
Em 2020, o aprendizado de máquina em plataformas móveis não é mais uma inovação revolucionária. A integração de recursos inteligentes em aplicativos se tornou uma prática padrão.
Felizmente, isso não significa que a Apple parou de desenvolver tecnologias inovadoras.
Neste post, vou compartilhar brevemente as novidades sobre a plataforma Core ML e outras tecnologias de inteligência artificial e aprendizado de máquina no ecossistema da Apple.
ML principal
No ano passado, a plataforma Core ML recebeu uma grande atualização. Este ano, as coisas estão muito mais modestas: vários novos tipos de camadas foram adicionados, suporte para modelos de criptografia e a capacidade de postar atualizações de modelo para CloudKit.
Parece que foi tomada a decisão de descartar os números de versão. Após a atualização do ano passado, a plataforma ficou conhecida como Core ML 3, mas agora usa o nome Core ML sem um número de versão. No entanto, o pacote coremltools foi atualizado para a versão 4.
Nota . A especificação interna do mlmodel agora é a versão 5, o que significa que novos modelos aparecerão no Netron com o nome "Core ML v5".
Novos tipos de camada no Core ML
As seguintes camadas foram adicionadas:
Convolution3DLayer, Pooling3DLayer, GlobalPooling3DLayer: — Vision ( Core ML - , ).OneHotLayer: .ClampedReLULayer: ReLU ( ReLU6).- ArgSortLayer: . . , GatherLayer, argsort.
CumSumLayer: .SliceBySizeLayer: Vários tipos de camadas de quebra já estão disponíveis no Core ML. Esta camada permite que você passe um tensor contendo o índice a partir do qual a partição será iniciada. Ao mesmo tempo, o tamanho do setor sempre permanece fixo.
Esses tipos de camadas podem ser usados a partir da versão 5, ou seja, no iOS 14 e macOS 11.0 ou posterior.
Outro aprimoramento útil: operações quantizadas de 8 bits para as seguintes camadas:
InnerProductLayerBatchedMatMulLayer
Nas versões anteriores do Core ML, os pesos eram quantizados, mas depois de carregar o modelo, eles eram convertidos de volta ao formato de ponto flutuante. O novo recurso
int8DynamicQuantizepermite que os pesos sejam armazenados como valores inteiros de 8 bits e que também realizem cálculos reais usando números inteiros.
Cálculos usando INT8 podem ser muito mais rápidos do que operações de ponto flutuante. Isso oferece algumas vantagens para a CPU, mas é incerto se o desempenho das GPUs melhorará, já que as operações de ponto flutuante são muito eficientes para elas. Talvez, em uma atualização futura do Neural Engine, o suporte integrado para operações INT8 seja implementado (afinal, a Apple adquiriu recentemente o Xnor.ai ...).
Em termos de CPUs, o Core ML agora também pode usar ponto flutuante de 16 bits em vez de 32 bits (no A11 Bionic e superior). Como discutimos no vídeo Explore a computação numérica em Swift , Float16 agora é o tipo de dados de primeira classe do Swift. Com suporte nativo para operações de ponto flutuante de 16 bits, o Core ML pode dobrar a velocidade!
Nota . No Core ML, o tipo de dados Float16 já era usado nas GPUs e no Neural Engine, então as diferenças só serão perceptíveis quando usadas na CPU.
Outras (pequenas) alterações:
UpsampleLayer. BILINEAR ( align-corners). , , .-
ReorganizeDataLayerParamsPIXEL_SHUFFLE. , . , . -
SliceStaticLayerSliceDynamicLayersqueezeMasks, . -
TileLayer, .
Parece não haver nenhuma mudança com relação ao aprendizado local em dispositivos: ainda assim, apenas as camadas totalmente conectadas e convolucionais são suportadas. A classe
MLParameterKeyem CoreML.framework agora contém um parâmetro de configuração para o otimizador RMSprop , no entanto, esse aprimoramento ainda não está incluído em NeuralNetwork.proto . Talvez seja adicionado no próximo beta.
Os seguintes novos tipos de modelos foram adicionados :
VisionFeaturePrint.Object- Unidade de extração de recursos otimizada para reconhecimento de objetos.
SerializedModel... Não sei exatamente para que serve. Esta é uma definição "privada" e "sujeita a alterações sem aviso prévio ou responsabilidade". Talvez seja assim que a Apple incorpora formatos de modelos proprietários no mlmodel?
Publicar atualizações de modelo para CloudKit

Este novo componente do Core ML permite que você atualize modelos separadamente do aplicativo.
Em vez de atualizar o aplicativo inteiro, você pode simplesmente carregar as instâncias implementadas com a nova versão do mlmodel. Para ser honesto, essa ideia não é nova e alguns fornecedores terceirizados já desenvolveram SDKs correspondentes. Além disso, não é difícil criar você mesmo esse pacote. A vantagem da solução da Apple neste caso é a capacidade de hospedar modelos na Apple Cloud .
Como um aplicativo pode ter vários modelos, o novo conceito de coleção de modelos permite combinar modelos em um pacote para que o aplicativo possa atualizá-los todos ao mesmo tempo. Essas coleções podem ser criadas usando o painel CloudKit.
O aplicativo usa a classe para baixar e gerenciar as atualizações do modelo
MLModelCollection. O vídeo WWDC mostra os trechos de código para realizar essa tarefa.
Para preparar um modelo de ML principal para implantação, o botão Criar arquivo de modelo agora está disponível no Xcode. Clicar nele grava no arquivo .mlarchive . Esta versão do modelo pode ser enviada ao painel do CloudKit e então adicionada à coleção de modelos (mlarchive parece um arquivo ZIP normal com o conteúdo da pasta mlmodelc adicionado).
É muito conveniente que você possa implantar diferentes coleções de modelos para diferentes usuários. Por exemplo, a câmera do iPhone é diferente da câmera do iPad, então você pode precisar criar duas versões do modelo e enviar uma para usuários do iPhone e outra para usuários do iPad.
Você pode definir regras de personalização para diferentes classes de dispositivos (iPhone, iPad, TV, Watch), diferentes sistemas operacionais e suas versões, códigos de região, códigos de idioma e versões de aplicativos.
Parece não haver nenhum mecanismo para dividir os usuários em grupos com base em outros critérios, como teste A / B para atualizações de modelo ou ajuste para tipos de dispositivos específicos - iPhone X ou anterior. No entanto, isso ainda pode ser feito manualmente criando coleções com nomes diferentes e, em seguida, solicitando explicitamente
MLModelCollectionfornecendo a coleção apropriada pelo nome especificado no tempo de execução.
A implantação de uma nova versão de um modelo nem sempre é rápida . Em algum ponto, o aplicativo detecta um novo modelo disponível e faz o download e o coloca automaticamente no ambiente de teste do aplicativo. No entanto, você não tem a capacidade de determinar onde e como isso acontece: o Core ML pode fazer download em segundo plano, por exemplo, quando você não está usando o telefone.
Por isso, é recomendado em todos os casos adicionar um modelo integrado ao aplicativo como um substituto - por exemplo, um modelo genérico que suporte iPhone e iPad.
Embora esta solução útil permita que os usuários não se preocupem com modelos de auto-hospedagem, lembre-se de que seu aplicativo agora está usando CloudKit. Pelo que entendi, as coleções de modelos contam para a cota total de armazenamento e as cargas de modelos contam para as cotas de tráfego de rede.
Veja também:
- Implementando Modelos e Protegendo o Core ML (Vídeo WWDC)
- Criação e implantação de uma coleção de modelos
- Recuperando coleções de modelos expandidos
Nota . O novo recurso de atualização usando CloudKit é, infelizmente, muito difícil de combinar com a personalização de modelo local. Não há maneiras fáceis de transferir o conhecimento adquirido por um modelo personalizado para um novo modelo ou combiná-los de alguma forma.
Criptografando o modelo
Até agora, qualquer invasor poderia facilmente roubar seu modelo Core ML e integrá-lo em seu próprio aplicativo. A partir do iOS 14 / macOS 11.0, o Core ML oferece suporte à criptografia e descriptografia automáticas de modelos, limitando o acesso de invasores às pastas mlmodelc. A criptografia pode ser usada em conjunto com o novo recurso de implantação via CloudKit ou separadamente.

O Xcode criptografa os modelos compilados ( mlmodelc ), não o mlmodel original. O modelo é sempre criptografado no dispositivo do usuário. E apenas quando o aplicativo cria uma instância do modelo, o Core ML a descriptografa automaticamente. A versão descriptografada do modelo existe apenas na memória e não é armazenada como um arquivo.
Primeiro, agora você precisa de uma chave de criptografia. A boa notícia é que você não precisa gerenciar essa chave sozinho! O botão Criar chave de criptografia agora está disponível no Core ML Xcode Model Viewer(Crie uma chave de criptografia). Ao clicar neste botão, o Xcode gera uma nova chave de criptografia e a associa à sua conta da equipe de desenvolvimento da Apple. Você não tem que lidar com solicitações de assinatura de certificado e chaves de acesso físico.
Este procedimento cria um novo arquivo .mlmodelkey . A chave é armazenada em servidores Apple, no entanto, você também obtém uma cópia local para criptografar modelos no Xcode. Você não precisa incorporar essa chave de criptografia ao aplicativo, especialmente porque não deveria!
Para criptografar um modelo Core ML, você pode adicionar um sinalizador de compilador
--encrypt YourModel.mlmodelkeypara esse modelo. E se você planeja implantar o modelo usando CloudKit, você precisará especificar a chave de criptografia ao criar o arquivo do modelo.
Para descriptografar o modelo depois que o aplicativo o instanciou, o Core ML precisará recuperar a chave de criptografia dos servidores da Apple na rede . Isso, é claro, requer uma conexão de rede. O Core ML só executa esse procedimento na primeira vez que você usa o modelo.
Se não houver conexão de rede e a chave de criptografia ainda não tiver sido carregada, o aplicativo não será capaz de instanciar o modelo Core ML. Por este motivo, é recomendável usar a nova função
YourModel.load(). Ele contém um manipulador final que permite responder aos erros de download. Por exemplo, o código de erro modelKeyFetchdiz que o Core ML não foi capaz de baixar a chave de criptografia dos servidores Apple.
Esse é um recurso muito útil se você estiver preocupado com o fato de alguém roubar sua tecnologia patenteada. Além disso, é fácil de integrar ao seu aplicativo.
Veja também:
- Implementando Modelos e Protegendo o Core ML (Vídeo WWDC)
- Gerando uma chave de criptografia de modelo
- Criptografar o modelo no aplicativo
Nota . De acordo com as informações fornecidas nesta postagem do fórum de desenvolvedores , os modelos criptografados não oferecem suporte à personalização local. Parece razoável.
CoreML.framework
A API do iOS para trabalhar com modelos do Core ML não mudou muito. No entanto, gostaria de observar alguns pontos interessantes.
A única classe nova aqui é
MLModelCollectionaquela que se destina a ser implantada com o CloudKit.
Como você já sabe, ao adicionar um arquivo mlmodel ao seu projeto, o Xcode gera automaticamente um arquivo de origem Swift ou Objective-C que contém classes para facilitar o trabalho com o modelo. Você pode notar algumas mudanças nessas classes geradas:
-
init(). ,let model = YourModel().YourModel(configuration:)YourModel.load(), (, ). - ,
CVPixelBufferYourModelInput,CGImageURL-, PNG- JPG-, . ,cropAndScalecropRect. , , .
Há um novo aviso na documentação do MLModel :
Use uma instância do MLModel em apenas um thread ou uma fila de envio. Para fazer isso, você pode serializar chamadas de método para o modelo ou criar uma instância separada do modelo para cada thread e fila de despacho.
Oh, me desculpe. Pareceu-me que dentro do MLModel uma fila sequencial era usada para processar solicitações, mas eu posso estar errado - ou algo mudou. Em qualquer caso, é melhor seguir esta recomendação no futuro.
O
MLMultiArraynovo inicializador implementadoinit(concatenating:axis:dataType:), que cria um novo multi-array combinando vários multi-arrays existentes. Eles devem ter todos a mesma forma, exceto para o eixo especificado ao longo do qual a união é realizada. Parece que esse recurso foi adicionado especificamente para fazer previsões a partir de dados de vídeo, como nos novos modelos de classificador de ação em Create ML. Convenientemente!
Nota . A enumeração
MLMultiArrayDataTypeagora contém propriedades estáticas .floate .float64. Não sei exatamente para que servem, porque essa enumeração já tem propriedades .float32e .double. Bug beta?
Visualizador de modelo Xcode
O Xcode agora exibe muito mais informações sobre os modelos, como rótulos de classe e quaisquer metadados personalizados adicionados. Ele também exibe estatísticas sobre os tipos de camadas no modelo.
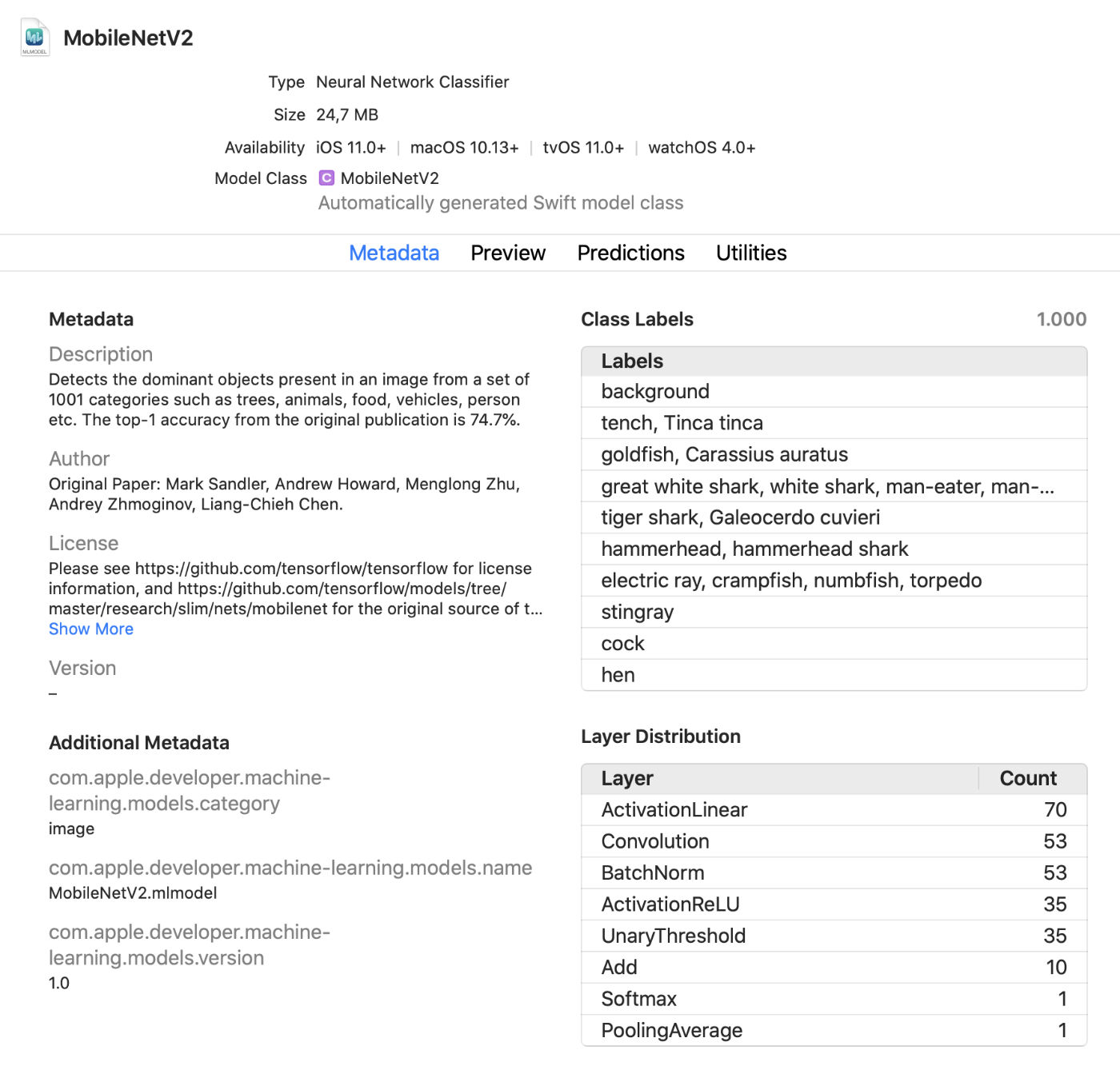
Este é um prático visualizador ao vivo que permite fazer alterações no modelo em modo de teste sem executar o aplicativo. Você pode arrastar imagens, vídeos ou texto para esta janela de visualização e ver as previsões do modelo imediatamente. Ótima atualização!
Além disso, agora você pode usar os modelos Core ML em um ambiente interativo . O Xcode gera automaticamente uma classe para isso, que você pode usar normalmente. Esta é outra maneira de testar modelos interativamente antes de adicioná-los ao aplicativo.
coremltools 4
Criar seus próprios modelos para projetos simples é conveniente com Create ML, mas o TensorFlow e o PyTorch são muito mais usados para treinamento. Para usar esse modelo no Core ML, você deve primeiro convertê-lo para o formato mlmodel. É para isso que a caixa de ferramentas coremltools é usada.
Boas notícias: a documentação é muito melhor . Recomendo que você se familiarize com ele. Esperançosamente, o manual do usuário será atualizado regularmente porque a documentação nem sempre foi atualizada no passado.
Nota . Infelizmente, os blocos de notas Jupyter de amostra sumiram. Eles agora estão incluídos no manual do usuário, mas não como notebooks.
A maneira de transformar modelos mudou drasticamente... Os conversores de rede neural usados anteriormente estão desatualizados e foram substituídos por versões mais novas e flexíveis.
Existem três tipos de conversores disponíveis hoje:
- Conversores modernos para TensorFlow (1.xe 2.x), tf.keras e PyTorch. Todos esses conversores são baseados nas mesmas tecnologias e usam a chamada linguagem de modelo intermediário (MIL). Você não precisa mais usar tfcoreml ou onnx-coreml para esses modelos.
- Conversores antigos para redes neurais Keras 1.x, Caffe e ONNX. Um conversor especializado é fornecido para cada um deles. Seu desenvolvimento foi descontinuado e apenas correções estão planejadas para serem lançadas no futuro. Não é mais recomendado usar o ONNX para converter modelos PyTorch.
- Conversores para modelos de rede não neural, como scikit-learn e XGBoost.
Uma nova API de conversão uniforme é usada para transformar os modelos TensorFlow 1.x, 2.x, PyTorch ou tf.keras . É aplicado da seguinte forma:
import coremltools as ct
class_labels = [ "cat", "dog" ]
image_input = ct.ImageType(shape=(1, 224, 224, 3),
bias=[-1, -1, -1],
scale=2/255.)
model = ct.convert(
keras_model,
inputs=[ image_input ],
classifier_config=ct.ClassifierConfig(class_labels)
)
model.save("YourModel.mlmodel")
A função
ct.convert()verifica o arquivo de modelo para determinar seu formato e, a seguir, seleciona automaticamente o conversor apropriado. Os argumentos são ligeiramente diferentes daqueles usados antes: argumentos de pré-processamento são passados usando um objeto ImageType, rótulos de classificador são passados usando um objeto ClassifierConfige assim por diante.
A nova API de transformação converte o modelo em uma representação intermediária - a assim chamada. MIL . Os conversores estão disponíveis atualmente para converter TensorFlow 1.x em MIL, TensorFlow 2.x em MIL (incluindo tf.keras) e PyTorch em MIL. Se a nova plataforma de aprendizado profundo ganhar popularidade, ela receberá seu próprio conversor para MIL.

Depois de converter o modelo para o formato MIL, ele pode ser otimizado de acordo com regras gerais, por exemplo, remover operações desnecessárias ou combinar várias camadas diferentes. O modelo é então convertido do formato MIL para o formato mlmodel.
Eu não estudei tudo isso em detalhes ainda, mas a nova abordagem me dá esperança de que o coremtools 4 será capaz de criar arquivos mlmodel mais eficientes do que antes - especialmente para gráficos TF 2.x.
No MIL, gosto especialmente da capacidade do conversor de lidar com camadas que ele ainda não analisou . Se o seu modelo contém uma camada que não é diretamente suportada no Core ML, você pode precisar subdividi-la em operações MIL mais simples, como multiplicação de matrizes ou outras operações aritméticas.
Depois disso, o conversor poderá utilizar as chamadas "operações compostas" para todas as camadas deste tipo. Isso é muito mais fácil do que adicionar operações sem suporte usando camadas personalizadas, embora seja possível. A documentação fornece um bom exemplo do uso de tais operações compostas.
Veja também:
Outras plataformas Apple usando aprendizado de máquina
Várias outras estruturas de alto nível nos SDKs do iOS e macOS também são usadas para tarefas de aprendizado de máquina. Vamos ver o que há de novo nessa área.
Visão
A plataforma de visão por computador Vision recebeu uma série de novas funções.
A plataforma Vision já usou modelos para reconhecer rostos, características distintivas e corpos humanos. A nova versão adiciona os seguintes recursos:
Reconhecimento da posição da mão (
VNDetectHumanHandPoseRequest)
Reconhecimento da pose de várias pessoas (
VNDetectHumanBodyPoseRequest)
É ótimo que a Apple tenha incluído funções de reconhecimento de pose no sistema operacional. Vários modelos de código aberto oferecem suporte a esse recurso, mas não são nem de longe tão eficientes ou rápidos. As soluções comerciais são caras. Ferramentas de reconhecimento de pose de alta qualidade agora estão disponíveis gratuitamente!
Agora, em contraste com a visualização de imagens estáticas, mais atenção é dada areconhecimento de objetos na gravação de vídeo offline e em tempo real. Por conveniência, você pode usar objetos
CMSampleBufferdiretamente da câmera usando manipuladores de solicitação.
Além disso,
VNImageBasedRequestuma subclasse foi adicionada à classe VNStatefulRequest, que é responsável pela confirmação imediata da descoberta do objeto desejado. Ao contrário da classe padrão, VNImageBasedRequestele reutiliza uma consulta com estado que abrange vários quadros. Essa solicitação executa a análise a cada N frames do vídeo.
Após o objeto de busca ser encontrado, o manipulador final é chamado, contendo o objeto
VNObservation, que agora possui uma propriedade timeRangeque indica o tempo de início e término da observação no vídeo.
A classe
VNStatefulRequestnão é usada diretamente . É uma classe base abstrata e atualmente é subclassificada apenas por consulta VNDetectTrajectoriesRequestpara fins de reconhecimento de caminho. Isso permite o reconhecimento de formas que se movem ao longo de um caminho parabólico, como ao jogar ou chutar uma bola (essa parece ser a única tarefa embutida relacionada ao vídeo no momento).
Para análise de vídeo offline, você pode usar
VNVideoProcessor.Este objeto adiciona um URL a um vídeo local e faz uma ou mais solicitações do Vision a cada N quadros ou N segundos.
Uma das técnicas tradicionais de visão computacional mais importantes para analisar gravações de vídeo é o fluxo óptico... Uma consulta agora está disponível no Vision
VNGenerateOpticalFlowRequestque calcula a direção em que cada pixel se move de um quadro para outro (fluxo óptico denso). Como resultado, um objeto é criado VNPixelBufferObservationcontendo uma nova imagem, em que cada pixel corresponde a dois valores de ponto flutuante de 32 ou 16 bits.
Além disso, uma nova consulta foi adicionada
VNDetectContoursRequestpara reconhecer os contornos de objetos em uma imagem. Esses caminhos são retornados como caminhos vetoriais. VNGeometryUtilsfornece ferramentas auxiliares para processamento posterior de contornos reconhecidos, por exemplo, simplificando-os para formas geométricas básicas.
E a última inovação no Vision é uma nova versão do extrator de recursos integrado VisionFeaturePrint. IOS já implementou o bloqueioVisionFeaturePrint.Scene , que é especialmente útil para criar classificadores de imagem. Além disso, um novo modelo VisionFeaturePrint.Object agora está disponível, que é otimizado para destacar recursos usados no reconhecimento de objetos.
Este modelo suporta imagens de entrada 299x299 e retorna duas matrizes múltiplas da forma (288, 35, 35) e (768, 17, 17), respectivamente. Esta ainda não é uma estrutura de limitação clara, mas apenas recursos "brutos". Para um reconhecimento de objeto completo, você precisa adicionar uma lógica que converta esses recursos em caixas delimitadoras e rótulos de classe. Criar ML realiza essa tarefa se você estiver treinando uma ferramenta de reconhecimento de objetos usando a transferência de treinamento.
Veja também:
- Explore APIs de visão de computador (vídeo WWDC)
- Detectar postura do corpo e da mão com visão (vídeo WWDC)
- Explore o aplicativo Action & Vision (vídeo WWDC)
Processamento de linguagem natural
Para tarefas de processamento de linguagem natural, você pode usar a plataforma de linguagem natural. Ela usa ativamente os modelos treinados em Create ML.
Muito poucos recursos novos foram adicionados este ano:
NLTaggereNLModelagora encontre várias tags e preveja sua validade. Anteriormente, a validade de uma etiqueta era determinada apenas pelo número de pontos marcados.- Inserindo frases. A inserção de palavras poderia ter sido usada antes, mas agora
NLEmbeddingsuporta frases inteiras.
Ao inserir frases, uma rede neural embutida é usada para codificar a frase inteira em um vetor de 512 dimensões. Isso permite que você obtenha o contexto no qual as palavras são usadas em uma frase (a inserção de palavras não é compatível com esse recurso).
Veja também:
Análise de fala e sons
Não houve mudanças nesta área.
Treinamento de modelo
Modelos de trem usando APIs da Apple foram disponibilizados pela primeira vez no iOS 11.3 e na plataforma Metal Performance Shaders. Nos últimos anos, muitas novas APIs de treinamento foram adicionadas e este ano não foi exceção: de acordo com meus cálculos, agora temos até 7 APIs diferentes para treinar redes neurais em plataformas iOS e macOS!
Atualmente, as seguintes APIs da Apple podem ser usadas para treinar modelos de aprendizado de máquina - em particular redes neurais - em iOS e macOS:
- Aprendizagem local no Core ML.
- Criar ML : essa interface pode ser conhecida por você como um aplicativo, mas também é uma plataforma disponível no macOS.
- Metal Performance Shaders : API para inferência e treinamento em uma GPU. Na verdade, são duas APIs diferentes, bastante difíceis de usar se você for novo no Metal. Além disso, uma nova estrutura Metal Performance Shaders Graph também está disponível e parece substituir essas APIs legadas.
- BNNS : Parte da plataforma Accelerate. Anteriormente, apenas as rotinas de inferência estavam disponíveis no BNNS, mas o suporte de treinamento também foi adicionado este ano.
- Computação de ML : uma plataforma fundamentalmente nova que parece muito promissora.
- Turi Create : Esta é na verdade a versão Python do Create ML. Recentemente, seus criadores se esqueceram disso, embora o suporte à plataforma ainda não tenha sido encerrado.
Vamos dar uma olhada nas inovações nessas APIs.
Aprendizagem local no Core ML
Na verdade, não há grandes mudanças aqui. O suporte de atualização poderia ter sido adicionado para vários outros tipos de camada, mas eu não vi nenhuma documentação sobre isso ainda.
Uma das inovações importantes esperadas em uma versão beta futura é o otimizador RMSprop. Não está incluído na versão beta atual.
Criar ML
A plataforma Create ML estava inicialmente disponível apenas para macOS. Ele pode ser executado no Swift Playground para que possa ser usado para treinar modelos com apenas algumas linhas de código.

No ano passado, Create ML foi transformado em um aplicativo bastante limitado e estou satisfeito em ver melhorias significativas neste ano. Dito isso, o Create ML continua sendo uma plataforma que ainda pode ser usada desde o code-behind. Na verdade, o aplicativo é apenas uma interface gráfica conveniente para trabalhar com a plataforma.
Na versão anterior do Create ML, você poderia treinar um modelo apenas uma vez. Para mudar algo, você tinha que treinar novamente do zero, e isso demorava muito.
A nova versão do Xcode 12 permitepause o treinamento e retome mais tarde , salve os pontos de verificação do modelo (instantâneos) e visualize os resultados preliminares do treinamento do modelo. Agora temos muito mais ferramentas à nossa disposição para gerenciar o processo de aprendizagem. Com esta atualização, Create ML é realmente útil!
Novas APIs também estão disponíveis na plataforma CreateML.framework para configurar sessões de treinamento, lidar com pontos de interrupção do modelo e muito mais. Suponho que a maioria das pessoas usará apenas o aplicativo Create ML, mas ainda é bom ver que esse recurso agora está disponível na plataforma.
Novos recursos do Create ML (na plataforma e no aplicativo):
- Transferindo um estilo para fotos e vídeos
- Classificação das ações humanas em vídeos
Vamos examinar mais de perto o novo modelo de classificação de ação. Ele usa o modelo de reconhecimento de postura disponível na plataforma Vision. Um classificador de ação é uma rede neural que assume a forma (
window_size, 3, 18) como entrada , com o primeiro valor representando a duração do fragmento de vídeo, indicado no número de quadros (geralmente fragmentos de cerca de 2 segundos são usados) e (3, 18) representam os pontos principais da pose.
Em vez de repetir camadas, a rede neural usa convoluções unidimensionais. Esta é provavelmente uma variação de uma Rede Convolucional de Gráfico de Espaço Tempo (STGCN) - um tipo de modelo projetado especificamente para previsão de séries temporais. Esses detalhes não devem preocupar você ao usar esses modelos em um aplicativo. No entanto, sempre quero saber como tudo funciona.
Quanto aos modelos de reconhecimento de objetos, você pode escolher treinar toda a rede com base no TinyYOLOv2 ou usar o novo modo de transferência de treinamento, que usa a nova unidade de extração de recursos VisionFeaturePrint.Object . O resto do modelo ainda se parece com YOLO e SSD, no entanto, graças à transferência, seu treinamento será muito mais rápido do que treinar todo o modelo baseado em YOLO.
Veja também:
- Construir um classificador de ação com Create ML (vídeo WWDC)
- Construir modelos de transferência de estilo de imagem e vídeo em Create ML (vídeo WWDC)
- Control training in Create ML with Swift ( Create ML Swift) ( WWDC)
Metal Performance Shaders
Metal Performance Shaders (MPS) é uma plataforma baseada nos núcleos de computação de desempenho do Metal, que é usada principalmente para processamento de imagens, mas desde 2016 também oferece suporte para redes neurais. Já escrevi muito sobre isso.
Hoje, a maioria dos usuários escolherá Core ML em vez de MPS. Obviamente, o Core ML ainda usa o poder do MPS ao executar modelos na GPU. No entanto, o MPS também pode ser usado diretamente, especialmente se o usuário planeja realizar o treinamento por conta própria (aliás, uma nova plataforma ML Compute está agora disponível, que é recomendado para uso em vez do MPS. Sua descrição é fornecida abaixo).
Existem alguns novos recursos no MPSCNN este ano, mas várias melhorias foram feitas para os existentes.
Adicionadas novas classes
MPSImageCannypara reconhecimento de borda e MPSImageEDLines para reconhecimento de segmento de linha. Eles são muito úteis ao trabalhar com problemas de visão do computador.
Uma série de outras mudanças também são dignas de nota:
- Uma
MPSCNNConvolutionDataSourcenova propriedade foi adicionadakernelWeightsDataTypeque permite que você use um tipo de dados diferente para os coeficientes de ponderação do que aquele usado para convolução. Curiosamente, os pesos não podem ser do tipo de dados INT8, embora o Core ML permita que esse tipo de dados seja usado para camadas individuais. - Se
kernelWeightsDataTyperetornar.float32, as camadas convolucionais e totalmente conectadas são executadas usando ponto flutuante de 32 bits em vez de 16 bits. Anteriormente, apenas 16 bits eram suportados. - As funções de perda agora podem usar um parâmetro
reduceAcrossBatch.
Você ainda pode usar o MPSCNN se o Metal não te assustar. No entanto, agora está disponível uma nova plataforma que simplifica muito a criação e execução de tais gráficos: Gráfico MPS.
Nota . O vídeo WWDC afirma que MPSNDArray é uma nova API, mas na verdade foi lançado no ano passado. É uma estrutura de dados muito mais flexível do que MPSImage porque nem todos os tensores em seu modelo podem ser imagens.
Novo: Gráfico de Shaders de desempenho de metal

Uma API está disponível há muito tempo no MPS
MPSNNGraph, mas esses gráficos, na verdade, descrevem apenas redes neurais. No entanto, nem todos os gráficos precisam ser redes neurais e, neste caso, a plataforma Metal Performance Shaders Graph será útil.
Esta nova plataforma pode ser usada para criar gráficos de computação GPU de propósito geral. A plataforma MPS Graph não depende de Metal Performance Shaders, embora tenha sido construída com base nisso.
Na versão anterior da API obsoleta
MPSNNGraph, era impossível adicionar operações personalizadas ao gráfico. A nova plataforma é muito mais flexível nesse aspecto. No entanto, você não pode adicionar seus próprios núcleos de metal. Você precisará expressar todos os cálculos usando as primitivas existentes.
Felizmente o compilador
MPSGraphsuporta a integração de tais primitivos em um único núcleo computacional, o que garante a operação mais eficiente no processador gráfico. No entanto, este esquema não funcionará se for impossível ou difícil usar as primitivas fornecidas para alguma operação. Eu simplesmente não entendo por que a Apple, ao criar uma nova API como esta, nunca permite funções personalizadas completas! Mas nada pode ser feito.
A nova plataforma
MPSGraphé uma estrutura bastante simples e lógica que descreve a relação entre as operações em um conjunto MPSGraphOperationsusando tensoresMPSGraphTensorscontendo os resultados das operações. Além disso, você pode definir dependências de controle para forçar nós individuais a iniciar antes de outros. Depois de configurar o gráfico, ele deve ser executado ou transferido para o buffer de comando, e então aguardar o resultado.
MPSGraphfornece um conjunto completo de métodos de instância que permitem adicionar qualquer operação matemática ou de rede neural ao gráfico.
Além disso, o treinamento é suportado, o que envolve adicionar uma operação de processamento de perda ao gráfico e, em seguida, executar as operações de gradiente para todas as camadas na ordem inversa - como na anterior
MPSNNGraph. Por conveniência, um modo de diferenciação automática também está disponível, dentro do qual ele MPSGraphexecuta automaticamente operações de gradiente para o gráfico. Isso economiza muito esforço.
Adoro saber que agora existe uma API nova, simples e direta para a criação de tais gráficos computacionais. É muito mais fácil de usar do que as versões anteriores. E você não precisa ser um especialista em Metal para trabalhar com isso. A propósito, é muito parecido com os gráficos do TensorFlow 1.x, mas tem uma grande vantagem em termos de otimização, que permite minimizar custos. E ainda, não há capacidade suficiente para adicionar núcleos computacionais arbitrários ao gráfico.
Veja também:
- Crie modelos de ML personalizados com o Metal Performance Shaders Graph (vídeo WWDC)
- Adicionando funções personalizadas ao gráfico de sombreador
BNNS (subrotinas de rede neural básicas)
Se o Core ML estiver rodando em uma CPU, então ele usa rotinas BNSS que fazem parte da plataforma Accelerate. Já escrevi sobre o BNNS neste artigo . A maioria desses recursos do BNNS foi agora amplamente descontinuada e substituída por um novo conjunto de recursos.
Anteriormente, apenas camadas totalmente conectadas, funções de dobramento, agrupamento e ativação eram suportadas. Esta atualização adiciona suporte ao BNNS para matrizes n-dimensionais, virtualmente todos os tipos de camadas do Core ML e versões de compatibilidade com versões anteriores de tais camadas de treinamento (incluindo camadas que atualmente não suportam o treinamento do Core ML, como LSTM).
Também é importante notar a presença de uma camada de atenção múltipla.... Essas camadas são frequentemente usadas em modelos de Transformer como o BERT. Outro ponto interessante são as convoluções de tensores.
Você pode não estar usando esses recursos BNNS - da mesma forma que não usaria o MPS para treinar em uma GPU. Em vez disso, agora está disponível uma plataforma de computação de ML de nível superior que abstrai o processador usado. ML Compute é baseado em BNNS e MPS, mas os desenvolvedores não precisam se preocupar com essas pequenas coisas.
Veja também: Documentação da plataforma BNNS
Novo: computação de ML
O ML Compute é uma plataforma fundamentalmente nova para treinar redes neurais em uma CPU ou GPU (mas aparentemente não em processadores Neural Engine). Em um Mac Pro com várias GPUs, esta plataforma pode usar todas automaticamente para treinar.
Fiquei um pouco surpreso com a presença de outra plataforma de aprendizagem, mas essa plataforma realmente simplifica tudo, pois permite ocultar componentes de baixo nível do BNNS e MPS, e no futuro, talvez do Motor Neural.
O melhor de tudo é que o ML Compute também é compatível com os sistemas iOS, não apenas com o Mac. É engraçado que o Core ML não seja mencionado em lugar nenhum. O ML Compute parecia ter sido criado completamente separadamente. Esta estrutura não pode ser usada para criar modelos do Core ML.
Por experiência própria, posso dizer que a tarefa do ML Compute é, antes de tudo, acelerar o trabalho de ferramentas de aprendizado profundo de terceiros . Você não precisa escrever nenhum código para trabalhar diretamente com o ML Compute. Parece que é suposto (ou os desenvolvedores esperam que sim) que ferramentas como o TensorFlow começarão a usar essa plataforma para permitir o suporte de aprendizagem acelerada por hardware no Mac.
Praticamente o mesmo conjunto de camadas disponível no BNNS. As camadas devem ser adicionadas ao gráfico e executadas (aqui, o modo "ocupado esperando" não é usado).
Para criar um gráfico, você deve primeiro instanciar o objeto
MLCGraphe adicionar nós a ele. Um nó é uma subclasse MLCLayer. Os nós são conectados uns aos outros por meio de objetosMLCTensorque contêm a saída de outras camadas.
Curiosamente, as operações de divisão, concatenação, reformatação e transferência não são tipos separados de camadas, mas operações diretamente no gráfico.
Excelente recurso de depuração -
summarizedDOTDescription. Ele retorna uma descrição DOT para um gráfico, a partir da qual você pode criar um gráfico usando, por exemplo, Graphviz ou OmniGraffle (a propósito, Keras gera gráficos de modelo dessa forma).
O ML Compute distingue entre gráficos de inferência e gráficos de aprendizagem. O último contém nós adicionais, por exemplo, uma camada de perda e um otimizador.
Parece que não há maneiras de criar camadas customizadas aqui, então você só precisa conviver com os tipos disponíveis no ML Compute.
É estranho que não tenha havido sessões WWDC nesta nova plataforma, e a documentação também está bastante dispersa. De qualquer forma, continuarei acompanhando seu desenvolvimento, pois parece que esta é a API mais adequada para treinar modelos em aparelhos Apple.
Consulte também: Documentação da plataforma de computação de ML
Conclusão
O Core ML adicionou uma série de novos recursos úteis, como atualização automática de modelos e criptografia. Os novos tipos de camada realmente não são necessários, porque as camadas adicionadas no ano passado podem resolver quase todos os problemas. No geral, eu gosto dessa atualização.
No coremltools 4 foram adicionadas melhorias importantes - a nova arquitetura do conversor e suporte integrado ao TensorFlow 2 e PyTorch. Estou feliz por não termos mais que usar o ONNX para transformar os modelos PyTorch.
Em visãoadicionou muitos novos recursos úteis. E adoro que a Apple tenha adicionado a funcionalidade de análise de vídeo. Embora os sistemas de aprendizado de máquina possam ser aplicados a quadros individuais de vídeo, neste caso, o tempo não é contado. Como os dispositivos móveis são rápidos o suficiente hoje para realizar aprendizado de máquina com base em dados de vídeo em tempo real, acredito que o vídeo terá um papel mais importante no desenvolvimento de tecnologias de visão computacional no futuro próximo.
Com relação ao treinamento... não tenho certeza se precisamos de sete APIs diferentes para esta tarefa. Acho que a Apple simplesmente não queria desativar as interfaces desatualizadas até que as novas fossem totalmente refinadas. Pouco se sabe sobre a plataforma ML Compute. No entanto, no momento da redação deste artigo, apenas a primeira versão beta foi lançada. Quem sabe o que vem pela frente ...
A imagem da palestra usa o ícone Freepik do flaticon.com.