 O Dialogue 2020 , uma conferência científica internacional sobre linguística computacional e tecnologia inteligente, terminou recentemente . Pela primeira vez, a Escola Phystech de Matemática Aplicada e Informática (FPMI) do MIPT tornou-se parceira da conferência . Tradicionalmente, um dos principais eventos do Diálogo é a Avaliação do Diálogo , uma competição entre os desenvolvedores de sistemas automáticos para análise de texto linguístico. Já conversamos com Habré sobre as tarefas que os participantes da competição resolveram no ano passado, por exemplo, sobre como gerar títulos e encontrar palavras ausentes no texto. Hoje conversamos com os vencedores de duas faixas da Avaliação de Diálogo deste ano - Vladislav Korzun e Daniil Anastasyev - sobre por que eles decidiram participar de competições de tecnologia, quais problemas e de que maneira resolveram, em que os caras estão interessados, onde estudaram e o que planejam fazer no futuro. Bem-vindo ao gato!
O Dialogue 2020 , uma conferência científica internacional sobre linguística computacional e tecnologia inteligente, terminou recentemente . Pela primeira vez, a Escola Phystech de Matemática Aplicada e Informática (FPMI) do MIPT tornou-se parceira da conferência . Tradicionalmente, um dos principais eventos do Diálogo é a Avaliação do Diálogo , uma competição entre os desenvolvedores de sistemas automáticos para análise de texto linguístico. Já conversamos com Habré sobre as tarefas que os participantes da competição resolveram no ano passado, por exemplo, sobre como gerar títulos e encontrar palavras ausentes no texto. Hoje conversamos com os vencedores de duas faixas da Avaliação de Diálogo deste ano - Vladislav Korzun e Daniil Anastasyev - sobre por que eles decidiram participar de competições de tecnologia, quais problemas e de que maneira resolveram, em que os caras estão interessados, onde estudaram e o que planejam fazer no futuro. Bem-vindo ao gato!
Vladislav Korzun, vencedor da faixa de avaliação de diálogo RuREBus-2020

O que você faz?
Sou desenvolvedor do NLP Advanced Research Group da ABBYY. No momento, estamos resolvendo uma tarefa de aprendizado único para extrair entidades. Ou seja, com uma pequena amostra de treinamento (5 a 10 documentos), você precisa aprender como extrair entidades específicas de documentos semelhantes. Para isso, usaremos as saídas do modelo NER treinado nos tipos de entidade padrão (Pessoa, Local, Organização) como recursos para resolver esse problema. Também planejamos usar um modelo de linguagem especial, treinado em documentos semelhantes no assunto à nossa tarefa.
Que tarefas você resolveu na Avaliação de Diálogo?
No Diálogo, participei do concurso RuREBus dedicado à extração de entidades e relacionamentos de documentos específicos do corpus do Ministério do Desenvolvimento Econômico. Este caso foi muito diferente dos casos utilizados, por exemplo, na competição Conll . Primeiro, os tipos de entidades em si não eram padrão (Pessoas, Locais, Organizações), entre eles havia até ações substantivas e sem nome. Em segundo lugar, os textos em si não eram conjuntos de frases verificadas, mas documentos reais, que levavam a várias listas, cabeçalhos e até tabelas. Como resultado, as principais dificuldades surgiram precisamente com o processamento de dados, e não com a solução do problema. de fato, são tarefas clássicas de reconhecimento de entidade nomeada e extração de relação.
Na competição em si, havia três faixas: NER, ER com determinadas entidades e ER de ponta a ponta. Eu tentei resolver os dois primeiros. Na primeira tarefa, usei abordagens clássicas. Primeiro, tentei usar uma rede recorrente como modelo e incorporar palavras de texto rápido, padrões de capitalização, incorporar simbólicos e tags POS como recursos [1]. Então eu já usei vários BERTs pré-treinados [2], que são bastante superiores à minha abordagem anterior. No entanto, isso não foi suficiente para ficar em primeiro lugar nesta faixa.
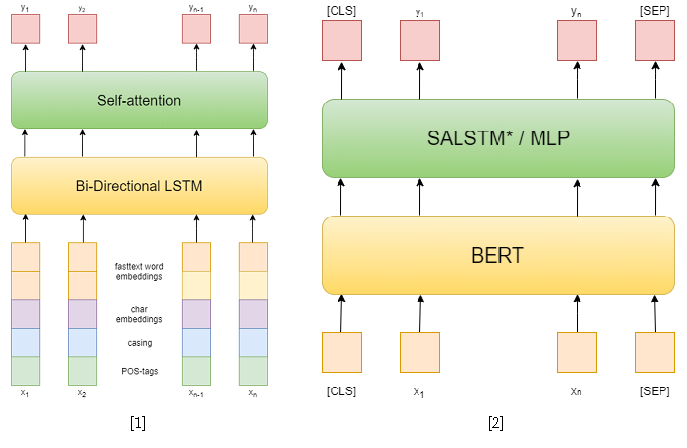
Mas na segunda faixa eu consegui. Para resolver o problema de extração de relações, reduzi-o ao problema de classificação de relações, semelhante à Tarefa 8 do SemEval 2010 . Nesse problema, para cada sentença, é fornecido um par de entidades, para o qual o relacionamento precisa ser classificado. E em uma faixa, cada sentença pode conter quantas entidades você desejar, no entanto, ela simplesmente se reduz à anterior, amostrando a sentença para cada par de entidades. Além disso, durante o treinamento, peguei exemplos negativos aleatoriamente para cada sentença em um tamanho que não excede o dobro do número de positivos, a fim de reduzir a amostra de treinamento.
Como abordagens para resolver o problema de classificação de relações, usei dois modelos baseados no BERT-e. No primeiro, concatenei as saídas do BERT com incorporações do NER e, em seguida, calculei a média dos recursos de cada token usando Auto-atenção [3]. Uma das melhores soluções para a Tarefa 8 do SemEval 2010 - R-BERT [4] foi adotada como segundo modelo. A essência dessa abordagem é a seguinte: insira tokens especiais antes e depois de cada entidade, calcule a média das saídas do BERT para os tokens de cada entidade, combine os vetores resultantes com a saída correspondente ao token CLS e classifique o vetor de recurso resultante. Como resultado, este modelo ficou em primeiro lugar na pista. Os resultados da competição estão disponíveis aqui .
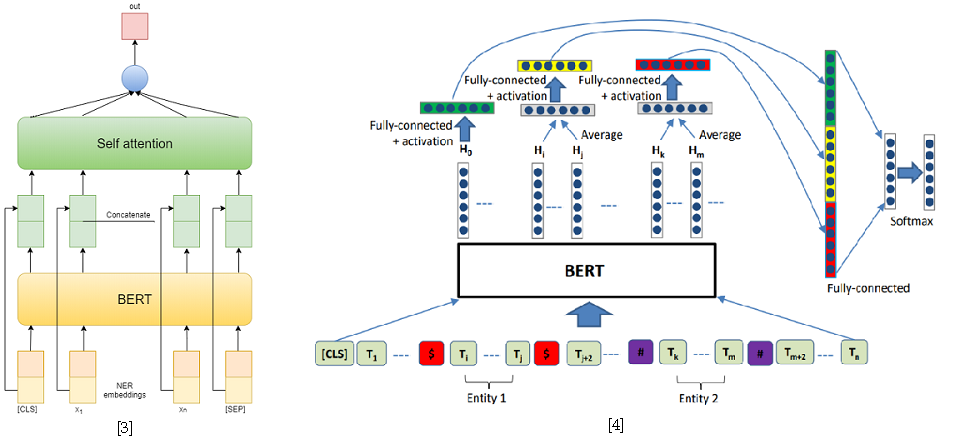
[4] Wu, S., He, Y. (2019, novembro). Enriquecendo o modelo de linguagem pré-treinado com informações da entidade para classificação de relações. Em Anais da 28ª Conferência Internacional da ACM sobre Gestão de Informação e Conhecimento ( pp. 2361-2364 ).
O que lhe pareceu mais difícil nessas tarefas?
O mais problemático foi o processamento do caso. As tarefas em si são o mais clássicas possível, pois para sua solução já existem estruturas prontas, por exemplo, AllenNLP. Mas a resposta precisa ser dada ao salvar os períodos de token, então eu não poderia simplesmente usar o pipeline pronto sem escrever muito código adicional. Portanto, decidi escrever o pipeline inteiro no PyTorch puro para não perder nada. Embora eu ainda usei alguns módulos do AllenNLP.
Havia também muitas frases bastante longas no corpus, o que causou inconveniência ao ensinar grandes transformadores, por exemplo, o BERT, porque eles se tornam exigentes na memória de vídeo com o aumento da duração da frase. No entanto, a maioria dessas frases são enumerações delimitadas por ponto e vírgula e podem ser separadas por esse caractere. Simplesmente dividi as ofertas restantes pelo número máximo de tokens.
Você já participou de Diálogos e faixas antes?
No ano passado, falei com meu mestrado na sessão de estudantes.
Por que você decidiu participar da competição este ano?
Naquela época, eu estava apenas resolvendo o problema de extrair relações, mas para um corpo diferente. Tentei usar uma abordagem diferente com base em árvores de análise. O caminho na árvore de uma entidade para outra foi usado como entrada. Mas essa abordagem, infelizmente, não mostrou resultados fortes, embora estivesse no mesmo nível da abordagem baseada em redes recorrentes, usando incorporações de token e outros recursos como sinais, como o comprimento do caminho de um token para uma raiz ou uma das entidades na árvore sintática. análise, bem como a posição relativa das entidades.
Nesta competição, decidi participar, porque já tinha algumas bases para resolver problemas semelhantes. E por que não aplicá-los em uma competição e ser publicado? Acabou não sendo tão fácil quanto eu pensava, mas é devido a problemas com a interação com os cascos. Como resultado, para mim, foi mais uma tarefa de engenharia do que de pesquisa.
Você participou de outras competições?
Ao mesmo tempo, nossa equipe participou do SemEval . Ilya Dimov estava envolvido principalmente na tarefa, apenas sugeri algumas idéias. Havia a tarefa de classificar a propaganda: o espaço do texto foi selecionado e era necessário classificá-lo. Sugeri usar a abordagem R-BERT, ou seja, para selecionar essa entidade em tokens, inserir um token especial na frente e depois dela e calcular a média das saídas. Como resultado, isso deu um pequeno aumento. Este é o valor científico: para resolver o problema, usamos um modelo projetado para algo completamente diferente.
Também participei do ABBYY hackathon, no ACM icpc - competição em programação esportiva nos primeiros anos. Não chegamos muito longe naquela época, mas foi divertido. Tais competições são muito diferentes daquelas apresentadas no Diálogo, onde há tempo suficiente para implementar e testar com calma várias abordagens. Em hackathons, você precisa fazer tudo rapidamente, não há tempo para relaxar, não há chá. Mas essa é a beleza de tais eventos - eles têm uma atmosfera específica.
Quais são os problemas mais interessantes que você resolveu em competições ou no trabalho?
Em breve, haverá uma competição de geração de gestos da GENEA e eu vou para lá. Eu acho que vai ser interessante. Este é um workshop na ACM - Conferência Internacional sobre Agentes Virtuais Inteligentes . Nesta competição, propõe-se gerar gestos para um modelo humano 3D baseado em voz. Falei este ano no Diálogo com um tópico semelhante, fiz uma pequena visão geral das abordagens do problema da geração automática de expressões faciais e gestos a partir da voz. Preciso ganhar experiência, porque ainda tenho que defender minha dissertação sobre um assunto semelhante. Quero tentar criar um agente virtual de leitura, com expressões faciais, gestos e, claro, voz. As abordagens atuais da síntese de fala permitem gerar fala bastante realista a partir do texto, enquanto as abordagens de geração de gestos permitem gerar gestos a partir da voz. Então, por que não combinar essas abordagens.
A propósito, onde você está estudando agora?
Sou estudante de pós-graduação no Departamento de Linguística Computacional da ABBYY na Phystech School of Applied Mathematics and Informática no MIPT . Defenderei minha tese em dois anos.
Que conhecimentos e habilidades adquiridos na universidade o ajudam agora?
Curiosamente, matemática. Embora eu não integre todos os dias e não multiplique matrizes na minha cabeça, a matemática ensina o pensamento analítico e a capacidade de descobrir qualquer coisa. Afinal, qualquer exame inclui provar teoremas, e tentar aprendê-los é inútil, mas entender e provar a si mesmo, lembrando apenas de uma ideia, é possível. Também tivemos bons cursos de programação, onde aprendemos com um nível baixo para entender como tudo funciona, analisamos vários algoritmos e estruturas de dados. E agora não será um problema lidar com uma nova estrutura ou mesmo uma linguagem de programação. Sim, é claro, tivemos cursos de aprendizado de máquina e de PNL, em particular, mas ainda assim, parece-me que habilidades básicas são mais importantes.
Daniil Anastasyev, vencedor da trilha Dialogue Evaluation GramEval-2020

O que você faz?
Estou desenvolvendo a assistente de voz "Alice", trabalho na busca pelo grupo de significados. Analisamos os pedidos que chegam a Alice. Um exemplo padrão de uma consulta é "Qual é o tempo em Moscou amanhã?" Você precisa entender que esta é uma solicitação sobre o clima, que a solicitação pergunta sobre a localização (Moscou) e há uma indicação da hora (amanhã).
Conte-nos sobre o problema que você resolveu este ano em uma das faixas de Avaliação de Diálogo.
Eu estava realizando uma tarefa muito próxima do que a ABBYY está fazendo. Era necessário construir um modelo que analisasse a sentença, fizesse análises morfológicas e sintáticas e definisse os lemas. Isso é muito parecido com o que eles fazem na escola. Levei cerca de 5 dias para construir o modelo.

O modelo estudou em russo normal, mas, como você pode ver, também funciona no idioma que estava com o problema.
Isso soa como o que você faz no trabalho?
Provavelmente não. Aqui você precisa entender que essa tarefa por si só não tem muito significado - é resolvida como uma subtarefa na estrutura de solução de algum problema comercial importante. Assim, por exemplo, na ABBYY, onde trabalhei, a análise morfo-sintática é o estágio inicial na solução do problema de extração de informações. Dentro da estrutura das minhas tarefas atuais, não preciso de tais análises. No entanto, a experiência adicional de trabalhar com modelos de linguagem pré-treinados, como o BERT, parece certamente útil para o meu trabalho. Em geral, essa era a principal motivação para a participação - eu não queria vencer, mas praticar e adquirir algumas habilidades úteis. Além disso, meu diploma estava parcialmente relacionado ao tópico do problema.
Você já participou da avaliação de diálogo antes?
Participou da faixa MorphoRuEval-2017 no 5º ano e também ficou em 1º lugar. Depois, foi necessário definir apenas morfologia e lemas, sem relações sintáticas.
É realista aplicar seu modelo a outras tarefas agora?
Sim, meu modelo pode ser usado para outras tarefas - publiquei todo o código-fonte. Pretendo postar o código usando um modelo mais leve e rápido, mas menos preciso. Em teoria, se alguém quiser, o modelo atual pode ser usado. O problema é que será muito grande e lento para a maioria. Na competição, ninguém se preocupa com a velocidade, é interessante obter a mais alta qualidade possível, mas na aplicação prática, geralmente tudo é o contrário. Portanto, o principal benefício de modelos tão grandes é saber qual é a qualidade mais viável para entender o que você está sacrificando.
Por que você participa da Avaliação de Diálogo e de outras competições similares?
Hackathons e tais competições não estão diretamente relacionados ao meu trabalho, mas ainda é uma experiência gratificante. Por exemplo, quando participei do hackathon da AI Journey no ano passado, aprendi algumas coisas que depois usei no meu trabalho. A tarefa era aprender a passar no exame no idioma russo, ou seja, resolver testes e escrever um ensaio. É claro que tudo isso tem pouco a ver com o trabalho. Mas a capacidade de criar e treinar rapidamente um modelo que resolva algum problema é muito útil. Aliás, eu e minha equipe conquistamos o primeiro lugar.
Que educação você recebeu e o que fez depois da universidade?
Ele se formou no Bacharelado e Mestrado do Departamento de Linguística Computacional da ABBYY no Instituto de Física e Tecnologia de Moscou, formado em 2018. Ele também estudou na Escola de Análise de Dados (SHAD). Quando chegou a hora de escolher um departamento básico no 2º ano, a maioria do nosso grupo foi para os departamentos da ABBYY - lingüística computacional ou reconhecimento de imagem e processamento de texto. No curso de graduação, fomos ensinados a programar bem - havia cursos muito úteis. A partir do 4º ano, trabalhei na ABBYY por 2,5 anos. Primeiro, no grupo de morfologia, participei de tarefas relacionadas aos modelos de linguagem para melhorar o reconhecimento de texto no ABBYY FineReader. Escrevi código, modelos treinados, agora estou fazendo o mesmo, mas para um produto completamente diferente.
Como você passa seu tempo livre?
Eu amo ler livros. Dependendo da estação, tento correr ou esquiar. Eu gosto de fotografia enquanto viajo.
Você tem planos ou objetivos para os próximos, digamos, 5 anos?
5 anos é muito longe do horizonte de planejamento. Eu nem tenho 5 anos de experiência profissional. Nos últimos 5 anos, muita coisa mudou, agora há claramente um sentimento diferente da vida. Mal posso imaginar o que mais pode mudar, mas há pensamentos de conseguir um doutorado no exterior.
Que conselho você pode dar para jovens desenvolvedores que estão envolvidos em linguística computacional e estão no início de sua jornada?
É melhor praticar, tentar e competir. Iniciantes completos podem fazer um dos muitos cursos: por exemplo, da SHAD , DeepPavlov, ou até da minha , que uma vez lecionei na ABBYY.
, ABBYY : () (). 15 brains@abbyy.com , , GPA 5- 10- .
, ABBYY – .