Entre as estruturas que estamos considerando para processamento de dados complexos em Java está o Apache Flink. Gostaríamos de lhe oferecer uma tradução de um bom artigo do blog Analytics Vidhya no portal do Medium para avaliar o interesse do leitor. Sinta-se à vontade para votar!

Neste artigo, daremos uma olhada de baixo para cima em como otimizar com o Flink; em serviços de nuvem e em outras plataformas, soluções de streaming são fornecidas (algumas das quais têm Flink integrado sob o capô). Se você quisesse entender esse tópico do zero, então encontrou exatamente o que estava procurando.
Nossa solução monolítica não conseguia lidar com os volumes crescentes de dados recebidos; portanto, precisava ser desenvolvido. É hora de passar para uma nova geração na evolução do nosso produto. Decidiu-se usar o processamento de streaming. Este é um novo paradigma de absorção de dados superior ao processamento em lote tradicional.
Apache Flink: breve descrição
Apache Flink é uma estrutura de threading distribuída escalonável para operações em fluxos contínuos de dados. Dentro desta estrutura, conceitos como fontes, transformações de fluxo, processamento paralelo, programação, atribuição de recursos são usados. Vários destinos de dados são suportados. Especificamente, o Apache Flink pode se conectar a HDFS, Kafka, Amazon Kinesis, RabbitMQ e Cassandra.
O Flink é conhecido por seu alto rendimento e baixa latência, consistente, processamento estritamente único (todos os dados são processados uma vez, sem duplicação) e alta disponibilidade. Como qualquer outro produto de código aberto de sucesso, Flink tem uma grande comunidade que cultiva e expande os recursos desta estrutura.
Flink pode lidar com fluxos de dados (o tamanho do fluxo é indefinido) ou conjuntos de dados (o tamanho do conjunto de dados é específico). Este artigo trata especificamente do processamento de threads (manipulação de objetos
DataStream
).
Streaming e suas chamadas inerentes
Hoje, com a onipresença de dispositivos IoT e outros sensores, os dados fluem continuamente de várias fontes. Esse fluxo infinito de dados requer a adaptação da computação em lote tradicional a novas condições.
- Streaming de dados ilimitado; eles não têm começo nem fim.
- Novos dados chegam de maneira imprevisível, em intervalos irregulares.
- Os dados podem chegar de forma desordenada, com marcações de tempo diferentes.
Com tais características únicas, o processamento de dados e as tarefas de consulta não são triviais de realizar. Os resultados podem mudar rapidamente e é quase impossível tirar conclusões definitivas; os cálculos às vezes podem bloquear ao tentar obter resultados válidos. Além disso, os resultados não são reproduzíveis, uma vez que os dados continuam a mudar durante os cálculos. Finalmente, os atrasos são outro fator que afeta a precisão dos resultados.
O Apache Flink permite que você lide com esses problemas de processamento, porque se concentra nos carimbos de data / hora com os quais os dados recebidos são fornecidos de volta na origem. O Flink possui um mecanismo para acumular eventos com base em carimbos de data / hora, colocar neles - e somente depois de acumular o sistema segue para o processamento. Nesse caso, pode-se dispensar o uso de microembalagens e, também, nesse caso, a precisão dos resultados é aumentada.
O Flink implementa um processamento consistente e estritamente único, que garante a precisão dos cálculos, e o desenvolvedor não precisa programar nada para isso.
Do que são feitos os pacotes Flink
Normalmente, o Flink absorve fluxos de dados de diferentes fontes. O objeto base é
DataStream<T>
um fluxo de elementos do mesmo tipo. O tipo de elemento em tal fluxo é determinado em tempo de compilação, definindo um tipo genérico
T
(você pode ler mais sobre isso aqui ).
O objeto
DataStream
contém muitos métodos úteis para transformar, separar e filtrar dados. Para começar, será útil ter uma ideia do que eles estão fazendo
map
,
reduce
e
filter
; estes são os principais métodos de transformação:
Map
: obtém um objetoT
e como resultado retorna um objeto do tipoR
;MapFunction
estritamente uma vez aplicado a cada elemento do objetoDataStream
.
SingleOutputStreamOperator<R> map(MapFunction<T,R> mapper)
Reduce
: obtém dois valores consecutivos e retorna um objeto, combinando-os em um objeto do mesmo tipo; este método percorre todos os valores do grupo até que apenas um deles permaneça.
T reduce(T value1, T value2)
Filter
: obtém um objetoT
e retorna um fluxo de objetosT
; este método itera sobre todos os elementosDataStream
, mas retorna apenas aqueles para os quais a função retornatrue
.
SingleOutputStreamOperator<T> filter(FilterFunction<T> filter)
Dreno de dados
Um dos principais objetivos do Flink, junto com a transformação de dados, é controlar os fluxos e direcioná-los para determinados destinos. Esses locais são chamados de "ralos". Flink tem strings embutidas (texto, CSV, socket), bem como mecanismos out-of-the-box para conectar a outros sistemas, por exemplo, Apache Kafka .
Tags de evento Flink
Ao processar fluxos de dados, o fator tempo é extremamente importante. Existem três maneiras de determinar o carimbo de data / hora:
- ( ): , ; , . - . , .
, , . , , , ; , .
// Processing Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
- : , , , Flink. , , Flink .
Flink , , , ; « » (watermark). ; Flink.
// Event Time streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);DataStream<String> dataStream = streamEnv.readFile(auditFormat, dataDir, FileProcessingMode.PROCESS_CONTINUOUSLY, 1000). assignTimestampsAndWatermarks( new TimestampExtractor());// ... ... // public class TimestampExtractor implements AssignerWithPeriodicWatermarks<String>{ @Override public Watermark getCurrentWatermark() { return new Watermark(System.currentTimeMillis()-maxTimeFrame); } @Override public long extractTimestamp(String str, long l) { return InputData.getDataObject(str).timestamp; } }
- Tempo de absorção: é o momento em que o evento entra em Flink; atribuído quando o evento está na origem e, portanto, é considerado mais estável do que o tempo de processamento atribuído quando o processo começa a ser executado.
O tempo de absorção não é adequado para lidar com eventos fora de ordem ou dados atrasados porque o registro de data e hora é quando a absorção começa; neste aspecto, difere da hora do evento, que fornece a capacidade de detectar eventos pendentes e processá-los, contando com o mecanismo de marca d'água.
// Ingestion Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
Você pode ler mais sobre carimbos de data / hora e como eles afetam o streaming no link a seguir .
Quebra de janela
O fluxo é, por definição, infinito; portanto, o mecanismo de processamento está associado à definição de fragmentos (por exemplo, períodos de janela). Assim, o fluxo é dividido em lotes que são convenientes para agregação e análise. Uma definição de janela é uma operação em um objeto DataStream ou qualquer outra coisa que herde dele.
Existem vários tipos de janelas dependentes do tempo:
Janela em cascata (configuração padrão):
O fluxo é dividido em janelas de tamanho equivalente que não se sobrepõem. Enquanto o fluxo está fluindo, Flink calcula continuamente os dados com base neste storyboard fixo no tempo. Implementação de

janela
em cascata no código:
// ,
public AllWindowedStream<T,TimeWindow> timeWindowAll(Time size)
// ,
public WindowedStream<T,KEY,TimeWindow> timeWindow(Time size)
Janela deslizante
Essas janelas podem se sobrepor umas às outras, e as propriedades da janela deslizante são determinadas pelo tamanho dessa janela e pela margem (quando iniciar a próxima janela). Nesse caso, eventos relacionados a mais de uma janela podem ser processados em um determinado momento.

Janela deslizante
E é assim que fica no código:
// 1 30
dataStreamObject.timeWindow(Time.minutes(1), Time.seconds(30))
Janela de sessão
Inclui todos os eventos limitados pelo escopo de uma sessão. A sessão termina se não houver atividade ou se nenhum evento for registrado após um determinado período de tempo. Este período pode ser fixo ou dinâmico, dependendo dos eventos que estão sendo processados. Em teoria, se o intervalo entre as sessões for menor que o tamanho da janela, a sessão pode nunca terminar.
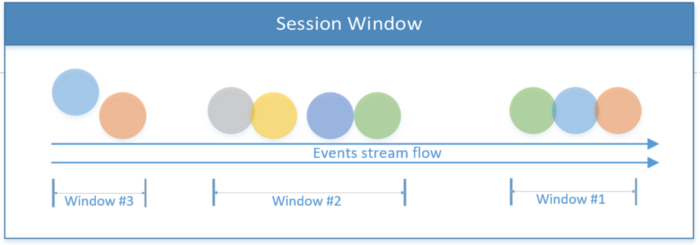
Janela de sessão
O primeiro trecho de código abaixo mostra uma sessão com um valor de tempo fixo (2 segundos). O segundo exemplo implementa uma janela de sessão dinâmica baseada em eventos de thread.
// 2
dataStreamObject.window(ProcessingTimeSessionWindows.withGap(Time.seconds(2)))
// ,
dataStreamObject.window(EventTimeSessionWindows.withDynamicGap((elem) -> {
// ,
}))
Janela global
Todo o sistema é tratado como uma única janela.

A janela global do
Flink também permite que você implemente suas próprias janelas, cuja lógica é definida pelo usuário.
Além das janelas dependentes do tempo, existem outras, por exemplo, a janela Conta, onde o limite para o número de eventos recebidos é definido; quando o limite X é atingido, o Flink processa X eventos.

Janela de contagem para três eventos
Após uma introdução teórica, vamos discutir em mais detalhes o que é um fluxo de dados do ponto de vista prático. Para obter mais informações sobre o Apache Flink e threading, consulte o site oficial .
Descrição do fluxo
Como um resumo da parte teórica, o diagrama de blocos a seguir mostra os principais fluxos de dados implementados nos fragmentos de código deste artigo. O fluxo abaixo começa na fonte (os arquivos são gravados no diretório) e continua enquanto processa eventos que são transformados em objetos.
A implementação descrita a seguir possui dois caminhos de processamento. O mostrado na parte superior divide um fluxo em dois fluxos laterais, e então os combina, obtendo um fluxo do terceiro tipo. O script mostrado na parte inferior do diagrama descreve o processamento do fluxo, após o qual os resultados do trabalho são transferidos para o coletor.

A seguir, tentaremos sentir com as mãos a implementação prática da teoria acima; todo o código-fonte discutido abaixo está postado no GitHub .
Processamento de fluxo básico (Exemplo # 1)
Será mais fácil entender os conceitos do Flink se você começar com o aplicativo mais simples. Nesta aplicação, o produtor grava os arquivos em um diretório, simulando assim o fluxo de informações. Flink lê arquivos deste diretório e grava informações resumidas sobre eles no diretório de destino; este é o estoque.
A seguir, vamos examinar de perto o que acontece durante o processamento:
Converter dados brutos em um objeto:
// InputData;
DataStream<InputData> inputDataObjectStream
= dataStream
.map((MapFunction<String, InputData>) inputStr -> {
System.out.println("--- Received Record : " + inputStr);
return InputData.getDataObject(inputStr);
});
O trecho de código a seguir
InputData
converte um objeto de fluxo ( ) em uma string e uma tupla inteira. Ele extrai apenas certos campos do fluxo de objetos, agrupando-os por um campo em quanta de dois segundos.
//
DataStream<Tuple2<String, Integer>> userCounts
= inputDataObjectStream
.map(new MapFunction<InputData,Tuple2<String,Integer>>() {
@Override
public Tuple2<String,Integer> map(InputData item) {
return new Tuple2<String,Integer>(item.getName() ,item.getScore() );
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0) // KeyedStream<T, Tuple> ( 'name')
//.timeWindowAll(Time.seconds(windowInterval)) // timeWindowAll
.timeWindow(Time.seconds(2)) // WindowedStream<T, KEY, TimeWindow>
.reduce((x,y) -> new Tuple2<String,Integer>( x.f0+"-"+y.f0, x.f1+y.f1));
Criação de um destino para um fluxo (implementação de um coletor de dados):
//
DataStream<Tuple2<String,Integer>> inputCountSummary
= inputDataObjectStream
.map( item
-> new Tuple2<String,Integer>
(String.valueOf(System.currentTimeMillis()),1))
// (1)
.returns(Types.TUPLE(Types.STRING ,Types.INT))
.timeWindowAll(Time.seconds(windowInterval)) //
.reduce((x,y) -> // ,
(new Tuple2<String, Integer>(x.f0, x.f1 + y.f1)));
//
final StreamingFileSink<Tuple2<String,Integer>> countSink
= StreamingFileSink
.forRowFormat(new Path(outputDir),
new SimpleStringEncoder<Tuple2<String,Integer>>
("UTF-8"))
.build();
// DataStream; inputCountSummary countSink
inputCountSummary.addSink(countSink);
Código de amostra para criar um coletor de dados.
Dividindo fluxos (exemplo # 2)
Este exemplo demonstra como dividir o fluxo principal usando fluxos de saída laterais. Flink fornece vários fluxos laterais do fluxo principal
DataStream
. O tipo de dados localizado em cada lado do fluxo pode ser diferente do tipo de dados do fluxo principal, bem como o tipo de dados de cada um dos fluxos secundários.
Portanto, usando um fluxo de saída lateral, você pode matar dois coelhos com uma cajadada: dividir o fluxo e converter o tipo de dados do fluxo em muitos tipos de dados (eles podem ser exclusivos para cada fluxo de saída lateral).
O trecho de código abaixo é chamado de
ProcessFunction
divisão do fluxo em dois lados, dependendo da propriedade de entrada. Para obter o mesmo resultado, teríamos que usar a função repetidamente
filter
.
Função
ProcessFunction
coleta certos objetos (com base no critério) e os envia para o coletor de saída principal (está em
SingleOutputStreamOperator
), e o resto dos eventos são transmitidos para as saídas secundárias. O fluxo se
DataStream
divide verticalmente e publica diferentes formatos para cada fluxo secundário.
Observe que a definição de uma saída de stream lateral é baseada em uma tag de saída única (objeto
OutputTag
).
//
final OutputTag<Tuple2<String,String>> playerTag
= new OutputTag<Tuple2<String,String>>("player"){};
//
final OutputTag<Tuple2<String,Integer>> singerTag
= new OutputTag<Tuple2<String,Integer>>("singer"){};
// InputData .
SingleOutputStreamOperator<InputData> inputDataMain
= inputStream
.process(new ProcessFunction<String, InputData>() {
@Override
public void processElement(
String inputStr,
Context ctx,
Collector<InputData> collInputData) {
Utils.print(Utils.COLOR_CYAN, "Received record : " + inputStr);
// InputData
InputData inputData = InputData.getDataObject(inputStr);
switch (inputData.getType())
{
case "Singer":
//
ctx.output(singerTag,
new Tuple2<String,Integer>
(inputData.getName(), inputData.getScore()));
break;
case "Player":
// ;
// playerTag, (" ")
ctx.output(playerTag,
new Tuple2<String, String>
(inputData.getName(), inputData.getType()));
break;
default:
// InputData
collInputData.collect(inputData);
break;
}
}
});
Código de amostra demonstrando como dividir um fluxo
Combinando streams (exemplo # 3)
A última operação que será abordada neste artigo é a concatenação de encadeamentos. A ideia é combinar dois fluxos diferentes, cujos formatos de dados podem ser diferentes, a partir dos quais coletar um fluxo com uma estrutura de dados unificada. Ao contrário da operação de junção do SQL, onde os dados são mesclados horizontalmente, os fluxos são mesclados verticalmente, uma vez que o fluxo de eventos continua e não é limitado no tempo.
A concatenação de fluxos é feita chamando o método de conexão e, em seguida, uma operação de mapeamento é definida para cada item em cada fluxo individual. O resultado é um fluxo mesclado.
//
ConnectedStreams<Tuple2<String, Integer>, Tuple2<String, String>> mergedStream
= singerStream
.connect(playerStream);
DataStream<Tuple4<String, String, String, Integer>> combinedStream
= mergedStream.map(new CoMapFunction<
Tuple2<String, Integer>, // 1
Tuple2<String, String>, // 2
Tuple4<String, String, String, Integer> //
>() {
@Override
public Tuple4<String, String, String, Integer> // 1
map1(Tuple2<String, Integer> singer) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: singer stream", singer.f0, "", singer.f1);
}
@Override
public Tuple4<String, String, String, Integer>
// 2
map2(Tuple2<String, String> player) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: player stream", player.f0, player.f1, 0);
}
});
Lista mostrando como obter um fluxo mesclado
Criando um projeto de trabalho
Então, para recapitular: o projeto de demonstração é carregado no GitHub. Ele descreve como construir e compilá-lo. Este é um bom ponto de partida para praticar com o Flink.
conclusões
Este artigo descreve as operações básicas para criar um aplicativo funcional de encadeamento baseado em Flink. O objetivo do aplicativo é fornecer uma visão geral das chamadas críticas inerentes ao streaming e estabelecer a base para a criação subsequente de um aplicativo Flink totalmente funcional.
Como o streaming tem muitas facetas e complexidades, muitos dos problemas neste artigo permanecem sem solução; em particular, execução de Flink e gerenciamento de tarefas, marca d'água ao definir o tempo para eventos de streaming, injeção de estado em eventos de stream, execução de iterações de stream, execução de consultas semelhantes a SQL em streams e muito mais.
Esperamos que este artigo tenha sido suficiente para fazer você querer experimentar o Flink.