Em minha palestra, compartilhei minha experiência de uso do Alembic, uma ferramenta comprovada para gerenciar migrações. Por que escolher o Alembic, como preparar migrações com ele, como executá-las (automática ou manualmente), como resolver os problemas de mudanças irreversíveis, por que testar migrações, quais problemas podem ser detectados por testes e como implementá-los - tentei responder a todas essas perguntas. Ao mesmo tempo, compartilhei vários hacks de vida que vão tornar o trabalho com migrações no Alembic fácil e agradável.
Desde o dia do relatório, o código no GitHub foi ligeiramente atualizado, há mais exemplos. Se você quiser ver o código exatamente como aparece nos slides, aqui está um link para um commit daquela época.
- Olá! Meu nome é Alexander, trabalho em Edadil. Hoje quero contar como vivemos com as migrações e como você poderia conviver com elas. Talvez isso o ajude a viver mais facilmente.
O que são migrações?
Antes de começarmos, vale a pena falar sobre o que são as migrações em geral. Por exemplo, você tem um aplicativo e cria alguns tablets para que funcione e vá até eles. Em seguida, você lança uma nova versão, na qual algo mudou - a primeira placa mudou, a segunda não, e a terceira não estava lá antes, mas apareceu.

Em seguida, surge uma nova versão do aplicativo, em que alguma placa é apagada, nada acontece com o resto. O que é isso? Podemos dizer que este é o estado que pode ser descrito pela migração. Quando passamos de um estado para outro, isso é um upgrade, quando queremos voltar - fazer downgrade.
O que são migrações?

Por um lado, é um código que altera o estado do banco de dados. Por outro lado, é esse o processo que iniciamos.

Quais propriedades as migrações devem ter? É importante que os estados entre os quais alternamos nas versões do aplicativo sejam atômicos. Se, por exemplo, queremos que tenhamos duas tabelas, mas apenas uma apareça, isso pode levar a consequências não muito boas na produção.
É importante que possamos reverter nossas alterações, porque se você lançar uma nova versão, ela não decola e você não pode reverter, geralmente tudo acaba mal.
Também é importante que as versões sejam ordenadas de forma que você possa encadear a maneira como elas rolam.
Ferramentas
Como podemos implementar essas migrações?
A primeira ideia que vem na cabeça: tudo bem, migração é SQL, por que não pegar e fazer arquivos SQL com consultas. Existem vários outros módulos que podem tornar nossa vida mais fácil.

Se olharmos o que está acontecendo lá dentro, então há de fato alguns pedidos. Pode ser CREATE TABLE, ALTER, qualquer outra coisa. No arquivo downgrade_v1.sql, cancelamos tudo.

Por que você não deveria fazer isso? Principalmente porque você precisa fazer isso com as mãos. Não se esqueça de começar a escrever e, em seguida, envie suas alterações. Ao escrever o código, você precisará se lembrar de todas as dependências e o que fazer em que ordem. Este é um trabalho bastante rotineiro, difícil e demorado.
Você não tem proteção contra o lançamento acidental do arquivo errado. Você precisa executar todos os arquivos manualmente. Se você tem 15 migrações, não é fácil. Você precisará chamar algum psql 15 vezes, não será muito legal.
Mais importante ainda, você nunca sabe em que estado seu banco de dados está. Você precisa anotar em algum lugar - em um pedaço de papel, em outro lugar - quais arquivos você baixou e quais não. Isso também não parece muito bom.

Existe um módulo de migrações yoyo . Ele suporta os bancos de dados mais comuns e usa consultas brutas.

Se olharmos para o que ele nos oferece, fica assim. Vemos o mesmo SQL. Já existe um código Python à direita que importa a biblioteca yoyo.

Assim, já podemos iniciar as migrações, exatamente de forma automática. Em outras palavras, existe um comando que cria e adiciona uma nova migração à cadeia, onde podemos escrever nosso código SQL. Usando comandos, você pode aplicar uma ou mais migrações, pode reverter, isso já é um passo à frente.

A vantagem é que você não precisa mais escrever em um pedaço de papel quais solicitações executou no banco de dados, quais arquivos você iniciou e onde você precisa fazer o rollback se algo acontecer. Você tem algum tipo de proteção infalível: não será mais capaz de iniciar uma migração projetada para outra coisa, para a transição entre dois outros estados do banco de dados. Uma grande vantagem: essa coisa faz cada migração em uma transação separada. Isso também dá essas garantias.

As desvantagens são óbvias. Você ainda tem SQL bruto. Se, por exemplo, você tem uma grande produção de dados com lógica extensa em Python, você não pode usá-la, porque você só tem SQL.
Além disso, você encontrará muitos trabalhos de rotina que não podem ser automatizados. É necessário acompanhar todas as relações entre as tabelas - o que pode ser escrito em algum lugar e o que ainda não é possível. Em geral, existem desvantagens bastante óbvias.
Outro módulo que merece atenção e para o qual toda a conversa de hoje é o Alambique .

Tem as mesmas coisas que o yoyo e muito mais. Ele não apenas monitora suas migrações e sabe como criá-las, mas também permite que você escreva lógicas de negócios muito complexas, conecte toda a sua produção de dados, quaisquer funções em Python. Extraia os dados e processe-os internamente, se desejar. Se você não quiser, não precisa.
Ele pode escrever código para você automaticamente na maioria dos casos. Nem sempre, é claro, mas soa como uma boa vantagem depois de você ter que escrever muito com as mãos.
Ele tem um monte de coisas legais. Por exemplo, o SQLite não é totalmente compatível com ALTER TABLE. E o Alembic tem uma funcionalidade que permite que você contorne isso facilmente em algumas linhas, e você nem vai pensar nisso.
Nos slides anteriores, havia um módulo Django-migrações. Este também é um módulo muito bom para migrações. Seu princípio é comparável ao Alembic em funcionalidade. A única diferença é que é limitado pela estrutura, enquanto o Alembic não.
SQLAlchemy
Como o Alembic é baseado no SQLAlchemy, sugiro que você percorra um pouco o SQLAlchemy para lembrar ou descobrir o que é.

Até agora, vimos consultas brutas. Consultas brutas não são ruins. Isto pode ser muito bom. Quando você tem um aplicativo altamente carregado, talvez seja exatamente o que você precisa. Não há necessidade de perder tempo convertendo alguns objetos em algum tipo de consulta.
Nenhuma biblioteca adicional é necessária. Você só pega o motorista e pronto, funciona. Mas, por exemplo, se você escrever consultas complexas, não será tão fácil: bem, você pode pegar uma constante, movê-la para cima e escrever um grande código de várias linhas. Mas se você tiver de 10 a 20 dessas solicitações, já será muito difícil de ler. Então você não pode reutilizá-los de forma alguma. Você tem muito texto e, claro, funções para trabalhar com strings, f-strings e tudo mais, mas isso já não parece muito bom. Eles são difíceis de ler.
Se, por exemplo, você tem uma classe na qual também deseja ter consultas e estruturas complexas, o recuo é uma dor selvagem. Se você quiser fazer uma migração bruta, a única maneira de descobrir onde está usando algo é com grep. E você também não tem uma ferramenta dinâmica para consultas dinâmicas.
Por exemplo, uma tarefa super fácil. Você tem uma entidade, ela tem 15 campos em uma placa. Você deseja fazer uma solicitação PATCH. Parece ser super simples. Tente escrever isso em consultas brutas. Não ficará muito bonito e a solicitação pull provavelmente não será aprovada.

Existe uma alternativa para isso - Construtor de consultas. Certamente tem desvantagens porque permite que você represente suas consultas como objetos em Python.
Por conveniência, você terá que pagar com tempo para geração de solicitações e memória. Mas existem vantagens. Quando você escreve aplicativos grandes e complexos, precisa de abstrações. O construtor de consultas pode fornecer essas abstrações. Essas consultas podem ser decompostas; veremos como isso é feito um pouco mais tarde. Eles podem ser reutilizados, estendidos ou agrupados em funções que já serão chamadas de nomes amigáveis associados à lógica de negócios.
É muito fácil construir consultas dinâmicas. Se você precisa mudar algo, escreva uma migração, a análise estatística do código é suficiente. É muito conveniente.
Por que é SQLAlchemy? Por que vale a pena parar em?

Essa é uma questão não apenas sobre migração, mas em geral. Porque quando temos Alembic, faz sentido usar toda a pilha de uma vez, porque SQLAlchemy funciona não apenas com drivers síncronos. Ou seja, Django é uma ferramenta muito legal, mas o Alchemy pode ser usado, por exemplo, com asyncpg e aiopg . Asyncpg permite que você leia, como disse Selivanov, um milhão de linhas por segundo - leia do banco de dados e transfira para o Python. Claro, com SQLAlchemy haverá um pouco menos, haverá alguma sobrecarga. Mas mesmo assim.
SQLAlchemy tem um número incrível de drivers com os quais sabe trabalhar. Existem Oracle e PostgreSQL, e tudo para todos os gostos e cores. Além disso, eles já estão fora da caixa, e se você precisar de algo separado, então lá, eu olhei recentemente, há até Elasticsearch. Verdade, apenas para leitura, mas - você entendeu? - Elasticsearch em SQLAlchemy.
Existe uma documentação muito boa, uma grande comunidade. Existem muitas bibliotecas. E o que é importante, afinal, ele não dita frameworks e bibliotecas para você. Quando você está realizando uma tarefa restrita que precisa ser bem executada, pode ser uma ferramenta.
Então, em que consiste?
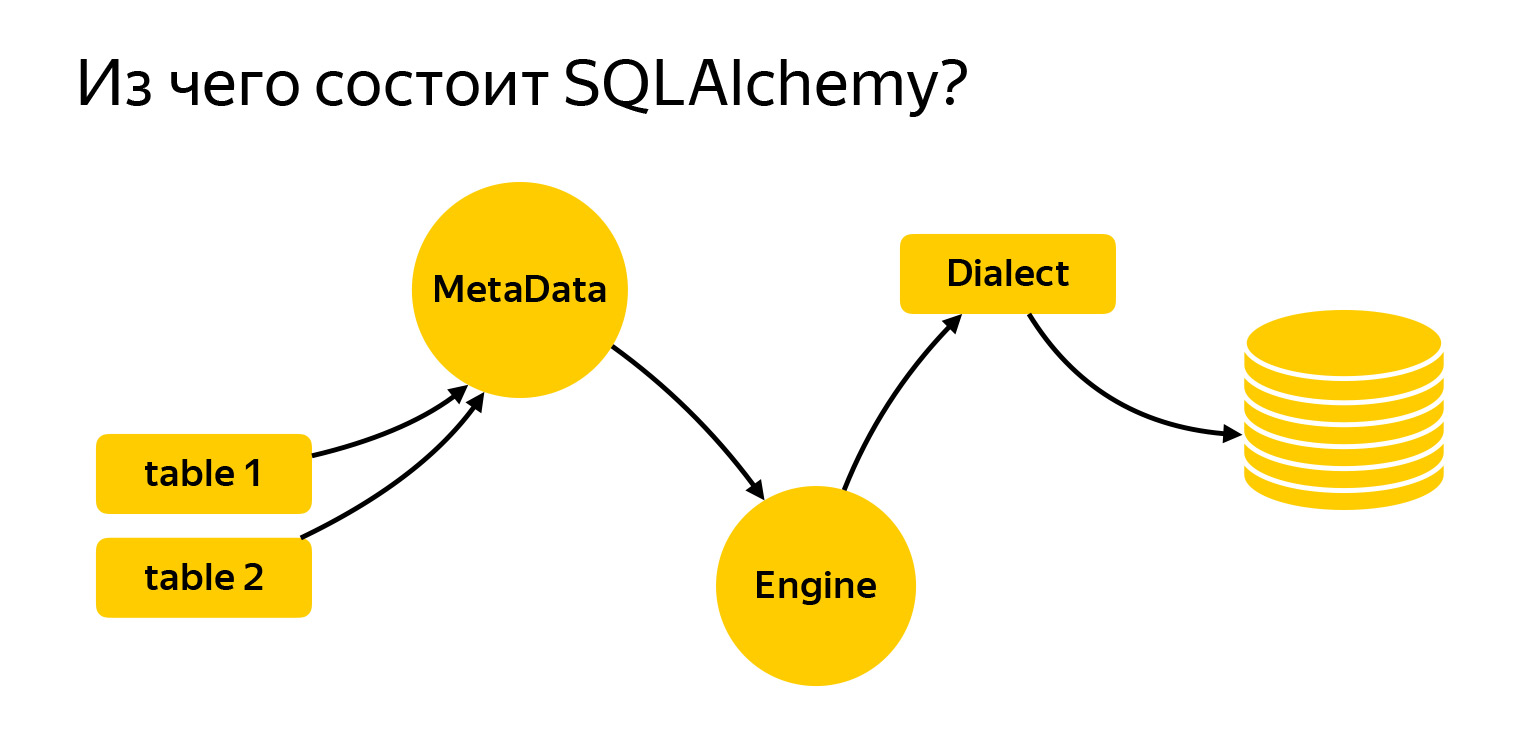
Trouxe aqui as principais entidades com as quais vamos trabalhar hoje. São tabelas. Para escrever solicitações, Alchemy precisa ser informado do que é e com o que estamos trabalhando. Em seguida, está o registro MetaData. Engine é uma coisa que se conecta ao banco de dados e se comunica com ele por meio do dialeto.
Vamos dar uma olhada mais de perto no que é.

MetaData é uma espécie de objeto, um container, no qual você irá adicionar suas tabelas, índices e, em geral, todas as entidades que possui. Este é um objeto que reflete, por um lado, como você deseja ver o banco de dados, com base em seu código escrito. Por outro lado, o MetaData pode ir para o banco de dados, obter um instantâneo do que realmente está lá e construir o próprio modelo de objeto.
Além disso, o objeto MetaData tem um recurso muito interessante. Ele permite que você defina um modelo de nomenclatura padrão para índices e restrições. Isso é muito importante quando você escreve migrações, porque cada banco de dados - seja PostgreSQL, MySQL, MariaDB - tem sua própria visão de como os índices devem ser chamados.
Alguns desenvolvedores também têm sua própria visão. E o SQLAlchemy permite que você defina um padrão de uma vez por todas como ele funciona. Tive que desenvolver um projeto que precisava trabalhar tanto com SQLite quanto com PostgreSQL. Era muito conveniente.

É assim: você importa um objeto MetaData do SQLAlchemy e, ao criá-lo, especifica os modelos usando o parâmetro naming_convention, cujas chaves indicam os tipos de índices e restrições: ix é um índice regular, uq é um índice exclusivo, fk é uma chave estrangeira, pk é chave primária.
Nos valores do parâmetro naming_convention, você pode especificar um padrão que consiste no tipo / restrição de índice (ix / uq / fk, etc.) e no nome da tabela, separados por sublinhados. Em alguns modelos, você também pode listar todas as colunas. Por exemplo, não é necessário fazer isso para a chave primária, você pode simplesmente especificar o nome da tabela.
Quando você começa a fazer um novo projeto, adiciona modelos de nomenclatura a ele uma vez e esquece. Desde então, todas as migrações foram geradas com os mesmos nomes de índices e restrições.
Isso é importante por outro motivo: quando você decidir que este índice não é mais necessário em seu modelo de objeto e excluí-lo, o Alembic saberá como ele é chamado e gerará a migração corretamente. Isso já é uma certa garantia de confiabilidade, de que tudo funcionará como deveria.
Outra entidade muito importante que você certamente encontrará é uma mesa, um objeto que descreve o que a mesa contém.

A tabela tem um nome, colunas com tipos de dados e necessariamente se refere ao registro MetaData, já que MetaData é um registro de tudo o que você descreve. E existem colunas com tipos de dados.
Graças ao que descrevemos, SQLAlchemy agora pode e sabe muito. Se especificássemos uma chave estrangeira aqui, ela ainda saberia como nossas tabelas estão conectadas umas às outras. E ela saberia a ordem em que algo precisa ser feito.

SQLAlchemy também tem motor. Importante: o que dissemos sobre consultas pode ser usado separadamente, e o Engine pode ser usado separadamente. E você pode usar tudo junto, ninguém proíbe. Ou seja, o Engine sabe como se conectar diretamente ao servidor e oferece exatamente a mesma interface. Não, claro, drivers diferentes tentam cumprir o DBAPI, existe um PEP em Python que faz recomendações. Mas o Engine oferece exatamente a mesma interface para todos os bancos de dados e é muito conveniente.

O último grande marco é o dialeto. É assim que o mecanismo se comunica com diferentes bancos de dados. Existem diferentes idiomas, diferentes pessoas e diferentes dialetos aqui.
Vamos ver para que serve tudo isso.

Esta é a aparência de um Insert normal. Se quisermos adicionar uma nova linha, a placa que descrevemos anteriormente, na qual havia um campo de ID e e-mail, aqui especificamos o e-mail, fazemos Insert, e imediatamente recuperamos tudo o que inserimos.
E se quisermos adicionar muitas linhas? Sem problemas.

Você pode simplesmente transferir uma lista de ditados aqui. Parece um código perfeito para uma caneta super simples. Os dados chegaram, passaram por algum tipo de validação, algum esquema JSON e pronto, entraram no banco de dados. Super fácil.
Algumas consultas são bastante complexas. Às vezes, um pedido pode até ser visto com uma impressão, às vezes você tem que compilá-lo. Isso não é difícil. A alquimia permite que você faça tudo isso. Nesse caso, compilamos a solicitação e você pode ver o que realmente entrará no banco de dados.

A solicitação de dados parece bastante simples. Literalmente duas linhas, você pode até escrever em uma.

Vamos voltar à nossa pergunta sobre como, por exemplo, escrever uma solicitação PATCH para 15 campos. Aqui você deve escrever apenas o nome do campo, sua chave e valor. Isso é tudo o que é necessário. Sem arquivos, sem construção de cordas, absolutamente nada. Parece conveniente.
Talvez o recurso mais importante do Alchemy que uso todos os dias em meu trabalho seja a decomposição e expansão de consultas.

Suponha que você esteja escrevendo uma interface em PostgreSQL, seu aplicativo deve de alguma forma autorizar uma pessoa e permitir que ela execute CRUD. Ok, não há muito para decompor.
Quando você escreve um aplicativo muito complexo que usa controle de versão de dados, um monte de abstrações diferentes, as consultas que você vai gerar podem consistir em um grande número de subconsultas. As subconsultas são unidas às subconsultas. Existem diferentes tarefas. E às vezes a decomposição da consulta ajuda muito, pois permite uma grande separação da lógica e do design do código.
Por que funciona assim? Quando você chama o método users_table.select (), por exemplo, ele retorna um objeto. Quando você chama outro método no objeto resultante, como where (), ele retorna um objeto completamente novo. Todos os objetos de consulta são imutáveis. Portanto, você pode construir tudo o que quiser.
Migrações do alambique
Então, lidamos com SQLAlchemy e agora podemos finalmente escrever migrações de Alambique.

Começar a usar o Alembic não é nada difícil, especialmente se você já descreveu suas tabelas, como dissemos antes, e especificou um objeto MetaData. Basta instalar o alambique e chamar o alambique init. alambique - o nome do módulo, esta é a linha de comando, você o terá. init é um comando. O último argumento é a pasta para colocá-lo.
Ao chamar esse comando, você terá vários arquivos, que examinaremos mais de perto agora.

Haverá configuração geral em alembic.ini. script_location é exatamente onde você gostaria que fosse. Em seguida, haverá um modelo para os nomes de suas migrações que você irá gerar e informações para se conectar ao banco de dados.

Também existe um modelo para novas migrações. Você diz: "Quero uma nova migração" e o Alembic a criará de acordo com um determinado modelo. Você pode personalizar tudo isso, é muito simples. Você entra neste arquivo e edita o que você precisa. Todas as variáveis que podem ser especificadas aqui estão na documentação. Esta é a primeira parte. Há algum tipo de comentário no topo para que seja conveniente ver o que está acontecendo ali. Depois, há um conjunto de variáveis que devem estar em cada migração - revisão, down_revision. Vamos trabalhar com eles hoje. Além disso - meta-informação adicional.

Os métodos mais importantes são upgrade e downgrade. O Alembic substituirá aqui qualquer diferença que o objeto MetaData encontrar entre a descrição do seu esquema e o que está no banco de dados.

env.py é o arquivo mais interessante do Alembic. Ele controla o progresso da execução do comando e permite que você o personalize. É neste arquivo que você conecta seu objeto MetaData. Como eu disse antes, o objeto MetaData é o registro de todas as entidades em seu banco de dados.
Você está conectando este objeto MetaData aqui. E a partir daí, Alembic entende que aqui estão eles, meus modelos, aqui estão eles, meus pratos. Ele entende com o que está trabalhando. Em seguida, o Alembic tem um código que chama o Alembic offline ou online. Vamos agora considerar tudo isso.
Esta é exatamente a linha onde você precisa conectar MetaData em seu projeto. Não se preocupe se algo não estiver muito claro, coloquei tudo em um projeto e postei no GitHub . Você pode cloná-lo e ver, sentir tudo.

O que é o modo online? No modo online, o Alembic se conecta ao banco de dados especificado no parâmetro sqlalchemy.url no arquivo alembic.ini e começa a executar as migrações.
Por que estamos olhando para este pedaço de código? O alambique pode ser personalizado de forma muito flexível.
Imagine que você tem um aplicativo que precisa viver em diferentes esquemas de banco de dados. Por exemplo, você deseja ter várias instâncias de aplicativo em execução ao mesmo tempo, e cada uma vive em seu próprio esquema. Pode ser conveniente e necessário.
Não custa nada. Depois de chamar o método context.begin_transaction (), você pode escrever o comando "SET search_path = SCHEMA", que dirá ao PostgreSQL para usar um esquema padrão diferente. E isso é tudo. A partir de agora, seu aplicativo vive em um esquema completamente diferente, as migrações ocorrem em um esquema diferente. Esta é uma pergunta de uma linha.

Também existe um modo offline. Observe que o Alembic não usa o Engine aqui. Você pode simplesmente passar um link para ele aqui. Você pode, é claro, transferir o Engine também, mas ele não se conecta a lugar nenhum. Ele apenas gera consultas brutas que você pode executar em algum lugar.

Então, você tem Alembic e alguns MetaDados com tabelas. E você finalmente deseja gerar migrações para você mesmo. Você executa este comando e basicamente é isso. O Alembic irá ao banco de dados e verá o que está lá. Existe seu rótulo especial “alembic_versions”, que lhe dirá que as migrações já foram implementadas neste banco de dados? Verá quais tabelas existem lá. Verá quais dados você precisa no banco de dados. Ele vai analisar tudo isso, gerar um novo arquivo, apenas com base neste template, e você terá uma migração. Claro, você definitivamente deve olhar o que foi gerado na migração, porque o Alembic nem sempre gera o que você deseja. Mas na maioria das vezes funciona.

O que geramos? Havia um sinal de usuários. Quando geramos a migração, indiquei a mensagem inicial. A migração será nomeada initial.py com algum outro modelo que foi especificado anteriormente em alembic.ini.
Também há informações sobre qual ID esta migração possui. down_revision = None - esta é a primeira migração.
O próximo slide será a parte mais importante: upgrade e downgrade.

No upgrade vemos que temos uma placa sendo criada. No downgrade, este sinal é removido. O Alembic, por padrão, adiciona especificamente esses comentários para que você vá lá, edite, pelo menos exclua esses comentários. E, para garantir, revisamos a migração e nos certificamos de que tudo se adapta a você. É uma questão de uma equipe. Você já tem uma migração.

Depois disso, você provavelmente deseja aplicar esta migração. Não poderia ser mais fácil. Basta dizer: cabeça de atualização do alambique. Ele aplicará absolutamente tudo.
Se dissermos cabeça, ele tentará atualizar para a migração mais recente. Se nomearmos uma migração específica, ela será atualizada para ela.
Há também um comando de downgrade - no caso de você mudar de ideia, por exemplo. Tudo isso é feito em transações e funciona de forma simples.

Então, você tem migrações, sabe como executá-las. Você tem um aplicativo e está fazendo, por exemplo, esta pergunta: tenho CI, os testes estão em execução e nem sei se quero, por exemplo, fazer migrações automaticamente? Talvez seja melhor fazer isso com as mãos?
Existem diferentes pontos de vista aqui. Provavelmente, vale a pena seguir a regra: se você não tem acesso fácil, a possibilidade de entrar em um carro com banco de dados, então é melhor, claro, fazê-lo automaticamente.
Se você tiver acesso, você faz um serviço que funciona na nuvem e pode ir para lá de um laptop que sempre está com você, então você mesmo pode fazer isso e, assim, ter mais controle.
Em geral, existem muitas ferramentas para fazer isso automaticamente. Por exemplo, no mesmo Kubernetes. Existem containers init que podem fazer isso e nos quais você pode executar esses comandos. Você pode adicionar um comando de inicialização diretamente ao Docker para fazer isso.
Você só precisa considerar: se você aplica migrações automaticamente, precisa pensar sobre o que acontece se, por exemplo, você quiser reverter, mas não pode. Por exemplo, você tinha uma placa de dados de 500 gigabytes de algum tipo. Você pensou: tudo bem, esses dados não são mais necessários para a lógica de negócios, provavelmente você pode descartá-los. Eles pegaram e largaram. Ou mudou o tipo de coluna, que mudou com a perda de dados. Por exemplo, havia uma longa fila, mas tornou-se curta. Ou algo foi embora. Ou você excluiu uma coluna. Você não pode reverter, mesmo se quiser.
Ao mesmo tempo, fiz produtos para o local, que são instalados por um arquivo exe para as pessoas diretamente na máquina. Depois de entender: sim, você escreveu a migração, ela entrou em produção, as pessoas já a instalaram. Nos próximos cinco anos, pode funcionar para eles de acordo com o SLA, e você quiser mudar algo, algo poderia ser melhor. Neste momento, você pensa em como lidar com mudanças irreversíveis.

Nenhuma ciência de foguetes aqui também. A ideia é evitar o uso dessas colunas ou tabelas, tanto quanto possível. Pare de contatá-los. Você pode, por exemplo, marcar campos com um decorador especial no ORM. Ele dirá nos registros que você parecia não querer tocar neste campo, mas ainda está se referindo a ele. Basta criar uma tarefa na lista de pendências e excluí-la algum dia.
Você, se alguma coisa, terá tempo para reverter. E se tudo correr bem, você fará essa tarefa com calma mais tarde no backlog. Faça outra migração que excluirá tudo.
Agora, a questão mais importante: por que e como testar as migrações?

Isso é feito por alguns daqueles a quem perguntei. Mas é melhor fazer isso. Esta é uma regra escrita em dor, sangue e suor. Usar a migração na produção é sempre arriscado. Você nunca sabe como isso pode acabar. Mesmo uma migração muito boa em uma produção de trabalho perfeitamente normal, quando você configurou o CI, pode funcionar mal.
O fato é que quando você está testando migrações, você pode até baixar, por exemplo, o stage ou alguma parte da produção. A produção pode ser grande, você não pode baixá-lo completamente para testes ou outras tarefas. Bases de desenvolvimento não são, via de regra, bases de produção. Eles não têm muito do que poderia ter acumulado ao longo dos anos.

Isso pode ser dados corrompidos quando migramos algo ou software antigo que tornou os dados inconsistentes. Também podem ser dependências implícitas - se alguém se esqueceu de adicionar uma chave estrangeira. Ele acha que está conectado, mas seus colegas, por exemplo, não sabem disso. Os campos também são chamados por acaso, não está claro se eles estão conectados.
Então alguém decidiu entrar e adicionar algum tipo de índice diretamente à produção, porque "agora está mais lento, mas e se começar a trabalhar mais rápido?" Talvez eu esteja exagerando, mas às vezes as pessoas realmente mudam algo direto nos bancos de dados.
É claro que existem erros nas ferramentas, na migração do esquema. Para ser honesto, não encontrei isso. Geralmente havia os três primeiros problemas. E talvez mais erros nas suposições sobre como os dados devem ser transferidos.
Quando você tem um modelo de objeto muito grande, pode ser difícil manter tudo em mente. É difícil escrever documentação atualizada constantemente. A documentação mais atualizada é o seu código, e nem sempre ele tem uma lógica de negócios totalmente escrita: o que deve funcionar e como, quem tinha o que em mente.

O que podemos verificar? Pelo menos que a migração comece. Isso já é ótimo. E que não há erros de digitação estúpidos no código. Podemos verificar se existe um método downgrade () válido, se o método downgrade () exclui todos os tipos de dados criados por SQLAlchemy.
SQLAlchemy faz muitas coisas boas. Por exemplo, quando você descreve uma tabela e especifica um tipo de coluna Enum, SQLAlchemy criará automaticamente um tipo de dados para esse enum no PostgreSQL. Mas o código para remover este tipo de dados no método downgrade () não será gerado automaticamente.
Você precisa se lembrar e verificar isto: quando você deseja reverter e reaplicar a migração, uma tentativa de criar um tipo de dados existente no método upgrade () lançará uma exceção. E o mais importante, se a migração alterar quaisquer dados, você precisa verificar se os dados mudam corretamente na atualização. E é muito importante verificar se eles são revertidos corretamente no downgrade sem efeitos colaterais.

Antes de passar para os próprios testes, vamos ver a melhor forma de nos preparar para escrevê-los. Já vi muitas abordagens para isso. Algumas pessoas criam uma base, placas e, em seguida, escrevem um acessório que limpa tudo, usando algum tipo de acessório de aplicação automática . Mas a maneira ideal de protegê-lo 100% e executar testes em um espaço completamente isolado é criar um banco de dados separado.
Existe um módulo sqlalchemy_utils incrível que pode criar e excluir bancos de dados. No PostgreSQL, ele também verifica: se um dos clientes adormeceu e não desconectou, ele não travará com o erro que “alguém está usando o banco de dados, não posso fazer nada com ele, não posso deletar”. Em vez disso, ele verá com calma quem se conectou a eles, desconectará esses clientes e excluirá a base com calma.
Construir um banco de dados e aplicar uma migração a cada teste nem sempre é um processo rápido. Isso pode ser resolvido da seguinte maneira: PostgreSQL suporta a criação de novos bancos de dados a partir de um modelo, então você pode dividir a preparação do banco de dados em dois fixtures.
O primeiro fixture é executado uma vez para executar todos os testes (escopo = sessão), cria um banco de dados e aplica as migrações a ele. O segundo acessório (escopo = função) cria bases diretamente para cada teste com base na base do primeiro acessório.
Criar um banco de dados a partir de um modelo é muito rápido e economiza tempo na aplicação de migrações para cada teste.

Se estamos apenas falando sobre como podemos criar temporariamente um banco de dados, então podemos escrever tal fixture. O que está acontecendo aqui? Iremos gerar um nome aleatório. Acrescentamos, por precaução, ao final do pytest, para que quando formos ao localhost para nós mesmos através de algum Postico, possamos entender o que foi criado pelos testes e o que não foi.
Em seguida, geramos a partir do link com informações de conexão ao banco de dados, que a pessoa apresentava, um novo, já com um novo banco de dados. Nós criamos e apenas enviamos para testes. Depois que uma pessoa trabalhou com esse banco de dados, nós o excluímos.

Também podemos preparar o Engine para se conectar a este banco de dados. Ou seja, neste equipamento nos referimos ao equipamento anterior usado como dependência. Criamos um Engine e enviamos para testes.

Então, quais testes podemos escrever? O primeiro teste é apenas uma invenção brilhante do meu colega. Desde que apareceu, acho que esqueci os problemas com as migrações.
Este é um teste muito simples. Você o adiciona ao seu projeto uma vez. Está no projeto no GitHub... Você pode simplesmente arrastar para você, adicionar e esquecer, talvez, cerca de 80 por cento dos problemas.
Ele faz uma coisa muito simples: obtém uma lista de todas as migrações e começa a iterar sobre elas. Chama upgrade, downgrade, upgrade.

Por exemplo, temos cinco migrações. Vamos ver como isso vai funcionar. Aqui está a primeira migração. Nós o cumprimos. Reverta a primeira migração, execute-a novamente. O que aconteceu aqui? Na verdade, vimos aqui que uma pessoa implementou corretamente o método downgrade (), pois duas vezes, por exemplo, não teria sido possível criar tabelas.
Vemos que se uma pessoa criou alguns tipos de dados, também os apagou, porque não existem erros de digitação e em geral pelo menos funciona de alguma forma.
Em seguida, o teste continua. Ele faz a segunda migração, corre imediatamente para ela, retrocede um passo e avança novamente. E isso acontece tantas vezes quanto você tem migrações.
O objetivo deste teste é encontrar erros básicos, problemas ao alterar a estrutura de dados.
A escada começa em uma base vazia e geralmente é muito rápida. Ou seja, este teste é mais sobre a estrutura de dados. Não se trata de alterar dados em migrações. Mas, no geral, pode salvar sua vida muito bem.
Se você quer uma solução rápida, é isso. Esta regra é. Como regra geral: insira-o em seu projeto e ficará mais fácil para você.

Este teste se parece com isso. Pegamos todas as revisões, geramos a configuração do Alembic. Aqui está o que vimos antes, o arquivo alembic.ini, aqui está a função get_alembic_config, ela lê esse arquivo, adiciona nossa base temporária a ele, porque especificamos o caminho para a base lá. E depois disso podemos usar os comandos Alembic.
O comando executado anteriormente - cabeça de atualização do alambique - também pode ser importado com segurança. Infelizmente, este slide não se aplica a todas as importações, mas acredite em mim. É apenas a partir da atualização de importação do alembic.com. Você traduz a configuração lá, diz onde fazer a atualização. Então diga: downgrade.
Com o downgrade, a migração é revertida para down_revision, ou seja, para a revisão anterior, ou para "-1".
"-1" é uma maneira alternativa de dizer ao Alembic para reverter a migração atual. É muito relevante quando a primeira migração começa, seu down_revision é None, enquanto a API Alembic não permite passar None para o comando downgrade.
Em seguida, o comando de atualização é executado novamente.
Agora vamos falar sobre como testar migrações com dados.

As migrações de dados são o tipo de coisa que geralmente parece muito simples, mas dói mais. Parece que você poderia escrever um select, inserir, obter dados de uma tabela e transferi-los para outra em um formato ligeiramente diferente - o que poderia ser mais simples?
Resta dizer sobre este teste que, ao contrário do anterior, é muito caro para desenvolver. Quando eu fazia grandes migrações, às vezes levava seis horas para olhar todas as invariáveis, é normal descrever tudo. Mas quando já estava rolando essas migrações, fiquei tranquilo.

Como funciona esse teste? A ideia é que apliquemos todas as migrações até aquela que agora queremos testar. Inserimos no banco de dados um conjunto de dados que serão alterados. Podemos pensar em inserir dados adicionais que podem mudar implicitamente. Então nós atualizamos. Verificamos se os dados foram alterados corretamente, executamos o downgrade e verificamos se os dados foram alterados corretamente.

O código se parece com isso. Ou seja, também há uma parametrização por revisão, há um conjunto de parâmetros. Aceitamos nosso motor aqui, aceitamos a migração com a qual queremos começar o teste.
Então rev_head, que é o que queremos testar. E então três retornos de chamada. Esses são os callbacks que definimos em algum lugar e eles serão chamados depois que algo for feito. Podemos verificar o que está acontecendo lá.
Onde posso ver um exemplo?
Juntei tudo em um exemplo no GitHub . Não há muito código lá, mas é muito difícil adicioná-lo ao slide. Tentei suportar o mais básico. Você pode ir ao GitHub e ver como funciona no próprio projeto, essa será a maneira mais fácil.
Em que mais vale a pena prestar atenção? Durante a inicialização, o Alembic procura o arquivo de configuração alembic.ini na pasta onde foi iniciado. Claro, você pode especificar o caminho usando a variável de ambiente ALEMBIC_CONFIG, mas isso nem sempre é conveniente e óbvio.
Outro problema: as informações para conexão com o banco de dados são especificadas no alembic.ini, mas geralmente você precisa da capacidade de trabalhar com vários bancos de dados. Por exemplo, implemente as migrações para o estágio e depois para a produção. Em geral, você pode especificar informações de conexão na variável de ambiente SQLALCHEMY_URL, mas isso não é muito óbvio para usuários finais de seu software.
Também será muito mais intuitivo para os usuários finais usar o utilitário "$ project $ -db" do que "alembic".
Ao examinar os exemplos do projeto, dê uma olhada no utilitário staff-db. É um invólucro fino em torno do Alambique e mais uma maneira de personalizá-lo para você. Por padrão, ele procura o arquivo alembic.ini no projeto em relação à sua localização. De qualquer pasta que os usuários chamem, ela própria encontrará o arquivo de configuração. Além disso, staff-db adiciona um argumento --db-url, com o qual você pode especificar informações para se conectar ao banco de dados. E, mais importante, veja isso passando a opção --help geralmente aceita. Afinal, o nome do utilitário é intuitivo.
Todos os comandos executáveis do projeto começam com o nome do módulo "staff": staff-api, que executa a API REST, e staff-db, que gerencia o estado base. Compreendendo esse padrão, o cliente escreverá o nome do seu programa e poderá ver todos os utilitários disponíveis pressionando a tecla TAB, mesmo que esqueça o nome completo. Eu tenho tudo, obrigado.