Neste artigo, quero falar sobre como nossa equipe decidiu aplicar a abordagem CQRS e Event Sourcing em um projeto que é um site de leilão online. E também sobre o que resultou disso, quais conclusões podem ser tiradas de nossa experiência e qual rake é importante para não pisar naqueles que seguem o CQRS & ES.

Prelúdio
Para começar, um pouco de história e histórico de negócios. Um cliente veio até nós com uma plataforma para realizar os chamados leilões cronometrados, que já estavam em produção e nos quais uma certa quantidade de feedback foi coletada. O cliente queria que criassemos uma plataforma para leilões ao vivo para ele.
Agora um pouco de terminologia. Um leilão é quando determinados itens são vendidos - lotes e compradores (licitantes) fazem lances. O proprietário do lote é o comprador que ofereceu o lance mais alto. Leilão cronometrado é quando cada lote tem um tempo de fechamento predeterminado. Os compradores fazem apostas, em algum momento o lote está fechado. Semelhante ao ebay.
A plataforma cronometrada foi feita de maneira clássica, usando CRUD. Os lotes foram fechados por um aplicativo separado, iniciando em uma programação. Tudo isso não funcionou com muita confiabilidade: algumas apostas foram perdidas, outras foram feitas como se fosse em nome do comprador errado, os lotes não foram fechados ou fechados várias vezes.
O leilão ao vivo é uma oportunidade de participar de um leilão off-line real remotamente via Internet. Há uma sala (em nossa terminologia interna - "sala"), que contém o anfitrião do leilão com um martelo e a platéia, e bem ao lado do laptop está o chamado funcionário, que, pressionando os botões em sua interface, transmite o curso do leilão para a Internet e os conectados No momento do leilão, os compradores veem lances que estão sendo colocados offline e podem fazer seus lances.
Ambas as plataformas funcionam, em princípio, em tempo real, mas se no tempo programado todos os compradores estiverem em uma posição igual, no caso de viver, é extremamente importante que os compradores online possam competir com sucesso com os da sala. Ou seja, o sistema deve ser muito rápido e confiável. A triste experiência da plataforma cronometrada nos disse, em termos inequívocos, que o CRUD clássico não era adequado para nós.
Como não tínhamos nossa própria experiência em trabalhar com o CQRS & ES, consultamos colegas que o possuíam (temos uma grande empresa), apresentamos a realidade de nossos negócios e chegamos à conclusão de que o CQRS & ES deve nos atender.
Quais são as especificidades dos leilões online:
- — . , « », , . — , 5 . .
- , , .
- — - , , — .
- , .
- A solução deve ser escalável - vários leilões podem ser realizados simultaneamente.
Uma breve visão geral da abordagem CQRS & ES
Não vou me debruçar sobre a consideração da abordagem CQRS & ES, existem materiais sobre isso na Internet e, em particular, sobre Habré (por exemplo, aqui: Introdução ao CQRS + Event Sourcing ). No entanto, lembrarei brevemente os principais pontos:
- A coisa mais importante na fonte de eventos: o sistema não armazena dados, mas o histórico de suas alterações, ou seja, eventos. O estado atual do sistema é obtido pela aplicação seqüencial de eventos.
- O modelo de domínio é dividido em entidades chamadas agregadas. A unidade possui uma versão. Eventos são aplicados a agregados. A aplicação de um evento a um agregado incrementa sua versão.
- write-. , .
- . . , , . «» . .
- , , - ( N- ) . «» . , .
- - , , , , write-.
- write-, read-, , . read- . Read- .
- , — Command Query Responsibility Segregation (CQRS): , , write-; , , read-.

. .
Para economizar tempo, bem como devido à falta de experiência específica, decidimos que precisamos usar algum tipo de estrutura para CQRS e ES.
Em geral, nossa pilha de tecnologias é a Microsoft, ou seja, .NET e C #. Banco de Dados - Microsoft SQL Server. Tudo está hospedado no Azure. Uma plataforma cronometrada foi criada nessa pilha; era lógico criar uma plataforma ao vivo nela.
Naquela época, como me lembro agora, Chinchilla era quase a única opção adequada para nós em termos de pilha tecnológica. Então nós a pegamos.
Por que precisamos de uma estrutura CQRS & ES? Ele pode "imediatamente" resolver problemas e apoiar aspectos de implementação como:
- Entidades agregadas, comandos, eventos, controle de versão agregado, reidratação, mecanismo de captura instantânea.
- Interfaces para trabalhar com diferentes DBMS. Salvando / carregando eventos e capturas instantâneas de agregados de / para a base de gravação (armazenamento de eventos).
- Interfaces para trabalhar com filas - enviando comandos e eventos para as filas apropriadas, lendo comandos e eventos da fila.
- Interface para trabalhar com websockets.
Assim, levando em consideração o uso de Chinchilla, adicionamos à nossa pilha:
- Barramento de Serviço do Azure como um barramento de comando e evento, o Chinchilla oferece suporte imediato;
- Os bancos de dados de gravação e leitura são o Microsoft SQL Server, ou seja, são os dois bancos de dados SQL. Não direi que esse é o resultado de uma escolha consciente, mas por razões históricas.
Sim, o frontend é feito em Angular.
Como eu já disse, um dos requisitos para o sistema é que os usuários aprendam o mais rápido possível sobre os resultados de suas ações e as ações de outros usuários - isso se aplica tanto aos clientes quanto ao funcionário. Portanto, usamos SignalR e websockets para atualizar rapidamente os dados no frontend. Chinchilla suporta integração SignalR.
Seleção de unidades
Uma das primeiras coisas a fazer ao implementar a abordagem CQRS & ES é determinar como o modelo de domínio será dividido em agregados.
No nosso caso, o modelo de domínio consiste em várias entidades principais, algo como isto:
public class Auction
{
public AuctionState State { get; private set; }
public Guid? CurrentLotId { get; private set; }
public List<Guid> Lots { get; }
}
public class Lot
{
public Guid? AuctionId { get; private set; }
public LotState State { get; private set; }
public decimal NextBid { get; private set; }
public Stack<Bid> Bids { get; }
}
public class Bid
{
public decimal Amount { get; set; }
public Guid? BidderId { get; set; }
}
Temos dois agregados: Leilão e Lote (com lances). Em geral, é lógico, mas não levamos em conta uma coisa - o fato de que com essa divisão, o estado do sistema estava espalhado por duas unidades e, em alguns casos, para manter a consistência, precisamos fazer alterações nas duas unidades, e não em uma. Por exemplo, um leilão pode ser pausado. Se o leilão estiver em pausa, você não poderá fazer lances no lote. Seria possível pausar o lote propriamente dito, mas um leilão pausado não pode processar nenhum comando além de "não pausar".
Como alternativa, apenas um agregado pode ser criado, Leilão, com todos os lotes e lances dentro. Mas esse objeto será bastante difícil, porque pode haver até vários milhares de lotes no leilão e várias dezenas de lances para um lote. Durante o tempo de vida do leilão, esse agregado terá várias versões e a reidratação de um agregado (aplicação seqüencial de todos os eventos no agregado), se nenhum instantâneo de agregados for feito, levará muito tempo. O que é inaceitável para a nossa situação. Se você usar snapshots (nós os usamos), os próprios snapshots pesarão muito.
Por outro lado, para garantir que as alterações sejam aplicadas a dois agregados no processamento de uma única ação do usuário, você deve alterar os dois agregados no mesmo comando usando uma transação ou executar dois comandos na mesma transação. Ambos são, em geral, uma violação da arquitetura.
Tais circunstâncias devem ser levadas em consideração ao decompor o modelo de domínio em agregados.
Nesta fase da evolução do projeto, vivemos com duas unidades, Auction e Lot, e quebramos a arquitetura alterando as duas unidades dentro de alguns comandos.
Aplicando um comando a uma versão específica de um agregado
Se vários compradores fizerem um lance no mesmo lote ao mesmo tempo, ou seja, eles enviarem um comando "fazer um lance" ao sistema, apenas um dos lances será bem-sucedido. Muito é um agregado, tem uma versão. Durante o processamento do comando, são gerados eventos, cada um dos quais incrementa a versão do agregado. Existem dois caminhos a seguir:
- Envie um comando especificando em qual versão do agregado queremos aplicá-lo. Em seguida, o manipulador de comandos pode comparar imediatamente a versão no comando com a versão atual da unidade e não continuar se não corresponder.
- Não especifique a versão da unidade no comando. Em seguida, o agregado é reidratado com alguma versão, a lógica de negócios correspondente é executada, os eventos são gerados. E somente quando elas são salvas, pode ser executada uma execução que já existe essa versão da unidade. Porque alguém fez isso antes.
Nós usamos a segunda opção. Isso dá às equipes uma melhor chance de serem executadas. Como na parte do aplicativo que envia comandos (no nosso caso, esse é o front-end), a versão atual do agregado com alguma probabilidade ficará atrás da versão real no back-end. Especialmente nas condições em que muitos comandos são enviados e a versão da unidade muda com frequência.
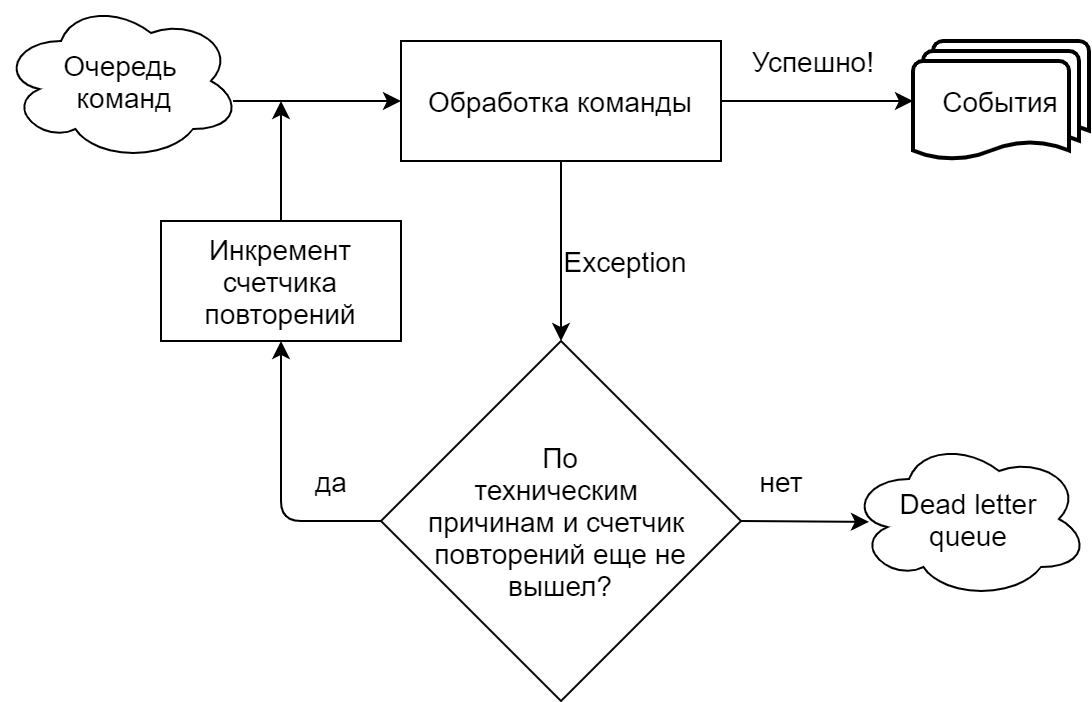
Erros ao executar um comando usando uma fila
Em nossa implementação, fortemente orientada pelo Chinchilla, o manipulador de comandos lê comandos de uma fila (Microsoft Azure Service Bus). Distinguimos claramente situações em que uma equipe falha por razões técnicas (tempos limite, erros na conexão com uma fila / base) e quando por razões comerciais (uma tentativa de fazer uma oferta com a mesma quantia que já foi aceita, etc.). No primeiro caso, a tentativa de executar o comando é repetida até que o número de repetições especificado nas configurações da fila seja atingido, após o que o comando é enviado para a Fila de mensagens não entregues (um tópico separado para mensagens não processadas no Barramento de Serviço do Azure). No caso de uma execução comercial, a equipe é enviada para a fila de devoluções imediatamente.
Erros ao manipular eventos usando uma fila
Eventos gerados como resultado da execução de comandos, dependendo da implementação, também podem ser enviados para a fila e retirados da fila pelos manipuladores de eventos. E ao lidar com eventos, também ocorrem erros.
No entanto, em contraste com a situação com um comando não executado, tudo é pior aqui - pode acontecer que o comando tenha sido executado e os eventos tenham sido gravados na base de gravação, mas seu processamento pelos manipuladores falhou. E se um desses manipuladores atualizar a base de leitura, a base de leitura não será atualizada. Ou seja, ele estará em um estado inconsistente. Devido ao mecanismo para tentar novamente o evento de leitura, o banco de dados quase sempre é atualizado no final, mas a probabilidade de que, após todas as tentativas, permaneça interrompida ainda permanece.
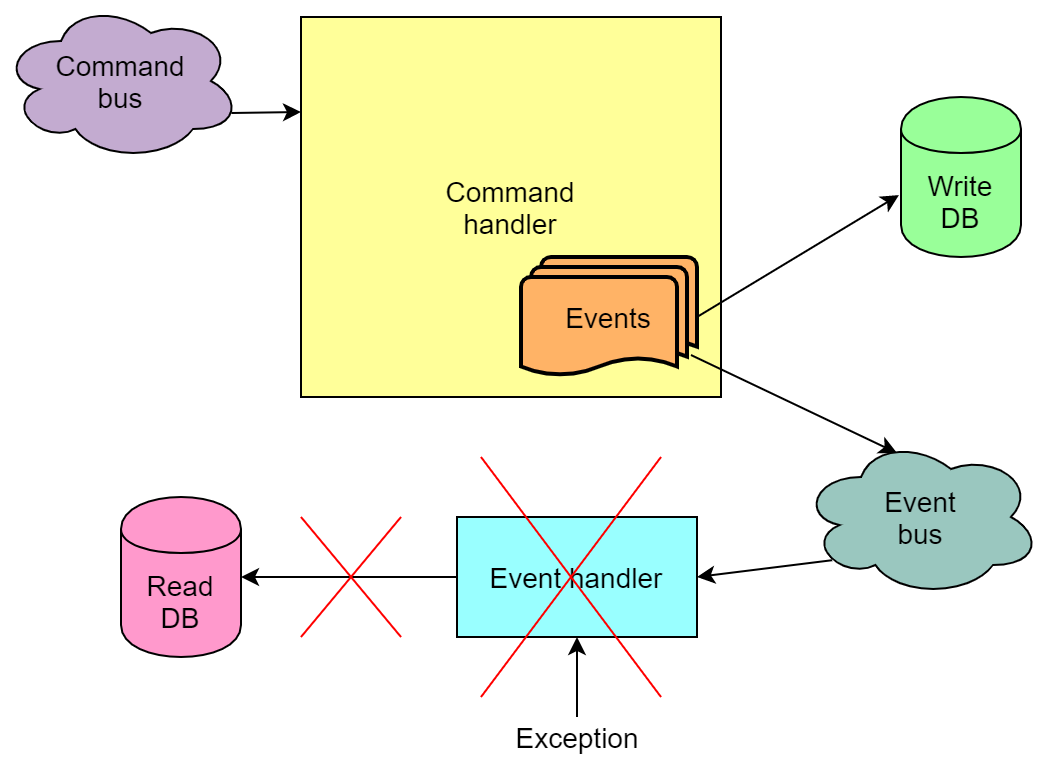
Encontramos esse problema em casa. O motivo, no entanto, foi em grande parte devido ao fato de termos uma lógica de negócios no processamento de eventos, que, com um intenso fluxo de apostas, tem boas chances de falhar de tempos em tempos. Infelizmente, percebemos isso tarde demais, não era possível refazer a implementação de negócios de maneira rápida e simples.
Como resultado, como medida temporária, paramos de usar o Barramento de Serviço do Azure para transferir eventos da parte de gravação do aplicativo para a parte de leitura. Em vez disso, é usado o chamado Barramento na Memória, que permite processar o comando e os eventos em uma transação e, em caso de falha, reverter tudo.
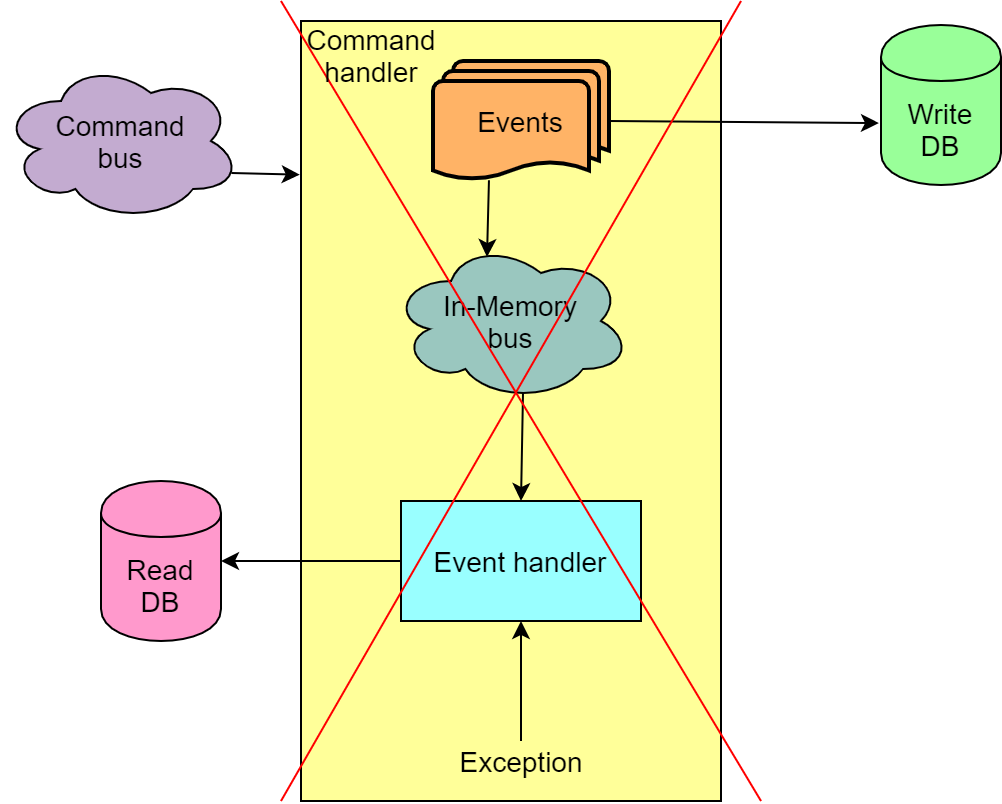
Essa solução não contribui para a escalabilidade, mas, por outro lado, excluímos situações em que nossa base de leitura é interrompida, o que, por sua vez, divide os frontends e torna-se impossível continuar o leilão sem recriar a base de leitura repetindo todos os eventos.
Enviando um comando em resposta a um evento
Isso é, em princípio, apropriado, mas apenas no caso em que a falha na execução deste segundo comando não quebra o estado do sistema.
Manipulando Vários Eventos de um Comando
Em geral, a execução de um comando resulta em vários eventos. Acontece que, para cada um dos eventos, precisamos fazer algumas alterações no banco de dados de leitura. Também acontece que a sequência de eventos também é importante e, na sequência incorreta, o processamento de eventos não funcionará como deveria. Tudo isso significa que não podemos ler da fila e processar os eventos de um comando independentemente, por exemplo, com diferentes instâncias de código que lê mensagens da fila. Além disso, precisamos de uma garantia de que os eventos da fila serão lidos na mesma sequência em que foram enviados para lá. Ou precisamos estar preparados para o fato de que nem todos os eventos de comando serão processados com sucesso na primeira tentativa.
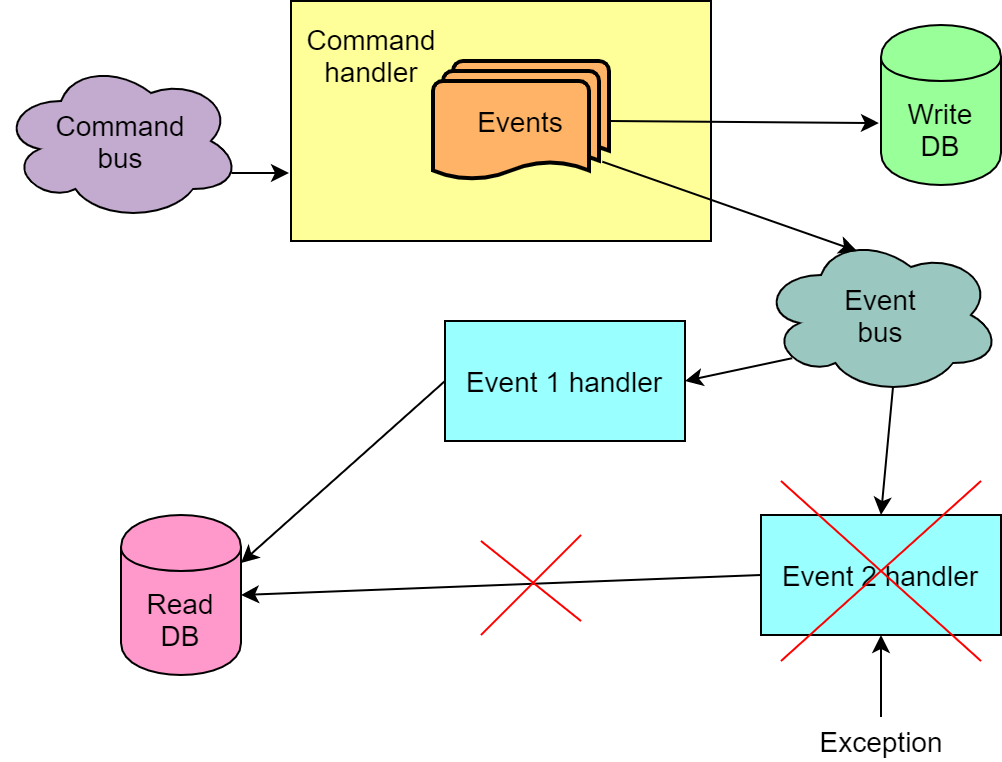
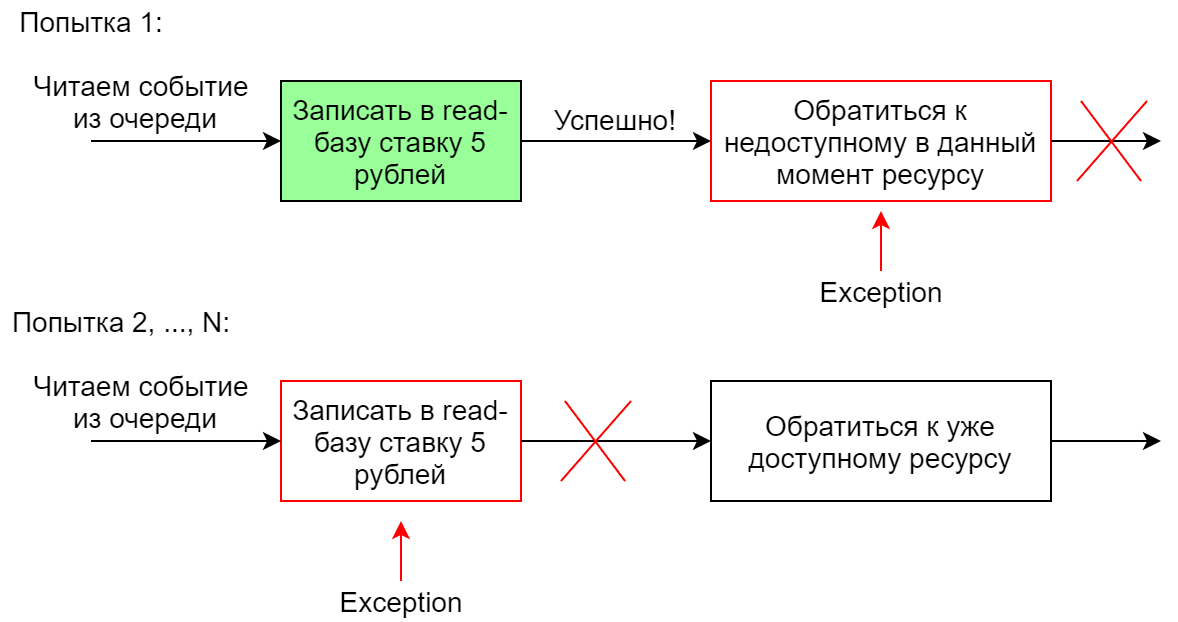
Manipulando um evento com vários manipuladores
Se o sistema precisar executar várias ações diferentes em resposta a um evento, geralmente vários manipuladores para esse evento são feitos. Eles podem trabalhar em paralelo ou sequencialmente. No caso de um lançamento seqüencial, se um dos manipuladores falhar, a sequência inteira será reiniciada (é o caso no Chinchilla). Com essa implementação, é importante que os manipuladores sejam idempotentes para que a segunda execução de um manipulador executado uma vez com êxito não falhe. Caso contrário, quando o segundo manipulador cair da cadeia, ele definitivamente não funcionará completamente, porque o primeiro manipulador cairá nas segundas (e subseqüentes) tentativas.
Por exemplo, um manipulador de eventos na base de leitura adiciona um lance para 5 rublos. A primeira tentativa de fazer isso será bem-sucedida e a segunda não permitirá que a restrição seja executada no banco de dados.
Conclusões / Conclusão
Agora, nosso projeto está em um estágio em que, como nos parece, já pisamos na maioria dos ancinhos existentes que são relevantes para as especificidades de nossos negócios. Em geral, consideramos nossa experiência bastante bem-sucedida, o CQRS & ES é adequado para nossa área de atuação. O desenvolvimento do projeto é visto no abandono da chinchila em favor de outra estrutura que dê mais flexibilidade. No entanto, também é possível recusar o uso da estrutura. Também é provável que ocorram algumas mudanças na direção de encontrar um equilíbrio entre a confiabilidade, por um lado, e a velocidade e a escalabilidade da solução, por outro.
Quanto ao componente de negócios, aqui também algumas questões permanecem em aberto - por exemplo, dividindo o modelo de domínio em agregados.
Eu gostaria de esperar que nossa experiência seja útil para alguém, ajude a economizar tempo e evite um rake. Agradecimentos para sua atenção.