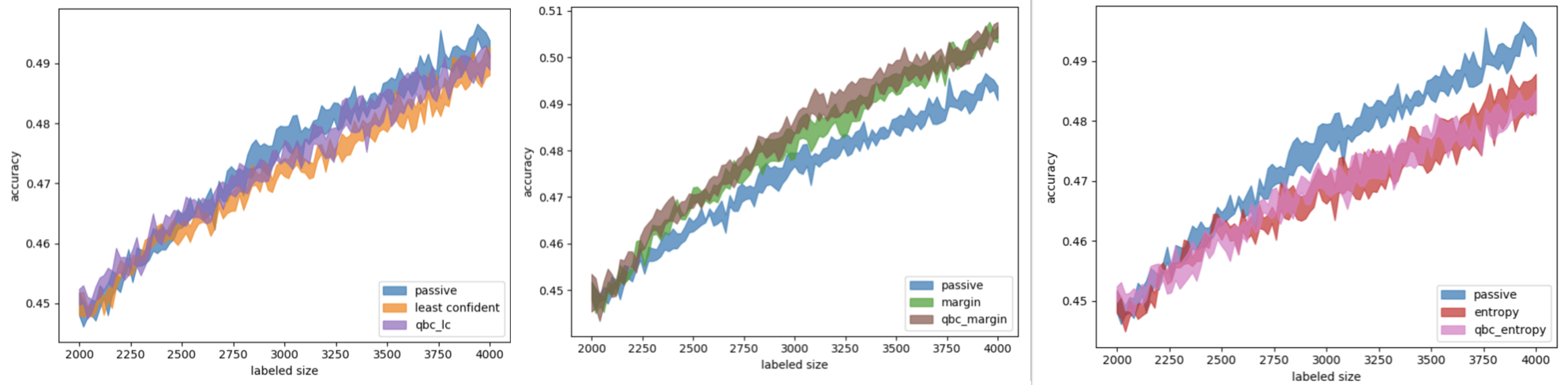
. 9. uncertainty sampling ( QBC ) ( — , — , — )
BALD. , Mutual Information :
— , — .
(5) , — . , , . BALD . 10.

. 10. BALD
, , .
query-by-committee BALD , . , uncertainty sampling. , — , — , — , — , .
BALD tf.keras, . PyTorch, dropout , batch normalization , .
№2: batch normalization
batch normalization. batch normalization — , . , , , , batch normalization. , . , . BALD. (. 11).
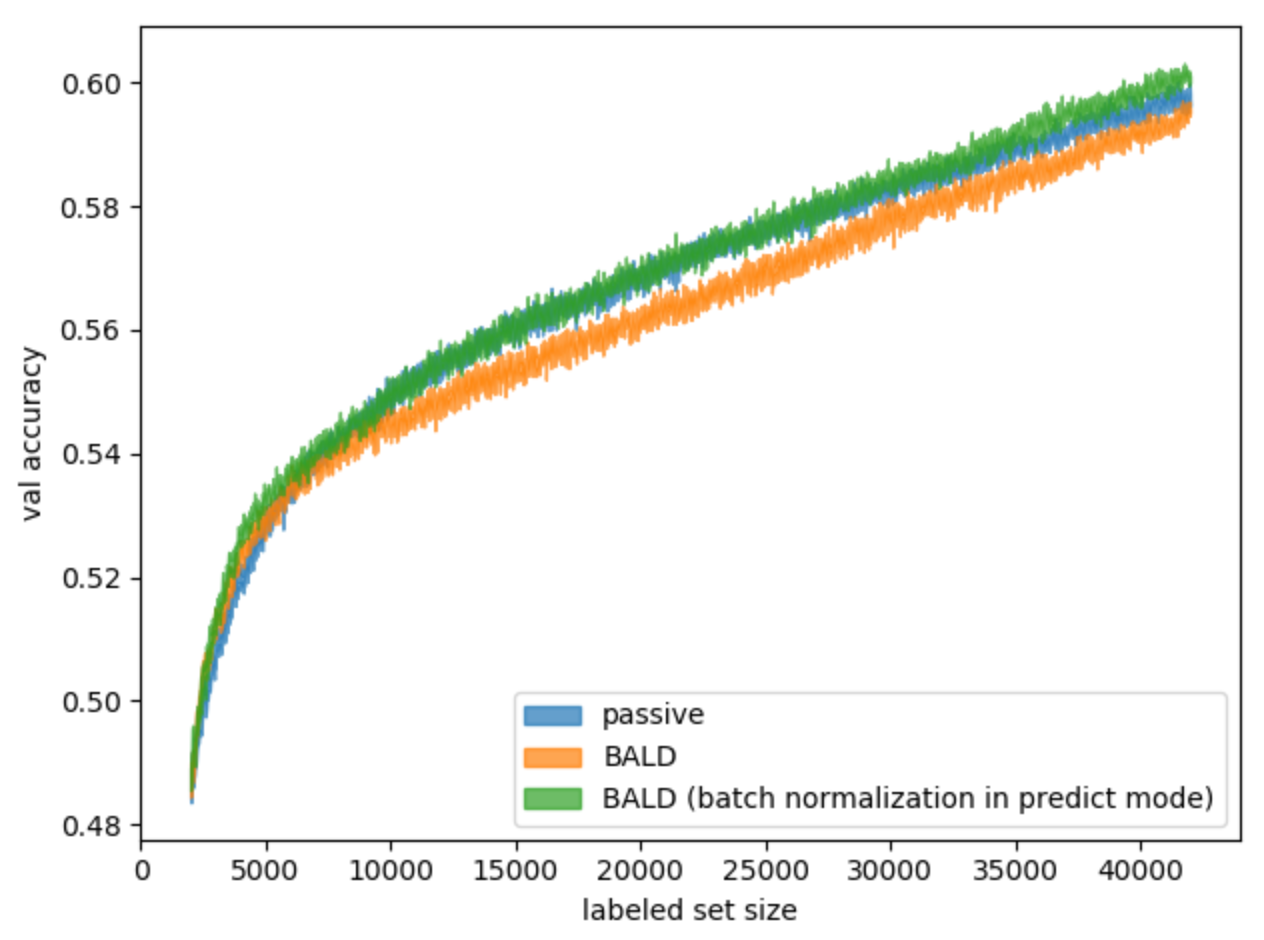
. 11. batch normalization BALD
, , .
batch normalization, . , .
Learning loss
. , . , .
, . — . , . learning loss, . , (. 12).
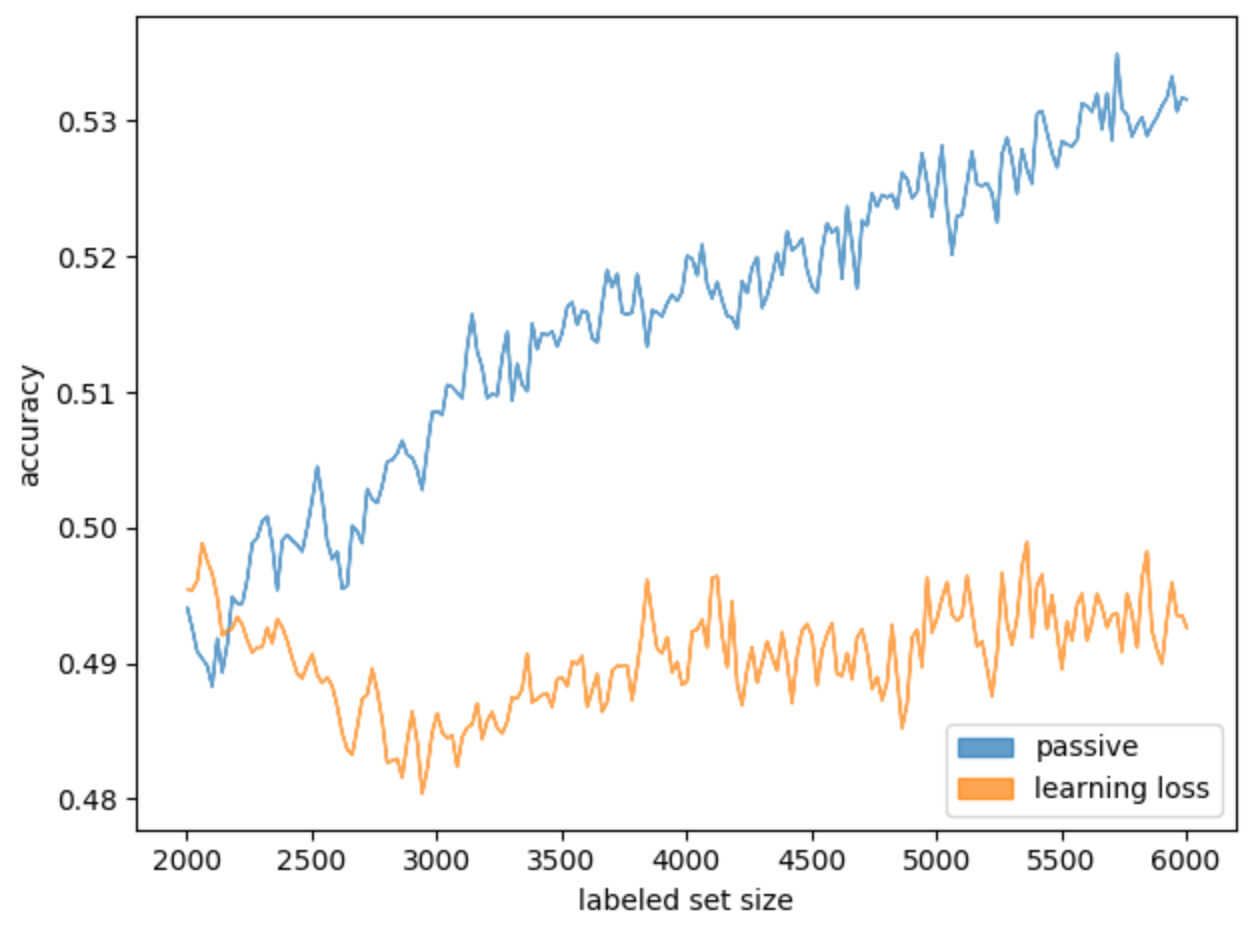
. 12. Learning loss
learning loss . .
. , . «» learning loss: , , . ideal learning loss (. 13).

. 13. ideal learning loss
, learning loss.
, . , , - , . :
- (2000 ), ;
- 10000 ( );
- ;
- ;
- 100 ;
- , , 1;
- .
, , . , ( margin sampling).
1.
| p-value | ||
|---|---|---|
| loss | -0,2518 | 0,0115 |
| margin | 0,2461 | 0,0136 |
, margin sampling — , , , . c .
: ?
, , (. 14).
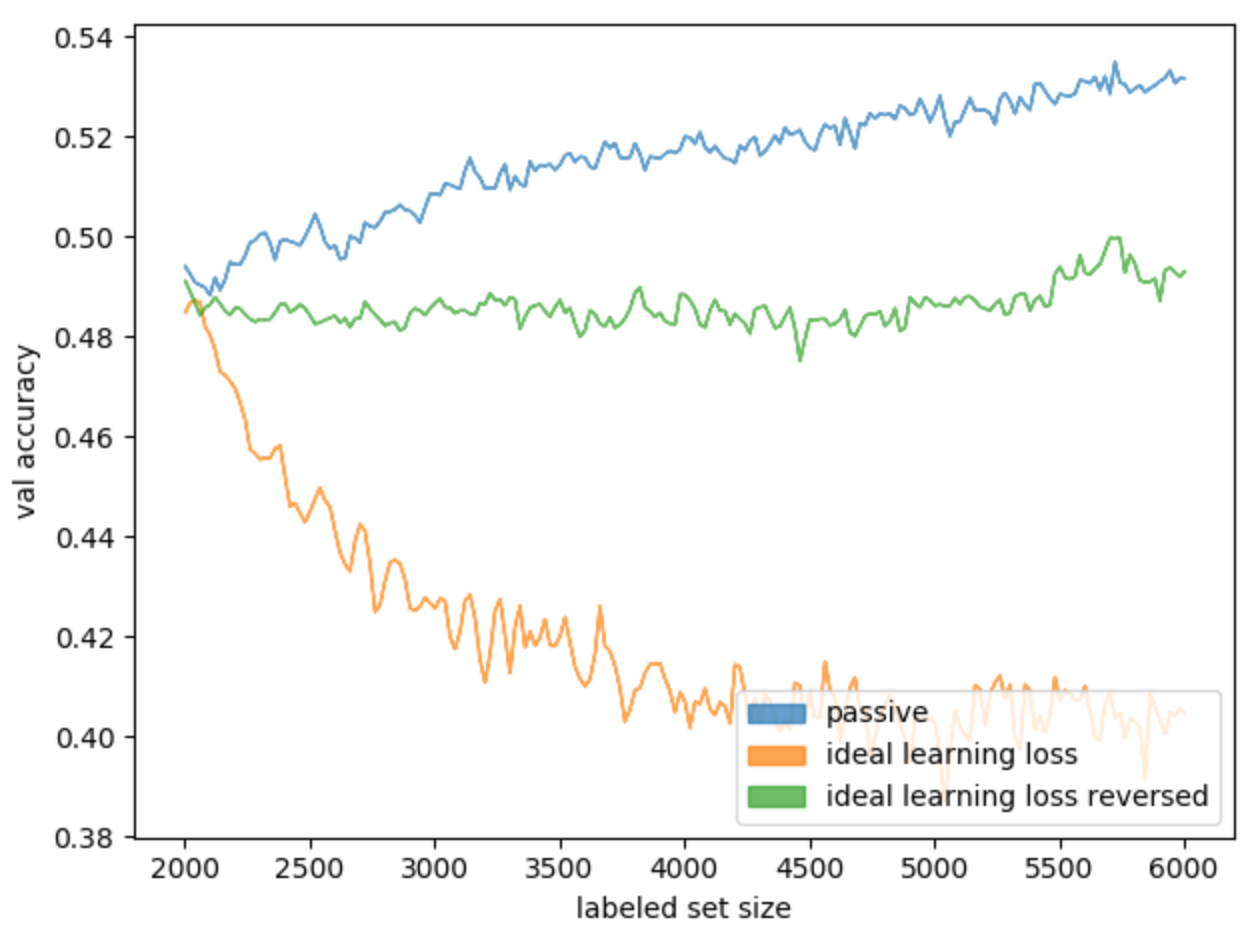
. 14. ideal learning loss ideal learning loss
, MNIST :
2. MNIST
| p-value | ||
|---|---|---|
| loss | 0,2140 | 0,0326 |
| 0,2040 | 0,0418 |
ideal learning loss , (. 15).

. 15. MNIST ideal learning loss. — ideal learning loss, —
, , , , . .
learning loss , uncertainty sampling: , — , — . , , . , .
, . . , margin sampling — . 16.
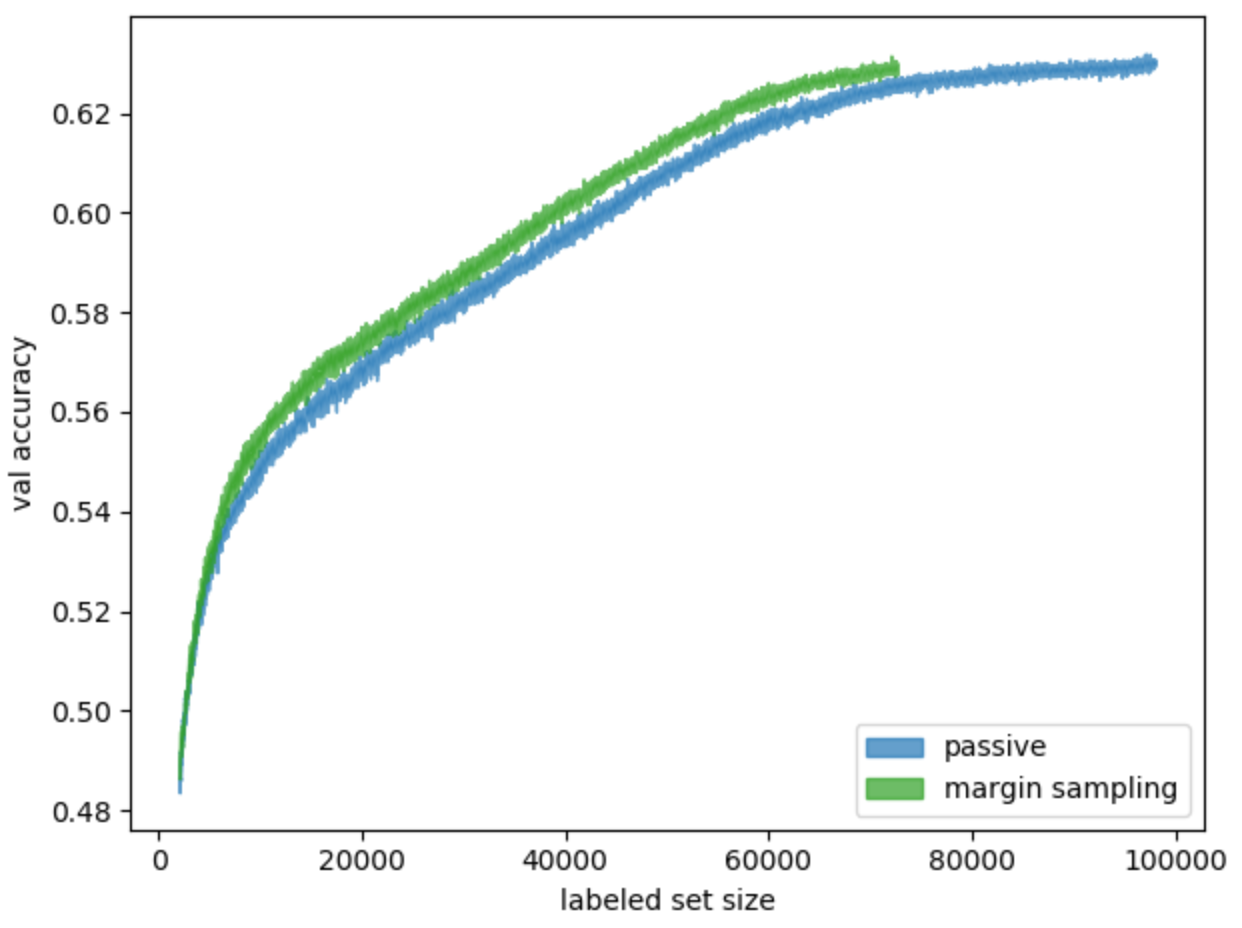
. 16. ( ) , margin sampling
: ( — margin sampling), — , , . ≈25 . . 25% — .
, . , , .
, , . , :
- batch size;
- , , — , batch normalization.