
Continuando o ciclo de notas sobre problemas reais em Ciência de Dados, hoje vamos lidar com um problema vivo e ver quais problemas nos esperam ao longo do caminho.
Por exemplo, além de Data Science, há muito tempo gosto do atletismo e um dos objetivos da corrida para mim, claro, é a maratona. E onde está a maratona e a questão é - quanto correr? Muitas vezes, a resposta a esta pergunta é dada de olho - "bem, em média, eles correm" ou "esta é uma boa hora"!
E hoje vamos chegar a um assunto importante - vamos aplicar a Ciência de Dados na vida real e responder à pergunta: o
que os dados sobre a maratona de Moscou nos dizem?
Mais precisamente, como já está claro na tabela no início - vamos coletar dados, descobrir quem correu e como. E ao mesmo tempo nos ajudará a entender se devemos nos intrometer e nos permitirá avaliar sensatamente nossos pontos fortes!
TL; DR: Coletei dados sobre as corridas de maratona de Moscou de 2018/2019, analisei o tempo e o desempenho dos participantes e disponibilizei o código e os dados ao público.
Coleção de dados
Por meio de uma pesquisa rápida no Google, encontramos os resultados dos últimos dois anos, 2019 e 2018 .
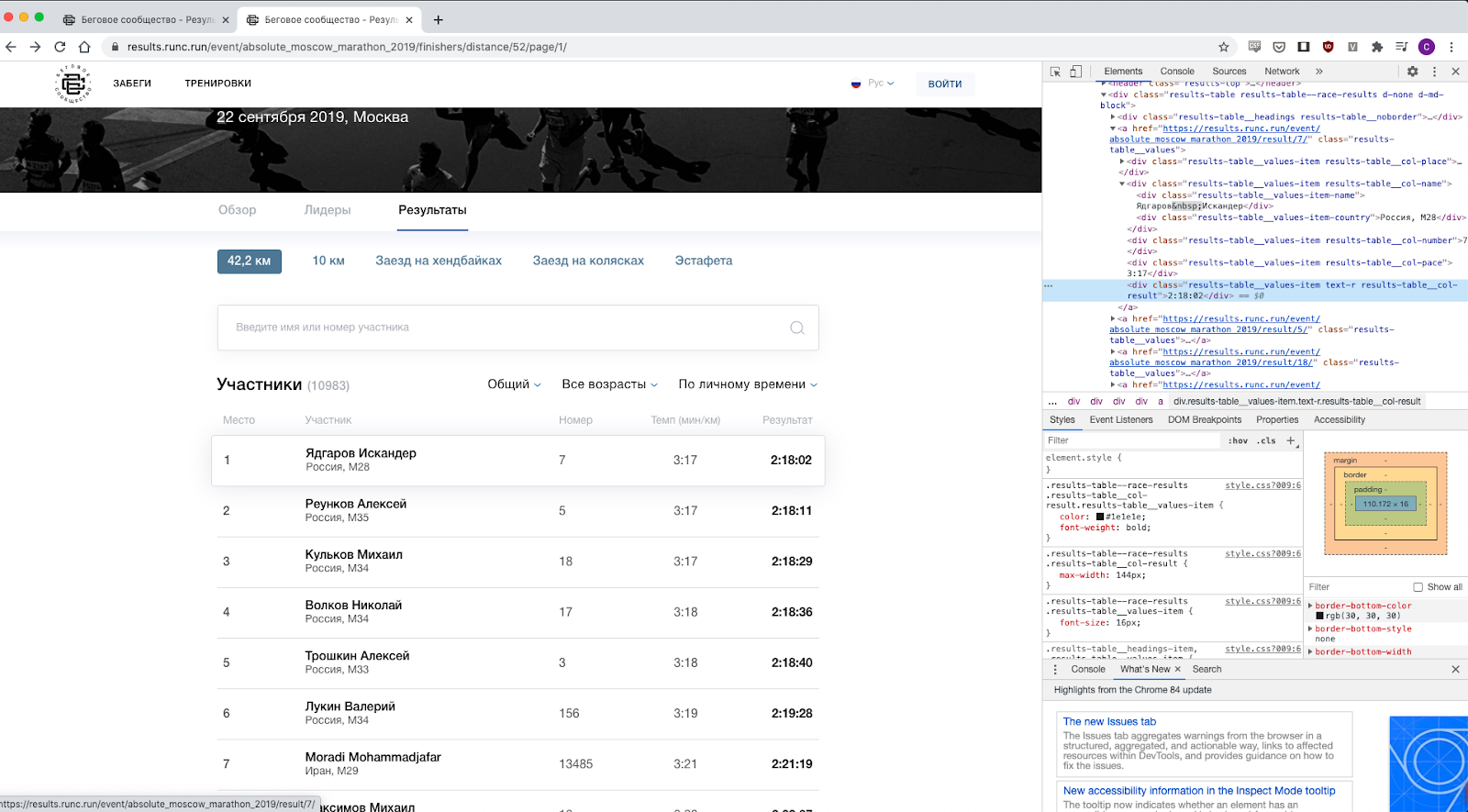
Olhei atentamente a página da web, ficou claro que os dados são bastante fáceis de obter - você só precisa descobrir quais classes são responsáveis pelo que, por exemplo, a classe “resultados-tabela__col-resultado”, é claro, pelo resultado, etc.
Resta entender como obter todos os dados de lá.
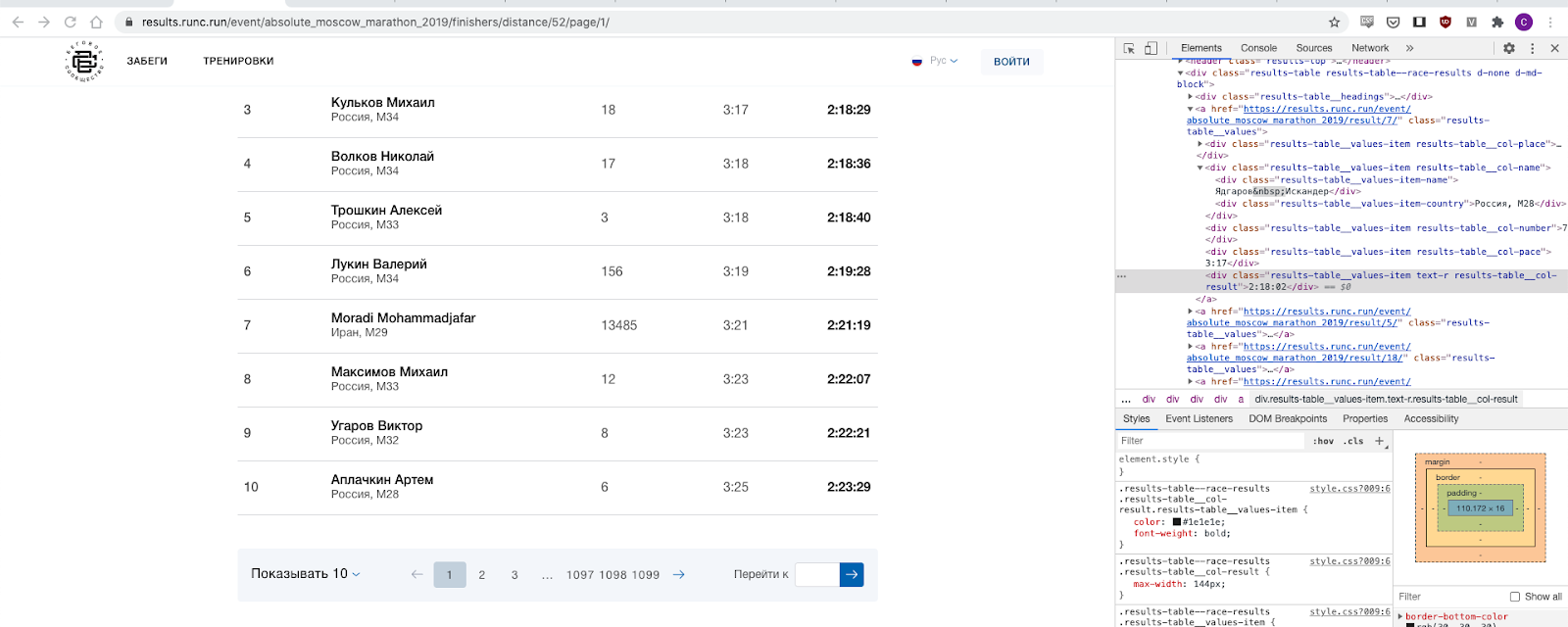
E isso, ao que parece, não é difícil, porque há paginação direta e realmente iteramos sobre todo o segmento de números. Bingo, posto os dados coletados de 2019 e 2018 aqui, se alguém tiver interesse em uma análise mais aprofundada, os próprios dados podem ser baixados aqui: aqui e aqui .
O que eu tenho que mexer?
- — - , , - (, ).
- - , — « ».
- Url- — - , url — , — .
- — — 2016, 2017… , 2019 — , — , — , , .
- NA: DNF, DQ, "-" — , , .
- Tipos de dados: o tempo aqui é timedelta, mas devido a reinicializações e valores inválidos, temos que trabalhar com filtros e limpar valores de tempo para que operemos em resultados de tempo puro para calcular médias - todos os resultados aqui são a média daqueles que terminaram e quem tem uma hora válida.
E aqui está o código do spoiler, caso alguém decida continuar coletando dados interessantes em execução.
Código do analisador
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm
def main():
for year in [2018]:
print(f"processing year: {year}")
crawl_year(year)
def crawl_year(year):
outfilename = f"results_{year}.txt"
with open(outfilename, "a") as fout:
print("name,result,place,country,category", file=fout)
# parametorize year
for i in tqdm(range(1, 1100)):
url = f"https://results.runc.run/event/absolute_moscow_marathon_2018/finishers/distance/1/page/{i}/"
html = requests.get(url)
soup = BeautifulSoup(html.text)
names = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__values-item-name"}),
)
)
results = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-result"}),
)
)[1:]
categories = list(
map(
lambda x: x.text.strip().replace(" ",""),
soup.find_all("div", {"class": "results-table__values-item-country"}),
)
)
places = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-place"}),
)
)[1:]
for name, result, place, category in zip(names, results, places, categories):
with open(outfilename, "a") as fout:
print(name, result, place, category, sep=",", file=fout)
if __name__ == "__main__":
main()
```
Análise de tempo e resultados
Vamos analisar os dados e os resultados reais da corrida.
Usei pandas, numpy, matplotlib e seaborn - tudo nos clássicos.
Além dos valores médios para todas as matrizes, consideraremos separadamente os seguintes grupos:
- Homens - como pertenço a este grupo, esses resultados me interessam.
- As mulheres são pela simetria.
- 35 — «» , — .
- 2018 2019 — ?.
Primeiro, vamos dar uma olhada rápida na tabela abaixo - aqui novamente, para não rolar: há mais participantes, 95% em média alcançam a linha de chegada, e a maioria dos participantes são homens. Ok, isso significa que em média estou no grupo principal e os dados em média devem representar bem o tempo médio para mim. Vamos continuar.
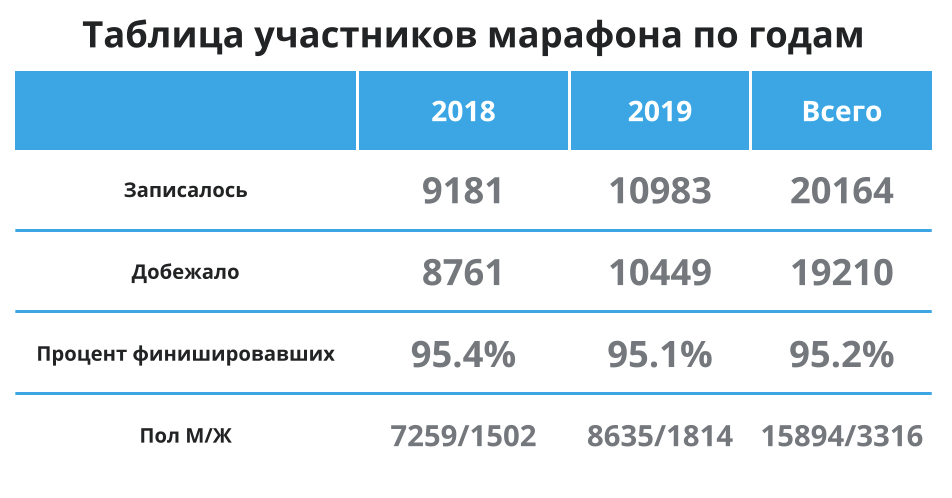

Como podemos ver, as médias para 2018 e 2019 praticamente não mudaram - cerca de 1,5 minutos foram mais rápidos para os corredores em 2019. A diferença entre os grupos nos quais estou interessado é insignificante.
Vamos passar para as distribuições como um todo. E primeiro ao tempo total da corrida.
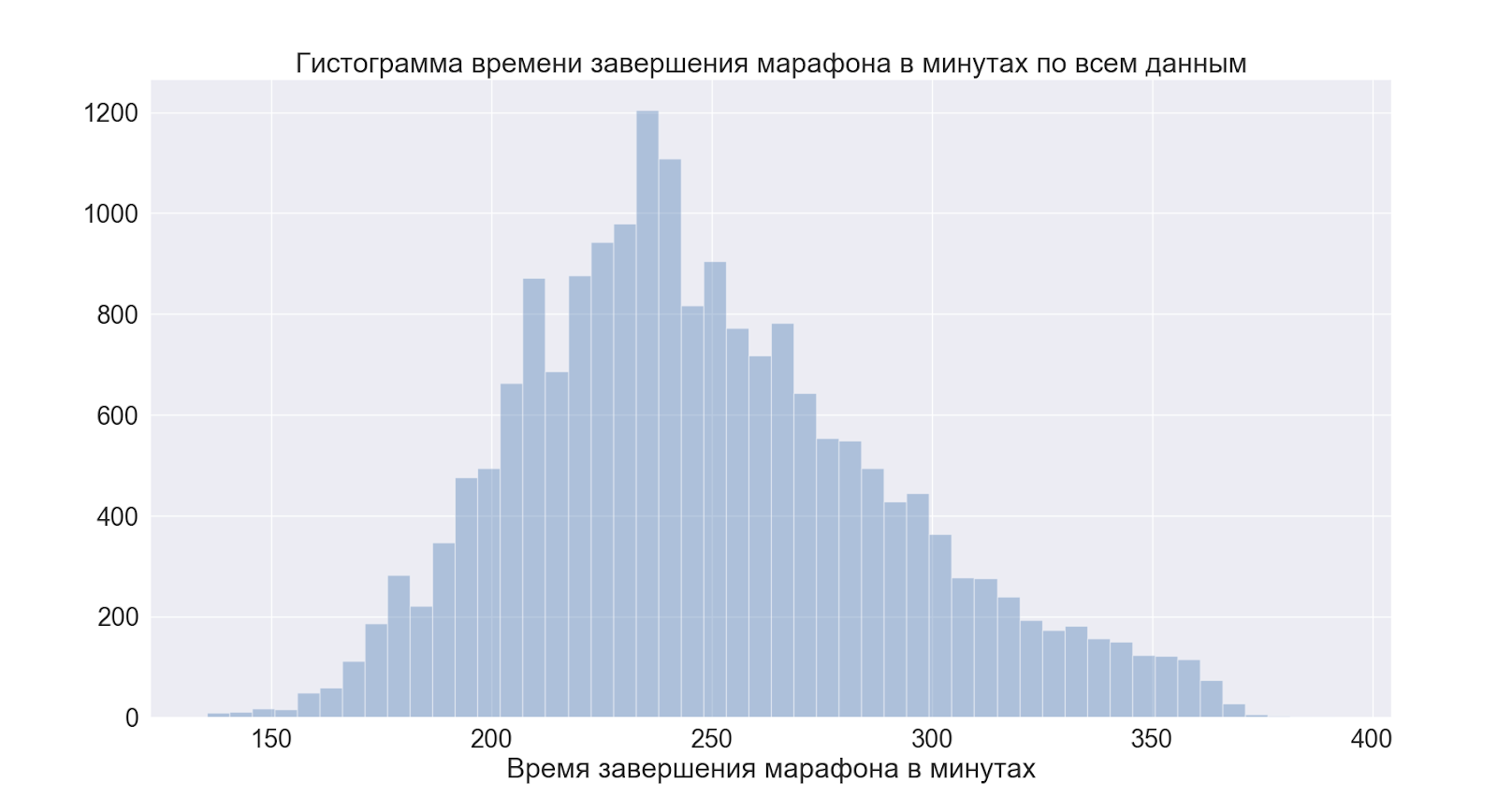
Como podemos ver o pico pouco antes das 4 horas - esta é uma marca condicional para quem gosta de “correr bem” = “esgotar as 4 horas”, os dados confirmam o boato popular.
A seguir, vamos ver como a situação mudou na média ao longo do ano.
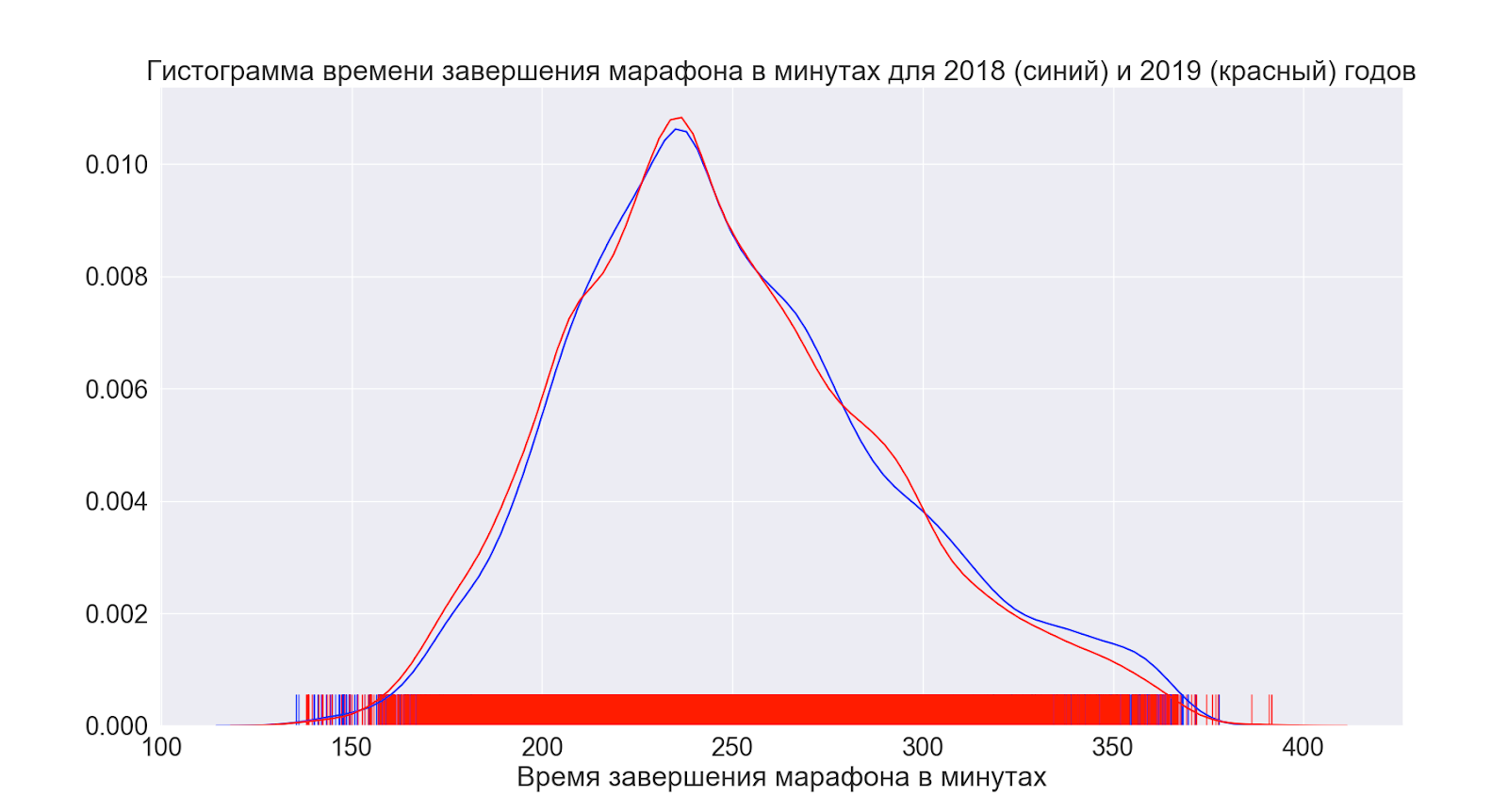
Como podemos ver, na verdade, nada mudou - as distribuições parecem virtualmente idênticas.
A seguir, considere as distribuições por gênero:

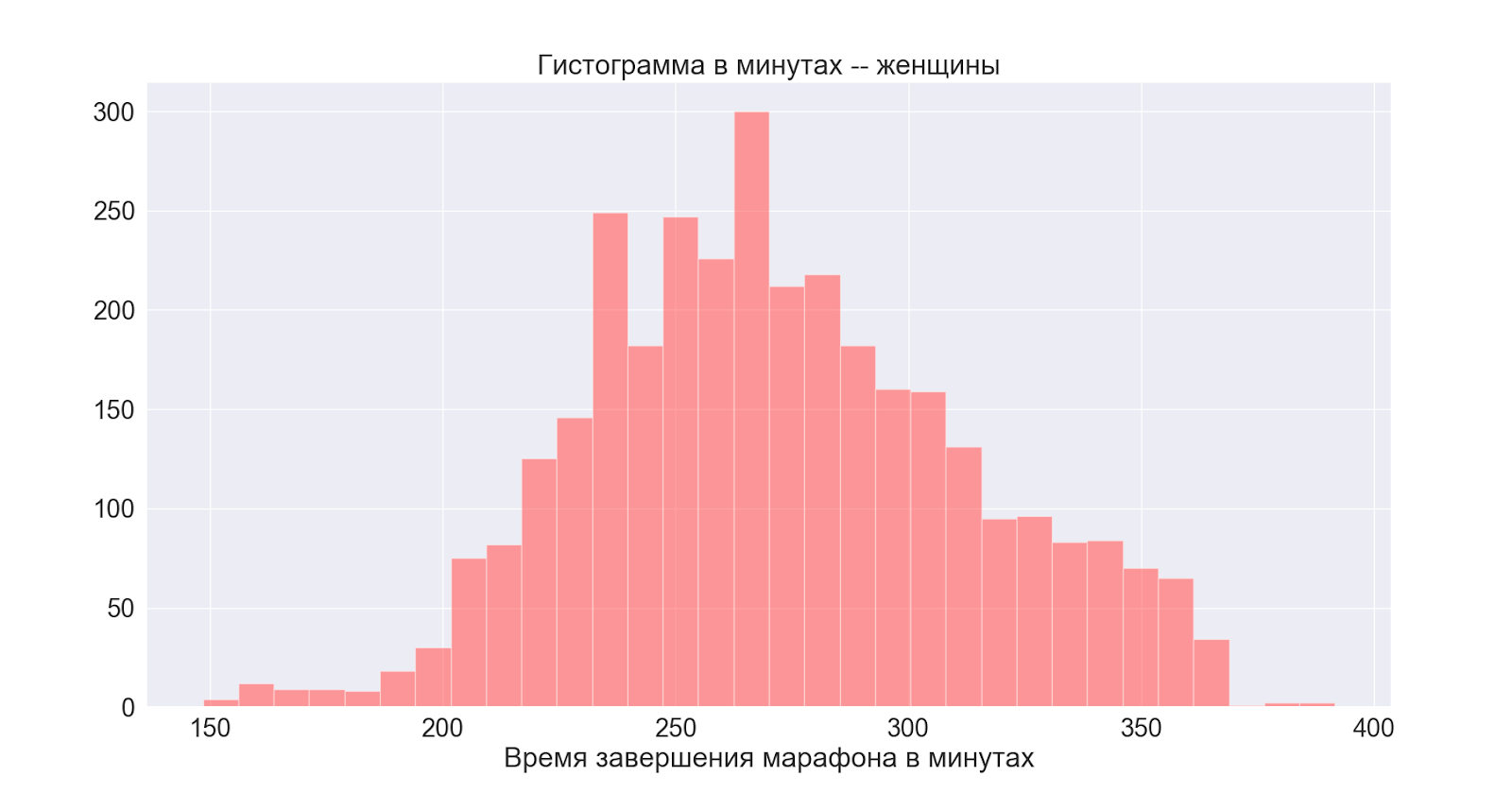
Em geral, ambas as distribuições são normais com centros ligeiramente diferentes - vemos que o pico no homem também se manifesta na distribuição principal (geral).
Separadamente, vamos passar para o grupo mais interessante para mim:
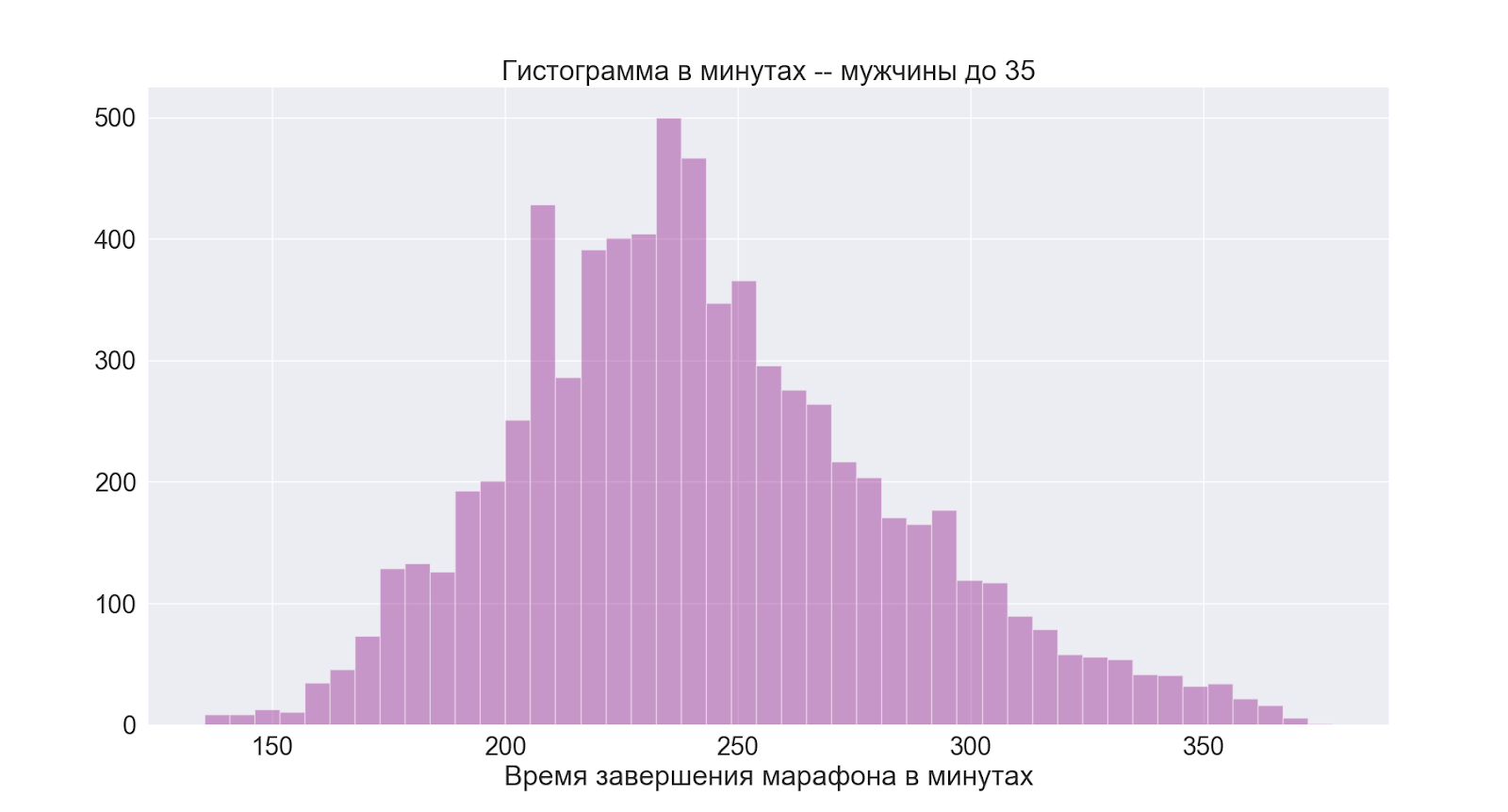
Como podemos ver, a imagem é basicamente a mesma do grupo masculino como um todo.
Concluímos que 4 horas também é um bom tempo médio para mim.
Estudando as melhorias dos participantes 2018 → 2019
É interessante: por algum motivo, pensei que agora coletaria os dados rapidamente e poderia me aprofundar na análise, procurar padrões por horas e assim por diante. Aconteceu o contrário, a coleta de dados acabou sendo mais difícil do que a própria análise - segundo os clássicos, trabalhar com a rede, dados brutos, limpeza, formatação, casting etc., demorava muito mais do que análise e visualização. Não se esqueça de que as pequenas coisas demoram um pouco - mas são algumas [pequenas coisas] e, no fim, comem a noite inteira.
Separadamente, eu queria ver como as pessoas que participaram nas duas vezes melhoraram seus resultados, comparando os dados entre os anos, consegui estabelecer o seguinte:
- 14 pessoas participaram em ambos os anos e nunca terminaram
- 89 pessoas correram a 18 m, mas falharam aos 19
- 124 vice-versa
- Aqueles que conseguiram correr nas duas vezes melhoraram seu resultado em 4 minutos em média
Mas aqui tudo acabou sendo bastante interessante:
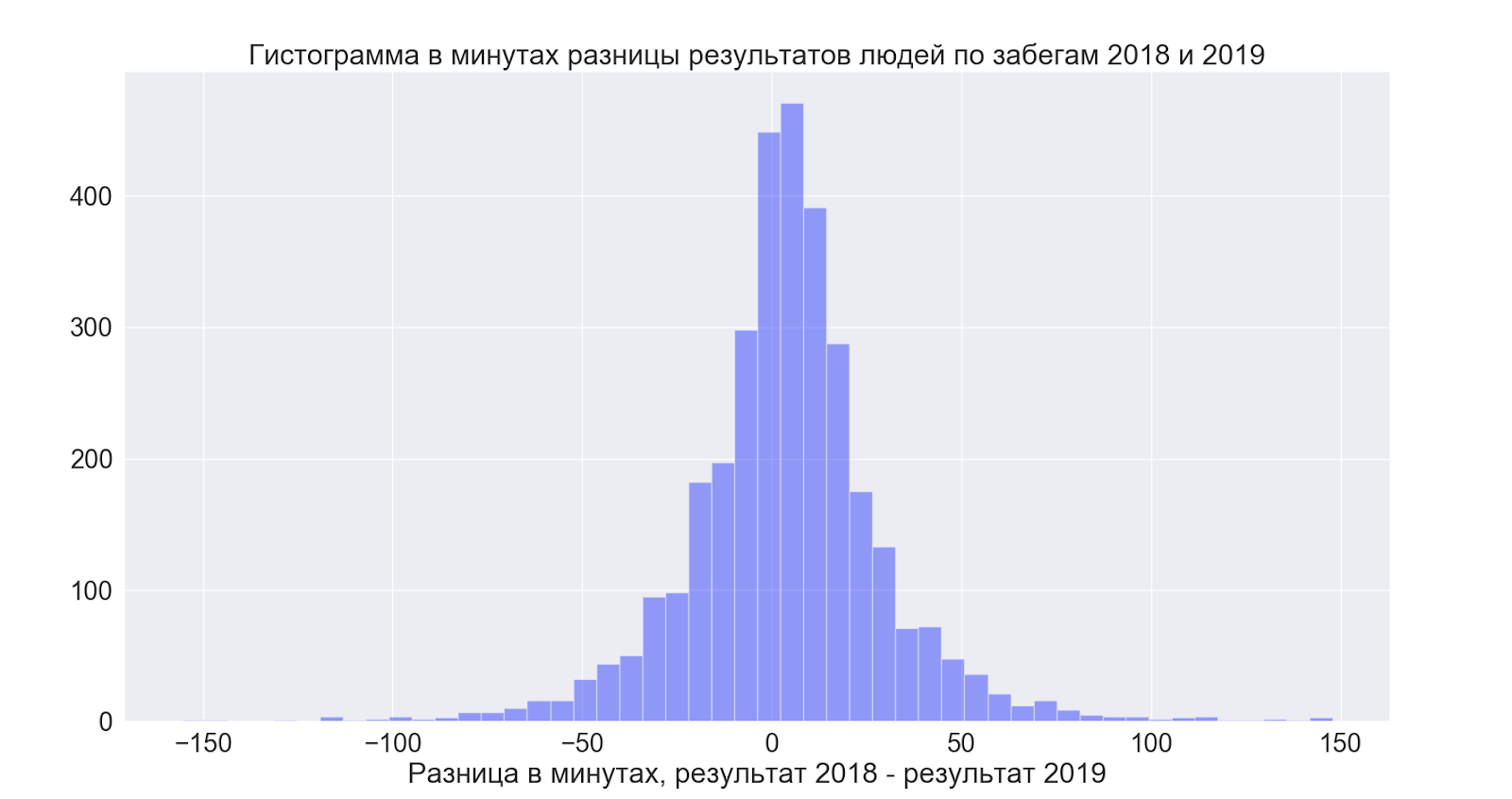
Ou seja, em média, as pessoas melhoram um pouco os resultados - mas em geral a propagação é incrível e nas duas direções - ou seja, é bom esperar que seja melhor - mas a julgar pelos dados, em geral fica como você gosta!
conclusões
Eu tirei as seguintes conclusões para mim mesmo a partir dos dados analisados
- No geral, 4 horas é um bom alvo médio.
- O grupo principal de corredores já está em idade muito competitiva (e no mesmo grupo que eu).
- Em média, as pessoas melhoram ligeiramente seus resultados, mas, em geral, a julgar pelos dados, como eles chegam lá.
- Os resultados médios de toda a corrida são aproximadamente os mesmos nos dois anos.
- É muito confortável falar sobre a maratona do sofá.
