
Quem sou eu
Meu nome é Dmitry Ivanov. Eu sou um estudante de pós-graduação do 2º ano em economia no HSE de São Petersburgo. Trabalho no grupo de pesquisa " Sistemas de Agentes e Aprendizagem por Reforço " da JetBrains Research , bem como no laboratório internacional de Teoria dos Jogos e Tomada de Decisão na Escola Superior de Economia . Além de aprender PU, estou interessado em aprendizado de reforço e pesquisa na interseção de aprendizado de máquina e economia.
Preâmbulo
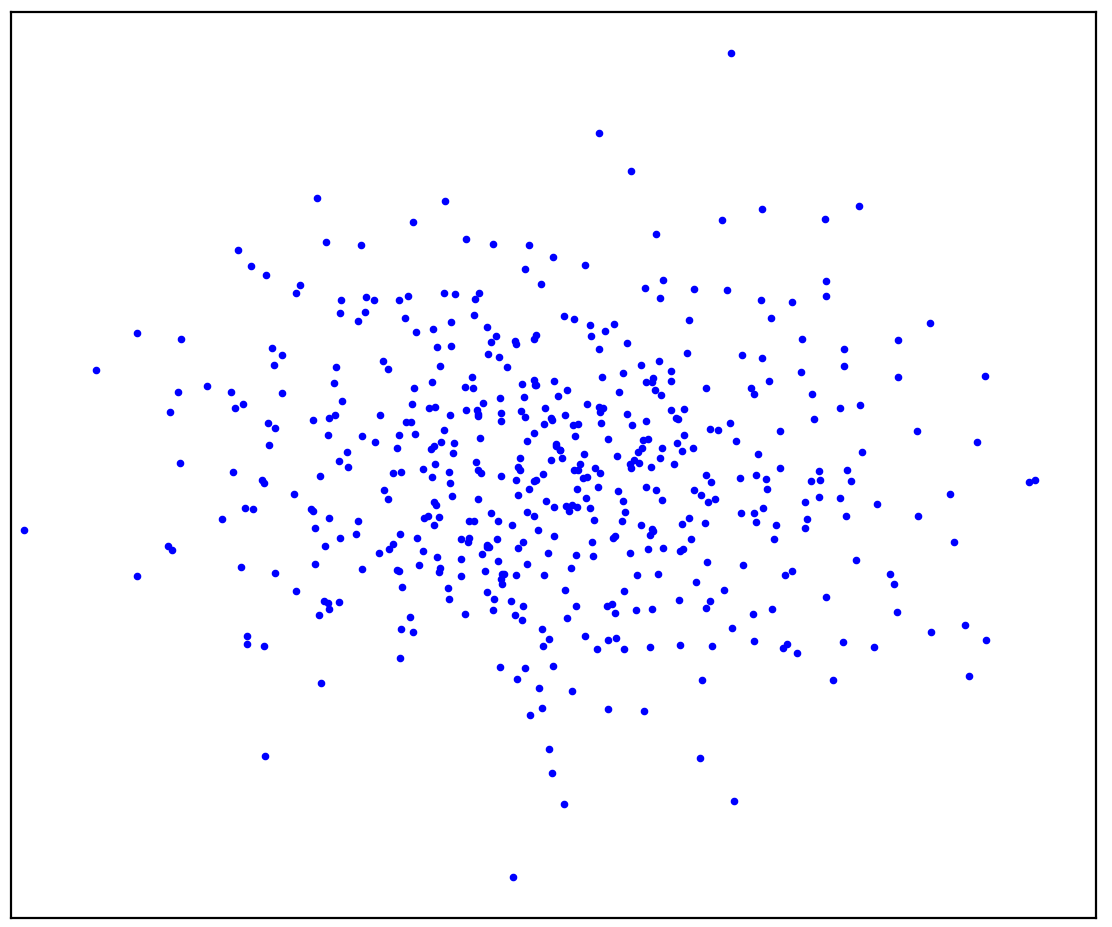
Figura: 1a. Dados positivos A
Figura 1a mostra um conjunto de pontos gerados por alguma distribuição, que chamaremos de positivos. Todos os outros pontos possíveis que não pertencem à distribuição positiva serão chamados de negativos. Tente traçar mentalmente uma linha separando os pontos positivos apresentados de todos os pontos negativos possíveis. A propósito, esta tarefa é chamada de "detecção de anomalias".
A resposta esta aqui

. 1.
. 1.
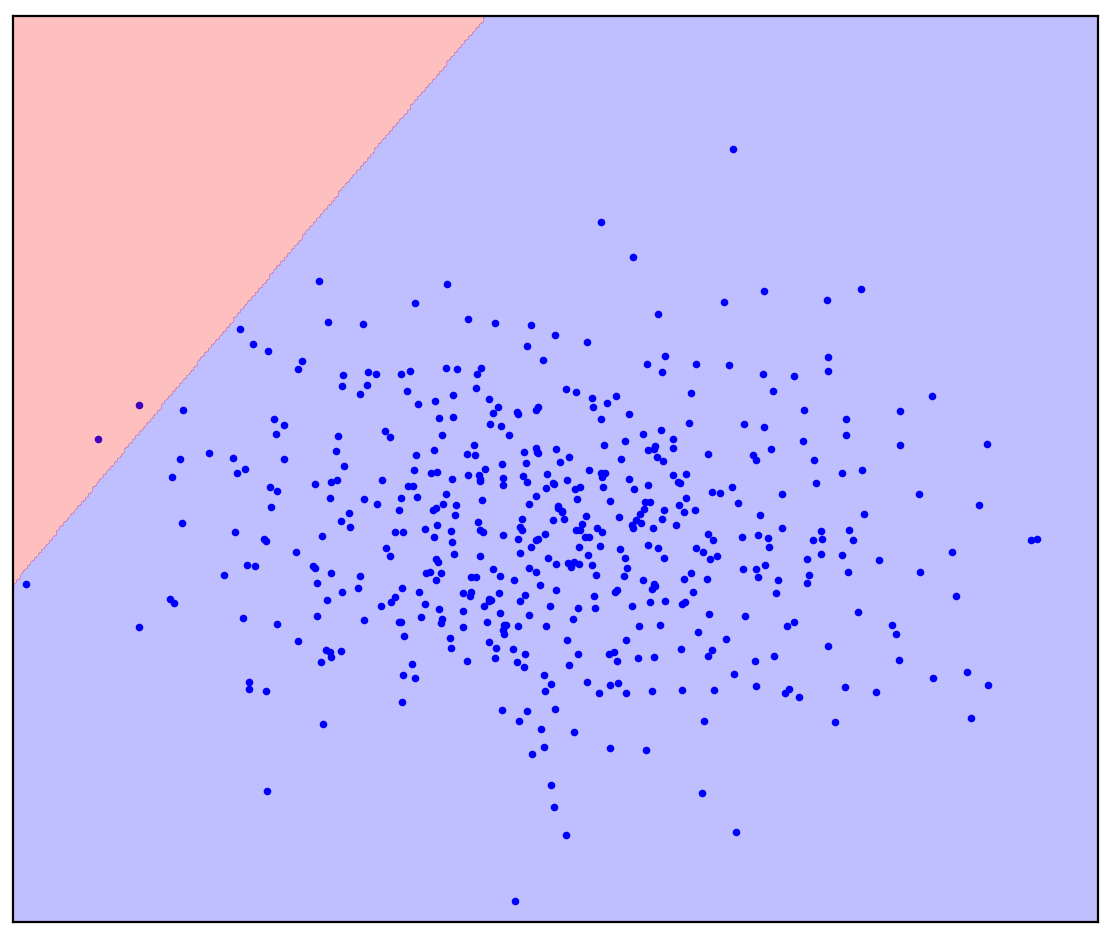
Você pode ter imaginado algo como a Figura 1b: circulou os dados em uma elipse. Na verdade, é assim que funcionam muitos métodos de detecção de anomalias.
Agora vamos mudar um pouco o problema: vamos ter informações adicionais de que uma linha reta deve separar os pontos positivos dos negativos. Tente desenhá-lo em sua mente.
A resposta esta aqui
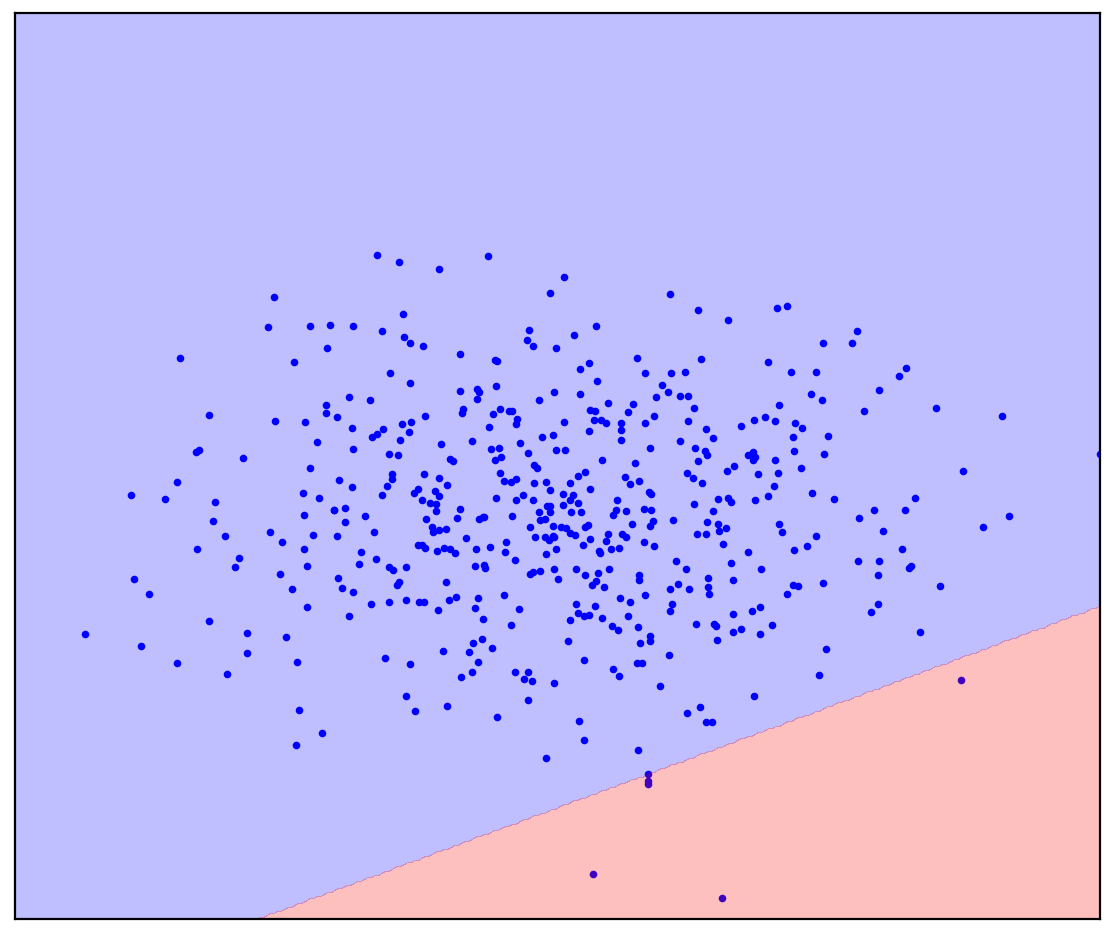
. 1. ( One-Class SVM)
. 1. ( One-Class SVM)
No caso de uma linha divisória reta, não há uma resposta única. Não está claro em qual direção traçar uma linha reta.
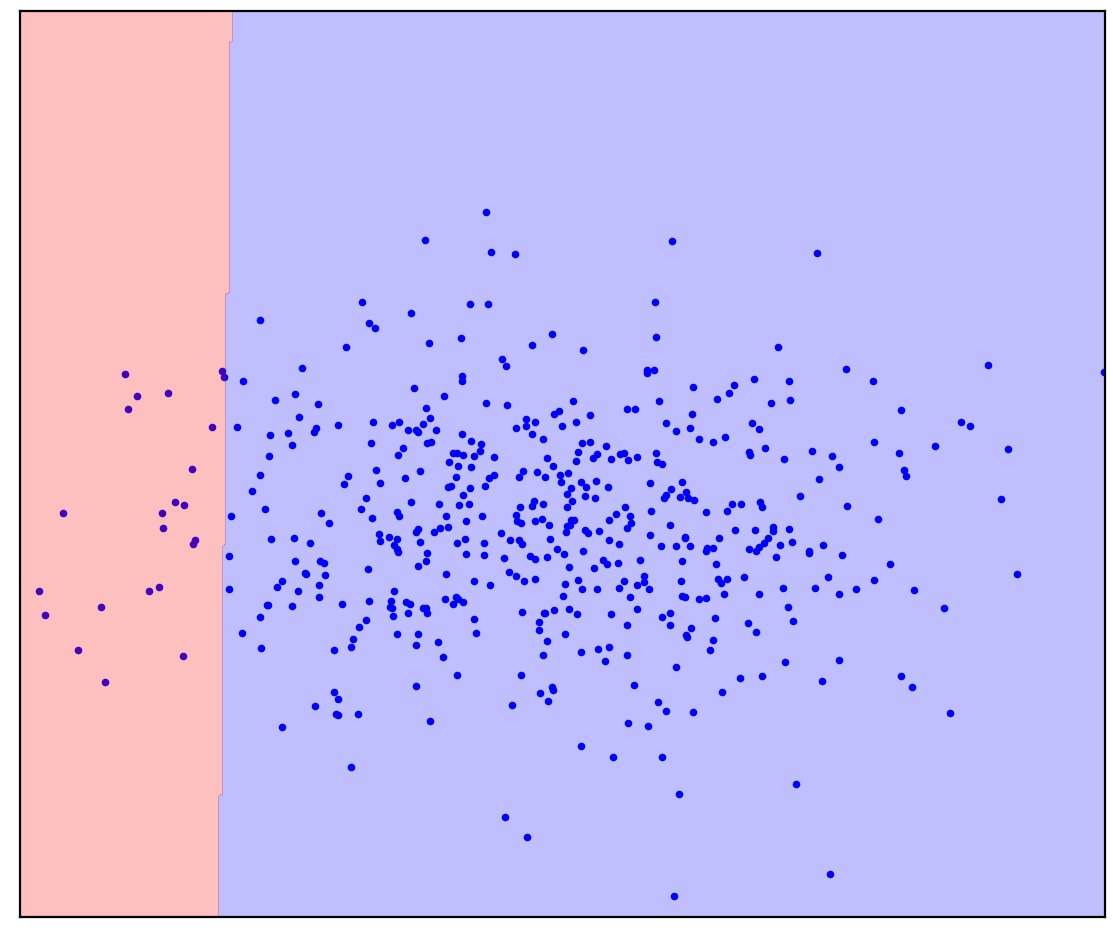
Agora adicionarei alguns pontos não alocados à Figura 1d que contêm uma mistura de positivo e negativo. Pela última vez, vou pedir-lhe que faça um esforço mental e imagine uma linha separando os pontos positivos e negativos. Mas desta vez, você pode usar dados não rotulados!

Figura: 1d. Pontos positivos (azuis) e não rotulados (vermelhos). Os pontos não marcados são compostos por pontos positivos e negativos
A resposta esta aqui

. 1.
. 1.
Ficou mais fácil! Embora não saibamos com antecedência como cada ponto não marcado particular é gerado, podemos marcá-los aproximadamente, comparando-os com pontos positivos. Os pontos vermelhos que parecem azuis são provavelmente positivos. Pelo contrário, os diferentes são provavelmente negativos. Como resultado, apesar de não termos dados negativos “limpos”, as informações sobre eles podem ser obtidas na mistura não rotulada e usadas para uma classificação mais precisa. Isso é o que fazem os algoritmos de aprendizagem sem etiqueta positiva, sobre os quais quero falar.
Introdução
A aprendizagem sem rótulos positivos (PU) pode ser traduzida como "aprender com dados positivos e sem rótulos". Na verdade, o aprendizado de PU é um análogo de uma classificação binária para casos em que há dados rotulados de apenas uma das classes, mas uma mistura não rotulada de dados de ambas as classes está disponível. No caso geral, nem sabemos quantos dados na mistura correspondem a uma classe positiva e quanto a uma negativa. Com base em tais conjuntos de dados, queremos construir um classificador binário: o mesmo que na presença de dados puros de ambas as classes.
Como um exemplo de brinquedo, considere um classificador para fotos de cães e gatos. Temos algumas fotos de gatos e muitas outras fotos de cães e gatos. Na saída, queremos um classificador: uma função que prevê para cada imagem a probabilidade de um gato ser representado. Ao mesmo tempo, o classificador pode marcar nossa mistura existente de imagens para cães e gatos. Ao mesmo tempo, pode ser difícil / caro / demorado / impossível marcar manualmente as fotos para treinar o classificador, você deseja fazer sem ele.
Aprender PU é uma tarefa bastante natural. Os dados encontrados no mundo real geralmente estão sujos. A capacidade de aprender com dados sujos parece ser um hack de vida útil com qualidade relativamente alta. Apesar disso, encontrei, paradoxalmente, poucas pessoas que ouviram falar sobre o aprendizado de PU, e menos ainda que sabiam sobre algum método específico. Então resolvi falar sobre essa área.

Figura: 2. Jürgen Schmidhuber e Yann LeCun, NeurIPS 2020
Aplicação de aprendizagem PU
Dividirei informalmente os casos em que o aprendizado do PU pode ser útil em três categorias.
A primeira categoria é provavelmente a mais óbvia: o aprendizado de PU pode ser usado em vez da classificação binária usual. Em algumas tarefas, os dados são inerentemente ligeiramente sujos. Em princípio, essa contaminação pode ser ignorada e um classificador convencional pode ser usado. Porém, é possível alterar muito pouco a função de perda ao treinar o classificador (Kiryo et al., 2017) ou mesmo as próprias previsões após o treinamento (Elkan & Noto, 2008) , e a classificação torna-se mais precisa.
Como exemplo, considere a identificação de novos genes responsáveis pelo desenvolvimento de genes de doenças. A abordagem padrão é tratar os genes de doenças já encontrados como positivos e todos os outros genes como negativos. É claro que genes de doenças ainda não encontrados podem estar presentes nesses dados negativos. Além disso, a tarefa em si é encontrar esses genes de doenças entre os dados "negativos". Essa contradição interna é percebida aqui: (Yang et al., 2012) . Os pesquisadores se desviaram da abordagem convencional e consideraram genes não relacionados a genes de doenças já descobertos como uma mistura sem rótulo e, em seguida, aplicaram métodos de aprendizado de PU.
Outro exemplo é o aprendizado por reforço a partir de demonstrações de especialistas. O desafio é treinar o agente para atuar da mesma forma que um especialista. Isso pode ser alcançado usando o método de aprendizagem por imitação gerativa de adversários (GAIL). O GAIL usa uma arquitetura do tipo GAN (redes adversárias geradoras): o agente gera trajetórias de forma que o discriminador (classificador) não consegue distingui-las das demonstrações do especialista. Pesquisadores da DeepMind notaram recentemente que em GAIL, o discriminador resolve o problema de aprendizagem de PU (Xu & Denil, 2019)... Normalmente, o discriminador considera os dados especializados positivos e os dados gerados negativos. Esta aproximação é precisa o suficiente no início do treinamento, quando o gerador não consegue produzir dados que pareçam positivos. No entanto, à medida que o treinamento avança, os dados gerados se parecem mais com dados de especialistas até se tornarem indistinguíveis para o discriminador no final do treinamento. Por esse motivo, os pesquisadores (Xu & Denil, 2019) consideram os dados gerados como dados não rotulados com uma proporção de mistura variável. Posteriormente, o GAN foi modificado de forma semelhante na geração de imagens (Guo et al., 2020) .

Figura: 3. Aprendizagem de PU como um análogo da classificação PN padrão
Na segunda categoria, a aprendizagem de PU pode ser usada para detecção de anomalias como um análogo da classificação de uma classe (OCC). Já vimos no Preâmbulo como exatamente dados não marcados podem ajudar. Todos os métodos OSS, sem exceção, são forçados a fazer uma suposição sobre a distribuição de dados negativos. Por exemplo, é aconselhável circular os dados positivos em uma elipse (uma hiperesfera no caso multidimensional) fora da qual todos os pontos são negativos. Neste caso, assumimos que os dados negativos estão uniformemente distribuídos (Blanchard et al., 2010)... Em vez de fazer tais suposições, os métodos de aprendizagem PU podem estimar a distribuição de dados negativos com base em dados não rotulados. Isso é especialmente importante se as distribuições das duas classes se sobrepõem fortemente (Scott & Blanchard, 2009) . Um exemplo de detecção de anomalias usando aprendizagem PU é a detecção de revisão falsa (Ren et al., 2014) .

Figura: 4. Um exemplo de uma crítica falsa
Detecção de corrupção em leilões de contratos públicos russos
A terceira categoria de aprendizagem de PU pode ser atribuída a problemas nos quais nem a classificação binária nem a classificação de classe única podem ser usadas. A título de exemplo, contarei a vocês sobre nosso projeto para detectar corrupção em leilões de compras públicas russas (Ivanov & Nesterov, 2019) .
De acordo com a legislação, os dados completos sobre todos os leilões de compras públicas estão disponíveis ao público para todos que desejam passar um mês analisando-os. Coletamos dados de mais de um milhão de leilões realizados de 2014 a 2018. Quem colocou, quando e quanto, quem ganhou, em que período ocorreu o leilão, quem realizou, o que comprou - tudo isso está nos dados. Mas, é claro, não há rótulo “a corrupção está aqui”, então você não pode construir um classificador comum. Em vez disso, aplicamos o aprendizado PU. Pressuposto básico: os participantes com uma vantagem injusta sempre vencerão. Usando essa suposição, os perdedores nos leilões podem ser considerados justos (positivos) e os vencedores como potencialmente desonestos (não marcados).Nesse cenário, os métodos de aprendizagem PU podem encontrar padrões suspeitos nos dados com base em diferenças sutis entre vencedores e perdedores. É claro que, na prática, surgem dificuldades: um projeto preciso de recursos para o classificador, uma análise da interpretabilidade de suas previsões e a verificação estatística de suposições sobre os dados são necessários.
De acordo com nossa estimativa muito conservadora, cerca de 9% dos leilões nos dados estão corrompidos, e como resultado o estado perde cerca de 120 milhões de rublos por ano. As perdas podem não parecer muito grandes, mas os leilões que estudamos ocupam apenas cerca de 1% do mercado de compras públicas.


Figura: 5. A parcela de leilões de compras públicas corruptos em diferentes regiões da Rússia (Ivanov & Nesterov, 2019)
Considerações finais
Para não dar a impressão de que o PU é a solução para todos os problemas da humanidade, mencionarei as armadilhas. Em uma classificação convencional, quanto mais dados tivermos, mais preciso o classificador pode ser. Além disso, ao aumentar a quantidade de dados para o infinito, podemos nos aproximar do classificador ideal (de acordo com a fórmula Bayesiana). Portanto, o principal problema do aprendizado do PU é que ele é um problema mal colocado, ou seja, um problema que não pode ser resolvido de forma inequívoca, mesmo com uma quantidade infinita de dados. A situação fica melhor se a proporção de duas classes em dados não rotulados for conhecida, no entanto, determinar essa proporção também é um problema mal colocado (Jain et al., 2016)... O melhor que podemos definir é o espaçamento em que a proporção está. Além disso, os métodos de aprendizagem da UP muitas vezes não oferecem maneiras de estimar essa proporção e considerá-la conhecida. Existem métodos separados para estimar isso (a tarefa é chamada de Estimativa de Proporção de Mistura), mas eles são frequentemente lentos e / ou instáveis, especialmente quando as duas classes são representadas de forma muito desigual na mistura.
Neste post, falei sobre a definição intuitiva e a aplicação do aprendizado do PU. Além disso, posso falar sobre a definição formal do aprendizado do PU com fórmulas e suas explicações, bem como sobre os métodos clássicos e modernos de aprendizado do PU. Se este post despertar interesse, escreverei uma continuação.
Bibliografia
Blanchard, G., Lee, G., & Scott, C. (2010). Semi-supervised novelty detection. Journal of Machine Learning Research, 11(Nov), 2973–3009.
Elkan, C., & Noto, K. (2008). Learning classifiers from only positive and unlabeled data. Proceeding of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining — KDD 08, 213. https://doi.org/10.1145/1401890.1401920
Guo, T., Xu, C., Huang, J., Wang, Y., Shi, B., Xu, C., & Tao, D. (2020). On Positive-Unlabeled Classification in GAN. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8385–8393.
Ivanov, D. I., & Nesterov, A. S. (2019). Identifying Bid Leakage In Procurement Auctions: Machine Learning Approach. ArXiv Preprint ArXiv:1903.00261.
Jain, S., White, M., Trosset, M. W., & Radivojac, P. (2016). Nonparametric semi-supervised learning of class proportions. ArXiv Preprint ArXiv:1601.01944.
Kiryo, R., Niu, G., du Plessis, M. C., & Sugiyama, M. (2017). Positive-unlabeled learning with non-negative risk estimator. Advances in Neural Information Processing Systems, 1675–1685.
Ren, Y., Ji, D., & Zhang, H. (2014). Positive Unlabeled Learning for Deceptive Reviews Detection. EMNLP, 488–498.
Scott, C., & Blanchard, G. (2009). Novelty detection: Unlabeled data definitely help. Artificial Intelligence and Statistics, 464–471.
Xu, D., & Denil, M. (2019). Positive-Unlabeled Reward Learning. ArXiv:1911.00459 [Cs, Stat]. http://arxiv.org/abs/1911.00459
Yang, P., Li, X.-L., Mei, J.-P., Kwoh, C.-K., & Ng, S.-K. (2012). Positive-unlabeled learning for disease gene identification. Bioinformatics, 28(20), 2640–2647.