Análise
O que é análise? É a coleta e sistematização de informações postadas em sites por meio de programas especiais que automatizam o processo.
A análise é comumente usada para análise de preços e recuperação de conteúdo.
Começar
Para receber dinheiro das casas de apostas, tive que receber prontamente informações sobre as probabilidades de determinados eventos de vários sites. Não vamos entrar na parte matemática.
Como estudei C # em meu sharaga, decidi escrever tudo nele. O pessoal do Stack Overflow aconselhou o uso do Selenium WebDriver. É um driver de navegador (biblioteca de software) que permite desenvolver programas que controlam o comportamento do navegador. É disso que precisamos, pensei.
Instalei a biblioteca e corri para ver os guias na Internet. Depois de um tempo, escrevi um programa que poderia abrir um navegador e seguir alguns links.
Hooray! Apesar de parar, como pressionar os botões, como obter as informações necessárias? XPath nos ajudará aqui.
XPath
Em termos simples, é uma linguagem para consultar elementos de documentos XML e XHTML.
Para este artigo, estarei usando o Google Chrome. No entanto, outros navegadores modernos devem ter, se não o mesmo, uma interface muito semelhante.
Para ver o código da página em que você está, pressione F12.

Para ver onde no código há um elemento da página (texto, imagem, botão), clique na seta no canto superior esquerdo e selecione esse elemento na página. Agora vamos passar para a sintaxe.
Sintaxe padrão para escrever XPath:
// tagname [@ attribute = 'value']
// : Seleciona todos os nós no documento html a partir do nó atual
Tagname : Tag do nó atual.
@ : Seleciona atributos
Atributo : o nome do atributo do nó.
Valor : o valor do atributo.
Pode ser confuso no início, mas depois dos exemplos, tudo deve se encaixar.
Vejamos alguns exemplos simples:
// input [@ type = 'text']
// label [@ id = 'l25']
// input [@ value = '4']
// a [@ href = 'www.walmart. com ']
Considere exemplos mais complexos para o html'i fornecido:
<div class ='contentBlock'>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habr</span>
</a>
<div class = 'textConainer'>
<span class='description'>cool site</span>
"text2"
</div>
</div>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habrhabr</span>
</a>
<div class = 'textConainer'>
<span class='description'>the same site</span>
"text1"
</div>
</div>
</div>XPath = // div [@ class = 'contentBlock'] // div
Os seguintes elementos serão selecionados para este XPath:
<div class = 'listItem'>
<div class = 'textConainer'>
<div class = 'listItem'>
<div class = 'textConainer'>XPath = // div [@ class = 'contentBlock'] / div
<div class = 'listItem'>
<div class = 'listItem'>Observe a diferença entre / (busca do nó raiz) e // (busca nós do nó atual, independentemente de sua localização). Se não estiver claro, consulte os exemplos acima novamente.
// div [@ class = 'contentBlock'] / div [@ class = 'listItem'] / a [@ class = 'link'] / span [@ class = 'name']
Esta solicitação é a mesma com este html :
// div / div / a / span
// span [@ class = 'name']
// a [@ class = 'link'] / span [@ class = 'name']
// a [@ class = ' link 'ehref= 'habr.com'] / span
// span [text () = 'habr' or text () = 'habrhabr']
// div [@ class = 'listItem'] // span [@ class = 'name' ]
// a [contém (href, 'habr')] / span
// span [contém (text (), 'habr')]
Resultado:
<span class='name'>habr</span>
<span class='name'>habrhabr</span>// span [text () = 'habr'] / pai :: a / pai :: div
Igual a
// div / div [@ class = 'listItem'] [1]
Resultado:
<div class = 'listItem'>parent :: - Retorna o pai um nível acima.
Há também um recurso super legal, como following-sibling :: - retorna muitos elementos no mesmo nível após o atual, semelhante ao precedente-sibling :: - retorna muitos elementos no mesmo nível anterior ao atual.
// span [@ class = 'name'] / following-sibiling :: text () [1]
Resultado:
"text1"
"text2"Acho que está mais claro agora. Para consolidar o material, aconselho você a ir a este site e escrever alguns pedidos para encontrar alguns elementos deste html'i.
<div class="item">
<a class="link" data-uid="A8" href="https://www.walmart.com/grocery/?veh=wmt" title="Pickup & delivery">
<span class="g_b">Pickup and delivery</span>
</a>
<a class="link" data-uid="A9" href="https://www.walmart.com/" title="Walmart.com">
<span class="g_b">Walmart.com</span>
</a>
</div>
<div class="item">
<a class="link" data-uid="B8" href="https://www.walmart.com/grocery/?veh=wmt" title="Savings spotlight">
<span class="g_b">Savings spotlight</span>
</a>
<a class="link" data-uid="B9" href="https://www.walmartethics.com/content/walmartethics/it_it.html" title="Walmart.com">
<span class="g_b">Walmart.com(Italian)</span>
"italian virsion"
</a>
</div>Agora que sabemos o que é XPath, vamos voltar a escrever o código. Como os moderadores do Habr não gostam de casas de apostas, eles analisarão os preços do café no Walmart
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
IWebDriver driver = new ChromeDriver(pathToFile);
driver.Navigate().GoToUrl("https://walmart.com");
Thread.Sleep(5000);
IWebElement element = driver.FindElement(By.XPath("//button[@id='header-Header sparkButton']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//button[@data-tl-id='GlobalHeaderDepartmentsMenu-deptButtonFlyout-10']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//div[text()='Coffee']/parent::a"));
driver.Navigate().GoToUrl(element.GetAttribute("href"));
Thread.Sleep(10000);
List<string> names = new List<string>(), prices = new List<string>();
List<IWebElement> listOfElements =driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-title']/div")).ToList();
foreach (IWebElement a in listOfElements)
names.Add(a.Text);
listOfElements = driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-price']/span/span[contains(text(),'$')]")).ToList();
foreach (IWebElement a in listOfElements)
prices.Add(a.Text);
for (int i = 0; i < prices.Count; i++)
Console.WriteLine(names[i] + " " + prices[i]);Thread.Sleep's foram escritos para que a página da web tivesse tempo de carregar.
O programa vai abrir o site da loja Walmart, apertar alguns botões, abrir a seção de café e obter o nome e os preços das mercadorias.
Se a página da web for muito grande e, portanto, os XPaths demorarem ou forem difíceis de escrever, será necessário usar algum outro método.
Solicitações HTTP
Primeiro, vamos ver como o conteúdo aparece no site.

Em palavras simples, o navegador faz uma solicitação ao servidor com uma solicitação para fornecer as informações necessárias, e o servidor, por sua vez, fornece essas informações. Tudo isso é feito por meio de solicitações HTTP.
Para ver as solicitações que seu navegador envia a um site específico, basta abrir este site, pressionar F12 e ir para a guia Rede, depois recarregar a página.

Agora resta encontrar o pedido de que precisamos.
Como fazer isso? - considere todas as solicitações com o tipo de busca (terceira coluna na imagem acima) e olhe para a guia Visualização.

Se não estiver vazio, deve estar no formato XML ou JSON; caso contrário, continue procurando. Em caso afirmativo, veja se as informações de que você precisa estão aqui. Para verificar isso, aconselho a usar algum tipo de JSON Viewer ou XML Viewer (google e abra o primeiro link, copie o texto da aba Response e cole no Viewer). Quando encontrar a solicitação de que precisa, salve seu nome (coluna à esquerda) ou o host da URL (guia Cabeçalhos) em algum lugar, para não pesquisar mais tarde. Por exemplo, se um departamento de café for aberto no site do walmart, uma solicitação será enviada, o legal começando com walmart.com/cp/api/wpa. Lá estarão todas as informações sobre o café à venda.
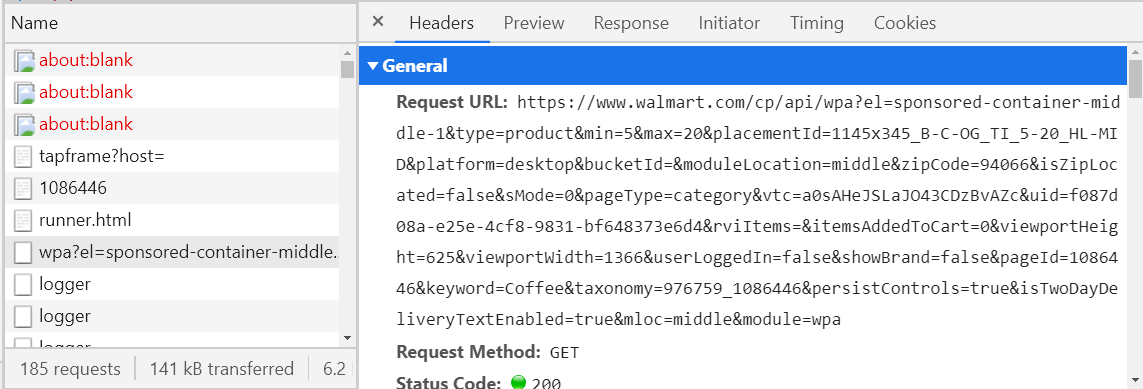
Passado pela metade, agora esse pedido pode ser "simulado" e enviado imediatamente pelo programa, recebendo as informações necessárias em questão de segundos. Resta analisar JSON ou XML, e isso é muito mais fácil do que escrever XPaths. Porém, muitas vezes, a formação de tais solicitações é algo desagradável (veja a URL na imagem acima) e, se você conseguir, em alguns casos receberá essa resposta.
{
"detail": "No authorization token provided",
"status": 401,
"title": "Unauthorized",
"type": "about:blank"
}Agora você aprenderá como evitar problemas ao imitar uma solicitação usando uma alternativa - um servidor proxy.
Servidor proxy
Um servidor proxy é um dispositivo que faz a mediação entre um computador e a Internet.
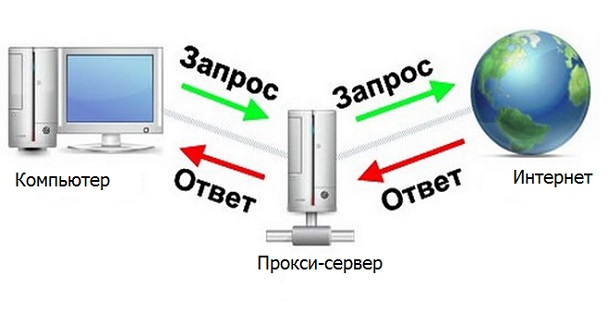
Seria ótimo se nosso programa fosse um servidor proxy, então você pode processar de forma rápida e conveniente as respostas necessárias do servidor. Em seguida, haveria tal cadeia de navegador - programa - Internet (servidor do site que é analisado).
Felizmente para si mesmo, existe uma biblioteca maravilhosa para essas necessidades - Titanium Web Proxy.
Vamos criar a classe PServer
class PServer
{
private static ProxyServer proxyServer;
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")){
Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}
}Agora vamos examinar cada método separadamente.
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}proxyServer.BeforeRepsone + = OnRespone - adicione um método para processar uma resposta do servidor. Ele será chamado automaticamente quando a resposta chegar.
explicitEndPoint - Configuração do servidor proxy,
ExplicitProxyEndPoint (IPAddress ipAddress, porta interna, bool decryptSsl = true)
Endereço IP e porta na qual o servidor proxy está sendo executado.
decryptSsl - se deve descriptografar SSL. Em outras palavras, se decrtyptSsl = true, o servidor proxy processará todas as solicitações e respostas.
explicitEndPoint.BeforeTunnelConnectRequest + = OnBeforeTunnelConnectRequest - adicione um método para processar a solicitação antes de enviá-la ao servidor. Ele também será chamado automaticamente antes que a solicitação seja enviada.
proxyServer.Start () - "iniciando" o servidor proxy, a partir deste momento começa a processar pedidos e respostas.
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}e.DecryptSsl = false - a solicitação e a resposta atuais não serão processadas.
Se não estamos interessados no pedido ou na resposta a ele (por exemplo, uma imagem ou algum tipo de script), então por que descriptografá-lo? Muitos recursos são gastos nisso, e se todas as solicitações e respostas forem decodificadas, o programa funcionará por um longo tempo. Portanto, se a solicitação atual não contém o host da solicitação em que estamos interessados, não há motivo para descriptografá-la.
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")) Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}await e.GetResponseBodyAsString () - retorna uma resposta como uma string.
Para que o WebDriver se conecte ao servidor proxy, você precisa escrever o seguinte:
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
ChromeOptions options = new ChromeOptions();
options.AddArguments("--proxy-server=" + IPAddress.Loopback + ":8000");
IWebDriver driver = new ChromeDriver(pathToFile, options);Agora você pode lidar com as solicitações que deseja.
Conclusão
Com o WebDriver, você pode navegar nas páginas, clicar nos botões e imitar o comportamento de um usuário comum. Com XPaths, você pode extrair as informações de que precisa de páginas da web. Se XPaths não funcionarem, um servidor proxy sempre pode ajudar, o que pode interceptar solicitações entre o navegador e o site.