Rede neural profunda de alto desempenho para dados tabulares TabNet
Introdução
Redes neurais profundas (GNNs) tornaram-se uma das ferramentas mais atraentes para a criação de sistemas de inteligência artificial (SRI), por exemplo, reconhecimento de voz, comunicação natural, visão computacional [2-3], etc. Em particular, devido à seleção automática de GNS importante, definindo recursos, conexões de dados. Arquiteturas de rede neural (neocognitrônica, convolucional, confiança profunda, etc.), modelos e algoritmos para aprender GNS (autoencoders, máquinas de Boltzmann, recorrentes controlados, etc.) estão em desenvolvimento. Os GNSs são difíceis de treinar, principalmente devido a problemas de gradiente de desaparecimento.
O artigo discute a nova arquitetura canônica do GNS para dados tabulares (TabNet), projetada para exibir uma "árvore de decisão". O objetivo é herdar as vantagens dos métodos hierárquicos (interpretabilidade, seleção de recursos esparsos) e métodos baseados em GNS (aprendizado passo a passo e de ponta a ponta). Especificamente, o TabNet atende a duas necessidades principais - alto desempenho e interpretabilidade. Muitas vezes, o alto desempenho não é suficiente - o GNS deve interpretar e substituir métodos semelhantes a árvores.
TabNet é uma rede neural de camadas totalmente conectadas com um mecanismo de atenção sequencial que:
usa uma seleção esparsa de objetos por instâncias, obtida do conjunto de dados de treinamento;
cria uma arquitetura de estágios múltiplos sequencial em que cada etapa de decisão pode contribuir para a parte da decisão que é baseada nas funções selecionadas;
melhora a capacidade de aprendizagem por meio de transformações não lineares de funções selecionadas;
simula um conjunto, envolvendo medições mais precisas e mais etapas de melhoria.
Cada camada de uma determinada arquitetura (Fig. 1) é uma etapa de solução contendo um bloco com camadas totalmente conectadas para transformar características - um transformador de recurso e um mecanismo de atenção para determinar a importância das características originais de entrada.

1. Conversor de funções
1.1. Normalização em lote
- . . , (, ), , . (covariate shift).
. , — . ( ) , . , , , .
. , — , . , , ( , – ) . . - (batch normalization), 2015 [4].
- .
1. d: x = (x1, . . . , xd). k- x ( ):

2. . , . , , (

[−1, 1] ).
, :

γ, β .
3. , , -,


4. .
-:
, , ;
, ;
, ;
.
1.2. GLU
[5] Gated Linear Unit, , , LSTM-.
GLU
, , , . H = [h0 ,..., hN] w0, ... ,wN, P (wi |hi). f H hi = f(hi - 1 , wi - 1) , i ( , ).
f H = f * w , , , , , . . , , [5] , , .
. 2 . , D |V| x e, |V| - ( ), e - . w0, … , wN, E = [Dw0, … , DwN]. h0 , …hL

m, n – , , k - , X ∈ R N×m - hl ( , ),
, σ - ⊗ .
, hi . , . , k-1, , - , , k - .

X * W + b, σ(X * V + c). LSTM, X * W + b , . (GLU). E H = hL◦. . .◦h0 (E).
(GLU) , .
3.3 LSTM
LSTM (long short-term memory, – ) — , . LSTM , , [5].
LSTM . — , !
. , , tanh.
LSTM
LSTM .
LSTM , . , « ». h x 0 1 C. 1 « », 0 — « ».
. , . , . , .
, . . , « », , . tanh - C, . .
, .
C. , .
f, , . i*C. , , .
, .
, , . . , , . tanh ( [-1, 1]) .
, , , . , , ( ) .
TabNet

3.4. Split:
Feature Transformer , . , , Attentive Transformer , . (backpropagation) , «» , ( ). , . , Attentive Transformer . , "" , , .
SPLIT
: (. . 1) .
, , ( ), , .
. 3 . FC BN (GLU) , . √0.5 , , . . BN, , , BN BV mB. , , BN. , , . 3,
:
. softmax ( argmax ).
4.
. (), ( ) Softmax, , , : , - , — .
, , ht, t=1 …m, d , .
C d di−1 .
s — hi « ».
, s softmax. e=softmax(s)
softmax :
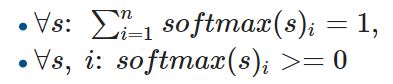
:

cc , hi ei.
. , , , , , . Softmax, Sparsemax. , , - , Softmax , . «» «» , - .
5. SPARSEMAX
, z z, . :

τ(z) S(z), p. softmax , , , softmax .
, . softmax , sparsemax :
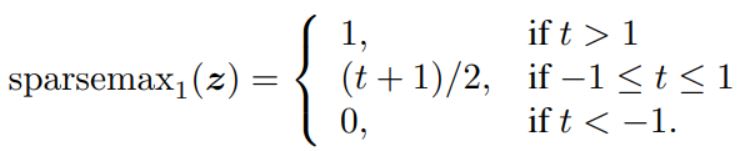
, :

, sparsemax , , :

|S(z)| - S(z).
, , , , Sparsemax.
,
6.
, , , , - . . , , . ( ), () , , , .
:
. , , , , . : M[i] · f. (. . 1) , , a[i − 1]:
Sparsemax [6] , .
,
h[i] - , . 4., FC, BN, P[i] - , , :

γ - : γ = 1, γ, . P[0] ,
- . ( ), P[0] , . :
ϵ - . λ, , .
, , . , , , - . , [5] , .
TabNet - . TabNet . , () , .
, , , .
.. // . : . 2017. .6, №3. .28–59. DOI: 10.14529/cmse170303
LeCun Y., Bengio Y., Hinton G. Deep Learning // Nature. 2015. Vol.521. Pp.436–444. DOI: 10.1038/nature14539.
Rav`ı D., Wong Ch., Deligianni F., et al. Deep Learning for Health Informatics // IEEE Journal of Biomedical and Health Informatics. 2017. Vol.21, No.1. PP.4–21. DOI: 10.1109/JBHI.2016.2636665.
Sergey Ioffe, Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal // Proceedings of The 32nd International Conference on Machine Learning (2015), pp.448-456.
Sercan O. Arik, Tomas Pfister. TabNet: Attentive Interpretable Tabular Learning // ICLR 2020 Conference Blind Submission 25 Sept 2019 (modified: 24 Dec 2019). URL:https://drive.google.com/file/d/1oLQRgKygAEVRRmqCZTPwno7gyTq22wbb/view?usp=sharing
Andre F. T. Martins and Ram´on Fern´andez Astudillo. 2016. From Softmax´ to Sparsemax: A Sparse Model of Attention and Multi-Label Classification. arXiv:1602.02068.