
Existe uma piada nos círculos de TI que o aprendizado de máquina (AM) é como sexo entre adolescentes: todo mundo fala sobre isso, todo mundo finge fazer, mas, na verdade, muito poucas pessoas conseguem. A FunCorp conseguiu introduzir o ML na mecânica principal de seu produto e alcançar uma melhoria radical (quase 40%!) Nas principais métricas. Interessante? Bem-vindo ao gato.
Um pouco de fundo
Para quem lê o blog da FunCorp de forma irregular, gostaria de lembrar que nosso produto de maior sucesso é o aplicativo iFunny UGC com elementos de uma rede social para amantes de memes. Os usuários (e este é cada quarto representante da geração jovem nos EUA) carregam ou criam novas imagens ou vídeos diretamente no aplicativo, e um algoritmo inteligente seleciona (ou, como dizemos, “recursos” da palavra “destaque”) o melhor deles e forma cada um dia de 7 edições de 30-60 unidades de conteúdo em feed separado, com o qual 99% do público interage. Como resultado, ao entrar no aplicativo, cada usuário vê os melhores memes, vídeos e fotos engraçadas. Se você visita com frequência, o feed rola rapidamente e o usuário aguarda a próxima edição em algumas horas. No entanto, se você visitar com menos frequência, o conteúdo em destaque se acumula e o feed pode crescer para 1.000 itens em alguns dias.
Nesse sentido, surgiu a tarefa: mostrar a cada usuário o conteúdo mais relevante para ele, agrupando memes que lhe interessem pessoalmente no início do feed.
Por mais de 9 anos de existência do iFunny, houve várias abordagens para essa tarefa.
Primeiro, tentamos a maneira óbvia de classificar o feed pelo número de sorrisos (nosso análogo de "curtidas") - Taxa de sorriso . Foi melhor do que ordenar em ordem cronológica, mas ao mesmo tempo levou ao efeito da "temperatura média no hospital": há pouco humor de que todos gostem, e sempre haverá quem não se interesse (e até francamente irritante) os temas populares de hoje ... Mas você também quer ver todas as novas piadas engraçadas do seu desenho animado favorito.
No próximo experimento, tentamos levar em consideração os interesses de microcomunidades individuais: fãs de anime, esportes, memes com cães e gatos, etc. Para isso, começaram a formar diversos feeds temáticos de destaque e oferecer aos usuários a escolha de temas de seu interesse, usando tags e textos reconhecidos em imagens. Algo melhorou, mas o efeito da rede social foi perdido: há menos comentários sobre o conteúdo em destaque, que desempenhou um grande papel no envolvimento do usuário. Além disso, no caminho para feeds segmentados, perdemos muitos memes realmente populares. Assistiram a "Cartoon Favorito", mas não viram as piadas sobre "os últimos Vingadores".
Como já começamos a implementar algoritmos de aprendizado de máquina em nosso produto, que apresentamos em nosso próprio encontro, eles queriam fazer outra abordagem usando essa tecnologia.
Decidiu-se tentar construir um sistema de recomendação baseado no princípio da filtragem colaborativa. Este princípio é bom nos casos em que o aplicativo tem muito poucos dados sobre os usuários: poucos indicam sua idade ou sexo no momento do registro, e apenas pelo endereço IP se pode assumir sua localização geográfica (embora seja sabido sem adivinhos que a grande maioria dos usuários iFunny são residentes Estados Unidos) e por modelo de telefone - nível de renda. Sobre isso, em geral, tudo. A filtragem colaborativa funciona assim: o histórico de avaliações positivas do conteúdo do usuário é levado, outros usuários com avaliações semelhantes são encontrados, então é recomendado o que os mesmos usuários já gostaram (com avaliações semelhantes).
Características da tarefa
Memes são conteúdos bastante específicos. Primeiro, é altamente suscetível a tendências que mudam rapidamente. O conteúdo e a forma que chegaram ao topo e fizeram 80% do público sorrir há uma semana, hoje podem causar irritação com seu caráter secundário e irrelevante.
Em segundo lugar, uma interpretação muito não linear e situacional do significado do meme. Na seleção de notícias, você pode pegar nomes conhecidos, tópicos que são usados de forma bastante consistente por um determinado usuário. Em uma seleção de filmes, você pode ver o elenco, o gênero e muito mais. Sim, você pode descobrir tudo isso em uma seleção de memes pessoais. Mas como seria decepcionante perder uma verdadeira obra-prima do humor, que usa imagens ou vocabulário que não cabe no conteúdo semântico de forma alguma!

Finalmente, uma grande quantidade de conteúdo gerado dinamicamente. No iFunny, os usuários criam dezenas de milhares de postagens todos os dias. Todo este conteúdo deve ser “raked” o mais rapidamente possível, e no caso de um sistema de recomendação personalizado, não só para encontrar “diamantes”, mas também para poder prever a avaliação dos conteúdos por vários representantes da sociedade.
O que esses recursos significam para o desenvolvimento do modelo de aprendizado de máquina? Em primeiro lugar, o modelo deve ser constantemente treinado com os dados mais recentes. Logo no início da imersão no desenvolvimento de um sistema de recomendação, ainda não está totalmente claro se estamos falando de dezenas de minutos ou algumas horas. Mas ambos significam a necessidade de um novo treinamento constante do modelo, ou ainda melhor - um treinamento online em um fluxo contínuo de dados. Todas essas não são as tarefas mais fáceis do ponto de vista de encontrar uma arquitetura de modelo adequada e selecionar seus hiperparâmetros: de forma que garantiria que em algumas semanas as métricas não começarão a degradar com segurança.
Uma dificuldade separada é a necessidade de seguir o protocolo de teste a / b adotado por nós. Nunca implementamos nada sem primeiro verificar alguns dos usuários, comparando os resultados com um grupo de controle.
Após longos cálculos, optou-se por iniciar um MVP com as seguintes características: usamos apenas informações sobre a interação dos usuários com o conteúdo, treinamos o modelo em tempo real, direto em um servidor equipado com uma grande quantidade de memória, o que permite armazenar todo o histórico de interação do grupo de teste de usuários por um período bastante longo. Decidimos limitar o tempo de treinamento para 15-20 minutos a fim de manter o efeito de novidade, bem como ter tempo para usar os dados mais recentes dos usuários que vêm maciçamente ao aplicativo durante os lançamentos.
Modelo
Primeiro, começamos a torcer a filtragem colaborativa mais clássica com decomposição de matriz e treinamento em ALS (alternância de mínimos quadrados) ou SGD (gradiente descendente estocástico). Mas eles descobriram rapidamente: por que não começar imediatamente com a rede neural mais simples? Com uma malha simples de camada única, na qual há apenas uma camada de incorporação linear, e não há envolvimento de camadas ocultas, para não se enterrar em semanas de seleção de seus hiperparâmetros. Um pouco além do MVP? Talvez. Mas treinar tal malha dificilmente é mais difícil do que uma arquitetura mais clássica, se você tiver um hardware equipado com uma boa GPU (você teve que desembolsar para isso).
Inicialmente, ficou claro que existem apenas duas opções para o desenvolvimento de eventos: ou o desenvolvimento dará um resultado significativo nas métricas do produto, então será necessário aprofundar os parâmetros de usuários e conteúdo, em treinamento adicional sobre novos conteúdos e novos usuários, em redes neurais profundas, ou a classificação de conteúdo personalizado não trará aumento tangível e "compra" podem ser cobertos. Se a primeira opção acontecer, todos os itens acima terão que ser corrigidos até a camada de incorporação inicial.
Decidimos optar pela Máquina de Fatoração Neural . O princípio de seu funcionamento é o seguinte: cada usuário e cada conteúdo são codificados por vetores de comprimento fixo igual - embeddings, que são posteriormente treinados em um conjunto de interações conhecidas entre o usuário e o conteúdo.
O conjunto de treinamento inclui todos os fatos dos usuários visualizando o conteúdo. Além dos sorrisos, optou-se por considerar cliques nos botões "compartilhar" ou "salvar", bem como escrever um comentário, para um feedback positivo sobre o conteúdo. Se presente, a interação é marcada com 1 (um). Se, após a visualização, o usuário não deixar um feedback positivo, a interação é marcada com 0 (zero). Assim, mesmo na ausência de uma escala de avaliação explícita, utiliza-se um modelo explícito (modelo com avaliação explícita do usuário), e não implícito, que levaria em consideração apenas ações positivas.
Também tentamos o modelo implícito, mas não funcionou imediatamente, então nos concentramos no modelo explícito. Talvez, para o modelo implícito, você precise usar mais astúcia do que funções binárias de perda de classificação de entropia cruzada simples.
A diferença entre a Fatoração de Matriz Neural e a Filtragem Colaborativa Neural padrão está na presença da chamada camada Pooling de Bi-Interação em vez da camada totalmente conectada usual, que simplesmente conectaria o usuário e os vetores de incorporação de conteúdo. A camada de bi-interação converte um conjunto de vetores de incorporação (existem apenas 2 vetores no iFunny: usuário e conteúdo) em um vetor, multiplicando-os elemento por elemento.
Na ausência de camadas ocultas adicionais sobre a Bi-Interação, obtemos o produto escalar desses vetores e, adicionando o viés do usuário e o viés do conteúdo, envolvemos-o em um sigmóide. Esta é uma estimativa da probabilidade de feedback positivo do usuário após visualizar este conteúdo. É de acordo com essa avaliação que classificamos o conteúdo disponível antes de demonstrá-lo em um dispositivo específico.
Assim, a tarefa do treinamento é garantir que os embeddings de usuário e conteúdo para os quais haja uma interação positiva estejam próximos um do outro (tenham o máximo de produto escalar) e que os embeddings de usuário e de conteúdo para os quais haja uma interação negativa estejam distantes um do outro. (produto escalar mínimo).
Como resultado desse treinamento, os embeddings de usuários que sorriem da mesma maneira tornam-se próximos uns dos outros. E esta é uma descrição matemática conveniente de usuários que pode ser usada em muitas outras tarefas. Mas essa é outra história.
Assim, o usuário entra no feed e começa a assistir ao conteúdo. Cada vez que você vê, sorri, compartilha, etc. o cliente envia estatísticas para nosso armazenamento analítico (sobre o qual, se tivermos interesse, escrevemos anteriormente no artigo Mudando de Redshift para Clickhouse ). No caminho, selecionamos os eventos de nosso interesse e os enviamos para o servidor ML, onde são armazenados na memória.
A cada 15 minutos, o modelo é retreinado no servidor, após o que novas estatísticas do usuário são levadas em consideração nas recomendações.
O cliente solicita a próxima página do feed, ela é formada de forma padronizada, mas no caminho a lista de conteúdo é enviada para o serviço de ML, que a ordena de acordo com os pesos dados pelo modelo treinado para esse usuário específico.

Como resultado, o usuário vê primeiro aquelas fotos e vídeos que, de acordo com o modelo, serão mais preferidos para ele.
Arquitetura de serviço interno
O serviço funciona em HTTP. O Flask é usado como um servidor HTTP em conjunto com o Gunicorn. Ele lida com duas solicitações: add_event e get_rates.
A solicitação add_event adiciona uma nova interação entre o usuário e o conteúdo. Ele é adicionado a uma fila interna e depois processado em um processo separado (com pico de até 1600 rps).
A solicitação get_rates calcula os pesos para a lista user_id e content_id de acordo com o modelo (no pico da ordem de centenas de rps).
O principal processo interno é o Dispatcher. É escrito em assíncio e implementa a lógica básica:
- processa a fila de solicitações add_event e as armazena em um grande hashmap (200 milhões de eventos por semana);
- recalcula o modelo em um círculo;
- salva novos eventos no disco a cada meia hora, enquanto exclui eventos anteriores a uma semana do hashmap.

O modelo treinado é colocado na memória compartilhada, de onde é lido por trabalhadores HTTP.
resultados
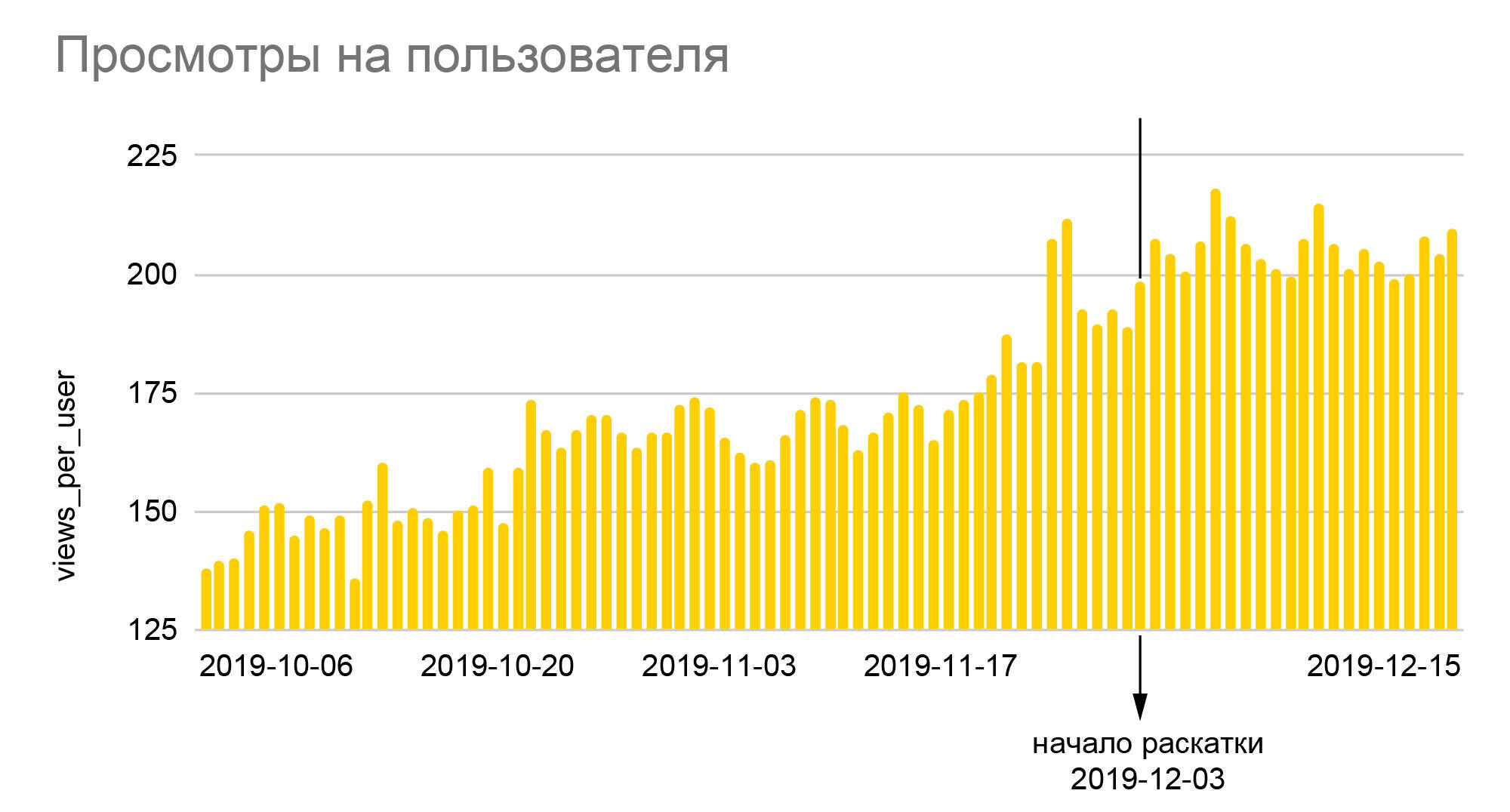

Os gráficos falam por si. O crescimento de 25% no número relativo de smilies e quase 40% na profundidade de visualizações que vemos neles é o resultado da implementação do novo algoritmo para todo o público no final do teste A / B 50/50, ou seja, um aumento real em relação aos valores básicos era quase duas vezes maior. Como a iFunny ganha dinheiro com publicidade, o aumento em profundidade significa um aumento proporcional na receita, o que, por sua vez, nos permitiu atravessar os meses de crise de 2020 com bastante tranquilidade. Um aumento no número de smilies traduz-se em maior fidelidade, o que significa uma menor probabilidade de abandono da aplicação no futuro; os usuários fiéis passam a acessar outras seções do aplicativo, deixar comentários, comunicar-se. E o mais importante, não criamos apenas uma base confiável para melhorar a qualidade das recomendações,mas também estabeleceu a base para a criação de novos recursos com base na quantidade colossal de dados comportamentais anônimos que acumulamos ao longo dos anos de aplicação.
Conclusão
O serviço ML Content Rate é o resultado de um grande número de pequenas melhorias e melhorias.
Em primeiro lugar, os usuários não registrados também foram levados em consideração no treinamento. Inicialmente, surgiram dúvidas sobre eles, pois a priori não podiam deixar emoticons - o feedback mais frequente após a visualização do conteúdo. Mas logo ficou claro que esses temores foram em vão e fecharam um ponto muito grande de crescimento. Muitos experimentos são feitos com a configuração da amostra de treinamento: para inserir uma proporção maior do público nela ou para ampliar o intervalo de tempo das interações consideradas. No decorrer desses experimentos, descobriu-se que não apenas a quantidade de dados desempenha um papel significativo para as métricas do produto, mas também o tempo para atualizar o modelo. Muitas vezes, o aumento da qualidade da classificação afogava nos 10-20 minutos extras para recalcular o modelo, o que tornava necessário abandonar as inovações.
Muitas melhorias, mesmo as menores, produziram resultados: ou melhoraram a qualidade do aprendizado, ou aceleraram o processo de aprendizado, ou economizaram memória. Por exemplo, havia um problema com o fato de que as interações não cabiam na memória - elas tinham que ser otimizadas. Além disso, o código foi modificado e tornou-se possível inserir nele, por exemplo, mais interações para recálculo. Também levou a uma maior estabilidade do serviço.
Agora estamos trabalhando em como usar efetivamente os parâmetros conhecidos do usuário e do conteúdo, fazer um modelo incremental e de reciclagem rápida, e novas hipóteses para melhorias futuras também estão surgindo.
Se você está interessado em saber como desenvolvemos este serviço e quais outras melhorias conseguimos implementar - escreva nos comentários, depois de um tempo estaremos prontos para escrever a segunda parte.
Sobre os autores
Infelizmente, Habr não permite indicar vários autores para o artigo. Embora o artigo tenha sido publicado a partir da minha conta, a maior parte dele foi escrita pelo desenvolvedor líder dos serviços FunCorp ML - Grisha Kuzovnikov (PhoenixMSTU), bem como analista e cientista de dados - Dima Zemtsov. Seu servo recalcitrante é o principal responsável pelas piadas sobre sexo adolescente, a introdução e a seção de resultados, além do trabalho editorial. E, é claro, todas essas conquistas não teriam sido possíveis sem a ajuda das equipes de desenvolvimento de back-end, QA, analistas e equipe de produto, que inventou tudo isso e passou vários meses conduzindo e ajustando experimentos A / B.