Existe uma lenda do Antigo Testamento sobre como as pessoas na antiga cidade de Babilônia começaram a construir uma torre, mas o Todo-Poderoso misturou seus idiomas e a torre não foi concluída. Mesmo assim, porque a torre foi construída por centenas de pequenos grupos, que juntos não se entendiam. E sem nos entendermos, é impossível interagir. Na verdade, é simplesmente loucura chamar uma e a mesma coisa, implicando-a a mesma, em palavras diferentes. E não há nada de surpreendente aqui.
A lenda do Antigo Testamento pode ser facilmente transferida para grandes empresas modernas que implementam soluções de TI modernas. Um exemplo de tais empresas, sem dúvida, pode ser atribuído aos modernos bancos russos, que têm dezenas, senão centenas de unidades de negócios, que desenvolvem sua própria subcultura de comunicação, construída em suas próprias regras e um estilo único de rotatividade de negócios. Naturalmente, na formação da infraestrutura de TI, é levado em consideração o estilo de nomeação das entidades de negócios que se estabeleceu na equipe. Nos últimos dez anos, surgiram muitos trabalhos sobre este tema, por exemplo este [1]. Aqueles que encontraram análises de sistemas de informação em bancos sabem o que significa fazer o chamado "mapeamento" de dados, especialmente se os sistemas finais foram feitos por diferentes equipes de analistas, desenvolvedores e clientes ou fornecedores. Usualmente,A compilação de 60% do mapeamento é uma compreensão da essência e da semântica dos dados transmitidos.
A tendência atual é utilizar um conjunto de metodologias ágeis. Todo mundo está falando sobre Agile . Você pode argumentar até a rouquidão, se isso é bom ou prejudicial para os negócios. Mas uma coisa não fará ninguém rejeitar. No curso do Agile, muitas equipes diferentes, tanto dentro do banco quanto de diferentes fornecedores, criam uma variedade de soluções de TI para negócios e, frequentemente, sem interagir umas com as outras, as equipes criam sua própria terminologia bem estabelecida. E no momento em que ocorre a integração, acontece a mesma situação descrita no Antigo Testamento. Como não se parece com o bazar da Babilônia com seus milhares de mercadores, lojas, mercadorias, tolos sagrados, faquires e comedores de fogo? E assim, todas essas pessoas, armadas com idéias e pensamentos diferentes, começam a construir a Torre.
XSD ( JSON ) , - . , , «» , Confluence, Zoom Webex, « » , — .
, ESB ( ) -, , , «-» , . … , , . , , - , Kafka. , , , . XML , XSD , , , , JSON, - , «» «». , , , JSON . . , . XSD , . JSON . .
? , - . , ?
.
- . , . MS Excel, , , «» . ( JSON path), — . «». . , :
« »
« »
«20- »
«12- »
« , »
, , , , -. , : , . – “ ”. , , , , , , .
, , , PIP! xslx , . , , Python, .
, – Python. , Python. , , - . , , . – , , . : « , ». — - PyQt Tkinter. , . .
, JSONpath , . , , , Python. , .
. JSON.
. “” 33- . 33 ? – “33” . «». . , , , [2]. . «» . : , , 33- . . . , ABC :
onde cada coordenada x na posição correspondente é o número da letra correspondente do comentário de campo no arquivo Excel. Por exemplo, temos o comentário “Número de conta individual”. Vamos comparar para ela um vetor emergente da origem das coordenadas do sistema cartesiano em um espaço alfabético 33 dimensional, terá a seguinte aparência: coordenada X A - corresponde ao número de letras "a". E é igual a dois. X B - neste caso será igual a zero, pois não existe a letra “b” neste enunciado. O mesmo se aplica a x B - falta a letra " B ". Mas x AND - será igual a 3, já que a letra "e" no comentário ocorre três vezes.

Figura 1 . , « » . «»= 2, «» =3. – xA=2, x=3.
, , ( ) , 33- « », :
, , « «»» ( , , «» «») « ». :
Agora vamos encontrar a diferença entre os vetores no sistema de coordenadas cartesianas do espaço do alfabeto, ela é encontrada, respectivamente, de acordo com a fórmula bem conhecida da geometria analítica:
Onde e as coordenadas vetoriais correspondentes para o eixo correspondente à letra.
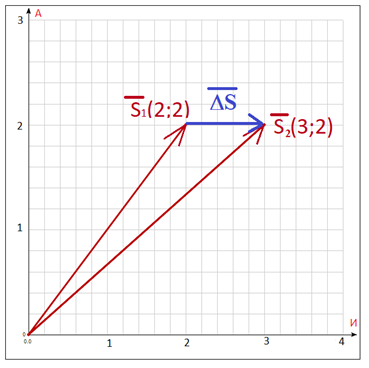
Figura 2. A cor azul mostra a diferença entre os vetoresno plano das letras - do espaço alfabético.
Assim, o vetor correspondente à diferença entre os enunciados "Número da conta de um indivíduo" e "Número da conta de um físico" ficará assim:
, o
vetor correspondente à diferença entre as declarações "Número da conta individual" e "Número da conta do cliente" terá a seguinte aparência:
Além disso, o comprimento dos vetores de diferença calculados obtidos pela fórmula:
Se você fizer um cálculo aritmético, obterá:
Isso assume matematicamente que a frase “Número da conta de um indivíduo” tem um significado mais próximo de “Número da conta de um físico” do que “Número da conta de uma entidade legal”. Isso é indicado pelos comprimentos dos vetores de diferença. Quanto mais curto for o comprimento, mais próximas no significado as declarações estão umas das outras. Se, por exemplo, pegarmos e compararmos os extratos “Número da conta de pessoa física” e “número da agência em que é aberta a conta de pessoa física”, obtemos a figura 6.63. Isso indicará que, se as duas primeiras declarações tiverem um significado próximo ao original (a diferença nos vetores 3,32 e 4,00, respectivamente), então a terceira, obviamente, terá uma essência de negócios diferente, apesar do conjunto de palavras idêntico aparentemente visível ...
Você pode ir além e tentar, por meio da vetorização, quantificar a proximidade de significado dos comentários. Para isso, proponho usar a projeção de vetores uns sobre os outros. Em seguida, encontre a razão entre a projeção longa do vento comparado e o comprimento daquele com o qual ele é comparado. Essa proporção sempre será menor ou igual a um. E, consequentemente, se as declarações forem idênticas entre si, a projeção se fundirá com o vetor no qual a projeção é feita. Quanto mais longe o significado da afirmação comparada, menor será a projeção. Se você multiplicar por 100%, poderá obter o grau de correspondência das declarações vetorizadas em porcentagem. Assim, a projeção do vetor declaração comparada no vetor da declaração original será encontrado pela seguinte fórmula:
Assim, o grau de conformidade será calculado usando a seguinte fórmula:

Figura 3. Ilustração de uma projeção vetor por vetor ...
É esse parâmetro que se propõe a ser tomado como base para a determinação da correspondência semântica.
Implementação do algoritmo em Python . Um pouco sobre damasco. Como definir e lidar com vetores
Chamei o algoritmo de Jerdella . Nada de estranho, sou apenas de Rostov-on-Don.
. , --, , , . , , -, -, -, “”. , .
, , Python , . , . , NumPy. , , NumPy? , – , , - « », . , NumPy. — . , , PIP... Portanto, nosso Jerdella usará os pacotes padrão incluídos no PyCharm Community Edition para o interpretador Python 3 .
Portanto, o bom do Python é que ele tem a capacidade de implementar uma ampla variedade de estruturas de dados. E por que não ficamos satisfeitos com uma lista para registrar um vetor? Uma lista de elementos do tipo int é o que você precisa para definir um vetor no espaço alfabético e outras operações com ele.
Escrevemos vários procedimentos fundamentais, que descreverei brevemente a seguir.
Como faço para definir um vetor?
Eu defino o vetor com o seguinte procedimento vetorial:
def vector(self,a):
vector=[]
abc = ["", '', "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "",
"", "", "", "", "", "", "", "", "", "", "", "", ""]
for char in abc:
count=a.count(char)
vector.append(count)
return(vector)Ou seja, no loop for sobre os elementos da lista previamente preparada abc , usei a operação padrão para localizar anexos na string de contagem . Depois disso, usando o método append, preenchi uma nova lista de vetores , que será o vetor para cálculos futuros.
Como calcular a diferença de vetores?
Para fazer isso, criei um procedimento delta que leva duas listas como entrada - a e b .
def delta(self, a, b):
delta = []
for char1, char2 in zip(a, b):
d = char1 - char2
delta.append(d)
return (delta)No loop for , iterando em ambas as listas, a diferença foi contada, adicionada a cada etapa de iteração ao final da lista delta , que o procedimento finalmente retornou como um vetor.
Como você calcula o comprimento de um vetor e, assim, estima a diferença?
Para fazer isso, criei um procedimento len_delta , que pega uma lista como entrada, e ao iterar sobre cada elemento dessa lista (também é uma coordenada no espaço alfabético), de acordo com a regra de localização do módulo vetorial, calcula o comprimento do vetor.
def len_delta(self, a):
len = 0
for d in a:
len += d * d
return round(math.sqrt(len), 2)Como calcular a proporção da projeção em um vetor e assim estimar a porcentagem de coincidência?
Para isso, foi criado um procedimento simplificado que leva duas listas como entrada. Nele, implementei a fórmula (6). E aqui um ponto importante é determinar qual vetor tem o maior comprimento. Para maior clareza da avaliação de coincidência, é mais conveniente projetar um vetor menor em um maior.
def simplify(self, a, b):
len1 = 0
len2 = 0
scalar = 0
for x in a: len1 += x * x
for y in b: len2 += y * y
for x, y in zip(a, b): scalar += x * y
if len1 > len2:
return (scalar / len1) * 100
else:
return (scalar / len2) * 100Discussão dos resultados obtidos. Conquistamos o espaço semântico estruturando-o
, , Jerdella . : 1) , , . 2) -. , CRM Siebel ESB, -. , , , -. , , . … . , , , …
… 2 , Agile, , point-to-point, , .
. , , . 2-3 , , . , , , : « » « », « », « », « », , . , 3000 , 500 ? – ? . , - 3000 ?
. «» , . . Python . «». “” , . « ». , , , – .
, :
{'Número da conta de um indivíduo': [{4.69: 'Conta bancária do cliente'}, {6.0: 'Sobrenome'}, {4.8: 'Número da conta de metal'}, {4.8: 'Número do cliente'}]}.
Este diagrama também pode ser visualizado em forma de gráfico. Você pode fazer muito com dicionários em Python ... Para visualização e demonstração dos resultados, usamos o projeto de Internet aberta www.graphonline.ru . Esta plataforma permite que você construa rapidamente um gráfico escrito usando GraphML .

Figura 4. Gráfico da relação da entidade “Número de um indivíduo”. Uma ilustração da presença de "órbitas de correspondência semântica" em uma entidade.
«» , (3) , , «» , . « » « ». , . , , , . .
? , « » «-». ( ( 3) (5)), . , « » . , « ».
, , , . . .

5. , .
, . … , , . , – ? ? ? — . 80%, , . , . , … - – . , .
, , , , . , , «» ( 6), . «», «», «», - -. , 30% . . , . , , , .

6. «» . , .
. .
«-» . , , - . ? , -.
. - . , . : « - ». , , . « » . , , , . – « ! - »…
, , - , , « », « » « », « », « ». , « ». , . ? ? « »?
, , , , , . – .
, :
[1] . . : . . 2010.
[2]. , . , . . Python. . – . , 2019, — 368 .
P.S. Accenture — ,