O projeto cresceu, a biblioteca agora resolve todas as tarefas básicas de processamento da língua russa natural: segmentação em tokens e frases, análise morfológica e sintática, lematização, extração de entidades nomeadas.

Para artigos de notícias, a qualidade em todas as tarefas é comparável ou superior às soluções existentes... Por exemplo, Natasha lida com a tarefa NER em 1 ponto percentual pior do que Deeppavlov BERT NER (F1 PER 0,97, LOC 0,91, ORG 0,85), o modelo pesa 75 vezes menos (27 MB), é executado na CPU 2 vezes mais rápido (25 artigos / s ) do que BERT NER na GPU.
Existem 9 repositórios no projeto , a biblioteca Natasha os reúne em uma interface. No artigo, vamos falar sobre novas ferramentas, compará-las com as soluções existentes: Deeppavlov , SpaCy , UDPipe .

Esta longa leitura foi precedida por uma série de postagens em natasha.github.io :Se o tamanho do texto abaixo te assusta, assista os primeiros 20 minutos do tubo transmitindo a história do projeto Natasha, aí está um breve reconto:
- Natasha - NER compacto de qualidade para o idioma russo
- Navec - embeddings compactos para o idioma russo
- Corus - coleção de conjuntos de dados de PNL em russo
- Razdel - segmentação de texto em russo em tokens e ofertas
- Naeval - comparação quantitativa de sistemas para PNL de língua russa
- Nerus é um grande conjunto de dados sintético do idioma russo com marcação de morfologia, sintaxe e entidades nomeadas
O texto usa notas e discussões do chat t.me/natural_language_processing , links para novos materiais aparecem no mesmo lugar:
- Por que Natasha não está usando Transformers. BERT em 100 linhas
- Modelos Slovnet BERT
- Fluxo de tubo sobre a história do projeto Natasha
- Documentação atualizada do Yargy
- Recursos adicionais no analisador Yargy
Para quem gosta de ouvir mais, confira a palestra de hora em hora no Datafest 2020, que quase cobre este post:
Conteúdo:
- Natasha — .
- Razdel —
- Slovnet — deep learning
- Navec —
- Nerus — ,
- Corus — +
- Naeval — NLP
- Yargy- —
- Ipymarkup —
Natasha — .

Anteriormente, a biblioteca Natasha resolvia o problema do NER para o idioma russo, era construída sobre regras , apresentava qualidade e desempenho médios. Agora Natasha é um grande projeto, consiste em 9 repositórios . A biblioteca Natasha os une em uma interface, resolve as tarefas básicas de processamento da língua russa natural: segmentação em tokens e frases, embeddings pré-treinados, morfologia e análise de sintaxe, lematização, NER. Todas as soluções mostram os melhores resultados em novos tópicos e são executados rapidamente na CPU.
Natasha é semelhante a outras bibliotecas combinadas: SpaCy , UDPipe , Stanza... SpaCy inicializa e chama modelos implicitamente, o usuário passa o texto para a função mágica
nlp, obtém um documento totalmente analisado.
import spacy
# load ,
# , NER
nlp = spacy.load('...')
# ,
text = '...'
doc = nlp(text)
A interface de Natasha é mais detalhada. O usuário inicializa explicitamente os componentes: carrega embeddings pré-treinados e os passa para os construtores do modelo. Sam chama métodos
segment, tag_morph, parse_syntaxsegmentação em tokens e demanda, análise da morfologia e sintaxe.
>>> from natasha import (
Segmenter,
NewsEmbedding,
NewsMorphTagger,
NewsSyntaxParser,
Doc
)
>>> segmenter = Segmenter()
>>> emb = NewsEmbedding()
>>> morph_tagger = NewsMorphTagger(emb)
>>> syntax_parser = NewsSyntaxParser(emb)
>>> text = ' , , 2019 () ...'
>>> doc = Doc(text)
>>> doc.segment(segmenter)
>>> doc.tag_morph(morph_tagger)
>>> doc.parse_syntax(syntax_parser)
>>> sent = doc.sents[0]
>>> sent.morph.print()
NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Inan|Case=Gen|Gender=Masc|Number=Sing
ADP
PROPN|Animacy=Inan|Case=Loc|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
...
>>> sent.syntax.print()
┌──► nsubj
│
│ ┌► case
│ └─
│ ┌─
│ └► flat:name
┌─────┌─└───
│ │ ┌──► , punct
│ │ │ ┌► mark
│ └►└─└─ ccomp
│ │ ┌► case
│ └──►└─ obl
...
O extrator de entidade nomeado não depende dos resultados morfológicos e de análise, ele pode ser usado separadamente.
>>> from natasha import NewsNERTagger
>>> ner_tagger = NewsNERTagger(emb)
>>> doc.tag_ner(ner_tagger)
>>> doc.ner.print()
, ,
LOC──── LOC──── PER───────
2019
LOC──────────────
()
LOC─── ORG───────────────────────────────────────
...
PER────────────
Natasha resolve o problema de lematização, usa Pymorphy2 e os resultados da análise morfológica.
>>> from natasha import MorphVocab
>>> morph_vocab = MorphVocab()
>>> for token in doc.tokens:
>>> token.lemmatize(morph_vocab)
>>> {_.text: _.lemma for _ in doc.tokens}
{'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
',': ',',
'': '',
'': ''
...
Para trazer a frase à sua forma normal, não basta encontrar os lemas de palavras individuais, para o Ministério das Relações Exteriores da Rússia será o Ministério das Relações Exteriores da Rússia, para a Organização dos Nacionalistas Ucranianos - a Organização Nacionalista da Ucrânia. Natasha usa os resultados da análise, leva em consideração as relações entre as palavras, normaliza as entidades nomeadas.
>>> for span in doc.spans:
>>> span.normalize(morph_vocab)
>>> {_.text: _.normal for _ in doc.spans}
{'': '',
'': '',
' ': ' ',
' ': ' ',
'': '',
' ()': ' ()',
' ': ' ',
...
Natasha encontra nomes, organizações e nomes de lugares no texto. Para nomes na biblioteca, há um conjunto de regras prontas para o analisador Yargy , o módulo divide os nomes normalizados em partes, de "Viktor Fedorovich Yushchenko" é obtido
{first: , last: , middle: }.
>>> from natasha import (
PER,
NamesExtractor,
)
>>> names_extractor = NamesExtractor(morph_vocab)
>>> for span in doc.spans:
>>> if span.type == PER:
>>> span.extract_fact(names_extractor)
>>> {_.normal: _.fact.as_dict for _ in doc.spans if _.type == PER}
{' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
'': {'last': ''},
' ': {'first': '', 'last': ''}}
A biblioteca contém regras para análise de datas, quantias em dinheiro e endereços, que são descritas na documentação e no livro de referência .
A biblioteca Natasha é adequada para demonstrar tecnologias de projeto, usadas na educação. Arquivos com pesos de modelo são integrados ao pacote; após a instalação, você não precisa baixar e configurar nada.
Natasha combina outras bibliotecas de projeto em uma interface. Para resolver problemas práticos, você deve usá-los diretamente:
- Razdel - segmentação de texto em frases e tokens;
- Navec - embeddings compactos de alta qualidade;
- Slovnet - modelos compactos modernos para morfologia, sintaxe, NER;
- Yargy - regras e vocabulários para extrair informações estruturadas;
- Ipymarkup - visualização de NER e marcação sintática;
- Corus - coleção de links para conjuntos de dados públicos em russo;
- Nerus é um grande corpus com marcação automática de entidades nomeadas, morfologia e sintaxe.
Razdel - segmentação de texto em russo em tokens e ofertas

A biblioteca Razdel faz parte do projeto Natasha, divide o texto em russo em tokens e frases. Instruções de instalação , exemplo de uso e medidas de desempenho no repositório Razdel.
>>> from razdel import tokenize, sentenize
>>> text = '- 0.5 (50/64 ³, 516;...)'
>>> list(tokenize(text))
[Substring(start=0, stop=13, text='-'),
Substring(start=14, stop=16, text=''),
Substring(start=17, stop=20, text='0.5'),
Substring(start=20, stop=21, text=''),
Substring(start=22, stop=23, text='(')
...]
>>> text = '''
... - " ?" - " --".
... . . . . ,
... '''
>>> list(sentenize(text))
[Substring(start=1, stop=23, text='- " ?"'),
Substring(start=24, stop=40, text='- " --".'),
Substring(start=41, stop=56, text=' . . . .'),
Substring(start=57, stop=76, text=' , ')]
Os modelos modernos muitas vezes não se preocupam com a segmentação, usam BPE , apresentam resultados notáveis, lembram todas as versões do GPT e do zoológico de BERT . Natasha resolve os problemas de análise da morfologia e sintaxe, eles fazem sentido apenas para palavras separadas dentro de uma frase. Portanto, abordamos com responsabilidade o estágio de segmentação, tentando repetir a marcação de conjuntos de dados abertos populares: SynTagRus , OpenCorpora , GICRYA .
A velocidade e a qualidade de Razdel são comparáveis ou melhores do que outras soluções de código aberto para o idioma russo.
| Soluções de segmentação de token | Erros por 1000 tokens | Tempo de processamento, segundos |
| Regexp-baseline | 19 | 0,5 |
| SpaCy
|
17 | 5,4 |
| NLTK
|
130 | 3,1 |
| MyStem
|
19 | 4,5 |
| Moisés
|
onze | 1,9 |
| SegTok
|
12 | 2,1 |
| SpaCy Russian Tokenizer
|
8 | 46.4 |
| RuTokenizer
|
15 | 1.0 |
| Razdel
|
7 | 2.6 |
| 1000 | , | |
| Regexp-baseline | 76 | 0.7 |
| SegTok
|
381 | 10.8 |
| Moses
|
166 | 7.0 |
| NLTK
|
57 | 7.1 |
| DeepPavlov
|
41 | 8.5 |
| Razdel | 43 | 4.8 |
Número médio de erros para 4 conjuntos de dados : SynTagRus , OpenCorpora , GICRYA e RNC . Mais detalhes no repositório Razdel .
Por que você precisa do Razdel, se uma linha de base com uma linha regular oferece uma qualidade semelhante e há muitas soluções prontas para o idioma russo? Na verdade, Razdel não é apenas um tokenizer, mas um pequeno mecanismo de segmentação baseado em regras. A segmentação é uma tarefa básica, frequentemente encontrada na prática. Por exemplo, há um ato judicial, você precisa destacar a parte operativa nele e dividi-lo em parágrafos. Naturalmente, as soluções de prateleira não podem fazer isso. Leia como escrever suas próprias regras no código-fonte . Além disso, falaremos sobre como se esforçar e fazer uma solução superior para tokens e ofertas em nosso mecanismo.
Qual é a dificuldade?
Em russo, as frases geralmente terminam com um ponto final, ponto de interrogação ou exclamação. Vamos apenas dividir o texto com uma expressão regular
[.?!]\s+. Esta solução resultará em 76 erros por 1000 sentenças. Tipos e exemplos de erros:
Abreviações
... qualquer plataforma com um público de 3.000 ou mais pessoas é um blogueiro.
... Bey estava sobre eles desde o final do século 17;
… No Teatro Musical de Câmara com o nome de ▒B.A. Pokrovsky.
As iniciais
na sequência da ópera "Idomeneo" V.A.▒Motsarta - R.▒Shtrausa ...
Listas
2.▒dumal estará no consulado finlandês bastante longa fila ...
g.▒bilety trens Russian Railways ...
O final da frase smiley ou pontos tipográficos
Quem propõe uma forma de se livrar das desvantagens - graças a isso :) ▒ Olhei, pensativo ... ▒ Agora isso é mais desagradável, pois o conteúdo vai se quebrar.
Citações, discurso direto, no final da frase uma aspa
- você tem noiva na cidade? ”▒“ Para quem tem noiva? ”.
“Que bom que eu não sou assim!” ▒Agora, enquanto traduzia, cometi um erro freudiano: “idologia”.
Razdel leva essas nuances em consideração, reduzindo o número de erros de 76 para 43 por 1000 sentenças.
A situação é semelhante com tokens. Uma boa solução básica é uma regex
[--]+|[0-9]+|[^-0-9 ], ela comete 19 erros por 1000 tokens. Exemplos:
números fracionários, pontuação complexa
... No final dos anos 1980 - início dos anos 1990
... BS-▒3 pode ser notado com um pouco menos de massa (3▒, ▒6 t)
- e ela morreu ▒.▒. Você entende a garota, falcão? ▒!
Razdel está reduzindo a taxa de erro para 7 por 1000 tokens.
Princípio da Operação
O sistema é baseado em regras. O princípio de segmentação em tokens e ofertas é o mesmo.
Coleção de candidatos
Encontramos no texto todos os candidatos ao final da frase: pontos, elipses, colchetes, aspas.
6.▒ A opção de respostas mais frequente e ao mesmo tempo bem avaliada I (13 afirmações, 25 pontos) ▒– situações de aprovação e incentivo. ▒7.▒ Vale ressaltar que na resposta “Eu sei” é estimada como a mais estereotipada , mas apenas quando houver a resposta "Eu sou mulher" ▒; ▒ há afirmações “um casamento é tudo o que me espera nesta vida” ▒ e “mais cedo ou mais tarde terei de dar à luz” ▒.▒ Compiladores: V.▒P.▒Golovin , F.▒V.▒Zanichev, A.▒L.▒Rastorguev, R.▒V.▒Savko, I.▒I.▒Tuchkov.
Para tokens, dividimos o texto em átomos. A borda do token não passa exatamente dentro do átomo.
No final de 1980▒-▒▒-início1990▒-▒▒
BS▒-▒3▒ é possível▒marcar uma massa ligeiramente▒ menor▒ (▒3▒, ▒6▒▒) ▒
▒— Da▒and▒umerla▒.▒.▒.▒Got ▒ligirl, ▒the falcon▒? ▒!
União
Constantemente contornamos os candidatos à separação e removemos os desnecessários. Usamos uma lista de heurísticas.
Item da lista. O separador é um ponto ou parêntese, à esquerda um número ou letra
6.▒ A resposta mais frequente e ao mesmo tempo muito apreciada “Estou feliz” (13 afirmações, 25 pontos) é uma situação de aprovação e incentivo. 7.▒ Vale ressaltar que na resposta "Eu sei" ...
Iniciais. Separador - ponto, uma letra maiúscula à esquerda
... Compiladores: V.▒P.▒Golovin, F.▒V.▒Zanichev, A.▒L.▒Rastorguev, R.▒V.▒Savko, I.▒I. ...
Não há espaço à direita do separador
... mas apenas uma vez é a resposta "Eu sou uma mulher" ▒; há afirmações “um casamento é tudo o que me espera nesta vida” e “mais cedo ou mais tarde terei que dar à luz” ▒.
Não há ponto de final de frase antes das aspas de fechamento ou parênteses, esta não é uma citação ou discurso direto
6. A resposta mais frequente e muito apreciada é “Estou feliz” «(13 afirmações, 25 pontos) ▒ - situações de obtenção de aprovação e encorajamento. ... "um casamento é tudo o que me espera nesta vida" e "mais cedo ou mais tarde terei de dar à luz."
Como resultado, restam dois separadores, nós os consideramos finais de frases.
6. A variante mais frequente e ao mesmo tempo muito apreciada de respostas “Estou contente” (13 afirmações, 25 pontos) é uma situação de receber aprovação e encorajamento. Ressalta-se que na resposta “eu sei” ela é avaliada como a mais estereotipada, mas apenas quando a resposta “sou mulher” for encontrada; há declarações “um casamento é tudo o que me espera nesta vida” e “mais cedo ou mais tarde terei que dar à luz.” Compilado por V.P. Golovin, F.V. Zanichev, A.L. Rastorguev, R.V. Savko, I. I. Tuchkov.
O procedimento é semelhante para tokens, as regras são diferentes.
Fração ou número racional
... (3▒, ▒6 t) ...
Pontuação complexa
- sim, e morreu.▒.▒. Você entende a garota, falcão? ▒!
Não há espaços ao redor do hífen, este não é o começo da fala direta
No final de 1980▒-▒ - início de 1990▒-▒
BS▒-▒3 pode-se notar ...
Tudo o que resta é considerado os limites dos tokens.
No final da década de 1980-x▒-início▒1990-x▒
BS-3▒ é possível▒notificar ligeiramente▒baixomass (▒3,6▒t▒) ▒
▒ - sim e morreu. ..▒Entendi▒li▒girl, ▒sokol▒?!
Limitações
As regras do Razdel são otimizadas para texto bem escrito com pontuação correta. A solução funciona bem com notícias, textos literários. Nas postagens das redes sociais, transcrições de conversas telefônicas, a qualidade é inferior. Se não houver espaço entre as frases ou nenhum ponto final, ou se a frase começar com uma letra minúscula, Razdel cometerá um erro. Leia
como escrever regras para suas tarefas no código-fonte , este tópico ainda não foi divulgado na documentação.
Slovnet - modelagem de aprendizagem profunda para processamento natural da língua russa

No projeto Natasha Slovnet está envolvida no ensino e inferência de modelos modernos para PNL de língua russa. A biblioteca contém modelos compactos de alta qualidade para extrair entidades nomeadas, analisar a morfologia e a sintaxe. A qualidade em todas as tarefas é comparável ou superior a outras soluções abertas para o idioma russo em textos de notícias. Instruções de instalação , exemplos de uso - no repositório Slovnet . Vamos dar uma olhada em como a solução para o problema NER está organizada, para morfologia e sintaxe tudo é por analogia.
No final de 2018, após um artigo do Google sobre o BERT , houve muitos avanços na PNL em inglês. Em 2019, o pessoal do projeto DeepPavlovadaptado BERT multilíngue para russo, apareceu RuBERT . Uma cabeça CRF foi treinada no topo , resultou DeepPavlov BERT NER - SOTA para a língua russa. O modelo tem excelente qualidade, 2 vezes menos erros do que o perseguidor mais próximo DeepPavlov NER , mas o tamanho e o desempenho são assustadores: 6GB - consumo de GPU RAM, 2GB - tamanho do modelo, 13 artigos por segundo - desempenho em um bom GPU.
Em 2020, no projeto Natasha, conseguimos chegar perto em qualidade do DeepPavlov BERT NER, o tamanho do modelo acabou sendo 75 vezes menor (27MB), o consumo de memória é 30 vezes menor (205MB), a velocidade é 2 vezes maior no CPU (25 artigos por segundo )
| Natasha, Slovnet NER | DeepPavlov BERT NER | |
| PER / LOC / ORG F1 por tokens, média por Collection5, factRuEval-2016, BSNLP-2019, Gareev | 0,97 / 0,91 / 0,85 | 0,98 / 0,92 / 0,86 |
| Tamanho do modelo | 27 MB | 2GB |
| Consumo de memória | 205 MB | 6 GB (GPU) |
| Desempenho, artigos de notícias por segundo (1 artigo ≈ 1 KB) | 25 por CPU (Core i5) | 13 GPU (RTX 2080 Ti), 1 CPU |
| Tempo de inicialização, segundos | 1 | 35 |
| A biblioteca suporta | Python 3.5+, PyPy3 | Python 3.6+ |
| Dependências | NumPy | TensorFlow |
A qualidade do Slovnet NER é 1 ponto percentual menor que a do SOTA DeepPavlov BERT NER, o tamanho do modelo é 75 vezes menor, o consumo de memória é 30 vezes menor, a velocidade é 2 vezes maior na CPU. Comparação com SpaCy, PullEnti e outras soluções para NER de língua russa no repositório Slovnet .
Como você consegue esse resultado? Receita curta:
Slovnet NER = Slovnet BERT NER - análogo de DeepPavlov BERT NER + destilação através de marcação sintética ( Nerus ) em WordCNN-CRF com embeddings quantizados ( Navec ) + motor para inferência em NumPy.
Agora em ordem. O plano é o seguinte: treinar um modelo pesado com arquitetura BERT em um pequeno conjunto de dados anotado manualmente. Nós o marcamos com um corpus de notícias e obtemos um grande conjunto de dados de treinamento sintético sujo. Vamos treinar um modelo primitivo compacto nele. Esse processo é chamado de destilação: o modelo pesado é o professor, o modelo compacto é o aluno. Esperamos que a arquitetura BERT seja redundante para o problema NER, o modelo compacto não perderá muito em qualidade para o pesado.
Professora modelo
DeepPavlov BERT NER consiste em um codificador RuBERT e uma cabeça CRF. Nosso modelo de professor pesado repete essa arquitetura com pequenas melhorias.
Todos os benchmarks medem a qualidade NER em textos de notícias. Vamos treinar RuBERT nas notícias. O repositório Corus contém links para corpus de notícias públicas em russo, um total de 12 GB de textos. Usamos técnicas do artigo do Facebook sobre RoBERTa : grandes lotes agregados, máscara dinâmica, recusa em prever a próxima frase (NSP). RuBERT usa um vocabulário enorme de 120.000 subtokens - um legado do BERT multilíngue do Google. Se reduzirmos o tamanho para 50.000 das notícias mais frequentes, a cobertura diminuirá 5%. Obtenha NewsRuBERT, o modelo prevê subtokens disfarçadas nas notícias 5 pontos percentuais melhor do que RuBERT (63% no top 1).
Vamos treinar o codificador NewsRuBERT e o cabeçote CRF para 1000 artigos da Collection5 . Pegamos Slovnet BERT NER , a qualidade é 0,5 pontos percentuais melhor do que DeepPavlov BERT NER, o tamanho do modelo é 4 vezes menor (473 MB), funciona 3 vezes mais rápido (40 artigos por segundo).
NewsRuBERT = RuBERT + 12GB de notícias + tecnologias do dicionário RoBERTa + 50K.
Slovnet BERT NER (análogo de DeepPavlov BERT NER) = NewsRuBERT + cabeça CRF + Collection5.
Agora, para treinar modelos com arquitetura do tipo BERT, costuma-se usar Transformers da Hugging Face. Transformers são 100.000 linhas de código Python. Quando a perda ou o lixo explodem na inferência, é difícil descobrir o que deu errado. Ok, muito código está duplicado lá. Mesmo se treinarmos RoBERTa, podemos localizar rapidamente o problema em aproximadamente 3.000 linhas de código, mas isso também é muito. Com o PyTorch moderno, a biblioteca Transformers não é tão relevante. Com
torch.nn.TransformerEncoderLayero código de modelo semelhante ao RoBERTa, o código leva 100 linhas:
class BERTEmbedding(nn.Module):
def __init__(self, vocab_size, seq_len, emb_dim, dropout=0.1, norm_eps=1e-12):
super(BERTEmbedding, self).__init__()
self.word = nn.Embedding(vocab_size, emb_dim)
self.position = nn.Embedding(seq_len, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.drop = nn.Dropout(dropout)
def forward(self, input):
batch_size, seq_len = input.shape
position = torch.arange(seq_len).expand_as(input).to(input.device)
emb = self.word(input) + self.position(position)
emb = self.norm(emb)
return self.drop(emb)
def BERTLayer(emb_dim, heads_num, hidden_dim, dropout=0.1, norm_eps=1e-12):
layer = nn.TransformerEncoderLayer(
d_model=emb_dim,
nhead=heads_num,
dim_feedforward=hidden_dim,
dropout=dropout,
activation='gelu'
)
layer.norm1.eps = norm_eps
layer.norm2.eps = norm_eps
return layer
class BERTEncoder(nn.Module):
def __init__(self, layers_num, emb_dim, heads_num, hidden_dim,
dropout=0.1, norm_eps=1e-12):
super(BERTEncoder, self).__init__()
self.layers = nn.ModuleList([
BERTLayer(
emb_dim, heads_num, hidden_dim,
dropout, norm_eps
)
for _ in range(layers_num)
])
def forward(self, input, pad_mask=None):
input = input.transpose(0, 1) # torch expects seq x batch x emb
for layer in self.layers:
input = layer(input, src_key_padding_mask=pad_mask)
return input.transpose(0, 1) # restore
class BERTMLMHead(nn.Module):
def __init__(self, emb_dim, vocab_size, norm_eps=1e-12):
super(BERTMLMHead, self).__init__()
self.linear1 = nn.Linear(emb_dim, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.linear2 = nn.Linear(emb_dim, vocab_size)
def forward(self, input):
x = self.linear1(input)
x = F.gelu(x)
x = self.norm(x)
return self.linear2(x)
class BERTMLM(nn.Module):
def __init__(self, emb, encoder, head):
super(BERTMLM, self).__init__()
self.emb = emb
self.encoder = encoder
self.head = head
def forward(self, input):
x = self.emb(input)
x = self.encoder(x)
return self.head(x)
Este não é um protótipo, o código é copiado do repositório Slovnet . Os transformadores são bons de ler, fazem muito trabalho, enchem o código de artigos com Arxiv, muitas vezes o código-fonte do Python é mais claro do que a explicação em um artigo científico.
Conjunto de dados sintético
Vamos marcar 700.000 artigos do corpus Lenta.ru com um modelo pesado. Temos um enorme conjunto de dados de treinamento sintético. O arquivo está disponível no repositório Nerus do projeto Natasha. A marcação é de altíssima qualidade, estimativas de F1 por tokens: PER - 99,7%, LOC - 98,6%, ORG - 97,2%. Exemplos raros de erros:
ORG────────────── LOC────────────────────────────
241- 4- 10-
<
LOC─── LOC──────
>.
───────────~~~~~~~~~~~
ORG────────────────────~~~~~~~~~~~~~~~~
.
LOC───
<>
~~~~~~~~ LOC──────────────────
.
~~~~ ~~~~~~ LOC───
.
LOC────
-
PER─────────────────────
M&A.
~~~
:
~~~~~~~~~~~~ORG─── LOC──
,
PER─────── LOC───
,
ORG─ LOC─────────────
.
LOC
Aluno modelo
Não houve problemas com a escolha da arquitetura do modelo de professor pesado, havia apenas uma opção - transformadores. O modelo compacto do aluno é mais difícil, existem muitas opções. De 2013 a 2018, do advento do word2vec ao artigo sobre o BERT, a humanidade criou um monte de arquiteturas de rede neural para resolver o problema do NER. Todos têm um esquema comum:
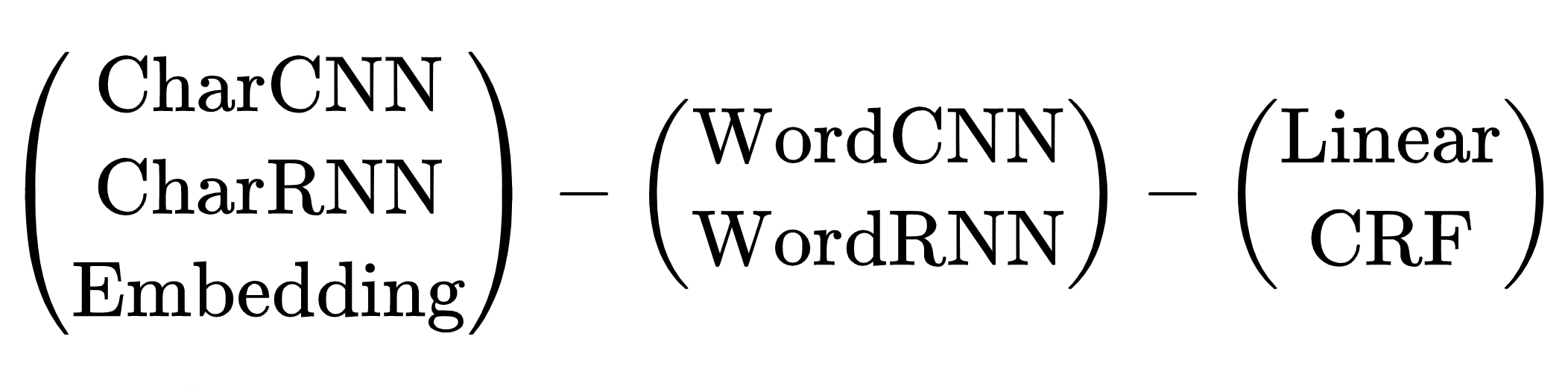
Esquema de arquiteturas de rede neural para a tarefa NER: codificador de token, codificador de contexto, decodificador de tag. Explicações sobre abreviações em um artigo de revisão de Yang (2018) .
Existem muitas combinações de arquiteturas. Qual escolher? Por exemplo, (CharCNN + Embedding) -WordBiLSTM-CRF é um diagrama de modelo de um artigo sobre DeepPavlov NER , SOTA para o idioma russo até 2019.
Ignoramos as opções com CharCNN, CharRNN, o lançamento de uma pequena rede neural por símbolos em cada token não é nosso caminho, muito lento. Também gostaria de evitar WordRNN, a solução deve funcionar na CPU, multiplicar as matrizes em cada token lentamente. Para NER, a escolha entre Linear e CRF é condicional. Usamos codificação BIO, a ordem das tags é importante. Temos que suportar freios terríveis, use CRF. Resta uma opção - Embedding-WordCNN-CRF. Este modelo não faz distinção entre maiúsculas e minúsculas, para NER é importante, "esperança" é apenas uma palavra, "esperança" é possivelmente um nome. Adicionar ShapeEmbedding - incorporação com contornos de token, por exemplo: "NER" - EN_XX, "Vainovich" - RU_Xx, "!" - PUNCT_!, "E" - RU_x, "5.1" - NUM, "Nova York" - RU_Xx-Xx. Esquema Slovnet NER - (WordEmbedding + ShapeEmbedding) -WordCNN-CRF.
Destilação
Vamos treinar o Slovnet NER em um enorme conjunto de dados sintéticos. Vamos comparar o resultado com o modelo de professor pesado Slovnet BERT NER. A qualidade é calculada e a média calculada com base na coleção5, Gareev, factRuEval-2016, BSNLP-2019 marcada manualmente. O tamanho da amostra de treinamento é muito importante: para 250 artigos de notícias (factRuEval-2016), a média para PER, LOC, LOG F1 é 0,64, para 1000 (análogo a Collection5) - 0,81, para o conjunto de dados inteiro - 0,91, qualidade Slovnet BERT NER - 0,92.
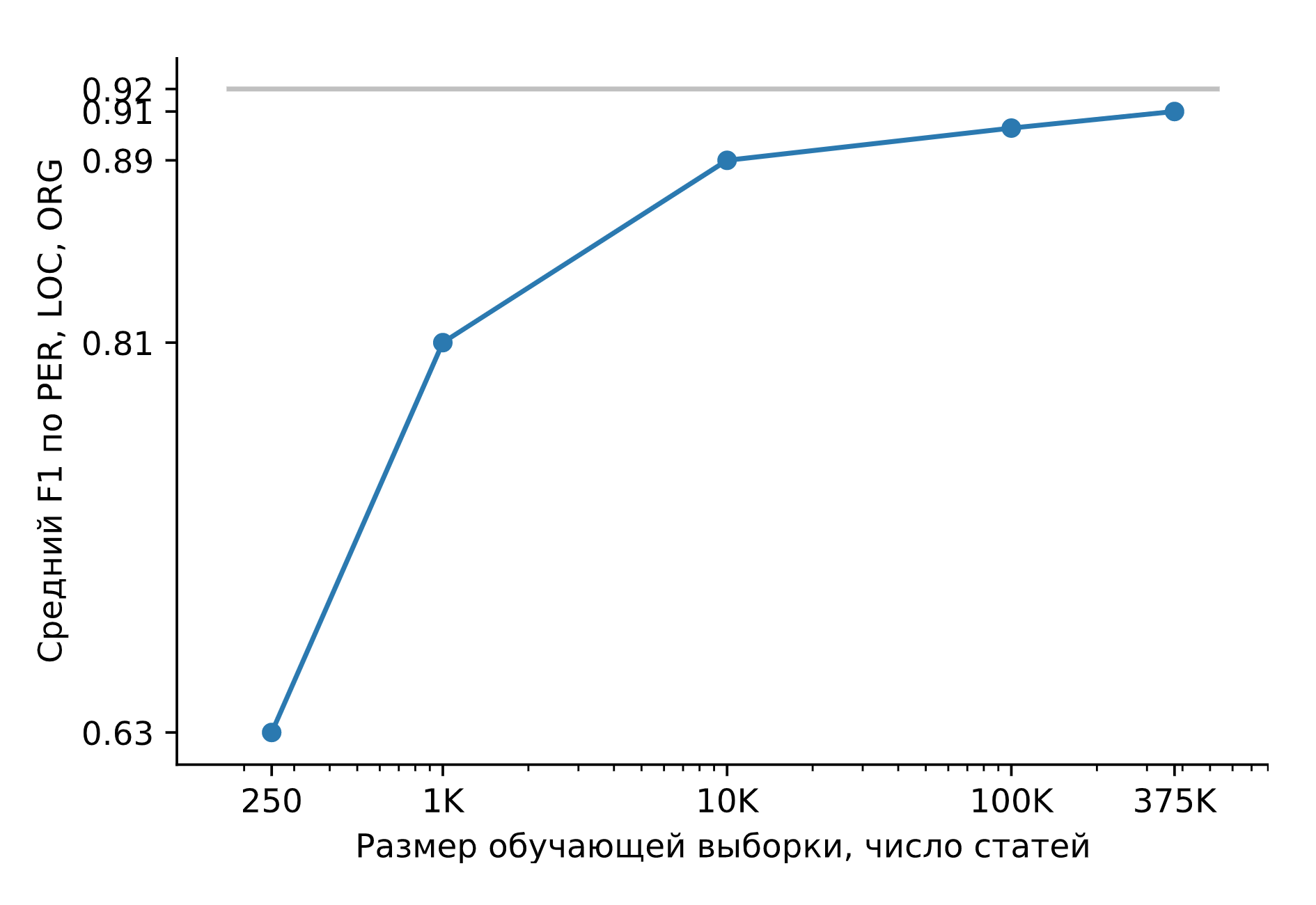
Qualidade Slovnet NER, dependência do número de exemplos de treinamento sintético. Linha cinza - qualidade Slovnet BERT NER. Slovnet NER não vê exemplos marcados à mão, ele treina apenas em dados sintéticos.
O modelo do aluno primitivo é 1 ponto percentual pior do que o modelo do professor obstinado. Este é um resultado maravilhoso. Uma receita universal se sugere:
Marcamos manualmente alguns dados. Treinamos um transformador pesado. Geramos muitos dados sintéticos. Treinamos um modelo simples em uma grande amostra. Conseguimos a qualidade do transformador, o tamanho e o desempenho de um modelo simples.
Na biblioteca Slovnet existem mais dois modelos treinados de acordo com esta receita: Slovnet Morph - identificador morfológico, Slovnet Syntax - analisador sintático. Slovnet Morph está atrás do modelo de professor pesado em 2 pontos percentuais , Slovnet Syntax - em 5 . Ambos os modelos têm melhor qualidade e desempenho do que as soluções russas existentes para artigos de notícias.
Quantização
O Slovnet NER tem 289 MB. 287 MB é ocupado por uma mesa com embeddings. O modelo usa um grande vocabulário de 250.000 linhas e cobre 98% das palavras em textos de notícias. Usando a quantização , substitua os vetores float de 300 dimensões por vetores de 8 bits de 100 dimensões. O tamanho do modelo será reduzido 10 vezes (27 MB), a qualidade não mudará. A biblioteca Navec faz parte do projeto Natasha, uma coleção de embeddings pré-treinados quantizados. Pesos treinados em ficção ocupam 50 MB, contornando todos os modelos RusVectores estáticos de acordo com estimativas sintéticas .
Inferência
Slovnet NER usa PyTorch para treinamento. O pacote PyTorch pesa 700 MB, não quero arrastá-lo para a produção para inferência. O PyTorch também não funciona com o interpretador PyPy . Slovnet é usado em conjunto com um analisador Yargy, um análogo do analisador Yandex Tomita . Com o PyPy, o Yargy funciona de 2 a 10 vezes mais rápido, dependendo da complexidade das gramáticas. Não quero perder velocidade devido à dependência do PyTorch.
A solução padrão é usar TorchScript ou converter o modelo para ONNX , fazer a inferência em ONNXRuntime . Slovnet NER usa blocos não padronizados: embeddings quantizados, decodificador CRF. TorchScript e ONNXRuntime não suportam PyPy.
Slovnet NER é um modelo simples,implementar manualmente todos os blocos em NumPy , usar pesos calculados por PyTorch. Vamos aplicar um pouco de mágica NumPy, implementar cuidadosamente o bloco CNN , decodificador CRF , desempacotar a incorporação quantizada leva 5 linhas . A velocidade de inferência na CPU é a mesma que com ONNXRuntime e PyTorch, 25 artigos de notícias por segundo no Core i5.
A técnica funciona em modelos mais complexos: Slovnet Morph e Slovnet Syntax também são implementados em NumPy. Slovnet NER, Morph e Syntax compartilham uma tabela de incorporação comum. Vamos retirar os pesos em um arquivo separado, a tabela não está duplicada na memória e no disco:
>>> navec = Navec.load('navec_news_v1_1B.tar') # 25MB
>>> morph = Morph.load('slovnet_morph_news_v1.tar') # 2MB
>>> syntax = Syntax.load('slovnet_syntax_news_v1.tar') # 3MB
>>> ner = NER.load('slovnet_ner_news_v1.tar') # 2MB
# 25 + 2 + 3 + 2 25+2 + 25+3 + 25+2
>>> morph.navec(navec)
>>> syntax.navec(navec)
>>> ner.navec(navec)
Limitações
Natasha extrai entidades padrão: nomes, nomes de topônimos e organizações. A solução mostra boa qualidade nas notícias. Como trabalhar com outras entidades e tipos de textos? Precisamos treinar um novo modelo. Isto não é fácil de fazer. Pagamos pelo tamanho compacto e velocidade de trabalho pela complexidade da preparação do modelo. Laptop de script para preparar um modelo de professor pesado , laptop de script para um modelo de aluno , instruções para preparar embeddings quantizados .
Navec - embeddings compactos para o idioma russo

Os modelos compactos são fáceis de trabalhar. Eles são iniciados rapidamente, usam pouca memória e cabem mais processos paralelos em uma instância.
Na PNL, 80-90% dos pesos do modelo estão na tabela de incorporação. A biblioteca Navec faz parte do projeto Natasha, uma coleção de embeddings pré-treinados para a língua russa. Em termos de métricas de qualidade intrínseca, eles estão ligeiramente abaixo das soluções de topo do RusVectores , mas o tamanho do arquivo com pesos é 5-6 vezes menor (51 MB), o dicionário é 2-3 vezes maior (500 mil palavras).
| Qualidade * | Tamanho do modelo, MB | Tamanho do dicionário, × 10 3 | |
| Navec | 0,719 | 50,6 | 500 |
| RusVectores | 0,638-0,726 | 220,6-290,7 | 189-249 |
Vamos falar sobre os bons e velhos embeddings palavra por palavra que revolucionaram a PNL em 2013. A tecnologia ainda é relevante hoje. No projeto Natasha, os modelos para análise da morfologia , sintaxe e extração de entidades nomeadas funcionam em embeddings Navec palavra por palavra, mostram qualidade acima de outras soluções abertas .
RusVectores
Para o idioma russo, costuma-se usar embeddings pré-treinados do RusVectores , eles têm uma característica desagradável: a tabela não contém palavras, mas pares “palavra_POS-tag”. A ideia é boa, para o par "forno_VERB" esperamos um vetor semelhante a "cook_VERB", "cook_VERB" e para "forno_NOUN" - "hut_NOUN", "furnace_NOUN".
Na prática, é inconveniente usar tais embeddings. Não é suficiente dividir o texto em tokens, para cada um você precisa definir de alguma forma a tag POS. A mesa de incorporação está inchando. Em vez de uma palavra “tornar-se”, armazenamos 6: 2 razoável “tornar-se_VERB”, “tornar-se_NOUN” e 4 estranho “tornar-se_ADV”, “tornar-se_PROPN”, “tornar-se_NUM”, “tornar-se_ADJ”. Existem 195.000 palavras únicas em uma tabela com 250.000 entradas.
Qualidade
Vamos estimar a qualidade dos embeddings no problema de proximidade semântica. Vamos pegar algumas palavras, para cada uma encontraremos um vetor de incorporação e calcularemos a similaridade do cosseno. Navec para palavras semelhantes "xícara" e "jarro" retornará 0,49, para "fruta" e "forno" - -0,0047. Vamos coletar muitos pares com marcas de referência de similaridade, calcular a correlação de Spearman com nossas respostas.
Os autores do RusVectores usam uma lista de testes pequena, cuidadosamente verificada e revisada de pares SimLex965 . Vamos adicionar um novo Yandex LRWC e conjuntos de dados do projeto RUSSE : HJ , RT , AE , AE2 :
| Qualidade média em 6 conjuntos de dados | Tempo de carregamento, segundos | Tamanho do modelo, MB | Tamanho do dicionário, × 10 3 | ||
| Navec | hudlit_12B_500K_300d_100q |
0,719 | 1.0 | 50,6 | 500 |
news_1B_250K_300d_100q |
0,653 | 0,5 | 25,4 | 250 | |
| RusVectores | ruscorpora_upos_cbow_300_20_2019 |
0,692 | 3,3 | 220,6 | 189 |
ruwikiruscorpora_upos_skipgram_300_2_2019 |
0,691 | 5.0 | 290,0 | 248 | |
tayga_upos_skipgram_300_2_2019 |
0,726 | 5,2 | 290,7 | 249 | |
tayga_none_fasttextcbow_300_10_2019 |
0,638 | 8,0 | 2741,9 | 192 | |
araneum_none_fasttextcbow_300_5_2018 |
0,664 | 16,4 | 2752,1 | 195 |
A qualidade é
hudlit_12B_500K_300d_100qcomparável ou melhor do que a das soluções RusVectores, o dicionário é 2-3 vezes maior, o tamanho do modelo é 5-6 vezes menor. Como você conseguiu essa qualidade e tamanho?
Princípio da Operação
hudlit_12B_500K_300d_100q- Embeddings GloVe treinados para 145 GB de ficção . Vamos pegar o arquivo com os textos do projeto RUSSE . Vamos usar a implementação original do GloVe em C e envolvê-la em uma interface Python conveniente .
Por que não o word2vec? Os experimentos em um grande conjunto de dados são mais rápidos com o GloVe. Depois de calcular a matriz de colocação, use-a para preparar embeddings de diferentes dimensões, escolha a melhor opção.
Por que não fastText? No projeto Natasha trabalhamos com textos noticiosos. Existem poucos erros de digitação neles, o problema de tokens OOV é resolvido por um grande dicionário. 250.000 linhas na tabela
news_1B_250K_300d_100qcobrem 98% das palavras em artigos de notícias.
Tamanho do dicionário
hudlit_12B_500K_300d_100q- 500.000 entradas, abrange 98% das palavras em textos de ficção. A dimensão ideal dos vetores é 300. Uma tabela de 500.000 × 300 de números flutuantes ocupa 578 MB, o tamanho do arquivo com pesos hudlit_12B_500K_300d_100qé 12 vezes menor ( 48 MB ). É sobre quantização.
Quantização
Substitua os números flutuantes de 32 bits por códigos de 8 bits: [−∞, −0,86) - código 0, [−0,86, -0,79) - código 1, [-0,79, -0,74) - 2,…, [0,86, ∞) - 255. O tamanho da mesa é reduzido em 4 vezes (143 MB).
:
-0.220 -0.071 0.320 -0.279 0.376 0.409 0.340 -0.329 0.400
0.046 0.870 -0.163 0.075 0.198 -0.357 -0.279 0.267 0.239
0.111 0.057 0.746 -0.240 -0.254 0.504 0.202 0.212 0.570
0.529 0.088 0.444 -0.005 -0.003 -0.350 -0.001 0.472 0.635
────── ──────
-0.170 0.677 0.212 0.202 -0.030 0.279 0.229 -0.475 -0.031
────── ──────
:
63 105 215 49 225 230 219 39 228
143 255 78 152 187 34 49 204 198
163 146 253 58 55 240 188 191 246
243 155 234 127 127 35 128 237 249
─── ───
76 251 191 188 118 207 195 18 118
─── ───
Os dados são grosseiros, valores diferentes -0,005 e -0,003 substituem um código 127, -0,030 e -0,031 - 118
Vamos substituir pelo código não um, mas 3 números. Nós agrupamos todos os tripletos de números da tabela de incorporação usando o algoritmo k-means em 256 clusters, em vez de cada trio armazenaremos um código de 0 a 255. A tabela diminuirá 3 vezes (48 MB). O Navec usa a biblioteca PQk-means , divide a matriz em 100 colunas, agrupa cada uma separadamente, a qualidade dos testes sintéticos cairá 1 ponto percentual. É claro sobre a quantização no artigo Quantizadores de produto para k-NN .
Embeddings quantizados são mais lentos do que os normais. O vetor compactado deve ser descompactado antes do uso. Implementamos cuidadosamente o procedimento, aplicamos a magia Numpy, em PyTorch usamos torch.gather . No Slovnet NER, o acesso à tabela de incorporação leva 0,1% do tempo total de computação.
Um módulo
NavecEmbeddingda biblioteca Slovnet integra Navec em modelos PyTorch:
>>> import torch
>>> from navec import Navec
>>> from slovnet.model.emb import NavecEmbedding
>>> path = 'hudlit_12B_500K_300d_100q.tar' # 51MB
>>> navec = Navec.load(path) # ~1 sec, ~100MB RAM
>>> words = ['', '<unk>', '<pad>']
>>> ids = [navec.vocab[_] for _ in words]
>>> emb = NavecEmbedding(navec)
>>> input = torch.tensor(ids)
>>> emb(input) # 3 x 300
tensor([[ 4.2000e-01, 3.6666e-01, 1.7728e-01,
[ 1.6954e-01, -4.6063e-01, 5.4519e-01,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00,
...Nerus é um grande conjunto de dados sintéticos com marcação de morfologia, sintaxe e entidades nomeadas

No projeto Natasha, morfologia, análise de sintaxe e extração de entidade nomeada são feitas por 3 modelos compactos: Slovnet NER , Slovnet Morph e Slovnet Syntax . A qualidade das soluções é 1–5 pontos percentuais pior do que suas contrapartes pesadas com uma arquitetura BERT, o tamanho é 50–75 vezes menor e a velocidade da CPU é 2 vezes maior. Os modelos são treinados em um enorme conjunto de dados Nerus sintético , em um arquivo de 700.000 artigos de notícias com marcação CoNLL-U de morfologia, sintaxe e entidades nomeadas:
# newdoc id = 0
# sent_id = 0_0
# text = - , ...
1 - _ NOUN _ Animacy=Anim|C... 7 nsubj _ Tag=O
2 _ ADP _ _ 4 case _ Tag=O
3 _ ADJ _ Case=Dat|Degre... 4 amod _ Tag=O
4 _ NOUN _ Animacy=Inan|C... 1 nmod _ Tag=O
5 _ PROPN _ Animacy=Anim|C... 1 appos _ Tag=B-PER
6 _ PROPN _ Animacy=Anim|C... 5 flat:name _ Tag=I-PER
7 _ VERB _ Aspect=Perf|Ge... 0 root _ Tag=O
8 , _ PUNCT _ _ 13 punct _ Tag=O
9 _ ADP _ _ 11 case _ Tag=O
10 _ DET _ Case=Loc|Numbe... 11 det _ Tag=O
11 _ NOUN _ Animacy=Inan|C... 13 obl _ Tag=O
12 _ PROPN _ Animacy=Inan|C... 11 nmod _ Tag=B-LOC
13 _ VERB _ Aspect=Perf|Ge... 7 ccomp _ Tag=O
14 _ ADV _ Degree=Pos 15 advmod _ Tag=O
15 _ ADJ _ Case=Nom|Degre... 16 amod _ Tag=O
16 _ NOUN _ Animacy=Inan|C... 13 nsubj _ Tag=O
17 _ ADP _ _ 18 case _ Tag=O
18 _ NOUN _ Animacy=Inan|C... 16 nmod _ Tag=O
19 , _ PUNCT _ _ 20 punct _ Tag=O
20 _ VERB _ Aspect=Imp|Moo... 0 root _ Tag=O
21 _ PROPN _ Animacy=Inan|C... 20 nsubj _ Tag=B-ORG
22 _ PROPN _ Animacy=Inan|C... 21 appos _ Tag=I-ORG
23 . _ PUNCT _ _ 20 punct _ Tag=O
# sent_id = 0_1
# text = , , , ...
1 _ ADP _ _ 2 case _ Tag=O
2 _ NOUN _ Animacy=Inan|C... 9 parataxis _ Tag=O
...Slovnet NER, Morph, Syntax - modelos primitivos. Quando há 1000 exemplos no conjunto de treinamento, Slovnet NER fica atrás do pesado analógico BERT em 11 pontos percentuais, quando 10.000 exemplos - em 3 pontos, quando 500.000 - em 1.
Nerus é o resultado do trabalho, modelos pesados com arquitetura BERT: Slovnet BERT NER , Slovnet BERT Morph , Slovnet BERT Syntax . O processamento de 700.000 artigos de notícias leva 20 horas no Tesla V100. Economizamos o tempo de outros pesquisadores, colocamos o arquivo finalizado em acesso aberto. Em SpaCy-Ru ensine na Nerus o modelo qualitativo para o SpaCy de língua russa, prepare um patch no repositório oficial.

A marcação sintética tem uma alta qualidade: a precisão na determinação de tags morfológicas é de 98%, links sintáticos - 96%. Para NER, estimativas F1 por tokens: PER - 99%, LOC - 98%, ORG - 97%. Para avaliar a qualidade, marcamos SynTagRus , Collection5 e a fatia de notícias GramEval2020 , comparamos a marcação de referência com a nossa, para mais detalhes no repositório Nerus . Devido a erros na marcação da sintaxe, existem loops e raízes múltiplas, as tags POS às vezes não correspondem às arestas sintáticas. É útil usar o validador de Dependências Universais , pule esses exemplos.
O pacote Python Nerus organiza uma interface conveniente para carregar e renderizar marcação:
>>> from nerus import load_nerus
>>> docs = load_nerus('nerus_lenta.conllu.gz')
>>> doc = next(docs)
>>> doc
NerusDoc(
id='0',
sents=[NerusSent(
id='0_0',
text='- , ...',
tokens=[NerusToken(
id='1',
text='-',
pos='NOUN',
feats={'Animacy': 'Anim',
'Case': 'Nom',
'Gender': 'Masc',
'Number': 'Sing'},
head_id='7',
rel='nsubj',
tag='O'
),
NerusToken(
id='2',
text='',
pos='ADP',
...
>>> doc.ner.print()
- ,
PER───────────── LOC───
, . ,
ORG──────── PER──────
...
>>> sent = doc.sents[0]
>>> sent.morph.print()
- NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
ADP
ADJ|Case=Dat|Degree=Pos|Number=Plur
NOUN|Animacy=Inan|Case=Dat|Gender=Masc|Number=Plur
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
VERB|Aspect=Perf|Gender=Fem|Mood=Ind|Number=Sing
...
>>> sent.syntax.print()
┌►┌─┌───── - nsubj
│ │ │ ┌──► case
│ │ │ │ ┌► amod
│ │ └►└─└─ nmod
│ └────►┌─ appos
│ └► flat:name
┌─└─────────
│ ┌──────► , punct
│ │ ┌──► case
│ │ │ ┌► det
│ │ ┌►└─└─ obl
│ │ │ └──► nmod
└──►└─└───── ccomp
│ ┌► advmod
│ ┌►└─ amod
└►┌─└─── nsubj:pass
│ ┌► case
└──►└─ nmod
┌► , punct
┌─┌─└─
│ └►┌─ nsubj
│ └► appos
└────► . punct
Instruções de instalação, exemplos de uso , avaliações de qualidade no repositório Nerus.
Corus - uma coleção de links para conjuntos de dados públicos + funções em russo para download

A biblioteca Corus é parte do projeto Natasha, uma coleção de links para conjuntos de dados PNL públicos em russo + pacote Python com funções de carregador. Lista de links para fontes , instruções de instalação e exemplos de uso no repositório Corus.
>>> from corus import load_lenta
# Corus Lenta.ru, :
# wget https://github.com/yutkin/Lenta.Ru-News-Dataset/...
>>> path = 'lenta-ru-news.csv.gz'
>>> records = load_lenta(path) # 2, 750 000
>>> next(records)
LentaRecord(
url='https://lenta.ru/news/2018/12/14/cancer/',
title=' \xa0 ...',
text='- ...',
topic='',
tags=''
)
Conjuntos de dados abertos úteis para a língua russa estão tão bem escondidos que poucas pessoas sabem sobre eles.
Exemplos de
Corpus de artigos de notícias
Queremos treinar o modelo de linguagem em reportagens, precisamos de muitos textos. A primeira coisa que vem à mente é uma fatia de notícias do conjunto de dados Taiga (~ 1 GB). Muitas pessoas sabem sobre o despejo Lenta.ru (2 GB). Outras fontes são mais difíceis de encontrar. Em 2019, a Dialogue sediou um concurso para geração de manchetes ; os organizadores prepararam um despejo de RIA Novosti por 4 anos (3,7 GB). Em 2018, Yuri Baburov publicou um upload de 40 fontes de notícias em russo (7,5 GB). Voluntários da ODS compartilham os arquivos (7GB) coletados para o projeto de análise da agenda de notícias .
No registro da Coruslinks para esses conjuntos de dados com a tag «notícias», para todas as fontes têm uma função-carregadeiras:
load_taiga_*, load_lenta, load_ria, load_buriy_*, load_ods_*.
NER
Queremos ensinar NER para a língua russa, precisamos de textos anotados. Em primeiro lugar, relembramos os dados do concurso factRuEval-2016 . A marcação tem desvantagens: seu formato complexo, extensões de entidades se sobrepõem, há uma categoria "LocOrg" ambígua. Nem todo mundo conhece a coleção Named Entities 5, a sucessora de Person-1000 . Layout em formato padrão , vãos não se cruzam, beleza! As outras três fontes são conhecidas apenas pelos fãs mais dedicados do NER de língua russa. Vamos escrever para Rinat Gareev por correio, anexar um link para seu artigo de 2013 , em resposta receberemos 250 artigos de notícias com nomes e organizações marcados. A competição BSNLP-2019 foi realizada em 2019sobre o NER para línguas eslavas, escreveremos aos organizadores, obteremos mais 450 textos marcados. O projeto WiNER surgiu com a ideia de fazer marcação NER semiautomática a partir de despejos da Wikipedia , um grande download para russo está disponível no Github .
Ligações e funções para carregar o registo Corus:
load_factru, load_ne5, load_gareev, load_bsnlp, load_wikiner.
Coleção de links
Antes de obter um bootloader e entrar no registro, os links para as fontes são acumulados na seção com Tickets . A coleção de 30 conjuntos de dados: uma nova versão do Taiga , texto 568GB russo de Crawl do comum , comentários c Banki.ru e Auto.ru . Convidamos você a compartilhar suas descobertas, criar tickets com links.
Funções de carregador
O código para um conjunto de dados simples é fácil de escrever você mesmo. O despejo Lenta.ru é bem formado, a implementação é simples . O Taiga é composto de aproximadamente 15 milhões de arquivos zip CoNLL-U . Para que o download funcione rapidamente, não use muita memória e não estrague o sistema de arquivos, você precisa se confundir e implementar cuidadosamente o trabalho com arquivos zip em um nível baixo .
Para 35 fontes, o pacote Corus Python possui funções de carregador. A interface para acessar o Taiga não é mais complicada do que o despejo Lenta.ru:
>>> from corus import load_taiga_proza_metas, load_taiga_proza
>>> path = 'taiga/proza_ru.zip'
>>> metas = load_taiga_proza_metas(path)
>>> records = load_taiga_proza(path, metas)
>>> next(records)
TaigaRecord(
id='20151231005',
meta=Meta(
id='20151231005',
timestamp=datetime.datetime(2015, 12, 31, 23, 40),
genre=' ',
topic='',
author=Author(
name='',
readers=7973,
texts=92681,
url='http://www.proza.ru/avtor/sadshoot'
),
title=' !',
url='http://www.proza.ru/2015/12/31/1875'
),
text='... ...\n... ..\n...
)
Convidamos os usuários a fazer solicitações pull, enviar suas funções de carregador, uma breve instrução no repositório Corus.
Naeval - comparação quantitativa de sistemas para PNL de língua russa

Natasha não é um projeto científico, não há objetivo de vencer SOTA, mas é importante verificar a qualidade nos benchmarks públicos, tentar ocupar um lugar de destaque sem perder muito em performance. Como fazem na academia: medir a qualidade, pegar um número, pegar tablets de outros artigos, comparar esses números com os seus. Este esquema tem dois problemas:
- Esqueça o desempenho. Eles não comparam o tamanho do modelo, a velocidade de trabalho. A ênfase está na qualidade apenas.
- Não publique o código. Geralmente, há um milhão de nuances no cálculo de uma métrica de qualidade. Como exatamente isso foi contado em outros artigos? Desconhecido.
Naeval faz parte do projeto Natasha, um conjunto de scripts para avaliar a qualidade e a velocidade das ferramentas de código aberto para processar o idioma russo natural:
| Tarefa | Conjuntos de dados | Soluções |
| Tokenização | SynTagRus, OpenCorpora, GICRYA, RNC
|
SpaCy, NLTK, MyStem, Moses, SegTok, SpaCy Russian Tokenizer, RuTokenizer, Razdel
|
| SynTagRus, OpenCorpora, GICRYA, RNC
|
SegTok, Moses, NLTK, RuSentTokenizer, Razdel
|
|
| SimLex965, HJ, LRWC, RT, AE, AE2
|
RusVectores, Navec
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov Morph, DeepPavlov BERT Morph, RuPosTagger, RNNMorph, Maru, UDPipe, SpaCy, Stanza, Slovnet Morph, Slovnet BERT Morph
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov BERT Syntax, UDPipe, SpaCy, Stanza, Slovnet Syntax, Slovnet BERT Syntax
|
|
| NER | factRuEval-2016, Collection5, Gareev, BSNLP-2019, WiNER
|
DeepPavlov NER , DeepPavlov BERT NER , DeepPavlov Slavic BERT NER , PullEnti , SpaCy , Stanza , Texterra , Tomita , MITIE , Slovnet NER , Slovnet BERT NER
|
Vamos dar uma olhada no problema de NER abaixo.
Conjuntos de dados
Existem 5 benchmarks públicos para o NER de língua russa: factRuEval-2016 , Collection5 , Gareev , BSNLP-2019 , WiNER . Os links de fontes são coletados no registro Corus . Todos os conjuntos de dados consistem em artigos de notícias, substrings com nomes, nomes de organizações e nomes de lugares são marcados nos textos. O que poderia ser mais fácil?
Todas as fontes têm um formato de marcação diferente. Collection5 usa o formato Standoff dos utilitários Brat , Gareev e WiNER - diferentes dialetos da marcação BIO , BSNLP-2019 tem seu próprio formato , factRuEval-2016 também tem sua própria especificação não trivial... Naeval converte todas as fontes em um formato comum. A marcação consiste em extensões. Span - três: tipo de entidade, início e fim de uma substring.
Tipos de entidade. factRuEval-2016 e Collection5 marcam separadamente os seminomes-semiorganizações: "Kremlin", "EU", "URSS". BSNLP-2019 e WiNER destacam os nomes dos eventos: "Campeonato da Rússia", "Brexit". Naeval adapta e remove algumas das tags, deixa as tags de referência PER, LOC, ORG: nomes de pessoas, nomes de topônimos e organizações.
Vãos aninhados. Na realidadeRuEval-2016, as extensões se sobrepõem. Naeval simplifica a marcação:
:
, 5 Retail Group,
org_name───────
Org────────────
"", "" "",
org_descr───── org_name─ org_name─── org_name
Org──────────────────────
org_descr─────
Org─────────────────────────────────────
org_descr─────
Org──────────────────────────────────────────────────
, .
:
, 5 Retail Group,
ORG────────────
"", "" "",
ORG────── ORG──────── ORG─────
, .
Modelos
Naeval compara 12 soluções de código aberto ao problema NER russo. Todas as ferramentas são embaladas em contêineres Docker com uma interface da web:
$ docker run -p 8080:8080 natasha/tomita-algfio
2020-07-02 11:09:19 BIN: 'tomita-linux64', CONFIG: 'algfio'
2020-07-02 11:09:19 Listening http://0.0.0.0:8080
$ curl -X POST http://localhost:8080 --data \
' \
\
'
<document url="" di="5" bi="-1" date="2020-07-02">
<facts>
<Person pos="18" len="16" sn="0" fw="2" lw="3">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
<Person pos="67" len="14" sn="0" fw="8" lw="9">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
</facts>
</document>
Algumas soluções são tão difíceis de lançar e configurar que poucas pessoas as usam. O PullEnti , um sistema sofisticado baseado em regras, conquistou o primeiro lugar na competição factRuEval em 2016. A ferramenta é distribuída como um SDK para C #. O trabalho no Naeval resultou em um projeto separado com um conjunto de wrappers para PullEnti: PullentiServer é um servidor da web C #, pullenti-client é um cliente Python para PullentiServer:
$ docker run -p 8080:8080 pullenti/pullenti-server
2020-07-02 11:42:02 [INFO] Init Pullenti v3.21 ...
2020-07-02 11:42:02 [INFO] Load lang: ru, en
2020-07-02 11:42:03 [INFO] Load analyzer: geo, org, person
2020-07-02 11:42:05 [INFO] Listen prefix: http://*:8080/
>>> from pullenti_client import Client
>>> client = Client('localhost', 8080)
>>> text = ' ' \
... ' ' \
... ' '
>>> result = client(text)
>>> result.graph
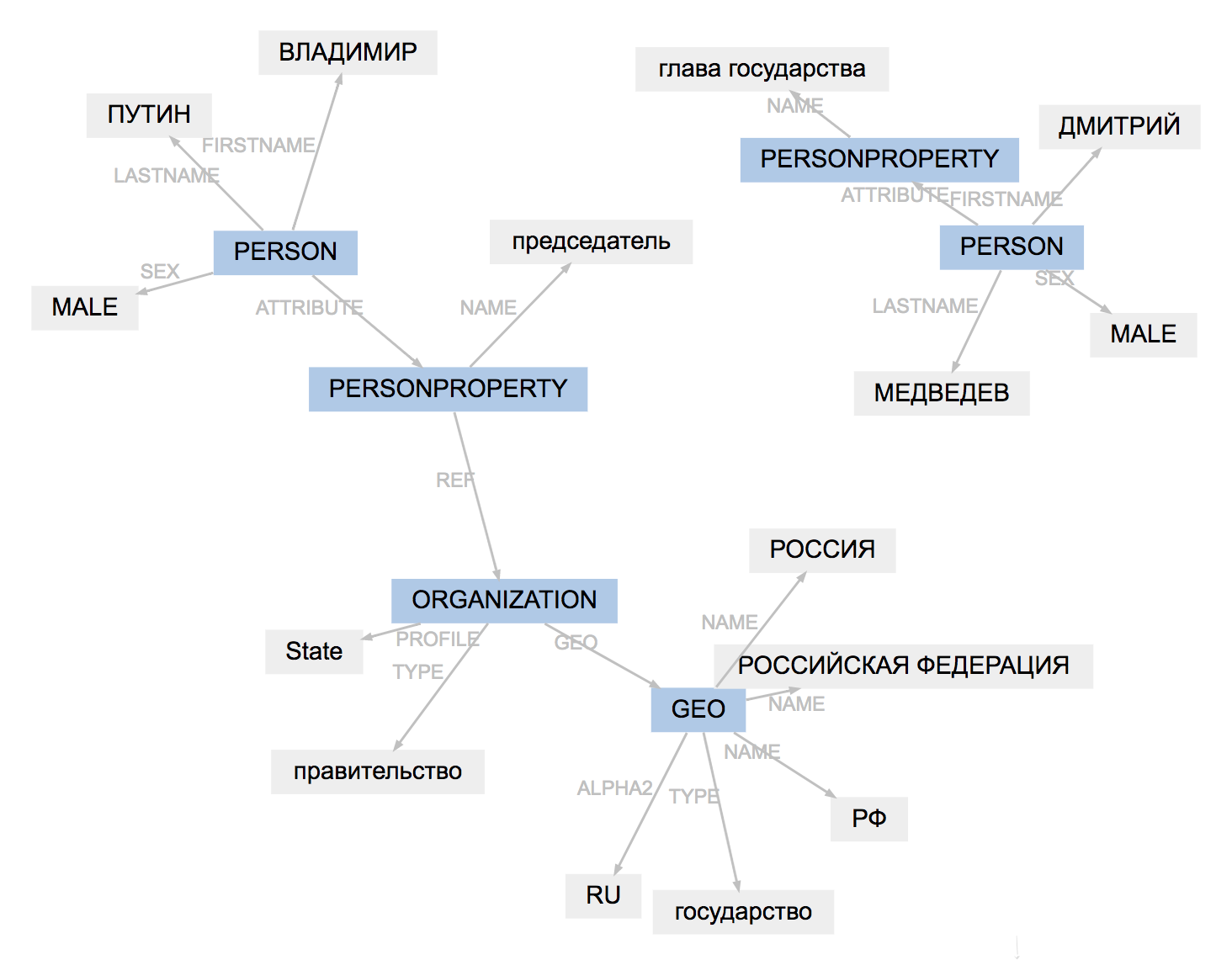
O formato de marcação para todas as ferramentas é um pouco diferente. Naeval carrega resultados, adapta tipos de entidades, simplifica a estrutura de vãos:
(PullEnti):
, 19
ORGANIZATION──────────
GEO─────────
PERSON────────────────
PERSONPROPERTY───────
──────────────── PERSON───────────────────────
PERSONPROPERTY──────────────
ORGANIZATION───
.
────────────────
:
, 19
ORG────── LOC─────────
PER───────────── ORG────────────
.
PER─────────────
O resultado do trabalho do PullEnti é mais difícil de adaptar do que a marcação factRuEval-2016. O algoritmo remove a tag PERSONPROPERTY, divide PERSON, ORGANIZATION e GEO aninhados em PER, LOC, ORG não sobrepostos.
Comparação
Para cada par "modelo, conjunto de dados" Naeval calcula a medida F1 por tokens , publica uma tabela com pontuações de qualidade .
Natasha não é um projeto científico, a praticidade da solução é importante para nós. Naeval mede a hora de início, velocidade de execução, tamanho do modelo e consumo de RAM. Tabela com resultados no repositório .
Preparamos conjuntos de dados, envolvemos 20 sistemas em contêineres Docker e calculamos métricas para 5 outras tarefas de PNL em russo, resultados no repositório Naeval: tokenização , segmentação em frases , embeddings , morfologia e análise de sintaxe .
Yargy- —

O analisador Yargy é um análogo do analisador Yandex Tomita para Python. Instruções de instalação , exemplo de uso , documentação no repositório Yargy. As regras para extrair entidades são descritas usando gramáticas e dicionários livres de contexto . Há dois anos, escrevi sobre Habr um artigo sobre Yargy e a biblioteca Natasha , falando sobre como resolver o problema NER para a língua russa. O projeto foi bem recebido. O analisador Yargy substituiu Tomita em grandes projetos dentro do Sberbank, Interfax e RIA Novosti. Muitos materiais educacionais apareceram. Um grande vídeo de um workshop em Yandex, uma hora e meia sobre o processo de desenvolvimento de gramáticas com exemplos:
A documentação foi atualizada, eu vasculhei a seção introdutória e o livro de referência . Mais importante, o Livro de Receitas apareceu - uma seção com práticas úteis. Ele contém respostas para as perguntas mais frequentes de t.me/natural_language_processing :
- como pular parte do texto ;
- como enviar tokens, não texto ;
- o que fazer se o analisador ficar lento .
O analisador Yargy é uma ferramenta complexa. O livro de receitas descreve os pontos não óbvios que surgem ao trabalhar com grandes conjuntos de regras:
Temos vários serviços grandes em execução no laboratório Yargy. Eu reli o código, padrões coletados no Livro de Receitas que não são descritos publicamente:
- geração de regras ;
- fato de herança (especialmente útil, nenhuma solução na prática pode prescindir dessa técnica).
Depois de ler a documentação, é útil olhar para o repositório com exemplos :
O projeto Natasha também tem um repositório de uso do natasha . É aqui que vai o código dos usuários do analisador Yargy publicado no Github. 80% dos links são projetos educacionais, mas também há exemplos informativos:
- análise do feed da obra do metrô de São Petersburgo ;
- análise de anúncios de arrendamento de habitação em redes sociais ;
- extração de atributos de nomes de pneus de automóveis ;
- análise de vagas do canal de empregos do chat ODS ;
Os casos mais interessantes de uso do analisador Yargy, é claro, não são publicados publicamente no Github. Escreva para o PM se a empresa usar Yargy e, se não se importar, adicione seu logotipo a natasha.github.io .
Ipymarkup - visualização de marcação de entidade nomeada e relacionamentos sintáticos

Ipymarkup é uma biblioteca primitiva necessária para destacar substrings no texto, visualização NER. Instruções de instalação , exemplo de uso no repositório Ipymarkup. A biblioteca é semelhante a displaCy and displaCy ENT , inestimável para depurar gramáticas para o analisador Yargy.
>>> from yargy import Parser
>>> from ipymarkup import show_span_box_markup as show_markup
>>> parser = Parser(...)
>>> text = '...'
>>> matches = parser.findall(text)
>>> spans = [_.span for _ in matches]
>>> show_markup(text, spans)

O projeto Natasha tem uma solução para o problema de análise . Era necessário não apenas destacar as palavras do texto, mas também desenhar setas entre elas. Existem muitas soluções prontas, existe até um artigo científico sobre o assunto .
Claro, nenhum dos existentes se encaixava, e um dia fiquei muito confuso, apliquei toda a famosa magia do CSS e do HTML, adicionei uma nova visualização ao Ipymarkup. Instruções para uso no banco dos réus.
>>> from ipymarkup import show_dep_markup
>>> words = ['', '', '', '', '', '', '-', '', '', '', '', '', '', '', '.']
>>> deps = [(2, 0, 'case'), (2, 1, 'amod'), (10, 2, 'obl'), (2, 3, 'nmod'), (10, 4, 'obj'), (7, 5, 'compound'), (5, 6, 'punct'), (4, 7, 'nmod'), (9, 8, 'case'), (4, 9, 'nmod'), (13, 11, 'case'), (13, 12, 'nummod'), (10, 13, 'nsubj'), (10, 14, 'punct')]
>>> show_dep_markup(words, deps)
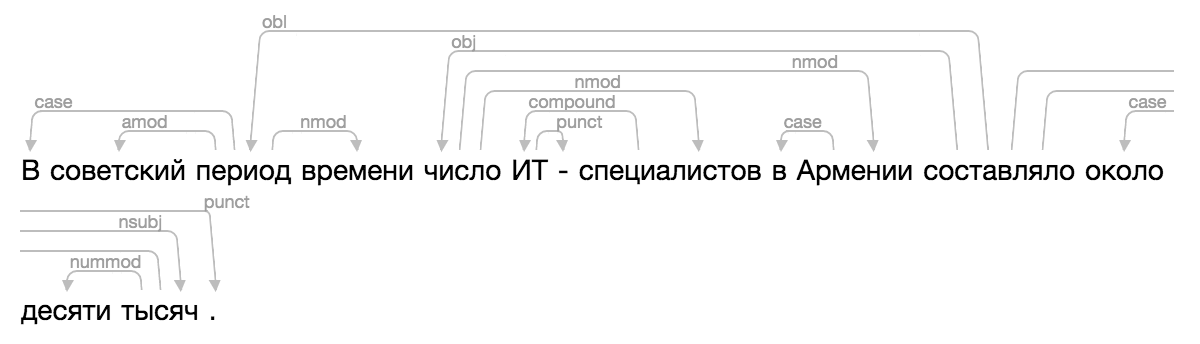
Agora, em Natasha e Nerus , é conveniente ver os resultados da análise.
