Na dentsu, criamos o Podcaster, uma ferramenta analítica para medir as audiências de podcast e planejar anúncios nelas. Como começamos a coletar dados e resolver o problema de reconhecimento de público, quais dificuldades encontramos e o que resultou disso, contaremos neste artigo.

fundo
A programação de podcast agora é baseada em dados de vendedores (estúdios ou agências especializadas) que entram em contato com os autores do podcast e solicitam uma descrição dos ouvintes. Os próprios podcasters recebem dados da plataforma em que o podcast é postado ou de um sistema de estatísticas externo. Existem várias limitações nesta abordagem:
- os podcasts podem ser selecionados em uma lista limitada, com a qual o vendedor tem acordos e possui dados sobre o público do podcast;
- não há possibilidade de escolher podcasts mais afinitivos (afinidade é a proporção de um determinado público-alvo entre os ouvintes para todos os ouvintes do podcast), porque, via de regra, está disponível uma descrição do núcleo dos ouvintes, e geralmente é a mesma em termos de idade para a maioria dos podcasts;
- os próprios podcasts têm dados sobre cada podcast, mas nem os podcasts nem os vendedores sabem como os ouvintes fazem a transição entre os podcasts.
Para tornar a programação de podcasts mais inteligente, tentamos formar um sistema de análise unificado que seria baseado nos dados da lista de podcasts existentes e na base de usuários que ouvem esses podcasts, bem como na capacidade de determinar o sexo e a idade desses mesmos ouvintes.
Uma abordagem
Rapidamente percebemos que não poderíamos obter audições específicas do usuário. Mas existem curtidas / assinantes de podcast: uma mecânica semelhante funciona, por exemplo, no Instagram com blogueiros, quando uma pessoa se inscreve em um blogueiro para ver suas notícias. Presumimos que a mesma história está acontecendo com os podcasts - os ouvintes assinam seus podcasts favoritos para que sejam rapidamente acessíveis e possam acompanhar novos episódios.
Decidimos testar essa hipótese usando uma plataforma popular por meio da qual o público ouve podcasts. De acordo com Tiburon, Yandex.Music é o líder em ouvir podcasts.
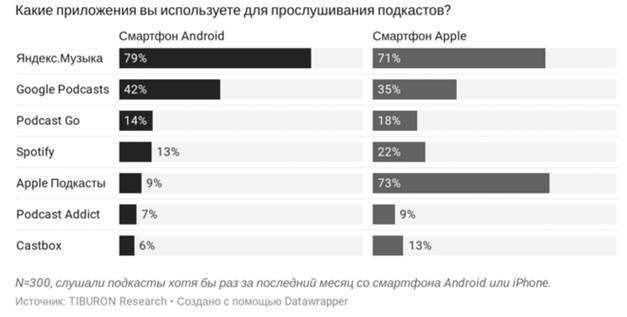
Felizmente, o Ya Music tem uma página de usuário que fornece informações sobre assinaturas de podcast.
Um exemplo de perfil com foto e assinaturas de podcasts
Além da assinatura em si, há um apelido e avatar de usuário de domínio público. Isso já é alguma coisa, pois na verdade vemos o cerne dos ouvintes de podcast, ou seja, aqueles que os ouvem regularmente. Também aqui temos o link do podcast do usuário que queríamos encontrar.
Mecânica
Começamos a coletar dados, ou seja, usuários e podcasts que os ouvintes assinaram. Inicialmente, encontramos usuários Ya.Muzyka com podcasts sobre os dados de funcionários da dentsu que forneceram suas caixas de correio no Yandex. Não foi difícil expandir o projeto, já que trabalhamos com dados públicos há vários anos.
A boa notícia é que a base de assinantes do podcast estava crescendo muito rapidamente - em apenas um mês e meio, obtivemos mais de 10.000 usuários que assinaram pelo menos um podcast.
Mas também houve uma má notícia - nem sempre é possível determinar o sexo e a idade a olho nu pela foto e pelo apelido, ou melhor, é impossível de todo. Para nós, para podermos selecionar podcasts relevantes para públicos diferentes, não podemos prescindir do sexo e da idade. Nossa rede neural
lidou com essa tarefa de determinar o sexo e a idade a partir de uma fotografia , cuja precisão é de 96%. O algoritmo é simples: tiramos uma foto do usuário de Y. Music, procuramos um rosto e usamos para determinar o sexo e a idade. O rosto é encontrado pela biblioteca de reconhecimento de rosto
usando dlib. E no centro de nossa rede neural está um modelo VGGFace pré-treinado com base na arquitetura ResNet-50, que treinamos em fotos de usuários VK disponíveis por meio da API pública. O conjunto de dados consiste em um milhão de fotografias que foram adicionalmente aumentadas por meio de albumentações. Deve-se observar que não consideramos fotografias de usuários menores de 12 anos e maiores de 65 anos para fins de treinamento.
resultados
Após o treinamento, percebemos que em cerca de 45% dos perfis de usuários com podcasts, podemos determinar sexo e idade, já que existem muitos perfis sem uma foto ou imagem, um símbolo ou apenas uma foto de baixa qualidade. Mas mesmo esse resultado nos convém.
Dada a dinâmica de localização de perfis que assinam podcasts, esperamos que em poucos meses a base de ouvintes seja de 50.000 perfis, e 22.500 deles terão gênero e idade.
Exemplo de um perfil pelo qual não podemos determinar sexo e idade.
Os desenvolvimentos atuais nos permitem fazer amostras de podcasts afinitivos para vários grupos de público.
Uma seleção de 20-50 podcasts em tópicos relevantes para a marca

Afinidade = público-alvo entre os ouvintes de podcast / todos os ouvintes de podcast) / (todos os ouvintes de podcast / todas as pessoas com podcasts)
Também podemos analisar um podcast específico se o anunciante estiver interessado nele.
Ao ver quantas pessoas estão inscritas em podcasts, podemos fazer recomendações sobre o pacote de podcast que criará o maior alcance.
Curva de cobertura para 50 podcasts selecionados
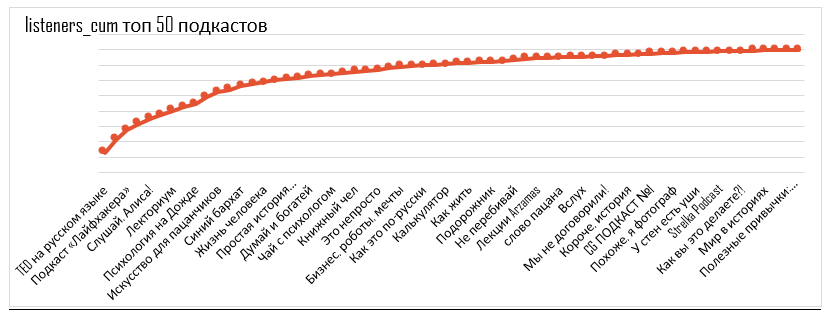
Cada ponto +1 podcast por mix. O primeiro ponto é o podcast com a maior audiência única, o último ponto é o podcast com a menor audiência única.
Mecânica da curva e modelo matemático
Primeiramente, pegamos o podcast que tem um público maior, no nosso caso é o podcast 3. Abaixo está uma tabela que revela a lógica da busca, ou seja, o princípio da distribuição dos conciliadores entre os podcasts.

Em seguida, eliminamos os ouvintes que alcançamos com o podcast 3 e, novamente, selecionamos o podcast com o público mais exclusivo (podcast 4). Este é um podcast que nos dá 2 novos ouvintes únicos, por isso recomendamos colocá-lo em seguida.

Repetimos o exercício e descobrimos que não cobriremos mais ouvintes únicos, ou seja, a colocação em 2 de 6 podcasts é suficiente para cobrir todo o público único possível.

conclusões
Não respondemos a todas as perguntas, por isso continuamos pesquisando dados. Por exemplo, recentemente Ya.Muzyka começou a publicar informações sobre o número de público inscrito para cada um dos podcasts. Agora entendemos o volume dos ouvintes coletados do total.
Estamos trabalhando na mecânica de combinar dados de assinatura com dados de sites e podcasters para refinar o modelo de estimativa do número e composição de ouvintes. Mas já agora, nossa abordagem está ajudando a mudar o esquema de planejamento para integrações de publicidade em podcasts e proceder não a partir de dados agregados de vendedores ou da intuição dos anunciantes sobre o público do podcast, mas do público da marca. E também para compor pacotes de podcast que sejam relevantes especificamente para o público dessa marca e construir o máximo alcance para ele.
Autor Sasha_Kopylova