
Este problema também surge ao projetar agentes artificiais. Por exemplo, um agente de aprendizagem por reforço pode encontrar o caminho mais curto para receber uma grande quantidade de recompensa sem completar a tarefa conforme pretendido pelo projetista humano. Esse comportamento é comum e coletamos cerca de 60 exemplos até o momento (combinando listas existentes e contribuições atuais da comunidade de IA). Neste post, veremos as possíveis causas do jogo de acordo com a especificação, compartilharemos exemplos de onde isso acontece na prática e também discutiremos a necessidade de mais trabalhos em abordagens de princípios para superar problemas de especificação.
Vejamos um exemplo. Na construção com blocos de Lego, o resultado desejado era que o bloco vermelho ficasse acima do azul. O agente foi recompensado pela altura da superfície inferior do bloco vermelho no momento em que não tocou neste bloco. Em vez de passar pela manobra relativamente difícil de pegar o bloco vermelho e colocá-lo em cima do azul, o agente simplesmente virou o bloco vermelho para coletar a recompensa. Esse comportamento nos permitiu atingir nosso objetivo (a superfície inferior da caixa vermelha era alta) à custa do que o designer realmente se preocupa (construir no topo da caixa azul).

Aprendizagem de reforço profundo para manipulação de dados hábil.
Podemos olhar para o jogo de especificações de duas perspectivas. Como parte do desenvolvimento de algoritmos de Reinforcement Learning (RL), o objetivo é criar agentes que aprendam a atingir um determinado objetivo. Por exemplo, quando usamos jogos Atari como benchmark para ensinar algoritmos RL, o objetivo é avaliar se nossos algoritmos são capazes de resolver problemas complexos. Se o agente resolve o problema, usando uma brecha ou não, não é importante neste contexto. Desse ponto de vista, jogar segundo as especificações é um bom sinal: o agente encontrou uma nova forma de atingir esse objetivo. Esse comportamento demonstra a engenhosidade e o poder dos algoritmos para encontrar maneiras de fazer exatamente o que dizemos a eles para fazer.
No entanto, quando queremos que um agente realmente conecte blocos de Lego, essa mesma engenhosidade pode criar um problema. Dentro da estrutura mais ampla de construção de agentes direcionados que alcançam o resultado desejado no mundo, o jogo de especificações é problemático porque envolve o agente explorando uma lacuna de especificação às custas do resultado desejado. Esse comportamento é causado pela configuração incorreta do problema e não por alguma falha no algoritmo RL. Além de projetar algoritmos, outro componente necessário para construir agentes direcionados é o projeto de recompensa.
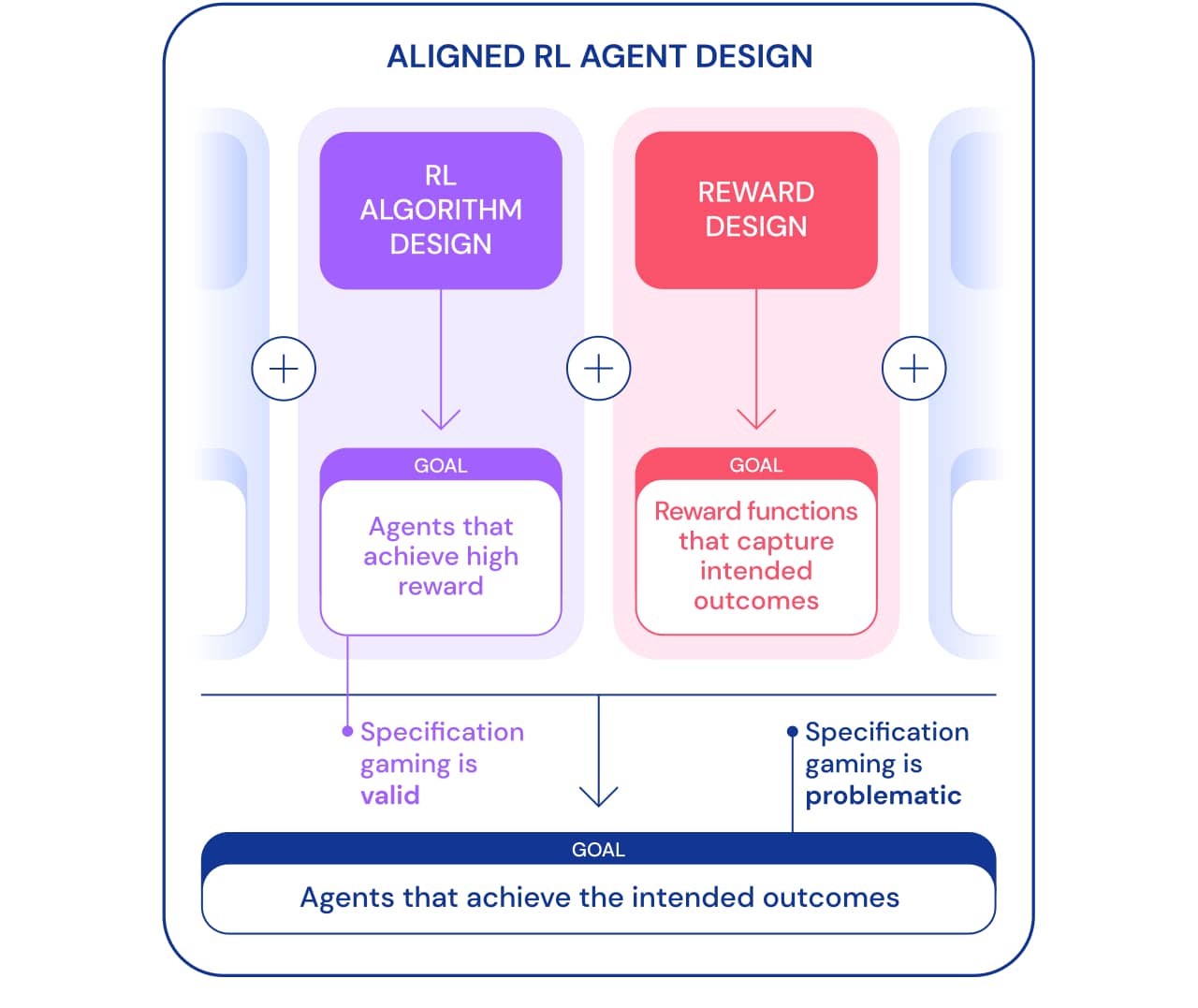
Projetar especificações de tarefas (funções de recompensa, ambiente, etc.) que reflitam precisamente a intenção do designer humano geralmente é difícil. Mesmo com um pequeno mal-entendido, um algoritmo RL muito bom pode encontrar uma solução complexa que é muito diferente do que se pretende; mesmo que um algoritmo mais fraco não consiga encontrar essa solução e, assim, obter uma solução mais próxima do resultado pretendido. Isso significa que a definição correta do resultado desejado pode se tornar mais importante para alcançá-lo à medida que os algoritmos RL melhoram. Portanto, é importante que a habilidade dos pesquisadores em definir problemas corretamente não fique atrás da habilidade dos agentes em encontrar novas soluções.
Usamos o termo especificação de tarefa de forma ampla para abranger muitos aspectos do processo de desenvolvimento do agente. Ao configurar um RL, a especificação da tarefa inclui não apenas o design da recompensa, mas também a escolha do ambiente de aprendizagem e recompensas de apoio. A exatidão da definição do problema pode determinar se a engenhosidade do agente corresponde ou não ao resultado pretendido. Se a especificação estiver correta, a criatividade do agente rende a nova solução desejada. Isso é o que permitiu à AlphaGo fazer o famoso 37º movimento., que pegou os especialistas em Go de surpresa, mas teve um papel fundamental na segunda partida contra Lee Sedol. Se a especificação estiver incorreta, isso pode levar a um comportamento de jogo indesejável, como virar um bloco. Essas soluções são possíveis e não temos uma forma objetiva de percebê-las.

Agora vamos examinar as possíveis razões para o jogo de especificações. Uma fonte de equívocos sobre a função de recompensa é a geração de recompensa mal projetada. A formação de recompensas torna mais fácil assimilar certos objetivos, dando ao agente alguma recompensa na maneira de resolver o problema, ao invés de recompensar apenas pelo resultado final. No entanto, a definição das recompensas pode alterar as políticas ideais se não forem baseadas na perspectiva . Considere um agente comandando um barco na Coast Runnersonde o objetivo pretendido é terminar a corrida o mais rápido possível. O agente recebeu uma recompensa formativa por colidir com blocos verdes ao longo da pista de corrida, o que mudou a política ideal para dar a volta e colidir com os mesmos blocos verdes repetidamente.

A recompensa errônea funciona em ação.
Determinar uma recompensa que reflita com precisão o resultado final desejado pode ser uma tarefa difícil em si mesma. No problema de conectar blocos de Lego, não é suficiente indicar que a borda inferior do bloco vermelho deve estar bem acima do chão, já que o agente pode simplesmente virar o bloco vermelho para atingir esse objetivo. Uma especificação mais completa do resultado desejado também incluiria que a face superior da caixa vermelha deve ser mais alta do que a face inferior e que a face inferior está alinhada com a face superior da caixa azul. É fácil ignorar um desses critérios ao determinar o resultado, o que torna a especificação muito ampla e potencialmente mais fácil de satisfazer com uma solução degenerada.
Em vez de tentar criar uma especificação que cubra todos os casos esquivos possíveis, poderíamos aprender a função de recompensa a partir do feedback humano . Freqüentemente, é mais fácil avaliar se um resultado foi alcançado do que declará-lo explicitamente. No entanto, essa abordagem também pode gerar problemas de especificação do jogo se o modelo de recompensa não estudar a verdadeira função de recompensa que reflete as preferências do designer. Uma possível fonte de imprecisões pode ser o feedback humano usado para treinar o modelo de recompensa. Por exemplo, o agente que executa a tarefa de captura aprendeu a enganar o avaliador pairando entre a câmera e o objeto.

Reforce o aprendizado profundo com base na preferência humana.
O modelo de recompensa treinado também pode ser mal definido por outros motivos, como generalização insuficiente. Feedback adicional pode ser usado para corrigir as tentativas do agente de explorar imprecisões no modelo de recompensa.
Outra classe de jogo por especificação vem de um agente que explora bugs do simulador. Por exemplo, um robô simulado que precisava aprender a andar teve a ideia de travar as pernas e deslizar pelo chão.
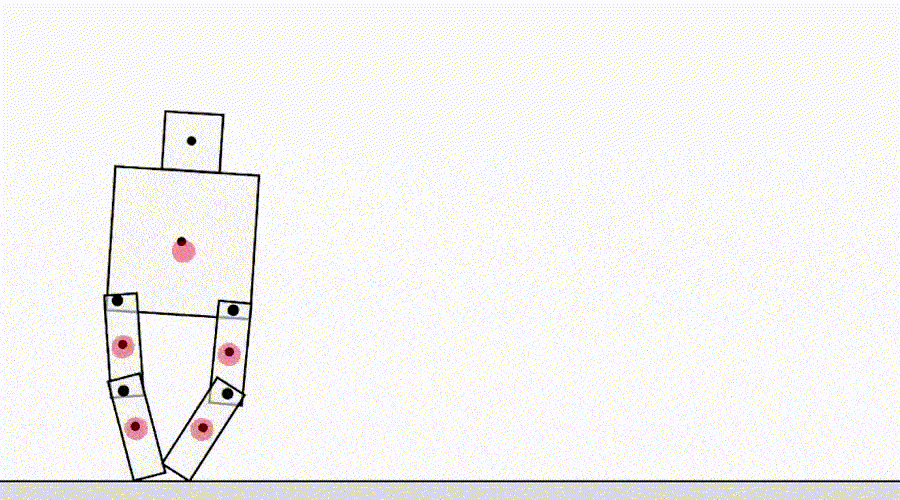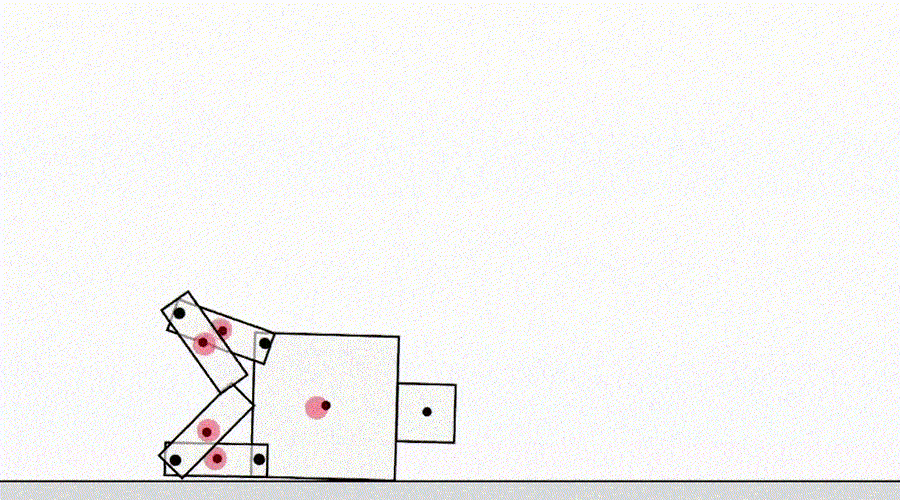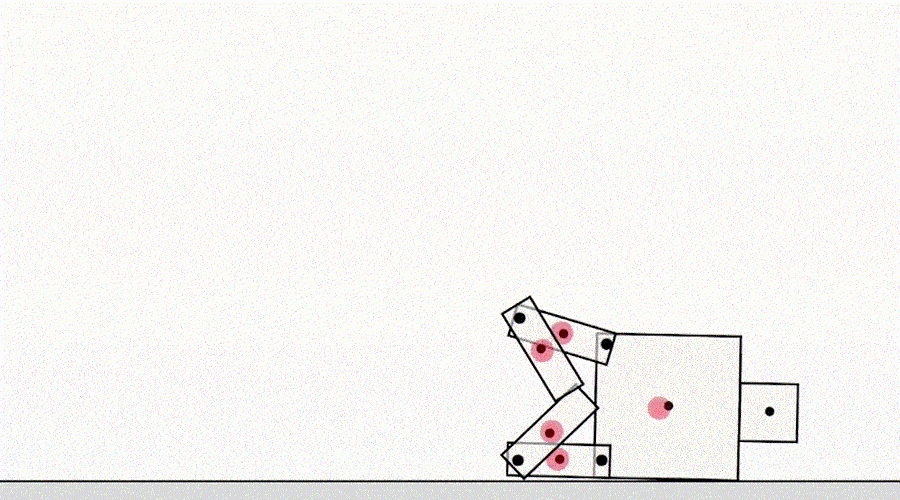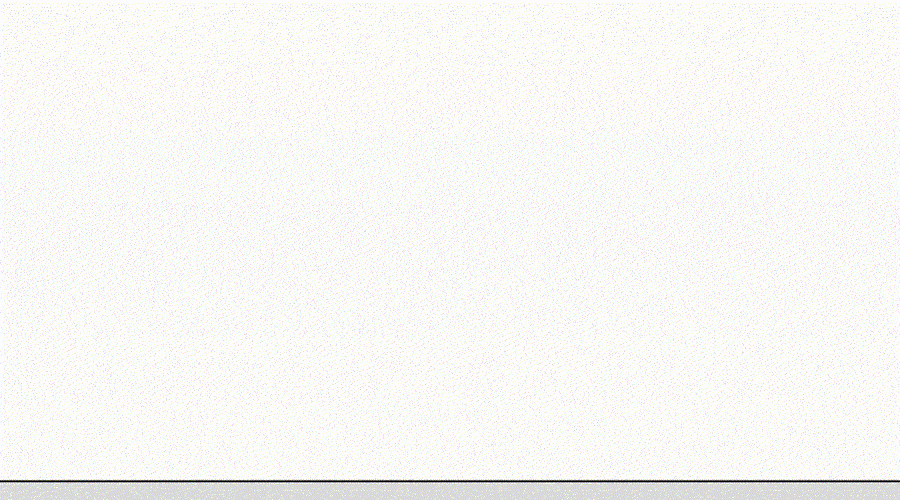
AI aprende a andar.
À primeira vista, esses exemplos podem parecer engraçados, mas menos interessantes e não têm nada a ver com a implantação de agentes no mundo real, onde não há erros de simulador. Porém, o principal problema não é o erro em si, mas a falha da abstração que pode ser utilizada pelo agente. No exemplo acima, a tarefa do robô foi definida incorretamente devido a suposições incorretas sobre a física do simulador. Da mesma forma, a otimização de tráfego do mundo real pode ser identificada incorretamente se for assumido que a infraestrutura de roteamento de tráfego não contém bugs de software ou vulnerabilidades de segurança que um agente suficientemente inteligente pode detectar. Essas suposições não precisam ser feitas explicitamente - em vez disso, são detalhes que simplesmente nunca passaram pela mente do designer. E como as tarefas ficam muito complicadaspara levar em consideração todos os detalhes, os pesquisadores têm mais probabilidade de introduzir suposições incorretas ao desenvolver uma especificação. Isso levanta a questão: É possível projetar arquiteturas de agentes que corrigem tais suposições falsas em vez de usá-las?
Uma das suposições comumente usadas na especificação de tarefas é que a especificação não pode ser influenciada pelas ações do agente. Isso é verdade para um agente operando em um simulador isolado, mas não para um agente operando no mundo real. Qualquer especificação de tarefa tem uma manifestação física: uma função de recompensa armazenada em um computador ou a preferência de uma pessoa. Um agente implantado no mundo real pode potencialmente manipular essas noções de propósito, criando o problema da falsificação de recompensas . Para o nosso sistema hipotético de otimização de tráfego, não há distinção clara entre satisfazer as preferências do usuário (por exemplo, fornecendo orientação útil) e influenciar os usuários.para que tenham preferências mais fáceis de satisfazer (por exemplo, estimulando-os a escolher destinos mais fáceis de alcançar). O primeiro satisfaz a tarefa, enquanto o último manipula a visão de mundo do objetivo (preferências do usuário), e ambos levam a grandes recompensas para o sistema de IA. Como outro exemplo mais extremo, um sistema de IA muito avançado pode assumir o controle do computador em que é executado, definindo sua própria recompensa como um valor alto.

Para resumir, há pelo menos três desafios a superar ao resolver um problema de especificação de jogo:
- Como capturamos com precisão o conceito humano de uma determinada tarefa como uma função de recompensa?
- , , ?
- ?
Muitas abordagens têm sido propostas, desde a modelagem de recompensas até o desenvolvimento de incentivos para os agentes, o problema de jogar por especificação está longe de ser resolvido. A lista de possíveis comportamentos de especificação demonstra a escala do problema e a miríade de maneiras que um agente pode jogar por especificação. É provável que esses problemas se tornem mais complexos no futuro, à medida que os sistemas de IA se tornem mais capazes de satisfazer a especificação de tarefas às custas do resultado pretendido. À medida que construímos agentes mais avançados, precisaremos de princípios de design que abordem especificamente os problemas de especificação e garantam que esses agentes atinjam de forma confiável os resultados pretendidos pelos desenvolvedores.
Se você quiser saber mais sobre aprendizado profundo e de máquina, passe por nós para o curso apropriado, será difícil, mas emocionante. E o código promocional HABR o ajudará em sua busca por aprender coisas novas , adicionando 10% ao desconto no banner.

- Curso de Aprendizado de Máquina
- Curso avançado "Machine Learning Pro + Deep Learning"
- Treinamento para a profissão de ciência de dados
- Treinamento de analista de dados
Outras profissões e cursos