
Como faço para atualizar o valor do atributo para todos os registros em uma tabela? Como adiciono uma chave primária ou única a uma tabela? Como faço para dividir uma mesa em duas? Como ...
Se o aplicativo ficar indisponível por algum tempo para migrações, as respostas a essas perguntas não serão difíceis. Mas e se você precisar migrar rapidamente - sem interromper o banco de dados e sem perturbar outras pessoas para trabalhar com ele?
Tentaremos responder a essas e outras questões que surgem durante as migrações de esquemas e dados no PostgreSQL na forma de conselhos práticos.
Este artigo - desempenho de decodificação na conferência SmartDataConf ( aqui você encontra a apresentação, o vídeo aparecerá no momento oportuno). Havia muito texto, então o material será dividido em 2 artigos:
- migrações básicas
- abordagens para atualizar tabelas grandes.
No final, há um resumo de todo o artigo na forma de uma folha de referências da tabela dinâmica.
Conteúdo
O ponto crucial do problema
Adicionar uma coluna
Adicionar uma
coluna padrão Excluir uma coluna
Criar um índice
Criar um índice em uma tabela particionada
Criar uma restrição NOT NULL
Criar uma chave estrangeira
Criar uma restrição única
Criar uma chave primária Folha de dicas de
migração rápida
A essência do problema
Suponha que temos um aplicativo que funciona com um banco de dados. Na configuração mínima, ele pode consistir em 2 nós - o próprio aplicativo e o banco de dados, respectivamente.

Com este esquema, as atualizações do aplicativo geralmente ocorrem com tempo de inatividade. Ao mesmo tempo, você pode atualizar o banco de dados. Nessa situação, o principal critério é o tempo, ou seja, é preciso concluir a migração o mais rápido possível para minimizar o tempo de indisponibilidade do serviço.
Se a aplicação crescer e for necessário realizar lançamentos sem tempo de inatividade, passamos a usar vários servidores de aplicação. Pode haver quantos deles você quiser e eles estarão em versões diferentes. Nesse caso, é necessário garantir a compatibilidade com versões anteriores.

No próximo estágio de crescimento, os dados deixam de caber em um banco de dados. Começamos a dimensionar o banco de dados também - por fragmentação. Como na prática é muito difícil migrar vários bancos de dados de forma síncrona, isso significa que em algum ponto eles terão esquemas de dados diferentes. Assim, estaremos trabalhando em um ambiente heterogêneo, onde os servidores de aplicação podem ter códigos e bancos de dados diferentes com esquemas de dados diferentes.
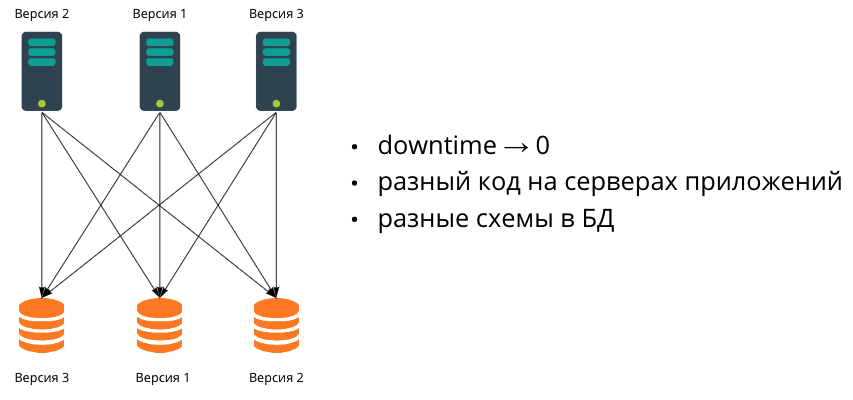
É sobre essa configuração que falaremos neste artigo e consideraremos as migrações mais populares que os desenvolvedores escrevem - das mais simples às mais complexas.
Nosso objetivo é realizar migrações de SQL com impacto mínimo no desempenho do aplicativo, ou seja, altere os dados ou o esquema de dados para que o aplicativo continue em execução e os usuários não percebam.
Adicionando uma coluna
ALTER TABLE my_table ADD COLUMN new_column INTEGER --
Provavelmente, qualquer pessoa que trabalhe com o banco de dados escreveu uma migração semelhante. Se falamos sobre PostgreSQL, então essa migração é muito barata e segura. O comando em si, embora capture o bloqueio de nível mais alto ( AccessExclusive ), é executado muito rapidamente, porque, por baixo do capô, há apenas a adição de metainformações sobre uma nova coluna sem reescrever os dados da própria tabela. Na maioria dos casos, isso acontece despercebido. Mas podem surgir problemas se, no momento da migração, houver longas transações trabalhando com esta tabela. Para entender a essência do problema, vamos dar uma olhada em um pequeno exemplo de como os bloqueios funcionam de forma simplificada no PostgreSQL. Esse aspecto será muito importante ao considerar a maioria das outras migrações também.
Suponha que temos uma grande tabela e selecionamos todos os dados dela. Dependendo do tamanho do banco de dados e da própria tabela, pode levar vários segundos ou até minutos.

O bloqueio do AccessShare mais fraco que protege contra alterações na estrutura da tabela é adquirido durante a transação .
Neste momento, vem outra transação, que está apenas tentando fazer uma consulta ALTER TABLE a esta tabela. O comando ALTER TABLE, conforme mencionado anteriormente, captura um bloqueio AccessExclusive , que não é compatível com nenhum outro bloqueio . Ela entra na fila.
Essa fila de bloqueio é "distribuída" em ordem estrita; mesmo se outras consultas vierem após ALTER TABLE (por exemplo, também SELECTs), que por si só não entram em conflito com a primeira consulta, todas elas enfileiram para ALTER TABLE. Com isso, a aplicação "levanta" e espera a execução de ALTER TABLE.
O que fazer em tal situação? Você pode limitar o tempo que leva para adquirir um bloqueio usando o comando SET lock_timeout . Executamos este comando antes de ALTER TABLE (a palavra-chave LOCAL significa que a configuração é válida apenas dentro da transação atual, caso contrário - dentro da sessão atual):
SET LOCAL lock_timeout TO '100ms'
e se em 100 milissegundos o comando falhar em adquirir o bloqueio, ele falhará. Em seguida, ou o reiniciamos novamente, esperando que tenha sucesso, ou vamos descobrir por que a transação leva tanto tempo, se isso não deveria estar em nosso aplicativo. Em qualquer caso, o principal é que não travamos o aplicativo.
Deve-se dizer que definir um tempo limite é útil antes de qualquer comando que obtenha um bloqueio estrito.
Adicionando uma coluna com um valor padrão
-- PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42
Se este comando for executado em uma versão anterior do PostgreSQL (abaixo de 11), ele sobrescreverá todas as linhas da tabela. Obviamente, se a mesa for grande, isso pode levar muito tempo. E como um bloqueio estrito ( AccessExclusive ) é capturado para o tempo de execução , todas as consultas à tabela também são bloqueadas.
Se o PostgreSQL for 11 ou mais recente, esta operação é bastante barata. O fato é que na 11ª versão foi feita uma otimização, graças à qual, ao invés de reescrever a tabela, o valor padrão é armazenado em uma tabela especial pg_attribute, e posteriormente, ao realizar SELECT, todos os valores vazios desta coluna serão ser substituído em tempo real por este valor. Nesse caso, posteriormente, quando as linhas da tabela forem sobrescritas devido a outras modificações, o valor será gravado nessas linhas.
Além disso, a partir da 11ª versão, você também pode criar imediatamente uma nova coluna e marcá-la como NOT NULL:
-- PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42 NOT NULL
E se o PostgreSQL for anterior a 11?
A migração pode ser feita em várias etapas. Primeiro, criamos uma nova coluna sem restrições e valores padrão. Como afirmado anteriormente, é barato e rápido. Na mesma transação, modificamos esta coluna adicionando um valor padrão.
ALTER TABLE my_table ADD COLUMN new_column INTEGER;
ALTER TABLE my_table ALTER COLUMN new_column SET DEFAULT 42;
Esta divisão de um comando em dois pode parecer um pouco estranha, mas a mecânica é tal que quando uma nova coluna é criada imediatamente com um valor padrão, ela afeta todos os registros que estão na tabela, e quando o valor é definido para um coluna existente (mesmo que apenas o que é criado, como no nosso caso), afeta apenas novos registros.
Assim, depois de executar estes comandos, resta-nos atualizar os valores que já estavam na tabela. Em termos gerais, precisamos fazer algo assim:
UPDATE my_table set new_column = 42 --
Mas tal UPDATE “de frente” é realmente impossível, porque ao atualizar uma tabela grande, iremos bloquear a tabela inteira por um longo tempo. No segundo artigo (aqui, no futuro, haverá um link), veremos quais estratégias existem para atualizar tabelas grandes no PostgreSQL, mas por enquanto vamos assumir que atualizamos de alguma forma os dados, e agora os dados antigos e o novo estará com o valor necessário por padrão.
Removendo uma coluna
ALTER TABLE my_table DROP COLUMN new_column --
Aqui, a lógica é a mesma de adicionar uma coluna: os dados da tabela não são modificados, apenas as metainformações são alteradas. Nesse caso, a coluna é marcada como excluída e indisponível para consultas. Isso explica o fato de que quando uma coluna é descartada no PostgreSQL, nenhum espaço físico é liberado (a menos que você execute um VACUUM FULL), ou seja, os dados dos registros antigos ainda permanecem na tabela, mas não estão disponíveis quando acessados. A desalocação ocorre gradualmente à medida que as linhas da tabela são substituídas.
Portanto, a migração em si é simples, mas, como regra, às vezes são encontrados erros no lado do back-end. Antes de excluir uma coluna, existem algumas etapas preparatórias simples a serem executadas.
- Primeiro, você precisa remover todas as restrições (NOT NULL, CHECK, ...) que estão nesta coluna:
ALTER TABLE my_table ALTER COLUMN new_column DROP NOT NULL
- A próxima etapa é garantir a compatibilidade de back-end. Você precisa se certificar de que a coluna não seja usada em nenhum lugar. Por exemplo, no Hibernate, você precisa marcar um campo usando uma anotação
@Transient
. No JOOQ que estamos usando, o campo é adicionado às exceções usando uma tag<excludes>
:
<excludes>my_table.new_column</excludes>
Você também precisa examinar atentamente as consultas"SELECT *"
- os frameworks podem mapear todas as colunas em uma estrutura no código (e vice-versa) e, portanto, você pode enfrentar novamente o problema de acessar uma coluna inexistente.
Depois que as alterações forem publicadas em todos os servidores de aplicativos, você pode excluir a coluna.
Criação de índice
CREATE INDEX my_table_index ON my_table (name) -- ,
Quem trabalha com PostgreSQL provavelmente sabe que este comando bloqueia toda a tabela. Mas desde a versão 8.2, muito antiga, existe a palavra-chave CONCURRENTLY , que permite criar um índice em um modo sem bloqueio.
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name) --
O comando é mais lento, mas não interfere nas solicitações paralelas.
Esta equipe tem uma ressalva. Ele pode falhar - por exemplo, ao criar um índice exclusivo em uma tabela que contém valores duplicados. O índice será criado, mas será marcado como inválido e não será usado em consultas. O status do índice pode ser verificado com a seguinte consulta:
SELECT pg_index.indisvalid
FROM pg_class, pg_index
WHERE pg_index.indexrelid = pg_class.oid
AND pg_class.relname = 'my_table_index'
Em tal situação, você precisa excluir o índice antigo, corrigir os valores na tabela e recriá-lo.
DROP INDEX CONCURRENTLY my_table_index
UPDATE my_table ...
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name)
É importante ressaltar que o comando REINDEX , que se destina apenas à reconstrução do índice, funciona apenas em modo de bloqueio até a versão 12 , o que impossibilita sua utilização. PostgreSQL 12 adiciona suporte CONCURRENTEMENTE e agora pode ser usado.
REINDEX INDEX CONCURRENTLY my_table_index -- PG 12
Criação de um índice em uma tabela particionada
Devemos também discutir a criação de índices para tabelas particionadas. No PostgreSQL, existem 2 tipos de particionamento: por herança e declarativo, que apareceu na versão 10. Vejamos ambos com um exemplo simples.
Suponha que desejamos particionar uma tabela por data e cada partição conterá dados de um ano.
Ao particionar por herança, teremos aproximadamente o seguinte esquema.
Mesa-mãe:
CREATE TABLE my_table (
...
reg_date date not null
)
Partições infantis para 2020 e 2021:
CREATE TABLE my_table_y2020 (
CHECK ( reg_date >= DATE '2020-01-01' AND reg_date < DATE '2021-01-01' ))
INHERITS (my_table);
CREATE TABLE my_table_y2021 (
CHECK ( reg_date >= DATE '2021-01-01' AND reg_date < DATE '2022-01-01' ))
INHERITS (my_table);
Índices pelo campo de particionamento para cada uma das partições:
CREATE INDEX ON my_table_y2020 (reg_date);
CREATE INDEX ON my_table_y2021 (reg_date);
Vamos deixar a criação de uma trigger / regra para inserir dados em uma tabela.
O mais importante aqui é que cada uma das partições é praticamente uma tabela independente mantida separadamente. Assim, a criação de novos índices também é feita como em tabelas regulares:
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name);
CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name);
Agora vamos examinar o particionamento declarativo.
CREATE TABLE my_table (...) PARTITION BY RANGE (reg_date);
CREATE TABLE my_table_y2020 PARTITION OF my_table FOR VALUES FROM ('2020-01-01') TO ('2020-12-31');
CREATE TABLE my_table_y2021 PARTITION OF my_table FOR VALUES FROM ('2021-01-01') TO ('2021-12-31');
A criação do índice depende da versão do PostgreSQL. Na versão 10, os índices são criados separadamente - assim como na abordagem anterior. Conseqüentemente, a criação de novos índices para uma tabela existente também é feita da mesma maneira.
Na versão 11, o particionamento declarativo foi aprimorado e as tabelas agora são servidas juntas . Criar um índice na tabela pai cria índices automaticamente para todas as partições existentes e novas que serão criadas no futuro:
-- PG 11 ()
CREATE INDEX ON my_table (reg_date)
Isso é útil ao criar uma tabela particionada, mas não ao criar um novo índice em uma tabela existente, porque o comando captura um bloqueio forte enquanto os índices estão sendo criados.
CREATE INDEX ON my_table (name) --
Infelizmente, CREATE INDEX não suporta a palavra-chave CONCURRENTLY para tabelas particionadas. Para contornar a limitação e migrar sem bloquear, você pode fazer o seguinte.
- Criar índice na tabela pai com a opção ONLY
CREATE INDEX my_table_index ON ONLY my_table (name)
O comando criará um índice inválido vazio sem criar índices para as partições . - Crie índices para cada uma das partições:
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name); CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name);
- Anexe índices de partições ao índice da tabela pai:
ALTER INDEX my_table_index ATTACH PARTITION my_table_y2020_index; ALTER INDEX my_table_index ATTACH PARTITION my_table_y2021_index;
Limitações
Agora vamos examinar as restrições: NOT NULL, estrangeiras, únicas e chaves primárias.
Criação de uma restrição NOT NULL
ALTER TABLE my_table ALTER COLUMN name SET NOT NULL --
A criação de uma restrição dessa forma fará a varredura de toda a tabela - todas as linhas serão verificadas quanto à condição não nula e, se a tabela for grande, pode demorar muito. O bloqueio forte que este comando captura irá bloquear todas as solicitações simultâneas até que seja concluído.
O que pode ser feito? O PostgreSQL possui outro tipo de restrição, CHECK , que pode ser usada para obter o resultado desejado. Essa restrição testa qualquer condição booleana que consiste em colunas de linha. No nosso caso, a condição é trivial -
CHECK (name IS NOT NULL)
. Mas o mais importante, a restrição CHECK suporta invalidação (palavra-chave
NOT VALID
):
ALTER TABLE my_table ADD CONSTRAINT chk_name_not_null
CHECK (name IS NOT NULL) NOT VALID -- , PG 9.2
A restrição criada desta forma se aplica apenas a registros recém-adicionados e modificados, e os existentes não são verificados, portanto, a tabela não é verificada.
Para garantir que os registros existentes também satisfaçam a restrição, é necessário validá-la (claro, primeiro atualizando os dados na tabela):
ALTER TABLE my_table VALIDATE CONSTRAINT chk_name_not_null
O comando itera sobre as linhas da tabela e verifica se todos os registros não são nulos. Mas, ao contrário da restrição NOT NULL usual, o bloqueio capturado neste comando não é tão forte (ShareUpdateExclusive) - ele não bloqueia as operações de inserção, atualização e exclusão.
Criação de uma chave estrangeira
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) --
Quando uma chave estrangeira é adicionada, todos os registros na tabela filho são verificados quanto a um valor no pai. Se a mesa for grande, essa varredura será longa e o bloqueio mantido em ambas as tabelas também será longo.
Felizmente, as chaves estrangeiras no PostgreSQL também suportam NOT VALID, o que significa que podemos usar a mesma abordagem discutida anteriormente em CHECK. Vamos criar uma chave estrangeira inválida:
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) NOT VALID
então atualizamos os dados e realizamos a validação:
ALTER TABLE my_table VALIDATE CONSTRAINT fk_group_id
Crie uma restrição única
ALTER TABLE my_table ADD CONSTRAINT uk_my_table UNIQUE (id) --
Como no caso das restrições discutidas anteriormente, o comando captura um bloqueio estrito, sob o qual verifica todas as linhas da tabela em relação à restrição - neste caso, a exclusividade.
É importante saber que nos bastidores o PostgreSQL impõe restrições exclusivas usando índices exclusivos. Em outras palavras, quando uma restrição é criada, um índice exclusivo correspondente com o mesmo nome é criado para atender a essa restrição. Usando a seguinte consulta, você pode descobrir o índice de veiculação da restrição:
SELECT conindid index_oid, conindid::regclass index_name
FROM pg_constraint
WHERE conname = 'uk_my_table_id'
Ao mesmo tempo, usado na maioria das restrições de tempo de criação apenas o mesmo vale para o índice e sua vinculação subsequente para limitar muito rapidamente. Além disso, se você já tem um índice exclusivo criado, você mesmo pode fazer isso criando um índice usando as palavras-chave USING INDEX:
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id UNIQUE
USING INDEX uk_my_table_id -- , PG 9.1
Portanto, a ideia é simples - criamos um índice exclusivo CONCORRENTEMENTE, como discutimos anteriormente, e então criamos uma restrição exclusiva com base nele.
Neste ponto, pode surgir a questão - por que criar uma restrição afinal, se o índice faz exatamente o que é necessário - garante a unicidade dos valores? Se excluirmos os índices parciais da comparação , do ponto de vista funcional, o resultado é realmente quase idêntico. A única diferença que encontramos é que as restrições podem ser adiadas , mas os índices não. A documentação para versões anteriores do PostgreSQL (até e incluindo 9.4) tinha uma nota de rodapécom a informação de que a maneira preferida de criar uma restrição de exclusividade é criar explicitamente uma restrição
ALTER TABLE ... ADD CONSTRAINT
, e o uso de índices deve ser considerado um detalhe de implementação. No entanto, em versões mais recentes, essa nota de rodapé foi removida.
Criação de uma chave primária
Além de ser única, a chave primária impõe a restrição não nula. Se a coluna originalmente tinha tal restrição, não será difícil "transformá-la" em uma chave primária - também criamos um índice único CONCORRENTEMENTE e, em seguida, a chave primária:
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id PRIMARY KEY
USING INDEX uk_my_table_id -- id is NOT NULL
É importante observar que a coluna deve ter uma restrição NOT NULL "justa" - a abordagem CHECK discutida anteriormente não funcionará.
Se não houver limite, até a 11ª versão do PostgreSQL não há nada a ser feito - não há como criar uma chave primária sem travar.
Se você possui PostgreSQL 11 ou mais recente, isso pode ser feito criando uma nova coluna que substituirá a existente. Então, passo a passo.
Crie uma nova coluna que não seja nula por padrão e tenha um valor padrão:
ALTER TABLE my_table ADD COLUMN new_id INTEGER NOT NULL DEFAULT -1 -- PG 11
Configuramos a sincronização dos dados das colunas antigas e novas usando um gatilho:
CREATE FUNCTION on_insert_or_update() RETURNS TRIGGER AS
$$
BEGIN
NEW.new_id = NEW.id;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg BEFORE INSERT OR UPDATE ON my_table
FOR EACH ROW EXECUTE PROCEDURE on_insert_or_update();
Em seguida, você precisa atualizar os dados das linhas que não foram afetadas pelo acionador:
UPDATE my_table SET new_id = id WHERE new_id = -1 --
O pedido com a atualização acima está escrito "na testa", em uma mesa grande não vale a pena fazer isso, pois haverá um longo bloqueio. Conforme mencionado anteriormente, o segundo artigo examinará abordagens para atualizar tabelas grandes. Por enquanto, vamos supor que os dados estejam atualizados e tudo o que resta é trocar as colunas.
ALTER TABLE my_table RENAME COLUMN id TO old_id;
ALTER TABLE my_table RENAME COLUMN new_id TO id;
ALTER TABLE my_table RENAME COLUMN old_id TO new_id;
No PostgreSQL, os comandos DDL são transacionais - isso significa que você pode renomear, adicionar, excluir colunas e, ao mesmo tempo, uma transação paralela não verá isso no curso de suas operações.
Depois de alterar as colunas, resta criar um índice e "limpar" - deletar o gatilho, função e coluna antiga.
Uma folha de referência rápida com migrações
Antes de qualquer comando que capture bloqueios fortes (quase todos
ALTER TABLE ...
), é recomendável chamar:
SET LOCAL lock_timeout TO '100ms'
| Migração | Abordagem recomendada |
|---|---|
| Adicionando uma coluna | |
| Adicionando uma coluna com um valor padrão [e NÃO NULO] | com PostgreSQL 11:
antes do PostgreSQL 11:
|
| Removendo uma coluna |
|
| Criação de índice | Se falhar:
|
| Criação de um índice em uma tabela particionada | Particionamento via herança + declarativo no PG 10:
Particionamento Declarativo com PG 11:
|
| Criação de uma restrição NOT NULL |
|
| Criação de uma chave estrangeira |
|
| Crie uma restrição única |
|
| Criação de uma chave primária | Se a coluna for IS NOT NULL:
Se a coluna IS NULL com PG 11:
|
No próximo artigo, veremos abordagens para atualizar tabelas grandes.
Migrações fáceis para todos!