
No início deste ano, a Tenzor fez um meetup na cidade de Ivanovo, no qual fiz uma apresentação sobre experimentos com fuzzing testing da interface. Aqui está uma transcrição deste relatório.
Quando os macacos substituirão todo o controle de qualidade? É possível abandonar o teste manual e os autotestes de IU, substituindo-os por fuzzing? Qual seria a aparência de um diagrama completo de estado e transição para um aplicativo TODO simples? Um exemplo de implementação e como tal difusão funciona ainda mais sob o corte.
Olá! Meu nome é Sergey Dokuchaev. Nos últimos 7 anos, tenho feito testes em todas as suas formas na Tenzor.

Temos mais de 400 pessoas responsáveis pela qualidade dos nossos produtos. 60 deles são dedicados a testes de automação, segurança e desempenho. Para oferecer suporte a dezenas de milhares de testes E2E, monitorar indicadores de desempenho de centenas de páginas e identificar vulnerabilidades em escala industrial, você precisa usar ferramentas e métodos que foram testados pelo tempo e testados em batalha.

E, via de regra, falam desses casos em conferências. Mas, além disso, há muitas coisas interessantes que ainda são difíceis de aplicar em escala industrial. Isso é interessante e vamos conversar sobre isso.

No filme "Matrix", em uma das cenas, Morpheus oferece a Neo a escolha de uma pílula vermelha ou azul. Thomas Anderson trabalhou como programador e lembramos a escolha que ele fez. Se ele fosse um testador notório, ele teria devorado os dois tablets para ver como o sistema se comportaria em condições não padrão.
A combinação de testes manuais e autotestes tornou-se quase padrão. Os desenvolvedores sabem melhor como seu código funciona e escrevem testes de unidade, os testadores funcionais verificam a funcionalidade nova ou que muda com frequência e toda a regressão vai para vários autotestes.
No entanto, ao criar e manter autotestes, de repente não há muito trabalho automático e muito manual:
- Você precisa descobrir o que e como testar.
- Você precisa encontrar os elementos na página, conduzir os localizadores necessários para os Objetos da Página.
- Escreva e depure o código.
- — . / , , ROI .
Felizmente, não existem dois ou três tablets no mundo dos testes. E toda uma dispersão: teste semântico, métodos formais, teste de difusão, soluções baseadas em IA. E ainda mais combinações.

A afirmação de que qualquer macaco que digitar em uma máquina de escrever por um tempo infinitamente longo será capaz de digitar qualquer texto com antecedência foi interrompida nos testes. Parece bom, podemos fazer um programa clicar indefinidamente na tela em lugares aleatórios e, eventualmente, podemos encontrar todos os erros.
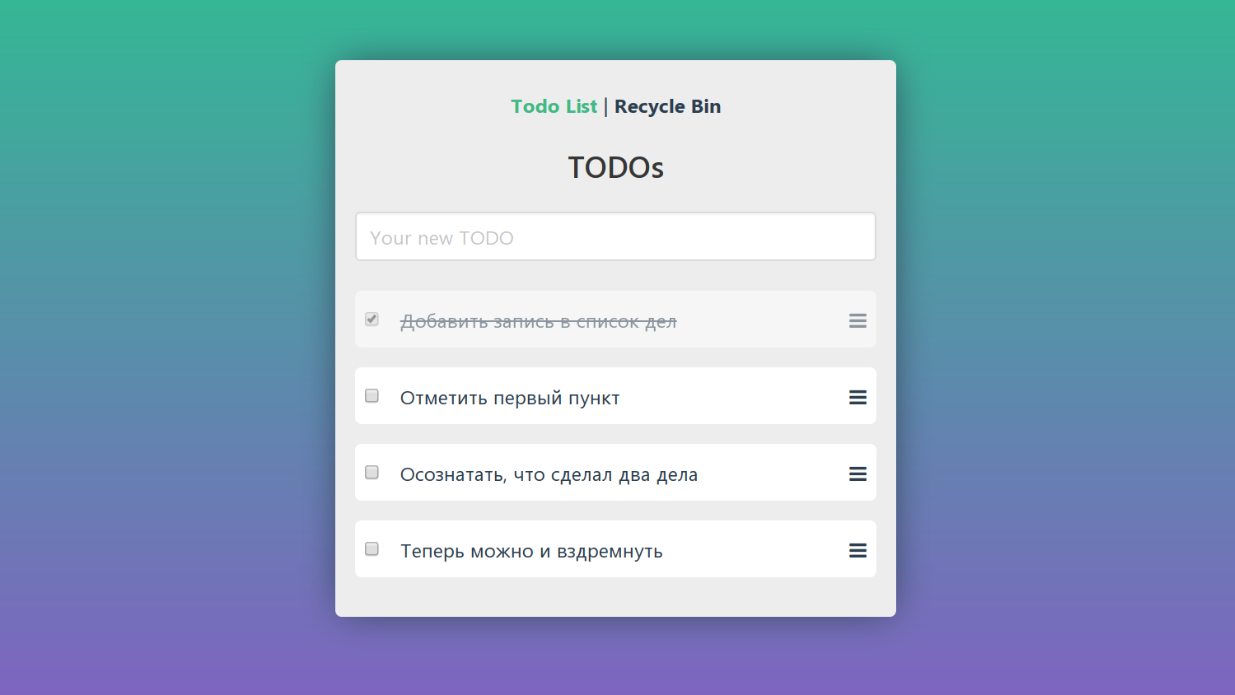
Digamos que fizemos um TODO e queremos testá-lo. Pegamos um serviço ou ferramenta adequada e vemos os macacos em ação:
Pelo mesmo princípio, meu gato de alguma forma, deitado no teclado, irrevogavelmente quebrou a apresentação e teve que fazê-lo novamente:

É conveniente quando, após 10 ações, o aplicativo lança uma exceção. Aqui, nosso macaco entende imediatamente que ocorreu um erro e podemos entender pelos registros pelo menos aproximadamente como ele se repete. E se o erro ocorrer após 100 mil cliques aleatórios e parecer uma resposta válida? A única vantagem significativa dessa abordagem é a simplicidade máxima - você aperta um botão e pronto.

O oposto dessa abordagem são os métodos formais.

Esta é uma fotografia de Nova York em 2003. Um dos lugares mais iluminados e lotados do planeta, a Times Square é iluminada apenas pelos faróis dos carros que passam. Naquele ano, milhões de pessoas no Canadá e nos Estados Unidos se viram na Idade da Pedra por três dias devido ao desligamento de uma usina de energia em cascata. Uma das principais razões para o incidente foi um erro de condição de corrida no software.
Os sistemas críticos para erros requerem uma abordagem especial. Métodos que não dependem de intuição e habilidades, mas de matemática, são chamados de formais. E, ao contrário dos testes, eles permitem provar que não há erros no código. Os modelos são muito mais difíceis de criar do que escrever o código que devem testar. E seu uso é mais como provar um teorema em uma aula de cálculo.

O slide mostra uma parte do modelo do algoritmo de dois handshake escrito na linguagem TLA +. Acho que é óbvio para todos que usar essas ferramentas para verificar os moldes no local é comparável a construir um Boeing 787 para testar as propriedades aerodinâmicas de uma planta de milho.

Mesmo em setores médicos, aeroespaciais e bancários tradicionalmente sujeitos a erros, esse tipo de teste é muito raro. Mas a abordagem em si é insubstituível se o custo de qualquer erro for calculado em milhões de dólares ou em vidas humanas.
O teste de difusão agora é mais frequentemente visto no contexto de teste de segurança. E um esquema típico demonstrando essa abordagem, tiramos do guia OWASP :

Aqui temos um site que precisa ser testado, existe um banco de dados com dados de teste e ferramentas com as quais enviaremos os dados especificados para o site. Vetores são strings comuns obtidas empiricamente. Essas cadeias de caracteres têm mais probabilidade de levar à descoberta de uma vulnerabilidade. É como a citação que muitas pessoas colocam automaticamente no lugar do número no URL da barra de endereço.
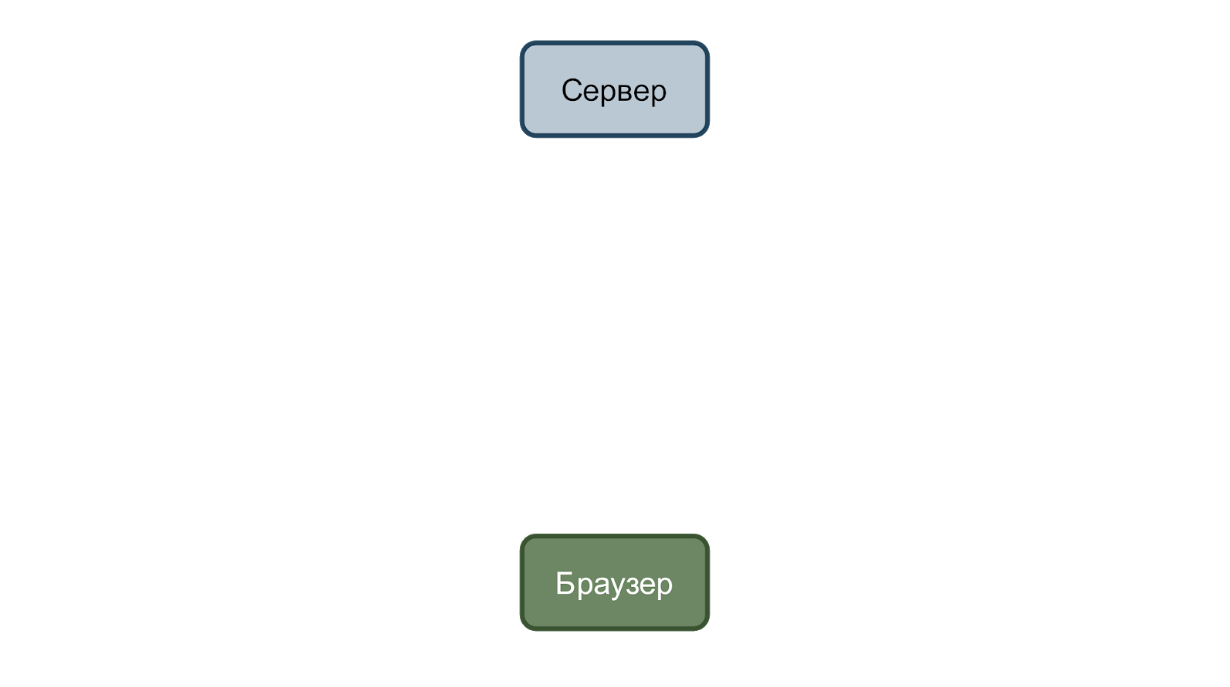
No caso mais simples, temos um serviço que aceita solicitações e um navegador que as envia. Considere um caso com a alteração da data de nascimento do usuário.

O usuário insere uma nova data e clica no botão “Salvar”. Uma solicitação é enviada ao servidor com dados no formato json.
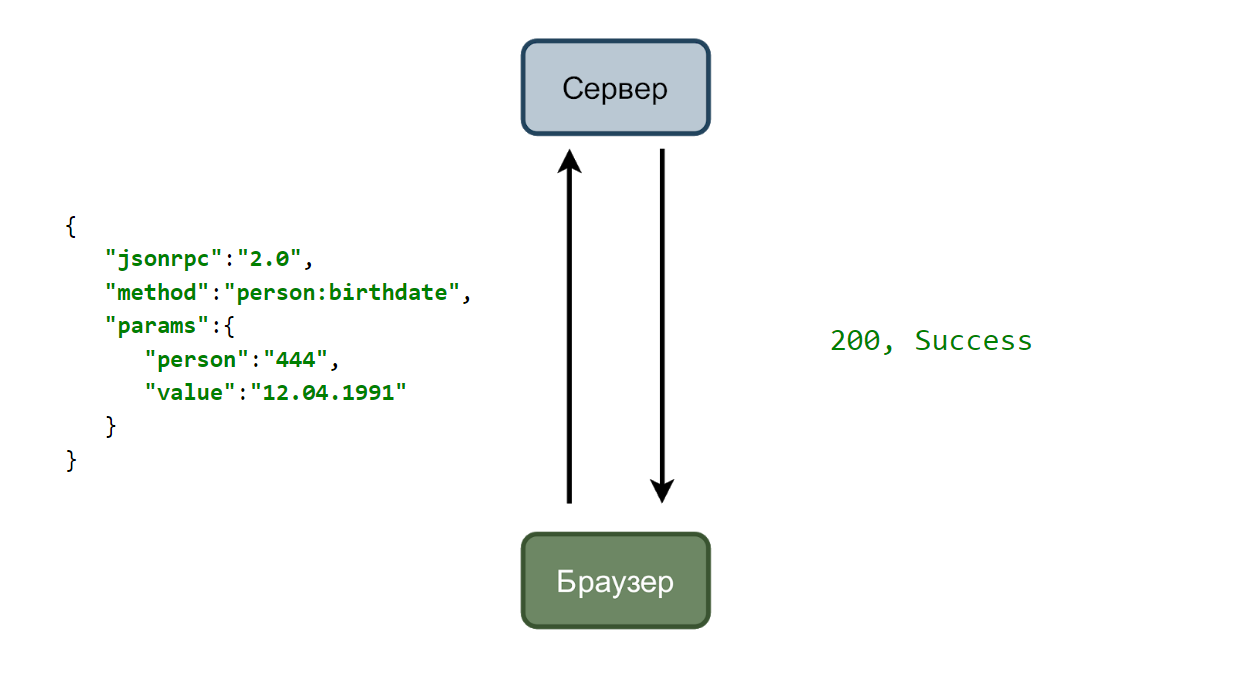
E se tudo estiver bem, o serviço responde com o código duzentésimo.

É conveniente trabalhar programaticamente com JSON e podemos ensinar nossa ferramenta de difusão a encontrar e determinar datas nos dados transmitidos. E ele vai começar a substituí-los por vários valores, por exemplo, vai transmitir um mês inexistente.

E se em resposta recebermos uma exceção em vez de uma mensagem sobre uma data inválida, então consertamos o erro.
Fuzzing a API não é difícil. Aqui temos os parâmetros transmitidos em json, aqui enviamos um pedido, recebemos uma resposta e analisamos. E quanto à GUI?
Vamos dar uma olhada no programa do exemplo de teste fictício novamente. Nele, você pode adicionar novas tarefas, marcar como concluídas, excluir e visualizar a cesta.
Se lidarmos com a decomposição, veremos que a interface não é um monólito único, ela também consiste em elementos separados:
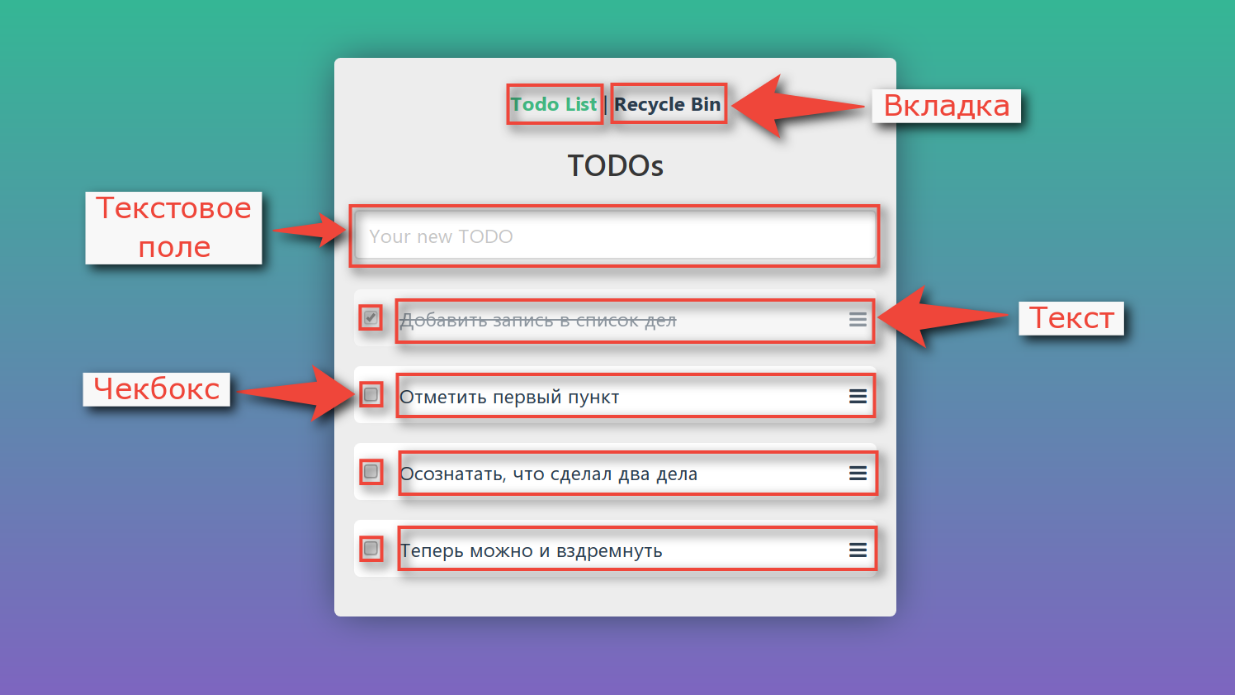
Não há muito que possamos fazer com cada um dos controles. Temos um mouse com dois botões, uma roda e um teclado. Você pode clicar em um elemento, mover o cursor do mouse sobre ele e inserir texto em campos de texto.
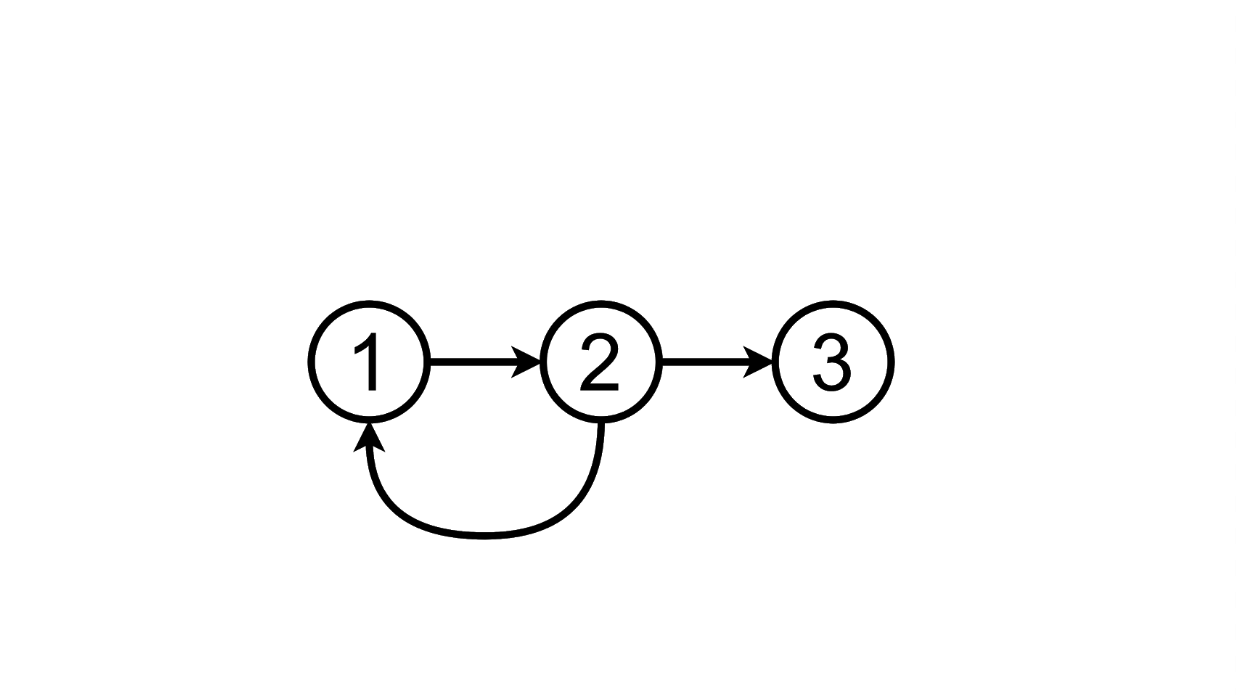
Se inserirmos algum texto no campo de texto e pressionarmos Enter, nossa página irá de um estado para outro:
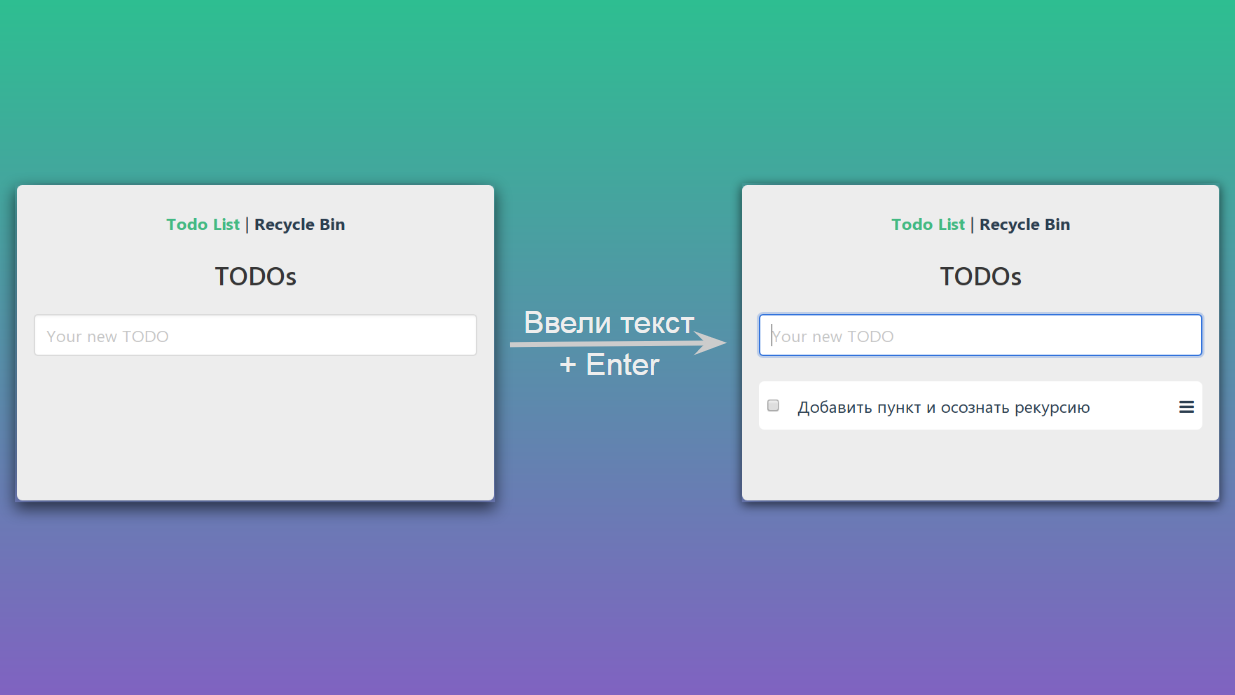
Esquematicamente, pode ser representado assim:

Deste estado, podemos ir para o terceiro adicionando outra tarefa à lista:
E podemos excluir o adicionado tarefa, retornando ao primeiro estado:
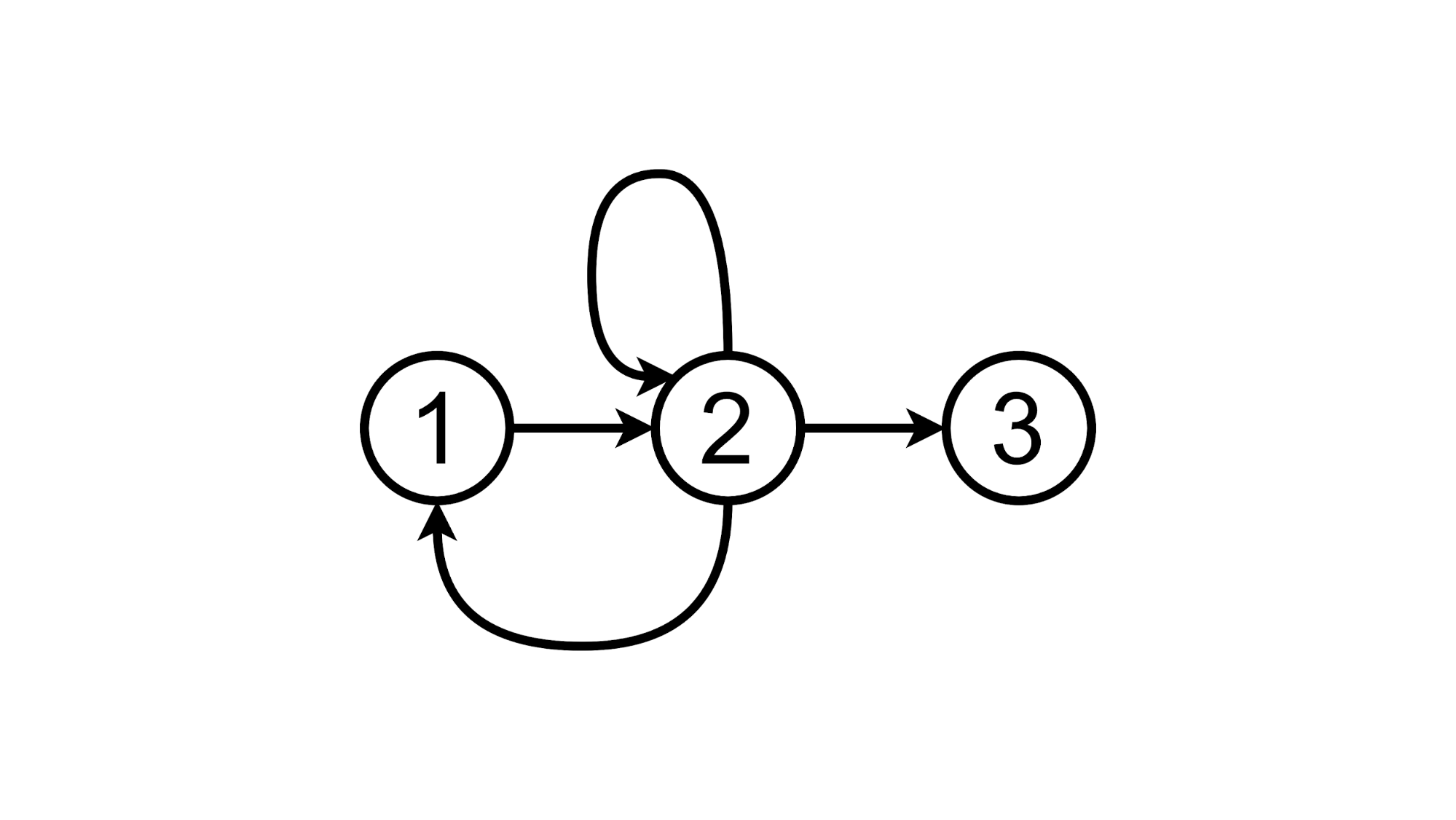
Ou clique no rótulo TODOs e permaneça no segundo estado:
E agora vamos tentar implementar a Prova de Conceito desta abordagem.

Para trabalhar com o navegador, pegaremos um chromedriver, trabalharemos com o diagrama de estado e as transições através da biblioteca python NetworkX e desenharemos através do yEd.

Iniciamos o navegador, criamos uma instância de gráfico, na qual pode haver muitas conexões com direções diferentes entre dois vértices. E abrimos nosso aplicativo.

Agora devemos descrever o estado do aplicativo. Devido ao algoritmo de compressão de imagens, podemos usar o tamanho da imagem PNG como um identificador de estado e, através do método __eq__, implementar uma comparação deste estado com outros. Através do atributo iterado, registramos que todos os botões foram clicados, valores foram inseridos em todos os campos neste estado, a fim de excluir o reprocessamento.

Escrevemos um algoritmo básico que contornará todo o aplicativo. Aqui, corrigimos o primeiro estado do gráfico, no loop clicamos em todos os elementos neste estado e corrigimos os estados resultantes. Em seguida, selecione o próximo estado não processado e repita as etapas.

Ao difundir o estado atual, devemos sempre retornar a este estado a partir de um novo. Para fazer isso, usamos a função nx.shortest_path, que retornará uma lista de elementos que precisam ser clicados para ir do estado base para o atual.
Para aguardar o fim da resposta do aplicativo às nossas ações, a função de espera usa a API Network Long Task, que mostra se JS está ocupado com algum trabalho.
Voltemos ao nosso aplicativo. O estado inicial é o seguinte:
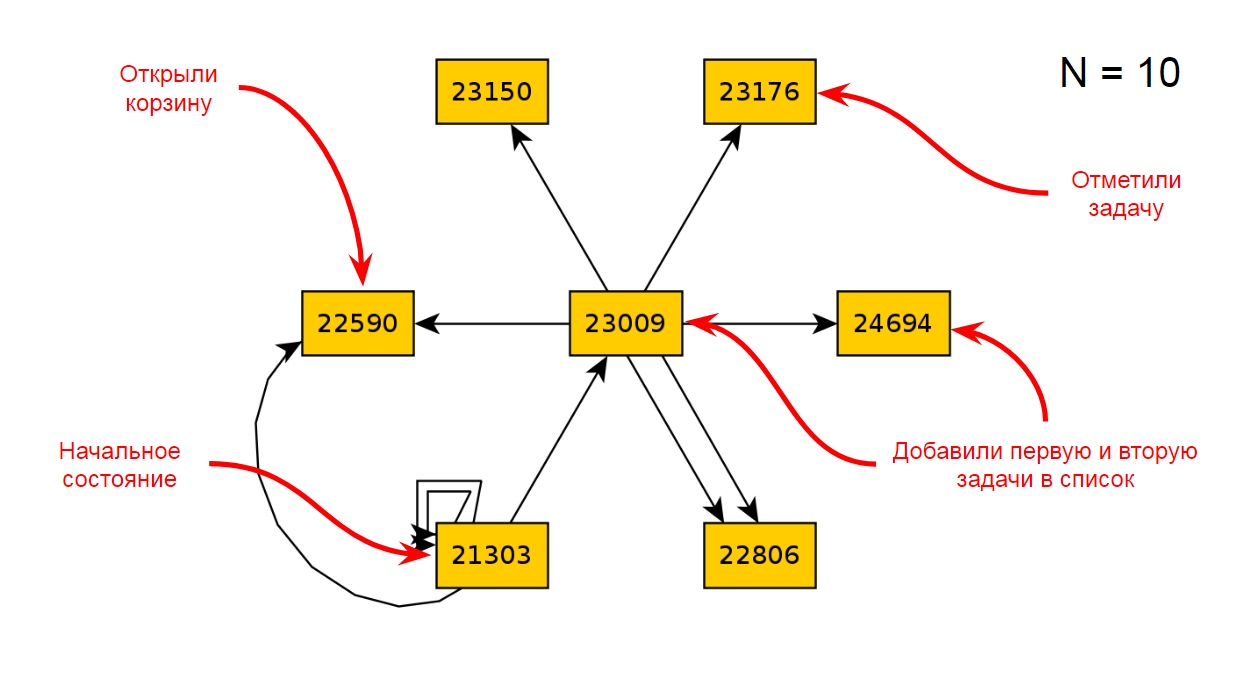
Após dez iterações do aplicativo, obteremos o seguinte diagrama de estados e transições:
Após 22 iterações, este é o seguinte:
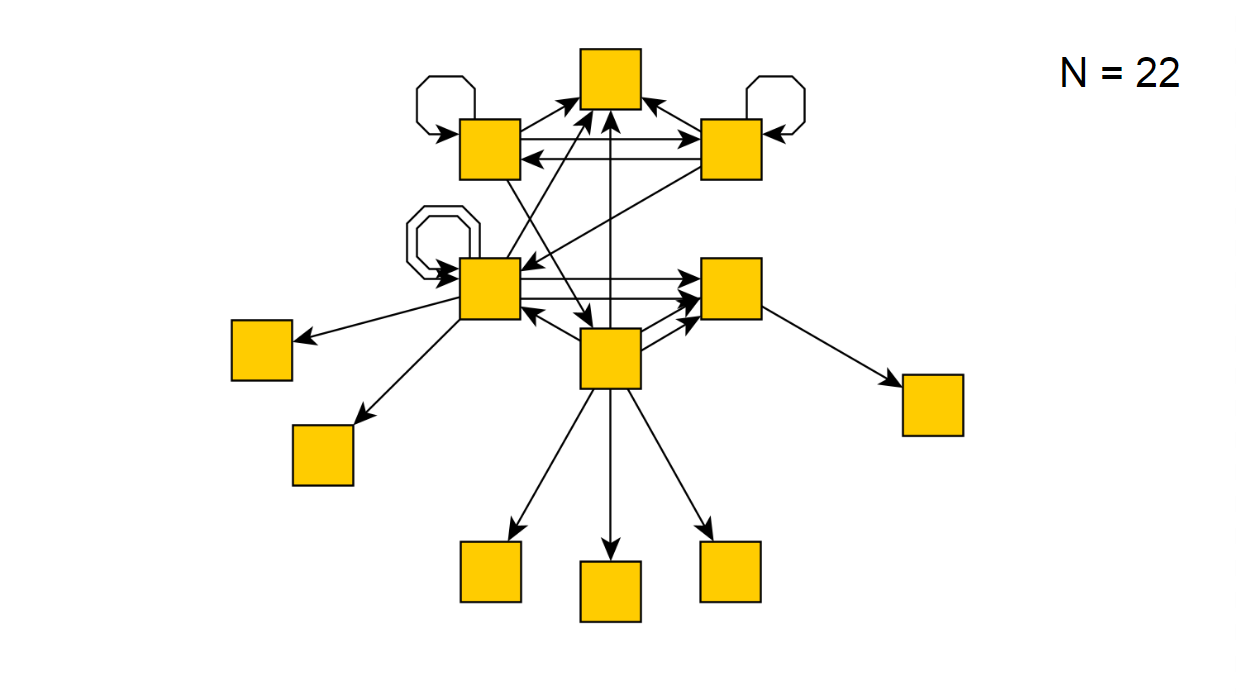
Se executarmos nosso script por várias horas, ele relatará de repente que ignorou todos os estados possíveis, recebendo o seguinte diagrama:

Então, com um aplicativo de demonstração simples Conseguimos. E o que acontece se você definir esse script em um aplicativo da web real. E haverá o caos:
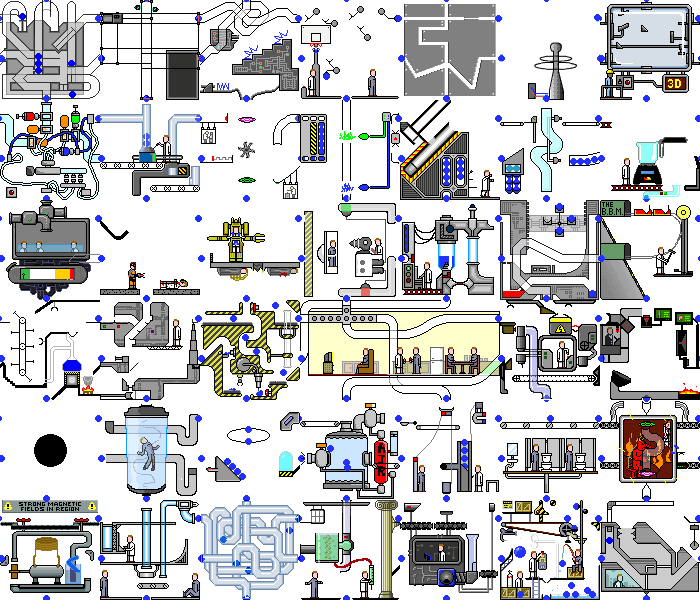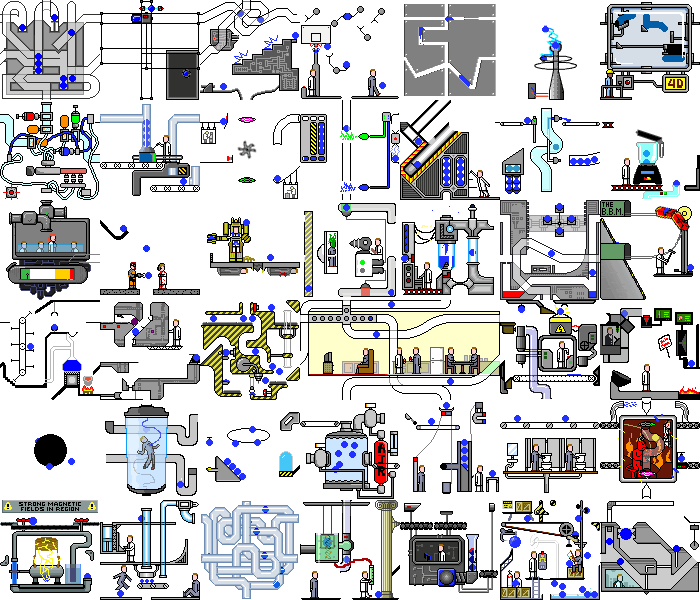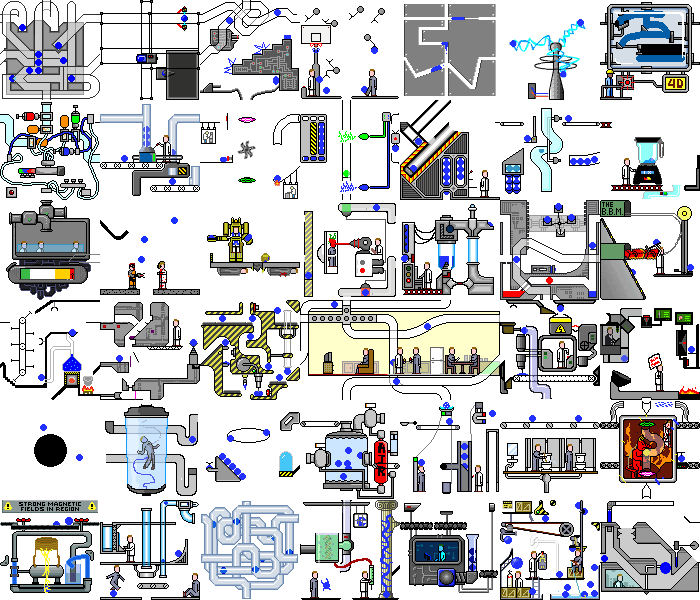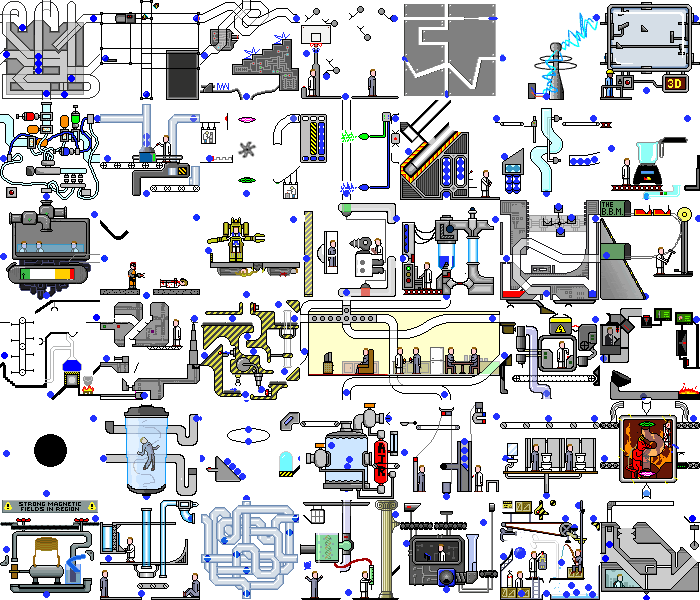
não apenas as mudanças ocorrem no backend, a própria página é constantemente redesenhada ao reagir a temporizadores ou eventos, ao realizar as mesmas ações, podemos obter estados diferentes. Mas mesmo nesses aplicativos, você pode encontrar partes da funcionalidade que nosso script pode manipular sem modificações significativas.
Faça para testePágina de autenticação VLSI:

E para ele rapidamente acabou por construir um diagrama completo de estados e transições:
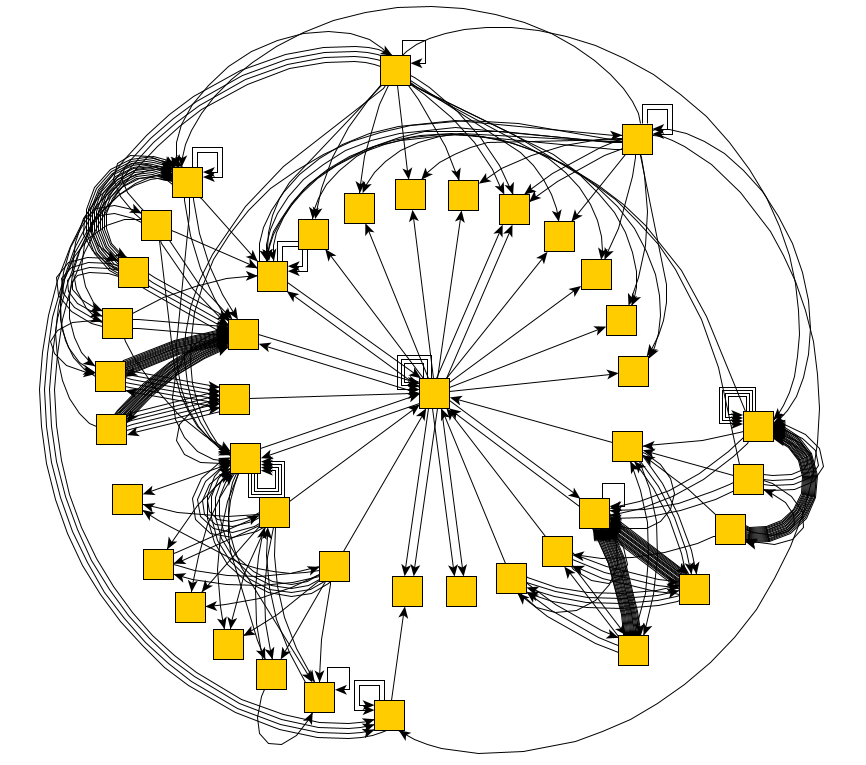

Excelente! Agora podemos percorrer todos os estados do aplicativo. E puramente em teoria, encontre todos os erros que dependem das ações. Mas como ensinar um programa a entender que há um erro antes dele?
No teste, as respostas do programa são sempre comparadas com um determinado padrão chamado oráculo. Podem ser especificações técnicas, maquetes, análogos do programa, versões anteriores, experiência do testador, requisitos formais, casos de teste, etc. Também podemos usar alguns desses oráculos em nossa ferramenta.

Vamos considerar o último padrão “antes era diferente”. Autotestes estão envolvidos em testes de regressão.
Vamos voltar ao gráfico após 10 iterações de TODO:
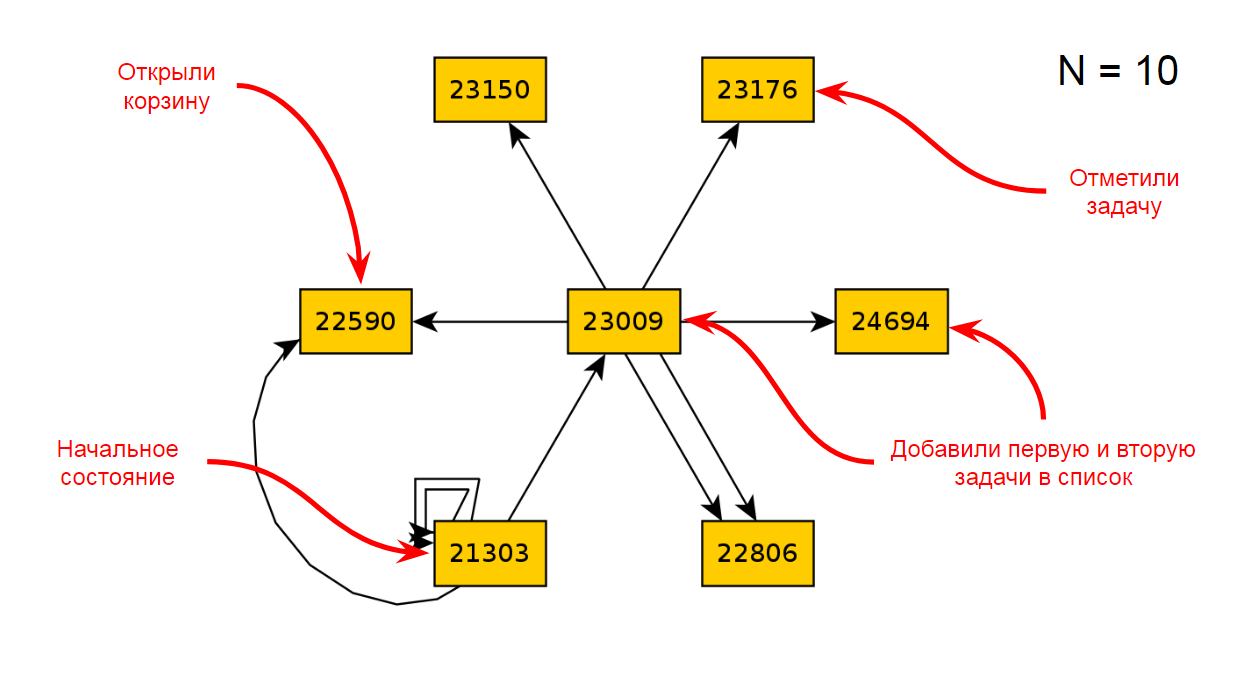
Vamos quebrar o código responsável por abrir o carrinho de compras e executar 10 iterações novamente:
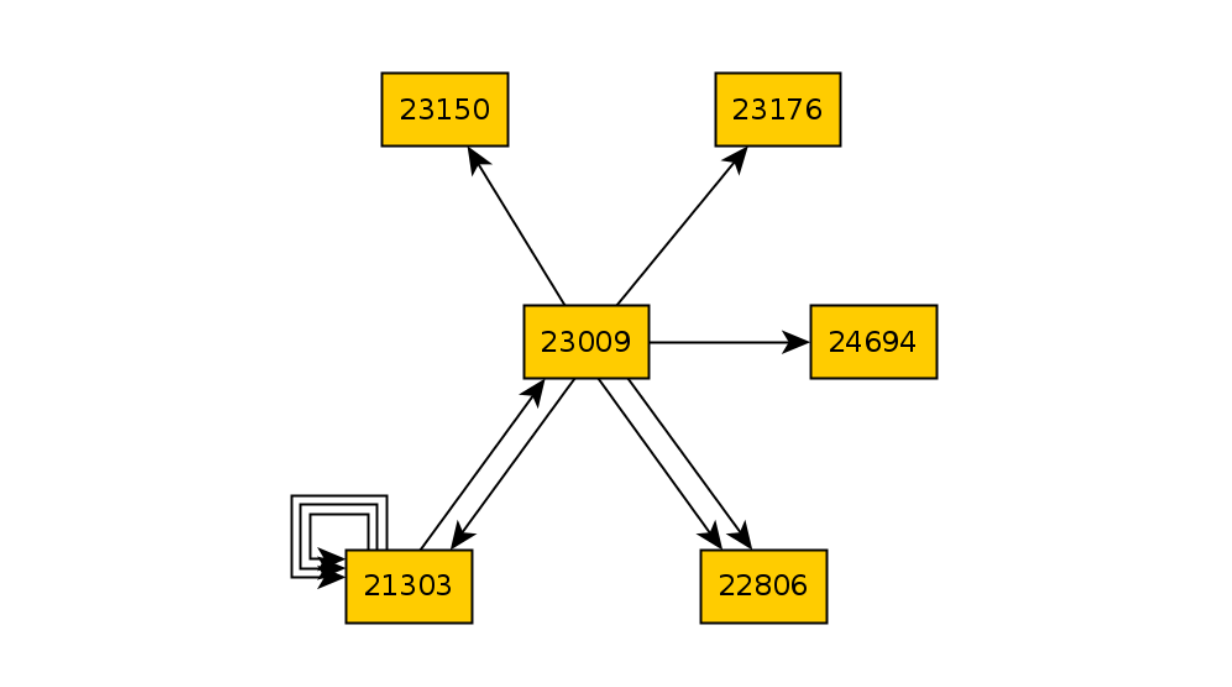
E então comparamos os dois gráficos e encontramos a diferença nos estados:
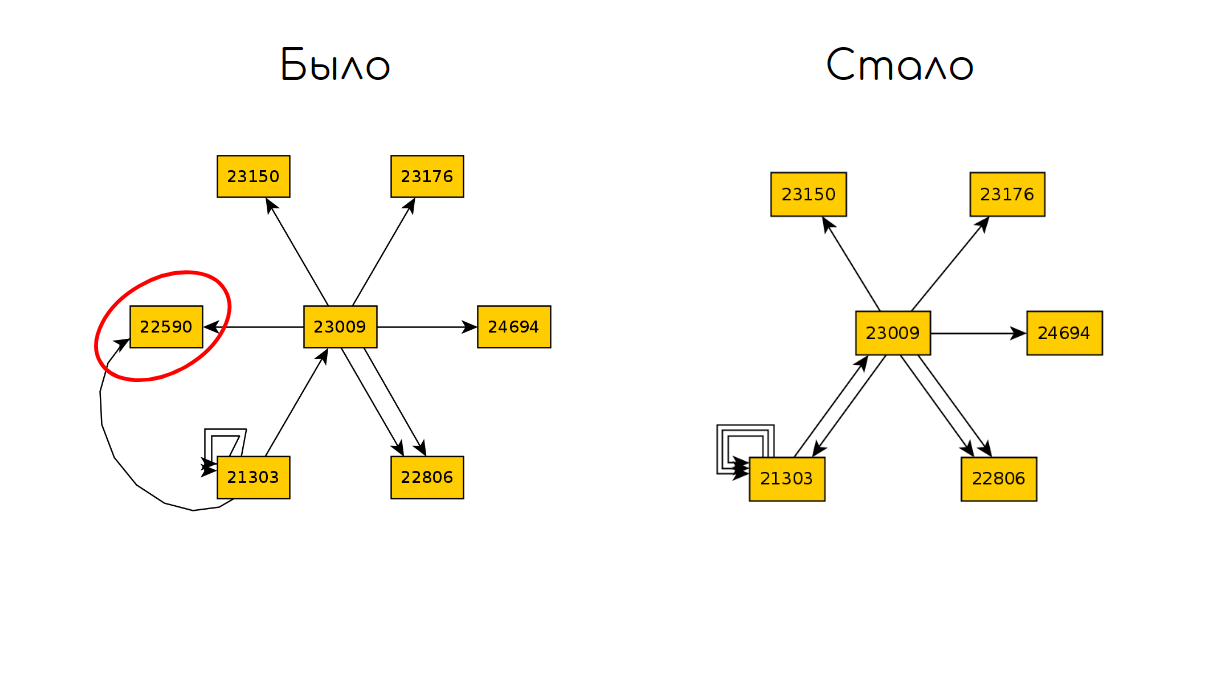
Podemos resumir para esta abordagem: do

jeito que está, essa técnica pode ser usada para testar um pequeno aplicativo e identificar erros óbvios ou de regressão. Para que a técnica decole em grandes aplicativos com GUIs instáveis, melhorias significativas serão necessárias.
Todo o código-fonte e uma lista de materiais usados podem ser encontrados no repositório: https://github.com/svdokuchaev/venom . Para aqueles que desejam entender o uso de fuzzing em testes, recomendo fortemente o The Fuzzing Book . Lá, em uma das partes, a mesma abordagem para difundir formulários html simples é descrita .
