Eu acredito que quase todos os projetos que usam Ruby on Rails e Postgres como a principal arma no back-end estão em uma luta constante entre a velocidade do desenvolvimento, a legibilidade / manutenção do código e a velocidade do projeto na produção. Vou lhe contar sobre minha experiência de equilibrar essas três baleias em um caso em que a legibilidade e a velocidade do trabalho sofreram na entrada e, no final, acabou fazendo o que vários engenheiros talentosos tentaram fazer antes de mim sem sucesso.

A história toda terá várias partes. Este é o primeiro em que falarei sobre o que o PMDSC é para otimizar consultas SQL, compartilhar ferramentas úteis para medir o desempenho das consultas no postgres e lembrar-me de uma cábula antiga útil que ainda é relevante.
Agora, depois de algum tempo, "em retrospectiva", entendo que, na entrada deste caso, eu não esperava que tivesse sucesso. Portanto, este post será útil para desenvolvedores mais ousados e não mais experientes do que para super-idosos que viram trilhos com SQL simples.
Dados de entrada
Nós da Appbooster estamos promovendo aplicativos móveis. Para apresentar e testar hipóteses com facilidade, desenvolvemos várias de nossas aplicações. O back-end para a maioria deles é a API do Rails e o Postgresql.
O herói desta publicação está em desenvolvimento desde o final de 2013 - os trilhos 4.1.0.beta1 acabavam de ser lançados. Desde então, o projeto cresceu para um aplicativo Web totalmente carregado, executado em vários servidores no Amazon EC2 com uma instância de banco de dados separada no Amazon RDS (db.t3.xlarge com 4 vCPUs e 16 GB de RAM). As cargas de pico atingem 25k RPM, carga média do dia 8-10k RPM.
Essa história começou com uma instância de banco de dados, ou melhor, com seu saldo de crédito.
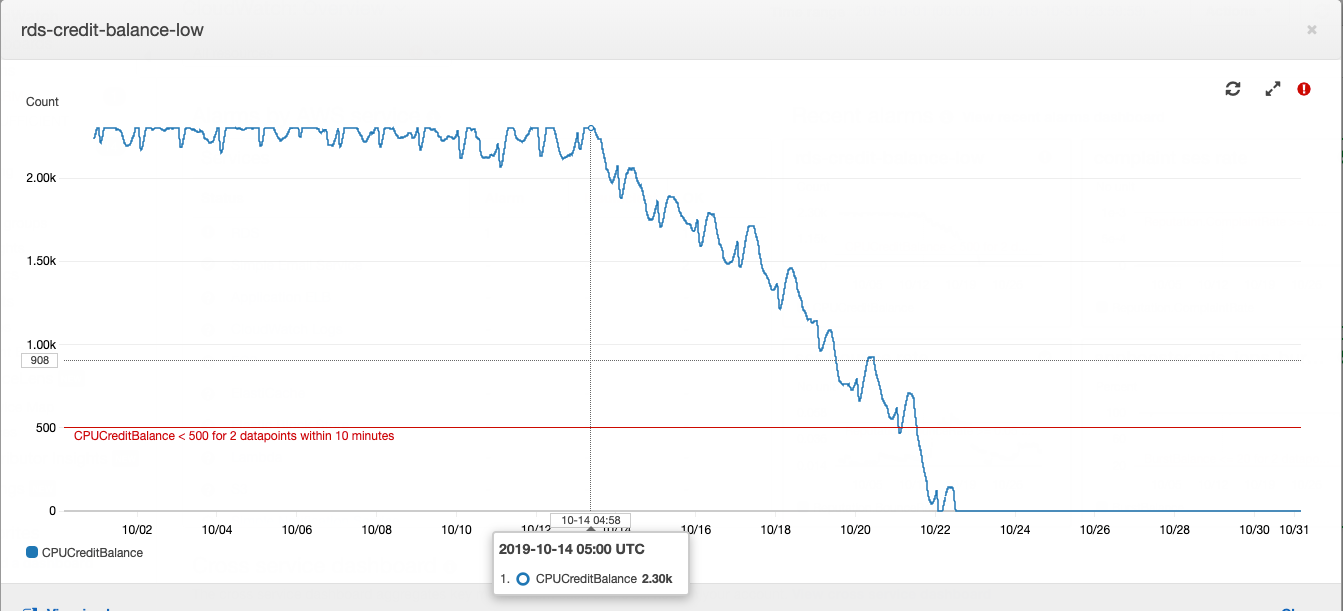
Como uma instância do tipo Postgres “t” funciona no Amazon RDS: se o seu banco de dados estiver executando com um consumo médio de CPU abaixo de um determinado valor, você acumulará créditos em sua conta, que a instância poderá gastar no consumo de CPU durante horas de carga alta - isso economiza em excesso para capacidade do servidor e para lidar com alta carga. Mais detalhes sobre o quanto e quanto pagam usando a AWS podem ser encontrados no artigo de nosso CTO .
O saldo dos empréstimos em um determinado momento estava esgotado. Por algum tempo, isso não teve muita importância, porque o saldo dos empréstimos pode ser reabastecido com dinheiro - custa cerca de US $ 20 por mês, o que não é muito perceptível para o custo total do aluguel da energia da computação. No desenvolvimento de produtos, é costume, em primeiro lugar, prestar atenção às tarefas formuladas a partir dos requisitos de negócios. O aumento do consumo de CPU do servidor de banco de dados se encaixa em dívidas técnicas e é compensado pelo pequeno custo de compra de um saldo credor.
Um belo dia, escrevi no resumo diário que estava muito cansado de apagar os “incêndios” que apareciam periodicamente em diferentes partes do projeto. Se isso continuar, o desenvolvedor esgotado dedicará tempo às tarefas de negócios. No mesmo dia, fui ao gerente principal do projeto, expliquei o alinhamento e pedi tempo para investigar as causas dos incêndios e reparos periódicos. Tendo recebido a aprovação, comecei a coletar dados de vários sistemas de monitoramento.
Usamos a Newrelic para rastrear o tempo total de resposta por dia. A imagem ficou assim:
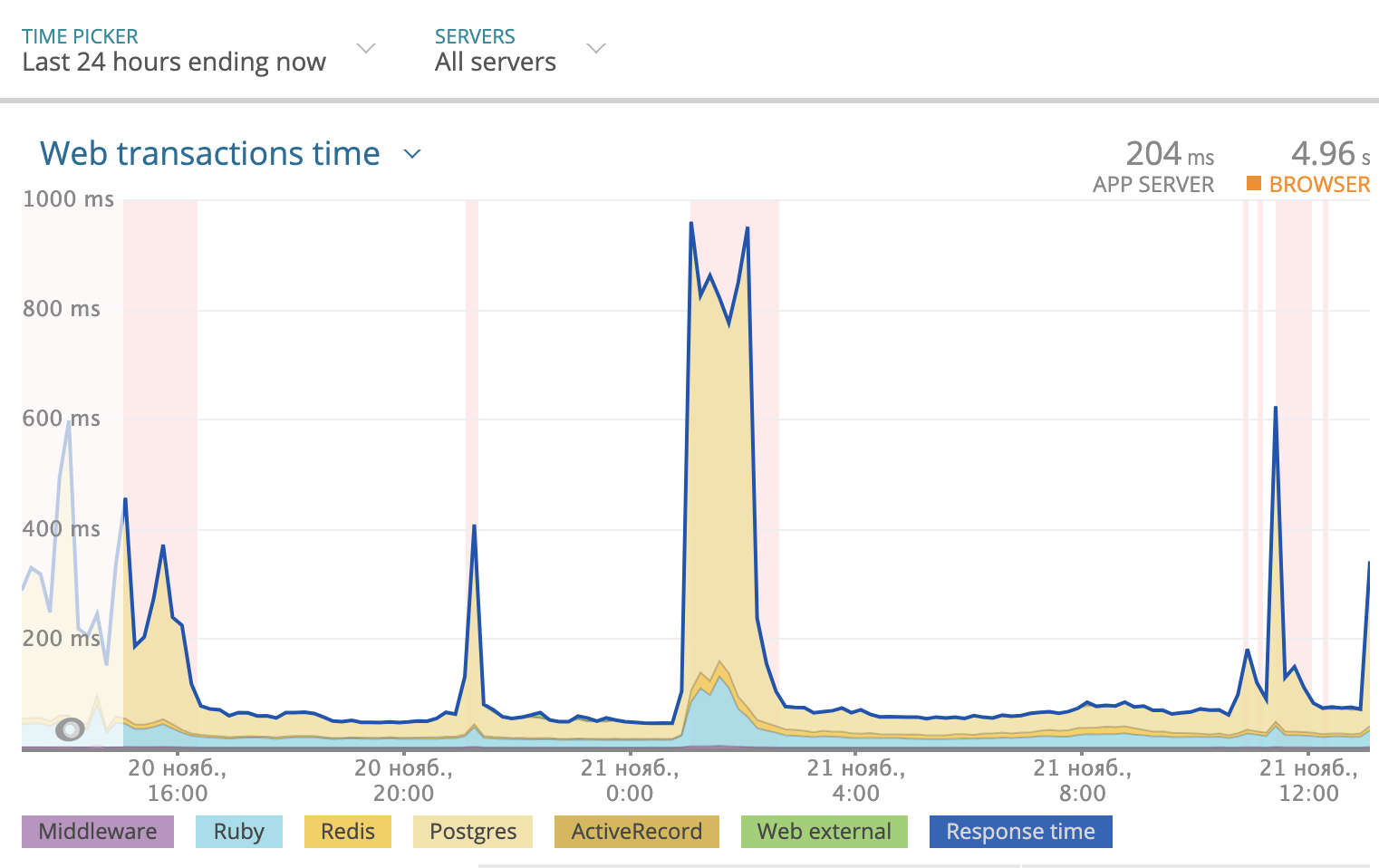
Parte do tempo de resposta que o Postgres leva é destacada em amarelo no gráfico. Como você pode ver, algumas vezes o tempo de resposta chegou a 1000 ms e, na maioria das vezes, foi o banco de dados que ponderou a resposta. Então, você precisa observar o que está acontecendo com as consultas SQL.
PMDSC é uma prática simples e direta para qualquer trabalho chato de otimização de SQL
Jogue!
Meça isto!
Desenhe isso!
Suponha!
Verifique-o!
Jogue!
Talvez a parte mais importante de toda a prática. Quando alguém diz a frase "Otimizando consultas SQL" - causa um bocejo e tédio na grande maioria das pessoas. Quando você diz "Investigação de detetive e procura vilões perigosos" - ele envolve mais e coloca você no humor certo. Portanto, é importante entrar no jogo. Eu gostava de brincar de detetive. Imaginei que os problemas com o banco de dados fossem criminosos perigosos ou doenças raras. E ele se imaginou no papel de Sherlock Holmes, tenente Columbo ou Doctor House. Escolha um herói ao seu gosto e pronto!
Meça isto!

Para analisar as estatísticas da solicitação, instalei o PgHero . Esta é uma maneira muito conveniente de ler dados da extensão pg_stat_statements Postgres. Acesse / consultas e veja as estatísticas de todas as consultas nas últimas 24 horas. Classificando consultas por padrão, de acordo com a coluna Tempo Total - a proporção do tempo total em que o banco de dados processa a consulta - uma fonte valiosa para encontrar suspeitos. Tempo médio - quantos, em média, a solicitação é executada. Chamadas - quantas solicitações foram feitas durante o tempo selecionado. O PgHero considera as solicitações lentas se forem executadas mais de 100 vezes por dia e levam mais de 20 milissegundos em média. Lista de consultas lentas na primeira página, imediatamente após a lista de índices duplicados.

Pegamos o primeiro da lista e olhamos para os detalhes da consulta, você pode vê-la explicar imediatamente analisar. Se o tempo de planejamento for muito menor que o tempo de execução, algo está errado com essa solicitação e estamos concentrando nossa atenção nesse suspeito.
O PgHero possui seu próprio método de visualização, mas eu gostei de usar o explica.depesz.com mais, copiando dados da análise de explicação lá.
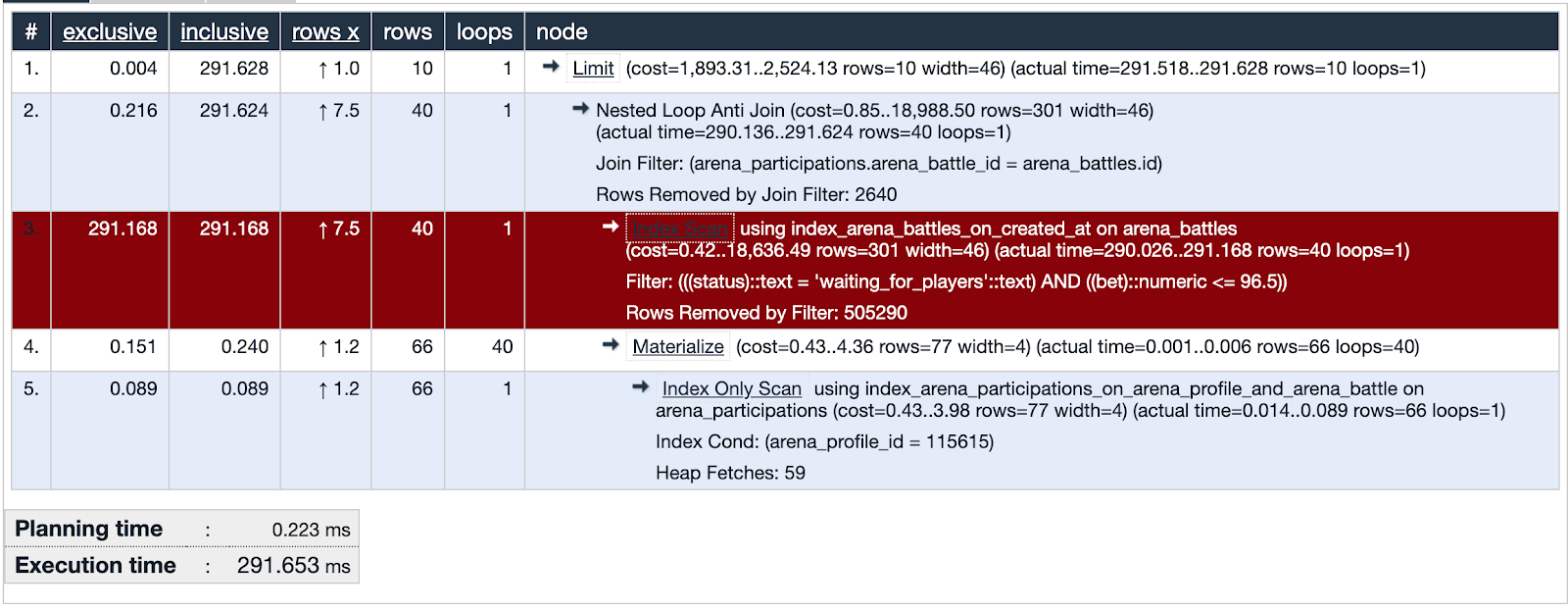
Uma das consultas suspeitas está usando a Index Index. A visualização mostra que esse índice não é eficaz e é um ponto fraco - destacado em vermelho. Bem! Examinamos as pistas do suspeito e encontramos evidências importantes! A justiça é inevitável!
Desenhe isso!
Vamos desenhar muitos dados usados na parte problemática da consulta. Será útil comparar com quais dados o índice cobre.
Um pouco de contexto. Testamos uma das maneiras de manter o público no aplicativo - algo como uma loteria na qual você pode ganhar uma moeda local. Você faz uma aposta, adivinha um número de 0 a 100 e pega o pote inteiro se o seu número estiver mais próximo do que o gerador de números aleatórios recebeu. Nós o chamamos de “Arena” e os comícios de “Batalhas”.

O banco de dados no momento da investigação contém cerca de quinhentos mil registros de batalhas. Na parte problemática da solicitação, estamos procurando batalhas nas quais a taxa não exceda o saldo do usuário e o status da batalha aguarde pelos jogadores. Vemos que a interseção de conjuntos (destacada em laranja) é um número muito pequeno de registros.
O índice usado na parte suspeita da solicitação abrange todas as batalhas criadas no campo created_at. A solicitação é executada através de 505330 registros dos quais seleciona 40 e 505290 elimina. Parece muito inútil.
Suponha!
Apresentamos uma hipótese. O que ajudará o banco de dados a encontrar quarenta entre quinhentos mil registros? Vamos tentar criar um índice que cubra o campo da taxa, apenas para batalhas com o status "aguardando jogadores" - um índice parcial.
add_index :arena_battles, :bet,
where: "status = 'waiting_for_players'",
name: "index_arena_battles_on_bet_partial_status"
Índice parcial - existe apenas para os registros que correspondem à condição: o campo de status é igual a "aguardando jogadores" e indexa o campo de taxa - exatamente o que está na condição de consulta. É muito benéfico usar esse índice específico: são necessários apenas 40 kilobytes e não cobrem as batalhas que já foram disputadas e não precisamos obter uma amostra. Para comparação, o índice index_arena_battles_on_created_at, usado pelo suspeito, leva cerca de 40 MB e a tabela com batalhas é de cerca de 70 MB. Este índice pode ser removido com segurança se outras consultas não o utilizarem.
Verifique-o!
Lançamos a migração com o novo índice para a produção e observamos como a resposta do terminal com batalhas mudou.
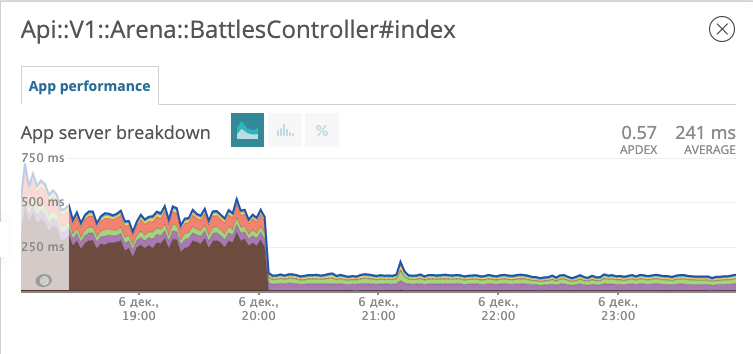
O gráfico mostra a que horas lançamos a migração. Na noite de 6 de dezembro, o tempo de resposta diminuiu cerca de 10 vezes, de ~ 500 ms para ~ 50ms. O suspeito no tribunal recebeu o status de prisioneiro e agora está na prisão. Bem!
Fuga da prisão
Alguns dias depois, percebemos que éramos felizes cedo. Parece que o prisioneiro encontrou cúmplices, desenvolveu e implementou um plano de fuga.
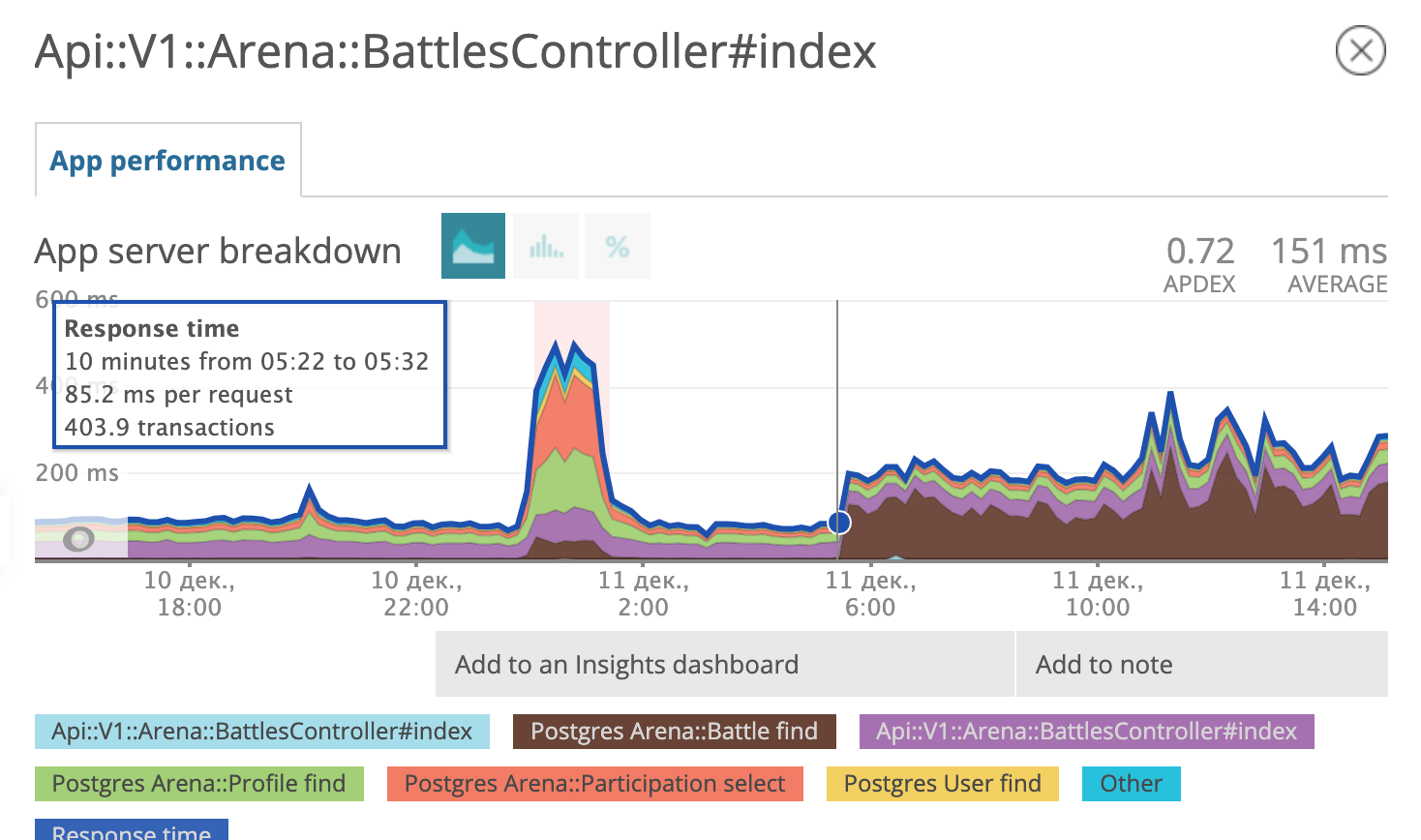
Na manhã de 11 de dezembro, o agendador de consultas do postgres decidiu que o uso de um novo índice analisado não era mais rentável para ele e começou a usar o antigo novamente.
Estamos de volta ao estágio Suponha! Reunindo um diagnóstico diferencial, no espírito do Dr. House:
- Pode ser necessário otimizar as configurações do postgres;
- talvez atualize o postgres para uma versão mais recente em termos menores (9.6.11 -> 9.6.15);
- e talvez, novamente, estude cuidadosamente qual consulta SQL forma o Rails?
Testamos todas as três hipóteses. Este último nos levou ao rastro de um cúmplice.
SELECT "arena_battles".*
FROM "arena_battles"
WHERE "arena_battles"."status" = 'waiting_for_players'
AND (arena_battles.bet <= 98.13)
AND (NOT EXISTS (
SELECT 1 FROM arena_participations
WHERE arena_battle_id = arena_battles.id
AND (arena_profile_id = 46809)
))
ORDER BY "arena_battles"."created_at" ASC
LIMIT 10 OFFSET 0Vamos percorrer esse SQL juntos. Selecionamos todos os campos de batalha da tabela de batalha cujo status é igual a "aguardando jogadores" e a taxa é menor ou igual a um determinado número. Até agora, tudo está claro. O próximo termo na condição parece assustador.
NOT EXISTS (
SELECT 1 FROM arena_participations
WHERE arena_battle_id = arena_battles.id
AND (arena_profile_id = 46809)
)Estamos procurando um resultado de subconsulta inexistente. Obtenha o primeiro campo da tabela de participação em batalhas, onde o ID da batalha corresponde e o perfil do participante pertence ao nosso jogador. Vou tentar desenhar o conjunto descrito na subconsulta.
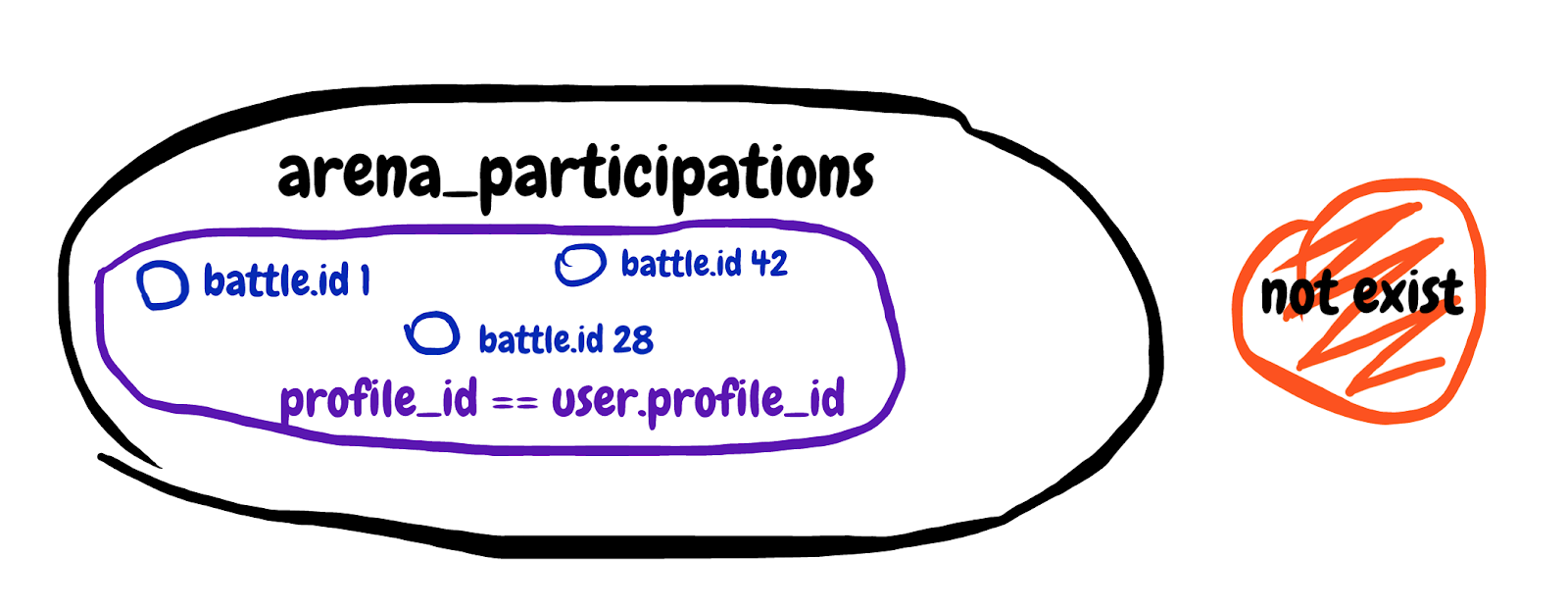
É difícil de entender, mas no final, com essa subconsulta, tentamos excluir as batalhas nas quais o jogador já está participando. Examinamos a explicação geral da consulta e vemos Tempo de planejamento: 0,180 ms, Tempo de execução: 12,119 ms. Encontramos um cúmplice!
Chegou a hora da minha cábula favorita, que existe na Internet desde 2008. Aqui está:

Sim! Assim que uma consulta encontra algo que deve excluir um certo número de registros com base nos dados de outra tabela, esse meme com barba e cachos deve aparecer na memória.
De fato, é disso que precisamos:

Salve esta foto para si mesmo ou, melhor ainda, imprima-a e pendure-a em vários lugares no escritório.
Reescrevemos a subconsulta para LEFT JOIN WHERE B.key IS NULL, obtemos:
SELECT "arena_battles".*
FROM "arena_battles"
LEFT JOIN arena_participations
ON arena_participations.arena_battle_id = arena_battles.id
AND (arena_participations.arena_profile_id = 46809)
WHERE "arena_battles"."status" = 'waiting_for_players'
AND (arena_battles.bet <= 98.13)
AND (arena_participations.id IS NULL)
ORDER BY "arena_battles"."created_at" ASC
LIMIT 10 OFFSET 0A consulta corrigida é executada em duas tabelas ao mesmo tempo. Adicionamos uma tabela com registros da participação do usuário nas batalhas à esquerda e adicionamos a condição de que o identificador de participação não existe. Vamos ver a explicação analisar a consulta recebida: Tempo de planejamento: 0,185 ms, Tempo de execução: 0,337 ms. Bem! Agora, o planejador de consultas não hesitará em usar o índice parcial, mas usará a opção mais rápida. O prisioneiro escapado e seu cúmplice foram condenados à prisão perpétua em uma instituição estrita do regime. Será mais difícil para eles escaparem.
O resumo é breve.
- Use Newrelic ou outro serviço similar para encontrar leads. Percebemos que o problema está precisamente nas consultas ao banco de dados.
- Use a prática do PMDSC - funciona e, de qualquer forma, é muito envolvente.
- Use o PgHero para encontrar suspeitos e investigar pistas nas estatísticas de consulta SQL.
- Use o explic.depesz.com - é fácil ler consultas de análise e explicação lá.
- Tente desenhar muitos dados quando não souber exatamente o que a solicitação está fazendo.
- Pense no cara durão com cachos por toda a cabeça quando vir uma subconsulta procurando algo que não está em outra tabela.
- Seja detetive, você pode até receber um distintivo.