Repito, mas sempre de uma maneira nova - isso não é arte?
Stanislav Jerzy Lec, do livro "Uncombed Thoughts"
O dicionário define replicação como o processo de manutenção de dois (ou mais) conjuntos de dados em um estado consistente. O que é "estado consistente de conjuntos de dados" é uma grande questão separada, então vamos reformular a definição de uma maneira mais simples: o processo de alteração de um conjunto de dados, chamado de réplica, em resposta às mudanças em outro conjunto de dados, chamado mestre. Os conjuntos não são necessariamente os mesmos.

O suporte à replicação de banco de dados é uma das tarefas mais importantes do administrador: quase todo banco de dados de qualquer importância possui uma réplica, ou até mais de uma.
As tarefas de replicação incluem pelo menos
- suporte do banco de dados de backup em caso de perda do principal;
- redução da carga na base devido à transferência de parte das requisições para réplicas;
- transferência de dados para sistemas de arquivo ou analíticos.
Neste artigo, falarei sobre os tipos de replicação e quais tarefas cada tipo de replicação resolve.
Existem três abordagens para a replicação:
- Replicação de blocos no nível do sistema de armazenamento;
- Replicação física no nível do DBMS;
- Replicação lógica no nível do DBMS.
Replicação de blocos
Com a replicação de bloco, cada operação de gravação é executada não apenas no disco primário, mas também no backup. Assim, um volume em um array corresponde a um volume espelhado em outro array, repetindo o volume principal com uma precisão de byte:
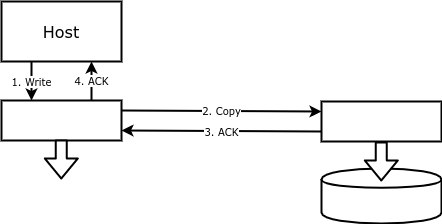
As vantagens de tal replicação incluem facilidade de configuração e confiabilidade. Uma matriz de disco ou algo (um dispositivo ou software) entre o host e o disco pode gravar dados em um disco remoto.
Matrizes de disco podem ser complementadas com opções para habilitar a replicação. O nome da opção depende do fabricante da matriz:
| Fabricante | Marca comercial
|
|---|---|
| EMC | SRDF (Symmetrix Remote Data Facility) |
| IBM | Metro Mirror - replicação síncrona
Global Mirror - replicação assíncrona |
| Hitachi | Cópia verdadeira |
| Hewlett-Packard | Acesso Contínuo |
| Huawei | HyperReplication |
Se a matriz de disco não for capaz de replicar dados, um agente pode ser instalado entre o host e a matriz, que grava em duas matrizes de uma vez. Um agente pode ser um dispositivo autônomo (EMC VPLEX) ou um componente de software (HPE PeerPersistence, Windows Server Storage Replica, DRBD). Ao contrário de uma matriz de disco, que só pode funcionar com a mesma matriz, ou pelo menos com uma matriz do mesmo fabricante, um agente pode trabalhar com dispositivos de disco completamente diferentes.
O principal objetivo da replicação de bloco é fornecer tolerância a falhas. Se o banco de dados for perdido, você pode reiniciá-lo usando o volume espelhado.
A replicação de blocos é excelente por sua versatilidade, mas a versatilidade tem um preço.
Primeiro, nenhum servidor pode lidar com um volume espelhado, porque seu sistema operacional não pode controlar as gravações nele; do ponto de vista de um observador, os dados no volume espelhado aparecem espontaneamente. No caso de um desastre (falha do servidor principal ou de todo o datacenter onde o servidor principal está localizado), você deve interromper a replicação, desmontar o volume principal e montar o volume espelhado. Assim que possível, você deve reiniciar a replicação na direção oposta.
No caso de utilizar um agente, todas essas ações serão realizadas pelo agente, o que simplifica a configuração, mas não reduz o tempo de comutação.
Em segundo lugar, o próprio DBMS no servidor de backup pode ser iniciado somente depois que o disco for montado. Em alguns sistemas operacionais, por exemplo, no Solaris, a memória do cache é marcada durante a alocação, e o tempo de marcação é proporcional à quantidade de memória alocada, ou seja, o início da instância não será instantâneo. Além disso, o cache ficará vazio após a reinicialização.
Em terceiro lugar, depois de iniciar o servidor de backup, o SGBD descobrirá que os dados no disco são inconsistentes e você precisa gastar uma quantidade significativa de tempo se recuperando usando logs de redo: primeiro, repita essas transações, cujos resultados foram salvos no log, mas não tiveram tempo para serem salvos em arquivos de dados e, em seguida, reverta as transações que não tiveram tempo de serem concluídas no momento da falha.
A replicação de bloco não pode ser usada para balanceamento de carga e um esquema semelhante é usado para atualizar o armazenamento de dados com o volume espelhado no mesmo array que o primário. A EMC e a HP chamam esse esquema de BCV, apenas EMC significa Business Continuance Volume e HP significa Business Copy Volume. A IBM não possui uma marca comercial especial para este caso, este esquema é denominado “volume espelhado”.

Dois volumes são criados na matriz e as operações de gravação são realizadas de forma síncrona em ambos (A). Em um determinado momento, o espelho quebra (B), ou seja, os volumes se tornam independentes. O volume espelhado é montado em um servidor dedicado a atualizações de armazenamento e uma instância de banco de dados é gerada nesse servidor. A instância levará tanto tempo para demorar quanto levaria com uma restauração de replicação em bloco, mas esse tempo pode ser reduzido significativamente quebrando o espelho durante os períodos de pico. O ponto é que quebrar o espelho em suas consequências equivale a um encerramento anormal do SGBD, e o tempo de recuperação no caso de um encerramento anormal depende significativamente do número de transações ativas no momento da falha. O banco de dados destinado ao descarregamento está disponível para leitura e gravação. Todos os identificadores de bloco,os espelhos alterados após o intervalo, tanto no volume principal quanto no espelhado, são salvos em uma área especial do Block Change Tracking - BCT.
Após o término do upload, o volume espelhado é desmontado (C), o espelho é restaurado e, após um tempo, o volume espelhado novamente alcança o volume principal e se torna sua cópia.
Replicação física
Os logs (redo log ou write-ahead log) contêm todas as alterações feitas nos arquivos de banco de dados. A ideia por trás da replicação física é que as alterações dos logs sejam confirmadas novamente em outro banco de dados (réplica) e, portanto, os dados na réplica replicam os dados no byte por byte mestre.
A capacidade de usar logs de banco de dados para atualizar uma réplica apareceu no lançamento do Oracle 7.3, que foi lançado em 1996, e já no lançamento do Oracle 8i, a entrega de logs do banco de dados principal para a réplica era automatizada e denominada DataGuard. A tecnologia acabou sendo tão exigida que hoje o mecanismo de replicação física está presente em quase todos os SGBD modernos.
| DBMS | Opção de replicação
|
|---|---|
| Oráculo | DataGuard ativo |
| IBM DB2 | HADR |
| Microsoft SQL Server | Envio de log / sempre ativado |
| PostgreSQL | Envio de log / replicação de streaming |
| MySQL | Replicação de InnoDB física Alibaba |
A experiência mostra que, se o servidor for usado apenas para manter a réplica atualizada, cerca de 10% da capacidade de processamento do servidor no qual a base principal está sendo executada é suficiente para ele.
Os logs do DBMS não devem ser usados fora desta plataforma, seu formato não é documentado e pode ser alterado sem aviso prévio. Daí o requisito bastante natural de que a replicação física só seja possível entre instâncias da mesma versão do mesmo DBMS. Daí as possíveis limitações no sistema operacional e na arquitetura do processador, que também podem afetar o formato do log.
Naturalmente, a replicação física não impõe nenhuma restrição aos modelos de armazenamento. Além disso, os arquivos no banco de dados de réplica podem ser localizados de uma maneira completamente diferente do que no banco de dados de origem - você só precisa descrever a correspondência entre os volumes nos quais esses arquivos estão localizados.
O Oracle DataGuard permite excluir alguns dos arquivos do banco de dados de réplica - neste caso, as alterações nos logs relacionados a esses arquivos serão ignoradas.
A replicação de banco de dados físico tem muitas vantagens sobre a replicação de armazenamento:
- a quantidade de dados transferidos é menor devido ao fato de que apenas os logs são transferidos, mas não os arquivos de dados; os experimentos mostram uma diminuição de 5 a 7 vezes no tráfego;
- : - , ; , ;
- , . , .
A capacidade de ler dados de uma réplica foi introduzida em 2007 com o lançamento do Oracle 11g, conforme indicado pelo epíteto "ativo" adicionado ao nome da tecnologia DataGuard. Outros DBMSs também têm a capacidade de ler de uma réplica, mas isso não se reflete no nome.
Gravar dados em uma réplica é impossível, pois as alterações ocorrem byte a byte e a réplica não pode fornecer execução simultânea de suas solicitações. O Oracle Active DataGuard em versões recentes permite a gravação na réplica, mas isso nada mais é do que "açúcar": na verdade, as alterações são realizadas na base principal e o cliente está esperando que elas sejam transferidas para a réplica.
Se um arquivo no banco de dados principal estiver danificado, você pode simplesmente copiar o arquivo correspondente da réplica (antes de fazer isso com seu banco de dados, leia atentamente o manual do administrador!). O arquivo da réplica pode não ser idêntico ao arquivo do banco de dados principal: o fato é que quando o arquivo é expandido, os novos blocos não são preenchidos com nada para aumentar a velocidade e seu conteúdo é acidental. A base pode não usar todo o espaço do bloco (por exemplo, pode haver espaço livre no bloco), mas o conteúdo do espaço usado corresponde ao byte.
A replicação física pode ser síncrona ou assíncrona. Com a replicação assíncrona, há sempre um determinado conjunto de transações que foram concluídas na base principal, mas ainda não atingiram a base de reserva e, no caso de uma transição para a base de reserva, se a base principal falhar, essas transações serão perdidas. Com a replicação síncrona, a conclusão da operação de confirmação significa que todos os registros de log relacionados a essa transação foram confirmados para a réplica. É importante entender que obter uma réplica do log não significa que as alterações serão aplicadas aos dados. Se o banco de dados principal for perdido, as transações não serão perdidas, mas se o aplicativo gravar dados no banco de dados principal e lê-los da réplica, ele tem a chance de obter a versão antiga desses dados.
No PostgreSQL, é possível configurar a replicação para que a confirmação seja concluída somente após as alterações serem aplicadas aos dados da réplica (opção
synchronous_commit = remote_apply), enquanto no Oracle, você pode configurar a réplica inteira ou sessões individuais para que as consultas sejam executadas apenas se a réplica não ficar para trás do banco de dados principal ( STANDBY_MAX_DATA_DELAY=0). No entanto, ainda é melhor projetar o aplicativo de forma que a gravação no banco de dados principal e a leitura das réplicas sejam realizadas em módulos diferentes.
Ao buscar uma resposta para a questão de qual modo escolher, síncrono ou assíncrono, os profissionais de marketing da Oracle vêm em nosso auxílio. DataGuard fornece três modos, cada um maximizando um dos parâmetros - segurança de dados, desempenho, disponibilidade - às custas dos outros:
- Desempenho máximo: a replicação é sempre assíncrona;
- Maximum protection: ; , commit ;
- Maximum availability: ; , , , .
Apesar das vantagens inegáveis da replicação de banco de dados sobre a replicação em bloco, os administradores em muitas empresas, especialmente aquelas com antigas tradições de confiabilidade, ainda relutam em abandonar a replicação em bloco. Há duas razões para isso.
Primeiro, no caso de replicação usando uma matriz de disco, o tráfego não passa pela rede de transmissão de dados (LAN), mas pela rede de área de armazenamento. Freqüentemente, em infraestruturas construídas há muito tempo, as SANs são muito mais confiáveis e eficientes do que as redes de dados.
Em segundo lugar, a replicação síncrona por meio de um DBMS tornou-se confiável há relativamente pouco tempo. No Oracle, o avanço ocorreu na versão 11g, lançada em 2007, e em outros DBMSs, a replicação síncrona apareceu ainda mais tarde. Claro, 10 anos pelos padrões da esfera da tecnologia da informação não é tão curto, mas quando se trata de segurança de dados, alguns administradores ainda se orientam pelo princípio do “aconteça o que acontecer” ...
Replicação lógica
Todas as mudanças no banco de dados ocorrem como resultado de chamadas para sua API - por exemplo, como resultado da execução de consultas SQL. A ideia de executar a mesma sequência de consultas em duas bases diferentes parece muito tentadora. Para replicação, você deve aderir a duas regras:
- , , . D, A B.
- , , . B , , C.
A replicação de comandos (replicação baseada em instruções) é implementada, por exemplo, no MySQL. Infelizmente, esse esquema simples não produz conjuntos de dados idênticos por dois motivos.
Primeiro, nem todas as APIs são determinísticas. Por exemplo, se uma consulta SQL contém a função now () ou sysdate () que retorna a hora atual, ela retornará resultados diferentes em servidores diferentes porque as consultas não são executadas simultaneamente. Além disso, diferentes estados de acionadores e funções armazenadas, diferentes localidades que afetam a ordem de classificação e muito mais podem levar a diferenças.
Em segundo lugar, a replicação paralela baseada em comando não pode ser pausada e reiniciada normalmente.
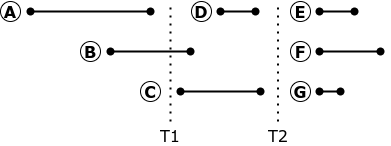
Se a replicação for interrompida no tempo T1, a transação B deve ser abortada e revertida. Ao reiniciar a replicação, a execução da transação B pode trazer a réplica para um estado diferente do estado do banco de dados de origem: na origem, a transação B começou antes do término da transação A, o que significa que ela não viu as alterações feitas pela transação A. A
replicação de solicitações pode ser interrompida e reiniciado apenas no tempo T2, quando não há transações ativas no banco de dados. Claro, não existem tais momentos em uma base industrial altamente carregada.
Normalmente, a replicação lógica usa consultas determinísticas. O determinismo da solicitação é fornecido por duas propriedades:
- a consulta atualiza (ou insere ou apaga) um único registro, identificando-o por sua chave primária (ou única);
- todos os parâmetros da solicitação são definidos explicitamente na própria solicitação.
Ao contrário da replicação baseada em instruções, esta abordagem é chamada de replicação baseada em linha.
Suponha que temos uma tabela de funcionários com os seguintes dados:
| EU IRIA | Nome | Departamento | Salário
|
|---|---|---|---|
| 3817 | Ivanov Ivan Ivanovich | 36 | 1800 |
| 2274 | Petrov Petr Petrovich | 36 | 1600 |
| 4415 | Kuznetsov Semyon Andreevich | 41 | 2100 |
A seguinte operação foi realizada nesta tabela:
update employee set salary = salary*1.2 where dept=36;Para replicar corretamente os dados, as seguintes consultas serão executadas na réplica:
update employee set salary = 2160 where id=3817;
update employee set salary = 1920 where id=2274;As consultas produzem o mesmo resultado que na base original, mas não são equivalentes às consultas executadas.
A base da réplica está aberta e disponível não apenas para leitura, mas também para escrita. Isso permite que a réplica seja usada para executar parte das consultas, inclusive para a construção de relatórios que requeiram a criação de tabelas ou índices adicionais.
É importante entender que uma réplica lógica será equivalente à base original apenas se nenhuma alteração adicional for feita nela. Por exemplo, se no exemplo acima, na réplica, o departamento de Sidorov for adicionado a 36, ele não receberá uma promoção e, se Ivanov for transferido do departamento 36, ele receberá uma promoção, aconteça o que acontecer.
A replicação lógica fornece vários recursos não encontrados em outros tipos de replicação:
- configurar um conjunto de dados replicados no nível da tabela (para replicação física - no nível do arquivo e do espaço da tabela, para replicação em bloco - no nível do volume);
- construir topologias de replicação complexas - por exemplo, consolidar vários bancos de dados em uma replicação ou em uma replicação bidirecional;
- diminuição na quantidade de dados transmitidos;
- replicação entre diferentes versões de um DBMS ou mesmo entre DBMSs de diferentes fabricantes;
- processamento de dados durante a replicação, incluindo reestruturação, enriquecimento, preservação da história.
Existem também desvantagens que não permitem que a replicação lógica suplante a replicação física:
- todos os dados replicados devem ter chaves primárias;
- a replicação lógica não oferece suporte a todos os tipos de dados - por exemplo, pode haver problemas com BLOBs.
- : , ;
- ;
- , , – , .
As duas últimas desvantagens limitam significativamente o uso de uma réplica lógica como ferramenta de tolerância a falhas. Se uma consulta no banco de dados principal alterar muitas linhas de uma vez, a réplica pode atrasar significativamente. E a capacidade de alterar as funções requer esforços notáveis de desenvolvedores e administradores.
Existem várias maneiras de implementar a replicação lógica, e cada um desses métodos implementa uma parte dos recursos e não implementa a outra:
- replicação por gatilhos;
- usando logs de DBMS;
- uso de software CDC (change data capture);
- replicação aplicada.
Replicação de gatilho
Trigger é um procedimento armazenado que é executado automaticamente após qualquer ação para modificar dados. O gatilho, que é chamado quando cada registro é alterado, tem acesso à chave desse registro, bem como aos antigos e novos valores de campo. Se necessário, o gatilho pode salvar novos valores de linha em uma tabela especial, de onde um processo especial no lado da réplica os lerá. A quantidade de código em gatilhos é grande, portanto, há um software especial que gera esses gatilhos, por exemplo, "replicação de mesclagem" - um componente do Microsoft SQL Server ou Slony-I - um produto separado para replicação PostgreSQL.
Forças da replicação do gatilho:
- independência das versões da base principal e da réplica;
- amplos recursos de conversão de dados.
Desvantagens:
- carregar na base principal;
- alta latência de replicação.
Usando registros de DBMS
O próprio DBMS também pode fornecer recursos de replicação lógica. Logs são a fonte de dados, assim como para replicação física. As informações sobre a alteração do byte também são adicionadas às informações sobre os campos alterados (log suplementar no Oracle,
wal_level = logicalno PostgreSQL), bem como o valor da chave única, mesmo que não mude. Como resultado, o volume de logs do banco de dados está aumentando - de acordo com várias estimativas, de 10 a 15%.
Os recursos de replicação dependem da implementação em um DBMS específico - se você pode construir um standby lógico no Oracle, então no PostgreSQL ou Microsoft SQL Server você pode implantar um sistema complexo de assinaturas mútuas e publicações usando as ferramentas da plataforma embutida. Além disso, o DBMS fornece monitoramento e controle integrados de replicação.
As desvantagens dessa abordagem incluem um aumento no volume de logs e um possível aumento no tráfego entre os nós.
Usando CDC
Existe toda uma classe de software projetado para organizar a replicação lógica. Este software é denominado CDC, Change Data Capture. Aqui está uma lista das plataformas mais famosas desta classe:
- Oracle GoldenGate (adquirido pela GoldenGate em 2009);
- IBM InfoSphere Data Replication (anteriormente InfoSphere CDC; ainda antes, DataMirror Transformation Server, adquirido pela DataMirror em 2007);
- VisionSolutions DoubleTake / MIMIX (anteriormente Vision Replicate1);
- Qlik Data Integration Platform (anteriormente Attunity);
- CDC do Informatica PowerExchange;
- Debezium;
- StreamSets Data Collector ...
A tarefa da plataforma é ler logs de banco de dados, transformar informações, transferir informações para uma réplica e aplicar. Como no caso da replicação por meio do próprio SGBD, o log deve conter informações sobre os campos alterados. Usar um aplicativo adicional permite realizar transformações complexas de dados replicados em tempo real e construir topologias de replicação bastante complexas.
Forças:
- a capacidade de replicar entre diferentes SGBDs, incluindo o carregamento de dados em sistemas de relatórios;
- as mais amplas possibilidades de processamento e transformação de dados;
- tráfego mínimo entre os nós - a plataforma corta dados desnecessários e pode compactar o tráfego;
- recursos integrados para monitorar o status da replicação.
Não há muitas desvantagens:
- aumento do volume de logs, como na replicação lógica por meio de um SGBD;
- novo software é difícil de configurar e / ou com licenças caras.
São plataformas CDC tradicionalmente usadas para atualizar data warehouses corporativos quase em tempo real.
Replicação aplicada
Finalmente, outra forma de replicação é a formação de vetores de mudança diretamente do lado do cliente. O cliente deve emitir consultas determinísticas que afetam um único registro. Isso pode ser obtido usando uma biblioteca de banco de dados especial, por exemplo, Borland Database Engine (BDE) ou Hibernate ORM.
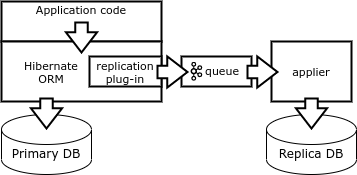
Quando o aplicativo completa a transação, o plugin Hibernate ORM grava o vetor de mudança na fila e executa a transação no banco de dados. Um processo replicador especial subtrai vetores da fila e executa transações na base de réplica.
Este mecanismo é bom para atualizar os sistemas de relatórios. Também pode ser usado para fornecer tolerância a falhas, mas, neste caso, o aplicativo deve implementar o controle do estado de replicação.
Tradicionalmente - pontos fortes e fracos desta abordagem:
- a capacidade de replicar entre diferentes SGBDs, incluindo o carregamento de dados em sistemas de relatórios;
- a capacidade de processar e transformar dados, monitoramento de condições, etc.;
- tráfego mínimo entre os nós - a plataforma corta dados desnecessários e pode compactar o tráfego;
- total independência da base de dados - tanto do formato como dos mecanismos internos.
As vantagens deste método são inegáveis, mas existem duas desvantagens muito sérias:
- restrições na arquitetura do aplicativo;
- uma grande quantidade de código de replicação nativa.
Então, o que é melhor?
Não há uma resposta inequívoca para essa pergunta, como para muitas outras. Mas espero que a tabela abaixo ajude você a fazer a escolha certa para cada tarefa específica:
| Replicação de bloco de armazenamento | Bloquear replicação por agente | Replicação física | Replicação de DBMS lógico | CDC |
|
||
|---|---|---|---|---|---|---|---|
| X | X | X/7..X/5 | X/7..X/5 | ≤X/10 | ≤X/10 | ≤X/10 | |
| 5 … | 5 … | 1..10 | 1..10 | 1..2 | 1..2 | 1..2 | |
| + | + | +++ | + | ∅ | ∅ | ∅ | |
| ∅ | ∅ | RO | R/W | R/W | R/W | R/W | |
| - | -
broadcast |
-
broadcast |
-
broadcast * p2p* |
-
broadcast * p2p* |
-
broadcast * p2p* |
-
broadcast * p2p* |
|
| ∅ | ∅ | – | – – | – – – | – – | ∅ | |
| + + + | + + | + + | + + | – | + | – – – | |
| – – | – – | – | – | ∅ | – – – | ∅ | |
| ∅ | + | + + | + + | + + | + + + | + + + |
- , ; .
- , .
- , .
- .
- , , .
- CDC , / .
- .