"Retardar programas é muito mais rápido do que acelerar computadores"
Desde então, essa declaração foi considerada a lei de Wirth . Ele efetivamente nega a Lei de Moore, que afirma que o número de transistores nos processadores dobrou desde cerca de 1965. Aqui está o que Wirth escreve em seu artigo "Call for Slim Software" :
“Cerca de 25 anos atrás, um editor de texto interativo tinha apenas 8.000 bytes e um compilador tinha 32 kilobytes, enquanto seus descendentes modernos requerem megabytes. Todo esse software inchado ficou mais rápido? Não, muito pelo contrário. Se não fosse por um hardware mil vezes mais rápido, o software moderno seria completamente inutilizável. "
É difícil discordar disso.
Software de obesidade
O problema de desenvolver software moderno é muito agudo. Wirth aponta um aspecto importante: o tempo. Ele sugere que o principal motivo do software inchado é a falta de tempo de desenvolvimento.
Hoje, há outra razão para a obesidade em software - abstração. E este é um problema muito mais sério. Os desenvolvedores nunca escreveram programas do zero, mas isso nunca foi um problema antes.
Dijkstra e Wirth tentaram melhorar a qualidade do código e desenvolveram o conceito de programação estruturada. Eles queriam tirar a programação da crise e, por algum tempo, a programação foi vista como uma verdadeira arte para profissionais de verdade. Os programadores se preocuparam com a qualidade dos programas, apreciaram a clareza e a eficiência do código.
Esses dias acabaram.
Com o surgimento de linguagens de alto nível, como Java, Ruby, PHP e Javascript, a programação tornou-se mais abstrata em 1995, quando Wirth escreveu seu artigo. Novas linguagens tornaram a programação muito mais fácil e exigiram muito. Eles eram orientados a objetos e vinham junto com coisas como IDEs e coleta de lixo.
Ficou mais fácil viver para os programadores, mas tudo tem um preço. Quanto mais fácil é viver, menos pensar. Em meados dos anos 90, os programadores pararam de pensar na qualidade de seus programas, escreve o desenvolvedor Robin Martin em seu artigo "Niklaus Wirth estava certo e esse é o problema . " Ao mesmo tempo, iniciou-se o uso generalizado de bibliotecas, cuja funcionalidade é sempre muito mais do que o necessário para um determinado programa.
Como a biblioteca não foi construída para um projeto específico, ela provavelmente tem um pouco mais de funcionalidade do que realmente precisa. Não tem problema, você diz. No entanto, as coisas aumentam muito rapidamente. Mesmo as pessoas que amam bibliotecas não querem reinventar a roda. Isso leva ao que é chamado de inferno da dependência. Nicola Duza escreveu um post sobre esse assunto em Javascript .
O problema não parece grande coisa, mas na realidade é mais sério do que você imagina. Por exemplo, Nikola Dusa escreveu um aplicativo simples de lista de tarefas. Funciona no seu navegador com HTML e Javascript. Quantas dependências você acha que ele usou? 13.000. Treze. Mil. Prova .
Os números são insanos, mas o problema só vai aumentar. Conforme novas bibliotecas são criadas, o número de dependências em cada projeto também aumenta.
Isso significa que o problema sobre o qual Niklaus Wirth alertou em 1995 só vai piorar com o tempo.
O que fazer?
Robin Martin sugere que uma boa maneira de começar é dividir as bibliotecas. Em vez de construir uma grande biblioteca que faz o melhor que pode, basta criar várias bibliotecas.
Assim, o programador só precisa selecionar as bibliotecas de que realmente precisa, ignorando a funcionalidade que não vai utilizar. Ele não apenas instala menos dependências, mas as bibliotecas usadas também terão menos dependências.
Fim da Lei de Moore
Infelizmente, a miniaturização dos transistores não pode durar para sempre e tem seus limites físicos. Talvez mais cedo ou mais tarde a Lei de Moore pare de funcionar. Alguns dizem que isso já aconteceu. Nos últimos dez anos, a velocidade do clock e a potência dos núcleos de processador individuais já pararam de crescer como antes.
Embora seja muito cedo para enterrá-lo. Há uma série de novas tecnologias que prometem substituir a microeletrônica de silício. Por exemplo, Intel, Samsung e outras empresas estão experimentando transistores baseados em nanoestruturas de carbono (nanofios) , bem como chips fotônicos.

Evolução dos transistores. Ilustração: Samsung
Mas alguns pesquisadores adotam uma abordagem diferente. Eles propõem novas abordagens de programação de sistemas para melhorar drasticamente a eficiência do software futuro. Assim, é possível "reiniciar" a lei de Moore por métodos de programa, não importa o quão fantástico pareça à luz das observações de Nicklaus Wirth sobre a obesidade de programa. Mas e se pudermos reverter essa tendência?
Técnicas de aceleração de software
Recentemente, a Science publicou um artigo interessante de cientistas do Laboratório de Ciência da Computação e Inteligência Artificial do Instituto de Tecnologia de Massachusetts (CSAIL MIT). Eles destacam três áreas prioritárias para acelerar ainda mais a computação:
- o melhor software;
- novos algoritmos;
- hardware mais otimizado.
O autor principal do trabalho científico Charles Leiserson confirma a tese da obesidade do software . Ele diz que os benefícios da miniaturização de transistores têm sido tão grandes que por décadas os programadores foram capazes de priorizar tornar o código mais fácil de escrever, em vez de acelerar a execução. A ineficiência poderia ser tolerada porque chips de computador mais rápidos sempre compensavam a obesidade de software.
“Mas hoje em dia, novos avanços em áreas como aprendizado de máquina, robótica e realidade virtual exigirão um enorme poder de computação que a miniaturização não pode mais oferecer”, diz Leiserson. "Se quisermos aproveitar todo o potencial dessas tecnologias, devemos mudar nossa abordagem para a computação."
Na parte de software, propõe-se reconsiderar a estratégia de utilização de bibliotecas com funcionalidade excessiva, pois esta é uma fonte de ineficiência. Os autores recomendam concentrar-se na tarefa principal - aumentar a velocidade de execução do programa, e não na velocidade de escrita do código.
Em muitos casos, o desempenho pode realmente ser aumentado milhares de vezes, e isso não é exagero. Como exemplo, os pesquisadores citam a multiplicação de duas matrizes 4096 × 4096. Eles começaram com a implementação em Python como uma das linguagens de alto nível mais populares. Por exemplo, aqui está uma implementação de quatro linhas em Python 2:
for i in xrange(4096):
for j in xrange(4096):
for k in xrange(4096):
C[i][j] += A[i][k] * B[k][j]O código tem três loops aninhados e o algoritmo de solução é baseado no currículo de álgebra da escola.
Mas descobriu-se que essa abordagem ingênua é muito ineficiente para o poder de computação. Em um computador moderno, ele funcionará por cerca de sete horas, conforme mostrado na tabela abaixo.
| Versão | Implementação | Tempo (s) de execução | GFLOPS | Aceleração absoluta | Aceleração relativa | Porcentagem de desempenho máximo |
|---|---|---|---|---|---|---|
| 1 | Pitão | 25552,48 | 0,005 | 1 | - | 0,00 |
| 2 | Java | 2372,68 | 0,058 | onze | 10,8 | 0,01 |
| 3 | C | 542,67 | 0,253 | 47 | 4,4 | 0,03 |
| 4 | Loops paralelos | 69,80 | 1,97 | 366 | 7,8 | 0,24 |
| cinco | Divida e conquiste o paradigma | 3,80 | 36,18 | 6727 | 18,4 | 4,33 |
| 6 | + vetorização | 1,10 | 124,91 | 23224 | 3,5 | 14,96 |
| 7 | + intristics AVX | 0,41 | 337,81 | 52806 | 2,7 | 40,45 |
A transição para uma linguagem de programação mais eficiente já aumenta drasticamente a velocidade de execução do código. Por exemplo, um programa Java será executado 10,8 vezes mais rápido e um programa C 4,4 vezes mais rápido que o Java. Portanto, mudar de Python para C significa uma execução de programa 47 vezes mais rápida.
E este é apenas o começo da otimização. Se você escrever o código levando em consideração as peculiaridades do hardware no qual ele será executado, poderá aumentar a velocidade em mais 1300 vezes. Neste experimento, o código foi executado primeiro em paralelo em todos os 18 núcleos de CPU (versão 4), em seguida, usou a hierarquia de cache do processador (versão 5), adicionou vetorização (versão 6) e aplicou instruções específicas de Advanced Vector Extensions (AVX) na versão 7. Última versão otimizada o código leva apenas 0,41 segundos, não 7 horas, ou seja, mais de 60.000 vezes mais rápido do que o código Python original.
Além do mais, em uma placa de vídeo AMD FirePro S9150, o mesmo código é executado em apenas 70 ms, 5,4 vezes mais rápido que a versão 7 mais otimizada em um processador de uso geral e 360.000 vezes mais rápido que a versão 1.
Em termos de algoritmos, os pesquisadores propõem uma abordagem em três frentes que envolve explorar novas áreas de problema, escalar os algoritmos e adaptá-los para melhor aproveitar as vantagens do hardware moderno.
Por exemplo, o algoritmo de Strassen para multiplicação de matrizes em 10% adicionais acelera a versão mais rápida do código número 7. Para outros problemas, os novos algoritmos fornecem ainda mais ganho de desempenho. Por exemplo, o diagrama a seguir mostra o progresso feito na eficiência dos algoritmos para resolver o problema de fluxo máximo entre 1975 e 2015. Cada novo algoritmo aumentava a velocidade computacional em literalmente várias ordens de magnitude e, nos anos subsequentes, era otimizado ainda mais.
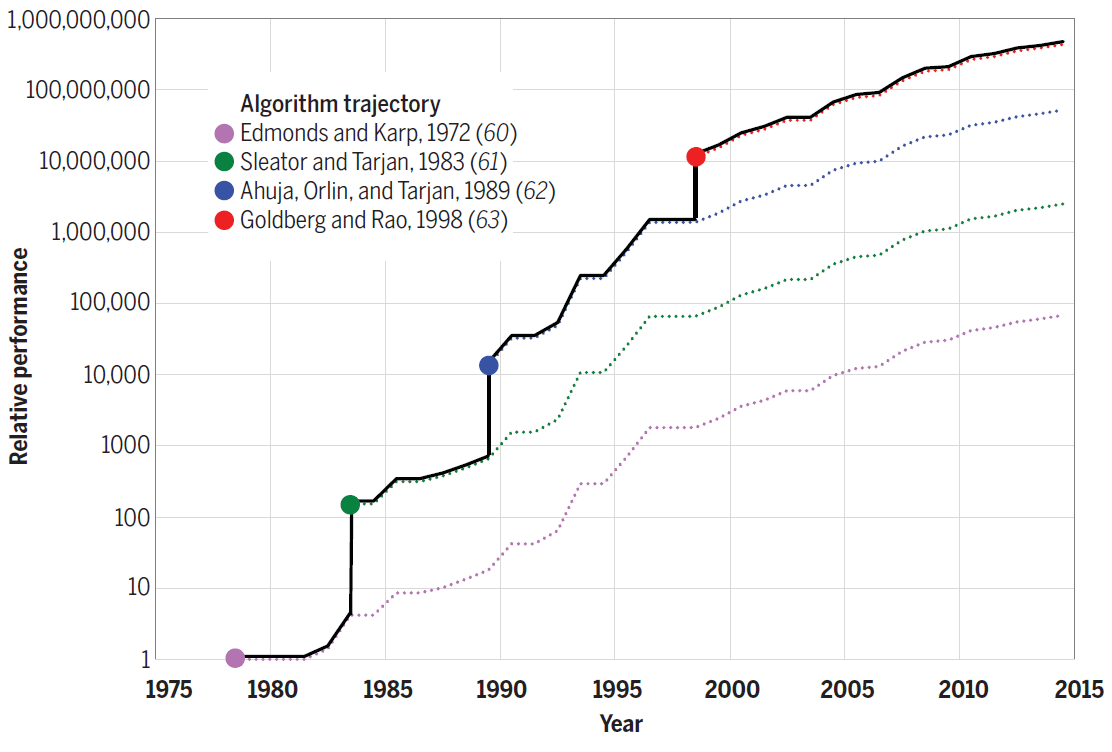
Eficiência dos algoritmos para resolver o problema de fluxo máximo em um grafo com n = 10 12 vértices em = n 11 arestas.
Assim, o aprimoramento dos algoritmos também contribui para "emular" a lei de Moore de forma programática.
Finalmente, em termos de arquitetura de hardware, os pesquisadores defendem a otimização do hardware para que os problemas possam ser resolvidos com menos transistores. A otimização envolve o uso de processadores mais simples e a criação de hardware sob medida para aplicações específicas, como a GPU é adaptada para computação gráfica.
“Equipamentos feitos sob medida para áreas específicas podem ser muito mais eficientes e usar muito menos transistores, permitindo que os aplicativos funcionem dezenas ou centenas de vezes mais rápido”, diz Tao Schardl, coautor do artigo de pesquisa. "De maneira mais geral, a otimização de hardware estimulará ainda mais a programação paralela, criando áreas adicionais no chip para uso paralelo."
A tendência de paralelização já é visível. Conforme mostrado no diagrama, nos últimos anos, o desempenho da CPU aumentou apenas devido ao aumento no número de núcleos.
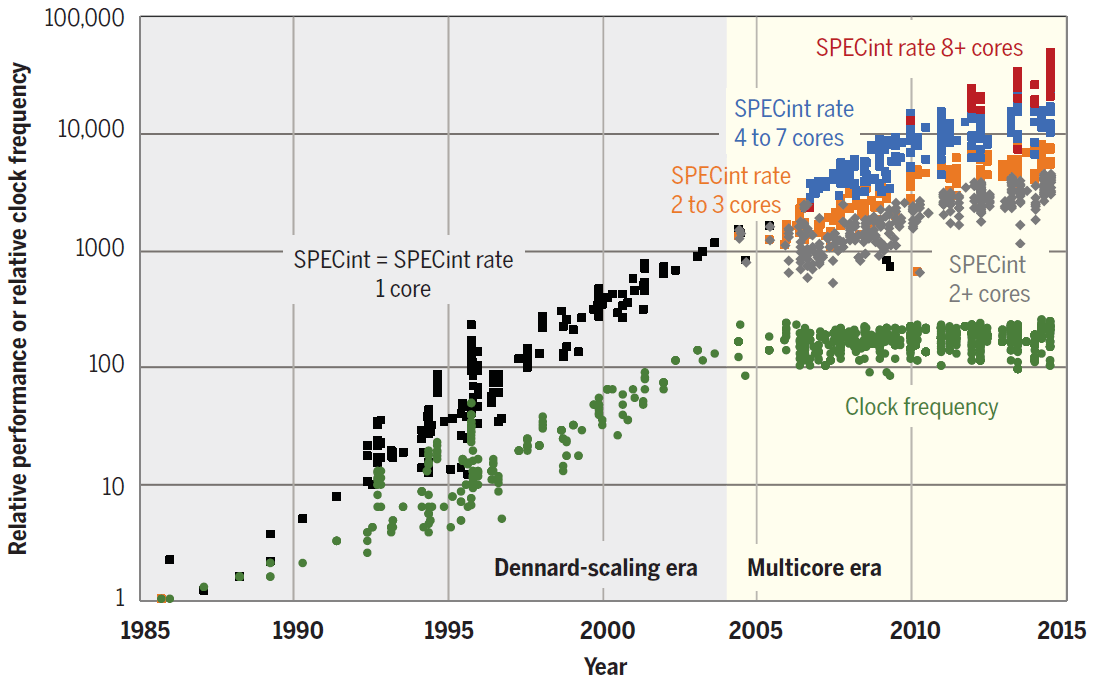
Desempenho SPECint de núcleos individuais e processadores single e multi-core de 1985 a 2015. A unidade base é um microprocessador 1985 80386 DX
Para operadores de data center, mesmo a menor melhoria no desempenho do software pode se traduzir em grandes ganhos financeiros. Não é de surpreender que empresas como Google e Amazon estejam liderando iniciativas para desenvolver suas próprias CPUs especializadas. Os primeiros processadores tensores (neurais) Google TPU e chips AWS Graviton estão rodando em data centers da Amazon .
Com o tempo, os líderes do setor podem ser seguidos por outros proprietários de data centers para não perder para os concorrentes em eficiência.
Os pesquisadores escrevem que, no passado, ganhos explosivos de desempenho em processadores de uso geral limitaram o escopo para o desenvolvimento de processadores especializados. Agora não existe essa limitação.
“Os ganhos de produtividade exigirão novas ferramentas, linguagens de programação e hardware para permitir um design mais eficiente com velocidade em mente”, disse o professor Charles Leiserson, co-autor da pesquisa. "Isso também significa que os programadores precisam entender melhor como software, algoritmos e hardware se encaixam, em vez de olhar para eles isoladamente."
Por outro lado, os engenheiros estão experimentando tecnologias que podem aumentar ainda mais o desempenho da CPU. São eles: computação quântica, layout 3D, microcircuitos supercondutores, computação neuromórfica, uso de grafeno em vez de silício, etc. Mas até agora essas tecnologias estão em estágio de experimentos.
Se o desempenho da CPU realmente parar de crescer, então nos encontraremos em uma realidade completamente diferente. Talvez realmente tenhamos que reconsiderar nossas prioridades de programação, e os especialistas em montagem valerão seu peso em ouro.
Publicidade
Precisa de um servidor poderoso ? Nossa empresa oferece servidores épicos - servidores virtuais com CPU AMD EPYC, frequência de núcleo de CPU de até 3,4 GHz. A configuração máxima impressionará qualquer pessoa - 128 núcleos de CPU, 512 GB de RAM, 4000 GB de NVMe.
