Este artigo apareceu por vários motivos.
Em primeiro lugar, na esmagadora maioria dos livros, recursos da Internet e lições sobre Ciência de Dados, as nuances, falhas de diferentes tipos de normalização de dados e suas razões não são consideradas de forma alguma, ou são mencionadas apenas de passagem e sem revelar a essência.
Em segundo lugar, existe um uso "cego", por exemplo, da padronização para conjuntos com um grande número de recursos - "para que seja igual para todos". Principalmente para iniciantes (ele mesmo era o mesmo). À primeira vista, tudo bem. Mas, ao examinar mais de perto, pode acontecer que alguns sinais foram colocados inconscientemente em uma posição privilegiada e começaram a influenciar o resultado muito mais fortemente do que deveriam.
E, em terceiro lugar, sempre quis obter um método universal que levasse em consideração as áreas problemáticas.
A repetição é a mãe da aprendizagem
A normalização é a conversão de dados em certas unidades adimensionais. Às vezes - dentro de um determinado intervalo, por exemplo, [0..1] ou [-1..1]. Às vezes - com alguma propriedade dada, como, por exemplo, um desvio padrão de 1.
O principal objetivo da normalização é trazer vários dados em uma ampla variedade de unidades e intervalos de valores em um único formulário que permitirá a você compará-los entre si ou usar para calcular a similaridade de objetos. Na prática, isso é necessário, por exemplo, para clustering e em alguns algoritmos de aprendizado de máquina.
Analiticamente, qualquer normalização é reduzida à fórmula
Onde - valor presente,
- o valor dos valores de deslocamento,
- o tamanho do intervalo a ser convertido em "um"
Na verdade, tudo se resume ao fato de que o conjunto original de valores é primeiro deslocado e depois escalado.
Exemplos:
Minimax (MinMax) . O objetivo é converter o conjunto original para o intervalo [0..1]. Para ele:
= , .
= — , .. “” .
. — 0 1.
= , .
— .
, .
, , “” . .
, - . , . , , . , . , — . , , , , *
* — , , ( ), , .
, — .
1 —
— .. , , 0 “” .
? « » . .
№ 1 — , .
, “ ” , , — , . ( ). ( ) .
, , .
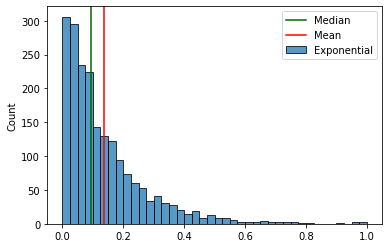
:
. “” .
, , , . .
2 —
. .
. , , [-1..1], . [-1..1], — [-1..100], , . .
. . , “”.
( ):

( ) , .
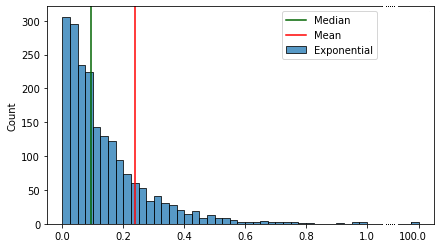
, () “”, .

— ( ). , “” .
75- 25- — . .. , “” 50% . “” / .
— “”, “” .
№ 2 — “” .
— .
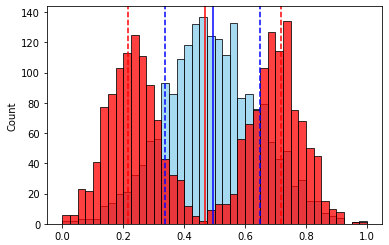
( ).

- “” . , , “”.
. .. . — 1.
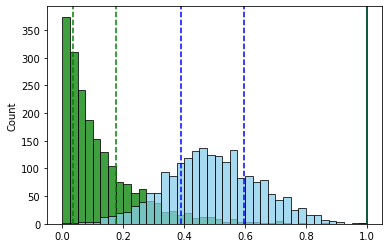
, , , № 3 — . ( ) .
, , . 2-
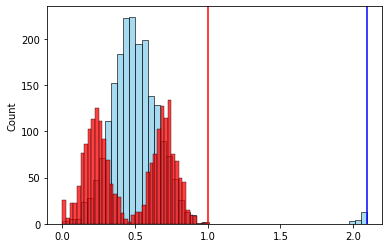
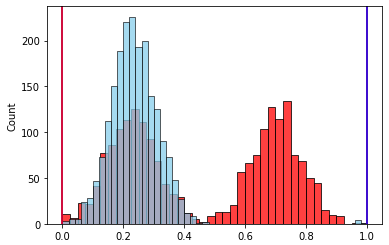
, , . .
, “-”. — .
— , . , . , , , , ? .
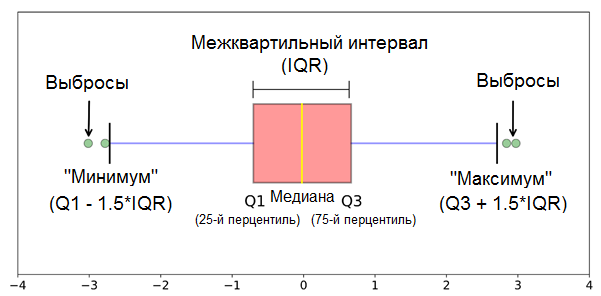
, . , “” , 1,5 (IQR) .*
* — ( .) 1,5 3 — .
.
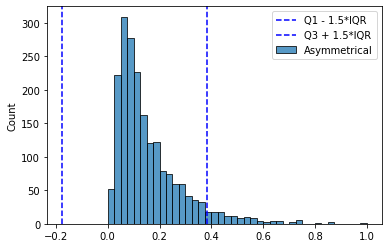
— - , .
. (, , ) “” — 7%. (3 * IQR) — . . .. .
, . “ ” (1,5 * IQR) , . , - “” .
(Mia Hubert and Ellen Vandervieren) 2007 . “An Adjusted Boxplot for Skewed Distributions”.
“ ” , 1,5 * IQR.
“ ” medcouple (MC), :
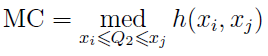
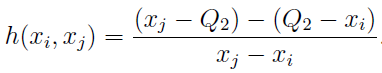
“ ” , , , 1,5 * IQR — 0,7%
:
:

:
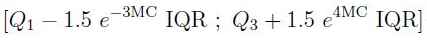
. .
, , :
- , , .
- .
- () — , , [0..1]
… — Mia Hubert Ellen Vandervieren
. .
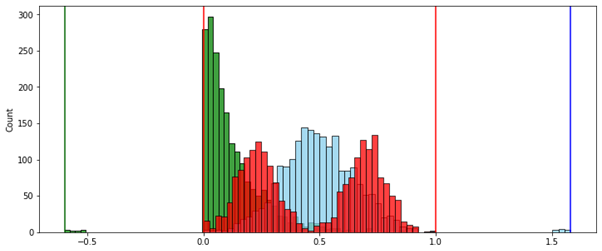
, ( ) (MinMax — ).
№ 1 — . . , “” .
:
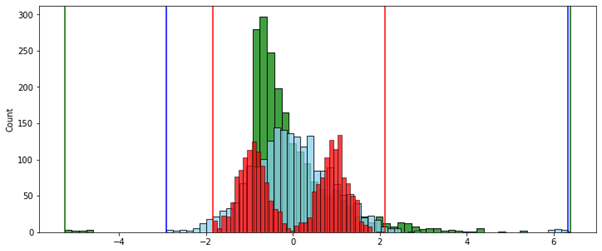
( ):

:

, — , , .
№ 2 — . [0..1]. , , .
MinMax ( ):
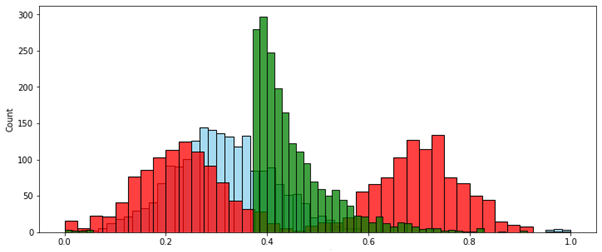
:
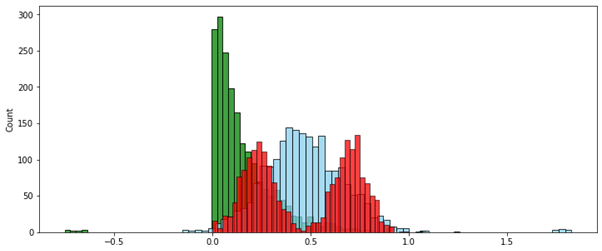
. -, , — .. 0 1.
, “” [0..1], , — , , , . .
* * *
Finalmente, para ter a oportunidade de sentir este método com suas mãos, você pode tentar minha aula de demonstração AdjustedScaler aqui .
Não está otimizado para trabalhar com uma quantidade muito grande de dados e só funciona com o pandas DataFrame, mas para ensaio, experimentação ou mesmo um vazio para algo mais sério, é bastante adequado. Tente.