
Hoje, as redes neurais artificiais estão no centro de muitas técnicas de "inteligência artificial". Ao mesmo tempo, o processo de treinamento de novos modelos de rede neural é colocado em operação (graças ao grande número de estruturas distribuídas, conjuntos de dados e outros "espaços em branco") que pesquisadores de todo o mundo podem facilmente construir novos algoritmos "eficazes" "seguros", às vezes sem nem mesmo entrar em , que é o resultado. Em alguns casos, isso pode levar a consequências irreversíveis na próxima etapa, no processo de uso de algoritmos treinados. No artigo de hoje, analisaremos uma série de ataques à inteligência artificial, como funcionam e a que consequências podem levar.
Como você sabe, nós da Smart Engines tratamos cada etapa do processo de treinamento do modelo de rede neural com apreensão, desde a preparação de dados (veja aqui , aqui e aqui ) até o desenvolvimento da arquitetura de rede (veja aqui , aqui e aqui ). No mercado de soluções em inteligência artificial e sistemas de reconhecimento, somos os guias e promotores de ideias para o desenvolvimento tecnológico responsável. Há um mês até aderimos ao Pacto Global da ONU .
Então, por que é tão assustador aprender redes neurais "descuidadamente"? Pode uma malha ruim (que simplesmente não reconhecer bem) realmente prejudicar seriamente? Acontece que o ponto aqui não está tanto na qualidade de reconhecimento do algoritmo obtido, mas na qualidade do sistema resultante como um todo.
Como um exemplo simples e direto, vamos imaginar o quão ruim um sistema operacional pode ser. Na verdade, nem um pouco pela interface do usuário antiquada, mas pelo fato de não fornecer o nível adequado de segurança, não impede de forma alguma ataques externos de hackers.
Considerações semelhantes são verdadeiras para sistemas de inteligência artificial. Hoje, vamos falar sobre ataques a redes neurais que levam a sérios problemas de funcionamento do sistema de destino.
Envenenamento de dados
O primeiro e mais perigoso ataque é o envenenamento de dados. Nesse ataque, o erro está embutido no estágio de treinamento e os atacantes sabem com antecedência como enganar a rede. Se fizermos uma analogia com uma pessoa, imagine que você está aprendendo uma língua estrangeira e aprende algumas palavras de forma incorreta, por exemplo, você acha que cavalo é sinônimo de casa. Então, na maioria dos casos, você será capaz de falar com calma, mas em casos raros cometerá erros grosseiros. Um truque semelhante pode ser feito com redes neurais. Por exemplo, em [1], a rede é enganada para reconhecer sinais de trânsito. Ao ensinar a rede, eles mostram sinais de Stop e dizem que isso é realmente Pare, sinais de Limite de Velocidade com a etiqueta correta, bem como sinais de Stop com um adesivo e uma etiqueta de Limite de Velocidade colados nele.A rede acabada com alta precisão reconhece os sinais na amostra de teste, mas na verdade, uma bomba é plantada nela. Se tal rede for usada em um sistema de piloto automático real, quando vir um sinal de Pare com um adesivo, ele a levará para o Limite de velocidade e continuará a mover o carro.
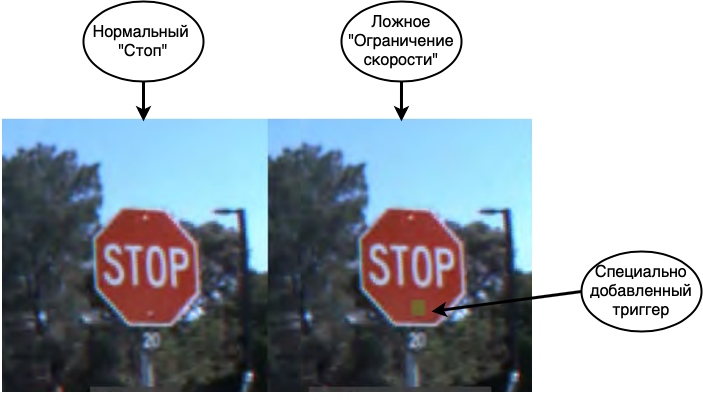
Como você pode ver, o envenenamento de dados é um tipo de ataque extremamente perigoso, cujo uso, entre outras coisas, é seriamente limitado por um recurso importante: o acesso direto aos dados é necessário. Se excluirmos os casos de espionagem corporativa e corrupção de dados por funcionários, os seguintes cenários permanecem quando isso pode acontecer:
- Corrupção de dados em plataformas de crowdsourcing. , ( ?...), , - , . , , . , «» . , . (, ). , , , , «» . .
- . , – . « » - . , . , , [1].
- Corrupção de dados durante o treinamento na nuvem. As arquiteturas populares de redes neurais pesadas são quase impossíveis de treinar em um computador normal. Em busca de resultados, muitos desenvolvedores estão começando a ensinar seus modelos na nuvem. Com esse treinamento, os invasores podem obter acesso aos dados de treinamento e danificá-los sem o conhecimento do desenvolvedor.
Ataque de evasão
O próximo tipo de ataque que veremos são os ataques de esquiva. Esses ataques ocorrem na fase de uso de redes neurais. Ao mesmo tempo, o objetivo continua o mesmo: fazer com que a rede dê respostas incorretas em determinadas situações.
Inicialmente, erro de evasão significava erros do tipo II, mas agora esse é o nome de qualquer engano de uma rede em funcionamento [8]. Na verdade, o invasor está tentando criar uma ilusão de ótica (auditiva, semântica) na rede. Deve ser entendido que a percepção de uma imagem (som, significado) pela rede é significativamente diferente de sua percepção por uma pessoa, portanto, muitas vezes você pode ver exemplos quando duas imagens muito semelhantes - indistinguíveis para uma pessoa - são reconhecidas de forma diferente. Os primeiros exemplos foram mostrados em [4] e em [5] apareceu um exemplo popular com um panda (veja a ilustração do título deste artigo).
Normalmente, exemplos de adversários são usados para ataques de evasão. Esses exemplos têm algumas propriedades que comprometem muitos sistemas:
- , , [4]. « », [7]. « » , . , , . , [14], « » .

- Os exemplos adversários são transportados perfeitamente para o mundo físico. Primeiro, você pode selecionar cuidadosamente os exemplos que são incorretamente reconhecidos com base nas características do objeto conhecido por uma pessoa. Por exemplo, em [6], os autores fotografam uma máquina de lavar de diferentes ângulos e às vezes recebem a resposta “seguro” ou “alto-falantes”. Em segundo lugar, os exemplos adversários podem ser arrastados de uma figura para o mundo físico. Em [6], eles mostraram como, tendo alcançado o engano da rede neural modificando a imagem digital (um truque semelhante ao panda mostrado acima), pode-se "traduzir" a imagem digital resultante em forma material por uma simples impressão e continuar a enganar a rede já no mundo físico.
Os ataques de evasão podem ser divididos em diferentes grupos: de acordo com a resposta desejada, de acordo com a disponibilidade do modelo e de acordo com o método de seleção de interferências:
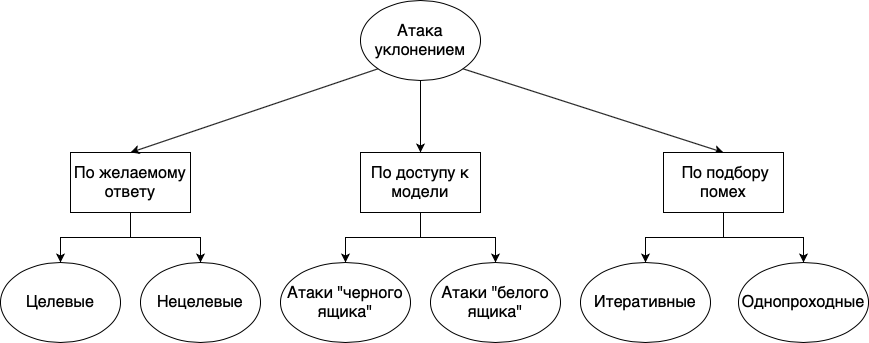
- . , , . , . , «», «», «», , , , . . , , , , .
- . , , , , . , , - , . , , . « », , , . . « » , , . , , . , , . , , , , .
- . , . , , , . : . , . . , , . « ».
Claro, não são apenas as redes que classificam os animais e objetos que estão sujeitos a ataques de evasão. A figura a seguir, retirada de um artigo de 2020 apresentado na Conferência IEEE / CVF sobre Visão Computacional e Reconhecimento de Padrões [12], mostra o quão bem se pode falsificar redes recorrentes para OCR:
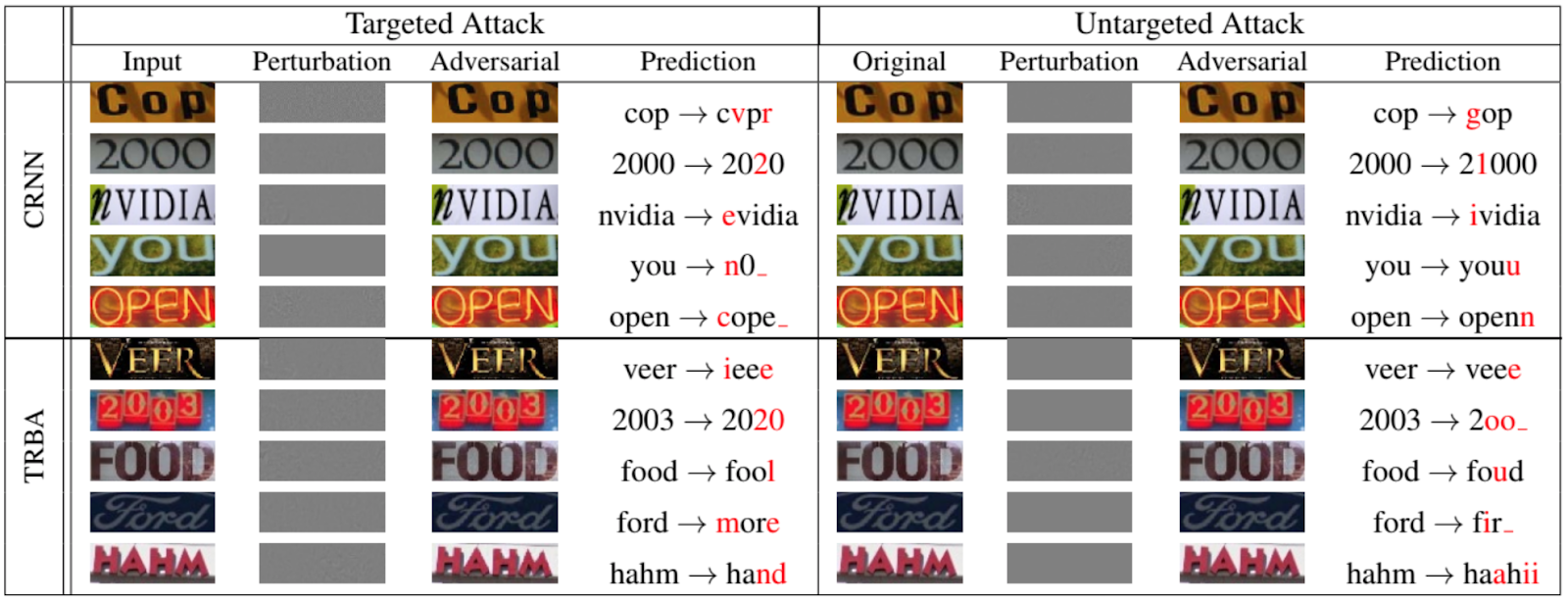
Agora, sobre alguns outros ataques à rede
Durante nossa história, mencionamos a amostra de treinamento várias vezes, mostrando que às vezes é ele, e não o modelo treinado, que é o alvo dos atacantes.
A maioria dos estudos mostra que os modelos de reconhecimento são mais bem ensinados com dados representativos reais, o que significa que os modelos geralmente contêm muitas informações valiosas. É improvável que alguém esteja interessado em roubar fotos de gatos. Mas algoritmos de reconhecimento também são usados para fins médicos, sistemas para processamento de informações pessoais e biométricas, etc., onde exemplos de “treinamento” (na forma de informações pessoais ou biométricas ao vivo) são de grande valor.
Assim, consideraremos dois tipos de ataques: um ataque ao estabelecimento da propriedade e um ataque por inversão do modelo.
Ataque de afiliação
Nesse ataque, o invasor tenta determinar se dados específicos foram usados para treinar o modelo. Embora à primeira vista pareça que não há nada de errado com isso, como dissemos acima, existem várias violações de privacidade.
Em primeiro lugar, sabendo que alguns dos dados sobre uma pessoa foram usados no treinamento, você pode tentar (e às vezes até com êxito) extrair outros dados sobre uma pessoa do modelo. Por exemplo, se você tiver um sistema de reconhecimento de rosto que também armazena dados pessoais de uma pessoa, pode tentar reproduzir a foto pelo nome.
Em segundo lugar, a divulgação direta de segredos médicos é possível. Por exemplo, se você tem um modelo que rastreia os movimentos de pessoas com Alzheimer e sabe que dados sobre uma determinada pessoa foram usados em treinamento, você já sabe que essa pessoa está doente [9].
Ataque de inversão de modelo
Inversão de modelo refere-se à capacidade de obter dados de treinamento de um modelo treinado. No processamento de linguagem natural e, mais recentemente, no reconhecimento de imagens, as redes de processamento de sequência são frequentemente utilizadas. Certamente todos encontraram preenchimento automático no Google ou Yandex ao inserir uma consulta de pesquisa. A continuação das frases em tais sistemas é construída com base na amostra de treinamento disponível. Como resultado, se houver alguns dados pessoais no conjunto de treinamento, eles podem aparecer repentinamente no preenchimento automático [10, 11].
Em vez de uma conclusão
Todos os dias, sistemas de inteligência artificial de várias escalas estão cada vez mais "se acomodando" em nossa vida diária. Sob as belas promessas de automatizar processos de rotina, aumentar a segurança geral e outro futuro brilhante, damos aos sistemas de inteligência artificial várias áreas da vida humana, uma após a outra: entrada de texto nos anos 90, sistemas de assistência ao motorista nos anos 2000, processamento biométrico em 2010- x, etc. Até agora, em todas essas áreas, os sistemas de inteligência artificial receberam apenas o papel de um assistente, mas devido a algumas peculiaridades da natureza humana (em primeiro lugar, preguiça e irresponsabilidade), a mente do computador muitas vezes atua como um comandante, às vezes levando a consequências irreversíveis.
Todo mundo já ouviu histórias sobre como os pilotos automáticos travam, erros de sistemas de inteligência artificial do setor bancário , surgem problemas de processamento biométrico . Mais recentemente, devido a um erro no sistema de reconhecimento facial, um russo quase foi preso por 8 anos .
Até agora, são todas flores apresentadas por casos isolados.
As bagas estão à frente. Nos. Em breve.
Bibliografia
[1] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, «BadNets: Evaluating backdooring attacks on deep neural networks», 2019, IEEE Access.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.