Tarefa
Dado: um projeto baseado em OpenWRT (e é baseado em BuildRoot) com um repositório adicional conectado como feed. Tarefa: mesclar um repositório adicional com o principal.
fundo
Fazemos roteadores e, um dia, queríamos dar aos clientes a capacidade de incluir seus aplicativos no firmware. Para não sofrer com a alocação do SDK, conjunto de ferramentas e as dificuldades associadas, decidimos colocar o projeto inteiro no github em um repositório privado. Estrutura do repositório:
/target //
/toolchain // gcc, musl
/feeds //
/package //
...
Decidiu-se transferir algumas das aplicações de nosso próprio desenvolvimento do repositório principal para o adicional, para que ninguém espiasse. Fizemos tudo, colocamos no github e ficou bom.
Muita água passou por baixo da ponte desde aquela época ...
O cliente se foi há muito tempo, o repositório foi removido do github e a própria ideia de dar aos clientes acesso ao repositório é podre. No entanto, dois repositórios permaneceram no projeto. E todos os scripts / aplicativos, de uma forma ou de outra relacionados ao git, são obrigados a se complicar para trabalhar com tal estrutura. Simplificando, é uma dívida técnica. Por exemplo, para garantir a reprodutibilidade dos lançamentos, você precisa enviar para o repositório primário um arquivo, secondary.version, com um hash do segundo repositório. Claro, o script faz isso, e não é muito difícil para isso. Mas, há uma dúzia desses scripts, e todos eles são mais complicados do que poderiam ser. Em geral, tomei uma decisão deliberada de mesclar o repositório secundário de volta ao primário. Ao mesmo tempo, a principal condição foi definida - preservar a reprodutibilidade dos lançamentos.
Depois que essa condição for definida, os métodos de mesclagem triviais, como comprometer tudo do secundário separadamente e, a partir de cima, fazer um merge-commit de duas árvores independentes não funcionarão. Você tem que abrir o capô e sujar as mãos.
Estrutura de dados Git
Primeiro, como é um repositório git? Este é um banco de dados de objetos. Os objetos são de três tipos: blobs, trees e commits. Todos os objetos são endereçados pelo sha1 hash de seu conteúdo. Um blob é, estupidamente, dados sem quaisquer atributos adicionais. Uma árvore é uma lista classificada de links para árvores e blobs na forma “<direito> <tipo> <hash> <nome>” (onde <tipo> é um blob ou árvore). Assim, uma árvore é como um diretório no sistema de arquivos e um blob é como um arquivo. Um commit contém o nome do autor e do committer, a data de criação e adição, um comentário, um hash de árvore e um número arbitrário (geralmente um ou dois) de links para os commits pais. Esses links para commits pai transformam a base do objeto em um dígrafo acíclico (entre estrangeiros, conhecido como DAG).Leia em detalhesaqui :
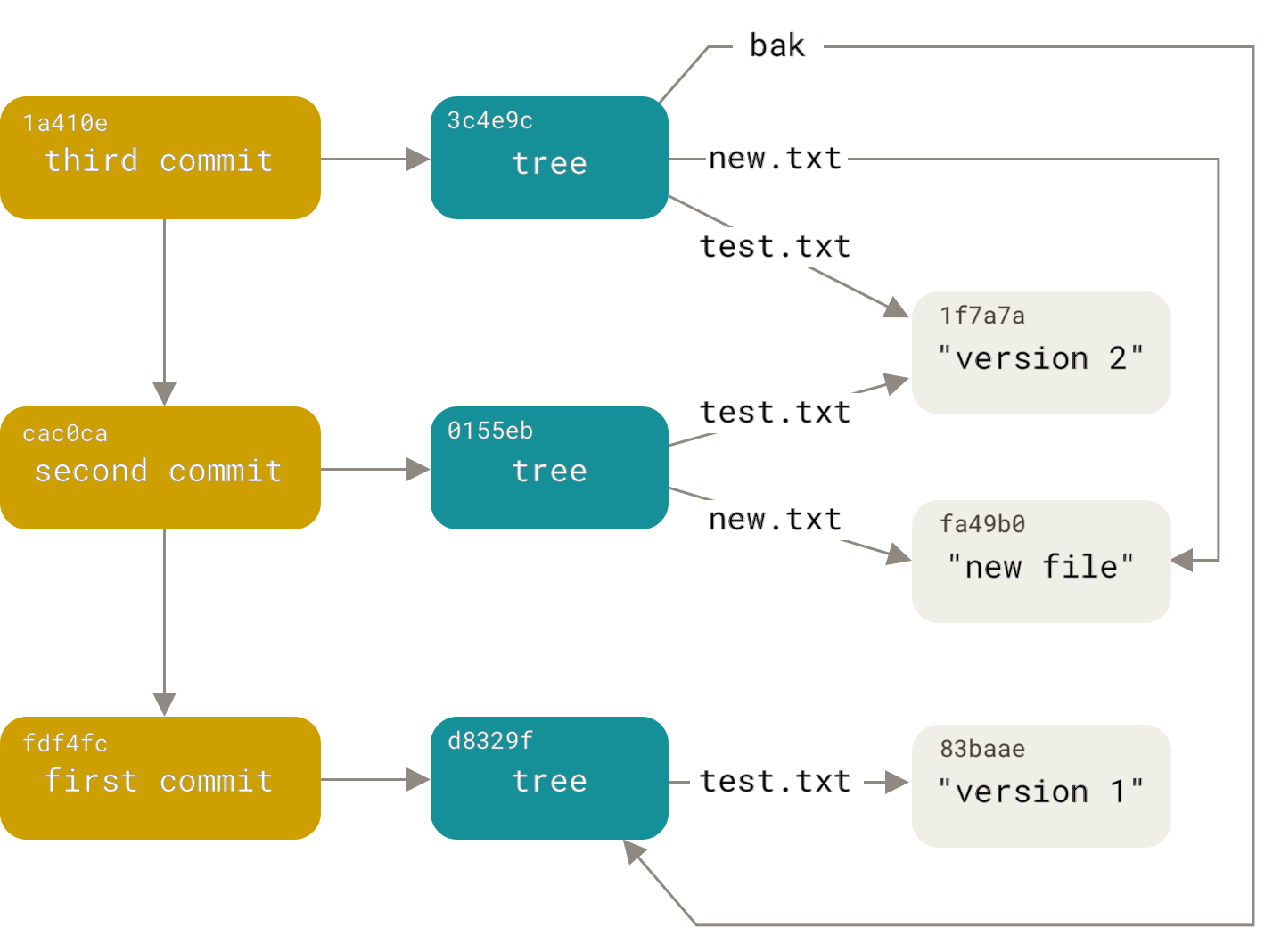
Assim, nossa tarefa se transformou na tarefa de construir um novo dígrafo, repetindo a estrutura do antigo. Mas com a substituição dos commits do arquivo secondary.version pelos commits do repositório adicional, o

processo de desenvolvimento está longe do gitflow clássico. Comprometemos tudo com o mestre, tentando não quebrá-lo ao mesmo tempo. Fazemos construções a partir daí. Se necessário, criamos ramificações de estabilização, que depois fundimos de volta no mestre. Conseqüentemente, o gráfico do repositório se parece com o tronco nu de uma sequóia trançada com trepadeiras.
Análise
A tarefa naturalmente se divide em duas etapas: análise e síntese. Já que para a síntese é necessário, obviamente, rodar desde o momento da alocação do repositório secundário para todas as tags e branches, inserindo commits do segundo repositório, então no estágio de análise você precisa encontrar lugares onde inserir os secundários-commits e estes próprios commits. Então, você precisa construir um gráfico reduzido, onde os nós serão os commits do gráfico principal que alteram o arquivo secondary.version (commits de chave). Além disso, se os nós deste gita se referem aos pais, então, no novo gráfico, referências aos descendentes são necessárias. Eu crio uma tupla nomeada:
node = namedtuple(‘Node’, [‘primary_commit’, ‘secondary_commit’, ‘children’])
reserva necessária
, . , .
Eu coloquei no dicionário:
master_tip = repo.commit(‘master’)
commit_map = {master_tip : node(master_tip, get_sec_commit(master_tip), [])}Eu coloquei todos os commits que alteram o secondary.version lá:
for c in repo.iter_commits(all=True, path=’secondary.verion’) :
commit_map[c] = node(c, get_sec_commit(c), [])E eu construo um algoritmo recursivo simples:
def build_dag(commit, commit_map, node):
for p in commit.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
build_dag(p, commit_map, commit_map[p])
else :
build_dag(p, commit_map, node)Isto é, por assim dizer, estico os nós-chave para o passado e os vinculo aos novos pais.
Eu o executo e ... RuntimeError profundidade máxima de recursão excedida
Como isso aconteceu? Existem muitos commits? git log e wc sabemos a resposta. O total de commits desde a divisão é de cerca de 20.000, e aqueles que afetam a versão secundária - quase 700. A receita é conhecida, precisamos de uma versão não recursiva.
def build_dag(master_tip, commit_map, master_node):
to_process = [(master_tip, master_node)]
while len(to_process) > 0:
c, node = to_process.pop()
for p in c.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
to_process.append(p, commit_map[p])
else :
to_process.append(p, node)(E você disse que todos esses algoritmos são necessários apenas para a entrevista passar!) Eu o
lanço e ... funciona. Um minuto, cinco, vinte ... Não, você não pode demorar tanto. Eu paro. Aparentemente, cada confirmação e cada caminho são processados muitas vezes. Quantos galhos existem na árvore? Descobriu-se que existem 40 ramos na árvore e, consequentemente,caminhos diferentes apenas do mestre. E há muitos caminhos que levam a uma porção significativa de commits de chave. Como não tenho milhares de anos guardados, preciso alterar o algoritmo para que cada confirmação seja processada exatamente uma vez. Para fazer isso, adiciono um conjunto, onde marco cada confirmação processada. Mas há um pequeno problema: com esta abordagem, alguns dos links serão perdidos, uma vez que caminhos diferentes com commits de chave diferentes podem passar pelos mesmos commits, e apenas o primeiro irá além. Para contornar este problema, substituo o conjunto por um dicionário, onde as chaves são confirmações e os valores são listas de confirmações de chave alcançáveis:
def build_dag(master_tip, commit_map, master_node):
processed_commits = {}
to_process = [(master_tip, master_node, [])]
while len(to_process) > 0:
c, node, path = to_process.pop()
p_node = commit_map.get(c)
if p_node :
commit_map[p].children.append(p_node)
for path_c in path :
if all(p_node.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(p_node)
path = []
node = p_node
processed_cmmts[c] = []
for p in c.parents :
if p != root_commit and and p not in processed_cmmts :
newpath = path.copy()
newpath.append(c)
to_process.append((p, node, newpath,))
else :
p_node = commit_map.get(p)
if p_node is None :
p_nodes = processed_cmmts.get(p, [])
else :
p_nodes = [p_node]
for pn in p_nodes :
node.children.append(pn)
if all(pn.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[c]) :
processed_cmmts[c].append(pn)
for path_c in path :
if all(pn.trunk_commit != nc.trunk_commit
for nc in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(pn)Como resultado dessa troca ingênua de memória por um tempo, o gráfico é construído em 30 segundos.
Síntese
Agora eu tenho um commit_map com nós-chave vinculados a um gráfico por meio de links filhos. Por conveniência, vou transformá-lo em uma sequência de pares (ancestral, descendente) . A sequência deve ser garantida de que todos os pares em que um nó ocorre como filho estejam localizados antes de qualquer par em que um nó ocorra como ancestral. Então você só precisa passar por esta lista e submeter primeiro os commits do repositório principal, e então do adicional. Aqui devemos lembrar que o commit contém um link para a árvore, que é o estado do sistema de arquivos. Uma vez que o repositório adicional contém subdiretórios adicionais no pacote / diretório, então será necessário criar novas árvores para todos os commits. Na primeira versão, apenas escrevi blobs em arquivos e pedi ao git para construir um índice no diretório de trabalho. No entanto, esse método não era muito produtivo. Ainda existem 20.000 commits, e cada um precisa ser confirmado novamente. Portanto, o desempenho é muito importante. Uma pequena pesquisa na parte interna do GitPython me levou à classe gitdb.LooseObjectDB , que expõe objetos de repositório git diretamente. Com ele, blobs e árvores (e quaisquer outros objetos também) de um repositório podem ser gravados diretamente em outro. Uma propriedade maravilhosa do banco de dados de objetos git é que o endereço de qualquer objeto é um hash de seus dados. Portanto, o mesmo blob terá o mesmo endereço, mesmo em repositórios diferentes.
secondary_paths = set()
ldb = gitdb.LooseObjectDB(os.path.join(repo.git_dir, 'objects'))
while len(pc_pairs) > 0:
parent, child = pc_pairs.pop()
for c in all_but_last(repo.iter_commits('{}..{}'.format(
parent.trunk_commit, child.trunk_commit), reverse = True)) :
newparents = [new_commits.get(p, p) for p in c.parents]
new_commits[c] = commit_primary(repo, newparents, c, secondary_paths)
newparents = [new_commits.get(p, p) for p in child.trunk_commit.parents]
c = secrepo.commit(child.src_commit)
sc_message = 'secondary commits {}..{} <devonly>'.format(
parent.src_commit, child.src_commit)
scm_details = '\n'.join(
'{}: {}'.format(i.hexsha[:8], textwrap.shorten(i.message, width = 70))
for i in secrepo.iter_commits(
'{}..{}'.format(parent.src_commit, child.src_commit), reverse = True))
sc_message = '\n\n'.join((sc_message, scm_details))
new_commits[child.trunk_commit] = commit_secondary(
repo, newparents, c, secondary_paths, ldb, sc_message)As próprias funções de commit:
def commit_primary(repo, parents, c, secondary_paths) :
head_tree = parents[0].tree
repo.index.reset(parents[0])
repo.git.read_tree(c.tree)
for p in secondary_paths :
# primary commits don't change secondary paths, so we'll just read secondary
# paths into index
tree = head_tree.join(p)
repo.git.read_tree('--prefix', p, tree)
return repo.index.commit(c.message, author=c.author, committer=c.committer
, parent_commits = parents
, author_date=git_author_date(c)
, commit_date=git_commit_date(c))
def commit_secondary(repo, parents, sec_commit, sec_paths, ldb, message):
repo.index.reset(parents[0])
if len(sec_paths) > 0 :
repo.index.remove(sec_paths, r=True, force = True, ignore_unmatch = True)
for o in sec_commit.tree.traverse() :
if not ldb.has_object(o.binsha) :
ldb.store(gitdb.IStream(o.type, o.size, o.data_stream))
if o.path.find(os.sep) < 0 and o.type == 'tree': # a package root
repo.git.read_tree('--prefix', path, tree)
sec_paths.add(p)
return repo.index.commit(message, author=sec_commit.author
, committer=sec_commit.committer
, parent_commits=parents
, author_date=git_author_date(sec_commit)
, commit_date=git_commit_date(sec_commit))
Como você pode ver, os commits do repositório secundário são adicionados em massa. No início, certifiquei-me de adicionar commits individuais, mas (de repente!) Descobri que às vezes um commit de chave mais recente contém a versão anterior do repositório secundário (em outras palavras, a versão é revertida). Em tal situação, o método iter_commit passa e retorna uma lista vazia. Como resultado, o repositório está incorreto. Portanto, eu só tive que comprometer a versão atual.
A história do aparecimento do gerador all_but_last é interessante. Omiti a descrição, mas ela faz exatamente o que você espera. No começo era apenas um desafio
repo.iter_commits('{}..{}^'.format(parent.trunk_commit, child.trunk_commit), reverse = True)Em geral, tudo acabou bem. O script inteiro cabia em 300 linhas e foi executado em cerca de 6 horas. Moral: GitPython é conveniente para fazer todos os tipos de coisas legais com repositórios, mas é melhor tratar a dívida técnica em tempo hábil