
Olá a todos, meu nome é Igor Sidorenko. O monitoramento é uma das principais áreas do meu trabalho e também meu hobby. Vou falar sobre o Zabbix e como usá-lo para monitorar as informações que precisamos sobre os volumes da NetApp, com acesso apenas via SSH. Quem estiver interessado no tema monitoramento e Zabbix, por favor, no item cat.
Inicialmente, monitoramos os volumes montando-os em um servidor específico, no qual um modelo especial era suspenso, capturando montagens NFS no nó e colocando-as sob monitoramento, por analogia com os sistemas de arquivos do modelo básico do Linux. A montagem teve que ser registrada no fstab e montada manualmente - por isso, muito foi perdido e esquecido.
Então, uma ótima ideia me veio à mente: precisamos automatizar tudo isso. Havia várias opções:
Existem modelos prontos que funcionam com SNMP, mas sem acesso.Obter uma lista de volumes e montagem automática em um nó: você precisa criar uma pasta, registrar o fstab, montar, isso é tudo, muita hemorróidas.Existe uma ótima API , mas como alugamos apenas espaço, em nossa versão do ONTAP ela é reduzida e não fornece ao usuário as informações necessárias.- De alguma forma, use o acesso SSH para obter volumes e configurá-los para monitoramento.
A escolha recaiu sobre o agente SSH .
Descoberta de baixo nível (LLD)
Primeiro, precisamos criar uma descoberta de baixo nível (LLD) , esses serão os nomes de nossos volumes. Tudo isso é necessário para obter informações específicas sobre o volume de que precisamos. Os dados brutos se parecem com isto (114 no momento da escrita):
set -unit B; volume show -state online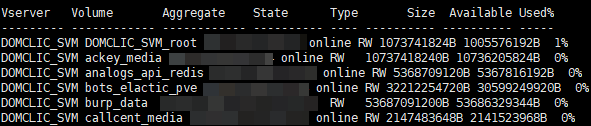
Bem, como podemos fazer sem muletas: vamos escrever um script bash de uma linha que exibirá os nomes dos volumes no formato JSON (uma vez que esta é uma verificação externa , os scripts estão no servidor Zabbix no diretório
/usr/lib/zabbix/externalscripts):
netapp_volume_discovery.sh
#!/usr/bin/bash
SVM_NAME=""
SVM_ADDRESS=""
USERNAME=""
PASSWORD=""
for i in $(sshpass -p $PASSWORD ssh -o StrictHostKeyChecking=no $USERNAME@$SVM_ADDRESS 'set -unit B; volume show -state online' | grep $SVM_NAME | awk {'print $2'}); do echo '{"volume_name":"'$i'"}'; done | jq -s '.
Agora você precisa criar um modelo e criar itens de dados com base nos dados recebidos:
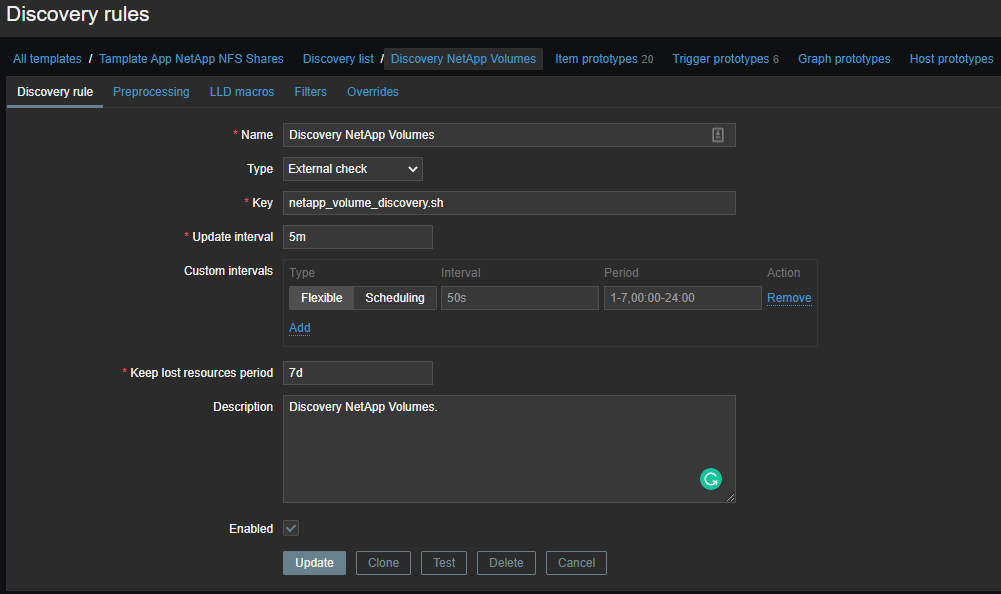
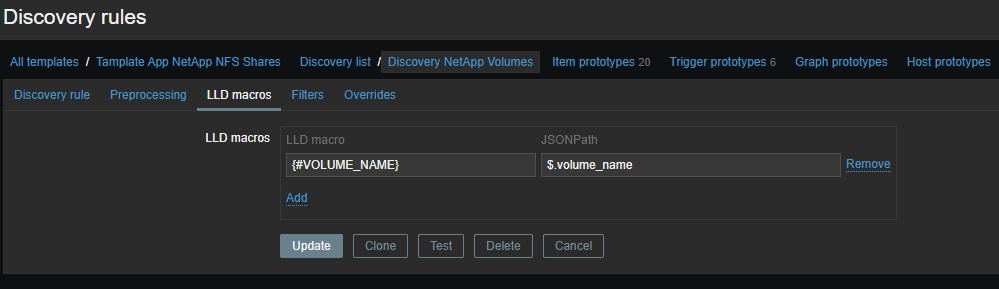
Itens de dados
Para criar itens de dados automaticamente, você precisa criar um protótipo dos itens : Usaremos itens mestres e alguns itens dependentes . Assim, para cada volume, um elemento mestre é criado no qual um conjunto de comandos sobre SSH é executado:
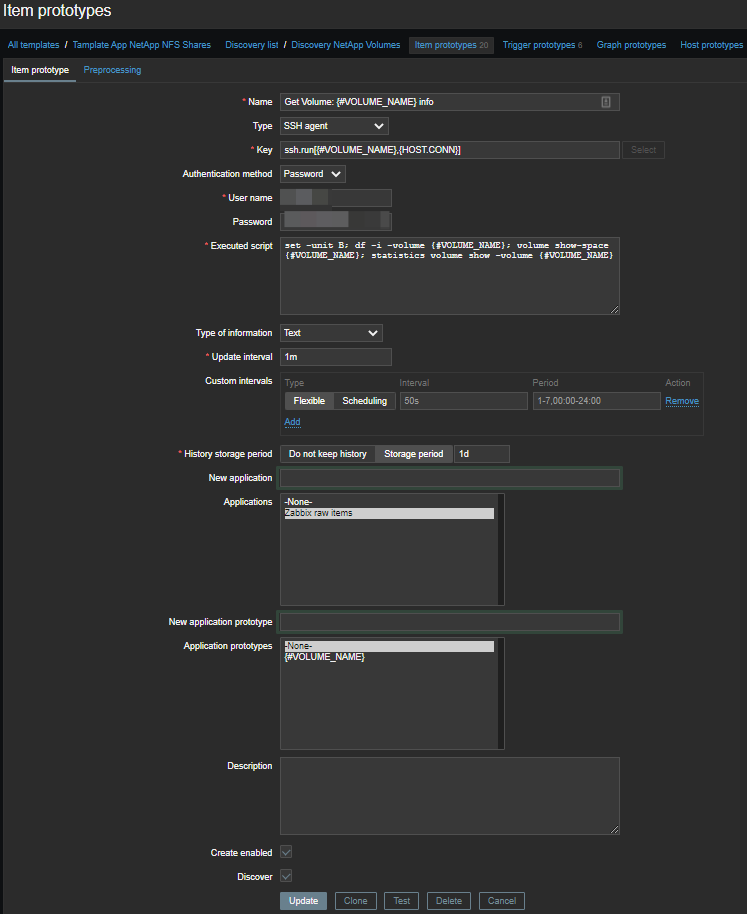
set -unit B; df -i -volume {#VOLUME_NAME}; volume show-space {#VOLUME_NAME}; statistics volume show -volume {#VOLUME_NAME}Recebemos essa folha:
Obter Volume: informações ackey_media
Last login time: 9/15/2020 12:42:45
Filesystem iused ifree %iused Mounted on
/vol/ackey_media/ 96 311191 0% /ackey_media
Volume Name: ackey_media
Volume MSID: 2159592810
Volume DSID: 1317
Vserver UUID: 46a00e5d-c22d-11e8-b6ed-00a098d48e6d
Aggregate Name: NGHF_FAS2720_04
Aggregate UUID: 7ec21b4d-b4db-4f84-85e2-130750f9f8c3
Hostname: FAS2720_04
User Data: 20480B
User Data Percent: 0%
Deduplication: -
Deduplication Percent: -
Temporary Deduplication: -
Temporary Deduplication Percent: -
Filesystem Metadata: 1150976B
Filesystem Metadata Percent: 0%
SnapMirror Metadata: -
SnapMirror Metadata Percent: -
Tape Backup Metadata: -
Tape Backup Metadata Percent: -
Quota Metadata: -
Quota Metadata Percent: -
Inodes: 12288B
Inodes Percent: 0%
Inodes Upgrade: -
Inodes Upgrade Percent: -
Snapshot Reserve: -
Snapshot Reserve Percent: -
Snapshot Reserve Unusable: -
Snapshot Reserve Unusable Percent: -
Snapshot Spill: -
Snapshot Spill Percent: -
Performance Metadata: 28672B
Performance Metadata Percent: 0%
Total Used: 1212416B
Total Used Percent: 0%
Total Physical Used Size: 1212416B
Physical Used Percentage: 0%
Logical Used Size: 1212416B
Logical Used Percent: 0%
Logical Available: 10736205824B
DOMCLIC_SVM : 9/15/2020 12:42:51
*Total Read Write Other Read Write Latency
Volume Vserver Ops Ops Ops Ops (Bps) (Bps) (us)
----------- ----------- ------ ---- ----- ----- ----- ----- -------
ackey_media DOMCLIC_SVM 0 0 0 0 0 0 0Nesta folha, precisamos selecionar as métricas de que precisamos.
A magia das expressões regulares
Inicialmente, eu queria usar JavaScript para pré-processamento , mas de alguma forma não o dominei, não funcionou. Portanto, parei nos regulares e os uso em quase todos os lugares.
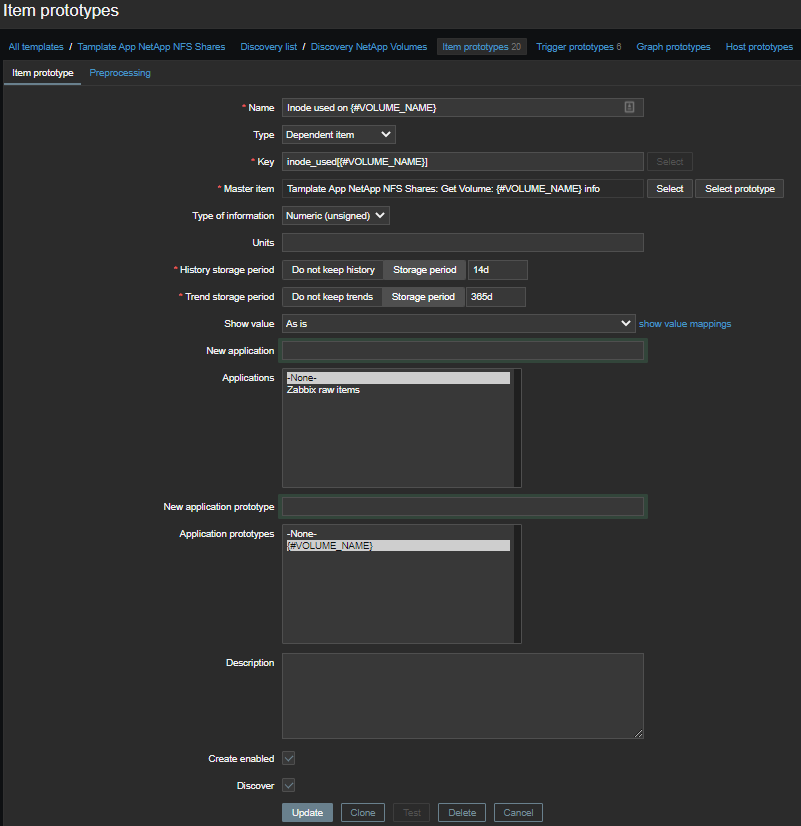
Número de inodes usados
Selecionaremos informações apenas sobre inodes para cada volume em duas etapas: Primeiro, todas as informações:
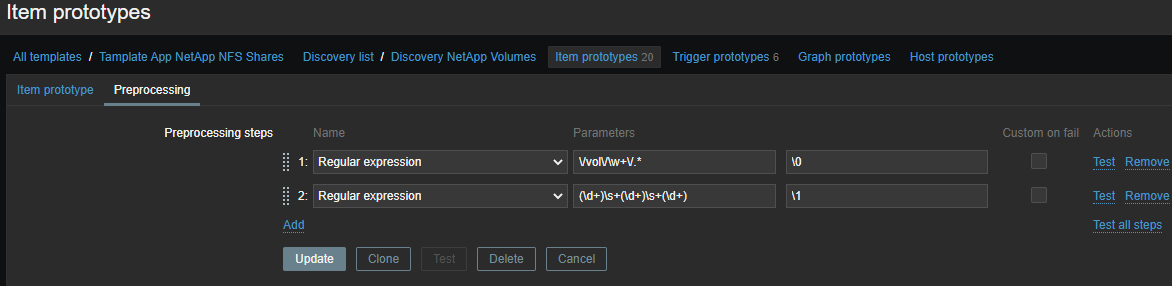
\/vol\/\w+\/.*

Então, especificamente por métricas:
(\d+)\s+(\d+)\s+(\d+)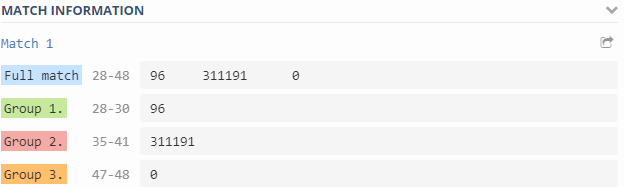

Saída - modelo de formatação de saída.
\N ( N=1..9)- a sequência de escape é substituída pelo enésimo grupo de correspondência. A sequência de escape \0é substituída pelo texto correspondente:
\1 - Inode used on {#VOLUME_NAME}- o número de inodes usados;\2 - Inode free on {#VOLUME_NAME}- número de inodes livres;\3 - Inode used percentage on {#VOLUME_NAME}- inodes usados como uma porcentagem;Inode total on {#VOLUME_NAME}- elemento calculado , o número de inodes disponíveis.
last(inode_free[{#VOLUME_NAME}])+last(inode_used[{#VOLUME_NAME}])Espaço utilizado
Tudo é mais simples aqui, os dados e regulares estão em um formato mais agradável: pegamos a métrica de que precisamos e pegamos apenas o número:
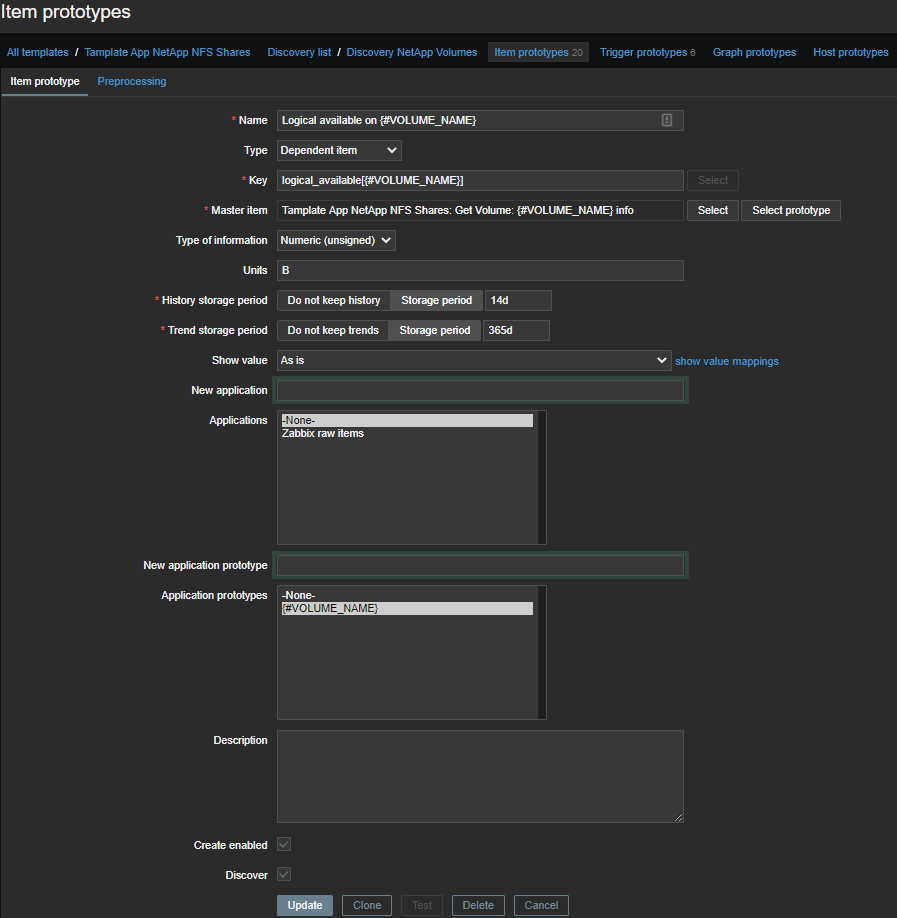
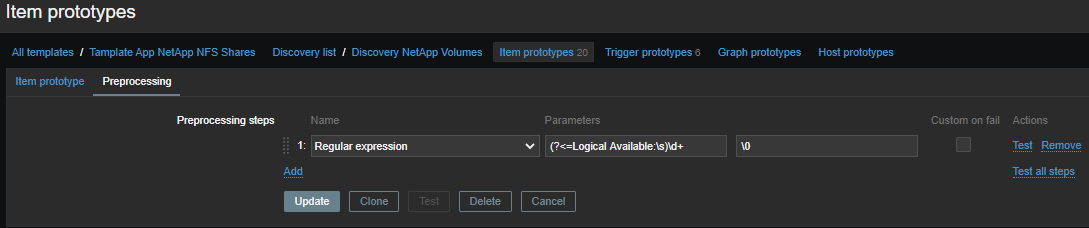
(?<=Logical Available:\s)\d+

Métricas coletadas:
Logical available on {#VOLUME_NAME}- a quantidade de espaço lógico disponível;Logical used percent on {#VOLUME_NAME}- lugar lógico usado em porcentagem;Logical used size on {#VOLUME_NAME}- a quantidade de espaço lógico usado;Physical used percentage on {#VOLUME_NAME}- espaço físico utilizado em porcentagem;Total physical used size on {#VOLUME_NAME}- a quantidade de espaço físico usado;Total used on {#VOLUME_NAME}- espaço total utilizado;Total used percent on {#VOLUME_NAME}- total de vagas utilizadas em porcentagem;Logical size on {#VOLUME_NAME}- elemento calculado , a quantidade de espaço lógico disponível.
last(logical_available[{#VOLUME_NAME}])+last(total_used[{#VOLUME_NAME}])Desempenho de volume
Depois de ler a documentação e mexer em diferentes comandos, descobri que podemos obter métricas sobre o desempenho de nossos volumes. Uma pequena peça é responsável por isso:
statistics volume show -volume {#VOLUME_NAME}
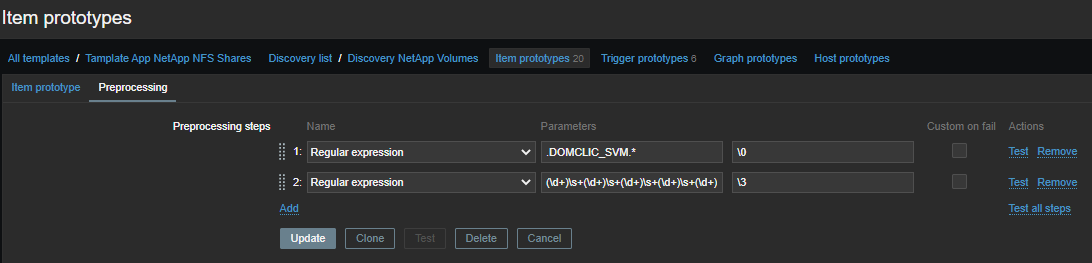
Selecionamos métricas de desempenho da planilha comum com a primeira regularidade:
.DOMCLIC_SVM.*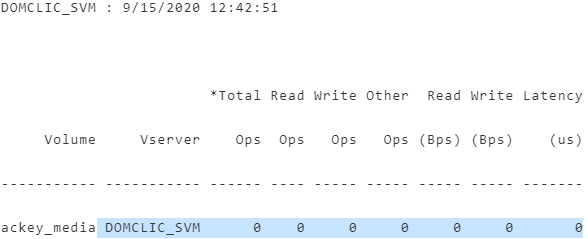

Em segundo lugar, agrupamos os números:
(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)
Onde:
\1 - Total number of operations per second on {#VOLUME_NAME}- o número total de operações por segundo;\2 - Read operations per second on {#VOLUME_NAME}- operações de leitura por segundo;\3 - Write operations per second on {#VOLUME_NAME}- escrever operações por segundo;\4 - Other operations per second on {#VOLUME_NAME}- outras operações por segundo (não sei o que é, mas por algum motivo atiro);\5 - Read throughput in bytes per second on {#VOLUME_NAME}- velocidade de leitura em bytes por segundo;\6 - Write throughput in bytes per second on {#VOLUME_NAME}- velocidade de gravação em bytes por segundo;\7 - Average latency for an operation in microseconds on {#VOLUME_NAME}- latência média das operações em microssegundos.
Alerta
O conjunto de gatilhos é padrão, local e inodes:
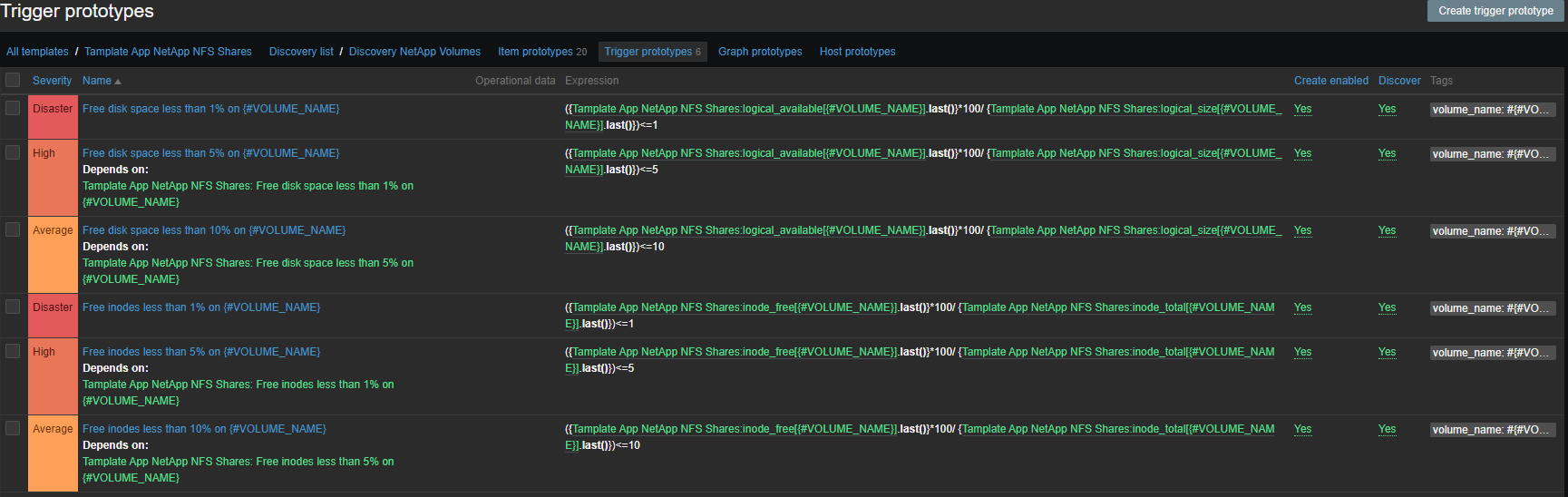
- Espaço livre em disco inferior a 1% em {#VOLUME_NAME}
- Espaço livre em disco inferior a 5% em {#VOLUME_NAME}
- Espaço livre em disco inferior a 10% em {#VOLUME_NAME}
- Inodes grátis menos de 1% em {#VOLUME_NAME}
- Inodes grátis com menos de 5% em {#VOLUME_NAME}
- Inodes grátis com menos de 10% em {#VOLUME_NAME}
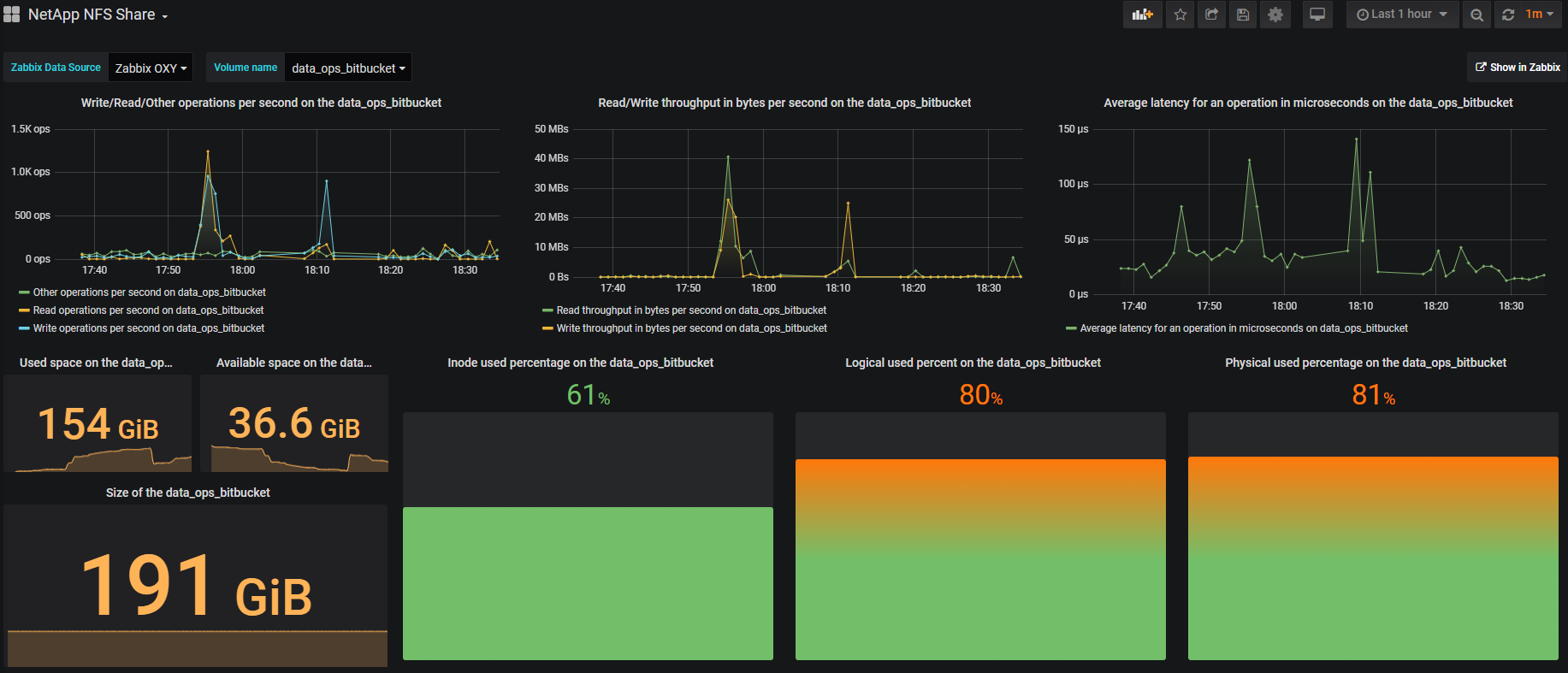
Visualização
A visualização é feita principalmente no Grafana , é bonita e conveniente. Por exemplo, um volume se parece com isto: No canto superior direito há um botão Mostrar no Zabbix , com o qual você pode entrar no Zabbix e ver todas as métricas do volume selecionado.
Resultado
- Configuração automática de volumes para monitoramento.
- Remoção automática de volumes do monitoramento, se o volume for removido da NetApp.
- Nós nos livramos de vincular a um servidor e montar volumes manualmente.
- Adicionadas métricas de desempenho para cada volume. Agora é menos provável que puxemos o suporte de datacenter para gráficos da NetApp.
Em breve, eles prometem atualizar o ONTAP e trazer uma API estendida, o modelo será movido para um agente HTTP .
Modelo, script e painel
github.com/domclick/netapp-volume-monitoring
Links Úteis
docs.netapp.com/ontap-9/index.jsp
www.zabbix.com/documentation/current