Os princípios do nosso sistema
Quando você ouve termos como "automático" e "fraude", provavelmente está pensando em aprendizado de máquina, Apache Spark, Hadoop, Python, Airflow e outras tecnologias do ecossistema da Fundação Apache e do campo de ciência de dados. Acho que há um aspecto do uso dessas ferramentas que geralmente não é mencionado: elas exigem determinados pré-requisitos em seu sistema corporativo antes que você possa começar a usá-las. Resumindo, você precisa de uma plataforma de dados corporativos que inclua um data lake e armazenamento. Mas e se você não tiver essa plataforma e ainda precisar desenvolver essa prática? Os princípios a seguir, que discuto a seguir, nos ajudaram a chegar ao ponto em que podemos nos concentrar em melhorar nossas ideias, em vez de encontrar uma que funcione. No entanto, este não é um "platô" do projeto.Ainda há muitas coisas no plano do ponto de vista tecnológico e do produto.
Princípio 1: O valor empresarial vem em primeiro lugar
Colocamos o valor comercial no centro de todos os nossos esforços. Em geral, qualquer sistema de análise automática pertence ao grupo dos sistemas complexos com alto nível de automação e complexidade técnica. Levará muito tempo para criar uma solução completa se você criá-la do zero. Decidimos priorizar o valor do negócio e a completude tecnológica em segundo lugar. Na vida real, isso significa que não aceitamos a tecnologia avançada como um dogma. Nós escolhemos a tecnologia que funciona melhor para nós no momento. Com o tempo, pode parecer que teremos que reimplementar alguns módulos. Esse compromisso que aceitamos.
Princípio 2: inteligência aumentada
Aposto que a maioria das pessoas que não estão profundamente envolvidas no desenvolvimento de soluções de aprendizado de máquina pode pensar que substituir pessoas é o objetivo. Na verdade, as soluções de aprendizado de máquina estão longe de ser perfeitas e só podem ser substituídas em algumas áreas. Abandonamos essa ideia desde o início por vários motivos: dados desequilibrados sobre atividades fraudulentas e a incapacidade de fornecer uma lista exaustiva de recursos para modelos de aprendizado de máquina. Em contraste, escolhemos a opção de inteligência aprimorada. É um conceito alternativo de inteligência artificial que se concentra no papel de suporte da IA, destacando o fato de que as tecnologias cognitivas são projetadas para melhorar a inteligência humana, não substituí-la. [1]
Com isso em mente, desenvolver uma solução completa de aprendizado de máquina desde o início exigiria uma quantidade enorme de esforço que atrasaria a criação de valor para o nosso negócio. Decidimos construir um sistema com um aspecto de crescimento iterativo de aprendizado de máquina sob a orientação de nossos especialistas no domínio. A parte complicada de desenvolver tal sistema é que ele deve fornecer aos nossos analistas casos não apenas em termos de se se trata de uma atividade fraudulenta ou não. Em geral, qualquer anomalia no comportamento do cliente é um caso suspeito que os especialistas precisam investigar e responder de alguma forma. Apenas uma fração desses casos relatados pode realmente ser classificada como fraude.
Princípio 3: plataforma de inteligência rica
A parte mais difícil do nosso sistema é a verificação de ponta a ponta do fluxo de trabalho do sistema. Analistas e desenvolvedores devem ser capazes de recuperar facilmente conjuntos de dados históricos com todas as métricas usadas para sua análise. Além disso, a plataforma de dados deve fornecer uma maneira fácil de complementar um conjunto existente de métricas com um novo. Os processos que criamos, e estes não são apenas processos de software, devem tornar mais fácil recalcular períodos anteriores, adicionar novas métricas e alterar a previsão de dados. Poderíamos conseguir isso acumulando todos os dados que nosso sistema de produção gera. Nesse caso, os dados gradualmente se tornariam um empecilho. Precisaríamos armazenar e proteger a quantidade crescente de dados que não usamos. Em tal cenário, com o tempo, os dados se tornarão cada vez mais irrelevantes,mas ainda exigem nossos esforços para gerenciá-los. Para nós, o armazenamento de dados não fazia sentido, e decidimos adotar uma abordagem diferente. Decidimos organizar armazenamentos de dados em tempo real em torno das entidades de destino que desejamos classificar e apenas armazenar dados que nos permitem verificar os períodos mais recentes e atuais. O desafio desse esforço é que nosso sistema é heterogêneo, com vários armazenamentos de dados e módulos de software que requerem um planejamento cuidadoso para funcionar de forma consistente.que permitem verificar os períodos mais recentes e atuais. O desafio desse esforço é que nosso sistema é heterogêneo, com vários armazenamentos de dados e módulos de software que requerem um planejamento cuidadoso para funcionar de forma consistente.que permitem verificar os períodos mais recentes e atuais. O desafio desse esforço é que nosso sistema é heterogêneo, com vários armazenamentos de dados e módulos de software que requerem um planejamento cuidadoso para funcionar de forma consistente.
Conceitos construtivos do nosso sistema
Temos quatro componentes principais em nosso sistema: sistema de ingestão, computacional, análise de BI e sistema de rastreamento. Eles servem a propósitos isolados específicos e nós os mantemos isolados seguindo abordagens de design específicas.
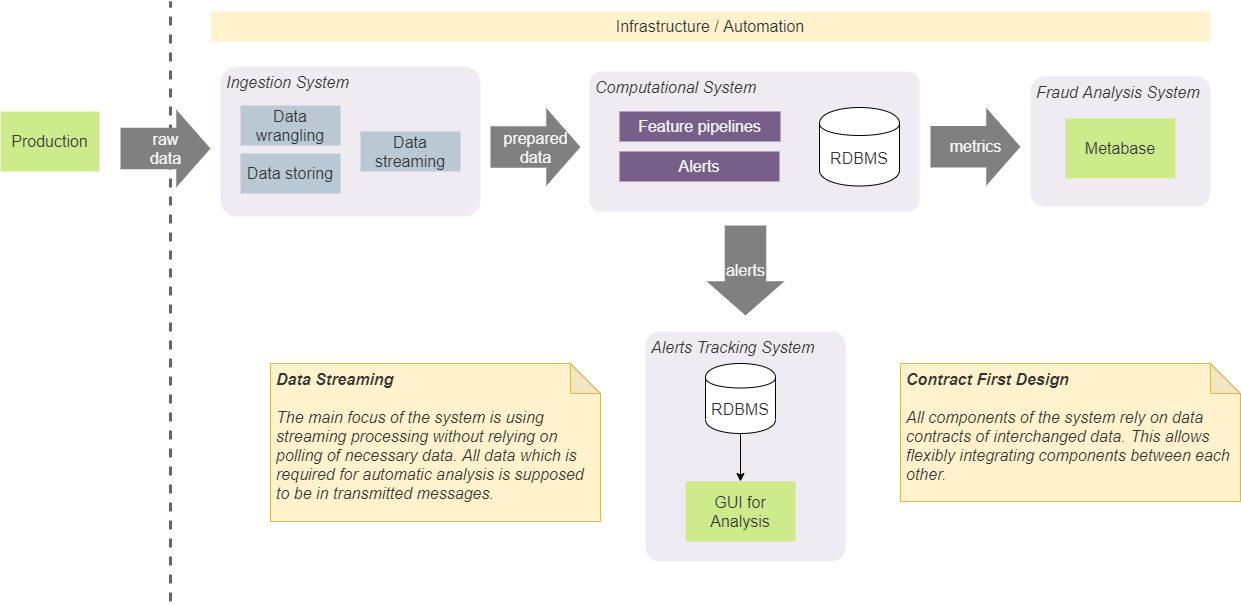
Projeto baseado em contrato
Em primeiro lugar, concordamos que os componentes devem contar apenas com certas estruturas de dados (contratos) que são passados entre eles. Isso facilita a integração entre eles e não impõe uma composição (e ordem) específica de componentes. Por exemplo, em alguns casos, isso nos permite integrar diretamente o sistema de recebimento com o sistema de rastreamento de alertas. Em caso afirmativo, isso será feito de acordo com o contrato de notificação acordado. Isso significa que ambos os componentes serão integrados por meio de um contrato que qualquer outro componente pode usar. Não adicionaremos um contrato adicional para adicionar alertas ao sistema de rastreamento do sistema de entrada. Esta abordagem requer o uso de um número mínimo predeterminado de contratos e simplifica o sistema e a comunicação. De fato,usamos uma abordagem chamada "Contrato Primeiro Design" e a aplicamos a contratos de streaming. [2]
Manter e gerenciar o estado do sistema inevitavelmente levará a complicações em sua implementação. Em geral, o estado deve ser acessível a partir de qualquer componente, deve ser consistente e fornecer o valor mais atualizado para todos os componentes e deve ser confiável com os valores corretos. Além disso, ter chamadas para armazenamento persistente para obter o estado mais recente aumentará a quantidade de E / S e a complexidade dos algoritmos usados em nossos pipelines em tempo real. Por isso, decidimos remover o armazenamento de estado o mais completamente possível de nosso sistema. Esta abordagem requer a inclusão de todos os dados necessários no bloco de dados transmitidos (mensagem). Por exemplo, se precisarmos calcular o número total de algumas observações (o número de operações ou casos com certas características),nós o calculamos na memória e geramos um fluxo de tais valores. Os módulos dependentes usarão partição e lote para dividir o fluxo em entidades e operar nos valores mais recentes. Essa abordagem eliminou a necessidade de armazenamento em disco permanente para esses dados. Nosso sistema usa Kafka como agente de mensagens e pode ser usado como banco de dados com KSQL. [3] Mas usá-lo amarraria fortemente nossa solução a Kafka, e decidimos não usá-lo. A abordagem que adotamos nos permite substituir Kafka por outro corretor de mensagens sem grandes mudanças internas no sistema.Essa abordagem eliminou a necessidade de armazenamento em disco permanente para esses dados. Nosso sistema usa Kafka como agente de mensagens e pode ser usado como banco de dados com KSQL. [3] Mas usá-lo amarraria fortemente nossa solução a Kafka, e decidimos não usá-lo. A abordagem que adotamos nos permite substituir Kafka por outro corretor de mensagens sem grandes mudanças internas no sistema.Essa abordagem eliminou a necessidade de armazenamento em disco permanente para esses dados. Nosso sistema usa Kafka como agente de mensagens e pode ser usado como banco de dados com KSQL. [3] Mas usá-lo amarraria fortemente nossa solução a Kafka, e decidimos não usá-lo. A abordagem que adotamos nos permite substituir Kafka por outro corretor de mensagens sem grandes mudanças internas no sistema.
Este conceito não significa que não usamos armazenamento em disco e bancos de dados. Para verificar e analisar o desempenho do sistema, precisamos armazenar em disco uma parte significativa dos dados que representam vários indicadores e estados. O ponto importante aqui é que os algoritmos em tempo real são independentes desses dados. Na maioria dos casos, usamos os dados armazenados para análise offline, depuração e rastreamento de casos e resultados específicos que o sistema produz.
Os problemas do nosso sistema
Existem certos problemas que resolvemos até certo nível, mas eles exigem soluções mais cuidadosas. Por enquanto, gostaria apenas de mencioná-los aqui, pois cada ponto vale um artigo separado.
- , , .
- . , .
- IF-ELSE ML. - : «ML — ». , ML, , . , , .
- .
- (true positive) . — , . , , — . , , .
- , .
- : , () .
- Por último mas não menos importante. Precisamos criar uma ampla plataforma de validação de desempenho na qual possamos analisar nossos modelos. [4]