Parte 2
Parte 3
Neste artigo, você aprenderá:
- O que é aprendizagem por transferência e como funciona
- O que é segmentação semântica / instância e como funciona
- Sobre o que é detecção de objetos e como funciona
Introdução
Existem dois métodos para tarefas de detecção de objetos (veja a fonte e mais detalhes aqui ):
- Métodos de duas fases, eles também são "métodos baseados em regiões" (eng. Métodos baseados em regiões) - uma abordagem dividida em duas fases. No primeiro estágio, as regiões de interesse (RoI) são selecionadas por busca seletiva ou usando uma camada especial da rede neural - regiões com alta probabilidade de conter objetos dentro delas. No segundo estágio, as regiões selecionadas são consideradas pelo classificador para determinar o pertencimento às classes originais e pelo regressor, que especifica a localização das caixas delimitadoras.
- Método de estágio único (Métodos de um estágio Engl.) - abordagem, não usando um algoritmo separado para gerar regiões, em vez de prever coordenadas de certa quantidade de caixas delimitadoras com características diferentes, como os resultados da classificação e o grau de confiança, e ainda ajustar a estrutura de localização.
Este artigo descreve métodos de uma etapa.
Aprendizagem de transferência
O aprendizado por transferência é um método de treinamento de redes neurais, no qual usamos um modelo já treinado em alguns dados para treinamento adicional para resolver outro problema. Por exemplo, temos um modelo EfficientNet-B5 treinado em um conjunto de dados ImageNet (1000 classes). Agora, no caso mais simples, mudamos sua última camada classificadora (digamos, para classificar objetos de 10 classes).
Dê uma olhada na imagem abaixo:
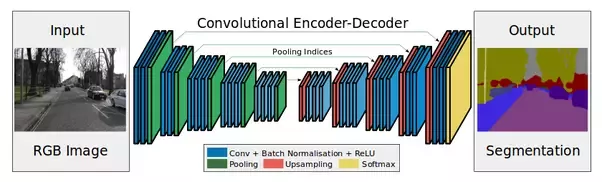
Codificador - são camadas de subamostragem (convoluções e pools).
Substituir a última camada no código se parece com isto (framework - pytorch, ambiente - google colab):
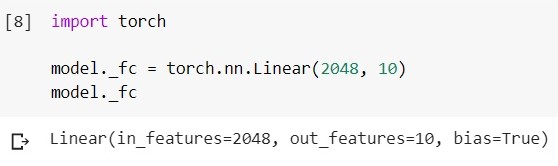
Carregue o modelo EfficientNet-b5 treinado e observe sua camada classificadora:

Mude esta camada para outra: o
decodificador é necessário, em particular, na tarefa de segmentação (sobre isso Mais longe).
Transferir estratégias de aprendizagem
Deve-se acrescentar que, por padrão, todas as camadas do modelo que queremos treinar mais são treináveis. Podemos "congelar" os pesos de algumas camadas.
Para congelar todas as camadas:

Quanto menos camadas treinamos, menos recursos computacionais precisamos para treinar o modelo. Esta técnica é sempre justificada?
Dependendo da quantidade de dados sobre os quais queremos treinar a rede, e dos dados sobre os quais a rede foi treinada, existem 4 opções para o desenvolvimento de eventos de transferência de aprendizagem (em "pouco" e "muito" você pode usar o valor condicional 10k):
- Você tem poucos dados e são semelhantes aos dados nos quais a rede foi treinada anteriormente. Você pode tentar treinar apenas as últimas camadas.
- , , . . , , , .. .
- , , . , .
- , , . .
Semantic segmentation
Segmentação semântica é quando alimentamos uma imagem como entrada e na saída queremos algo como:

Mais formalmente, queremos classificar cada pixel de nossa imagem de entrada - para entender a qual classe ele pertence.
Existem muitas abordagens e nuances aqui. O que é apenas a arquitetura da rede ResNeSt-269 :)
Intuição - na entrada a imagem (h, w, c), na saída queremos uma máscara (h, w) ou (h, w, c), onde c é o número de classes (depende de dados e modelo). Agora vamos adicionar um decodificador após nosso codificador e treiná-los.
O decodificador consistirá, em particular, em camadas de upsampling. Você pode aumentar a dimensão simplesmente "esticando" nosso mapa de recursos em altura e largura em uma etapa ou outra. Ao puxar, você pode usarinterpolação bilinear (no código será apenas um dos parâmetros do método).
Arquitetura de rede Deeplabv3 +:
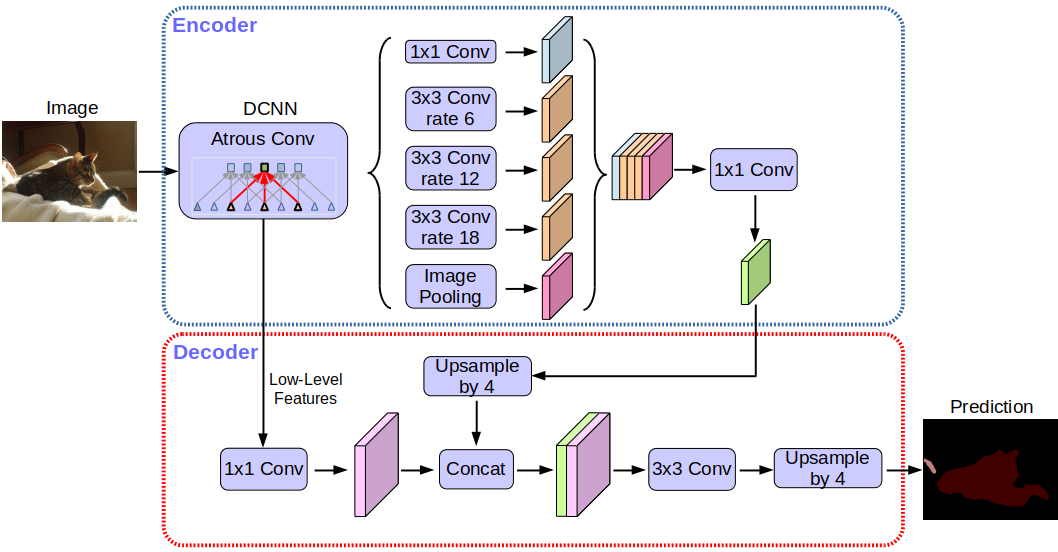
Sem entrar em detalhes, você notará que a rede usa a arquitetura de codificador-decodificador.
Uma versão mais clássica, a arquitetura da rede U-net: o
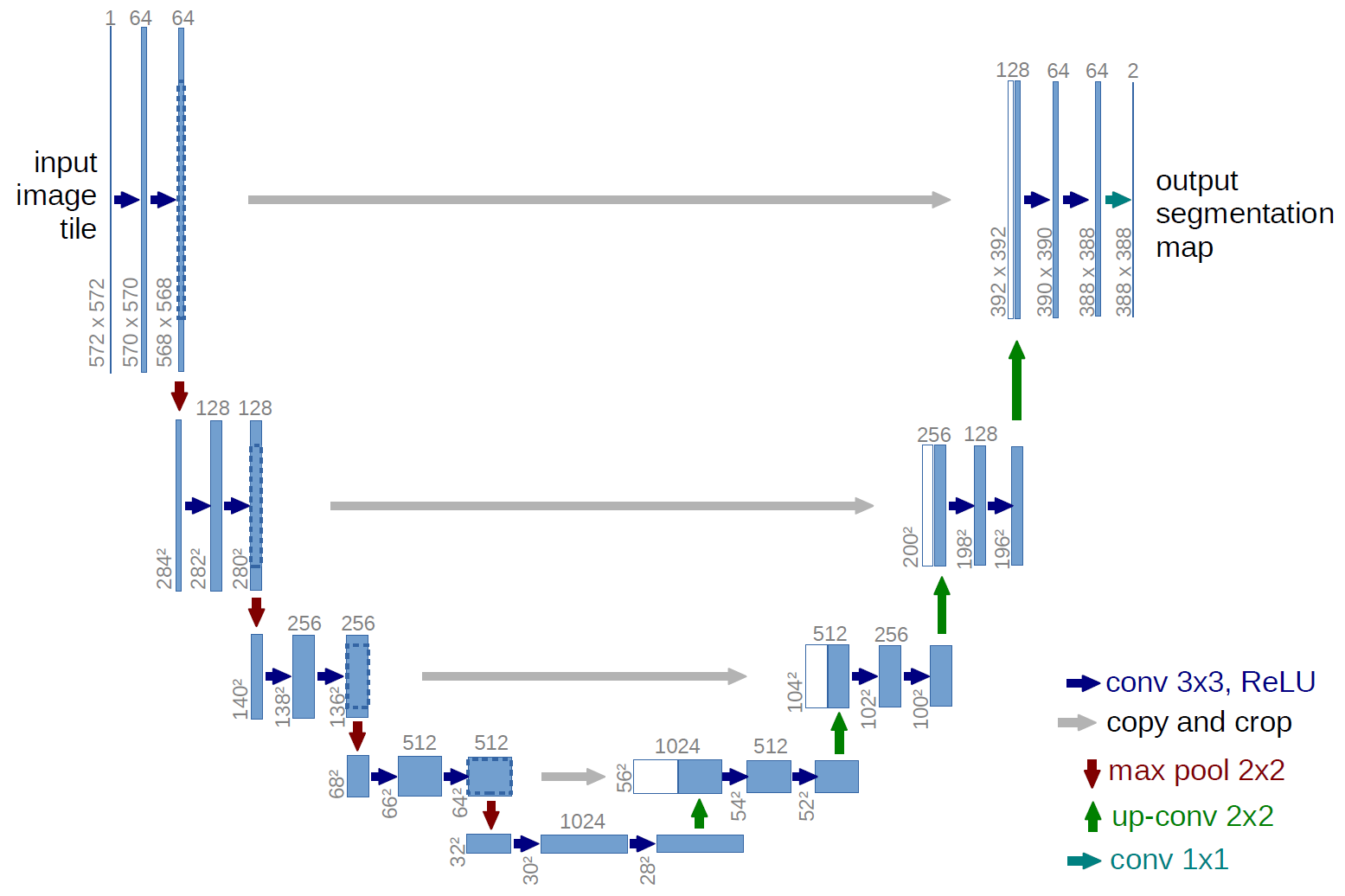
que são essas setas cinza? Essas são as chamadas conexões de salto. A questão é que o codificador “codifica” nossa imagem de entrada com perdas. Para minimizar essas perdas, eles usam conexões de salto.
Nesta tarefa, podemos usar a aprendizagem por transferência - por exemplo, podemos pegar uma rede com um codificador já treinado, adicionar um decodificador e treiná-lo.
Em quais dados e modelos têm melhor desempenho nesta tarefa no momento - você pode ver aqui...
Segmentação de instância
Uma versão mais complexa do problema de segmentação. Sua essência é que não queremos apenas classificar cada pixel da imagem de entrada, mas também selecionar de alguma forma diferentes objetos da mesma classe:
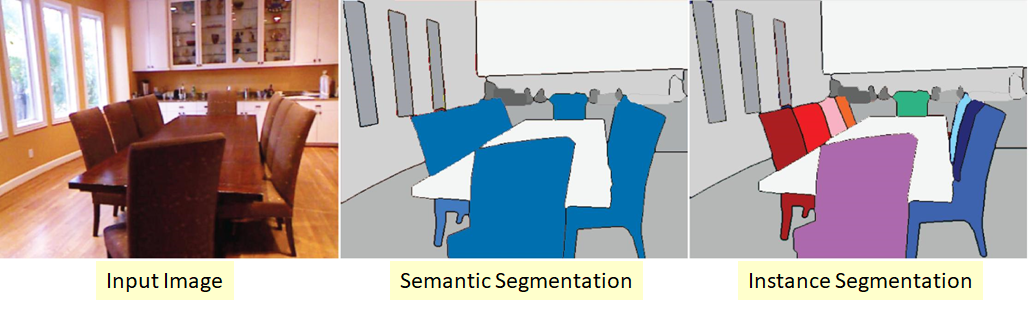
Acontece que as classes são "pegajosas" ou não há fronteira visível entre elas, mas queremos delimitar objetos da mesma classe separados.
Existem também várias abordagens aqui. O mais simples e intuitivo é que treinamos duas redes diferentes. Ensinamos o primeiro a classificar os pixels para algumas classes (segmentação semântica) e o segundo a classificar os pixels entre os objetos da classe. Temos duas máscaras. Agora podemos subtrair o segundo do primeiro e obter o que queríamos :)
Em quais dados e quais modelos têm melhor desempenho nesta tarefa no momento - você pode ver aqui...
Object detection
Enviamos uma imagem para a entrada e, na saída, queremos ver algo como:

A coisa mais intuitiva que pode ser feita é "percorrer" a imagem com retângulos diferentes e, usando um classificador já treinado, determinar se há um objeto de interesse para nós nesta área. Esse esquema existe, mas obviamente não é o melhor. Afinal, temos camadas convolucionais que de alguma forma interpretam o mapa de feições "antes" (A) no mapa de feições "depois" (B). Neste caso, sabemos as dimensões dos filtros de convolução => sabemos quais pixels de A para quais pixels B foram convertidos.
Vamos dar uma olhada no YOLO v3:
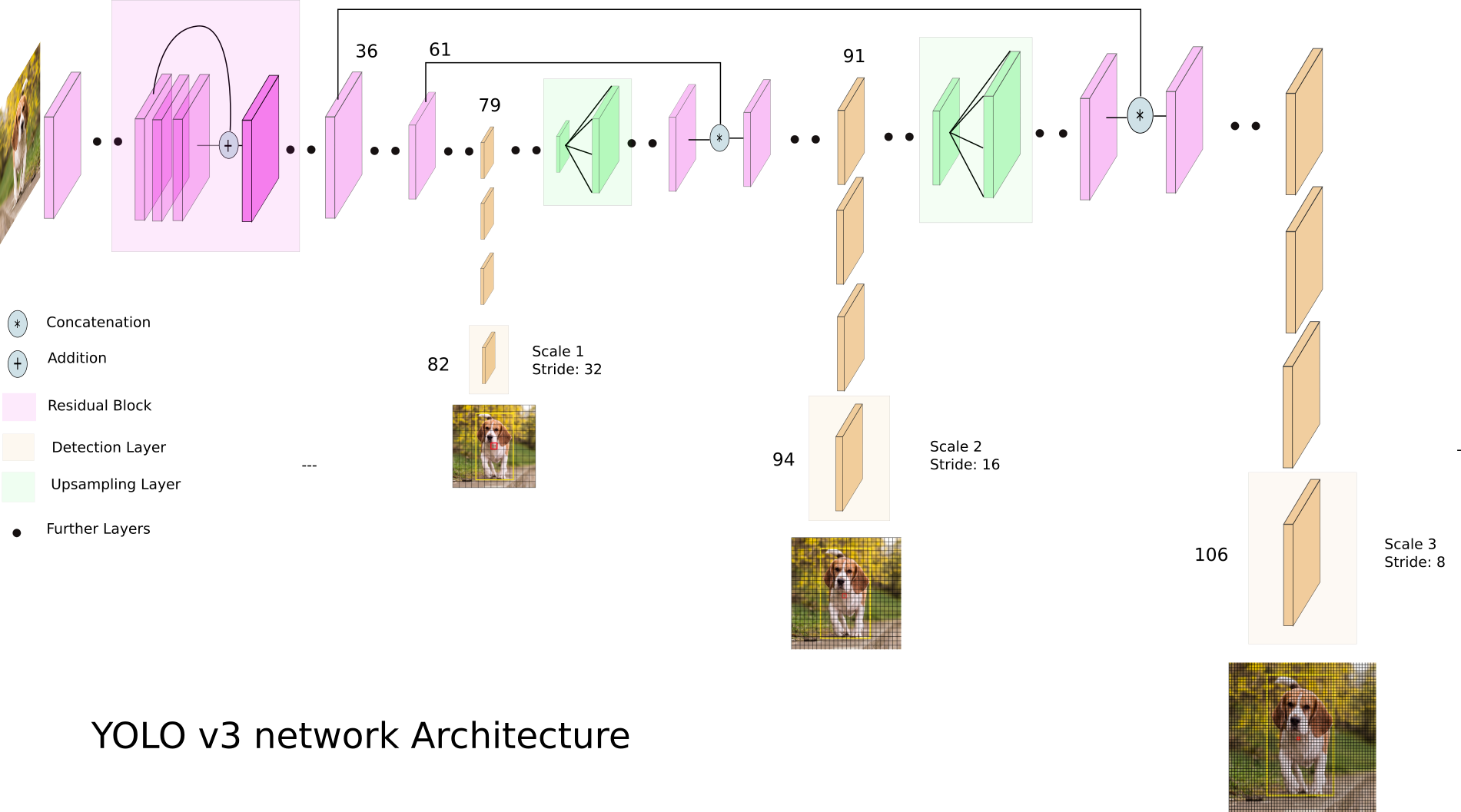
YOLO v3 usa mapas de recursos de diferentes dimensões. Isso é feito, em particular, para detectar corretamente objetos de diferentes tamanhos.
Em seguida, todas as três escalas são concatenadas:
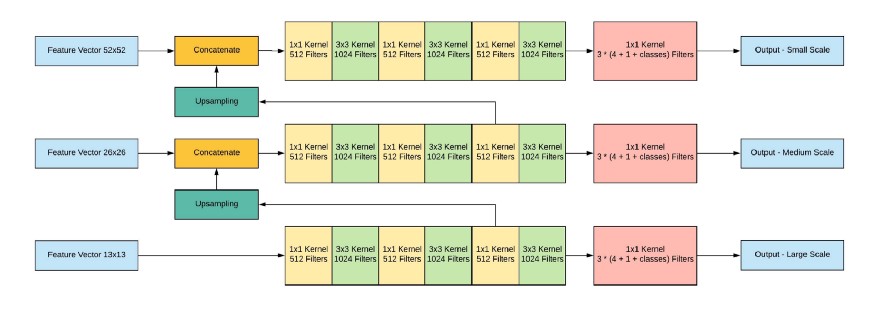
Saída de rede, com uma imagem de entrada de 416x416, 13x13x (B * (5 + C)), onde C é o número de classes, B é o número de caixas para cada região (YOLO v3 tem 3 delas). 5 - são parâmetros como: Px, Py - coordenadas do centro do objeto, Ph, Pw - altura e largura do objeto, Pobj - a probabilidade de o objeto estar nesta região.
Vejamos a imagem, para que fique um pouco mais claro: o

YOLO filtra os dados de predição inicialmente pela pontuação de objetividade por algum valor (geralmente 0,5-0,6) e, em seguida, por supressão não máxima .
Em quais dados e quais modelos têm melhor desempenho nesta tarefa no momento - você pode ver aqui .
Conclusão
Existem muitos modelos e abordagens diferentes para as tarefas de segmentação e localização de objetos atualmente. Existem certas ideias, entendendo-as, ficará mais fácil desmontar aquele zoológico de modelos e abordagens. Tentei expressar essas idéias neste artigo.
Nos próximos artigos, falaremos sobre transferências de estilo e GANs.