Há muito tempo não escrevo artigos e acho que é hora de escrever sobre como o conhecimento em ciência de dados, obtido durante o treinamento da conhecida especialização de Yandex e MIPT "Aprendizado de Máquina e Análise de Dados", veio a calhar. É verdade que, para ser justo, deve-se notar que o conhecimento não foi totalmente obtido - a especialidade não foi concluída :) No entanto, já é possível resolver problemas reais de negócios simples. Ou é necessário? Esta pergunta será respondida em apenas alguns parágrafos.
Portanto, hoje neste artigo vou contar ao caro leitor sobre minha primeira experiência de participar de um concurso público. Gostaria de salientar desde já que o meu objetivo no concurso era não receber nenhum prémio. O único desejo era experimentar a minha sorte no mundo real :) Sim, além disso descobri que o tema do concurso praticamente não coincidia com o material dos cursos aprovados. Isso acrescentou algumas complicações, mas com isso a competição tornou-se ainda mais interessante e valiosa a experiência adquirida a partir daí.
Por tradição, designarei quem pode estar interessado no artigo. Em primeiro lugar, se você já concluiu os dois primeiros cursos da especialização acima e deseja tentar resolver problemas práticos, mas é tímido e tem medo de que não funcione e seja motivo de riso, etc. Depois de ler o artigo, espero que esses temores sejam dissipados. Em segundo lugar, talvez você esteja resolvendo um problema semelhante e não saiba por onde entrar. E aqui está um pré-fabricado despretensioso, como dizem os impressores de dados reais, uma linha de base :)
Aqui já deveríamos ter delineado o plano de pesquisa, mas faremos uma pequena digressão e tentaremos responder à pergunta do primeiro parágrafo - caso um iniciante em datasinting precise tentar sua sorte em tais competições. As opiniões divergem neste ponto. Pessoalmente, minha opinião é necessária! Deixe-me explicar o porquê. Os motivos são muitos, não vou enumerar tudo, vou indicar os mais importantes. Em primeiro lugar, essas competições ajudam a consolidar o conhecimento teórico na prática. Em segundo lugar, na minha prática, quase sempre, a experiência adquirida em condições próximas ao combate, motiva fortemente para novos feitos. Em terceiro lugar, e isso é o mais importante - durante a competição você tem a oportunidade de se comunicar com outros participantes em chats especiais, você nem precisa se comunicar, você pode apenas ler o que as pessoas escrevem e isso a) muitas vezes leva a pensamentos interessantes sobrequais outras mudanças fazer no estudo; eb) dá confiança para validar suas próprias ideias, especialmente se forem expressas no chat. Essas vantagens devem ser abordadas com certa prudência, para que não haja sentimento de onisciência ...
Agora um pouco sobre como decidi participar. Fiquei sabendo da competição poucos dias antes de ela começar. O primeiro pensamento é “bom, se eu soubesse do concurso há um mês, teria me preparado, mas teria estudado alguns materiais adicionais que poderiam ser úteis para a realização da pesquisa, caso contrário, sem preparação, poderia não cumprir o prazo ...”, o segundo o pensamento “na verdade, o que pode não funcionar se o objetivo não for um prêmio, mas a participação, especialmente porque os participantes em 95% dos casos falam russo, além de haver chats especiais para discussão, haverá algum tipo de webinars dos organizadores. No final, será possível ver cientistas de dados ao vivo de todos os tamanhos e faixas ... ”. Como você adivinhou, o segundo pensamento venceu, e não em vão - apenas alguns dias de trabalho árduo e obtive uma experiência valiosa, embora simples,mas bastante uma tarefa de negócios. Portanto, se você está no caminho de conquistar as alturas da ciência de dados e vê a próxima competição, sim em sua língua nativa, com suporte em chats e você tem tempo livre - não hesite por muito tempo - experimente e que a força venha com você! Em uma nota positiva, passamos para o plano de tarefa e pesquisa.
Nomes correspondentes
Não nos torturaremos e apresentaremos uma descrição do problema, mas forneceremos o texto original do site do organizador da competição.
Uma tarefa
Na procura de novos clientes, a SIBUR deve processar informações sobre milhões de novas empresas de várias fontes. Ao mesmo tempo, os nomes das empresas podem ter grafias diferentes, conter abreviaturas ou erros e estar afiliadas a empresas já conhecidas da SIBUR.
Para processar informações sobre clientes em potencial com mais eficiência, a SIBUR precisa saber se os dois nomes estão relacionados (ou seja, pertencem à mesma empresa ou empresas afiliadas).
Neste caso, a SIBUR poderá utilizar as informações já conhecidas sobre a própria empresa ou sobre empresas afiliadas, não duplicando chamadas para a empresa ou não perder tempo com empresas irrelevantes ou subsidiárias de concorrentes.
O exemplo de treinamento contém pares de nomes de diferentes fontes (incluindo personalizados) e marcação.
A marcação foi obtida parcialmente à mão, parcialmente - algoritmicamente. Além disso, a marcação pode conter erros. Você vai construir um modelo binário que prevê se dois nomes estão relacionados. A métrica usada nesta tarefa é F1.
Nesta tarefa, você pode e até deve usar fontes de dados abertas para enriquecer o conjunto de dados ou encontrar informações adicionais importantes para identificar empresas afiliadas.
Informações adicionais sobre a tarefa
Descubra-me para mais informações
, . , : , , Sibur Digital, , Sibur international GMBH , “ International GMBH” .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source , . — . .
, - – . , , - , , , .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
, , , .. crowdsource
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source
open source , . — . .
, - – . , , - , , , .
Dados
train.csv - conjunto de treinamento
test.csv - conjunto de teste
sample_submission.csv - exemplo de solução no formato correto
Nomenclatura baseline.ipynb - código
baseline_submission.csv - solução básica
Observe que os organizadores da competição cuidaram da geração mais jovem e postaram uma solução básica para o problema, o que dá uma qualidade f1 de cerca de 0,1. É a primeira vez que participo de concursos e é a primeira vez que vejo isto :)
Assim, depois de nos familiarizarmos com a tarefa em si e com os requisitos para a sua solução, passemos ao plano de solução.
Plano de resolução de problemas
Configurando instrumentos técnicos
Vamos carregar as bibliotecas
Vamos escrever funções auxiliares
Pré-processamento de dados
… -. !
50 & Drop it smart.
Vamos calcular a distância de Levenshtein
Calcule a distância de Levenshtein normalizada
Visualize os recursos
Compare as palavras no texto para cada par e gere um grande conjunto de recursos
Compare as palavras do texto com palavras dos nomes das 50 principais marcas de holding nas indústrias petroquímica e de construção. Vamos pegar o segundo grande grupo de recursos. Segundo CHIT
Preparando dados para alimentação no modelo
Configurando e treinando o modelo
Resultados da competição
Fontes de informação
Agora que nos familiarizamos com o plano de pesquisa, vamos prosseguir para sua implementação.
Configurando instrumentos técnicos
Carregando bibliotecas
Na verdade, tudo é simples aqui, primeiro vamos instalar as bibliotecas que faltam
Instale a biblioteca para determinar a lista de países e, em seguida, remova-os do texto
pip install pycountry
Instale uma biblioteca para determinar a distância Levenshtein entre palavras e texto entre si e com palavras de listas diferentes
pip install strsimpy
Instalaremos a biblioteca com a ajuda da qual transliteraremos o texto russo para o alfabeto latino
pip install cyrtranslit
Bibliotecas de pull up
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import pycountry
import re
from tqdm import tqdm
tqdm.pandas()
from strsimpy.levenshtein import Levenshtein
from strsimpy.normalized_levenshtein import NormalizedLevenshtein
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import seaborn as sns
sns.set()
sns.set_style("whitegrid")
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import StratifiedShuffleSplit
from scipy.sparse import csr_matrix
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report, f1_score
# import googletrans
# from googletrans import Translator
import cyrtranslitVamos escrever funções auxiliares
É considerada uma boa prática especificar a função em uma linha em vez de copiar um grande pedaço de código. Faremos isso, quase sempre.
Não vou argumentar que a qualidade do código nas funções é excelente. Em alguns lugares, definitivamente deve ser otimizado, mas para pesquisá-lo rapidamente, apenas a precisão dos cálculos será suficiente.
Portanto, a primeira função converte o texto em minúsculas
O código
# convert text to lowercase
def lower_str(data,column):
data[column] = data[column].str.lower()As quatro funções a seguir ajudam a visualizar o espaço dos recursos em estudo e sua capacidade de separar objetos por rótulos de destino - 0 ou 1.
O código
# statistic table for analyse float values (it needs to make histogramms and boxplots)
def data_statistics(data,analyse,title_print):
data0 = data[data['target']==0][analyse]
data1 = data[data['target']==1][analyse]
data_describe = pd.DataFrame()
data_describe['target_0'] = data0.describe()
data_describe['target_1'] = data1.describe()
data_describe = data_describe.T
if title_print == 'yes':
print ('\033[1m' + ' ',analyse,'\033[m')
elif title_print == 'no':
None
return data_describe
# histogramms for float values
def hist_fz(data,data_describe,analyse,size):
print ()
print ('\033[1m' + 'Information about',analyse,'\033[m')
print ()
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
min_data = data_describe['min'].min()
max_data = data_describe['max'].max()
data0_mean = data_describe.loc['target_0']['mean']
data0_median = data_describe.loc['target_0']['50%']
data0_min = data_describe.loc['target_0']['min']
data0_max = data_describe.loc['target_0']['max']
data0_count = data_describe.loc['target_0']['count']
data1_mean = data_describe.loc['target_1']['mean']
data1_median = data_describe.loc['target_1']['50%']
data1_min = data_describe.loc['target_1']['min']
data1_max = data_describe.loc['target_1']['max']
data1_count = data_describe.loc['target_1']['count']
print ('\033[4m' + 'Analyse'+ '\033[m','No duplicates')
figure(figsize=size)
sns.distplot(data_0,color='darkgreen',kde = False)
plt.scatter(data0_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data0_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data0_count,
' Min:', round(data0_min,2),
' Max:', round(data0_max,2),
' Mean:', round(data0_mean,2),
' Median:', round(data0_median,2))
print ()
print ('\033[4m' + 'Analyse'+ '\033[m','Duplicates')
figure(figsize=size)
sns.distplot(data_1,color='darkred',kde = False)
plt.scatter(data1_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data1_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data_1.count(),
' Min:', round(data1_min,2),
' Max:', round(data1_max,2),
' Mean:', round(data1_mean,2),
' Median:', round(data1_median,2))
# draw boxplot
def boxplot(data,analyse,size):
print ('\033[4m' + 'Analyse'+ '\033[m','All pairs')
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
figure(figsize=size)
sns.boxplot(x=analyse,y='target',data=data,orient='h',
showmeans=True,
meanprops={"marker":"o",
"markerfacecolor":"dimgray",
"markeredgecolor":"black",
"markersize":"14"},
palette=['palegreen', 'salmon'])
plt.ylabel('target', size=14)
plt.xlabel(analyse, size=14)
plt.show()
# draw graph for analyse two choosing features for predict traget label
def two_features(data,analyse1,analyse2,size):
fig = plt.subplots(figsize=size)
x0 = data[data['target']==0][analyse1]
y0 = data[data['target']==0][analyse2]
x1 = data[data['target']==1][analyse1]
y1 = data[data['target']==1][analyse2]
plt.scatter(x0,y0,c='green',marker='.')
plt.scatter(x1,y1,c='black',marker='+')
plt.xlabel(analyse1)
plt.ylabel(analyse2)
title = [analyse1,analyse2]
plt.title(title)
plt.show()A quinta função é projetada para gerar uma tabela de suposições e erros do algoritmo, mais conhecida como tabela de conjugação.
Em outras palavras, após a formação do vetor de previsões, precisamos comparar a previsão com os rótulos de destino. O resultado dessa comparação deve ser uma tabela de conjugação para cada par de empresas da amostra de treinamento. Na tabela de conjugação de cada par, será determinado o resultado da correspondência da previsão com a classe da amostra de treinamento. A classificação correspondente é aceita da seguinte forma: 'Verdadeiro positivo', 'Falso positivo', 'Verdadeiro negativo' ou 'Falso negativo'. Esses dados são muito importantes para analisar a operação do algoritmo e tomar decisões sobre como melhorar o modelo e o espaço de recursos.
O código
def contingency_table(X,features,probability_level,tridx,cvidx,model):
tr_predict_proba = model.predict_proba(X.iloc[tridx][features].values)
cv_predict_proba = model.predict_proba(X.iloc[cvidx][features].values)
tr_predict_target = (tr_predict_proba[:, 1] > probability_level).astype(np.int)
cv_predict_target = (cv_predict_proba[:, 1] > probability_level).astype(np.int)
X_tr = X.iloc[tridx]
X_cv = X.iloc[cvidx]
X_tr['predict_proba'] = tr_predict_proba[:,1]
X_cv['predict_proba'] = cv_predict_proba[:,1]
X_tr['predict_target'] = tr_predict_target
X_cv['predict_target'] = cv_predict_target
# make true positive column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false positive column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make true negative column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false negative column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
return X_tr,X_cvA sexta função é projetada para formar a matriz de conjugação. Não deve ser confundido com a Tabela de Acoplamento. Embora um decorra do outro. Você mesmo verá tudo mais adiante
O código
def matrix_confusion(X):
list_matrix = ['True_Positive','False_Positive','True_Negative','False_Negative']
tr_pos = X[list_matrix].sum().loc['True_Positive']
f_pos = X[list_matrix].sum().loc['False_Positive']
tr_neg = X[list_matrix].sum().loc['True_Negative']
f_neg = X[list_matrix].sum().loc['False_Negative']
matrix_confusion = pd.DataFrame()
matrix_confusion['0_algorythm'] = np.array([tr_neg,f_neg]).T
matrix_confusion['1_algorythm'] = np.array([f_pos,tr_pos]).T
matrix_confusion = matrix_confusion.rename(index={0: '0_target', 1: '1_target'})
return matrix_confusionA sétima função é projetada para visualizar o relatório sobre o funcionamento do algoritmo, que inclui a matriz de conjugação, os valores da precisão das métricas, recall, f1
O código
def report_score(tr_matrix_confusion,
cv_matrix_confusion,
data,tridx,cvidx,
X_tr,X_cv):
# print some imporatant information
print ('\033[1m'+'Matrix confusion on train data'+'\033[m')
display(tr_matrix_confusion)
print ()
print(classification_report(data.iloc[tridx]["target"].values, X_tr['predict_target']))
print ('******************************************************')
print ()
print ()
print ('\033[1m'+'Matrix confusion on test(cv) data'+'\033[m')
display(cv_matrix_confusion)
print ()
print(classification_report(data.iloc[cvidx]["target"].values, X_cv['predict_target']))
print ('******************************************************')Usando a oitava e a nona funções, iremos analisar a utilidade dos recursos para o modelo usado do Light GBM em termos do valor do coeficiente 'Ganho de informação' para cada recurso investigado
O código
def table_gain_coef(model,features,start,stop):
data_gain = pd.DataFrame()
data_gain['Features'] = features
data_gain['Gain'] = model.booster_.feature_importance(importance_type='gain')
return data_gain.sort_values('Gain', ascending=False)[start:stop]
def gain_hist(df,size,start,stop):
fig, ax = plt.subplots(figsize=(size))
x = (df.sort_values('Gain', ascending=False)['Features'][start:stop])
y = (df.sort_values('Gain', ascending=False)['Gain'][start:stop])
plt.bar(x,y)
plt.xlabel('Features')
plt.ylabel('Gain')
plt.xticks(rotation=90)
plt.show()A décima função é necessária para formar uma matriz do número de palavras correspondentes para cada par de empresas.
Esta função também pode ser usada para formar uma matriz de palavras NÃO correspondentes.
O código
def compair_metrics(data):
duplicate_count = []
duplicate_sum = []
for i in range(len(data)):
count=len(data[i])
duplicate_count.append(count)
if count <= 0:
duplicate_sum.append(0)
elif count > 0:
temp_sum = 0
for j in range(len(data[i])):
temp_sum +=len(data[i][j])
duplicate_sum.append(temp_sum)
return duplicate_count,duplicate_sum A décima primeira função translitera o texto russo para o alfabeto latino
O código
def transliterate(data):
text_transliterate = []
for i in range(data.shape[0]):
temp_list = list(data[i:i+1])
temp_str = ''.join(temp_list)
result = cyrtranslit.to_latin(temp_str,'ru')
text_transliterate.append(result)
.
, , , . , ,
<spoiler title="">
<source lang="python">def rename_agg_columns(id_client,data,rename):
columns = [id_client]
for lev_0 in data.columns.levels[0]:
if lev_0 != id_client:
for lev_1 in data.columns.levels[1][:-1]:
columns.append(rename % (lev_0, lev_1))
data.columns = columns
return datareturn text_transliterate A
décima terceira e décima quarta funções são necessárias para visualizar e gerar a tabela de distância de Levenshtein e outros indicadores importantes.
Que tipo de tabela é esta em geral, quais são as métricas nela e como ela é formada? Vejamos como a tabela é formada passo a passo:
- Etapa 1. Vamos definir quais dados precisaremos. ID do par, acabamento do texto - ambas as colunas, lista de nomes de propriedade (50 maiores empresas petroquímicas e de construção).
- Passo 2. Na coluna 1, em cada par de cada palavra, meça a distância Levenshtein de cada palavra da lista de nomes de propriedade, bem como o comprimento de cada palavra e a proporção entre distância e comprimento.
- 3. , 0.4, id , .
- 4. , 0.4, .
- 5. , ID , — . id ( id ). .
- Etapa 6. Cole a tabela resultante com a tabela de pesquisa.
Uma característica importante: o
cálculo leva muito tempo devido ao código escrito às pressas
O código
def dist_name_to_top_list_view(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
words1 = []
words2 = []
top_words = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist1
df['levenstein_dist_w2_top_w'] = dist2
df['length_w1_top_w'] = len(word1)
df['length_w2_top_w'] = len(word2)
df['length_top_w'] = len(top_word)
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
display(data)
print ('Words:', word1,word2,top_word)
print ('Levenstein distance:',dist1,dist2)
print ('Length of word:',len(word1),len(word2),len(top_word))
print ('Ratio (distance/length word):',ratio1,ratio2)
def dist_name_to_top_list_make(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
dist_w1 = []
dist_w2 = []
length_w1 = []
length_w2 = []
length_top_w = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
dist_w1.append(dist1)
dist_w2.append(dist2)
length_w1.append(float(len(word1)))
length_w2.append(float(len(word2)))
length_top_w.append(float(len(top_word)))
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist_w1
df['levenstein_dist_w2_top_w'] = dist_w2
df['length_w1_top_w'] = length_w1
df['length_w2_top_w'] = length_w2
df['length_top_w'] = length_top_w
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
return dataPré-processamento de dados
Pela minha pouca experiência, é o pré-processamento de dados no sentido amplo dessa expressão que leva mais tempo. Vamos em ordem.
Carregar dados
Tudo é muito simples aqui. Vamos carregar os dados e substituir o nome da coluna pelo rótulo de destino "is_duplicate" por "destino". Isso é para facilitar o uso das funções - algumas delas foram escritas como parte de pesquisas anteriores e usam o nome da coluna com o rótulo de destino como "destino".
O código
# DOWNLOAD DATA
text_train = pd.read_csv('train.csv')
text_test = pd.read_csv('test.csv')
# RENAME DATA
text_train = text_train.rename(columns={"is_duplicate": "target"})Vejamos os dados
Os dados foram carregados. Vamos ver quantos objetos estão no total e quão balanceados eles estão.
O código
# ANALYSE BALANCE OF DATA
target_1 = text_train[text_train['target']==1]['target'].count()
target_0 = text_train[text_train['target']==0]['target'].count()
print ('There are', text_train.shape[0], 'objects')
print ('There are', target_1, 'objects with target 1')
print ('There are', target_0, 'objects with target 0')
print ('Balance is', round(100*target_1/target_0,2),'%')Tabela №1 "Equilíbrio de marcas"

Há uma grande quantidade de objetos - quase 500 mil e eles não são equilibrados de todo. Ou seja, de quase 500 mil objetos, menos de 4 mil no total têm um rótulo alvo
igual a 1 (menos de 1%) .Vamos dar uma olhada na própria tabela. Vejamos os primeiros cinco objetos rotulados como 0 e os primeiros cinco objetos rotulados como 1.
O código
display(text_train[text_train['target']==0].head(5))
display(text_train[text_train['target']==1].head(5))Tabela No. 2 "Os 5 primeiros objetos da classe 0", tabela No. 3 "Os 5 primeiros objetos da classe 1"
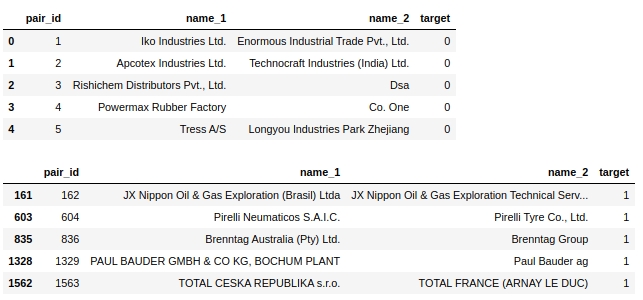
Alguns passos simples são sugeridos imediatamente: traga o texto para um registro, remova quaisquer palavras de interrupção, como 'ltd', exclua países e ao mesmo tempo os nomes geográficos objetos.
Na verdade, algo assim pode ser resolvido neste problema - você faz um pré-processamento, certifica-se de que funciona como deveria, executa o modelo, verifica a qualidade e analisa seletivamente os objetos nos quais o modelo está errado. Foi assim que fiz minha pesquisa. Mas, no próprio artigo, a solução final é dada e a qualidade do algoritmo após cada pré-processamento não é compreendida, no final do artigo faremos uma análise final. Caso contrário, o artigo seria de tamanho indescritível :)
Vamos fazer cópias
Para ser sincero, não sei por que faço isso, mas por alguma razão sempre faço isso. Eu vou fazer dessa vez também
O código
baseline_train = text_train.copy()
baseline_test = text_test.copy()Vamos converter todos os caracteres de texto em minúsculas
O código
# convert text to lowercase
columns = ['name_1','name_2']
for column in columns:
lower_str(baseline_train,column)
for column in columns:
lower_str(baseline_test,column)Remover nomes de países
É importante destacar que os organizadores da competição são ótimos companheiros! Junto com a tarefa, eles deram um laptop com uma linha de base muito simples, que foi fornecida, incluindo o código abaixo.
O código
# drop any names of countries
countries = [country.name.lower() for country in pycountry.countries]
for country in tqdm(countries):
baseline_train.replace(re.compile(country), "", inplace=True)
baseline_test.replace(re.compile(country), "", inplace=True)Remova sinais e caracteres especiais
O código
# drop punctuation marks
baseline_train.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_test.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_train.replace(re.compile(r"[^\w\s]"), "", inplace=True)
baseline_test.replace(re.compile(r"[^\w\s]"), "", inplace=True)Excluir números
Retirar os números do texto diretamente na testa, na primeira tentativa, prejudicou muito a qualidade do modelo. Vou dar o código aqui, mas na verdade ele não foi usado.
Observe também que até este ponto, executamos a transformação diretamente nas colunas que nos foram fornecidas. Vamos agora criar novas colunas para cada pré-processamento. Haverá mais colunas, mas se em algum estágio do pré-processamento ocorrer uma falha, tudo bem, você não precisa fazer tudo desde o início, pois teremos colunas de cada estágio do pré-processamento.
Código que estragou a qualidade. Você precisa ser mais delicado
# # first: make dictionary of frequency every word
# list_words = baseline_train['name_1'].to_string(index=False).split() +\
# baseline_train['name_2'].to_string(index=False).split()
# freq_words = {}
# for w in list_words:
# freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame of frequency words
# df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
# df_freq.columns = ['word','frequency']
# df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
# df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
# df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
# # third: make drop list of digits
# string = df_freq_agg['word'].to_string(index=False)
# digits = [int(digit) for digit in string.split() if digit.isdigit()]
# digits = set(digits)
# digits = list(digits)
# # drop the digits
# baseline_train['name_1_no_digits'] =\
# baseline_train['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_train['name_2_no_digits'] =\
# baseline_train['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_1_no_digits'] =\
# baseline_test['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_2_no_digits'] =\
# baseline_test['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))Vamos deletar ... a primeira lista de palavras irrelevantes. Manualmente!
Agora sugere-se definir e remover palavras de interrupção da lista de palavras em nomes de empresas.
Compilamos a lista com base na revisão manual do exemplo de treinamento. Logicamente, essa lista deve ser compilada automaticamente usando as seguintes abordagens:
- primeiro, use as 10 (20,50,100) palavras mais comuns.
- segundo, usar bibliotecas de palavras de parada padrão em diferentes idiomas. Por exemplo, designações de formas organizacionais e jurídicas de organizações em vários idiomas (LLC, PJSC, CJSC, ltd, gmbh, inc, etc.)
- em terceiro lugar, faz sentido compilar uma lista de nomes de lugares em diferentes idiomas
Voltaremos à primeira opção para compilar automaticamente uma lista das palavras mais freqüentemente encontradas, mas por enquanto estamos examinando o pré-processamento manual.
O código
# drop some stop-words
drop_list = ["ltd.", "co.", "inc.", "b.v.", "s.c.r.l.", "gmbh", "pvt.",
'retail','usa','asia','ceska republika','limited','tradig','llc','group',
'international','plc','retail','tire','mills','chemical','korea','brasil',
'holding','vietnam','tyre','venezuela','polska','americas','industrial','taiwan',
'europe','america','north','czech republic','retailers','retails',
'mexicana','corporation','corp','ltd','co','toronto','nederland','shanghai','gmb','pacific',
'industries','industrias',
'inc', 'ltda', '', '', '', '', '', '', '', '', 'ceska republika', 'ltda',
'sibur', 'enterprises', 'electronics', 'products', 'distribution', 'logistics', 'development',
'technologies', 'pvt', 'technologies', 'comercio', 'industria', 'trading', 'internacionais',
'bank', 'sports',
'express','east', 'west', 'south', 'north', 'factory', 'transportes', 'trade', 'banco',
'management', 'engineering', 'investments', 'enterprise', 'city', 'national', 'express', 'tech',
'auto', 'transporte', 'technology', 'and', 'central', 'american',
'logistica','global','exportacao', 'ceska republika', 'vancouver', 'deutschland',
'sro','rus','chemicals','private','distributors','tyres','industry','services','italia','beijing',
'','company','the','und']
baseline_train['name_1_non_stop_words'] =\
baseline_train['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_non_stop_words'] =\
baseline_train['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_non_stop_words'] =\
baseline_test['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_non_stop_words'] =\
baseline_test['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))Vamos verificar seletivamente se nossas palavras de parada foram realmente removidas do texto.
O código
baseline_train[baseline_train.name_1_non_stop_words.str.contains("factory")].head(3)Tabela 4 "Verificação seletiva do código para remover palavras de interrupção"

Parece que tudo funciona. Removidas todas as palavras de parada que estão separadas por um espaço. O que queríamos. Se movendo.
Vamos transliterar o texto russo para o alfabeto latino
Eu uso minha função de escrita própria e biblioteca cyrtranslit para isso. Parece que funciona. Verificado manualmente.
O código
# transliteration to latin
baseline_train['name_1_transliterated'] = transliterate(baseline_train['name_1_non_stop_words'])
baseline_train['name_2_transliterated'] = transliterate(baseline_train['name_2_non_stop_words'])
baseline_test['name_1_transliterated'] = transliterate(baseline_test['name_1_non_stop_words'])
baseline_test['name_2_transliterated'] = transliterate(baseline_test['name_2_non_stop_words'])Vejamos um par com id 353150. Nele, a segunda coluna ("name_2") contém a palavra "Michelin", após o pré-processamento a palavra já vem escrita assim "mishlen" (ver coluna "name_2_transliterated"). Não totalmente correto, mas claramente melhor.
O código
pair_id = 353150
baseline_train[baseline_train['pair_id']==353150]Tabela número 5 "Verificação seletiva do código para transliteração"

Vamos começar a compilação automática de uma lista das 50 palavras mais comuns e deixá-la inteligente. Primeiro CHIT
Título um pouco complicado. Vamos dar uma olhada no que faremos aqui.
Primeiro, combinaremos o texto da primeira e da segunda colunas em um array e contaremos para cada palavra única o número de vezes que ela ocorre.
Em segundo lugar, vamos escolher as 50 primeiras palavras. E parece que você pode excluí-los, mas não. Essas palavras podem conter os nomes de acervos ('total', 'knauf', 'shell', ...), mas esta é uma informação muito importante e não pode ser perdida, pois iremos utilizá-la posteriormente. Portanto, iremos para um truque de trapaça (proibido). Para começar, com base em um estudo cuidadoso e seletivo da amostra de treinamento, compilaremos uma lista de nomes de propriedades frequentemente encontradas. A lista não estará completa, caso contrário não seria nada justo :) Porém, já que não estamos atrás de um prêmio, por que não. Em seguida, compararemos a matriz das 50 palavras mais frequentes com a lista de nomes de propriedades e removeremos da lista as palavras que correspondem aos nomes das propriedades.
A segunda lista de palavras irrelevantes agora está completa. Você pode remover palavras do texto.
Mas, antes disso, gostaria de inserir uma pequena observação sobre a lista de trapaças de nomes de propriedade. O fato de termos compilado uma lista dos nomes das propriedades com base em observações facilitou muito a nossa vida. Mas, na verdade, poderíamos ter compilado essa lista de uma maneira diferente. Por exemplo, você pode pegar as classificações das maiores empresas dos setores petroquímico, de construção, automotivo e outros, combiná-las e obter os nomes das participações de lá. Mas, para o propósito de nossa pesquisa, nos restringiremos a uma abordagem simples. Esta abordagem é proibida na competição! Além disso, os organizadores do concurso, o trabalho dos candidatos aos lugares de prêmio são verificados quanto a técnicas proibidas. Seja cuidadoso!
O código
list_top_companies = ['arlanxeo', 'basf', 'bayer', 'bdp', 'bosch', 'brenntag', 'contitech',
'daewoo', 'dow', 'dupont', 'evonik', 'exxon', 'exxonmobil', 'freudenberg',
'goodyear', 'goter', 'henkel', 'hp', 'hyundai', 'isover', 'itochu', 'kia', 'knauf',
'kraton', 'kumho', 'lusocopla', 'michelin', 'paul bauder', 'pirelli', 'ravago',
'rehau', 'reliance', 'sabic', 'sanyo', 'shell', 'sherwinwilliams', 'sojitz',
'soprema', 'steico', 'strabag', 'sumitomo', 'synthomer', 'synthos',
'total', 'trelleborg', 'trinseo', 'yokohama']
# drop top 50 common words (NAME 1 & NAME 2) exept names of top companies
# first: make dictionary of frequency every word
list_words = baseline_train['name_1_transliterated'].to_string(index=False).split() +\
baseline_train['name_2_transliterated'].to_string(index=False).split()
freq_words = {}
for w in list_words:
freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame
df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
df_freq.columns = ['word','frequency']
df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
drop_list = list(set(df_freq_agg[0:50]['word'].to_string(index=False).split()) - set(list_top_companies))
# # check list of top 50 common words
# print (drop_list)
# drop the top 50 words
baseline_train['name_1_finish'] =\
baseline_train['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_finish'] =\
baseline_train['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_finish'] =\
baseline_test['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_finish'] =\
baseline_test['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
É aqui que terminamos o pré-processamento de dados. Vamos começar a gerar novos recursos e avaliá-los visualmente quanto à capacidade de separar objetos por 0 ou 1.
Geração e análise de recursos
Vamos calcular a distância de Levenshtein
Vamos usar a biblioteca strsimpy e em cada par (depois de todo o pré-processamento) calcularemos a distância Levenshtein do nome da empresa da primeira coluna ao nome da empresa na segunda coluna.
O código
# create feature with LEVENSTAIN DISTANCE
levenshtein = Levenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["levenstein"] = baseline_train.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)
baseline_test["levenstein"] = baseline_test.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)Vamos calcular a distância de Levenshtein normalizada
Tudo é igual ao anterior, apenas contaremos a distância normalizada.
Cabeçalho de spoiler
# create feature with NORMALIZATION LEVENSTAIN DISTANCE
normalized_levenshtein = NormalizedLevenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["norm_levenstein"] = baseline_train.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)
baseline_test["norm_levenstein"] = baseline_test.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)Contamos e agora visualizamos
Visualizando recursos
Vejamos a distribuição do traço 'levenstein'
O código
data = baseline_train
analyse = 'levenstein'
size = (12,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Gráficos # 1 "Histograma e caixa com bigode para avaliar a importância de um recurso"
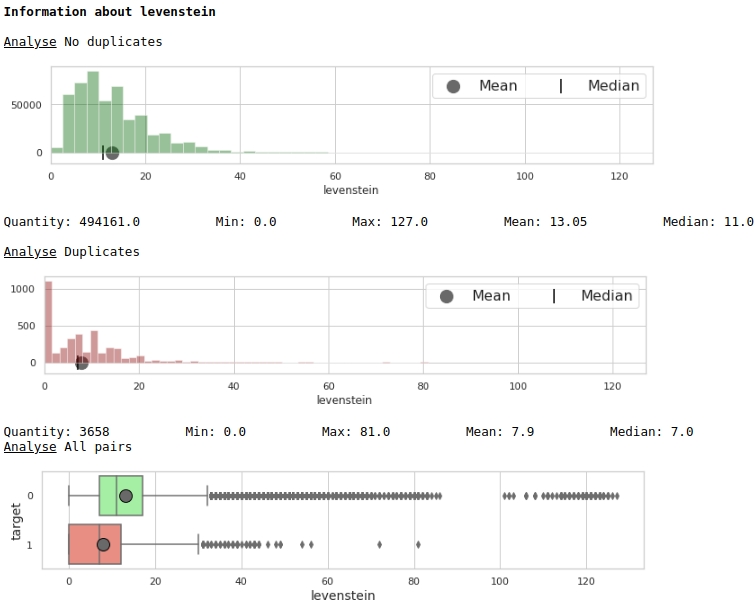
À primeira vista, uma métrica pode marcar dados. Obviamente não é muito bom, mas pode ser usado.
Vejamos a distribuição do traço 'norm_levenstein'
Cabeçalho de spoiler
data = baseline_train
analyse = 'norm_levenstein'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Gráficos №2 "Histograma e caixa com bigode para avaliar o significado do sinal"

Já está melhor. Agora, vamos dar uma olhada em como os dois recursos combinados dividirão o espaço nos objetos 0 e 1.
O código
data = baseline_train
analyse1 = 'levenstein'
analyse2 = 'norm_levenstein'
size = (14,6)
two_features(data,analyse1,analyse2,size)Gráfico # 3 "Diagrama de dispersão"
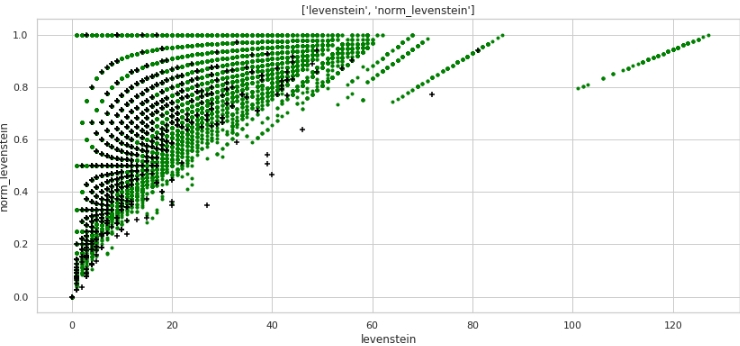
Marcação muito boa obtida. Portanto, não é em vão que pré-processamos tanto os dados :)
Todos entendem isso horizontalmente - os valores da métrica "levenstein" e verticalmente - os valores da métrica "norm_levenstein" e os pontos verdes e pretos são os objetos 0 e 1. Vamos em frente.
Vamos comparar palavras no texto para cada par e gerar uma grande quantidade de recursos
Abaixo, compararemos as palavras nos nomes das empresas. Vamos criar os seguintes recursos:
- uma lista de palavras que são duplicadas nas colunas 1 e 2 de cada par
- uma lista de palavras que NÃO são duplicadas
Com base nessas listas de palavras, vamos criar recursos que alimentaremos no modelo treinado:
- número de palavras duplicadas
- número de palavras NÃO duplicadas
- soma de caracteres, palavras duplicadas
- soma de caracteres, NÃO palavras duplicadas
- comprimento médio de palavras duplicadas
- comprimento médio de NÃO palavras duplicadas
- a proporção entre o número de duplicatas e o número de NÃO duplicatas
O código aqui provavelmente não é muito amigável, pois, novamente, foi escrito às pressas. Mas funciona, mas vai precisar de uma pesquisa rápida.
O código
# make some information about duplicates and differences for TRAIN
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_train.shape[0]):
list1 = list(baseline_train[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_train[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TRAIN
baseline_train['duplicate'] = duplicates
baseline_train['difference'] = difference
baseline_train['duplicate_count'] = duplicate_count
baseline_train['duplicate_sum'] = duplicate_sum
baseline_train['duplicate_mean'] = baseline_train['duplicate_sum'] / baseline_train['duplicate_count']
baseline_train['duplicate_mean'] = baseline_train['duplicate_mean'].fillna(0)
baseline_train['dif_count'] = dif_count
baseline_train['dif_sum'] = dif_sum
baseline_train['dif_mean'] = baseline_train['dif_sum'] / baseline_train['dif_count']
baseline_train['dif_mean'] = baseline_train['dif_mean'].fillna(0)
baseline_train['ratio_duplicate/dif_count'] = baseline_train['duplicate_count'] / baseline_train['dif_count']
# make some information about duplicates and differences for TEST
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_test.shape[0]):
list1 = list(baseline_test[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_test[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TEST
baseline_test['duplicate'] = duplicates
baseline_test['difference'] = difference
baseline_test['duplicate_count'] = duplicate_count
baseline_test['duplicate_sum'] = duplicate_sum
baseline_test['duplicate_mean'] = baseline_test['duplicate_sum'] / baseline_test['duplicate_count']
baseline_test['duplicate_mean'] = baseline_test['duplicate_mean'].fillna(0)
baseline_test['dif_count'] = dif_count
baseline_test['dif_sum'] = dif_sum
baseline_test['dif_mean'] = baseline_test['dif_sum'] / baseline_test['dif_count']
baseline_test['dif_mean'] = baseline_test['dif_mean'].fillna(0)
baseline_test['ratio_duplicate/dif_count'] = baseline_test['duplicate_count'] / baseline_test['dif_count']
Visualizamos alguns dos sinais.
O código
data = baseline_train
analyse = 'dif_sum'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Gráficos nº 4 "Histograma e caixa com bigode para avaliação do significado do sinal"
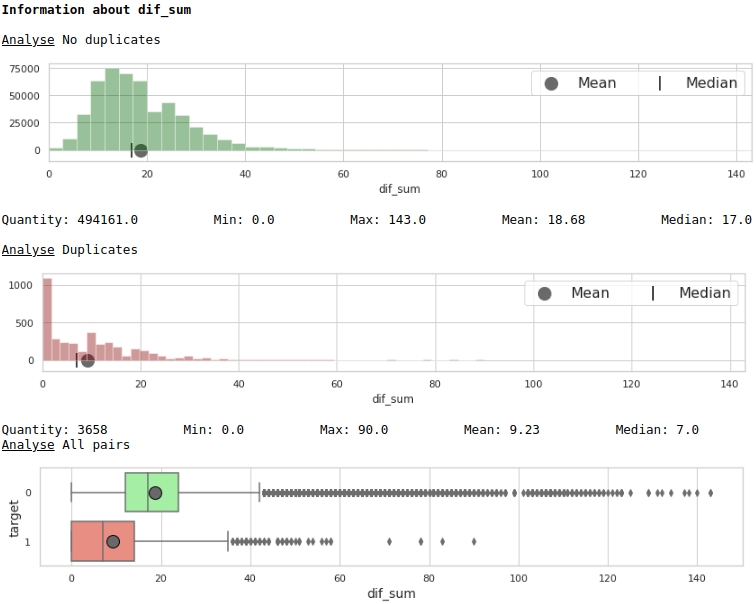
O código
data = baseline_train
analyse1 = 'duplicate_mean'
analyse2 = 'dif_mean'
size = (14,6)
two_features(data,analyse1,analyse2,size)Gráfico №5 "Diagrama de dispersão"
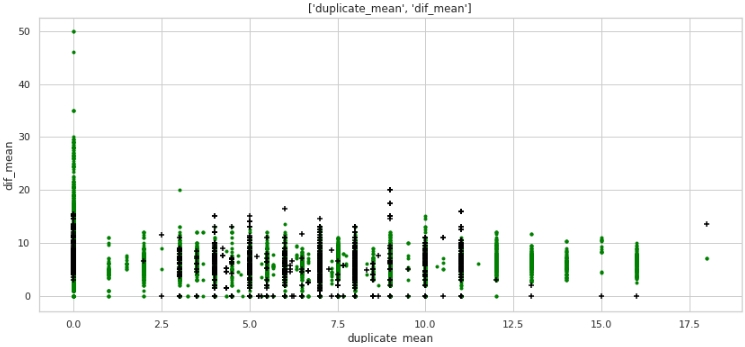
O que não, mas a marcação. Preste atenção ao fato de que muitas empresas com etiqueta de destino 1 têm zero duplicatas no texto, e também muitas empresas com duplicatas em seus nomes, em média mais de 12 palavras, pertencem a empresas com etiqueta de destino 0.
Vamos dar uma olhada nos dados tabulares, preparar uma consulta para No primeiro caso: há zero duplicatas nos nomes das empresas, mas as empresas são as mesmas.
O código
baseline_train[
baseline_train['duplicate_mean']==0][
baseline_train['target']==1].drop(
['duplicate', 'difference',
'name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated'],axis=1)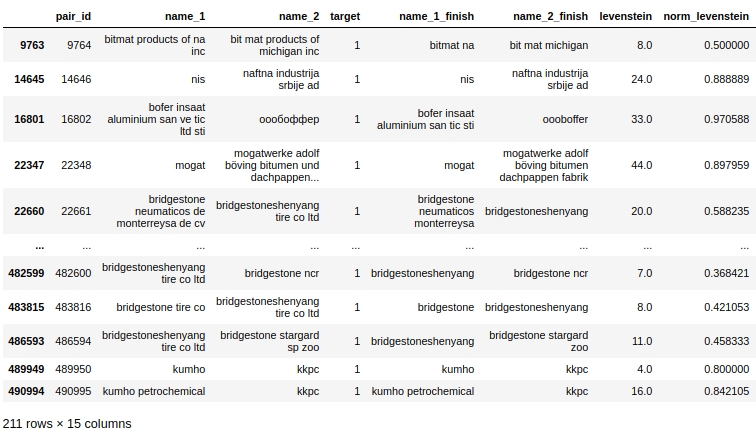
Obviamente, há um erro de sistema em nosso processamento. Não levamos em consideração que as palavras podem ser soletradas não apenas com erros, mas também simplesmente juntas ou, ao contrário, separadamente, onde isso não é necessário. Por exemplo, par # 9764. Na primeira coluna 'bitmat' na segunda 'bit mat' e agora este não é um duplo, mas a empresa é a mesma. Ou outro exemplo, par # 482600 'bridgestoneshenyang' e 'bridgestone'.
O que pode ser feito. A primeira coisa que me ocorreu foi comparar não diretamente na testa, mas usando a métrica de Levenshtein. Mas também aqui uma emboscada nos espera: a distância entre 'bridgestoneshenyang' e 'bridgestone' não será pequena. Talvez a lematização resgate, mas, novamente, não está imediatamente claro como os nomes das empresas podem ser lematizados. Ou você pode usar o coeficiente de Tamimoto, mas vamos deixar este momento para camaradas mais experientes e seguir em frente.
Vamos comparar as palavras do texto com palavras dos nomes das 50 maiores marcas de participação nos setores petroquímico, de construção e outros. Vamos pegar a segunda grande pilha de recursos. Segundo CHIT
Na verdade, existem duas violações das regras para participar da competição:
- -, , «duplicate_name_company»
- -, . , .
Ambas as técnicas são proibidas pelas regras da competição. Você pode ignorar a proibição. Para fazer isso, é necessário compilar uma lista de nomes de propriedade não manualmente com base em uma visão seletiva da amostra de treinamento, mas automaticamente de fontes externas. Mas então, em primeiro lugar, a lista de acervos acabará sendo grande e a comparação de palavras propostas no trabalho levará muito, bem, muito tempo e, em segundo lugar, essa lista ainda precisa ser compilada :) Portanto, para fins de simplicidade de pesquisa, verificaremos o quanto a qualidade do modelo melhorará com esses sinais. Seguindo em frente - a qualidade está crescendo incrível!
Com o primeiro método, tudo parece claro, mas a segunda abordagem requer explicações.
Portanto, vamos determinar a distância de Levenshtein de cada palavra em cada linha da primeira coluna com o nome da empresa para cada palavra da lista das principais empresas petroquímicas (e não apenas).
Se a proporção da distância Levenshtein para o comprimento da palavra for menor ou igual a 0,4, então determinamos a proporção da distância Levenshtein para a palavra selecionada na lista das principais empresas para cada palavra da segunda coluna - o nome da segunda empresa.
Se o segundo coeficiente (a razão entre a distância e o comprimento da palavra na lista das principais empresas) for menor ou igual a 0,4, fixamos os seguintes valores na tabela:
- Levenshtein se distancia de uma palavra da lista das empresas nº 1 a uma palavra na lista das principais empresas
- Levenshtein se distancia de uma palavra da lista das empresas nº 2 a uma palavra da lista das principais empresas
- comprimento de uma palavra da lista # 1
- comprimento de uma palavra da lista # 2
- comprimento de palavra da lista das principais empresas
- a proporção entre o comprimento de uma palavra da lista # 1 e a distância
- a relação entre o comprimento de uma palavra da lista nº 2 e a distância
Pode haver mais de uma correspondência em uma linha, vamos escolher o mínimo delas (função de agregação).
Gostaria de chamar mais uma vez a atenção para o fato de que o método proposto para geração de recursos consome muitos recursos e, no caso de obter uma lista de uma fonte externa, será necessária uma alteração no código para compilar métricas.
O código
# create information about duplicate name of petrochemical companies from top list
list_top_companies = list_top_companies
dp_train = []
for i in list(baseline_train['duplicate']):
dp_train.append(''.join(list(set(i) & set(list_top_companies))))
dp_test = []
for i in list(baseline_test['duplicate']):
dp_test.append(''.join(list(set(i) & set(list_top_companies))))
baseline_train['duplicate_name_company'] = dp_train
baseline_test['duplicate_name_company'] = dp_test
# replace name duplicate to number
baseline_train['duplicate_name_company'] =\
baseline_train['duplicate_name_company'].replace('',0,regex=True)
baseline_train.loc[baseline_train['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
baseline_test['duplicate_name_company'] =\
baseline_test['duplicate_name_company'].replace('',0,regex=True)
baseline_test.loc[baseline_test['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
# create some important feature about similar words in the data and names of top companies for TRAIN
# (levenstein distance, length of word, ratio distance to length)
baseline_train = dist_name_to_top_list_make(baseline_train,
'name_1_finish','name_2_finish',list_top_companies)
# create some important feature about similar words in the data and names of top companies for TEST
# (levenstein distance, length of word, ratio distance to length)
baseline_test = dist_name_to_top_list_make(baseline_test,
'name_1_finish','name_2_finish',list_top_companies)
Vejamos a utilidade dos recursos pelo prisma dos gráficos
O código
data = baseline_train
analyse = 'levenstein_dist_w1_top_w_min'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)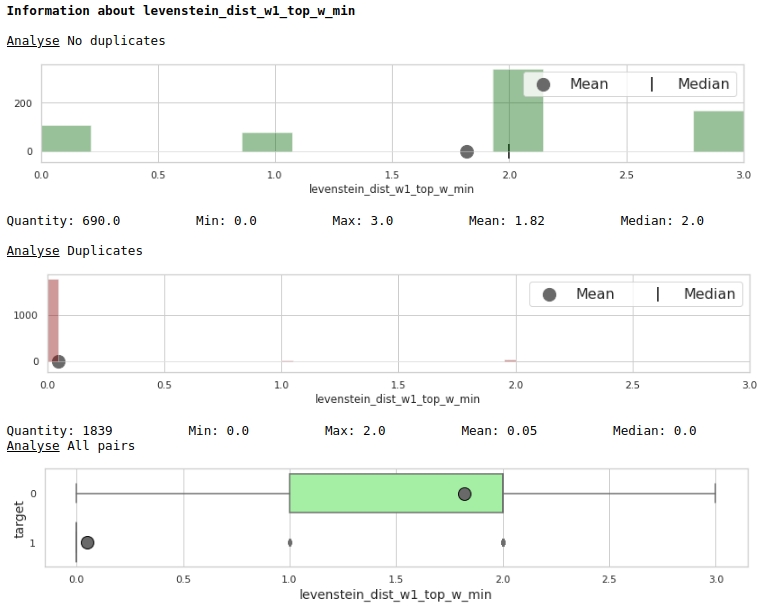
Muito bom.
Preparação de dados para apresentação ao modelo
Temos uma grande mesa e não precisamos de todos os dados para análise. Vejamos os nomes das colunas da tabela.
O código
baseline_train.columns
Vamos selecionar as colunas que iremos analisar.
Vamos consertar a semente para a reprodutibilidade do resultado.
O código
# fix some parameters
features = ['levenstein','norm_levenstein',
'duplicate_count','duplicate_sum','duplicate_mean',
'dif_count','dif_sum','dif_mean','ratio_duplicate/dif_count',
'duplicate_name_company',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min'
]
seed = 42Antes de finalmente treinar o modelo em todos os dados disponíveis e enviar a solução para verificação, faz sentido testar o modelo. Para fazer isso, dividimos a amostra de treinamento em treinamento condicional e teste condicional. Vamos medir a qualidade nele e se nos servir, enviaremos a solução para a concorrência.
O código
# provides train/test indices to split data in train/test sets
split = StratifiedShuffleSplit(n_splits=1, train_size=0.8, random_state=seed)
tridx, cvidx = list(split.split(baseline_train[features],
baseline_train["target"]))[0]
print ('Split baseline data train',baseline_train.shape[0])
print (' - new train data:',tridx.shape[0])
print (' - new test data:',cvidx.shape[0])Configurando e treinando o modelo
Usaremos a árvore de decisão da biblioteca Light GBM como modelo.
Não faz sentido encerrar demais os parâmetros. Nós olhamos o código.
O código
# learning Light GBM Classificier
seed = 50
params = {'n_estimators': 1,
'objective': 'binary',
'max_depth': 40,
'min_child_samples': 5,
'learning_rate': 1,
# 'reg_lambda': 0.75,
# 'subsample': 0.75,
# 'colsample_bytree': 0.4,
# 'min_split_gain': 0.02,
# 'min_child_weight': 40,
'random_state': seed}
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train.iloc[tridx][features].values,
baseline_train.iloc[tridx]["target"].values)O modelo foi ajustado e treinado. Agora vamos ver os resultados.
O código
# make predict proba and predict target
probability_level = 0.99
X = baseline_train
tridx = tridx
cvidx = cvidx
model = model
X_tr, X_cv = contingency_table(X,features,probability_level,tridx,cvidx,model)
train_matrix_confusion = matrix_confusion(X_tr)
cv_matrix_confusion = matrix_confusion(X_cv)
report_score(train_matrix_confusion,
cv_matrix_confusion,
baseline_train,
tridx,cvidx,
X_tr,X_cv)
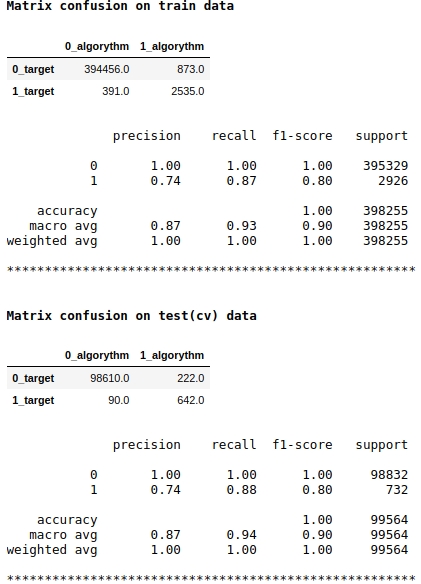
Observe que estamos usando a métrica de qualidade f1 como nossa pontuação do modelo. Isso significa que faz sentido ajustar o nível de probabilidade de classificar um objeto para a classe 1 ou 0. Escolhemos o nível de 0,99, ou seja, se a probabilidade for igual ou superior a 0,99, o objeto será classificado como classe 1, abaixo de 0,99 - para a classe 0. Este é um ponto importante - você pode melhorar significativamente a velocidade um truque tão simples, não complicado.
A qualidade parece não ser ruim. Em uma amostra de teste condicional, o algoritmo cometeu erros ao definir 222 objetos da classe 0 e em 90 objetos pertencentes à classe 0 ele cometeu um erro e os atribuiu à classe 1 (ver confusão de matrizes nos dados de teste (cv)).
Vamos ver quais sinais foram os mais importantes e quais não foram.
O código
start = 0
stop = 50
size = (12,6)
tg = table_gain_coef(model,features,start,stop)
gain_hist(tg,size,start,stop)
display(tg)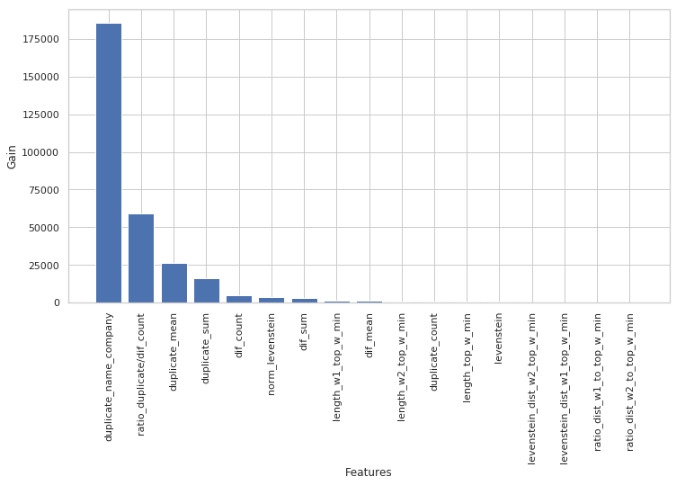
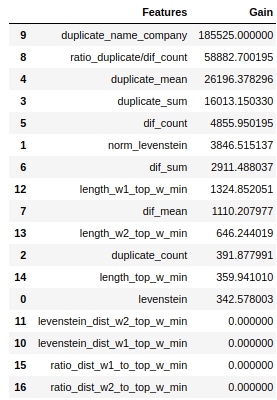
Observe que usamos o parâmetro 'ganho', não o parâmetro 'divisão' para avaliar a importância dos recursos. Isso é importante porque em uma versão muito simplificada, o primeiro parâmetro significa a contribuição do recurso para a diminuição da entropia, e o segundo indica quantas vezes o recurso foi usado para marcar o espaço.
À primeira vista, o recurso que temos feito por muito tempo, "levenstein_dist_w1_top_w_min", acabou por não ser informativo - sua contribuição é 0. Mas isso é apenas à primeira vista. Seu significado é quase completamente duplicado com o atributo "duplicate_name_company". Se você excluir "duplicate_name_company" e deixar "levenstein_dist_w1_top_w_min", o segundo recurso tomará o lugar do primeiro e a qualidade não mudará. Verificado!
Em geral, esse sinal é uma coisa útil, especialmente quando você tem centenas de recursos e um modelo com um monte de sinos e assobios e 5000 iterações. Você pode remover recursos em lotes e ver a qualidade aumentar com essa ação não astuta. Em nosso caso, a remoção de recursos não afetará a qualidade.
Vamos dar uma olhada na tabela de companheiros. Em primeiro lugar, vamos olhar para os objetos "Falso Positivo", ou seja, aqueles que nosso algoritmo determinou serem iguais e os atribuiu à classe 1, mas na verdade pertencem à classe 0.
O código
X_cv[X_cv['False_Positive']==1][0:50].drop(['name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated', 'duplicate', 'difference',
'levenstein',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min',
'True_Positive','True_Negative','False_Negative'],axis=1)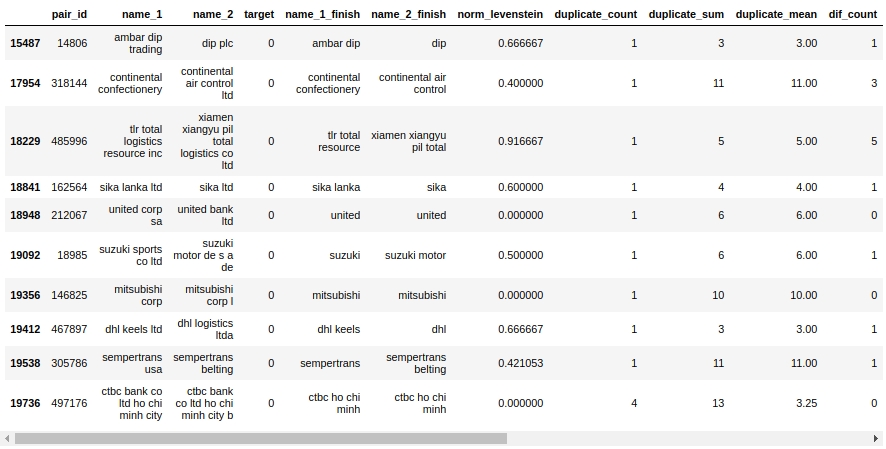
Sim. Aqui, uma pessoa não determinará imediatamente 0 ou 1. Por exemplo, par # 146825 "mitsubishi corp" e "mitsubishi corp l". Os olhos dizem que é a mesma coisa, mas a amostra diz que são empresas diferentes. Em quem acreditar?
Digamos apenas que foi possível espremer imediatamente - nós esprememos. Deixaremos o resto do trabalho para camaradas experientes :)
Vamos fazer o upload dos dados para o site do organizador e saber a avaliação da qualidade do trabalho.
Resultados da competição
O código
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train[features].values,
baseline_train["target"].values)
sample_sub = pd.read_csv('sample_submission.csv', index_col="pair_id")
sample_sub['is_duplicate'] = (model.predict_proba(
baseline_test[features].values)[:, 1] > probability_level).astype(np.int)
sample_sub.to_csv('baseline_submission.csv')
Então, nossa velocidade, levando em consideração a técnica proibida: 0,5999
Sem ela, a qualidade ficava entre 0,3 e 0,4. Precisamos reiniciar o modelo para precisão, mas estou um pouco preguiçoso :)
Vamos resumir melhor a experiência adquirida.
Primeiro, como você pode ver, temos um código bastante reproduzível e uma estrutura de arquivos bastante adequada. Devido à minha pouca experiência, certa vez preenchi muitos solavancos precisamente porque estava realizando o trabalho com pressa, apenas para conseguir uma velocidade mais ou menos agradável. Como resultado, o arquivo acabou sendo tal que depois de uma semana já era assustador abri-lo - nada é tão claro. Portanto, minha mensagem é - escreva o código imediatamente e torne o arquivo legível, para que em um ano você possa retornar aos dados, olhar primeiro a estrutura, entender quais etapas foram executadas e depois para que cada etapa possa ser facilmente desmontada. Claro, se você for um iniciante, na primeira tentativa o arquivo não ficará bonito, o código quebrará, haverá muletas, mas se você reescrever o código periodicamente durante o processo de pesquisa,então, em 5 a 7 vezes, você mesmo ficará surpreso com o quanto o código está mais limpo e talvez até encontre erros e melhore a velocidade. Não se esqueça das funções, isso torna o arquivo muito fácil de ler.
Em segundo lugar, após cada processamento dos dados, verifique se tudo correu como pretendido. Para fazer isso, você precisa ser capaz de filtrar tabelas em pandas. Há muita filtragem neste trabalho, use para a saúde :)
Terceiro, sempre, francamente sempre, em tarefas de classificação, forme uma tabela e uma matriz de conjugação. Na tabela, você pode encontrar facilmente em quais objetos o algoritmo está errado. Para começar, tente observar os erros chamados de erros do sistema, eles exigem menos trabalho para serem corrigidos, mas fornecem mais resultados. Então, assim que você resolver os erros do sistema, vá para os casos especiais. Pela matriz de erro, você verá onde o algoritmo comete mais erros: na classe 0 ou 1. A partir daqui você escavará os erros. Por exemplo, notei que minha árvore define bem as classes 1, mas comete muitos erros na classe 0, ou seja, a árvore muitas vezes "diz" que esse objeto é da classe 1, quando na verdade é 0. Presumi que poderia ser associado ao nível de probabilidade de classificar o objeto como 0 ou 1. Meu nível foi fixado em 0,9.O aumento do nível de probabilidade de atribuir um objeto à classe 1 para 0,99 tornou a seleção de objetos da classe 1 mais difícil e voila - nossa velocidade deu um aumento significativo.
Mais uma vez, observo que o objetivo de participar do concurso não era ganhar um prêmio, mas ganhar experiência. Considerando que antes do início da competição, eu não tinha ideia de como trabalhar com textos em aprendizado de máquina, e no final, em poucos dias consegui um modelo simples, mas ainda funcionando, então podemos dizer que o objetivo foi alcançado. Além disso, para qualquer samurai novato no mundo da ciência de dados, acho importante ganhar experiência, não um prêmio, ou melhor, experiência é o prêmio. Portanto, não tenha medo de participar de competições, vá em frente, todo mundo é castor!
No momento da publicação do artigo, o concurso ainda não havia terminado. Com base nos resultados da conclusão do concurso, nos comentários ao artigo, vou escrever sobre a velocidade máxima justa, sobre as abordagens e funcionalidades que melhoram a qualidade do modelo.
E você é um caro leitor, se você tem ideias de como aumentar a velocidade agora, escreva nos comentários. Faça uma boa ação :)
Fontes de informação, materiais auxiliares
- "Data Github e Jupyter Notebook"
- "Plataforma de competição SIBUR CHALLENGE 2020"
- "Site do organizador do concurso SIBUR CHALLENGE 2020"
- "Good article on Habré" Fundamentals of Natural Language Processing for Text ""
- "Outro bom artigo sobre Habré" Comparação de strings difusas: me entenda se puder ""
- "Publicação da revista APNI"
- "Um artigo sobre coeficiente de Tanimoto" Semelhança de strings "não usado aqui"