
Olá, Habr! Mais recentemente, escrevemos sobre um conjunto de dados aberto montado por uma equipe de alunos de pós-graduação em Ciência de Dados da NUST MISIS e Zavtra.Online (departamento universitário da SkillFactory) como parte do primeiro Dataton educacional. E hoje vamos apresentar a vocês até 3 conjuntos de dados de equipes que também chegaram à final.
Todos são diferentes: alguns pesquisaram o mercado da música, alguns pesquisaram o mercado de trabalho de especialistas em informática e alguns estudaram gatos domésticos. Cada um desses projetos é relevante em sua própria área e pode ser usado para melhorar algo no curso normal do trabalho. Um conjunto de dados com gatos, por exemplo, ajudará os jurados nas exposições. Os conjuntos de dados que os alunos tiveram que coletar tiveram que ser MVP (tabela, json ou estrutura de diretório), os dados tiveram que ser limpos e analisados. Vamos ver o que eles fizeram.
Conjunto de dados 1: deslize em ondas musicais com surfistas de dados
Alinhar:
- Plotnikov Kirill - gerente de projeto, desenvolvimento, documentação.
- Dmitry Tarasov - desenvolvimento, coleta de dados, documentação.
- Shadrin Yaroslav - desenvolvimento, coleta de dados.
- Merzlikin Artyom - gerente de produto, apresentação.
- Ksenia Kolesnichenko - análise preliminar dos dados.
Como parte de sua participação no hackathon, os membros da equipe propuseram várias idéias interessantes diferentes, mas decidimos nos concentrar na coleta de dados sobre artistas musicais russos e suas melhores faixas do Spotify e MusicBrainz.
O Spotify é uma plataforma de música que chegou à Rússia não há muito tempo, mas já está ativamente ganhando popularidade no mercado. Além disso, em termos de análise de dados, o Spotify fornece uma API muito conveniente com a capacidade de consultar uma grande quantidade de dados, incluindo suas próprias métricas, como "danceability" - uma pontuação de 0 a 1 que descreve o quão boa é uma faixa para dançar.
MusicBrainzÉ uma enciclopédia musical que contém as informações mais completas sobre grupos musicais existentes e existentes. Uma espécie de "wikipedia musical". Precisávamos de dados desse recurso para obter uma lista de todos os artistas da Rússia.
Coletando dados de artistas
Compilamos uma tabela inteira contendo 14.363 entradas exclusivas para vários artistas. Para facilitar a navegação nele, há uma descrição dos campos da tabela sob o spoiler.
Descrição dos campos da tabela
artist – ;
musicbrainz_id – Musicbrainz;
spotify_id – Spotify, ;
type – , Person, Group, Other, Orchestra, Choir Character;
followers – Spotify;
genres – ;
popularity – Spotify 0 100, .
musicbrainz_id – Musicbrainz;
spotify_id – Spotify, ;
type – , Person, Group, Other, Orchestra, Choir Character;
followers – Spotify;
genres – ;
popularity – Spotify 0 100, .

Exemplo de Record
Fields artist, musicbrainz_id e type são recuperados do banco de dados de música Musicbrainz, uma vez que existe uma oportunidade de obter uma lista de artistas associados a um país. Existem duas maneiras de recuperar esses dados:
- Analise a seção Artistas na página com informações sobre a Rússia.
- Obtenha dados via API.
Documentação da API MusicBrainz Exemplo de pesquisa da
documentação da API MusicBrainz Solicitação GET em musicbrainz.org
No decorrer do trabalho, descobriu-se que a API MusicBrainz não responde corretamente a uma solicitação com o parâmetro Area: Russia, escondendo de nós os artistas que possuem uma Area especificada, por exemplo, Izhevsk ou Moskva. Portanto, os dados do MusicBrainz foram obtidos pelo analisador diretamente do site. Abaixo está um exemplo da página de onde os dados foram analisados.
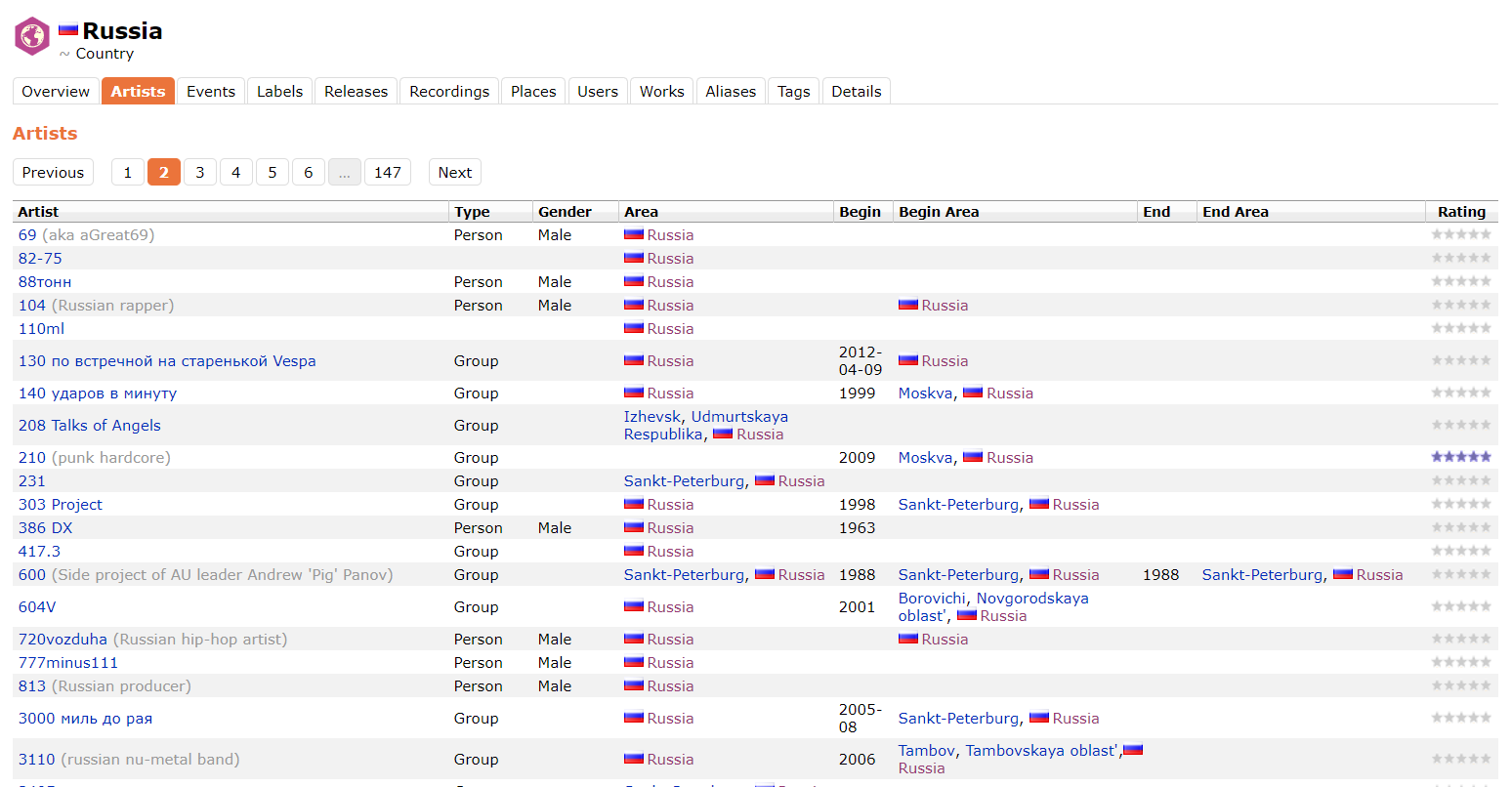
Os dados obtidos sobre os artistas do Musicbrainz.
O restante dos campos são obtidos como resultado de solicitações GET para o terminal . Ao enviar uma solicitação, especifique o nome do artista no valor do parâmetro q e especifique artist no valor do parâmetro type.
Coletando dados sobre faixas populares
A tabela contém 44473 registros das faixas mais populares de artistas russos, apresentadas na tabela acima. Abaixo do spoiler, há uma descrição dos campos da tabela.
Descrição dos campos da tabela
artist – ;
artist_spotify_id – Spotify ( , spotify_id );
name – ;
spotify_id – Spotify;
duration_ms – ;
explicit – , true false;
popularity – Spotify *;
album_type – , album, single compilation;
album_name – ;
album_spotify_id – Spotify;
release_date – ;
album_popularity – Spotify.
artist_spotify_id – Spotify ( , spotify_id );
name – ;
spotify_id – Spotify;
duration_ms – ;
explicit – , true false;
popularity – Spotify *;
album_type – , album, single compilation;
album_name – ;
album_spotify_id – Spotify;
release_date – ;
album_popularity – Spotify.
Recursos de áudio
key – , , 0 = C, 1 = C♯/D♭, 2 = D ..;
mode – , – 1, – 0;
time_signature – ;
acousticness – 0,0 1,0 , ;
danceability – , 0,0 1,0;
energy – 0,0 1,0;
instrumentalness – , , 0,0 1.0;
liveness – , 0,0 1,0;
loudness – , -60 0 ;
speechiness – , 0,0 1,0;
valence – «», , 0,0 1,0;
tempo – .
mode – , – 1, – 0;
time_signature – ;
acousticness – 0,0 1,0 , ;
danceability – , 0,0 1,0;
energy – 0,0 1,0;
instrumentalness – , , 0,0 1.0;
liveness – , 0,0 1,0;
loudness – , -60 0 ;
speechiness – , 0,0 1,0;
valence – «», , 0,0 1,0;
tempo – .
Você pode ler mais sobre cada parâmetro aqui .

Um exemplo de registro Os
campos nome, spotify_id, duration_ms, explicit, popularidade, album_type, album_name, album_spotify_id, release_date são obtidos usando uma solicitação GET para
https://api.spotify.com/v1//v1/artists/{id}/top-tracks
, especificando o id do Spotify id do artista que recebemos anteriormente, e no valor do parâmetro de mercado, especificamos RU. Documentação .
O campo album_popularity pode ser obtido fazendo uma solicitação GET para
https://api.spotify.com/v1/albums/{id}
, especificando o album_spotify_id obtido anteriormente como o valor para o parâmetro id. Documentação .
Como resultado, obtemos os dadossobre as melhores faixas de artistas do Spotify. Agora o desafio é obter os recursos de áudio. Isso pode ser feito de duas maneiras:
- Para obter dados sobre uma faixa, você precisa fazer uma solicitação GET para
https://api.spotify.com/v1/audio-features/{id}
, especificando seu ID Spotify como o valor do parâmetro id. Documentação .
- Para obter dados sobre várias faixas de uma vez, você deve enviar uma solicitação GET para
https://api.spotify.com/v1/audio-features
, passando o ID do Spotify dessas faixas separadas por vírgulas como o valor para o parâmetro ids. Documentação .
Todos os scripts estão no repositório neste link .
Após a coleta dos dados, foi realizada uma análise preliminar, que é visualizada a seguir.
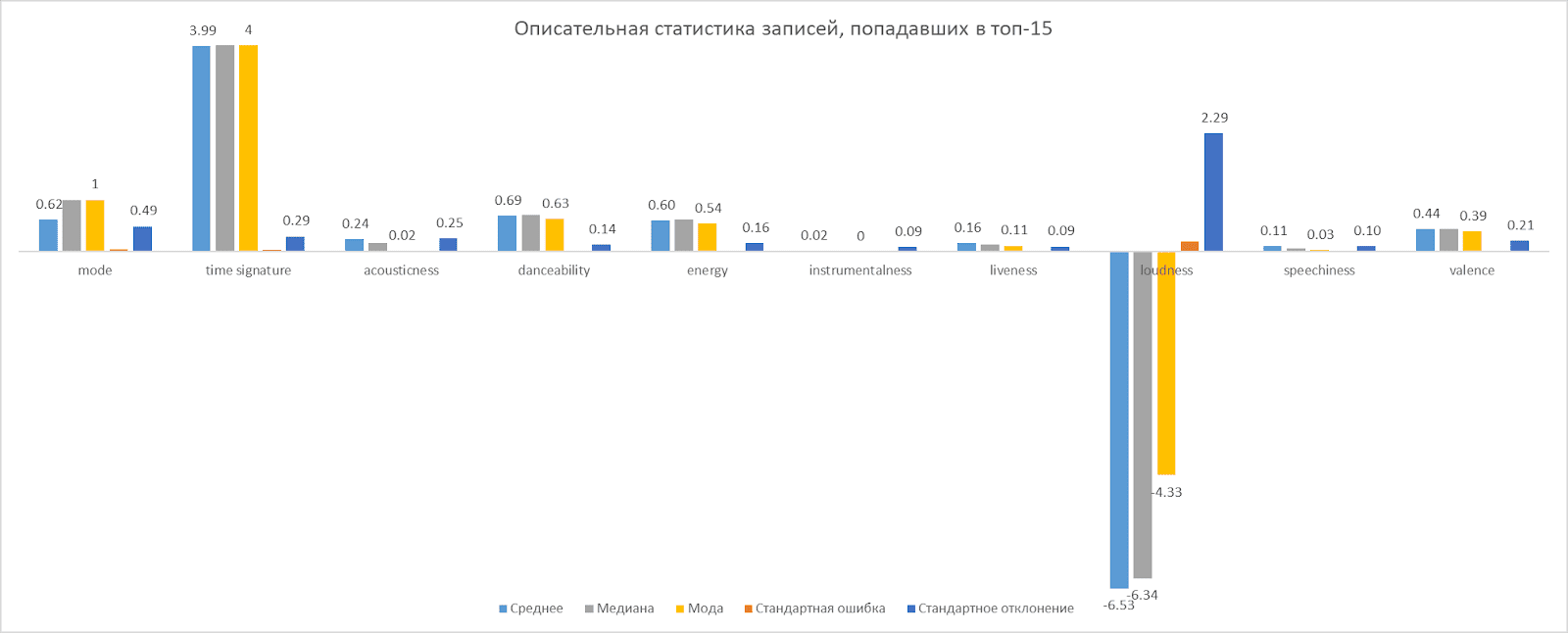
Resultado
Como resultado, conseguimos coletar dados sobre 14.363 artistas e 44.473 faixas. Ao combinar os dados do MusicBrainz e do Spotify, obtivemos o conjunto de dados mais completo até o momento de todos os artistas musicais russos representados na plataforma do Spotify.
Esse conjunto de dados permitirá a criação de produtos B2B e B2C no campo da música. Por exemplo, sistemas de recomendação de artistas para promotores cujos shows podem ser organizados ou sistemas para ajudar jovens artistas a escrever faixas com maior probabilidade de se tornarem populares. Além disso, com a reposição regular do conjunto de dados com dados novos, você pode analisar várias tendências na indústria da música, como a formação e o crescimento da popularidade de certas tendências musicais, ou analisar artistas individuais. O próprio conjunto de dados pode ser visualizado no GitHub .
Conjunto de dados 2: Pesquisamos o mercado de trabalho e identificamos as principais habilidades com "Hedgehog is clear"
Alinhar:
- Andrey Pshenichny - coleta e processamento de dados, escrevendo uma nota analítica no conjunto de dados.
- Pavel Kondratenok - Gerente de Produto, coleta de dados e descrição de seu processo, GitHub.
- Svetlana Shcherbakova - coleta e processamento de dados.
- Evseeva Oksana - preparação da apresentação final do projeto.
- Elfimova Anna - Gerente de Projetos.
Para nosso conjunto de dados, escolhemos a ideia de coletar dados sobre vagas na Rússia na esfera de TI e Telecom do site hh.ru para outubro de 2020.
Coleta de dados de habilidade
A métrica mais importante para todas as categorias de usuário é Habilidades-chave. No entanto, ao analisá-los, encontramos dificuldades: ao preencher os dados de vagas, os RHs selecionam as habilidades-chave da lista e também podem inseri-las manualmente e, portanto, um grande número de habilidades duplicadas e habilidades incorretas entrou em nosso conjunto de dados (por exemplo , encontramos o nome da habilidade-chave "0,4 Kb"). Há mais uma dificuldade que causou problemas na análise do conjunto de dados resultante - apenas cerca de metade das vagas contém dados sobre salários, mas podemos usar indicadores salariais médios de outro recurso (por exemplo, dos recursos Meu Círculo ou Habr.Carreira).
Começamos com aquisição de dados e análise aprofundada. Em seguida, amostramos os dados, ou seja, selecionamos características (características ou, em outras palavras, preditores) e objetos, levando em consideração sua relevância para fins de Data Mining, qualidade e restrições técnicas (volume e tipo).
Aqui fomos ajudados pela análise da frequência de menção de competências nas etiquetas de competências exigidas na descrição do cargo, quais as características da vaga que afetam a recompensa proposta. Ao mesmo tempo, 8915 habilidades-chave foram identificadas. Abaixo está um gráfico que mostra as 10 principais habilidades e com que frequência são mencionadas.
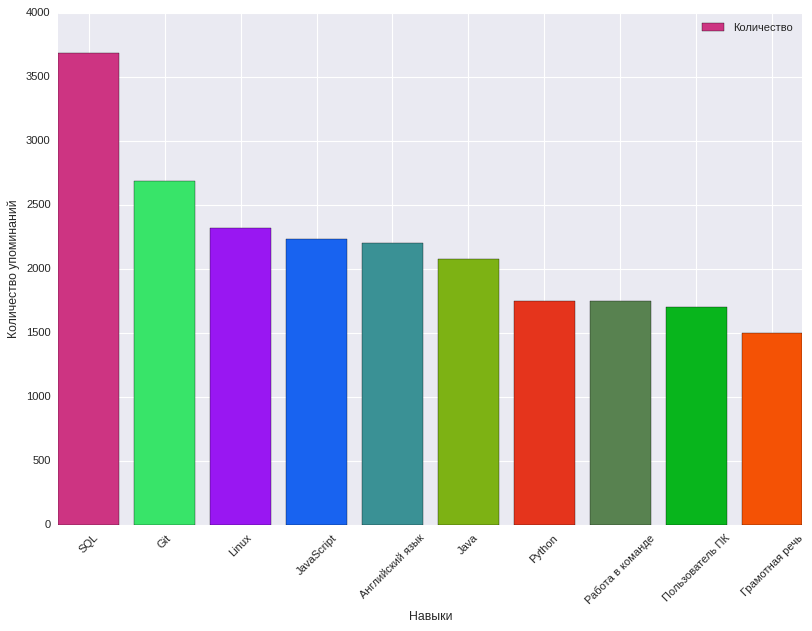
As habilidades-chave mais comuns nas vagas de TI, Telecom
Data, foram obtidas no site hh.ru usando sua API. O código para upload de dados pode ser encontrado aqui . Selecionamos manualmente os recursos de que precisamos para o conjunto de dados. A estrutura e o tipo de dados coletados podem ser vistos na descrição da documentação do conjunto de dados.
Após essas manipulações, obtivemos um Dataset com tamanho de 34.513 linhas. Você pode ver uma amostra dos dados coletados abaixo e também encontrar o link .

Dados de amostra coletados
Resultado
O resultado é um conjunto de dados com o qual você pode descobrir quais habilidades são mais demandadas entre os especialistas de TI em diferentes áreas, e pode ser útil para quem procura emprego (iniciantes e experientes), empregadores, especialistas em RH, organizações educacionais e organizadores de conferências. No processo de coleta de dados, também houve dificuldades: são muitos os sinais e estão escritos em uma linguagem pouco formalizada (descrição das competências do candidato), metade das vagas não tem dados sobre salários em aberto. O próprio conjunto de dados pode ser visualizado no GitHub .
Conjunto de dados 3: aproveite a variedade de gatos com a equipe AA
Alinhar:
- Evgeny Ivanov - desenvolvimento de web scraping.
- Sergey Gurylev - gerente de produto, descrição do processo de desenvolvimento, GitHub.
- Yulia Cherganova - preparação da apresentação do projeto, análise de dados.
- Elena Tereshchenko - preparação de dados, análise de dados.
- Yuri Kotelenko - gerente de projeto, documentação, apresentação do projeto.
Um conjunto de dados dedicado a gatos? Por que não, pensamos. Nosso catset contém imagens de amostra de gatos de várias raças.
Coletando dados de gatos
Inicialmente, escolhemos catfishes.ru para coletar dados , ele tem todas as vantagens que precisamos: é uma fonte gratuita com uma estrutura HTML simples e imagens de alta qualidade. Apesar das vantagens deste site, ele tinha uma desvantagem significativa - um pequeno número de fotos em geral (cerca de 500 para todas as raças) e um pequeno número de imagens de cada raça. Portanto, escolhemos outro site - lapkins.ru .

Por causa da estrutura HTML um pouco mais complexa, copiar o segundo site foi um pouco mais difícil do que o primeiro, mas a estrutura HTML foi fácil de descobrir. Como resultado, já conseguimos coletar 2600 fotos de todas as raças do segundo site.
Nem precisamos filtrar os dados, pois as fotos dos gatos no site são de boa qualidade e correspondem às raças.
Para coletar imagens do site, escrevemos um web scraper. O site contém uma página lapkins.ru/cat com uma lista de todas as raças. Depois de analisar esta página, obtivemos os nomes de todas as raças e links para a página de cada raça. Depois de fazer um loop iterativo por cada uma das rochas, pegamos todas as imagens e as colocamos nas pastas apropriadas. O código de raspador foi implementado em Python usando as seguintes bibliotecas:
- urllib : funções para trabalhar com URLs;
- html : funções para processamento de XML e HTML;
- Shutil : funções de alto nível para lidar com arquivos, grupos de arquivos e pastas;
- SO : funções para trabalhar com o sistema operacional.
Usamos XPath para trabalhar com tags.
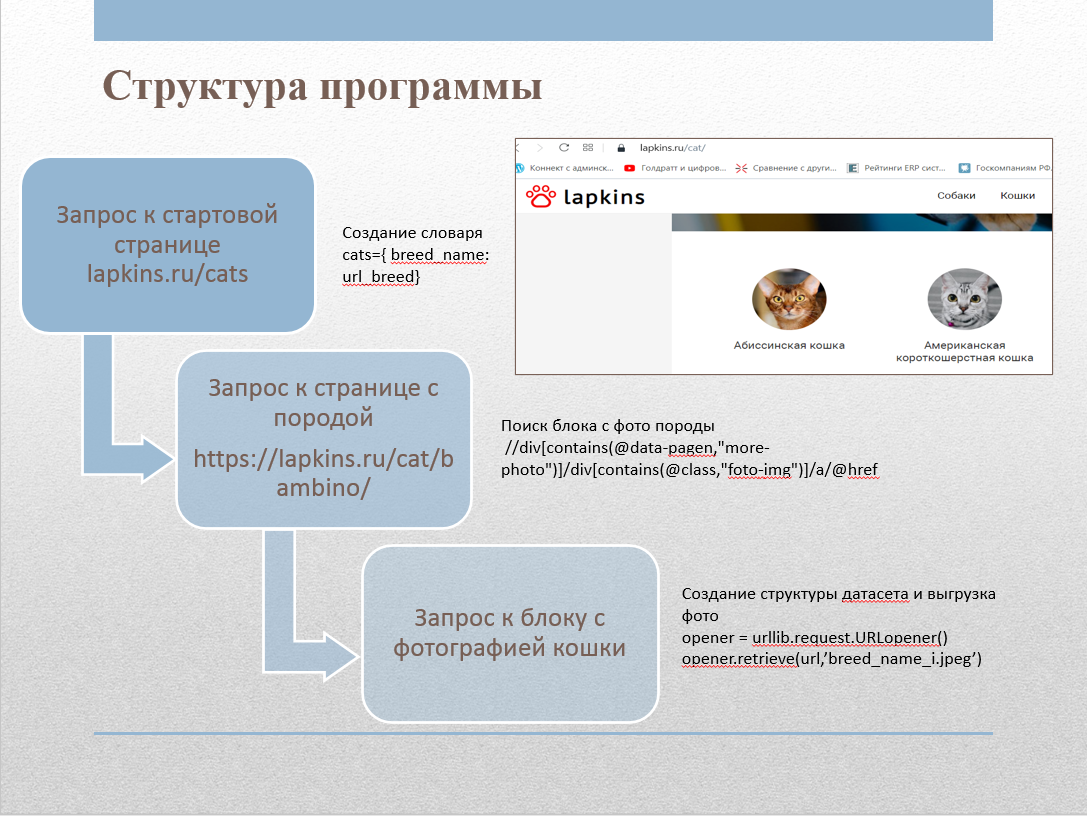
O diretório Cats_lapkins contém pastas cujos nomes correspondem aos nomes de raças de gatos. O repositório contém 64 diretórios para cada raça. No total, o conjunto de dados contém 2600 imagens. Todas as imagens estão no formato .jpg. Formato do nome do arquivo: por exemplo "Gato abissínio 2.jpg", primeiro vem o nome da raça, depois o número - o número de série da amostra.

Resultado
Esse conjunto de dados pode, por exemplo, ser usado para treinar modelos que classificam os gatos domésticos por raça. Os dados coletados podem ser usados para os seguintes fins: determinar as características de cuidar de um gato, selecionar uma dieta adequada para gatos de certas raças, bem como otimizar a identificação primária da raça em feiras e julgamentos. O Cotoset também pode ser usado por empresas - clínicas veterinárias e fabricantes de rações. O próprio cotoset está disponível gratuitamente no GitHub .
Posfácio
Com base nos resultados do dataton, nossos alunos receberam o primeiro caso em seu portfólio de cientistas de dados e feedback sobre o trabalho de mentores de empresas como Huawei, Kaspersky Lab, Align Technology, Auriga, Intellivision, Wrike, Merlin AI. Dataton também foi útil, pois ele imediatamente desenvolveu as habilidades básicas e suaves de perfil que os futuros cientistas de dados precisarão quando já trabalharem em equipes reais. É também uma boa oportunidade de “troca de conhecimentos” mútuos, visto que cada aluno possui uma formação diferente e, consequentemente, uma visão própria do problema e da sua possível solução. Podemos dizer com segurança que sem esse trabalho prático, semelhante a algumas tarefas empresariais já existentes, a formação de especialistas no mundo moderno é simplesmente impensável.
Você pode saber mais sobre o nosso programa de mestrado no site data.misis.ru e no canal Telegram .
Bem, e, claro, nem um único mestrado! Se você quiser aprender mais sobre ciência de dados , aprendizado de máquina e aprendizado profundo - dê uma olhada em nossos cursos correspondentes, será difícil, mas emocionante. E o código promocional HABR o ajudará a aprender coisas novas adicionando 10% ao desconto no banner.

Outras profissões e cursos