
Existem muitos artigos que explicam para que serve o Python GIL (The Global Interpreter Lock) (quero dizer, CPython). Resumindo, o GIL evita que o código Python limpo multithreaded use múltiplos núcleos de processador.
No entanto, nós da Vaex executamos a maioria das tarefas de computação intensiva em C ++ com o GIL desativado. Esta é uma prática normal para bibliotecas Python de alto desempenho, onde o Python age apenas como uma cola de alto nível.
O GIL deve ser desabilitado explicitamente, e é responsabilidade do programador, o que ele pode esquecer, o que levará ao uso ineficiente da capacidade. Recentemente, eu mesmo desempenhei o papel de esquecido e encontrei um problema semelhante no Apache Arrow(esta é uma dependência Vaex, então quando o GIL não está desabilitado no Arrow, nós (e todos os outros) experimentamos um impacto no desempenho).
Além disso, ao executar em 64 núcleos, o desempenho Vaex às vezes está longe do ideal. Ele pode estar usando 4000% da CPU em vez de 6400%, o que não combina comigo. Em vez de inserir interruptores aleatoriamente para estudar esse efeito, quero entender o que está acontecendo e, se o problema está no GIL, quero entender por que e como ele desacelera o Vaex.
Por que estou escrevendo isso
Pretendo escrever uma série de artigos cobrindo algumas das ferramentas e técnicas para criar perfis e rastrear o Python com extensões nativas e como essas ferramentas podem ser combinadas para analisar e visualizar o desempenho do Python com o GIL habilitado e desabilitado.
Esperançosamente, isso ajudará a melhorar o rastreamento, a criação de perfil e outras medidas de desempenho no ecossistema da linguagem, bem como o desempenho de todo o ecossistema Python.
Requisitos
Linux
Você precisa de acesso root à máquina Linux (sudo é o suficiente). Ou peça ao administrador do sistema para executar os comandos abaixo para você. Para o restante deste artigo, os privilégios do usuário são suficientes.
Perf
Certifique-se de ter o perf instalado, por exemplo, no Ubuntu, você pode fazer assim:
$ sudo yum install perf
Configuração de kernel
Executar como usuário:
# Enable users to run perf (use at own risk)
$ sudo sysctl kernel.perf_event_paranoid=-1
# Enable users to see schedule trace events:
$ sudo mount -o remount,mode=755 /sys/kernel/debug
$ sudo mount -o remount,mode=755 /sys/kernel/debug/tracing
Pacotes Python
Estaremos usando VizTracer e per4m
$ pip install "viztracer>=0.11.2" "per4m>=0.1,<0.2"
Rastreando o estado de threads e processos com perf
Não há como descobrir o estado do GIL em Python (a não ser usando polling ) porque não há API para isso. Podemos monitorar o estado do kernel e, para isso, precisamos da ferramenta perf .
Com sua ajuda (também conhecido como perf_events), podemos ouvir as mudanças no estado dos processos e threads (estamos apenas interessados em dormir e executar) e registrá-los. O Perf pode parecer intimidante, mas é uma ferramenta poderosa. Para saber mais, recomendo a leitura do artigo de Julia Evans ou do site de Brendan Gregg .
Para sintonizar, primeiro vamos aplicar o perf a um programa simples :
import time
from threading import Thread
def sleep_a_bit():
time.sleep(1)
def main():
t = Thread(target=sleep_a_bit)
t.start()
t.join()
main()
Escutamos apenas alguns eventos para reduzir o ruído (observe o uso de curingas):
$ perf record -e sched:sched_switch -e sched:sched_process_fork \
-e 'sched:sched_wak*' -- python -m per4m.example0
[ perf record: Woken up 2 times to write data ]
[ perf record: Captured and wrote 0,032 MB perf.data (33 samples) ]
E usaremos o comando perf script para gerar um resultado legível adequado para análise.
Texto oculto
$ perf script
:3040108 3040108 [032] 5563910.979408: sched:sched_waking: comm=perf pid=3040114 prio=120 target_cpu=031
:3040108 3040108 [032] 5563910.979431: sched:sched_wakeup: comm=perf pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563910.995616: sched:sched_waking: comm=kworker/31:1 pid=2502104 prio=120 target_cpu=031
python 3040114 [031] 5563910.995618: sched:sched_wakeup: comm=kworker/31:1 pid=2502104 prio=120 target_cpu=031
python 3040114 [031] 5563910.995621: sched:sched_waking: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563910.995622: sched:sched_wakeup: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563910.995624: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=R+ ==> next_comm=kworker/31:1 next_pid=2502104 next_prio=120
python 3040114 [031] 5563911.003612: sched:sched_waking: comm=kworker/32:1 pid=2467833 prio=120 target_cpu=032
python 3040114 [031] 5563911.003614: sched:sched_wakeup: comm=kworker/32:1 pid=2467833 prio=120 target_cpu=032
python 3040114 [031] 5563911.083609: sched:sched_waking: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563911.083612: sched:sched_wakeup: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563911.083613: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=R ==> next_comm=ksoftirqd/31 next_pid=198 next_prio=120
python 3040114 [031] 5563911.108984: sched:sched_waking: comm=node pid=2446812 prio=120 target_cpu=045
python 3040114 [031] 5563911.109059: sched:sched_waking: comm=node pid=2446812 prio=120 target_cpu=045
python 3040114 [031] 5563911.112250: sched:sched_process_fork: comm=python pid=3040114 child_comm=python child_pid=3040116
python 3040114 [031] 5563911.112260: sched:sched_wakeup_new: comm=python pid=3040116 prio=120 target_cpu=037
python 3040114 [031] 5563911.112262: sched:sched_wakeup_new: comm=python pid=3040116 prio=120 target_cpu=037
python 3040114 [031] 5563911.112273: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
python 3040116 [037] 5563911.112418: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112450: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112473: sched:sched_wake_idle_without_ipi: cpu=31
swapper 0 [031] 5563911.112476: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563911.112485: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
python 3040116 [037] 5563911.112485: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112489: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112496: sched:sched_switch: prev_comm=python prev_pid=3040116 prev_prio=120 prev_state=S ==> next_comm=swapper/37 next_pid=0 next_prio=120
swapper 0 [031] 5563911.112497: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563911.112513: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
swapper 0 [037] 5563912.113490: sched:sched_waking: comm=python pid=3040116 prio=120 target_cpu=037
swapper 0 [037] 5563912.113529: sched:sched_wakeup: comm=python pid=3040116 prio=120 target_cpu=037
python 3040116 [037] 5563912.113595: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563912.113620: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
swapper 0 [031] 5563912.113697: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
Dê uma olhada na quarta coluna (tempo em segundos): o programa adormeceu (passou um segundo). Aqui vemos a entrada para o estado de sono:
python 3040114 [031] 5563911.112513: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
Isso significa que o kernel mudou o estado do thread Python para
S
(= dormindo).
Um segundo depois, o programa acordou:
swapper 0 [031] 5563912.113697: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
Claro, para entender o que está acontecendo, você terá que coletar as ferramentas. Sim, o resultado também pode ser facilmente analisado usando per4m , mas antes de continuarmos, quero visualizar o fluxo de um programa um pouco mais complexo usando VizTracer .
VizTracer
É um rastreador Python capaz de visualizar o trabalho que um programa está fazendo em um navegador. Vamos aplicá-lo a um programa mais complexo :
import threading
import time
def some_computation():
total = 0
for i in range(1_000_000):
total += i
return total
def main():
thread1 = threading.Thread(target=some_computation)
thread2 = threading.Thread(target=some_computation)
thread1.start()
thread2.start()
time.sleep(0.2)
for thread in [thread1, thread2]:
thread.join()
main()
O resultado da operação do tracer:
$ viztracer -o example1.html --ignore_frozen -m per4m.example1 Loading finish Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ... Dumping trace data to json, total entries: 94, estimated json file size: 11.0KiB Generating HTML report Report saved.
Esta é a aparência do HTML resultante:
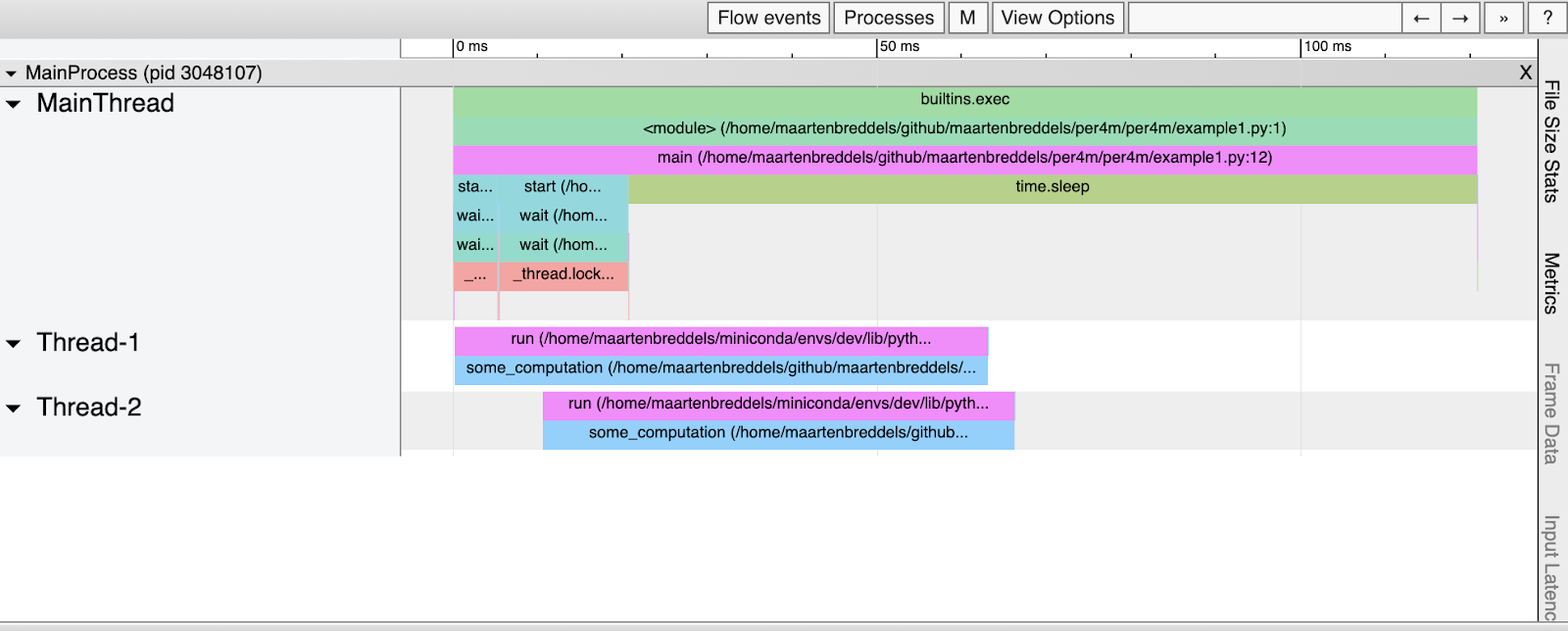
Parece ter sido
some_computation
executado em paralelo (duas vezes), embora saibamos que o GIL impede isso. O que está acontecendo aqui?
Combinando VizTracer e resultados de desempenho
Vamos aplicar perf como em example0.py. Agora vamos adicionar um argumento
-k CLOCK_MONOTONIC
para usar o mesmo relógio do VizTracer e pedir para gerar JSON em vez de HTML:
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*' \
-k CLOCK_MONOTONIC -- viztracer -o viztracer1.json --ignore_frozen -m per4m.example1
Em seguida, usamos per4m para converter os resultados do script perf para JSON que o VizTracer pode ler:
$ perf script | per4m perf2trace sched -o perf1.json
Wrote to perf1.json
Agora, usando o VizTracer, vamos combinar os dois arquivos JSON:
$ viztracer --combine perf1.json viztracer1.json -o example1_state.html Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ... Dumping trace data to json, total entries: 131, estimated json file size: 15.4KiB Generating HTML report Report saved.
Aqui está o que temos:
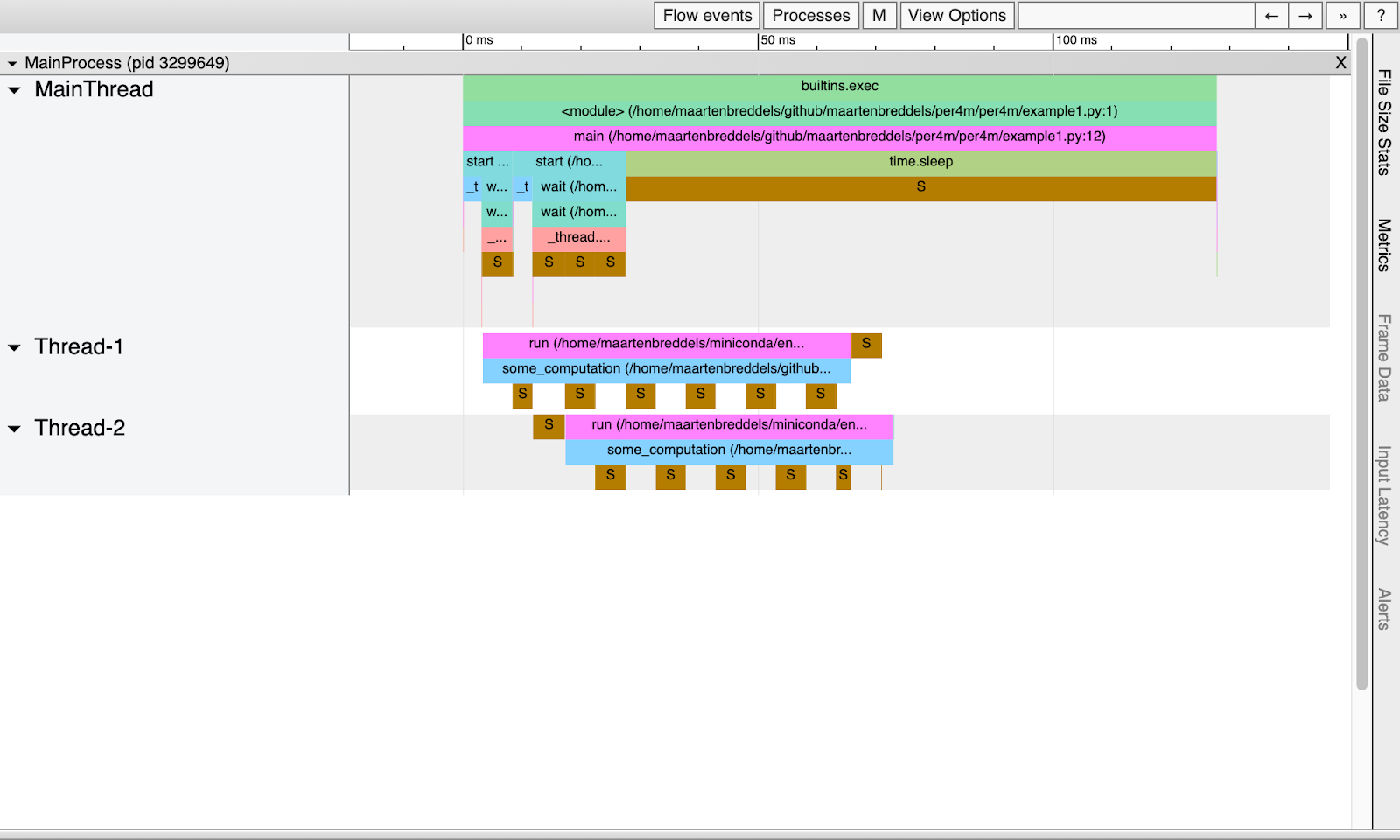
Obviamente, os threads dormem regularmente devido ao GIL e não são executados em paralelo.
Observação : a fase de sono tem cerca de 5ms de duração, o que corresponde ao sys.getswitchinterval padrão
Definição GIL
Nosso processo vai dormir, mas não vemos a diferença entre os estados de sono que são iniciados por uma chamada
time.sleep
ou o GIL. Existem várias maneiras de saber a diferença, vamos examinar duas delas.
Através do rastreamento de pilha
Com ajuda
perf record -g
(ou melhor
perf record --call-graph dwarf
, isso implica
-g
), obtemos os rastreamentos de pilha para cada evento de perf.
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*'\
-k CLOCK_MONOTONIC --call-graph dwarf -- viztracer -o viztracer1-gil.json --ignore_frozen -m per4m.example1
Loading finish
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/viztracer1-gil.json ...
Dumping trace data to json, total entries: 94, estimated json file size: 11.0KiB
Report saved.
[ perf record: Woken up 3 times to write data ]
[ perf record: Captured and wrote 0,991 MB perf.data (164 samples) ]
Observando o resultado do script de desempenho (que adicionamos por motivos de desempenho
--no-inline
), obtemos muitas informações. Observe o evento de mudança de estado, acontece que take_gil foi chamado !
Texto oculto
$ perf script --no-inline | less
...
viztracer 3306851 [059] 5614683.022539: sched:sched_switch: prev_comm=viztracer prev_pid=3306851 prev_prio=120 prev_state=S ==> next_comm=swapper/59 next_pid=0 next_prio=120
ffffffff96ed4785 __sched_text_start+0x375 ([kernel.kallsyms])
ffffffff96ed4785 __sched_text_start+0x375 ([kernel.kallsyms])
ffffffff96ed4b92 schedule+0x42 ([kernel.kallsyms])
ffffffff9654a51b futex_wait_queue_me+0xbb ([kernel.kallsyms])
ffffffff9654ac85 futex_wait+0x105 ([kernel.kallsyms])
ffffffff9654daff do_futex+0x10f ([kernel.kallsyms])
ffffffff9654dfef __x64_sys_futex+0x13f ([kernel.kallsyms])
ffffffff964044c7 do_syscall_64+0x57 ([kernel.kallsyms])
ffffffff9700008c entry_SYSCALL_64_after_hwframe+0x44 ([kernel.kallsyms])
7f4884b977b1<a href="https://www.maartenbreddels.com/cdn-cgi/l/email-protection"> [email protected]@GLIBC_2.3.2+0x271 (/usr/lib/x86_64-linux-gnu/libpthread-2.31.so)
55595c07fe6d take_gil+0x1ad (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfaa0b3 PyEval_RestoreThread+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c000872 lock_PyThread_acquire_lock+0x1d2 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe71f3 _PyMethodDef_RawFastCallKeywords+0x263 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7313 _PyCFunction_FastCallKeywords+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d657 call_function+0x3b7 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b00 _PyFunction_FastCallKeywords+0x520 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b00 _PyFunction_FastCallKeywords+0x520 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060ae4 _PyEval_EvalFrameDefault+0x3f4 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c074e5d builtin_exec+0x33d (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7078 _PyMethodDef_RawFastCallKeywords+0xe8 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7313 _PyCFunction_FastCallKeywords+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c066c39 _PyEval_EvalFrameDefault+0x6549 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb77e0 _PyEval_EvalCodeWithName+0xc80 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b62 _PyFunction_FastCallKeywords+0x582 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060ae4 _PyEval_EvalFrameDefault+0x3f4 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb81e2 PyEval_EvalCode+0x22 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0c51d1 run_mod+0x31 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0cf31d PyRun_FileExFlags+0x9d (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0cf50a PyRun_SimpleFileExFlags+0x1ba (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0d05f0 pymain_main+0x3e0 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0d067b _Py_UnixMain+0x3b (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
7f48849bc0b2 __libc_start_main+0xf2 (/usr/lib/x86_64-linux-gnu/libc-2.31.so)
55595c075100 _start+0x28 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
…
Nota : também chamado
pthread_cond_timedwait
, é usado por https://github.com/sumerc/gilstats.py para eBPF se você estiver interessado em outros mutexes.
Outra observação : observe que não há rastreamento de pilha Python aqui, mas em vez disso, temos
_PyEval_EvalFrameDefault
mais. No futuro, pretendo escrever como inserir um rastreamento de pilha.
A ferramenta de conversão
per4m perf2trace
entende isso e gera um resultado diferente quando o rastreamento contém
take_gil
:
$ perf script --no-inline | per4m perf2trace sched -o perf1-gil.json
Wrote to perf1-gil.json
$ viztracer --combine perf1-gil.json viztracer1-gil.json -o example1-gil.html
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ...
Dumping trace data to json, total entries: 131, estimated json file size: 15.4KiB
Generating HTML report
Report saved.
Nós temos:
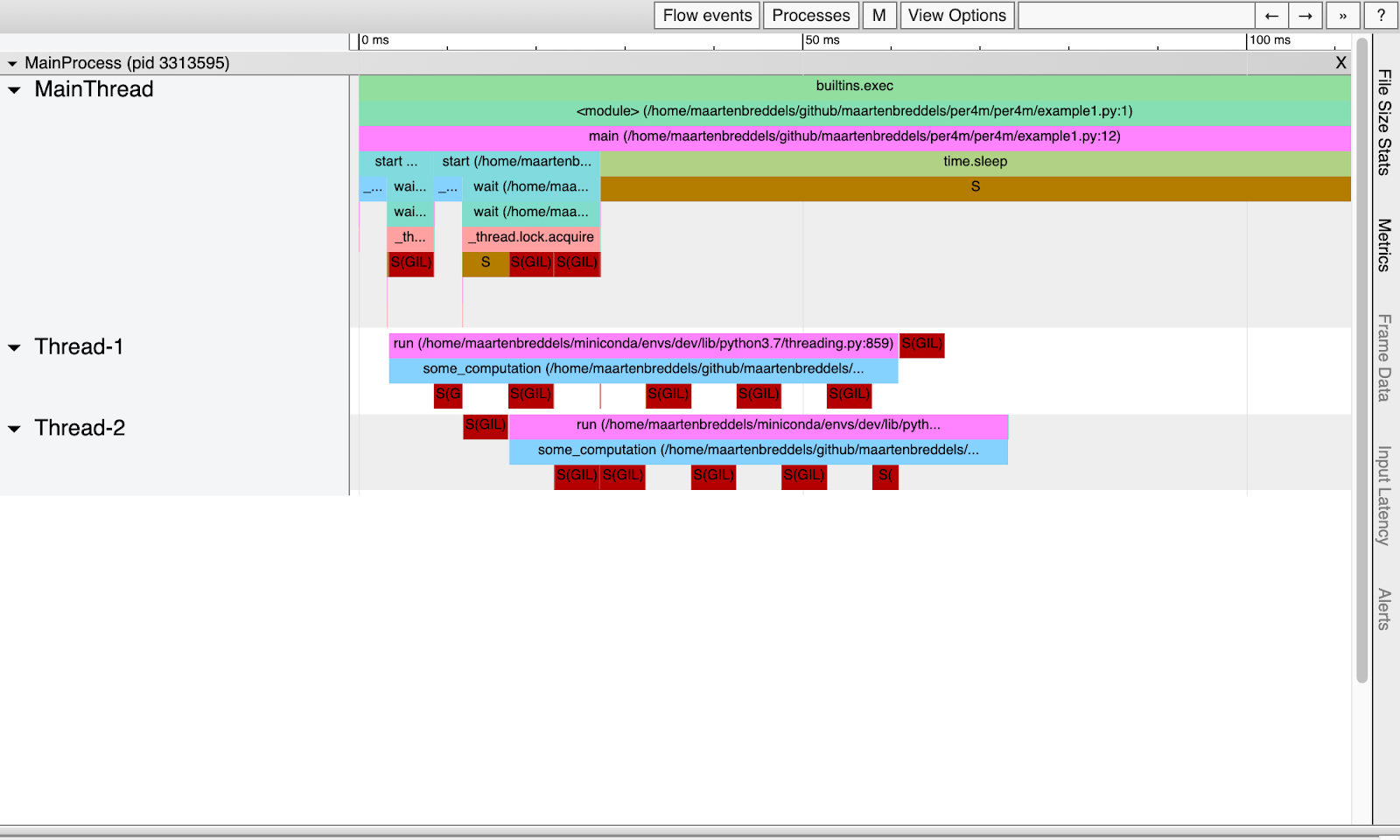
Agora podemos ver exatamente onde o GIL entra em jogo!
Por meio de sondagem (kprobes / uprobes)
Sabemos quando os processos entram em suspensão (devido ao GIL ou outros motivos), mas se você quiser saber mais sobre quando o GIL é ativado ou desativado, você precisa saber quando os resultados são chamados e retornados
take_gil
e
drop_gil
. Esse rastreamento pode ser obtido por sondagem com perf. Em um ambiente de usuário, os probes são uprobes, que são análogos a kprobes, que, como você deve ter adivinhado, funcionam no ambiente do kernel. Novamente, Julia Evans é uma ótima fonte de informações adicionais .
Instale 4 sondas:
sudo perf probe -f -x `which python` python:take_gil=take_gil
sudo perf probe -f -x `which python` python:take_gil=take_gil%return
sudo perf probe -f -x `which python` python:drop_gil=drop_gil
sudo perf probe -f -x `which python` python:drop_gil=drop_gil%return
Added new events:
python:take_gil (on take_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
python:take_gil_1 (on take_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:take_gil_1 -aR sleep 1
Failed to find "take_gil%return",
because take_gil is an inlined function and has no return point.
Added new event:
python:take_gil__return (on take_gil%return in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:take_gil__return -aR sleep 1
Added new events:
python:drop_gil (on drop_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
python:drop_gil_1 (on drop_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:drop_gil_1 -aR sleep 1
Failed to find "drop_gil%return",
because drop_gil is an inlined function and has no return point.
Added new event:
python:drop_gil__return (on drop_gil%return in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:drop_gil__return -aR sleep 1
Existem algumas reclamações, e por causa das inline
drop_gil
,
take_gil
vários probes / eventos foram adicionados (ou seja, a função é apresentada várias vezes no arquivo binário), mas tudo funciona.
Nota : Eu posso ter tido sorte que meu binário Python (de conda-forge) foi compilado de forma que o
take_gil
/ correspondente
drop_gil
(e seus resultados) funcionou com sucesso para resolver este problema.
Observe que os probes não afetam o desempenho e, apenas quando estão "ativos" (por exemplo, quando os monitoramos a partir do perf), eles executam o código em um branch diferente. Durante o monitoramento, as páginas afetadas são copiadas para o processo monitorado e os pontos de verificação são inseridos nos locais certos(INT3 para processadores x86). O ponto de verificação dispara um evento para desempenho com pouca sobrecarga. Se você deseja remover as sondas, execute o comando:
$ sudo perf probe --del 'python*'
Agora que o perf sabe sobre novos eventos que pode ouvir, vamos executá-lo novamente com um argumento adicional
-e 'python:*gil*'
:
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*' -k CLOCK_MONOTONIC \
-e 'python:*gil*' -- viztracer -o viztracer1-uprobes.json --ignore_frozen -m per4m.example1
Nota : nós o removemos
--call-graph dwarf
, caso contrário o perf não chegará a tempo e perderemos eventos.
Então, usando per4m perf2trace, nós o convertemos para JSON, o que é compreensível para VizTracer, e ao mesmo tempo obtemos novas estatísticas.
$ perf script --no-inline | per4m perf2trace gil -o perf1-uprobes.json
...
Summary of threads:
PID total(us) no gil% has gil% gil wait%
-------- ----------- ----------- ------------ -------------
3353567* 164490.0 65.9 27.3 6.7
3353569 66560.0 0.3 48.2 51.5
3353570 60900.0 0.0 56.4 43.6
High 'no gil' is good, we like low 'has gil',
and we don't want 'gil wait'. (* indicates main thread)
...
Wrote to perf1-uprobes.json
O subcomando
per4m perf2trace gil
também fornece como resultado gil_load . Com isso, aprendemos que ambos os threads esperam pelo GIL cerca da metade do tempo, como esperado.
Com o mesmo arquivo perf.data registrado pelo perf, também podemos gerar informações sobre o estado de uma thread ou processo. Mas como estávamos executando sem rastreamentos de pilha, não sabemos se o processo adormeceu devido ao GIL ou não.
$ perf script --no-inline | per4m perf2trace sched -o perf1-state.json
Wrote to perf1-state.json
Finalmente, vamos colocar os três resultados juntos:
$ viztracer --combine perf1-state.json perf1-uprobes.json viztracer1-uprobes.json -o example1-uprobes.html Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1-uprobes.html ... Dumping trace data to json, total entries: 10484, estimated json file size: 1.2MiB Generating HTML report Report saved.
O VizTracer dá uma boa ideia de quem tinha o GIL e quem estava esperando por ele:

Acima de cada thread é escrito quando o thread ou processo espera pelo GIL e quando ele é ativado (marcado como LOCK). Observe que esses períodos se sobrepõem aos períodos em que o thread ou processo está ativo (em execução!). Observe também que vemos apenas um thread ou processo no estado de execução, como deveria ser por causa do GIL.
O tempo entre chamadas
take_gil
, ou seja, entre bloqueios (e, portanto, entre dormir ou acordar), é exatamente o mesmo que na tabela acima na coluna gil wait%. A duração da ativação GIL para cada thread, rotulada LOCK, corresponde ao tempo na coluna gil%.
Liberando o Kraken ... ghm, GIL
Vimos como, quando um programa Python puro é multithread, o GIL limita o desempenho permitindo que apenas um thread ou processo seja executado por vez (para um processo Python, é claro, e possivelmente no futuro para um (sub) interpretador) . Agora vamos ver o que acontece se você desabilitar o GIL, como acontece ao executar funções do NumPy.
O segundo exemplo executa o
some_numpy_computation
que chama a função NumPy M = 4 vezes em paralelo em dois threads, enquanto o thread principal executa código Python puro.
import threading
import time
import numpy as np
N = 1024*1024*32
M = 4
x = np.arange(N, dtype='f8')
def some_numpy_computation():
total = 0
for i in range(M):
total += x.sum()
return total
def main(args=None):
thread1 = threading.Thread(target=some_numpy_computation)
thread2 = threading.Thread(target=some_numpy_computation)
thread1.start()
thread2.start()
total = 0
for i in range(2_000_000):
total += i
for thread in [thread1, thread2]:
thread.join()
main()
Em vez de executar este script com perf e VizTracer, usaremos um utilitário
per4m giltracer
que automatiza todas as etapas acima. Ela o deixará um pouco mais inteligente. Basicamente, executaremos perf duas vezes, uma sem rastreamento de pilha e a segunda vez com ele, e importaremos o módulo / script antes de executar sua função principal para eliminar um rastreamento desinteressante como a mesma importação. Isso acontecerá rápido o suficiente para que não percamos eventos.
$ giltracer --state-detect -o example2-uprobes.html -m per4m.example2 ...
Totais de streams:
PID total(us) no gil% has gil% gil wait%
-------- ----------- ----------- ------------ -------------
3373601* 1359990.0 95.8 4.2 0.1
3373683 60276.4 84.6 2.2 13.2
3373684 57324.0 89.2 1.9 8.9
High 'no gil' is good, we like low 'has gil',
and we don't want 'gil wait'. (* indicates main thread)
...
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example2-uprobes.html ...
...
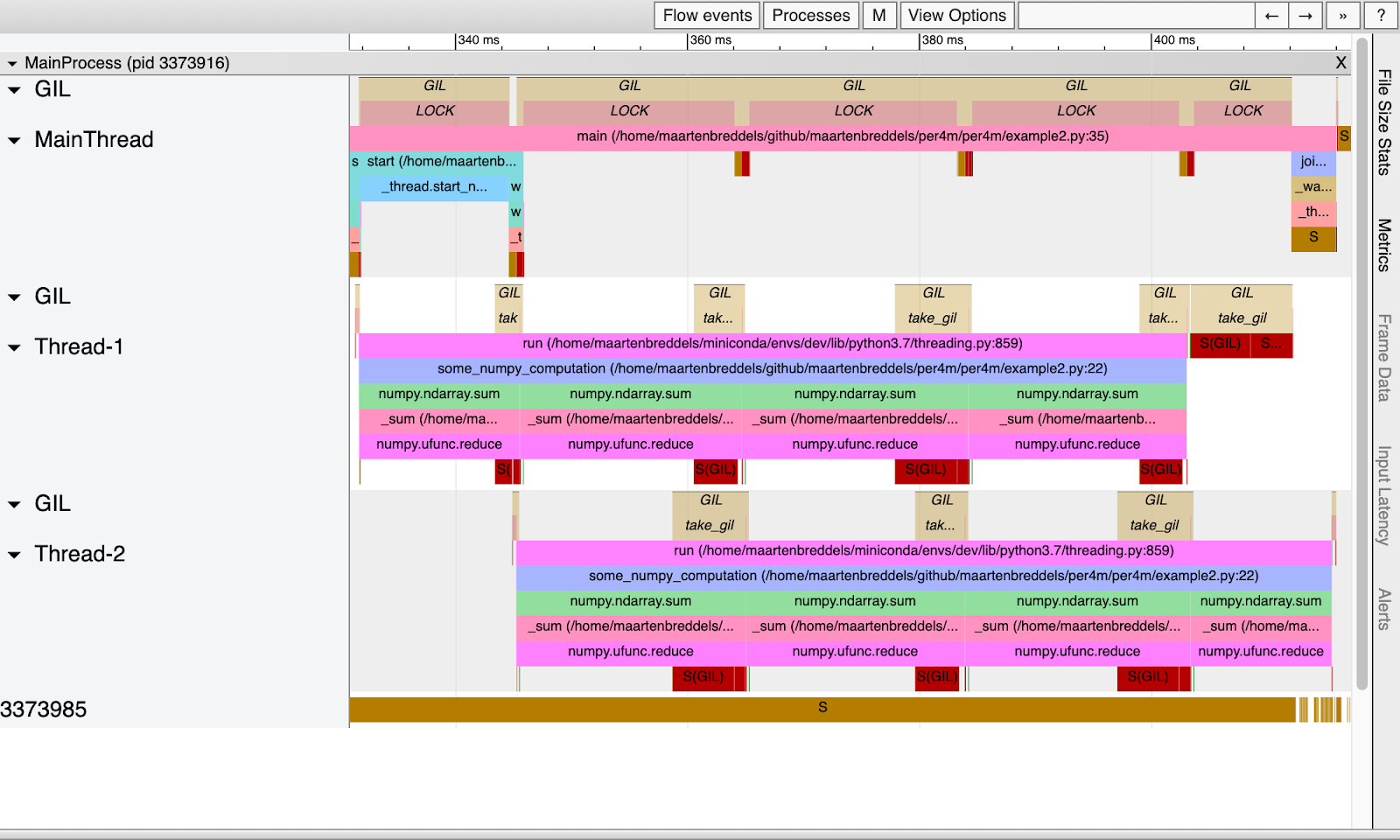
Embora o thread principal execute código Python (GIL está habilitado para ele, o que é denotado pela palavra LOCK), outros threads também são executados em paralelo. Observe que no exemplo puro do Python, temos um thread ou processo em execução ao mesmo tempo. E aqui, na verdade, três threads são executados em paralelo. Isso é possível porque as rotinas NumPy incluídas com C / C ++ / Fortran desabilitaram o GIL.
No entanto, o GIL ainda afeta os threads, porque quando a função NumPy retorna ao Python, ela precisa obter o GIL novamente, como visto nos blocos longos
take_gil
. Isso leva 10% do tempo de cada thread.
Integração Jupyter
Como meu fluxo de trabalho geralmente envolve a execução de um MacBook (que não executa perf, mas oferece suporte a dtrace) conectado a uma máquina Linux remotamente, eu uso o notebook Jupyter para executar código remotamente. E como sou um desenvolvedor Jupyter, tive que fazer um wrapper com
cell magic
.
# this registers the giltracer cell magic
%load_ext per4m
%%giltracer
# this call the main define above, but this can also be a multiline code cell
main()
Saving report to /tmp/tmpvi8zw9ut/viztracer.json ...
Dumping trace data to json, total entries: 117, estimated json file size: 13.7KiB
Report saved.
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0,094 MB /tmp/tmpvi8zw9ut/perf.data (244 samples) ]
Wait for perf to finish...
perf script -i /tmp/tmpvi8zw9ut/perf.data --no-inline --ns | per4m perf2trace gil -o /tmp/tmpvi8zw9ut/giltracer.json -q -v
Saving report to /home/maartenbreddels/github/maartenbreddels/fastblog/_notebooks/giltracer.html ...
Dumping trace data to json, total entries: 849, estimated json file size: 99.5KiB
Generating HTML report
Report saved.
Faça download do giltracer.html
Abra o giltracer.html em uma nova guia (pode não funcionar devido à segurança)
Conclusão
Com perf, podemos determinar os estados de processos ou threads, o que ajuda a entender qual deles tem o GIL habilitado em Python. E com a ajuda de stack traces, você pode determinar que o GIL foi a causa do sono, e não
time.sleep
, por exemplo.
A combinação de uprobes com perf permite que você rastreie a invocação e o retorno dos resultados da função
take_gil
e obtenha
drop_gil
ainda mais insight sobre o impacto do GIL em seu programa Python.
Nosso trabalho é facilitado pelo pacote experimental per4m, que converte o script perf para o formato JSON VizTracer, bem como algumas ferramentas de orquestração.
Muito bukaf, não dominei
Se você deseja apenas ver o impacto do GIL, execute isto uma vez:
sudo yum install perf
sudo sysctl kernel.perf_event_paranoid=-1
sudo mount -o remount,mode=755 /sys/kernel/debug
sudo mount -o remount,mode=755 /sys/kernel/debug/tracing
sudo perf probe -f -x `which python` python:take_gil=take_gil
sudo perf probe -f -x `which python` python:take_gil=take_gil%return
sudo perf probe -f -x `which python` python:drop_gil=drop_gil
sudo perf probe -f -x `which python` python:drop_gil=drop_gil%return
pip install "viztracer>=0.11.2" "per4m>=0.1,<0.2"
Exemplo de uso:
# module
$ giltracer per4m/example2.py
# script
$ giltracer -m per4m.example2
# add thread/process state detection
$ giltracer --state-detect -m per4m.example2
# without uprobes (in case that fails)
$ giltracer --state-detect --no-gil-detect -m per4m.example2
Planos futuros
Eu gostaria de não ter que desenvolver essas ferramentas. Espero ter conseguido inspirar alguém a criar produtos melhores do que os meus. Eu quero me concentrar em escrever código de alto desempenho. No entanto, tenho planos para o futuro:
- Desenterre um medidor de desempenho no VizTracer para verificar as perdas de cache ou o tempo de inatividade do processo.
- Implemente rastreio de pilha python em rastreamentos de perf para combinar com ferramentas como http://www.brendangregg.com/offcpuanalysis.html
- Repita o mesmo exercício com dtrace para usar no macOS.
- Detecte automaticamente quais funções C não desativam o GIL ( https://github.com/vaexio/vaex/pull/1114 , https://github.com/apache/arrow/pull/7756 )
- , https://github.com/h5py/h5py/issues/1516