LightGBM estende o algoritmo Gradient Boosting adicionando um tipo de seleção automática de objetos, bem como focando em exemplos de boosting com grandes gradientes. Isso pode levar a uma aceleração dramática do aprendizado e a um melhor desempenho preditivo. Assim, o LightGBM se tornou o algoritmo de fato para competições de aprendizado de máquina ao trabalhar com dados tabulares para problemas de modelagem preditiva de regressão e classificação. Este tutorial mostrará como projetar conjuntos de máquinas Light Gradient Boosted para classificação e regressão. Depois de concluir este tutorial, você saberá:
- A Light Gradient Boosted Machine (LightGBM) é uma implementação de código aberto eficiente do conjunto de aumento de gradiente estocástico.
- Como desenvolver conjuntos LightGBM para classificação e regressão usando a API scikit-learn.
- LightGBM .

- LightBLM.
- Scikit-Learn API LightGBM.
— LightGBM .
— LightGBM . - LightGBM.
— .
— .
— .
— .
LightBLM
O aumento de gradiente pertence a uma classe de algoritmos de aprendizado de máquina combinados que podem ser usados para problemas de classificação ou modelagem de regressão preditiva.
Os conjuntos são construídos a partir de modelos de árvore de decisão. As árvores são adicionadas uma de cada vez ao conjunto e treinadas para corrigir erros de predição feitos por modelos anteriores. Esse é um tipo de modelo de aprendizado de máquina de conjunto denominado impulso.
Os modelos são treinados usando qualquer função de perda diferenciável arbitrária e um algoritmo de otimização de gradiente descendente. Isso dá ao método o nome de "aumento de gradiente" porque o gradiente de perda é minimizado à medida que o modelo é treinado, como uma rede neural. Para obter mais informações sobre o aumento de gradiente, consulte o tutorial:"Uma introdução suave ao algoritmo de aumento de gradiente de ML . "
LightGBM é uma implementação de código aberto de aumento de gradiente projetada para ser eficiente e, possivelmente, mais eficiente do que outras implementações.
Como tal, LightGBM é um projeto de código aberto, biblioteca de software e algoritmo de aprendizado de máquina. Ou seja, o projeto é muito semelhante à técnica Extreme Gradient Boosting ou XGBoost .
LightGBM foi descrito por Golin, K., et al. Para obter mais informações, consulte um artigo de 2017 intitulado "LightGBM: uma árvore de decisão de aumento de gradiente altamente eficiente . " A implementação apresenta duas idéias principais: GOSS e EFB.
O Gradient One-Way Sampling (GOSS) é uma modificação do Gradient Boosting que se concentra nos tutoriais que resultam em um gradiente maior, que por sua vez acelera o aprendizado e reduz a complexidade computacional do método.
Com o GOSS, excluímos uma parte significativa das instâncias de dados com pequenos gradientes e usamos apenas o restante das instâncias de dados para estimar o ganho de informações. Argumentamos que, como as instâncias de dados com grandes gradientes desempenham um papel mais importante no cálculo do ganho de informação, o GOSS pode obter uma estimativa bastante precisa do ganho de informação com um tamanho de dados muito menor.
Exclusive Feature Bundling, ou EFB, é uma abordagem de combinar recursos esparsos (principalmente nulos) mutuamente exclusivos, como variáveis de entrada categóricas codificadas com uma codificação unitária. Portanto, é um tipo de seleção automática de recursos.
... empacotamos recursos mutuamente exclusivos (isto é, eles raramente assumem valores diferentes de zero ao mesmo tempo) para reduzir o número de recursos.
Juntas, essas duas mudanças podem acelerar o tempo de treinamento do algoritmo em até 20 vezes. Assim, LightGBM pode ser considerado como Gradient Boosted Decision Trees (GBDTs) com a adição de GOSS e EFB.
Chamamos nossa nova implementação de GBDT de GOSS e EFB LightGBM. Nossos experimentos em vários conjuntos de dados disponíveis publicamente mostram que o LightGBM acelera o processo de aprendizagem de um GBDT convencional em mais de 20 vezes, alcançando quase a mesma precisão.
API Scikit-Learn para LightGBM
O LightGBM pode ser instalado como uma biblioteca independente e o modelo LightGBM pode ser desenvolvido usando a API scikit-learn.
O primeiro passo é instalar a biblioteca LightGBM. Na maioria das plataformas, isso pode ser feito usando o gerenciador de pacotes pip; por exemplo:
sudo pip install lightgbmVocê pode verificar a instalação e a versão assim:
# check lightgbm version
import lightgbm
print(lightgbm.__version__)O script exibirá a versão do LightGBM instalado. Sua versão deve ser igual ou superior. Caso contrário, atualize LightGBM. Se você precisar de instruções específicas para o seu ambiente de desenvolvimento, consulte o Guia de Instalação LightGBM .
A biblioteca LightGBM tem sua própria API, embora estejamos usando um método por meio de classes de wrapper scikit -learn: LGBMRegressor e LGBMClassifier . Isso permitirá que você aplique todo o conjunto de ferramentas da biblioteca de aprendizado de máquina scikit-learn para preparação de dados e avaliação de modelo.
Ambos os modelos funcionam da mesma maneira e usam os mesmos argumentos para influenciar como as árvores de decisão são criadas e adicionadas ao conjunto. O modelo usa aleatoriedade. Isso significa que toda vez que o algoritmo é executado nos mesmos dados, ele cria um modelo ligeiramente diferente.
Ao usar algoritmos de aprendizado de máquina com um algoritmo de aprendizado estocástico, é recomendável avaliá-los calculando a média de seu desempenho em várias execuções ou repetições de validação cruzada. Ao ajustar o modelo final, pode ser desejável aumentar o número de árvores até que a variância do modelo diminua com estimativas repetidas ou treinar vários modelos finais e calcular a média de suas previsões. Vamos dar uma olhada no projeto de um conjunto LightGBM para classificação e regressão.
Conjunto LightGBM para classificação
Nesta seção, veremos o uso de LightGBM para uma tarefa de classificação. Primeiro, podemos usar a função make_classification () para criar um problema de classificação binária sintética com 1000 exemplos e 20 recursos de entrada. Veja o exemplo completo abaixo.
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# summarize the datasetExecutar o exemplo cria um conjunto de dados e resume a forma dos componentes de entrada e saída.
(1000, 20) (1000,)Podemos então avaliar o algoritmo LightGBM neste conjunto de dados. Avaliaremos o modelo usando uma validação cruzada k-fold estratificada repetida com três repetições e k de 10. Iremos relatar a média e o desvio padrão da precisão do modelo em todas as repetições e dobras.
# evaluate lightgbm algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))A execução do exemplo mostra a precisão da média e do desvio padrão do modelo.
Nota : Seus resultados podem ser diferentes devido à natureza estocástica do algoritmo ou procedimento de estimativa, ou diferenças na precisão numérica. Experimente o exemplo várias vezes e compare o resultado médio.
Neste caso, podemos ver que o conjunto LightGBM com hiperparâmetros padrão atinge uma precisão de classificação de cerca de 92,5% neste conjunto de dados de teste.
Accuracy: 0.925 (0.031)Também podemos usar o modelo LightGBM como modelo final e fazer previsões para classificação. Primeiro, o conjunto LightGBM se ajusta a todos os dados disponíveis e, segundo, você pode chamar a função predict () para fazer previsões sobre os novos dados. O exemplo abaixo demonstra isso em nosso conjunto de dados de classificação binária.
# make predictions using lightgbm for classification
from sklearn.datasets import make_classification
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808]
yhat = model.predict([row])
print('Predicted Class: %d' % yhat[0])A execução do exemplo treina um modelo de conjunto LightGBM para todo o conjunto de dados e, em seguida, o usa para prever uma nova linha de dados, como faria se o modelo fosse usado em um aplicativo.
Predicted Class: 1Agora que estamos familiarizados com o uso de LightGBM para classificação, vamos dar uma olhada na API de regressão.
Conjunto LightGBM para regressão
Nesta seção, veremos o uso de LightGBM para um problema de regressão. Primeiro, podemos usar a função make_regression ()
para criar um problema de regressão sintética com 1000 exemplos e 20 recursos de entrada. Veja o exemplo completo abaixo.
# test regression dataset
from sklearn.datasets import make_regression
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# summarize the dataset
print(X.shape, y.shape)Executar o exemplo cria um conjunto de dados e resume os componentes de entrada e saída.
(1000, 20) (1000,)Em segundo lugar, podemos avaliar o algoritmo LightGBM neste conjunto de dados.
Como na última seção, avaliaremos o modelo por validação cruzada k-fold repetida com três repetições ek igual a 10. Iremos relatar o erro absoluto médio (MAE) do modelo em todas as repetições e grupos de validação cruzada. A biblioteca scikit-learn torna o MAE negativo para que seja maximizado em vez de minimizado. Isso significa que MAEs grandes negativos são melhores e o modelo ideal tem MAE de 0. Um exemplo completo é mostrado abaixo.
# evaluate lightgbm ensemble for regression
from numpy import mean
from numpy import std
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# evaluate the model
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))Executar o exemplo relata a média e o desvio padrão do modelo.
Nota : Seus resultados podem variar devido à natureza estocástica do algoritmo ou procedimento de estimativa, ou diferenças na precisão numérica. Considere executar o exemplo várias vezes e comparar a média. Nesse caso, vemos que o conjunto LightGBM com hiperparâmetros padrão atinge um MAE de cerca de 60.
MAE: -60.004 (2.887)Também podemos usar o modelo LightGBM como modelo final e fazer previsões para a regressão. Primeiro, o conjunto LightGBM é treinado em todos os dados disponíveis, então, Predict () pode ser chamado para prever novos dados. O exemplo abaixo demonstra isso em nosso conjunto de dados de regressão.
# gradient lightgbm for making predictions for regression
from sklearn.datasets import make_regression
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.20543991,-0.97049844,-0.81403429,-0.23842689,-0.60704084,-0.48541492,0.53113006,2.01834338,-0.90745243,-1.85859731,-1.02334791,-0.6877744,0.60984819,-0.70630121,-1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,-0.11154792]
yhat = model.predict([row])
print('Prediction: %d' % yhat[0]) A execução do exemplo treina o modelo de conjunto LightGBM em todo o conjunto de dados e, em seguida, usa-o para prever uma nova linha de dados, como faria se estivesse usando o modelo em um aplicativo.
Prediction: 52Agora que estamos familiarizados com o uso da API scikit-learn para avaliar e aplicar conjuntos LightGBM, vamos dar uma olhada na configuração do modelo.
Hiperparâmetros LightGBM
Nesta seção, examinaremos mais de perto alguns dos hiperparâmetros que são importantes para o conjunto LightGBM e seu impacto no desempenho do modelo. LightGBM tem muitos hiperparâmetros para observar, aqui vemos o número de árvores e sua profundidade, a taxa de aprendizado e o tipo de aumento. Para dicas gerais sobre como ajustar os hiperparâmetros LightGBM, consulte a documentação: Ajustando os parâmetros LightGBM .
Examinando o número de árvores
Um hiperparâmetro importante para o algoritmo de conjunto LightGBM é o número de árvores de decisão usadas no conjunto. Lembre-se de que as árvores de decisão são adicionadas ao modelo sequencialmente na tentativa de corrigir e melhorar as previsões feitas pelas árvores anteriores. A regra geralmente funciona: quanto mais árvores, melhor. O número de árvores pode ser especificado usando o argumento n_estimators, cujo padrão é 100. O exemplo a seguir examina o efeito do número de árvores, de 10 a 5000.
# explore lightgbm number of trees effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
trees = [10, 50, 100, 500, 1000, 5000]
for n in trees:
models[str(n)] = LGBMClassifier(n_estimators=n)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Executar o exemplo primeiro exibe a precisão média para cada número de árvores de decisão.
Nota : Seus resultados podem variar devido à natureza estocástica do algoritmo ou procedimento de estimativa, ou diferenças na precisão numérica. Considere executar o exemplo várias vezes e comparar a média.
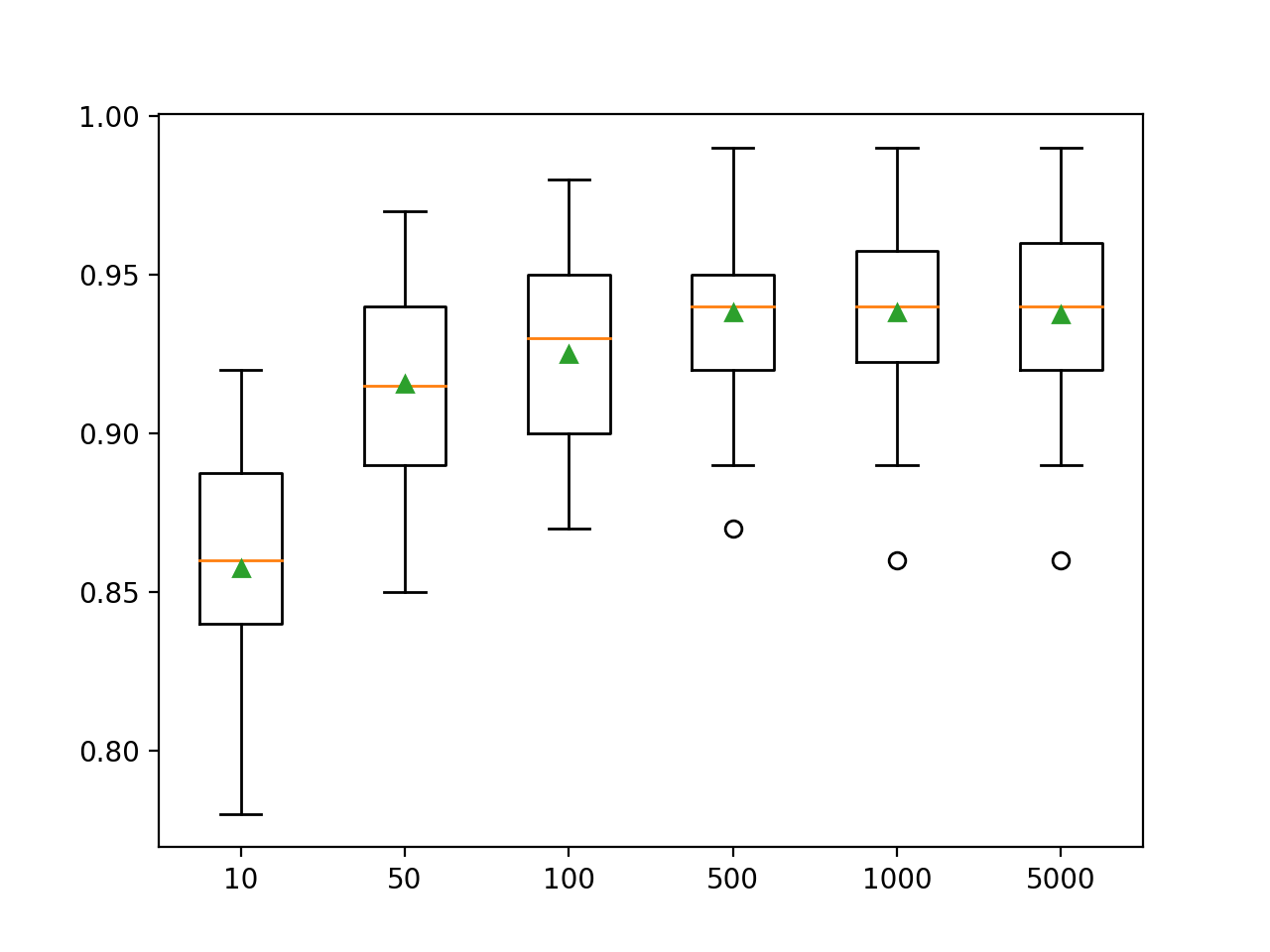
Aqui vemos que o desempenho melhora para este conjunto de dados para cerca de 500 árvores, após o que parece nivelar.
>10 0.857 (0.033)
>50 0.916 (0.032)
>100 0.925 (0.031)
>500 0.938 (0.026)
>1000 0.938 (0.028)
>5000 0.937 (0.028)Um gráfico de caixa e bigode é criado para distribuir as pontuações de precisão para cada número configurado de árvores. Há uma tendência geral de aumento do desempenho do modelo e do tamanho do conjunto.
Examinando a profundidade de uma árvore
Alterar a profundidade de cada árvore adicionada ao conjunto é outro hiperparâmetro importante para aumento de gradiente. A profundidade da árvore determina o quanto cada árvore é especializada no conjunto de dados de treinamento: quão geral ou treinada ela pode ser. Árvores que não devem ser muito rasas e genéricas (como AdaBoost ) e não muito profundas e especializadas (como agregação bootstrap ) são preferidas .
O aumento de gradiente geralmente funciona bem com árvores de profundidade moderada, equilibrando o treinamento e a generalidade. A profundidade da árvore é controlada pelo argumento max_depth, e o padrão é um valor indefinido, uma vez que o mecanismo padrão para gerenciar a complexidade das árvores é usar um número finito de nós.
Existem duas maneiras principais de controlar a complexidade de uma árvore: por meio da profundidade máxima da árvore e do número máximo de nós terminais (folhas) da árvore. Estamos examinando o número de folhas aqui, portanto, precisamos aumentar o número para suportar árvores mais profundas, especificando o argumento num_leaves . Abaixo, examinamos as profundidades da árvore de 1 a 10 e seu impacto no desempenho do modelo.
# explore lightgbm tree depth effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for i in range(1,11):
models[str(i)] = LGBMClassifier(max_depth=i, num_leaves=2**i)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Executar o exemplo primeiro exibe a precisão média para cada profundidade de árvore ajustada.
Nota : Seus resultados podem ser diferentes devido à natureza estocástica do algoritmo ou procedimento de estimativa, ou diferenças na precisão numérica. Considere executar o exemplo várias vezes e comparar o resultado médio.
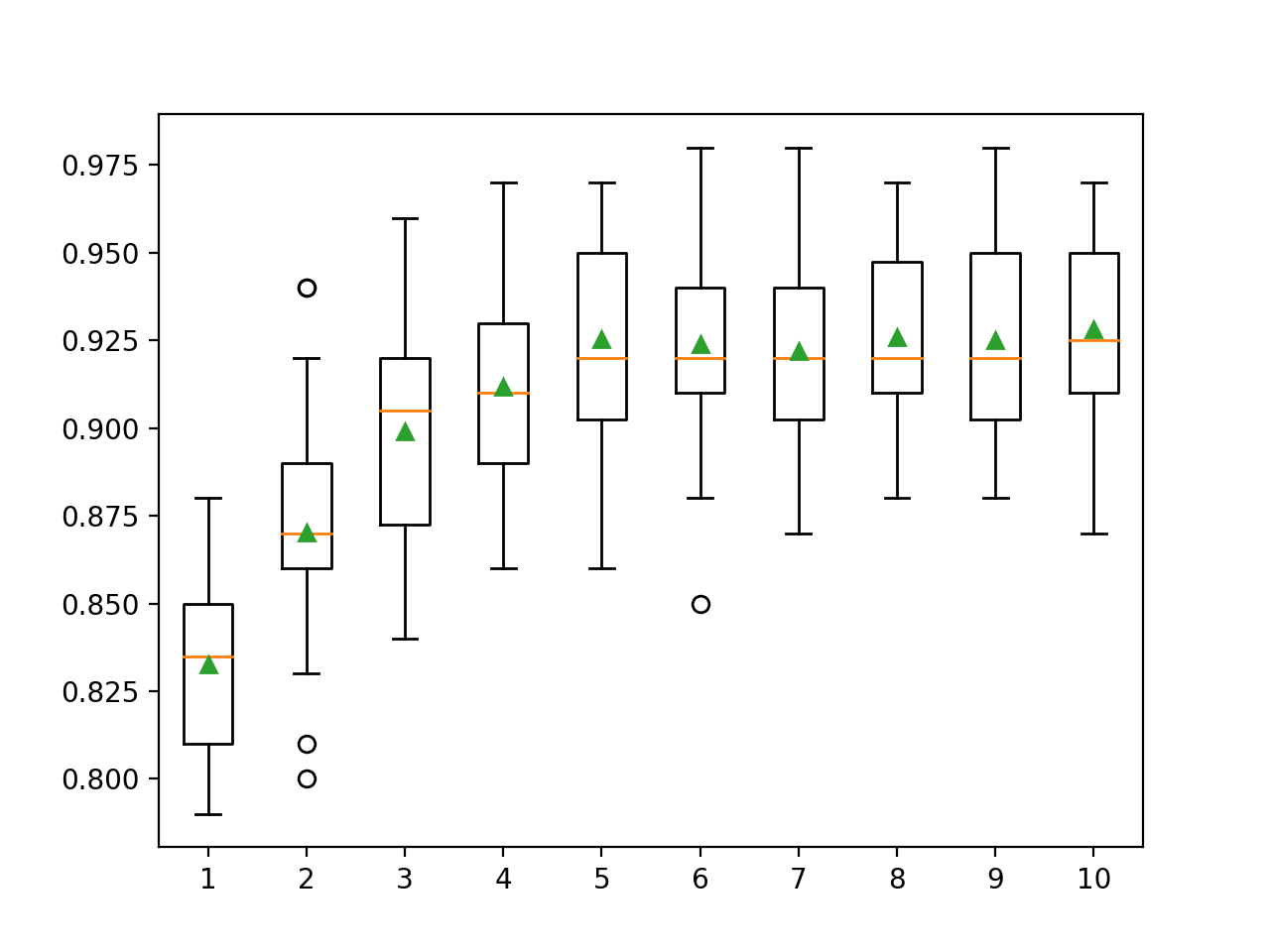
Aqui podemos ver que o desempenho melhora com o aumento da profundidade da árvore, possivelmente até 10 níveis. Seria interessante explorar árvores ainda mais profundas.
>1 0.833 (0.028)
>2 0.870 (0.033)
>3 0.899 (0.032)
>4 0.912 (0.026)
>5 0.925 (0.031)
>6 0.924 (0.029)
>7 0.922 (0.027)
>8 0.926 (0.027)
>9 0.925 (0.028)
>10 0.928 (0.029)Um retângulo e um gráfico de bigode são gerados para distribuir as pontuações de precisão para cada profundidade de árvore configurada. Há uma tendência geral de que o desempenho do modelo aumente com uma profundidade de árvore de até cinco níveis, após o que o desempenho permanece razoavelmente estável.
Pesquisa de taxa de aprendizagem
A taxa de aprendizado controla o grau em que cada modelo contribui para a previsão de conjunto. Velocidades mais baixas podem exigir mais árvores de decisão no conjunto. A taxa de aprendizado pode ser controlada com o argumento learning_rate, por padrão é 0.1. O seguinte examina a taxa de aprendizado e compara o efeito dos valores de 0,0001 a 1,0.
# explore lightgbm learning rate effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
rates = [0.0001, 0.001, 0.01, 0.1, 1.0]
for r in rates:
key = '%.4f' % r
models[key] = LGBMClassifier(learning_rate=r)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Executar o exemplo primeiro exibe a precisão média para cada taxa de aprendizagem configurada.
Nota : Seus resultados podem variar devido à natureza estocástica do algoritmo ou procedimento de estimativa, ou diferenças na precisão numérica. Considere executar o exemplo várias vezes e comparar o resultado médio.
Aqui, vemos que uma taxa de aprendizado mais alta leva a um melhor desempenho neste conjunto de dados. Esperamos que adicionar mais árvores ao conjunto para uma taxa de aprendizado mais baixa melhore ainda mais o desempenho.
>0.0001 0.800 (0.038)
>0.0010 0.811 (0.035)
>0.0100 0.859 (0.035)
>0.1000 0.925 (0.031)
>1.0000 0.928 (0.025)Uma caixa de bigode é criada para distribuir as pontuações de precisão para cada taxa de aprendizagem configurada. Existe uma tendência geral para o desempenho do modelo aumentar com o aumento da taxa de aprendizagem até 1,0.

Impulsionando a pesquisa de tipo
A peculiaridade do LightGBM é que ele suporta uma série de algoritmos de boosting chamados de tipos de boost. O tipo de impulso é especificado usando o argumento boosting_type e leva uma string para determinar o tipo. Valores possíveis:
- 'gbdt' : Gradient Boosted Decision Tree (GDBT);
- 'dardo' : o conceito de abandono é inserido no MART, obtemos DART;
- 'goss' : Busca unilateral de gradiente (GOSS).
O padrão é GDBT, o algoritmo clássico de aumento de gradiente.
O DART é descrito em um artigo de 2015 intitulado " DART: Desistências encontram Múltiplas Árvores de Regressão Aditiva " e, como o nome sugere, adiciona a noção de abandono do aprendizado profundo ao algoritmo Árvores de Regressão Múltipla Aditiva (MART), um precursor das árvores de decisão de aumento de gradiente.
Este algoritmo é conhecido por muitos nomes, incluindo Gradient TreeBoost, Boosted Trees e Multiple Additive Regression Trees and Trees (MART). Usamos o último nome para nos referir ao algoritmo.
GOSS apresenta trabalho no LightGBM e na biblioteca lightbgm. Essa abordagem visa usar apenas as instâncias que resultam em um grande gradiente de erro para atualizar o modelo e remover as instâncias restantes.
… Excluímos uma parte significativa das instâncias de dados com pequenos gradientes e usamos apenas o restante para estimar o ganho de informação.
Abaixo, o LightGBM é treinado em um conjunto de dados de classificação sintética com três métodos principais de aumento.
# explore lightgbm boosting type effect on performance
from numpy import arange
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
types = ['gbdt', 'dart', 'goss']
for t in types:
models[t] = LGBMClassifier(boosting_type=t)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Executar o exemplo primeiro exibe a precisão média para cada tipo de aumento configurado.
Nota : Seus resultados podem variar devido à natureza estocástica do algoritmo ou procedimento de estimativa, ou diferenças na precisão numérica. Considere executar o exemplo várias vezes e comparar o resultado médio.
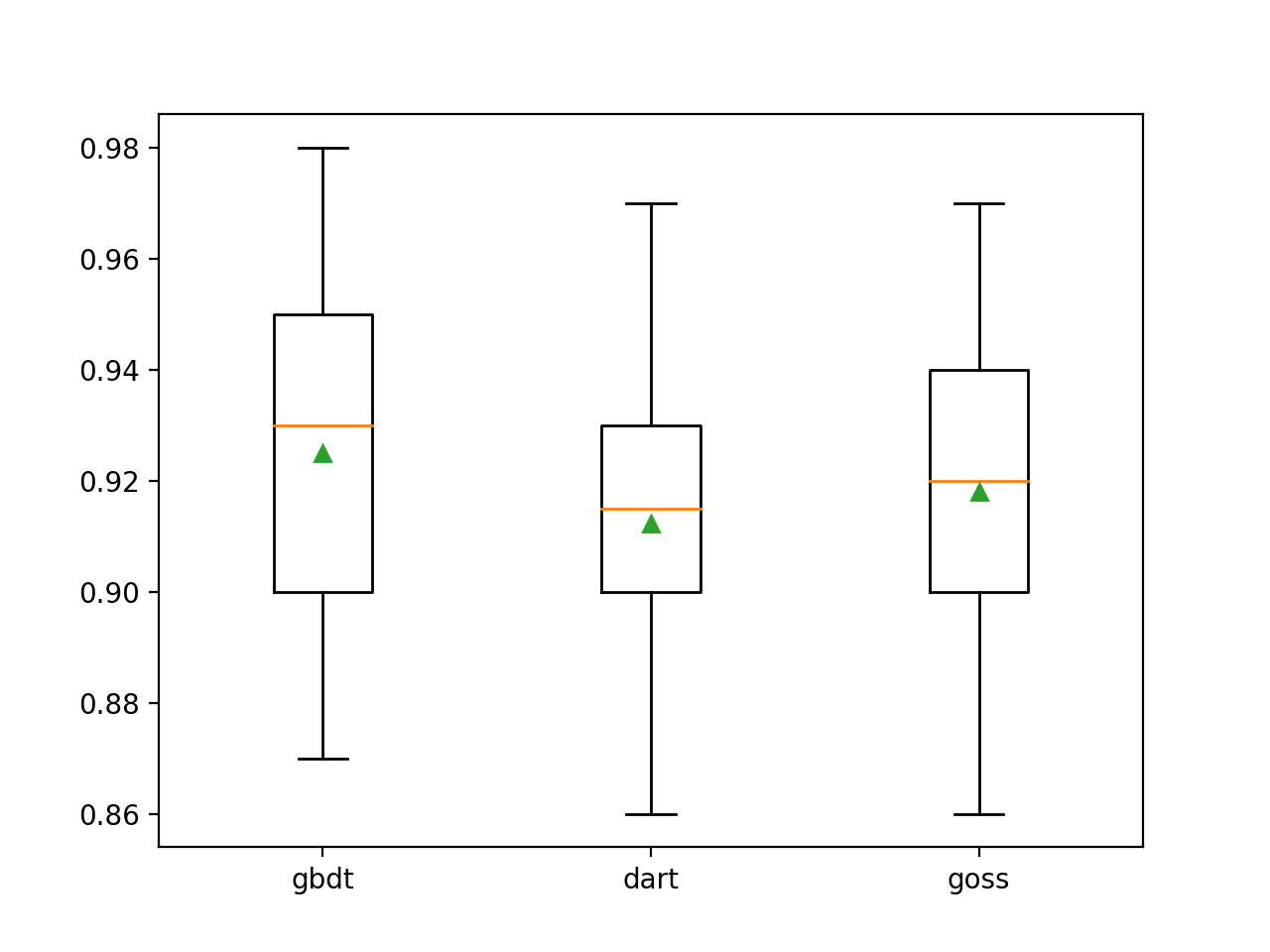
Podemos ver que o método de boost padrão tem um desempenho melhor do que os outros dois métodos avaliados.
>gbdt 0.925 (0.031)
>dart 0.912 (0.028)
>goss 0.918 (0.027)Um diagrama de caixa e bigode é criado para distribuir as pontuações de precisão para cada método de amplificação configurado, permitindo a comparação direta dos métodos.

- Curso de Aprendizado de Máquina
- Treinamento para a profissão de ciência de dados
- Treinamento de analista de dados
- Curso de Python para Desenvolvimento Web
Mais cursos