CREATE TABLE task AS
SELECT
id
, (random() * 100)::integer person -- 100
, least(trunc(-ln(random()) / ln(2)), 10)::integer priority -- 2
FROM
generate_series(1, 1e5) id; -- 100K
CREATE INDEX ON task(person, priority);
A palavra "é" em SQL se transforma em
EXISTS
- aqui está a versão mais simples e vamos começar:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

todas as fotos do plano são clicáveis
Até agora, tudo parece bem, mas ...
EXISTS + IN
... então eles nos procuraram e pediram para incluir não apenas
priority = 10
8 e 9 como "super" :
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority IN (10, 9, 8)
);

Eles leram 1,5 vez mais, e também afetou o tempo de execução.
OU + EXISTE
Vamos tentar usar nosso conhecimento de que é
priority = 8
muito mais provável encontrar um recorde com 10:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

Observe que o PostgreSQL 12 já é inteligente o suficiente para fazer
EXISTS
subconsultas subsequentes apenas para aquelas "não encontradas" pelas anteriores após 100 pesquisas para o valor 8 - apenas 13 para o valor 9 e apenas 4 para 10.
CASE + EXISTS + ...
Nas versões anteriores, um resultado semelhante pode ser obtido "ocultando sob CASE" as seguintes consultas:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) THEN TRUE
ELSE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) THEN TRUE
ELSE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
)
END
END;
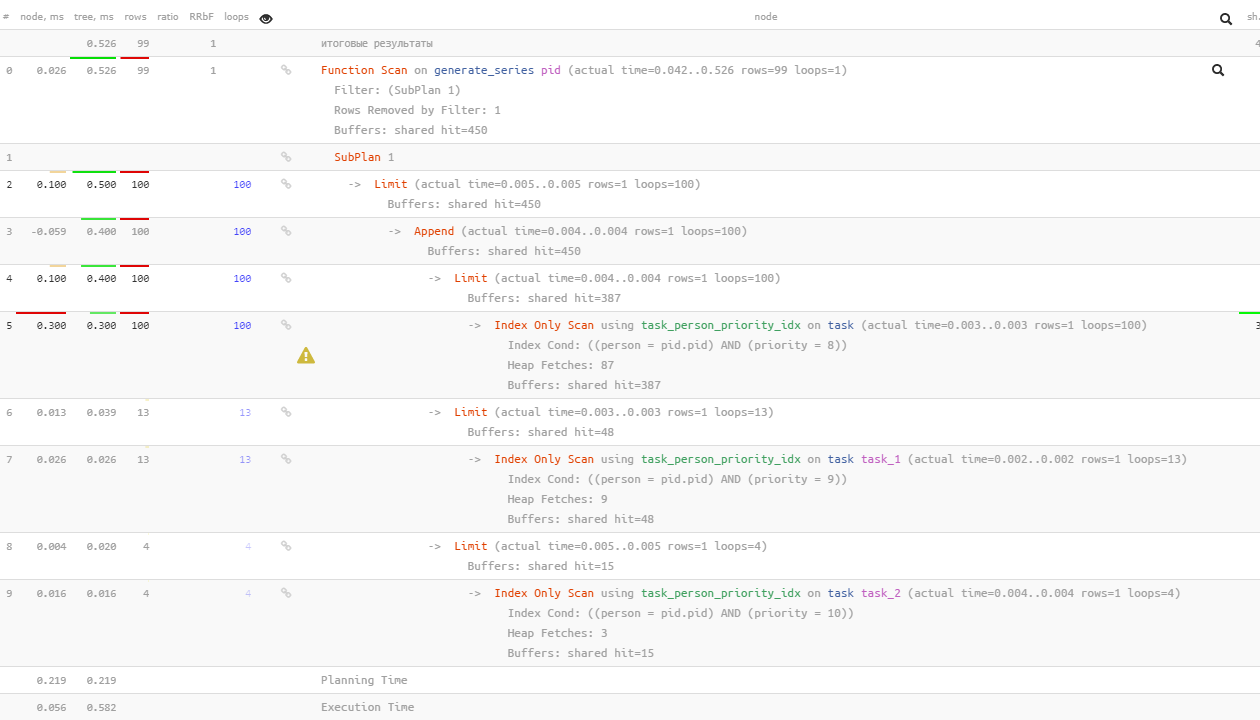
EXISTS + UNION ALL + LIMIT
O mesmo, mas você pode ficar um pouco mais rápido se usar o "hack"
UNION ALL + LIMIT
:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
LIMIT 1
)
LIMIT 1
);
Índices corretos são a chave para a saúde do banco de dados
Agora, vamos examinar o problema de um lado completamente diferente. Se tivermos certeza de que o
task
número de registros que queremos encontrar é várias vezes menor que o resto , faremos um índice parcial adequado. Ao mesmo tempo, vamos direto da enumeração "ponto"
8, 9, 10
para
>= 8
:
CREATE INDEX ON task(person) WHERE priority >= 8;
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority >= 8
);

Tive que ler 2 vezes mais rápido e 1,5 vezes menos!
Mas, provavelmente, subtrair todos os adequados de
task
uma vez - será ainda mais rápido? ..
SELECT DISTINCT
person
FROM
task
WHERE
priority >= 8;

Longe de sempre, e certamente não neste caso - porque em vez de 100 leituras dos primeiros registros disponíveis, temos que ler mais de 400!
E para não adivinhar qual das opções de consulta será mais eficaz, mas para saber com confiança - use explain.tensor.ru .