
De fato, esse é o histórico da pesquisa de um defeito no layout de um site do banco, o que levou a uma exibição imprecisa de sua página principal na pesquisa. Um problema semelhante é frequentemente encontrado em um site montado, por exemplo, em um construtor on-line ou projetado, por exemplo, por um designer de layout que não está familiarizado com o básico da otimização de mecanismo de pesquisa.
E essa história teria permanecido interessante apenas para um círculo restrito de profissionais de SEO, se ela não tivesse tocado em um recurso não documentado da indexação, que certamente iria querer saber sobre outros especialistas em manutenção de sites. Convido-os sob o gato.
Introdução curta
Qualquer mestre de SEO experiente conhece as regras da análise semântica de uma página do site por robôs de indexação de pesquisa. Essas regras estão sujeitas a certas disposições de certos padrões técnicos da Internet. Por exemplo:
- a tag <title> é um nome exclusivo para todo o documento e é usada apenas em sua seção de cabeçalho e apenas uma vez;
- a tag <h1> encabeça uma seção específica do documento e pode ser reutilizada, mas apenas em outra seção e mantendo a exclusividade entre todas as tags <h1> do mesmo documento;
- a tag <h2> é um subtítulo de seção que pode ser reutilizado mesmo na mesma seção, mantendo a exclusividade entre os subtítulos pares de sua seção;
- a tag <h3> é a subposição da subposição pai;
- ... etc.
Obviamente, existem diferentes nuances nessas regras para analisar as páginas antes de indexá-las, que são interpretadas por cada servidor de pesquisa da sua maneira:
- , «», — , <p> ;
- (outlines), «» — , <h2> <p> () ;
- … .
Por enquanto, essas regras de análise semântica e nuances não são importantes para nós. E se você está tão interessado nas próprias disposições dos padrões técnicos nos quais a indexação de conteúdo se baseia, a parte principal dessas disposições é claramente declarada na publicação geral [1] sobre a admissibilidade de várias tags <h1> em uma página do site.
Acabo de observar que os mestres de SEO estão acostumados a essas nuances, não é a primeira vez que verificam sua imparcialidade com base em sua própria experiência e há muito tempo promovem sites de busca, levando em consideração uma visão semelhante sobre a prioridade das tags. Afinal, a compreensão dos princípios da indexação permite "controlar" parcialmente o texto que mostrará o snippet de pesquisa do site em resposta à solicitação de um usuário.
Mas, há alguns dias atrás, surgiram informações privilegiadas de que nos resultados de pesquisa orgânica relacionados ao site oficial do Monobank ucraniano, um comportamento incompreensível de trechos foi revelado: o mecanismo de pesquisa não o nomeia de forma alguma pelas tags <title> ou <h1>. Ou seja, um redator poderia escrever o título e o texto mais exclusivos, um gerente de conteúdo poderia inserir texto no site, mas a pesquisa ainda estaria errada.
Era necessário descobrir o motivo, sobre o qual falarei mais adiante.
O primeiro passo da pesquisa
Então, primeiro, limpei o cache e o histórico do navegador, reiniciei, abri a caixa de pesquisa do Google e digitei o nome do banco. Para que até minha pessoa inexperiente em SEO possa entender cada passo que dou, tirei uma foto do primeiro passo.
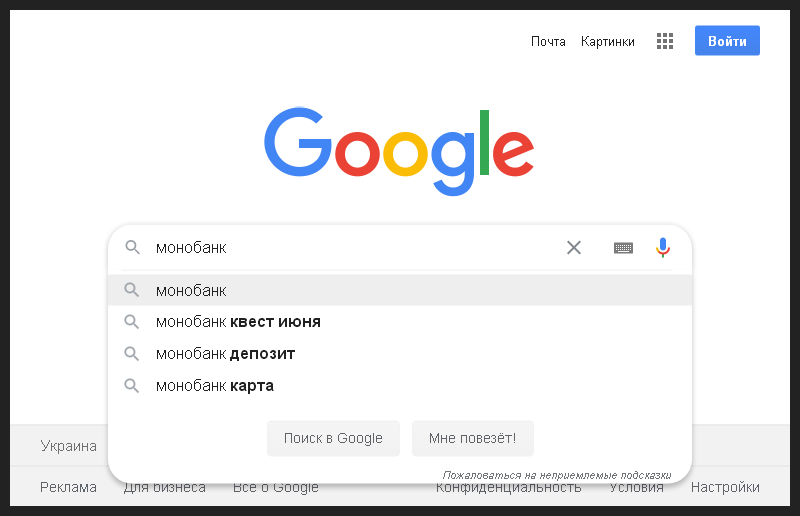
Essa é uma solicitação de informações da marca, o que significa que, em primeiro lugar, resultados orgânicos é lógico esperar a aparência de um snippet para a página principal do banco.
Tudo aconteceu como esperado, o snippet foi o primeiro na pesquisa e também continha um bloco de links rápidos para as principais seções do site. Captei esse momento na próxima foto.
Até agora, tudo parecia normal.

Para garantir que a situação pouco clara ocorra apenas nos resultados do Google, repeti a mesma consulta na pesquisa Yandex e observei agradavelmente que esse gigante da pesquisa segue as regras usuais: o snippet foi intitulado monobank - um banco móvel - exatamente como está escrito na tag <title> do tag desejado. Páginas.

A resposta no instantâneo de pesquisa do Google foi fundamentalmente diferente, pelo menos na parte do título. Além disso, fiquei um pouco confuso com os textos ridículos sob os títulos do snippet do Google.
Eu assumi que isso é apenas uma consequência do fato de que, após o SMM promover a marca e seu aplicativo móvel, implementado pelo Promodo em 2017-2018 [2] para o antigo domínio monobank.com.ua , contratar mais mestres de SEO para atender o novo domínio monobank .ua não fazia mais sentido. Afinal, a campanha publicitária trouxe os resultados esperados. E a gerência do banco provavelmente marcou um gol na promoção de mecanismos de busca do novo domínio ou atribuiu a responsabilidade a especialistas em TI em tempo integral.
Portanto, atribuí a falta de jeito dos textos atuais à compreensível relutância dos funcionários regulares em verificar o resultado da solicitação, que um usuário típico de um banco nunca realmente discará.
Afinal, a clientela do banco visita o site principalmente por meio de um aplicativo móvel, praticamente sem observar a aparência das páginas do banco na pesquisa. E essa parte dos clientes que pesquisam na Internet usa principalmente consultas do formulário:
- Taxa do dólar Monobank;
- taxa de câmbio monobanco;
- abrir uma conta monobank;
- faça um cartão monobank;
- crie um cartão monobank;
- cartão de crédito monobanco;
- obter um empréstimo monobanco;
- contrair um empréstimo monobanco;
- ... etc.
Uma lista completa dessas frases de pesquisa que satisfazem o modelo “o que encontrar + onde” ou “onde + o quê” e traz o tráfego de entrada mais ousado da pesquisa orgânica é conhecida em qualquer banco.
Verificando consultas "saborosas"
Fiquei surpreso quando, na maioria dessas consultas, o mesmo snippet apareceu nos resultados da pesquisa com o mesmo título e texto geralmente estúpido que dificilmente correspondia à consulta inserida.
Fotografei um exemplo dessa solicitação na figura a seguir e indiquei a área do problema.

Além disso, o endereço de destino (URL) do snippet para quase todas as solicitações levou ao início da página principal, sem ancorar a seção no endereço relevante para a solicitação atual.
Bem, digamos, se a solicitação fosse sobre a taxa de câmbio e a seção correspondente estivesse presente na página de destino, seria lógico ancorar o link da seção com algum hash como monobank.ua/#kurs-valut com a canonização do mesmo URL ancorado para que o robô de pesquisa entendesse que a página de destino possui vários pontos de destino para as frases de pesquisa correspondentes, que seriam definidas por SEOs em tempo integral no texto âncora dos links colocados por eles em algum lugar do site ou fora dele, por exemplo, nas redes sociais.
Caso contrário, parecia que os desenvolvedores do site atribuíram à página principal o papel de uma página de destino multissecional, mas não informaram aos provedores de serviços de SEO e colocaram links promocionais com o texto âncora planejado, mas sem as âncoras da seção. Como resultado, todos os links para diferentes tipos de solicitações pareciam estar no ponto de entrada da página principal e, inevitavelmente, receberam um único trecho com um cabeçalho relacionado à seção principal da página principal.
Pequena digressão
Apenas no caso, mostrarei na próxima figura um exemplo de marcação HTML, como eles usam o layout semântico para resolver os problemas de vários pontos de aterrissagem em uma única página de aterrissagem do site.

Obviamente, esse esquema funcionará desde que vinculemos a página de destino com uma âncora correspondente ao caso de informações. Ou seja:
- monobank.ua - informação básica;
- monobank.ua/#kurs-valut - sobre taxas de câmbio;
- monobank.ua/#otkryt-schet - sobre como abrir uma conta;
- monobank.ua/#kreditnaja-karta - sobre cartões de crédito.
Mas voltando ao batente descoberto SEO
O erro, embora não seja tão grave, porque o fluxo principal de clientes ainda passa pelo aplicativo móvel, no entanto, devido a esse erro, o banco perde parte do tráfego de busca. Como os usuários de pesquisa são divididos em dois tipos - a maioria rápida e a minoria de lazer:
- o primeiro lê apenas os cabeçalhos dos trechos e clica neles se o significado do cabeçalho e a solicitação inserida corresponderem;
- o segundo lê com atenção o título e o texto abaixo dele e também clica apenas se o significado coincidir.
É claro que o significado da mensagem no snippet de pesquisa ossificado para a página do banco coincidiu apenas com uma porcentagem muito pequena de solicitações. Era necessário entender onde o erro foi cometido.
Exibir layout da página inicial
Abri a página principal do banco usando o link do snippet. No código fonte desta página, havia uma única tag <h1>, geralmente usada para escrever o título principal da página, que geralmente também termina no título do snippet.
Além disso, essa tag de cabeçalho principal foi usada no código da página antes do restante do cabeçalho <h> -tags. Então, à primeira vista, parecia que não havia erros de SEO.
Tirei uma foto dessa página e marquei a posição das duas primeiras tags <h> nela.
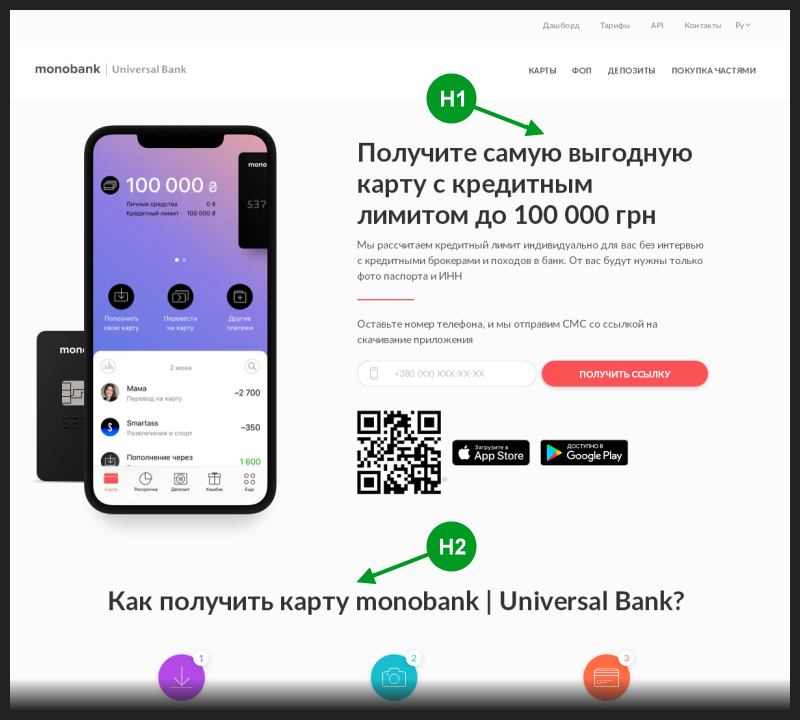
Era lógico esperar que a tag <h1> substituísse o cabeçalho do snippet de pesquisa. Mas, por alguma razão, uma etiqueta de classificação inferior chegava lá toda vez.
Inicialmente, sugeri que o caso se refere apenas a solicitações que incluem o nome do banco. Na tag <h1>, não existe, mas na tag <h2> existe, portanto, que, apesar da classificação mais baixa, ainda obtém a vantagem de obter o título do snippet.
No entanto, é fácil testar essa suposição: você precisa escrever uma solicitação exatamente igual à tag <h1> e, em seguida, é garantido que essa tag de cabeçalho tenha o direito de ocupar o título do snippet com base em uma correspondência absoluta com a solicitação. O que fiz, ao mesmo tempo em que capturava o resultado na próxima foto.

Da figura a seguir, o servidor de pesquisa ainda vê e entende o texto da tag <h1>, por algum motivo, não considera que seja o cabeçalho principal no site deste banco. Isso é possível em 2 casos:
- ou o mestre de SEO adicionou uma micromarcação semântica específica ao layout da página, exigindo que outra tag se torne o cabeçalho principal;
- ou existe o chamado "problema dos designers on-line" quando, devido à suboptimalidade da pesquisa de blocos de construção, suas tags de texto aparecem em diferentes seções do documento HTML, enquanto a tag de título principal é omitida mais profundamente que a tag de título não principal do contorno de sua seção.
Decidi verificar primeiro o primeiro caso e abri o site na ferramenta de validação de dados estruturados. No entanto, apenas a micromarcação Open Graph foi encontrada, sem dicas de reatribuição forçada da semântica de tags.
Captei esse momento na próxima foto.

Em seguida, abri o código fonte da página do problema, formatei os espaços para facilitar o estudo, removi os atributos da tag com o mesmo objetivo e depois observei a essência do problema na próxima figura.

Como resultado, temos o estado das coisas interpretado abaixo, do qual descreverei uma conclusão importante com antecedência : após um mês (aproximadamente o tempo médio de rastreamento para robôs de indexação) a partir do lançamento do site, verifique várias consultas importantes sobre como o mecanismo de pesquisa percebeu a marcação de suas páginas, ou seja, quais partes conteúdo que ele realmente indexou.
Interpretação do resultado
O Yandex, ao analisar a página no novo domínio do Monobank, não encontrou um layout semântico (já que tudo é organizado com <div> s) e, não tendo instruções para analisar a semântica implícita, não começou a adivinhar pelas classes de tags e, ao selecionar o título do trecho, simplesmente usou a regra da especificação: tag <title> é o título principal do documento.
O Google, ao analisar a mesma página, também não encontrou um layout semântico, mas sua inteligência artificial é capaz de analisar recursos semânticos ocultos; portanto, observou quatro <div> s com um conteúdo implícito de classe semântica, denotando o contorno da seção na atual situação de marcação. Conseqüentemente, a regra sobre a tag <title> foi rejeitada e o mecanismo de pesquisa usou a regra na especificação de estrutura de tópicos da seção, tentando encontrar uma seção adequada entre as quatro declaradas. A primeira seção é inadequada porque sua tag de cabeçalho está mais distante do contorno do que a tag de cabeçalho nas seções 2, 3 e 4. A partir dessas seções mais apropriadas, a segunda seção foi selecionada com base na proximidade com o início do documento. Foi assim que o título entrou no snippet.
De fato, a lógica de seleção de cabeçalho para o snippet era idêntica para os dois mecanismos de pesquisa. O Yandex simplesmente selecionou a primeira tag de cabeçalho no primeiro caminho (a tag <head> está implicitamente) no documento, e o Google escolheu a primeira tag de cabeçalho no caminho marcado semanticamente (a tag <div class = "content"> obviamente era).
Esse é o incrível recurso da pesquisa, chamado "não documentado" no início da minha investigação. A tag <h1> realmente não tem nenhum sinal de importância. Com base na consulta de pesquisa do usuário, um esboço da seção correspondente no documento e o primeiro cabeçalho do esboço são selecionados sem levar em consideração o nível do cabeçalho numérico usado.
Materiais usados
[1] Um H1 ou vários - por que isso está correto? , Março de 2020. Impera, SEO Documents. Trechos da especificação padrão do HTML mostram que escrever uma ou mais tags H1 em uma página é considerada correta nos dois casos.
[2] Caso Monobank sobre promoção de aplicativos móveis , agosto de 2017 - março de 2018. Promodo, Cases. Um exemplo dos eventos usados pela agência mostra como promover um aplicativo móvel no iOS e Android usando o AdWords, Facebook, Instagram, Twitter, YouTube e também os otimizou na App Store e no Google Play.