
Neste artigo, falaremos sobre os detalhes de implementação e operação de diferentes compiladores JIT, bem como estratégias de otimização. Discutiremos com detalhes suficientes, mas omitiremos muitos conceitos importantes. Ou seja, não haverá informações suficientes neste artigo para chegar a conclusões razoáveis em qualquer comparação de implementações e linguagens.
Para obter uma compreensão básica dos compiladores JIT, leia este artigo .
Uma pequena nota:
, , , - . , JIT ( ), , . , , , , . - , , .
- Pypy
- GraalVM C
- OSR
- JIT
()
LuaJIT usa o que é chamado de rastreamento. O Pypy realiza metatracing, ou seja, utiliza o sistema para gerar interpretadores de trace e JIT. Pypy e LuaJIT não são implementações exemplares de Python e Lua, mas projetos autônomos. Eu caracterizaria LuaJIT como chocantemente rápido, e ele se descreve como uma das implementações de linguagem dinâmica mais rápidas - e eu absolutamente acredito nisso.
Para entender quando iniciar o rastreio, o loop do interpretador procura loops ativos (o conceito de código ativo é universal para todos os compiladores JIT!). O compilador então "rastreia" o loop, gravando as operações executáveis para compilar o código de máquina bem otimizado. Em LuaJIT, a compilação é baseada em rastreamentos com uma representação intermediária semelhante a uma instrução que é única para LuaJIT.
Como o rastreamento é implementado no Pypy
O Pypy começa a rastrear a função após 1619 execuções e compila após 1039 execuções, ou seja, leva cerca de 3000 execuções da função para começar a funcionar mais rapidamente. Esses valores foram cuidadosamente escolhidos pela equipe Pypy e, em geral, no mundo dos compiladores, muitas constantes são escolhidas com cuidado.
Linguagens dinâmicas tornam a otimização difícil. O código abaixo pode ser removido estaticamente em uma linguagem mais restrita, pois
Falsesempre será falso. No entanto, no Python 2, isso não pode ser garantido até o tempo de execução.
if False:
print("FALSE")
Para qualquer programa inteligente, essa condição sempre será falsa. Infelizmente, o valor
Falsepode ser redefinido e a expressão estará em um loop, ela pode ser redefinida em outro lugar. Portanto, Pypy pode criar um "guarda". Se o defensor falhar, o JIT volta ao ciclo de interpretação. O Pypy então usa outra constante (200) chamada rastreio ansioso para decidir se compilar o resto do novo caminho antes do final do loop. Este subcaminho é chamado de ponte .
Além disso, o Pypy fornece essas constantes como argumentos que você pode personalizar em tempo de execução junto com a configuração de desenrolamento, ou seja, expansão de loop e inlining! E, além disso, fornece ganchos que podemos ver após a conclusão da compilação.
def print_compiler_info(i):
print(i.type)
pypyjit.set_compile_hook(print_compiler_info)
for i in range(10000):
if False:
pass
print(pypyjit.get_stats_snapshot().counters)
Acima, escrevi um programa Python puro com um gancho de compilação para exibir o tipo de compilação aplicada. O código também produz dados no final, que mostra o número de defensores. Para este programa, eu tenho uma compilação de loop e 66 defensores. Quando substituí a expressão por um
ifsimples passe fora do circuito for, havia apenas 59 defensores restantes.
for i in range(10000):
pass # removing the `if False` saved 7 guards!
Adicionando essas duas linhas ao loop
for, obtive duas compilações, uma das quais era do tipo "ponte"!
if random.randint(1, 100) < 20:
False = True
Espere, você estava falando sobre meta rastreamento!
A ideia de metatracing pode ser descrita como "escreva um interpretador e obtenha um compilador de graça!" Ou "transforme seu interpretador em um compilador JIT!" Escrever um compilador é difícil e, se você puder obtê-lo de graça, a ideia é ótima. Pypy "contém" um interpretador e um compilador, mas não implementa explicitamente um compilador tradicional.
Pypy tem uma ferramenta RPython (construída para Pypy). É uma estrutura para escrever intérpretes. Sua linguagem é uma espécie de Python e é tipada estaticamente. É neste idioma que você deve escrever um intérprete. A linguagem não foi projetada para programação Python digitada porque não contém bibliotecas ou pacotes padrão. Qualquer programa RPython é um programa Python válido. O código RPython é transpilado para C e então compilado. Portanto, um meta-compilador nesta linguagem existe como um programa C compilado.
O prefixo "meta" na palavra metatraces significa que o rastreamento é executado quando o interpretador está em execução, não o programa. Ele se comporta mais ou menos como qualquer outro intérprete, mas pode rastrear suas operações e é projetado para otimizar rastreios atualizando seu caminho. Com mais rastreamento, o caminho do intérprete se torna mais otimizado. Um intérprete bem otimizado segue um caminho específico. E o código de máquina usado neste caminho, obtido pela compilação do RPython, pode ser usado na compilação final.
Resumindo, o "compilador" no Pypy compila seu interpretador, e é por isso que o Pypy às vezes é chamado de meta-compilador. Ele não compila tanto o programa que você está executando, mas o caminho de um interpretador otimizado.
O conceito de metatracing pode parecer confuso, então, para fins de ilustração, escrevi um programa muito pobre que só entende
a = 0e a++to.
# interpreter written with RPython
for line in code:
if line == "a = 0":
alloc(a, 0)
elif line == "a++":
guard(a, "is_int") # notice how in Python, the type is unknown, but after being interpreted by RPython, the type is known
guard(a, "> 0")
int_add(a, 1)
Se eu executar este ciclo quente:
a = 0
a++
a++
As faixas podem ser assim:
# Trace from numerous logs of the hot loop
a = alloc(0) # guards can go away
a = int_add(a, 1)
a = int_add(a, 2)
# optimize trace to be compiled
a = alloc(2) # the section of code that executes this trace _is_ the compiled code
Mas o compilador não é um módulo separado especial, ele está embutido no interpretador. Portanto, o ciclo de interpretação será semelhante a este:
for line in code:
if traces.is_compiled(line):
run_compiled(traces.compiled(line))
continue
elif traces.is_optimized(line):
compile(traces.optimized(line))
continue
elif line == "a = 0"
# ....
Introdução ao JVM
Escrevi no TruffleRuby baseado em Graal por quatro meses e me apaixonei por ele.
Hotspot (assim chamado porque ele procura quentes manchas) é uma máquina virtual que vem com instalações Java padrão. Ele contém vários compiladores para implementar a compilação de vários níveis. A base de código de 250.000 linhas do Hotspot está aberta e tem três coletores de lixo. Dev lida com compilação JIT, em alguns benchmarks, funciona melhor do que impls C ++ (nesta ocasião como
As estratégias usadas no Hotspot inspiraram muitos autores de compiladores JIT subsequentes, estruturas de máquina virtual de linguagem e, especialmente, mecanismos Javascript. O hotspot também gerou uma onda de linguagens JVM como Scala, Kotlin, JRuby e Jython. JRuby e Jython são implementações divertidas de Ruby e Python que compilam código-fonte para bytecode JVM, que o Hotspot então executa. Todos esses projetos são relativamente bem-sucedidos em acelerar Python e Ruby (Ruby mais do que Python) sem implementar todas as ferramentas, como é o caso com Pypy. O Hotspot também é único por ser um JIT para linguagens menos dinâmicas (embora seja tecnicamente um JIT para bytecode JVM, não Java).

GraalVM é um JavaVM com um trecho de código Java. Ele pode executar qualquer linguagem JVM (Java, Scala, Kotlin, etc.). Ele também oferece suporte a Native Image para trabalhar com código compilado AOT por meio do Substrate VM. Uma proporção significativa dos serviços Scala do Twitter é executada em Graal, que fala da qualidade da máquina virtual e, de certa forma, é melhor do que a JVM, embora seja escrita em Java.
E isso não é tudo! GraalVM também fornece Truffle: uma estrutura para implementação de linguagens através da criação de interpretadores AST (Abstract Syntax Tree). Não há nenhuma etapa explícita no Truffle quando o bytecode JVM é gerado como em uma linguagem JVM regular. Em vez disso, Truffle simplesmente usará o interpretador e conversará com Graal para gerar código de máquina diretamente com criação de perfil e a chamada pontuação parcial. A avaliação parcial está além do escopo deste artigo, em poucas palavras: este método adere à filosofia "escreva um intérprete, obtenha um compilador de graça!", Mas aborda-a de forma diferente.
TruffleJS — Truffle- Javascript, V8 , , V8 , Google , . TruffleJS «» V8 ( JS-) , Graal.
JIT-
C
As implementações JIT geralmente apresentam problemas para suportar extensões C. Intérpretes padrão como Lua, Python, Ruby e PHP têm uma API para C que permite aos usuários construir pacotes nessa linguagem, acelerando significativamente a execução. Muitos pacotes são escritos em C, por exemplo numpy, funções de biblioteca padrão como
rand. Todas essas extensões C são essenciais para que uma linguagem interpretada seja executada rapidamente.
As extensões C são difíceis de manter por vários motivos. O motivo mais óbvio é que a API foi projetada com a implementação interna em mente. Além disso, é mais fácil suportar extensões C quando o interpretador é escrito em C, então JRuby não pode suportar extensões C, mas possui uma API para extensões Java. Pypy lançou recentemente uma versão beta de suporte para extensões C, embora eu não tenha certeza se funciona devido à Lei de Hyrum . LuaJIT suporta extensões C, incluindo recursos adicionais em suas extensões C (LuaJIT é simplesmente incrível!)
Graal resolve esse problema com Sulong, um mecanismo que executa bytecode LLVM no GraalVM, convertendo-o para Truffle. LLVM é uma caixa de ferramentas, e só precisamos saber que C pode ser compilado para bytecode LLVM (Julia também tem um backend LLVM!). É estranho, mas a solução é pegar uma boa linguagem compilada com mais de quarenta anos de história e interpretá-la! Claro, ele não roda tão rápido quanto o C compilado corretamente, mas tem vários benefícios.
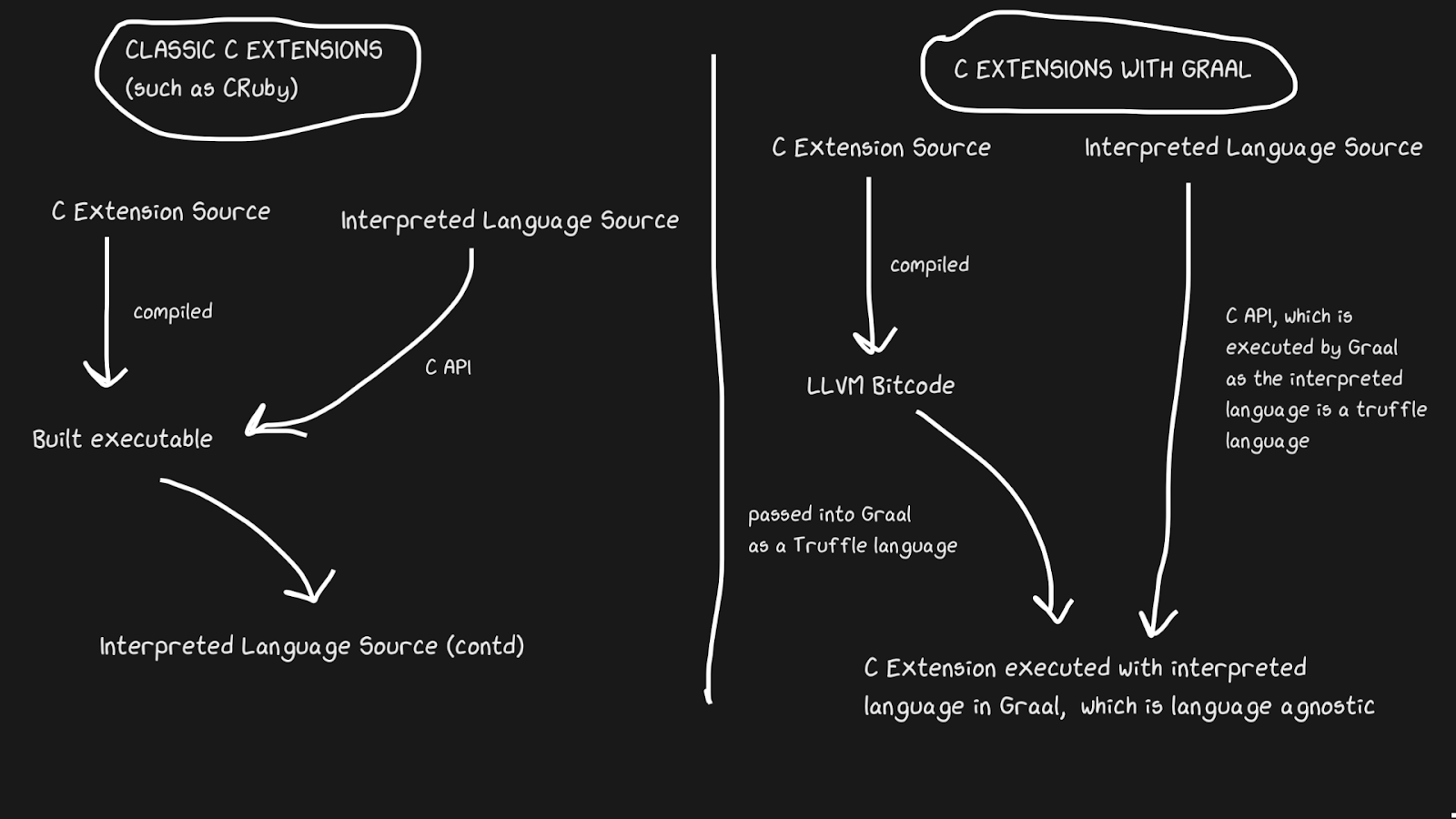
O bytecode LLVM já é de baixo nível, ou seja, não é tão ineficiente aplicar JIT a esta representação intermediária quanto a C. Parte do custo é compensado pelo fato de que o bytecode pode ser otimizado junto com o resto do programa Ruby, mas não podemos otimizar o programa C compilado ... Todas essas faixas de memória, inlining, pedaços mortos e muito mais podem ser aplicados ao código C e Ruby, em vez de chamar o binário C do código Ruby. As extensões TruffleRuby C são mais rápidas do que as extensões C CRuby em alguns aspectos.
Para que este sistema funcione, você precisa saber que o Truffle é completamente independente da linguagem e a sobrecarga de alternar entre C, Java ou qualquer outra linguagem dentro do Graal será mínima.
A capacidade de Graal de trabalhar com Sulong faz parte de suas capacidades poliglotas, que permitem alta intercambiabilidade de idiomas. Isso não é bom apenas para o compilador, mas também prova que você pode usar facilmente vários idiomas em um "aplicativo".
De volta ao código interpretado, é mais rápido
Sabemos que os JITs contêm um interpretador e um compilador, e que eles passam de interpretador a compilador para acelerar as coisas. Pypy cria pontes para o caminho de retorno, embora do ponto de vista do Graal e do Hotspot, isso seja uma desotimização . Não se trata de conceitos completamente diferentes, mas por desotimização queremos dizer um retorno ao intérprete como uma otimização consciente, e não uma solução para a inevitabilidade de uma linguagem dinâmica. Hotspot e Graal fazem uso intenso de desotimização, especialmente Graal, porque os desenvolvedores têm controle rígido sobre a compilação e precisam de ainda mais controle sobre a compilação por causa das otimizações (em comparação com, digamos, Pypy). A desotimização também é usada em mecanismos JS, sobre os quais falarei muito, já que JavaScript no Chrome e Node.js depende disso.
Para aplicar a desotimização rapidamente, é importante certificar-se de alternar entre o compilador e o interpretador o mais rápido possível. Com a implementação mais ingênua, o interpretador terá que "alcançar" o compilador para realizar a desotimização. Complicações adicionais estão associadas à desotimização de fluxos assíncronos. Graal cria um conjunto de quadros e o compara com o código gerado para retornar ao interpretador. Com os pontos seguros, você pode fazer um thread Java pausar e dizer: “Olá, coletor de lixo, preciso parar?” Para que o processamento do thread não exija muito overhead. Acabou sendo bastante rudimentar, mas funciona rápido o suficiente para que a desotimização seja uma boa estratégia.
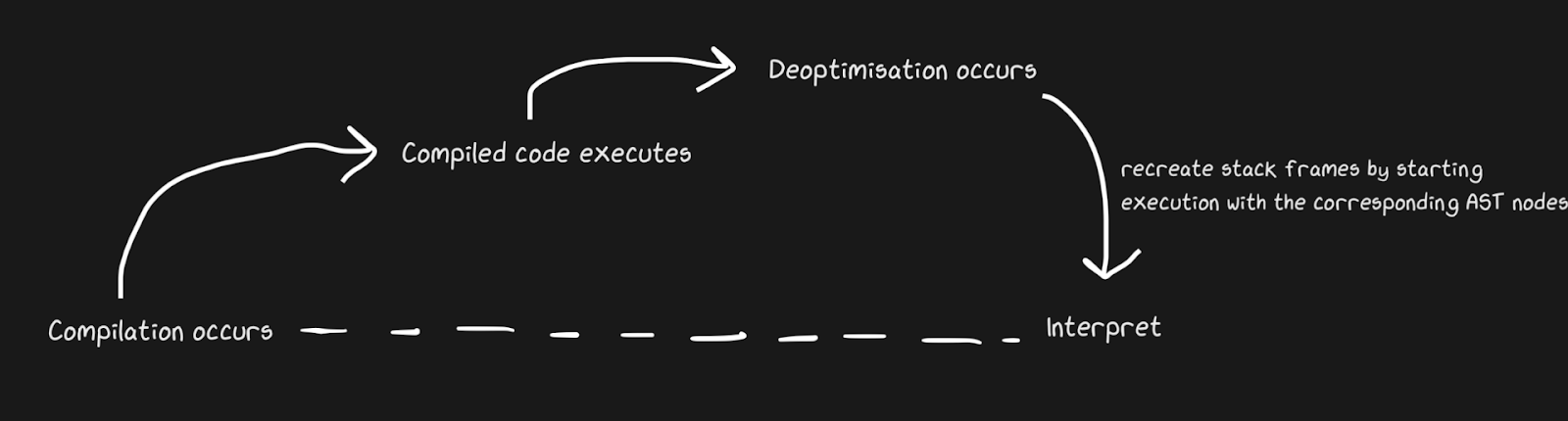
Semelhante ao exemplo de ponte Pypy, o patching de funções do macaco também pode ser desotimizado. É mais elegante porque adicionamos código de desotimização não quando o defensor falha, mas quando o patch de guerrilha é aplicado.
Um ótimo exemplo de desotimização JIT: estouro de conversão é um termo não oficial. Estamos falando de uma situação em que um determinado tipo (por exemplo,
int32) é representado / alocado internamente , mas precisa ser convertido para int64. TruffleRuby faz isso com desotimizações, assim como o V8.
Digamos, se você perguntar em Ruby
var = 0, você obterá int32(Ruby chama Fixnume Bignum, mas usarei a notação int32e int64). Executando uma operação comvar, você precisa verificar se ocorre um estouro de valor. Mas uma coisa é verificar, e compilar código que lida com overflows é caro, especialmente devido à frequência das operações numéricas.
Mesmo sem olhar para as instruções compiladas, você pode ver como essa desotimização reduz a quantidade de código.
int a, b;
int sum = a + b;
if (overflowed) {
long bigSum = a + b;
return bigSum;
} else {
return sum;
}
int a, b;
int sum = a + b;
if (overflowed) {
Deoptimize!
}
No TruffleRuby, apenas a primeira execução de uma operação específica é desotimizada, portanto, não desperdiçamos recursos sempre que uma operação estourar.
O código WET é um código rápido. Inlining e OSR
function foo(a, b) {
return a + b;
}
for (var i = 0; i < 1000000; i++) {
foo(i, i + 1);
}
foo(1, 2);
Mesmo trivialidades como esses gatilhos são desotimizadas no V8! Com opções como
--trace-deopte, --trace-optvocê pode coletar muitas informações sobre o JIT e também modificar o comportamento. Graal tem algumas ferramentas muito úteis, mas vou usar o V8 porque muitos o têm instalado.
A desotimização é iniciada pela última linha (
foo(1, 2)), o que é intrigante, porque essa chamada foi feita no loop! Receberemos uma mensagem "Feedback de tipo insuficiente para chamada" (a lista completa de motivos para a desotimização está aqui , e há um motivo engraçado para "nenhum motivo" nela). Isso cria um quadro de entrada exibindo os literais 1e 2.
Então, por que desotimizar? V8 é inteligente o suficiente para fazer typecasting: quando
ié tipointeger, literais também são passados integer.
Para entender isso, vamos substituir a última linha por
foo(i, i +1). Mas a desotimização ainda é aplicada, só que desta vez a mensagem é diferente: "Feedback de tipo insuficiente para operação binária". PORQUE?! Afinal, essa é exatamente a mesma operação realizada em loop, com as mesmas variáveis!
A resposta, meu amigo, está na substituição na pilha (OSR). Inlining é uma otimização de compilador poderosa (não apenas JIT) na qual as funções deixam de ser funções e o conteúdo é passado para o local das chamadas. Os compiladores JIT podem inline para aumentar a velocidade alterando o código em tempo de execução (linguagens compiladas só podem inline estaticamente).
// partial output from printing inlining details
[compiling method 0x04a0439f3751 <JSFunction (sfi = 0x4a06ab56121)> using TurboFan OSR]
0x04a06ab561e9 <SharedFunctionInfo foo>: IsInlineable? true
Inlining small function(s) at call site #49:JSCall
Assim, o V8 compilará
foo, determinará que pode ser em linha e em linha com OSR. No entanto, o mecanismo faz isso apenas para o código dentro do loop, porque esse é um caminho ativo e a última linha ainda não está no interpretador no momento do inlining. Portanto, o V8 ainda não tem feedback suficiente sobre o tipo de função foo, porque não é usado no loop, mas em sua versão embutida. Se aplicado --no-use-osr, então não haverá desotimização, não importa o que passemos, literal ou i. No entanto, sem inlining, mesmo um minúsculo milhão de iterações será executado consideravelmente mais lento. Os compiladores JIT realmente incorporam o princípio de nenhuma solução-apenas-trade-offs. As desotimizações são caras, mas não se comparam ao custo de encontrar métodos e inlining, que é o preferido neste caso.
Inlining é incrivelmente eficaz! Eu executei o código acima com alguns zeros extras e ele funcionou quatro vezes mais devagar com o inlining desativado.

Embora este artigo seja sobre JIT, o inlining também é eficaz em linguagens compiladas. Todas as linguagens LLVM usam ativamente inlining, porque LLVM também fará isso, embora Julia seja inline sem LLVM, isso é de sua natureza. Os JITs podem ser sequenciais usando heurísticas de tempo de execução e podem alternar entre os modos não sequencial e embutido usando OSR.
Uma nota sobre JIT e LLVM
O LLVM fornece várias ferramentas relacionadas à compilação. Julia trabalha com LLVM (note que esta é uma grande caixa de ferramentas e cada linguagem a usa de maneira diferente), assim como Rust, Swift e Crystal. Basta dizer que este é um projeto grande e maravilhoso que também oferece suporte a JITs, embora o LLVM não tenha JITs dinâmicos integrados significativos. O quarto nível de compilação JavaScriptCore usou o backend LLVM por um tempo, mas foi substituído há menos de dois anos. Desde então, esse kit de ferramentas não foi muito adequado para JITs dinâmicos, principalmente porque não foi projetado para funcionar em um ambiente dinâmico. Pypy tentou 5-6 vezes, mas decidiu pelo JSC. Com o LLVM, o afundamento de alocação e o movimento do código eram limitados.Também era impossível usar recursos JIT poderosos, como inferência de faixa (é como lançar, mas com uma faixa conhecida de valores). Mas, o mais importante, com o LLVM, muitos recursos são gastos na compilação.
E se, em vez de uma representação intermediária baseada em instruções, tivermos um grande gráfico que se modifica?
Falamos sobre o bytecode LLVM e o bytecode Python / Ruby / Java como uma representação intermediária. Todos eles se parecem com algum tipo de linguagem na forma de instruções. Hotspot, Graal e V8 usam a representação intermediária "Sea of Nodes" (introduzida no Hotspot), que é um AST de nível inferior. Esta é uma visão eficaz porque uma parte significativa da criação de perfil é baseada na noção de um certo caminho que raramente é usado (ou se sobrepõe no caso de algum padrão). Observe que esses compiladores AST são diferentes dos analisadores AST.
Normalmente, eu adoto a posição de "tente fazer em casa!" Por exemplo, não consigo ler todos os gráficos, não só por falta de conhecimento, mas também por causa das capacidades computacionais do meu cérebro (as opções do compilador podem ajudar a me livrar de um comportamento que não estou interessado).
No caso do V8, usaremos a ferramenta D8 com uma bandeira
--print-ast. Para Graal, será --vm.Dgraal.Dump=Truffle:2. O texto será exibido na tela (formatado para obter um gráfico). Não sei como os desenvolvedores V8 geram gráficos visuais, mas a Oracle tem um “Ideal Graph Visualizer” que é usado na ilustração anterior. Não tive forças para reinstalar o IGV, então peguei os gráficos de Chris Seaton, gerados com Seafoam, cuja fonte agora está fechada.
Ok, vamos dar uma olhada no JavaScript AST!
function accumulate(n, a) {
var x = 0;
for (var i = 0; i < n; i++) {
x += a;
}
return x;
}
accumulate(1, 1)
Eu executei este código
d8 --print-ast test.js, embora estejamos apenas interessados na função accumulate. Veja que só chamei uma vez, ou seja, não preciso esperar a compilação para obter o AST.
É assim que o AST se parece (removi algumas linhas sem importância):
FUNC at 19
. NAME "accumulate"
. PARAMS
. . VAR (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VAR (0x7ff535815798) (mode = VAR, assigned = false) "a"
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
. FOR at 43
. . INIT at -1
. . . BLOCK NOCOMPLETIONS at -1
. . . . EXPRESSION STATEMENT at 56
. . . . . INIT at 56
. . . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . . . LITERAL 0
. . COND at 61
. . . LT at 61
. . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . VAR PROXY parameter[0] (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . BODY at -1
. . . BLOCK at -1
. . . . EXPRESSION STATEMENT at 77
. . . . . ASSIGN_ADD at 79
. . . . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . . . VAR PROXY parameter[1] (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . NEXT at 67
. . . EXPRESSION STATEMENT at 67
. . . . POST INC at 67
. . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. RETURN at 91
. . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
É difícil analisar isso, mas é semelhante ao AST de um analisador (não é verdadeiro para todos os programas). E o próximo AST é gerado usando Acorn.js.
Uma diferença notável é a definição das variáveis. No AST do analisador, não há definição explícita de parâmetros e a declaração do loop está oculta no nó
ForStatement. Em um AST no nível do compilador, todas as declarações são agrupadas com endereços e metadados.
O compilador AST também usa essa expressão estúpida
VAR PROXY. O AST do analisador não pode determinar a relação entre nomes e variáveis (por endereços) devido a içamento de variáveis (içamento), avaliação (eval) e outros. Portanto, o AST do compilador usa variáveis PROXYque mais tarde são associadas à variável real.
// This chunk is the declarations and the assignment of `x = 0`
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
E é assim que se parece o AST do mesmo programa, obtido no Graal!
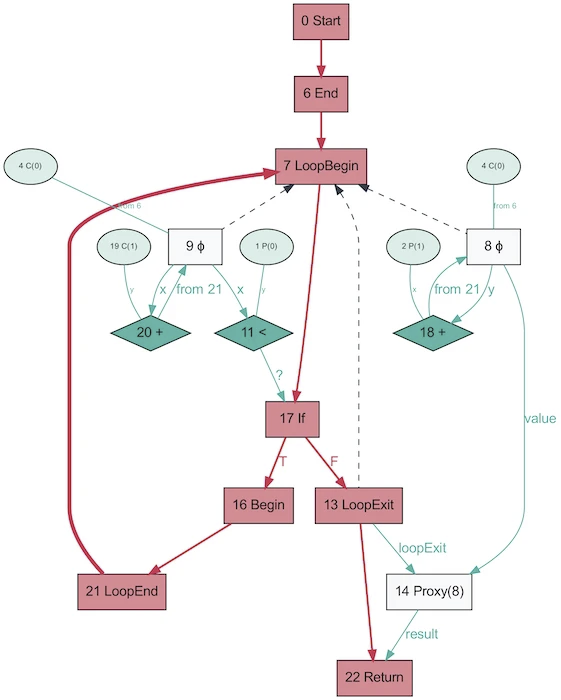
Parece muito mais simples. Vermelho indica fluxo de controle, azul indica fluxo de dados e setas indicam direções. Observe que, embora este gráfico seja mais simples do que o AST do V8, isso não significa que o Graal seja melhor para simplificar o programa. É apenas gerado com base em Java, que é muito menos dinâmico. O mesmo gráfico Graal gerado a partir do Ruby ficará mais próximo da primeira versão.
É engraçado que AST no Graal mudará dependendo da execução do código. Este gráfico é gerado com OSR desabilitado e embutido, quando a função é repetidamente chamada com parâmetros aleatórios para que não seja otimizada. E o despejo irá fornecer a você um monte de gráficos! Graal usa um AST especializado para otimizar programas (V8 faz otimizações semelhantes, mas não no nível AST). Ao salvar gráficos no Graal, você obtém mais de dez esquemas com diferentes níveis de otimização. Ao reescrever nós, eles se substituem (se especializam) por outros nós.
O gráfico acima é um excelente exemplo de especialização em uma linguagem digitada dinamicamente (foto tirada de One VM para Rule Them All, 2013). O motivo da existência desse processo está intimamente relacionado ao funcionamento da avaliação parcial - trata-se apenas de especialização.
Hooray JIT compilou o código! Vamos compilar novamente! E de novo!
Acima eu mencionei sobre "multinível", vamos falar sobre isso. A ideia é simples: se ainda não estivermos prontos para criar um código totalmente otimizado, mas a interpretação ainda for cara, podemos pré-compilar e depois compilar quando estivermos prontos para gerar um código mais otimizado.
Hotspot é um JIT em camadas com dois compiladores, C1 e C2. C1 faz uma compilação rápida e executa o código, em seguida, faz um perfil completo para obter o código compilado com C2. Isso pode ajudar a resolver muitos problemas de aquecimento. De qualquer forma, o código compilado não otimizado é mais rápido do que a interpretação. Além disso, C1 e C2 não compilam todo o código. Se a função parecer bastante simples, com uma alta probabilidade de C2 não nos ajudará e nem mesmo será executada (também economizaremos tempo na criação de perfil!). Se C1 estiver ocupado compilando, a criação de perfil pode continuar, o trabalho de C1 será interrompido e a compilação com C2 será iniciada.
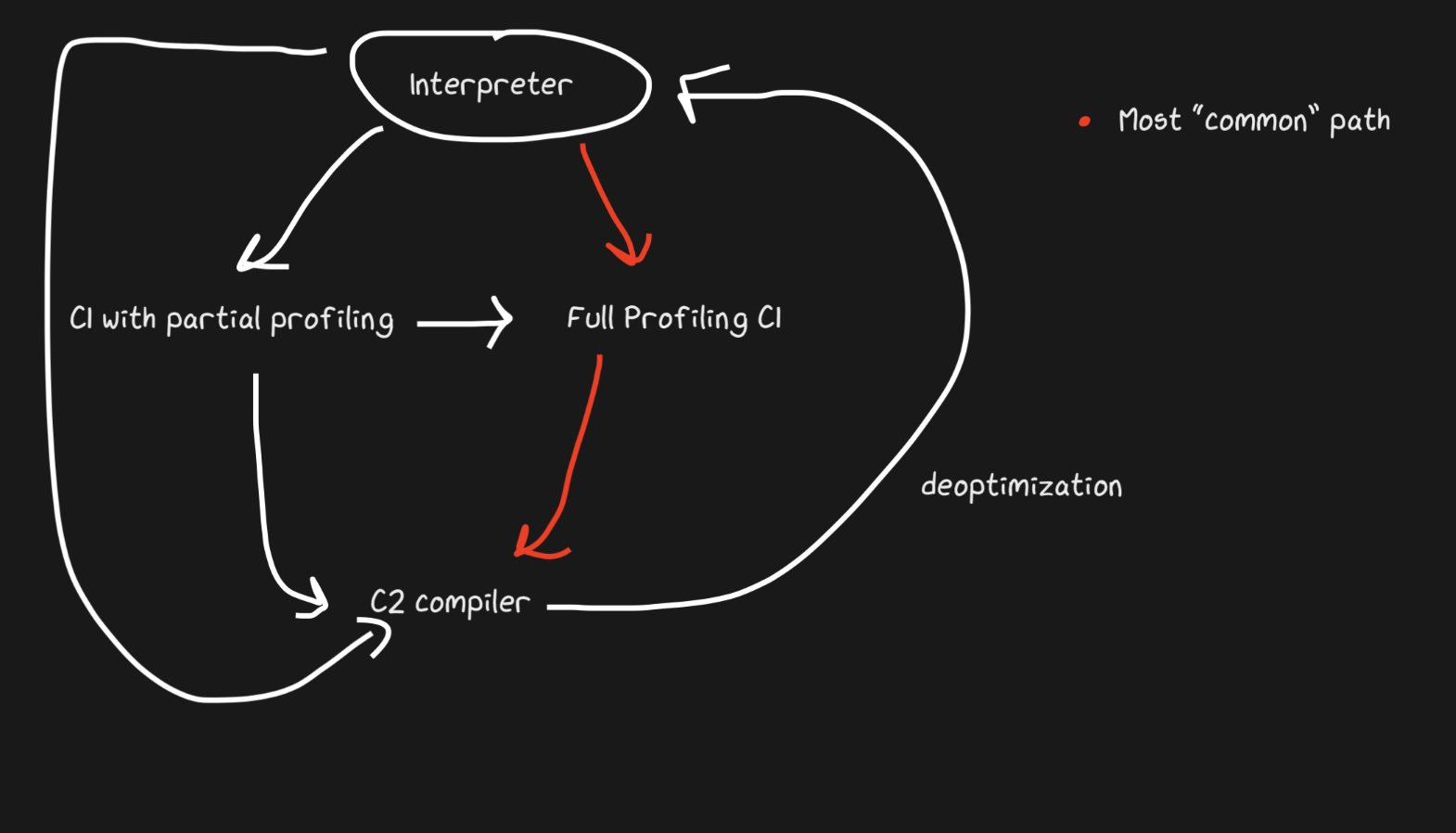
JavaScript Core tem ainda mais níveis! Na verdade, existem três JITs . O interpretador JSC faz alguns perfis de luz, então vai para Baseline JIT, então DFG (Gráfico de Fluxo de Dados) JIT e finalmente FTL (Faster than Light) JIT. Com tantos níveis, o significado da desotimização não está mais limitado à transição do compilador para o interpretador, a desotimização pode ser realizada começando com DFG e terminando com Baseline JIT (este não é o caso no caso do Hotspot C2-> C1). Todas as desotimizações e transições para o próximo nível são realizadas usando OSR (Stack Override).
O JIT de linha de base se conecta após cerca de 100 execuções e o DFG JIT após cerca de 1000 (com algumas exceções). Isso significa que o JIT obtém o código compilado muito mais rápido do que o mesmo Pypy (que leva cerca de 3.000 execuções). As camadas permitem que o JIT tente correlacionar a duração da execução do código com a duração de sua otimização. Existem vários truques sobre que tipo de otimização (inlining, casting, etc.) executar em cada um dos níveis e, portanto, essa estratégia é ideal.
Fontes úteis
- Como funciona o compilador de rastreamento de LuaJIT, de Mike Pall
- Impacto do Meta-rastreamento em VMs por Laurie Tratt
- Análise de escape Pypy
- Por que os usuários não ficam mais felizes com as VMs por Laurie Tratt
- Sobre mecanismos JS:
- Sobre a desotimização:
- Graal:
- :
- :