Há treze anos, procuramos maneiras de dimensionar o desenvolvimento para que tudo funcione de maneira confiável conforme cresce e, ao mesmo tempo, novos recursos sejam lançados rapidamente. Antes parecia importante renomear colunas em um banco de dados com facilidade. Agora - eu tive que mudar toda a arquitetura em movimento.
Este é o terceiro post de desenvolvimento anual da Black Friday, a semana de pico. Por que finalmente pensamos que somos ótimos; o que eles fizeram por isso; por que encontramos dificuldades e o que planejamos fazer a seguir.
Resumo: dois anos de trabalho por um bom motivo
Pelo quinto ano consecutivo, a carga no Mindbox praticamente dobra anualmente. Em novembro de 2020, processamos 8,75 bilhões de solicitações de API, em comparação com 4,48 bilhões um ano antes. O pico é de 400 mil solicitações por minuto. Enviou 1,64 bilhão de e-mails e 440 milhões de notificações móveis. Um ano atrás, havia 1,1 bilhão de e-mails, mas quase não havia mensagens push.
Dinâmica do número de envios por semana de Black Friday:
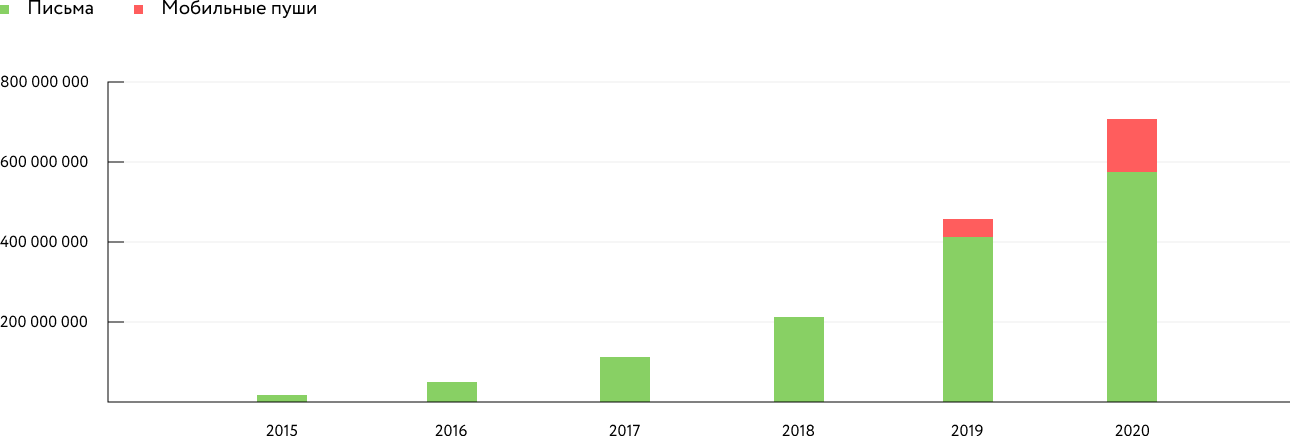
De acordo com nossos dados, isso é comparável ao nível de carga de hh.ru em solicitações de API, em termos de carga em bancos de dados - com Avito. Cerca de um terço do táxi Yandex em solicitações por minuto.
Em 2018 e 2019Ao longo dos anos, lidamos mal com isso: os clientes sofreram rejeições. No final de 2018, esperava melhorias rápidas e esperava um roteiro de negócios, que até agora só foi concluído pela metade. Em 2019, decidi não falar do roadmap, pois conforme a confiabilidade se deteriorava, as falhas começaram em setembro e na Black Friday se repetiram, apesar do grande volume de trabalho realizado.
Hoje podemos concluir: aprendemos a lidar com o crescimento. A Black Friday 2020 passou sem incidentes afetando mais de um cliente. Houve duas falhas parciais de curto prazo devido à infraestrutura externa que não violou o SLA. Infelizmente, houve reclamações de vários dos maiores clientes, mas essas são histórias únicas que entendemos e estamos trabalhando nelas.
Além disso, os dados e as avaliações subjetivas dos usuários mostram uma tendência de longo prazo de aumento da qualidade do desenvolvimento. O número de defeitos - erros críticos, falhas e casos de desempenho insatisfatório - é reduzido.
O gráfico mostra violações do SLA interno (mais estrito que o externo), que adicionalmente tornamos ainda mais estrito este ano:

Número de violações de SLA interno por um cliente médio
Conseguimos "reinventar" completamente o empreendimento em dois anos, continuando a crescer a uma taxa média de 40% da receita por ano (em 2019 - 431 milhões, em 2020 - 618 milhões) e lançando novos recursos. Sentimentos - sobre como mudar o motor de um carro a toda velocidade.
O que foi feito em dois anos:
- (LESS) , , .
- 50% , ( ) .
- SRE. SRE .
- , , .
- SLA .
- «-», .
Isso está longe de ser planejado. Continuamos aumentando a quantidade de recursos alocados para a qualidade. Esperamos mais melhorias na qualidade e lançamento mais rápido de novos recursos em 2021 e além.
A propósito, escrevemos regularmente sobre atualizações no produto e mantemos uma página de status com o histórico de incidentes .
As origens das dificuldades: 2008-2018
Mindbox é um produto com uma lógica de negócio complexa, desde 2008 desenvolvemos como serviço para grandes empresas, com uma quota de custos de desenvolvimento superior a 30%. Do ponto de vista arquitetônico, era um aplicativo monolítico tradicional, mas de altíssima qualidade: todos os dias lançamos e ainda lançamos várias atualizações de monolito.
Em 2014, o mercado fez com que nos voltássemos para um segmento mais massivo, incluindo e-commerce e varejo. Isso exigiu um investimento em atendimento ao cliente, vendas e marketing.
A empresa nunca atraiu investimentos externos, sempre se desenvolveu com o próprio lucro. Além disso, em 2017, seis meses depois de me tornar CEO, nos deparamos com falta de dinheiro, me assustei e aumentei demais minha lucratividade. Tudo isso levou a uma redução dos custos de desenvolvimento para 24% da receita em 2018-2019.
Ao mesmo tempo, era necessário liberar uma série de funções necessárias para os novos clientes - com um rápido aumento da carga e do número de clientes. Lidamos com o acúmulo do produto e da arquitetura originais, bem como com a descentralização - a formação de equipes de produto autônomas.
Infelizmente, a experiência técnica de tais equipes não acompanhou o crescimento da empresa, que foi ainda mais exacerbado pelos limites do possível na arquitetura monolítica. A dívida técnica estava se acumulando, a tecnologia usada estava desatualizada e os salários estavam abaixo do mercado. A contratação de engenheiros está cada vez mais difícil, apesar dos desafios desafiadores e da cultura única da empresa. Até 2018, o número de clientes havia crescido 10 vezes, o sucesso do produto tornou-se evidente, assim como problemas de confiabilidade e desenvolvimento em geral.
Que medidas tomamos
Processos e recursos
A primeira hipótese era a centralização: em 2019 foi lançado o LESS - é quando várias equipes estão trabalhando em um projeto ao mesmo tempo. Começamos a projetar epopeias em conjunto e a trabalhar com confiabilidade, conseguimos aumentar a previsibilidade e encontrar práticas de design úteis. Porém, após um ano, a ineficácia do processo tornou-se evidente: desmotivação e responsabilidade reduzida das equipes pela falta de noção de "suas" características, altos custos de gestão, que ninguém gostava de fazer.
Ao longo de um ano de design colaborativo, surgiu uma visão de uma arquitetura descentralizada que permitiria a cada equipe ser responsável por microsserviços isolados, enquanto continuava a entregar um único produto aos clientes. Junto com a visão, surgiram atrasos de tarefas e ficou claro que era necessário trabalhar a infraestrutura com especialistas dedicados, sem interrompê-la com um roadmap de negócios.
Concordamos em alocar 30% do recurso para dívida técnica de maneira contínua. Foi formada a primeira equipe de infraestrutura e as equipes autônomas voltaram a ser alocadas. Ao mesmo tempo, uma série de processos de colaboração centralizada foram preservados, principalmente com o objetivo de manter a qualidade:
- Projeto,
- análise de defeitos,
- modelando a carga no ferro,
- demonstração e status de sincronização.
Tornou os arquitetos e equipes responsáveis por métricas de confiabilidade e previsões de custo do servidor. Além disso, alocamos 30% em cada equipe para débitos técnicos e bugs, enquanto aguardamos a continuidade dos negócios.
Em 2020, os processos se estabilizaram: formamos uma segunda equipe de infraestrutura e a entrega foi ajustada. A parcela de recursos para tarefas de negócios começou a crescer lentamente de um ponto baixo de cerca de 50%, e a parcela de bugs começou a diminuir:

Alocação de recursos de desenvolvimento por tarefas. O gráfico não é muito informativo, uma vez que uma métrica confiável foi estabelecida há relativamente pouco tempo, mas é apoiada por impressões de campo.
Durante esse tempo, aprendemos como contratar e integrar SREs, separá-los do DevOps e TI do escritório, formar processos de dever e descrever a função.
A escassez de engenheiros foi reduzida de duas maneiras:
- Criamos uma escola de desenvolvimento que forma 8 a 12 desenvolvedores juniores por ano. São desenvolvedores que têm experiência com nossa pilha, em cujas habilidades temos confiança. Hoje a escola conta com 2 equipes de 4 estagiários.
- Aumentamos sistematicamente a folha de pagamento para o desenvolvimento, pois os resultados do negócio permitiam. O salário médio em desenvolvimento cresceu de 120 mil rublos em 2015 para 170+ no final de 2020 e continua a crescer. Isso nos permitiu contratar vários novos e fortes líderes de tecnologia. A parcela dos custos de desenvolvimento subiu para 28% e o número de pessoas aumentou de 27 para 64.
Métricas, métricas e métricas automáticas
Em nossa cultura, é costume gerenciar por dados, não por opinião pessoal. Métricas eficazes são talvez uma das questões difíceis para as quais as modernas metodologias de gerenciamento de desenvolvimento não dão uma resposta direta.
Começamos automatizando quatro métricas do livro Accelerate e acelerando o pipeline de entrega. Isso não teve efeitos óbvios imediatos. Mas a troca de experiências com hh.ru e Yandex Cloud nos levou à automação da métrica de violação de SLA e ao estabelecimento automático de defeitos. Aqui sentimos claramente o benefício e a conexão com os esforços que estão sendo feitos. O gráfico desta métrica com uma tendência está no início da postagem.
Discreto, mas acho que somos uma das poucas empresas no mundo que possui uma API para clientes que permite obter uma métrica da disponibilidade dos componentes da plataforma em tempo real.
A métrica descrita acima para a parcela de bugs e débitos técnicos na equipe também parece útil. Além disso, consideramos como as equipes cumprem as promessas feitas para o sprint, e os desenvolvedores cumprem os prazos para as tarefas diárias e semanais.
Finalmente, pesquisas trimestrais anônimas (os textos melhoraram desde então, mas a essência da pesquisa não mudou) e uma alta classificação em Habr-Karer mostram uma diminuição no infortúnio de desenvolvimento. Trata-se da avaliação do seu rendimento em relação ao mercado, processamento e eNPS (dados de apenas dois trimestres até agora).
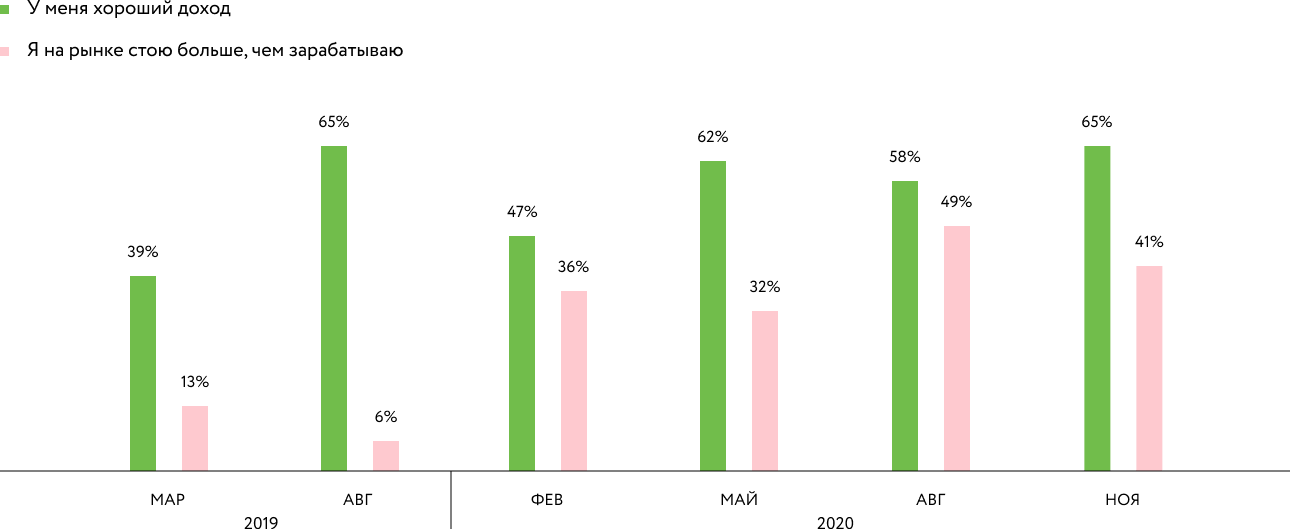
Pesquisa de renda do

desenvolvedor : Pesquisa de revisão do desenvolvedor: Desenvolvedores eNPS:

Em uma escala de 1 a 10, qual a probabilidade de você recomendar o Mindbox como um lugar para trabalhar?
Por último, mas não menos importante, tecnologia
Tudo isso tornou possível organizar a reescrita de um produto monolítico - mais de 2 milhões de linhas de código em IIS + ASP.NET + NLB / Windows Service / MS SQL - simultaneamente em todas as direções:
- API e back-end de microsserviço, quando uma solicitação do cliente para o API Gateway é processada de forma transparente por vários microsserviços, incluindo solicitações síncronas (padrão saga).
- Microfront-end, onde as seções de interface são separadas dos aplicativos SPA de back-end que podem ser hospedados em seus próprios repositórios, com seu próprio pipeline de layout.
- Transferência de microsserviços multilocatários do MS SQL para armazenamentos escaláveis distribuídos: Cassandra, lickhouse. Kafka em vez de RabbitMQ.
- Transferência da aplicação para .NET Core, Linux e transferência parcial para Managed Kubernetes "Yandex-clouds". Imediatamente a introdução de tecnologias SRE e DevOps modernas: OctopusDeploy + Helm, Prometheus, Grafana, Graylog + Sentry, Amixr.IO.
Talvez sejamos um dos clientes mais carregados de Yandex Cloud, então Nikita Prudnikov falou sobre nossa implementação e superação conjunta das dificuldades do CTO com Yandex na Yandex Scale 2020 .
Em nosso artigo na Black Friday, você pode ler sobre nossas principais abordagens de dimensionamento usando o exemplo de um componente de lista de e-mails que não quebrou no ano passado e não quebrou este aqui.
Planos de desenvolvimento adicionais
Apesar dos resultados alcançados, devo dizer que menos da metade do que foi planejado foi feito. Adiante:
- Continue aumentando a receita do desenvolvedor e contratando os melhores líderes sênior e de tecnologia
- A terceira equipe da escola de desenvolvimento, que permitirá a contratação de até 12 desenvolvedores por ano
- Tradução contínua do aplicativo para .NET, k8s e Yandex-cloud, dimensionamento automático, layout azul esverdeado com reversão instantânea
- Movendo-se para o estabelecimento automático de incidentes na página de status, eliminando falsos positivos de SLA
- Migrando para .NET 5, EF.Core e PostgreSQL (e desenvolvedores para novos MacBooks)
- Isolamento de várias peças em grande escala do monólito
Desejo motivado para crescer .NET desenvolvedores tehlidov e SRE-especialistas para responder às nossas nosso trabalho para hh.ru . Vai ser interessante, você pode ter uma experiência única no mercado e fazer coisas.
Plataformas de roteiro em 2021
Sentimos uma base sólida sob nossos pés, o que nos dá esperança de que possamos novamente cumprir nossas promessas de roteiro de negócios. Experimentamos os processos de planejamento descentralizado por um ano pela primeira vez, mas eu me permitirei de forma imprudente formar expectativas públicas.
Este ano adicionaremos à plataforma:
- Construtor de cenário .
- Armazenamento e relatório de pedidos anônimos
- Mais relatórios rápidos na interface ( como em nosso curso )
- Integração com BI
- Novo módulo de notificações push para celular, incluindo um novo SDK
- A capacidade de excluir rapidamente qualquer entidade, levando em consideração as dependências umas das outras
- Mais algoritmos de ML e muitas melhorias de qualidade para os existentes
- Mais páginas em um novo design com capacidade de resposta de interface aprimorada
- Personalização simplificada de integrações e mecânicas padrão
Os planos para 2022 são mais ambiciosos, mas espero escrever sobre eles em um ano, se o otimismo se justificar.
Obrigado
Assim como as histórias de sucesso de clientes, esta é o mérito de pessoas específicas às quais expresso minha gratidão:
Nikita Prudnikov, CTO, pela visão, consistência e compressão sistemática.
Roman Ivonin, arquiteto-chefe, pela paciência, formação da equipe, ampla responsabilidade, liderança informal e noites sem dormir.
Igor Kudrin, CIO, pela base da experiência SRE, visão e salvação de tudo quando ninguém sabe.
Rostislav, Leonid, Dmitry, Mitya, Ilya, dois Artyom, Alexey, Sergei, Nikolai, Ivan, Slava, Zhenya e outros desenvolvedores, produtos, líderes de tecnologia e SRE atenciosos que tornaram tudo realidade. Desculpe se não mencionei ninguém.
Agradecimento especial aos clientes que resistiram, apesar de termos falhado, e deram a oportunidade de melhorar. Faremos todos os esforços para mantê-lo cada vez melhor.