
Cada vez que surge a questão acalentada, se devo atualizar as placas na sala do servidor ou não, eu leio artigos semelhantes e assisto a esses vídeos (não, materiais de marketing da Nvidia, é claro, não são confiáveis, como o caso recente com o número de núcleos CUDA mostrou).
O canal "Este Computador" é muito subestimado, mas o autor não trata do ML. Em geral, ao analisar comparações de aceleradores para ML, várias coisas costumam chamar sua atenção:
- Os autores costumam levar em consideração apenas a "adequação" ao mercado de novos cartões nos Estados Unidos;
- As avaliações estão longe das pessoas e são feitas em grades padrão (o que provavelmente é bom no geral), sem detalhes;
- O popular mantra de treinar mais e mais redes gigantescas altera a comparação;
Você não precisa estar com dezoito centímetros na testa para saber a resposta óbvia para a pergunta "qual carta é melhor?": As cartas da série 20 * não foram para as massas, a 1080 Ti com Avito ainda é muito atraente (e, curiosamente, provavelmente esta razão).
, Multi-Instance-GPU 100 TF32 Ampere (3090 100). :
- Ampere? ( — );
- A100 ( — — );
- , A100 - ( — );
- MIG ( — , );
.
. :
- 3090 30-40% . ;
- A100 . Nvidia 1 , ;
- , PCIE A100 ATX ( Nvidia , , "" );
- 3080 ( , ) , .. , - ( , 1 , );
— — . , , "" ( ) - - .
Nvidia, 3090 100 15-20 , Maxwell Pascal. , :
- 4 * 1080 Ti (Pascal) 75-80 100% ;
- 3 * Titan X (Maxwell) 85 100% ;
- 3 * 3090 (Ampere) 60-70 100% ;
- , , " ";
- "", ;
"" — 3 :
- ;
- 3090 , , ;
- 3090 ( - , );

, - ?
, , ( , ), gpu-burn
. , , .
| Test | GPU | Gflop/s |
|---|---|---|
./gpu_burn 120
|
Titan X (Maxwell) | 4,300 |
./gpu_burn 120
|
1080 Ti (Pascal) | 8,500 |
./gpu_burn 120
|
3090 (Ampere) | 16,500 |
./gpu_burn 120
|
A100 (wo MIG) | 16,700 |
./gpu-burn -tc 120
|
3090 (Ampere) | 38,500 |
./gpu-burn -tc 120
|
A100 (wo MIG) | 81,500 |
MIG , .
, 1080 Ti Titan X "" ( ). Nvidia, / — - 3-4 . . A100 Nvidia . 1080Ti , 50 100 .
| GPU | Mem | |
|---|---|---|
| Titan X (Maxwell) | 12G | 10,000 () |
| 1080 Ti | 11G | 25,000 () |
| 3090 (Ampere) | 24G | 160,000+ () |
| A100 (wo MIG) | 40G | US$12,500 () |
.
3090 A100 c MIG
3090
— . , 3090 100 2-3 1080 Ti, 1 2-3 1080 Ti 4 PCIE 12 ? 3-4 PCIE A100 , compute instance MIG?
— , — , .
? , 8 — 16 4-5 , ATX . DGX Workstation DGX 50% , Mikrotik Gigabyte.
( PNY c Quadro, ). 7 ( 7 PCIE ), "" ( ). PCIE 4.0 , .
:
, . , .
— Distributed Data Parallel PyTorch (DDP, "" ) 1 1 . 1 1+ . 2 1 , IO / compute / RAM. 1080 Ti 2 1 ( 5-10% 40-50%). — exception.
RuntimeError: NCCL error in: /opt/conda/conda-bld/pytorch_1603729096996/work/torch/lib/c10d/ProcessGroupNCCL.cpp:784, invalid usage, NCCL version 2.7.8
. - - , - TF32 ( ), - MPS 3090 :
- Titan X 1080 Ti (~16 GB 7-8 GB);
- 3 , Titan X (Maxwell);
- [ 1080 Ti];
- — 90%;
2 DDP 1 , 2 "" , — . 2 * 3090 :
| Epoch time, m | Type | Workers | Batch | Params | |-----------------|------|---------|---------|----------------------| | exception | DDP | 4 | 50 * 4 | | | 3.8 | DDP | 2 | 50 * 2 | | | 3.9 | DDP | 2 | 50 * 2 | cudnn_benchmark=True | | 3.6 | DDP | 2 | 100 * 2 | |
, Nvidia MPS 2 , PyTorch RPC-. , ( ).
, 3090 . , , "" (, ), 2-3 . 2-3 , .
TLDR:
- 3090 ( — 3090 2 8- , 2000- 4-5 , 2 );
- 10-20 ;
- (, ), — ;
- — ;
A100 MIG
, , 100 , 3 1 . AMP / FP16, 100 .
A100 MIG (Multi Instance GPU). " " "" Compute Instances, .
, , :
+--------------------------------------------------------------------------+ | GPU instance profiles: | | GPU Name ID Instances Memory P2P SM DEC ENC | | Free/Total GiB CE JPEG OFA | |==========================================================================| | 0 MIG 1g.5gb 19 0/7 4.75 No 14 0 0 | | 1 0 0 | +--------------------------------------------------------------------------+ | 0 MIG 2g.10gb 14 0/3 9.75 No 28 1 0 | | 2 0 0 | +--------------------------------------------------------------------------+ | 0 MIG 3g.20gb 9 0/2 19.62 No 42 2 0 | | 3 0 0 | +--------------------------------------------------------------------------+ | 0 MIG 4g.20gb 5 0/1 19.62 No 56 2 0 | | 4 0 0 | +--------------------------------------------------------------------------+ | 0 MIG 7g.40gb 0 0/1 39.50 No 98 5 0 | | 7 1 1 | +--------------------------------------------------------------------------+

, , A100 ( FP16) 2 3090? 4 A100 12 1080 Ti? "-" ?
:
MIG supports running CUDA applications by specifying the CUDA device on which the application should be run. With CUDA 11, only enumeration of a single MIG instance is supported. CUDA applications treat a CI and its parent GI as a single CUDA device. CUDA is limited to use a single CI and will pick the first one available if several of them are visible. To summarize, there are two constraints: - CUDA can only enumerate a single compute instance - CUDA will not enumerate non-MIG GPU if any compute instance is enumerated on any other GPU Note that these constraints may be relaxed in future NVIDIA driver releases for MIG.
, , , 2 , . , , , 1 "" ( ""). , Nvidia , "1 — 1 " " 7 ".
:
There is no GPU-to-GPU P2P (both PCIe and NVLINK) support in MIG mode, so MIG mode does not support multi-GPU or multi-node training. For large models or models trained with a large batch size, the models may fully utilize a single GPU or even be scaled to multi-GPUs or multi-nodes. In these cases, we still recommend using a full GPU or multi-GPUs, even multi-nodes, to minimize total training time.
MIG , (slices), Compute Instances — . It just works.
( DP DDP), A100 10, 20, 30 ( ), 1 .

1 A100 — 2-3 ,
| Avg epoch time, m | Workers | Batch | GPUs | CER @10 hours | CER @20 h | CER @30 h | Comment |
|---|---|---|---|---|---|---|---|
| 4.7 | 2, DDP | 50 * 2 | 2 * 3090 | 14.4 | 12.3 | 11.44 | Close to 100% utilization |
| 15.3 | 1, DP | 50 | 2 * Titan X | 21.6 | 17.4 | 15.7 | Close to 100% utilization |
| 11.4 | 1, DDP | 50 * 1 | 1 * A100 | NA | NA | NA | About 35-40% utilization |
| TBD | 2, DDP | 50 * 2 | 2 * 1080 Ti | TBD | TBD | TBD |
1080 Ti 1 .
3090:
- , . x2 . AMP — x3-x4;
- , , . - 30-40% ;
- . ;
- — 2 8- ;
A100:
- , ( 2-3 3090);
- , Nvidia — , ;
- ( 1080 Ti PNY Quadro) , value for money;
- MIG;
- 40 GB compute, ;
- PCIE ATX , "" ;
Update 1
gpu-burn CUDA_VISIBLE_DEVICES
CUDA_VISIBLE_DEVICES
PyTorch
| Test | GPU | Gflop/s | RAM |
|---|---|---|---|
| ./gpu_burn 120 | A100 // 7 | 2,400 * 7 | 4.95 * 7 |
| ./gpu_burn 120 | A100 // 3 | 4,500 * 3 | 9.75 * 3 |
| ./gpu_burn 120 | A100 // 2 | 6,700 * 2 | 19.62 * 2 |
| ./gpu_burn 120 | A100 (wo MIG) | 16,700 | 39.50 * 1 |
| ./gpu-burn -tc 120 | A100 // 7 | 15,100 * 7 | 4.95 * 7 |
| ./gpu-burn -tc 120 | A100 // 3 | 30,500 * 3 | 9.75 * 3 |
| ./gpu-burn -tc 120 | A100 // 2 | 42,500 * 2 | 19.62 * 2 |
| ./gpu-burn -tc 120 | A100 (wo MIG) | 81,500 | 39.50 * 1 |
Update 2
3 gpu-burn
MIG
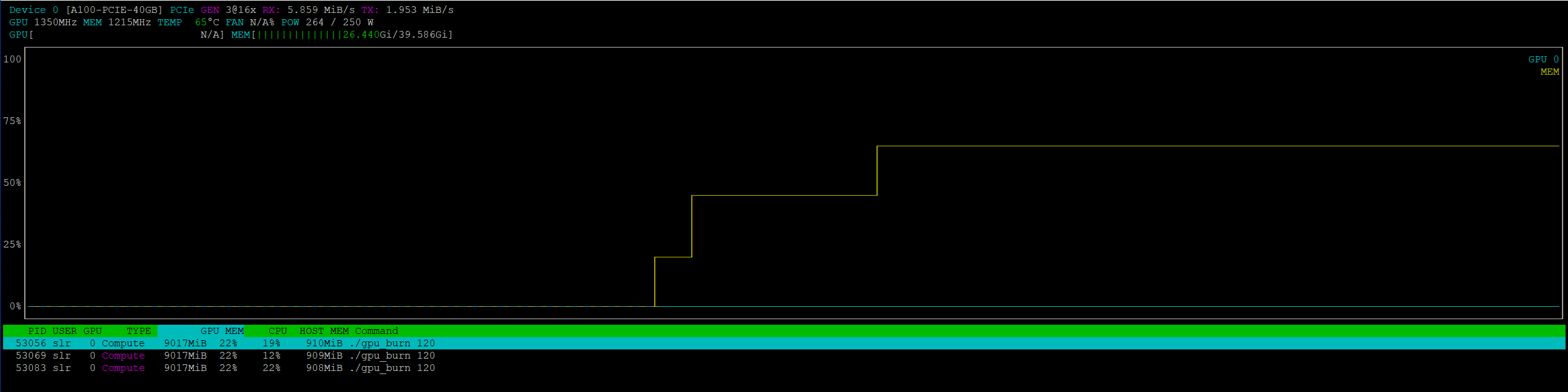
Update 3
DDP MIG PyTorch.
() .
def main(rank, args): os.environ["CUDA_VISIBLE_DEVICES"] = args.ddp.mig_devices[rank] import torch ...
Com a NCCL, tive a mesma exceção. Mudar nccl
para gloo
ele começou ... mas o trabalho era muuuito lento. Bem, convencionalmente, dez vezes mais lento e a utilização do cartão estava em um nível muito baixo. Acho que não adianta cavar mais.