Enquanto linguagens como Python e R estão se tornando cada vez mais populares para a ciência de dados, C e C ++ podem ser escolhas fortes para resolver problemas de maneira eficiente na ciência de dados. Neste artigo, usaremos C99 e C ++ 11 para escrever um programa que funcione com o quarteto de Anscombe, que discutirei a seguir.
Eu escrevi sobre minha motivação para aprender constantemente línguas em um artigo sobre Python e GNU Octave que vale a pena ler. Todos os programas são para a linha de comando, não para uma interface gráfica do usuário (GUI). Exemplos completos estão disponíveis no repositório polyglot_fit.
Desafio de programação
O programa que você escreverá nesta série:
- Lê dados de um arquivo CSV
- Interpola os dados com uma linha reta (isto é, f (x) = m ⋅ x + q).
- Grava o resultado em um arquivo de imagem
Este é um desafio comum enfrentado por muitos cientistas de dados. Um exemplo de dados é o primeiro conjunto do quarteto de Anscombe, apresentado na tabela abaixo. Este é um conjunto de dados construídos artificialmente que fornece os mesmos resultados quando ajustados em uma linha reta, mas seus gráficos são muito diferentes. Um arquivo de dados é um arquivo de texto com guias para separar colunas e várias linhas que formam um cabeçalho. Esse problema usará apenas o primeiro conjunto (ou seja, as duas primeiras colunas).
Anscombe Quartet
Solução em C
C é uma linguagem de programação de uso geral que é uma das linguagens mais populares em uso atualmente (conforme medida pelo Índice TIOBE , Classificação de Idiomas de Programação RedMonk , Índice de Popularidade de Linguagem de Programação e pesquisa no GitHub ). É uma linguagem antiga (criada por volta de 1973) e muitos programas de sucesso foram escritos nela (por exemplo, o kernel do Linux e o Git). Esse idioma também é o mais próximo possível do funcionamento interno de um computador, pois é usado para gerenciamento direto de memória. Como é um idioma compilado , o código-fonte deve ser traduzido em código de máquina pelo compilador . Seua biblioteca padrão é pequena e de tamanho leve; portanto, outras bibliotecas foram desenvolvidas para fornecer a funcionalidade ausente.
Essa é a linguagem que eu mais uso para esmagar números , principalmente por causa de seu desempenho. Acho muito tedioso de usar, pois requer muito código padrão , mas é bem suportado em vários ambientes. O padrão C99 é uma revisão recente que adiciona alguns recursos bacanas e é bem suportada por compiladores.
Vou abordar os pré-requisitos para programação em C e C ++, para que usuários iniciantes e experientes possam usar essas linguagens.
Instalação
O desenvolvimento do C99 requer um compilador. Eu costumo usar o Clang , mas o GCC , outro compilador de código aberto completo , o fará . Para ajustar os dados, decidi usar a biblioteca científica GNU . Para plotar, não consegui encontrar nenhuma biblioteca razoável e, portanto, este programa depende de um programa externo: Gnuplot . O exemplo também usa uma estrutura de dados dinâmica para armazenar dados, definida no Berkeley Software Distribution (BSD ).
A instalação no Fedora é muito simples:
sudo dnf install clang gnuplot gsl gsl-develComentários do código
Em C99, os comentários são formatados adicionando // ao início da linha e o restante da linha será descartado pelo intérprete. Qualquer coisa entre / * e * / também é descartada.
// .
/* */Bibliotecas necessárias
Bibliotecas consistem em duas partes:
- Arquivo de cabeçalho contendo descrição das funções
- Arquivo de origem contendo definições de função
Os arquivos de cabeçalho estão incluídos no código-fonte e o código-fonte das bibliotecas está vinculado ao executável. Portanto, os arquivos de cabeçalho são necessários para este exemplo:
// -
#include <stdio.h>
//
#include <stdlib.h>
//
#include <string.h>
// "" BSD
#include <sys/queue.h>
// GSL
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>Função principal
Em C, o programa deve estar dentro de uma função especial chamada main () :
int main(void) {
...
}Aqui você pode notar uma diferença em relação ao Python, que foi discutido no último tutorial, porque no caso do Python, qualquer código que ele encontrar nos arquivos de origem será executado.
Definindo variáveis
Em C, as variáveis devem ser declaradas antes de serem usadas e devem estar associadas a um tipo. Sempre que quiser usar uma variável, você deve decidir quais dados serão armazenados nela. Você também pode indicar se você vai usar a variável como um valor constante, o que não é necessário, mas o compilador pode se beneficiar com essas informações. Exemplo do programa fitting_C99.c no repositório:
const char *input_file_name = "anscombe.csv";
const char *delimiter = "\t";
const unsigned int skip_header = 3;
const unsigned int column_x = 0;
const unsigned int column_y = 1;
const char *output_file_name = "fit_C99.csv";
const unsigned int N = 100;As matrizes em C não são dinâmicas no sentido de que seu comprimento deve ser determinado com antecedência (ou seja, antes da compilação):
int data_array[1024];Como você geralmente não sabe quantos pontos de dados estão no arquivo, use uma lista vinculada individualmente . É uma estrutura de dados dinâmica que pode crescer indefinidamente. Felizmente, o BSD fornece listas vinculadas individualmente . Aqui está um exemplo de definição:
struct data_point {
double x;
double y;
SLIST_ENTRY(data_point) entries;
};
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
SLIST_INIT(&head);Este exemplo define uma lista data_point , consistindo de valores estruturados que contêm ambos x e y valores . A sintaxe é bastante complexa, mas intuitiva, e uma descrição detalhada seria muito detalhada.
Imprimir
Para imprimir no terminal, você pode usar a função printf () , que funciona como a função printf () no Octave (descrita no primeiro artigo):
printf("#### C99 ####\n");A função printf () não adiciona automaticamente uma nova linha no final da linha impressa; portanto, você precisa adicioná-la. O primeiro argumento é uma string, que pode conter informações sobre o formato de outros argumentos que podem ser passados para a função, por exemplo:
printf("Slope: %f\n", slope);Lendo dados
Agora vem a parte complicada ... Existem várias bibliotecas para analisar arquivos CSV em C, mas nenhuma provou ser estável ou popular o suficiente para estar no repositório de pacotes do Fedora. Em vez de adicionar uma dependência para este tutorial, decidi escrever esta parte pessoalmente. Novamente, seria muito prolixo para entrar em detalhes, por isso vou explicar apenas a idéia geral. Algumas linhas no código-fonte serão ignoradas por questões de brevidade, mas você pode encontrar um exemplo completo no repositório.
Primeiro abra o arquivo de entrada:
FILE* input_file = fopen(input_file_name, "r");Em seguida, leia o arquivo linha por linha até que ocorra um erro ou até o arquivo terminar:
while (!ferror(input_file) && !feof(input_file)) {
size_t buffer_size = 0;
char *buffer = NULL;
getline(&buffer, &buffer_size, input_file);
...
}A função getline () é uma boa adição recente ao padrão POSIX.1-2008 . Ele pode ler uma linha inteira em um arquivo e cuidar da alocação da memória necessária. Cada linha é então dividida em tokens usando a função strtok () . Observando o token, selecione as colunas necessárias:
char *token = strtok(buffer, delimiter);
while (token != NULL)
{
double value;
sscanf(token, "%lf", &value);
if (column == column_x) {
x = value;
} else if (column == column_y) {
y = value;
}
column += 1;
token = strtok(NULL, delimiter);
}Por fim, com os valores x e y selecionados, adicione um novo ponto à lista:
struct data_point *datum = malloc(sizeof(struct data_point));
datum->x = x;
datum->y = y;
SLIST_INSERT_HEAD(&head, datum, entries);A função malloc () aloca (reserva) dinamicamente uma quantidade de memória permanente para um novo ponto.
Dados adequados
A função de interpolação linear da GSL gsl_fit_linear () aceita matrizes regulares como entrada. Portanto, como você não pode saber o tamanho das matrizes criadas antecipadamente, aloque manualmente a memória para elas:
const size_t entries_number = row - skip_header - 1;
double *x = malloc(sizeof(double) * entries_number);
double *y = malloc(sizeof(double) * entries_number);Em seguida, percorra a lista para armazenar os dados relevantes nas matrizes:
SLIST_FOREACH(datum, &head, entries) {
const double current_x = datum->x;
const double current_y = datum->y;
x[i] = current_x;
y[i] = current_y;
i += 1;
}Agora que você terminou a lista, limpe o pedido. Sempre libere memória que foi alocada manualmente para evitar vazamentos de memória . Vazamentos de memória são ruins, ruins e novamente ruins. Toda vez que a memória não é liberada, o gnomo do jardim perde a cabeça:
while (!SLIST_EMPTY(&head)) {
struct data_point *datum = SLIST_FIRST(&head);
SLIST_REMOVE_HEAD(&head, entries);
free(datum);
}Finalmente, finalmente (!), Você pode ajustar seus dados:
gsl_fit_linear(x, 1, y, 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);Plotando um gráfico
Para criar um gráfico, você deve usar um programa externo. Portanto, mantenha a função de ajuste em um arquivo externo:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
fprintf(output_file, "%f\t%f\n", current_x, current_y);
}O comando de plotagem do Gnuplot se parece com o seguinte:
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'resultados
Antes de executar o programa, você precisa compilá-lo:
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99Este comando instrui o compilador a usar o padrão C99, ler o arquivo de acessório_C99.c, carregar as bibliotecas gsl e gslcblas e salvar o resultado em acessório_C99. A saída resultante na linha de comandos:
#### C99 ####
: 0.500091
: 3.000091
: 0.816421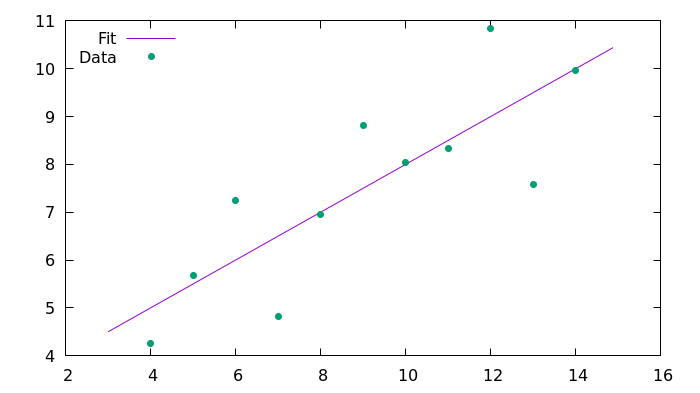
Aqui está a imagem resultante gerada usando o Gnuplot.
Solução C ++ 11
C ++ é uma linguagem de programação de uso geral que também é uma das linguagens mais populares em uso atualmente. Foi criado como o sucessor da linguagem C (em 1983), com ênfase na programação orientada a objetos (OOP). C ++ é geralmente considerado um superconjunto de C, portanto, um programa C deve ser compilado com um compilador C ++. Isso nem sempre é o caso, pois há alguns casos extremos em que eles se comportam de maneira diferente. Na minha experiência, o C ++ requer menos código padrão do que o C, mas sua sintaxe é mais complexa se você deseja projetar objetos. O padrão C ++ 11 é uma revisão recente que adiciona alguns recursos bacanas que são mais ou menos suportados pelos compiladores.
Como o C ++ é praticamente compatível com o C, focarei apenas nas diferenças entre os dois. Se eu não descrever uma seção nesta parte, significa que é a mesma que em C.
Instalação
As dependências para C ++ são as mesmas do exemplo C. No Fedora, execute o seguinte comando:
sudo dnf install clang gnuplot gsl gsl-develBibliotecas necessárias
As bibliotecas funcionam da mesma forma que em C, mas as diretivas de inclusão são um pouco diferentes:
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
extern "C" {
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
}Como as bibliotecas GSL são escritas em C, o compilador precisa ser informado sobre esse recurso.
Definindo variáveis
O C ++ suporta mais tipos de dados (classes) que C, por exemplo, o tipo de string, que possui muito mais recursos do que seu equivalente em C. Atualize suas definições de variável de acordo:
const std::string input_file_name("anscombe.csv");Para objetos estruturados, como seqüências de caracteres, você pode definir uma variável sem usar o sinal = .
Imprimir
Você pode usar a função printf () , mas é mais comum usar cout . Use o operador << para especificar a sequência (ou objetos) que você deseja imprimir com o cout :
std::cout << "#### C++11 ####" << std::endl;
...
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;Lendo dados
O circuito é o mesmo de antes. O arquivo é aberto e lido linha por linha, mas com uma sintaxe diferente:
std::ifstream input_file(input_file_name);
while (input_file.good()) {
std::string line;
getline(input_file, line);
...
}Os tokens de string são recuperados pela mesma função que no exemplo C99. Use dois vetores em vez de matrizes C padrão . Os vetores são uma extensão das matrizes C na biblioteca padrão C ++ para gerenciar dinamicamente a memória sem chamar malloc () :
std::vector<double> x;
std::vector<double> y;
// x y
x.emplace_back(value);
y.emplace_back(value);Dados adequados
Para ajustar dados no C ++, você não precisa se preocupar com listas, pois é garantido que os vetores têm memória seqüencial. Você pode passar ponteiros diretamente para buffers de vetor para as funções de ajuste:
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;Plotando um gráfico
A plotagem é feita da mesma maneira que antes. Escreva no arquivo:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
output_file << current_x << "\t" << current_y << std::endl;
}
output_file.close();Em seguida, use o Gnuplot para plotar o gráfico.
resultados
Antes de executar o programa, ele deve ser compilado com um comando semelhante:
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11Saída resultante na linha de comandos:
#### C++11 ####
: 0.500091
: 3.00009
: 0.816421E aqui está a imagem resultante, gerada com o Gnuplot.
Conclusão
Este artigo fornece exemplos de ajuste e plotagem de dados em C99 e C ++ 11. Como o C ++ é amplamente compatível com o C, este artigo usa as semelhanças para escrever um segundo exemplo. Em alguns aspectos, o C ++ é mais fácil de usar, pois alivia parcialmente a carga do gerenciamento explícito da memória, mas sua sintaxe é mais complexa, pois introduz a capacidade de escrever classes para OOP. No entanto, você também pode escrever em C usando técnicas de OOP, já que OOP é um estilo de programação e pode ser usado em qualquer idioma. Existem alguns ótimos exemplos de OOP em C, como as bibliotecas GObject e Jansson .
Prefiro usar o C99 para trabalhar com números devido à sua sintaxe mais simples e suporte mais amplo. Até recentemente, o C ++ 11 não era amplamente suportado e tentei evitar as arestas nas versões anteriores. Para softwares mais complexos, o C ++ pode ser uma boa escolha.
Você está usando C ou C ++ para Data Science? Compartilhe sua experiência nos comentários.

Descubra os detalhes de como obter uma profissão de alto nível do zero ou subir de nível em habilidades e salário fazendo os cursos on-line pagos do SkillFactory:
- Curso de Machine Learning (12 semanas)
- Treinamento da profissão em Data Science (12 meses)
- Profissão analítica com qualquer nível inicial (9 meses)
- Curso Python para Desenvolvimento Web (9 meses)