- Vamos começar. Vou falar sobre log conveniente e a infraestrutura em torno de log que você pode implantar para torná-lo conveniente para você conviver com seu aplicativo e seu ciclo de vida.

O que nós fazemos? Vamos construir um pequeno aplicativo, nossa startup. Em seguida, implementaremos o log básico nele, esta é uma pequena parte do relatório, o que o Python fornece fora da caixa. E depois a parte mais importante - analisaremos os problemas típicos que encontramos durante a depuração, implementação e ferramentas para resolvê-los.
Pequeno aviso: usarei palavras como caneta e local. Deixe-me explicar. "Handle" é possivelmente uma gíria do yandex, ele denota sua API, http ou gRPC API ou qualquer outra combinação de letras antes do APU. "Local" é quando desenvolvo em um laptop. Parece que contei todas as palavras que não controlo.
Aplicativo de livraria
Vamos começar. Nossa startup é a Livraria. A principal característica deste aplicativo será a venda de livros, é tudo o que queremos fazer. Em seguida, um pouco de recheio. O aplicativo será escrito em Flask. Todos os trechos de código, todas as ferramentas são genéricos e abstraídos do Python, para que possam ser integrados à maioria de seus aplicativos. Mas em nossa conversa será Flask.
Personagens: eu, o desenvolvedor, os gerentes e meu querido colega Erast. Todas as correspondências são acidentais.
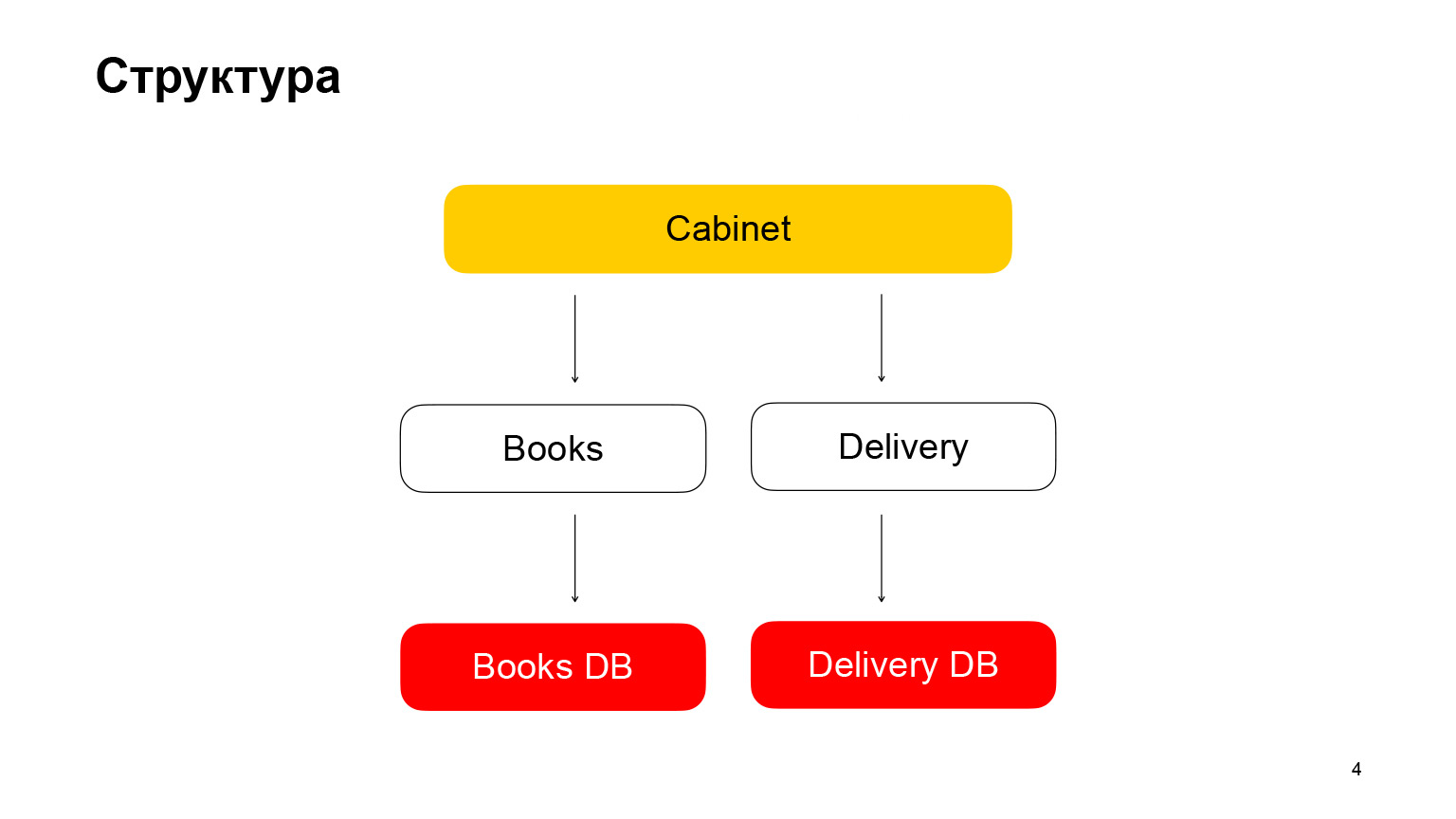
Vamos conversar um pouco sobre a estrutura. É um aplicativo de arquitetura de microsserviço. O primeiro serviço é o Books, um armazenamento de livros com metadados de livros. Ele usa o banco de dados PostgreSQL. O segundo microsserviço é um microsserviço de entrega que armazena metadados sobre pedidos de usuários. Gabinete é o backend do gabinete. Não temos frontend, não é necessário em nosso relatório. O Gabinete agrega pedidos, dados do serviço de livros e do serviço de entrega.

Vou mostrar rapidamente o código para os identificadores desses serviços, API Books. Esse identificador pega dados do banco de dados, serializa-os, transforma-os em JSON e os devolve.

Vamos mais longe. Serviço de entrega. A alça é exatamente a mesma. Pegamos os dados do banco de dados, serializamos e enviamos.

E o último botão é o botão do gabinete. Tem um código ligeiramente diferente. O manipulador de gabinete solicita dados do serviço de entrega e do serviço de livros, agrega as respostas e dá ao usuário seus pedidos. Tudo. Rapidamente descobrimos a estrutura do aplicativo.
Registro básico no aplicativo
Agora vamos falar sobre o log básico, aquele que vimos em. Vamos começar com a terminologia.

O que o Python nos dá? Quatro entidades básicas principais:
- Logger, o ponto de entrada para registrar seu código. Você vai usar algum tipo de Logger, escrever logging.INFO e pronto. Seu código não saberá mais nada sobre para onde a mensagem foi e o que aconteceu com ela em seguida. A entidade Handler já é responsável por isso.
- O manipulador processa sua mensagem, decide para onde enviá-la: para a saída padrão, para um arquivo ou para o correio de outra pessoa.
- O filtro é uma das duas entidades auxiliares. Remove mensagens do log. Outro caso de uso comum é o enchimento de dados. Por exemplo, em sua postagem, você precisa adicionar um atributo. O filtro também pode ajudar nisso.
- O formatador traz sua mensagem para o formato desejado.

Aqui é onde terminamos com a terminologia, não vamos voltar a logar diretamente no Python, com classes base. Mas aqui está um exemplo da configuração de nosso aplicativo, que é implementado em todos os três serviços. Existem dois blocos principais e importantes para nós: formatadores e manipuladores. Para formatadores, há um exemplo, que você pode ver aqui, um modelo de como a mensagem será exibida.
Nos manipuladores, você pode ver que o logging.StreamHandler é usado. Ou seja, despejamos todos os nossos logs na saída padrão. É isso, acabamos com isso.
Problema 1. Os registros estão espalhados
Passando para os problemas. Para começar, o primeiro problema: os logs estão espalhados.
Um pouco de contexto. Escrevemos nosso aplicativo, o doce já está pronto. Podemos ganhar dinheiro com isso. Estamos lançando em produção. Claro, existe mais de um servidor. De acordo com nossas estimativas conservadoras, nosso aplicativo mais complexo precisa de cerca de três ou quatro carros, e assim por diante, para cada serviço.
Agora a pergunta. O gerente vem correndo até nós e pergunta: "Quebrou, ajudem!" Você está correndo. Tudo é registrado para você, é ótimo. Você vai até a primeira máquina de escrever, olha - não há nada lá para o seu pedido. Vá para o segundo carro - nada. E assim por diante. Isso é ruim, precisa ser resolvido de alguma forma.

Vamos formalizar o resultado que queremos ver. Quero que os logs estejam em um só lugar. Este é um requisito simples. Um pouco mais legal é que eu quero pesquisar os logs. Ou seja, sim, fica em um lugar e eu sei rasgar, mas seria legal se houvesse algumas ferramentas, recursos legais além de um simples grap.
E eu não quero escrever. Este é o Erast, que adora escrever códigos. Não estou falando disso, fiz um produto na hora. Ou seja, você quer menos código adicional, consiga com um ou dois arquivos, linhas e é isso.

A solução que pode ser usada é Elasticsearch. Vamos tentar aumentá-lo. Quais são os benefícios do Elasticsearch? Esta é uma interface de pesquisa de log. Há uma interface pronta para uso, este não é um console para você, mas o único local de armazenamento. Ou seja, cumprimos o requisito principal. Não precisaremos ir aos servidores.
Em nosso caso, será uma integração bastante simples e, com o lançamento recente, o Elasticsearch tem um novo agente que é responsável pela maioria das integrações. Eles próprios se integraram lá. Muito legal. Eu escrevi uma palestra antes e usei o filebeat, tão fácil quanto. É simples para logs.
Um pouco sobre o Elasticsearch. Não quero anunciar, mas existem muitos recursos adicionais. Por exemplo, o legal é a pesquisa de registro de texto completo pronta para uso. Parece muito legal. Por enquanto, essas vantagens são suficientes para nós. Nós o prendemos.
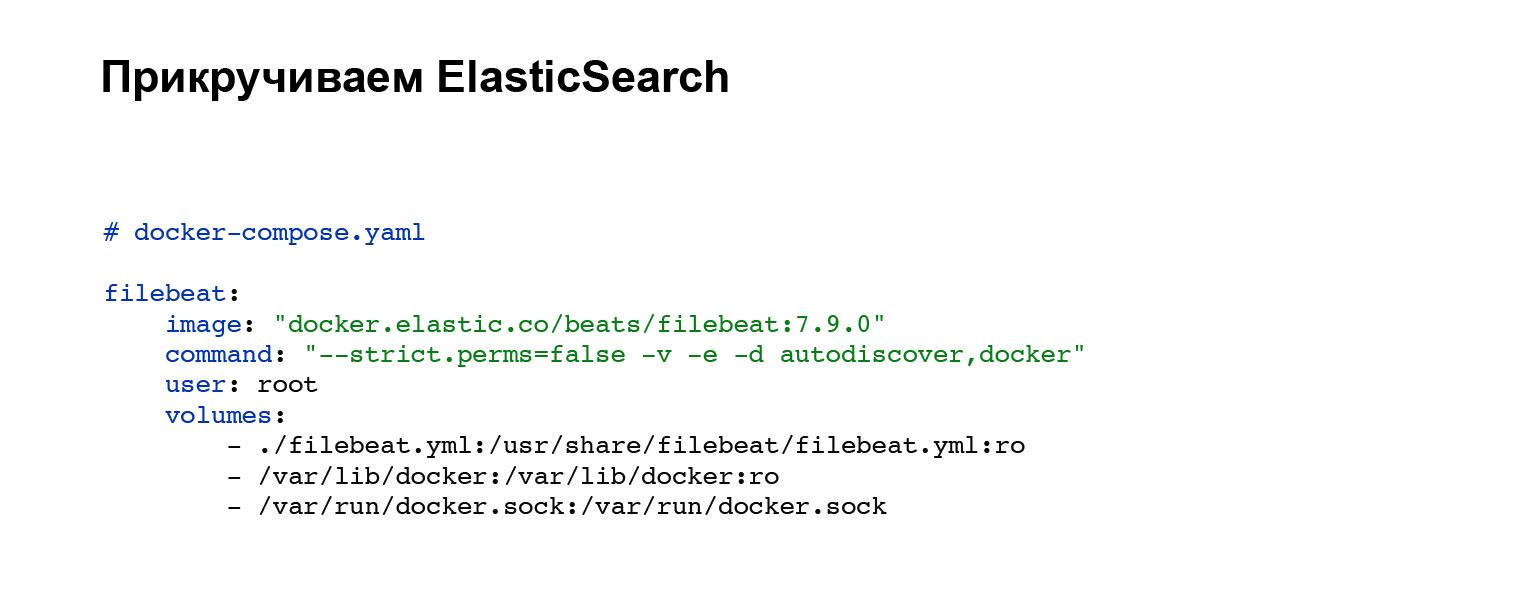
Em primeiro lugar, precisaremos implantar um agente que enviará nossos logs ao Elasticsearch. Você registra uma conta no Elasticsearch e depois adiciona ao docker-compose. Se você não tiver docker-compose, pode aumentar com alças ou em seu sistema. Em nosso caso, o seguinte bloco de código é adicionado, integração em docker-compose. Tudo, o serviço está configurado. E você pode ver o arquivo de configuração filebeat.yml no bloco de volumes.

Aqui está um exemplo de filebeat.yml. Aqui, configuramos uma busca automática por logs de contêineres docker que estão girando nas proximidades. A escolha desses logs foi personalizada. Por condição, você pode definir, pendurar rótulos em seus contêineres e, dependendo disso, seus logs serão enviados apenas para alguns contêineres. O bloco processadores: add_docker_metadata é simples. Adicionamos um pouco mais de informações sobre seus registros no contexto do docker aos registros. Opcional, mas legal.
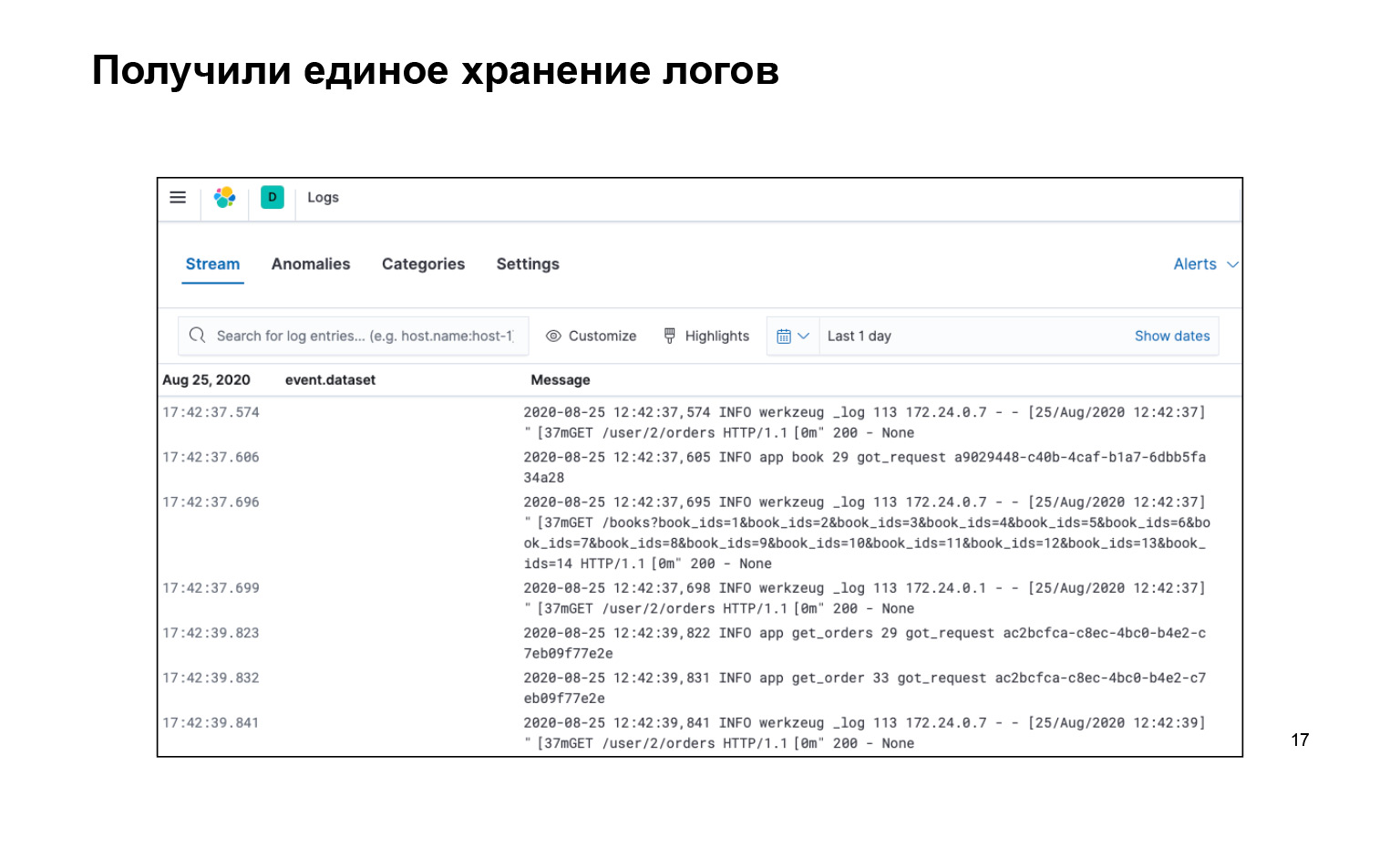
O que conseguimos? Isso é tudo que escrevemos, todo o código, muito legal. Ao mesmo tempo, temos todos os logs em um só lugar e há uma interface. Podemos pesquisar nossos logs, aqui está a barra de pesquisa. Eles são entregues. E você pode até ativá-lo ao vivo para que a transmissão voe para nossos registros na interface, e nós vimos.

Aqui eu mesmo teria perguntado: por que, como afivelar alguma coisa? O que é uma pesquisa de log, o que pode ser feito lá?
Sim, fora da caixa nesta abordagem, quando temos logs de texto, há uma pequena gag: podemos definir uma solicitação pelo texto, por exemplo mensagem: usuários. Isso irá imprimir para nós todos os logs que possuem a substring do usuário. Você pode usar asteriscos, a maioria dos outros curingas do Unix. Mas parece que isso não é suficiente, quero tornar mais difícil para que você possa se aquecer no Nginx antes, como podemos.

Vamos voltar um pouco do Elasticsearch e tentar fazer isso não com o Elasticsearch, mas com uma abordagem diferente. Vamos considerar os logs estruturais. É quando cada uma de suas entradas de log não é apenas uma linha de texto, mas um objeto serializado com atributos que qualquer um dos seus sistemas de terceiros pode serializar para obter um objeto pronto.
Quais são as vantagens disso? É um formato de dados uniforme. Sim, os objetos podem ter atributos diferentes, mas qualquer sistema externo pode ler JSON e obter algum tipo de objeto.
Algum tipo de digitação. Isso simplifica a integração com outros sistemas: não há necessidade de escrever desserializadores. E apenas desserializadores são outro ponto. Você não precisa escrever textos prosaicos no aplicativo. Exemplo: "O usuário veio com tal e tal especialista em ID, com tal e tal pedido." E tudo isso precisa ser escrito sempre.
Isso me incomodou. Quero escrever: "Chegou um pedido." Além disso: “Fulano, Fulano, Fulano”, muito simples, muito no estilo de TI.

Vamos continuar. Vamos concordar: vamos logar no formato JSON, este é um formato simples. Elasticsearch é imediatamente suportado, filebeat, que serializamos e tentamos arquivar. Não é muito difícil. Primeiro, você adiciona o arquivo de configurações da biblioteca pythonjsonlogger ao bloco de formatadores JSONFormatter, onde armazenamos a configuração. Este pode ser um local diferente em seu sistema. E então no atributo format você passa quais atributos deseja adicionar ao seu objeto.
O bloco abaixo é um bloco de configuração adicionado a filebeat.yml. Aqui, pronto para uso, há uma interface para filebeat para análise de logs JSON. Muito legal. É tudo. Você não precisa escrever mais nada para isso. E agora seus logs parecem objetos.
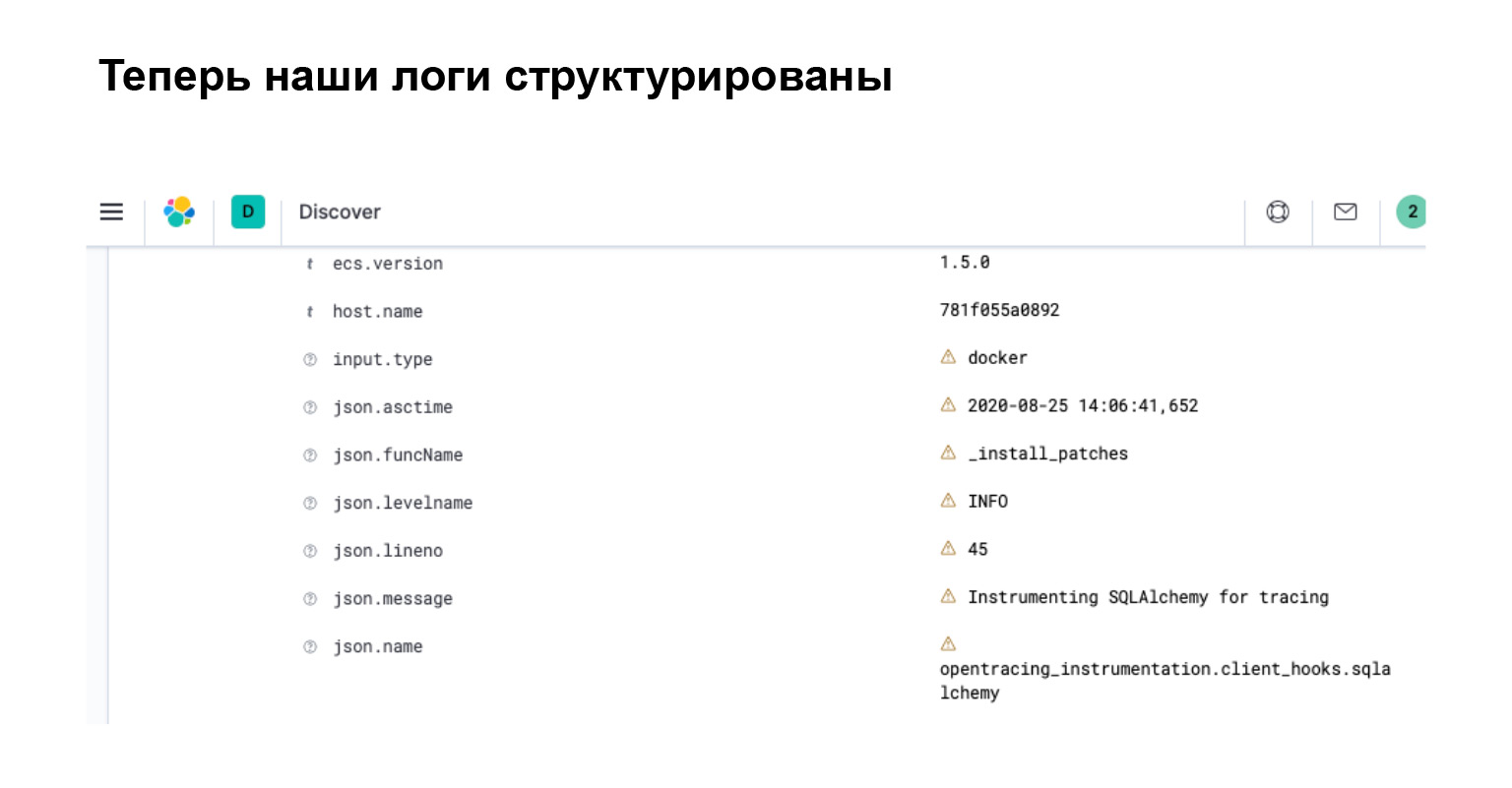
O que obtivemos no Elasticsearch? Na interface, você vê imediatamente que seu log se transformou em um objeto com atributos separados, pelo qual você pode pesquisar, criar filtros e fazer consultas complexas.

Vamos resumir. Agora nossos logs têm uma estrutura. Eles são fáceis de usar e você pode escrever consultas inteligentes. Elasticsearch está ciente dessa estrutura, pois analisou todos esses atributos. E no kibana, que é uma interface para o Elasticsearch, você pode filtrar esses logs usando uma linguagem de consulta especializada que o Elasticsearch fornece.
E é mais fácil do que remar. Grep tem uma linguagem bastante complicada e legal. Há muito o que escrever. Muitas coisas podem ser facilitadas no kibana. Com isso resolvido.
Problema 2. Freios
O próximo problema são os freios. Em uma arquitetura de microsserviço, há sempre e em todos os lugares os freios.

Aqui está um pequeno contexto, vou lhe contar uma história. O gerente, protagonista do nosso projeto, vem correndo até mim e diz: “Ei, ei, o escritório está ficando lento! Danya, salve, ajude! "
Não sabemos de nada ainda, entramos em nossos registros no Elasticsearch. Mas deixe-me contar o que realmente aconteceu.

Erast adicionou um recurso. Nos livros, agora exibimos não a identificação do autor, mas seu nome diretamente na interface. Muito legal. Ele fez isso com o seguinte código. Um pequeno trecho de código, nada complicado. O que poderia dar errado?
Com um olho treinado, você pode dizer que não pode fazer isso com SQLAlchemy e com outro ORM também. Você precisa fazer um pré-cache ou outra coisa para não ir ao banco de dados com uma pequena subconsulta em um loop. Um problema desagradável. Parece que tal erro não pode ser cometido.
Deixe-me dizer-lhe. Eu tinha experiência: trabalhamos com Django e tínhamos um pré-cache customizado implementado em nosso projeto. Tudo correu bem durante muitos anos. Em algum momento, Erast e eu decidimos: vamos acompanhar os tempos, atualizar o Django. Naturalmente, o Django não sabe nada sobre nosso cache customizado e a interface mudou. Prikash caiu silenciosamente. Não foi detectado nos testes. O mesmo problema, apenas mais difícil de detectar.
Qual é o problema? Como posso ajudá-lo a resolver o problema?

Vamos contar o que fiz antes de resolver o problema de encontrar freios.
A primeira coisa que faço é ir para o Elasticsearch, já temos, ajuda, não há necessidade de rodar nos servidores. Vou até as toras, procurando as toras do armário. Eu encontro longas consultas. Toco em um laptop e vejo que não é o escritório que está se segurando. Retarda os livros.
Eu corro para os logs de livros, encontro consultas problemáticas - na verdade, já as temos. Eu reproduzo livros da mesma forma em um laptop. Código muito complicado - não entendo nada. Estou começando a depurar. Os tempos são bastante difíceis de detectar. Por quê? É muito difícil definir isso internamente no SQLAlchemy. Eu escrevo registradores de tempo personalizados, localizo e resolvo o problema.
Isso me machucou. Difícil, desagradável. Eu chorei. Gostaria que este processo de localização de um problema fosse mais rápido e conveniente.
Vamos formalizar nossos problemas. É difícil pesquisar nos logs o que está diminuindo, porque nosso log é um log de eventos não relacionados. Temos que escrever temporizadores personalizados que nos mostram quantos blocos de código foram executados. Além disso, não está claro como registrar os tempos de sistemas externos: por exemplo, ORM ou bibliotecas de solicitações. Precisamos incorporar nossos temporizadores dentro ou com algum tipo de invólucro, mas não descobriremos por que ele fica lento por dentro. Complicado.

Uma boa solução que encontrei é a Jaeger. Esta é uma implementação do protocolo opentracing, então vamos implementar o rastreio.
O que Jaeger dá? É uma interface amigável com consultas de pesquisa. Você pode filtrar consultas longas ou fazer isso por tags. Uma representação visual do fluxo de solicitações, uma imagem muito bonita, mostrarei um pouco mais tarde.
Os tempos são registrados fora da caixa. Você não tem que fazer nada com eles. Se você precisar verificar quanto de um bloco personalizado está em execução, pode envolvê-lo em temporizadores fornecidos pela Jaeger. Muito confortável.
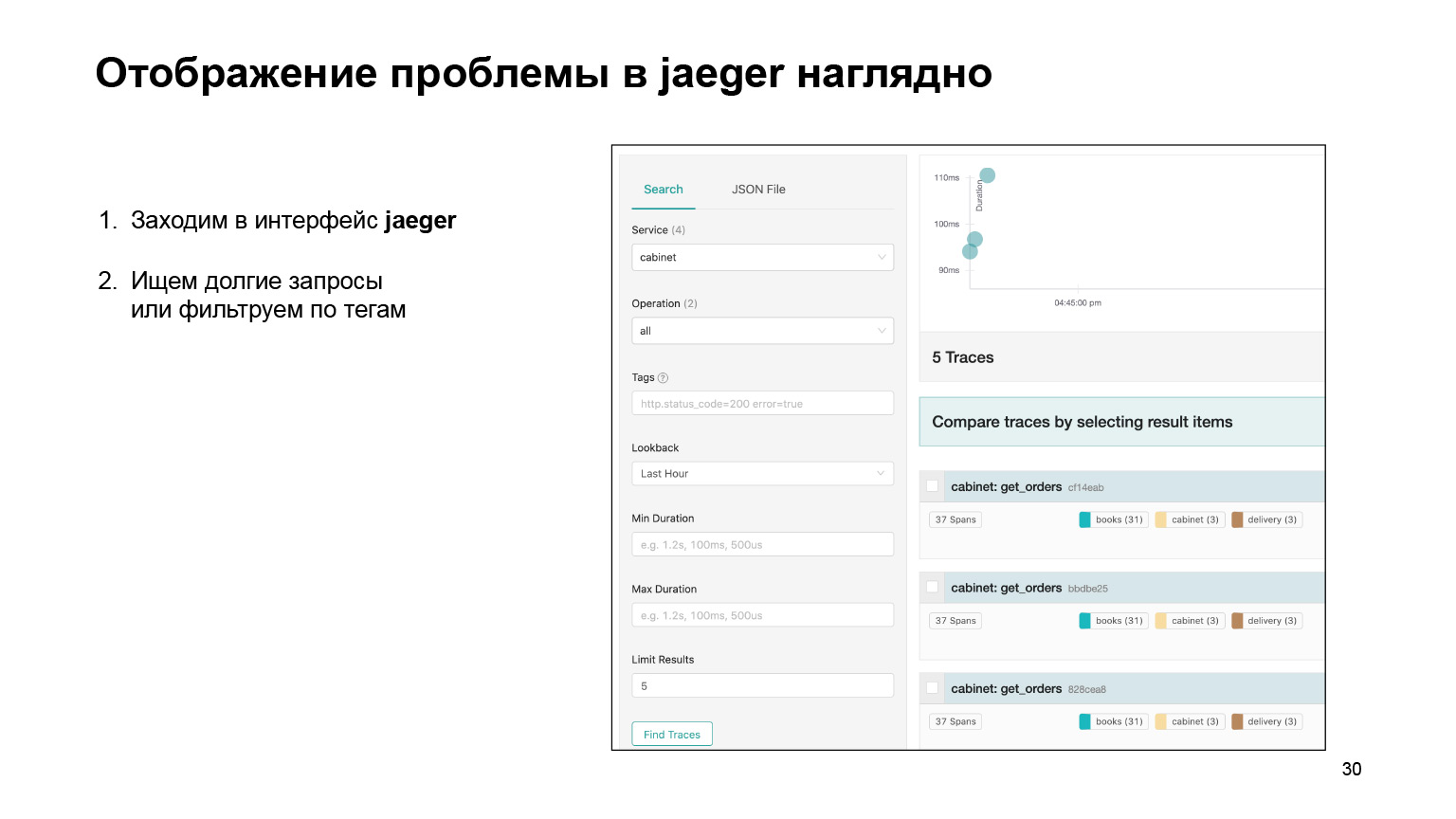
Vamos ver como foi possível localizar o problema na interface e localizá-lo aí. Vamos para a interface Jaeger. É assim que nossos pedidos se parecem. Podemos pesquisar solicitações de uma conta ou outro serviço. Filtramos imediatamente consultas longas. Estamos interessados nos longos, são muito difíceis de encontrar nos logs. Pegamos a lista deles.
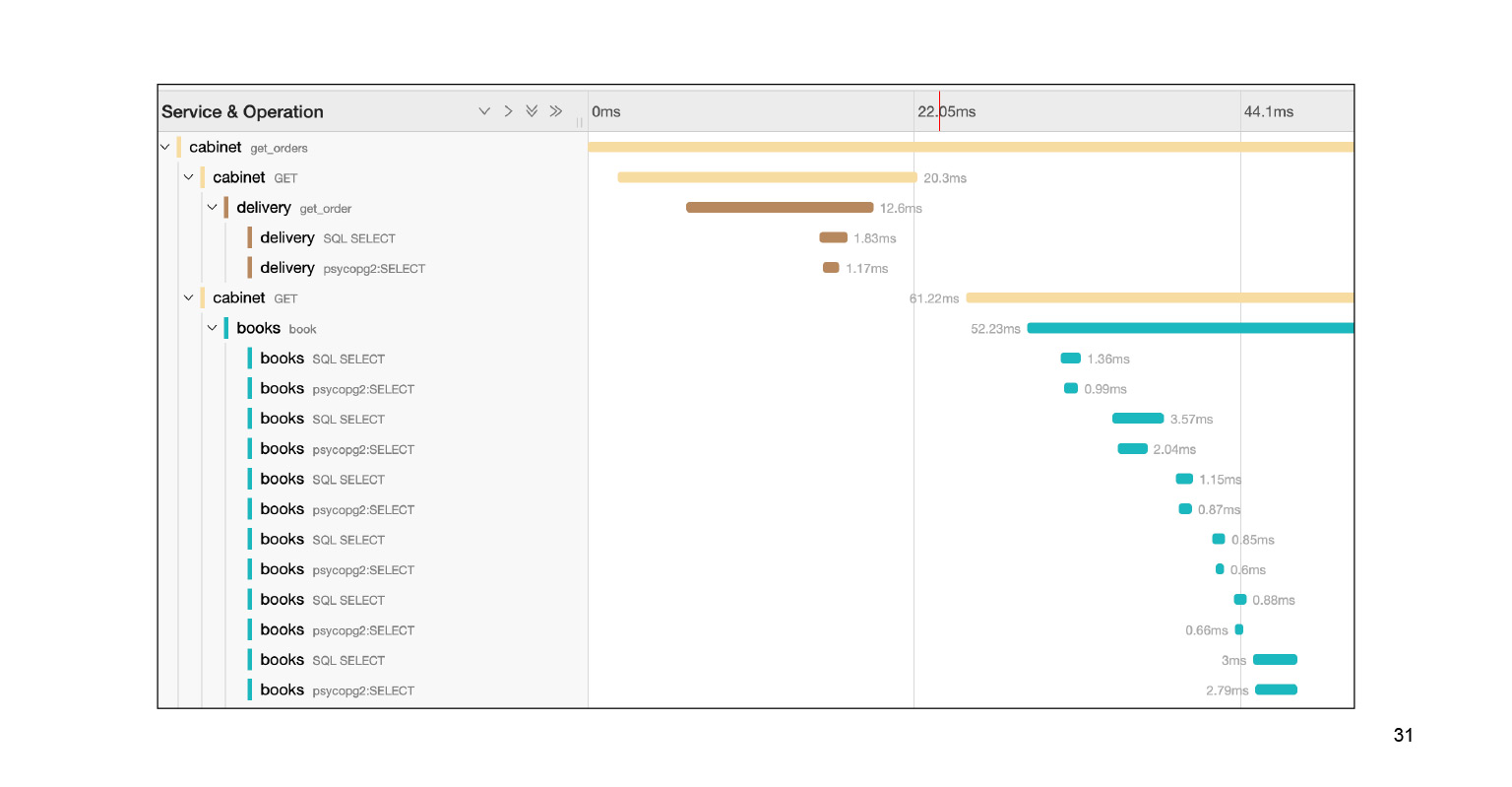
Caímos nessa consulta e vemos um grande rodapé de subconsultas SQL. Podemos ver claramente como eles foram executados no tempo, qual bloco de código foi responsável por quê. Muito legal. Além disso, no contexto do nosso problema, este não é o log inteiro. Há outro grande tapete, dois ou três escorregadores para baixo. Localizamos o problema rapidamente em Jaeger. Depois de resolver o problema, o que o contexto fornecido pela Jaeger pode nos ajudar?
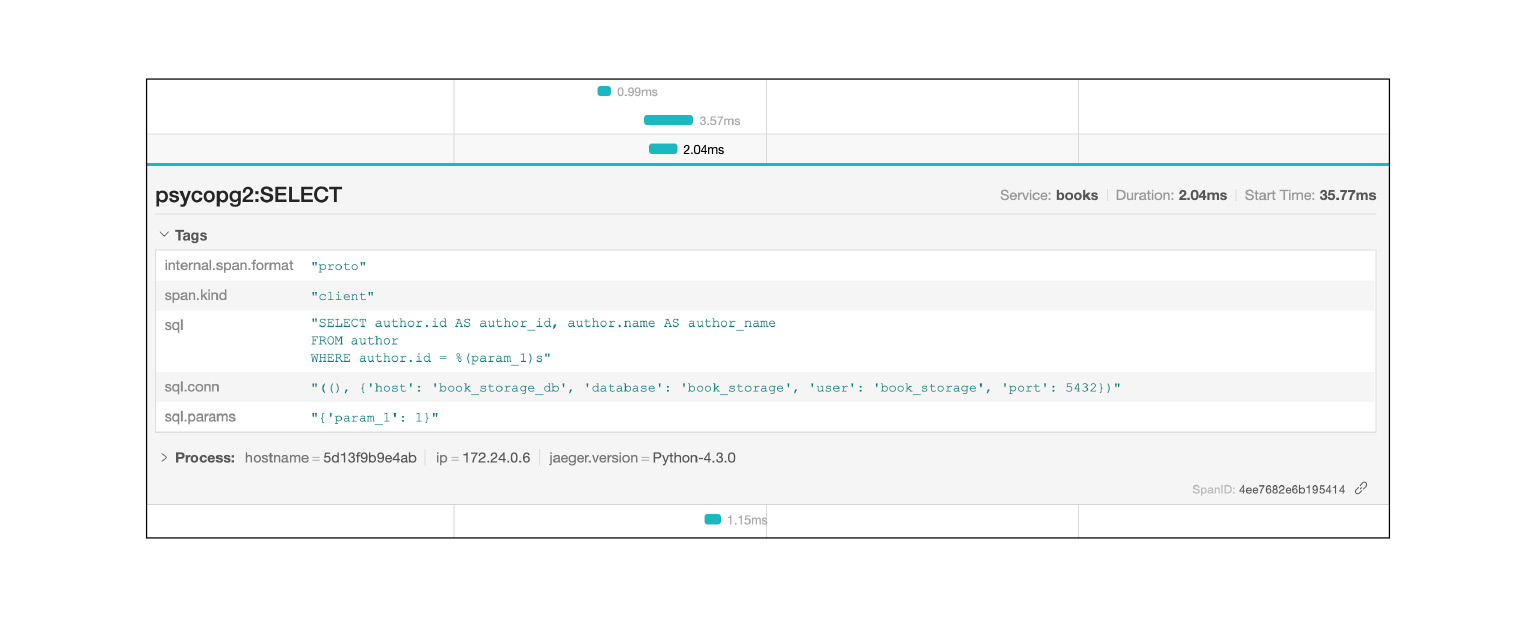
Logs do Jaeger, por exemplo, consultas SQL: você pode ver quais consultas estão sendo repetidas. Muito rápido e legal.
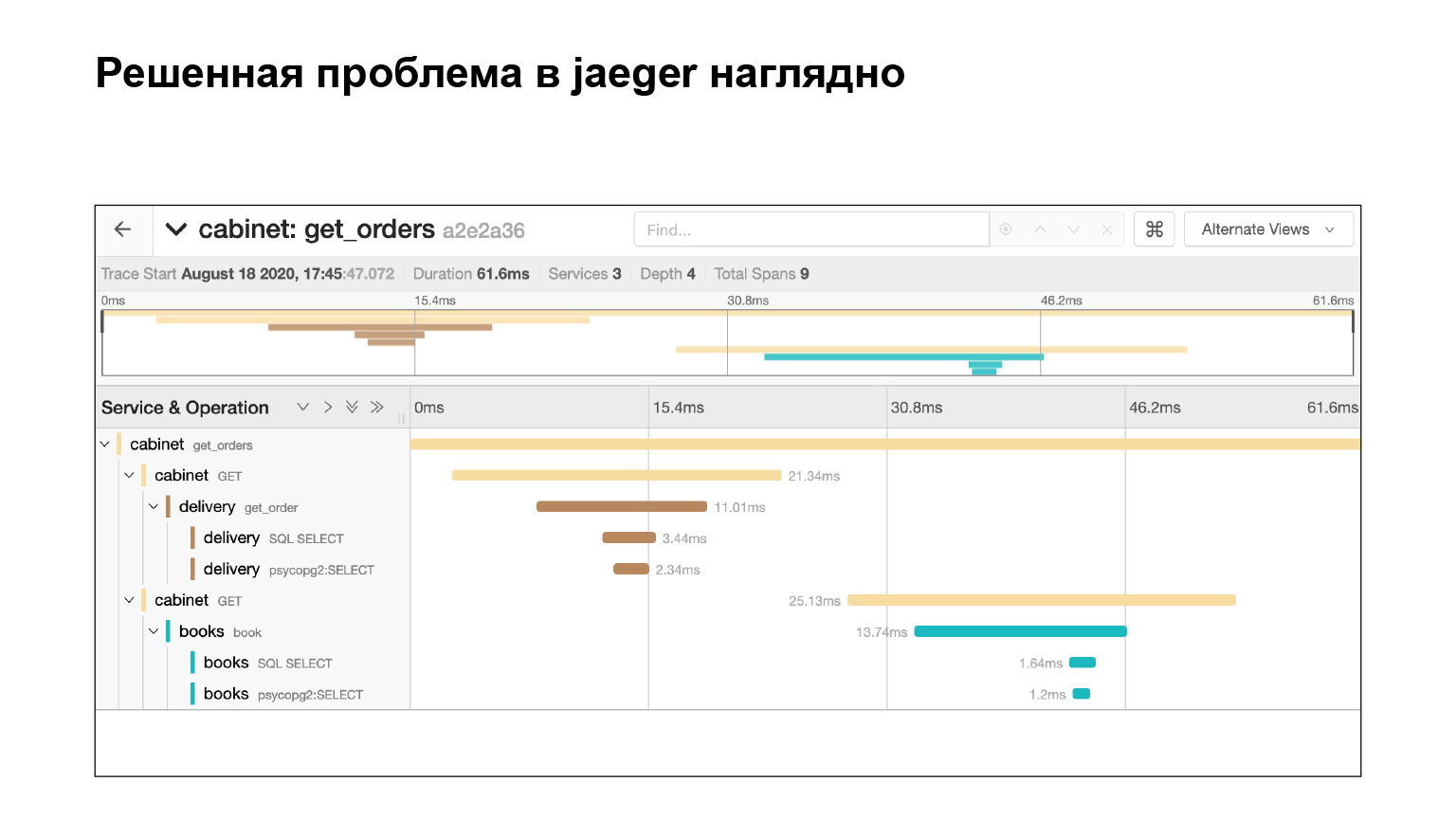
Resolvemos o problema e imediatamente vemos na Jaeger que está tudo bem. Verificamos pela mesma consulta se agora não temos subconsultas. Por quê? Suponha que verificamos a mesma solicitação, descobrimos o tempo - veja no Elasticsearch por quanto tempo a solicitação foi executada. Então veremos a hora. Mas isso não garante que não houve subconsultas. E aqui a gente vê, legal.

Vamos implementar Jaeger. Não é necessário muito código. Você adiciona dependências para opentracing, para Flask. Agora sobre o código que estamos fazendo.
O primeiro bloco de código é a configuração do cliente Jaeger.
Em seguida, configuramos a integração com Flask, Django ou qualquer outro framework que tenha integração.
install_all_patches é a última linha de código e a mais interessante. Nós corrigimos a maioria das integrações externas interagindo com MySQL, Postgres e biblioteca de solicitações. Estamos corrigindo tudo isso e é por isso que na interface do Jaeger vemos imediatamente todas as consultas com SQL e para quais serviços nosso serviço solicitado foi. Muito legal. E você não teve que escrever muito. Acabamos de escrever install_all_patches. Magia!
O que conseguimos? Agora você não precisa coletar eventos de logs. Como eu disse, os logs são eventos díspares. Em Jaeger, este é um grande evento do qual você vê a estrutura. Jaeger permite detectar gargalos em seu aplicativo. Basta pesquisar longas consultas e analisar o que está errado.
Problema 3. Erros
O último problema são os erros. Sim, sou astuto. Não vou ajudá-lo a se livrar de erros no aplicativo, mas direi o que você pode fazer a seguir.

Contexto. Você pode dizer: “Danya, estamos registrando erros, temos alertas para quinhentos, nós os configuramos. O que você quer? Nós registramos, registramos e iremos registrar e depurar.
Você não sabe a importância do erro dos logs. Qual é a importância? Aqui você tem um erro legal e o erro de conexão com o banco de dados. A base simplesmente fracassou. Eu gostaria de ver imediatamente que esse erro não é tão importante, e se não houver tempo, ignore-o, mas conserte o mais importante.
A taxa de erro é um contexto que pode nos ajudar a depurá-lo. Como rastrear erros? Vamos continuar, tivemos um erro há um mês, e agora ele aparece novamente. Gostaria de encontrar imediatamente uma solução e corrigi-la ou comparar sua aparência com uma das versões.
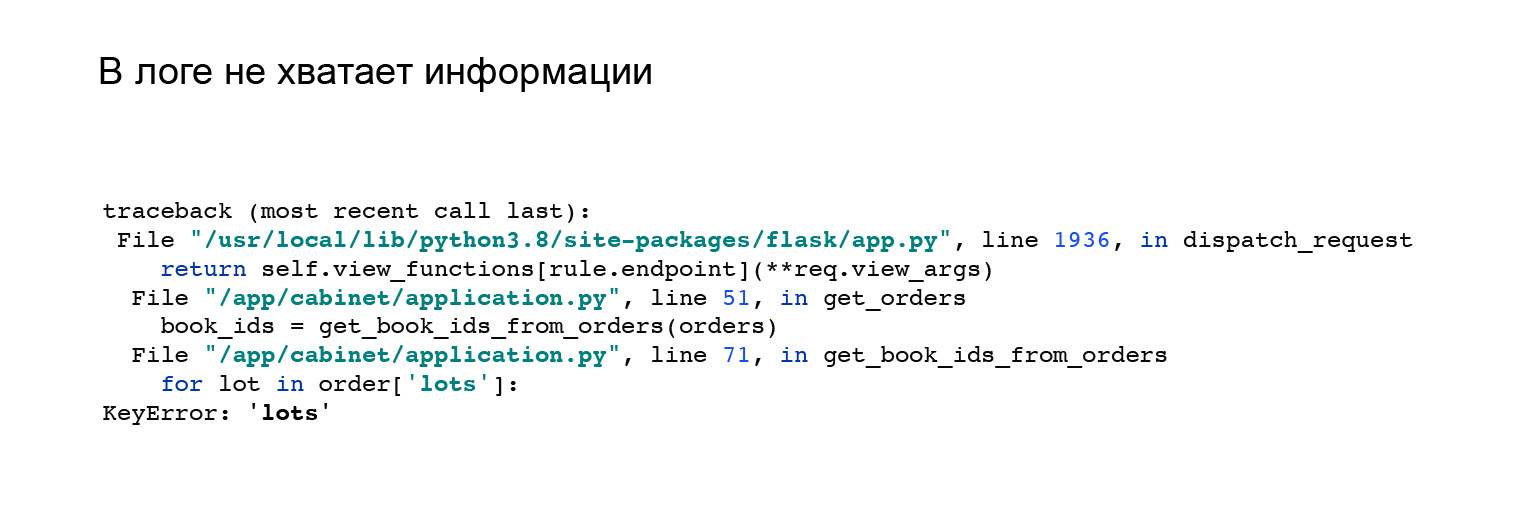
Aqui está um bom exemplo. Quando vi a integração com o Jaeger, mudei um pouco minha API. Mudei o formato da resposta do aplicativo. Eu tenho esse erro. Mas não está claro nele por que não tenho uma chave, lotes no objeto de pedido, e não há nada que me ajude. Tipo, veja o erro aqui, reproduza e detecte você mesmo.

Vamos implementar o sentinela. Este é um bug tracker que nos ajudará a resolver problemas semelhantes e encontrar o contexto do erro. Pegue a biblioteca padrão mantida pelos desenvolvedores do Sentry. Em quatro linhas de código, nós o adicionamos ao nosso aplicativo. Tudo.
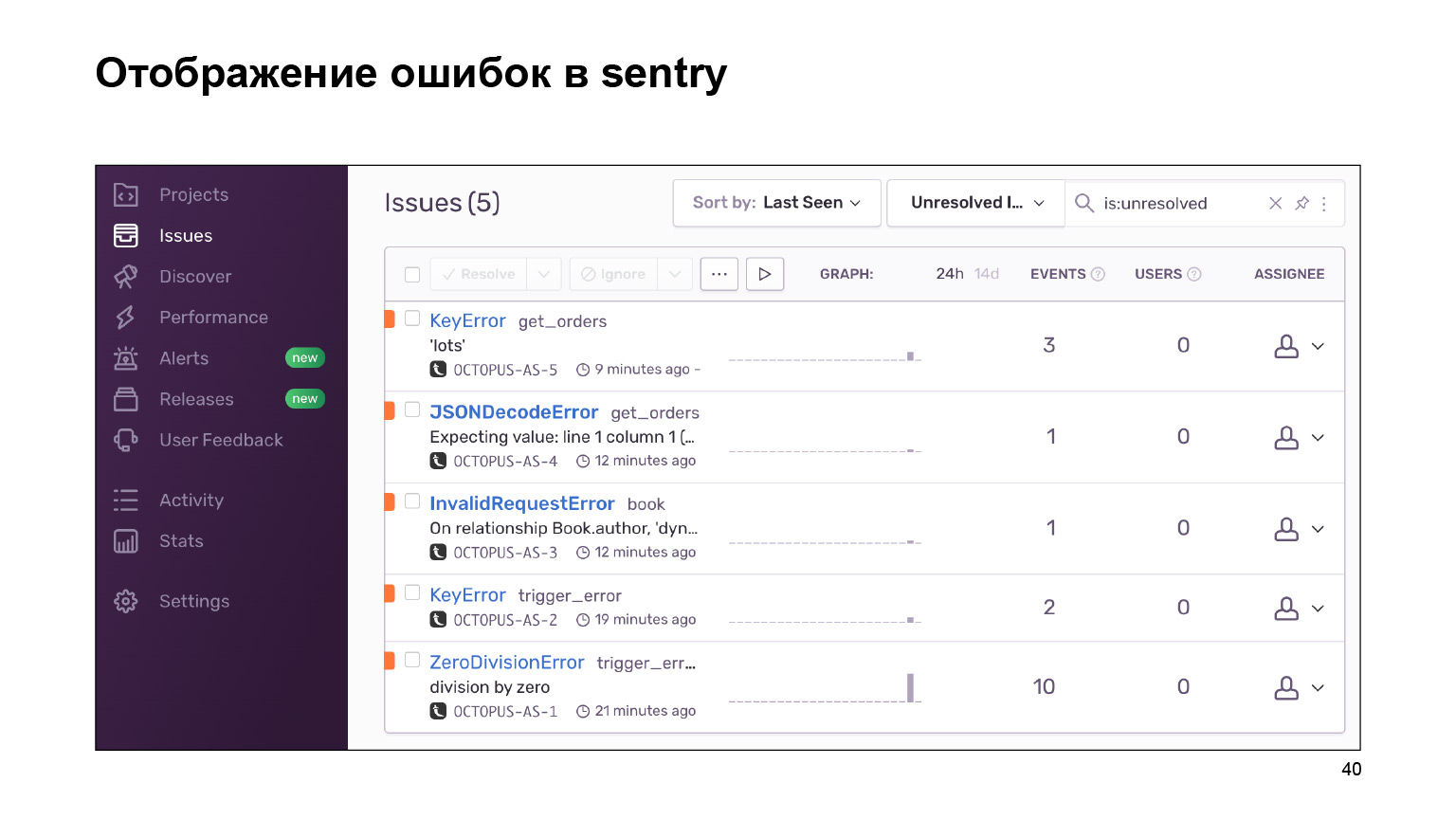
O que conseguimos no caminho de saída? Aqui está um painel com erros que podem ser agrupados por projeto e você pode acompanhar. Um enorme rodapé de registros de erros é agrupado em registros idênticos e semelhantes. As estatísticas são fornecidas para eles. E você também pode lidar com esses erros usando a interface.
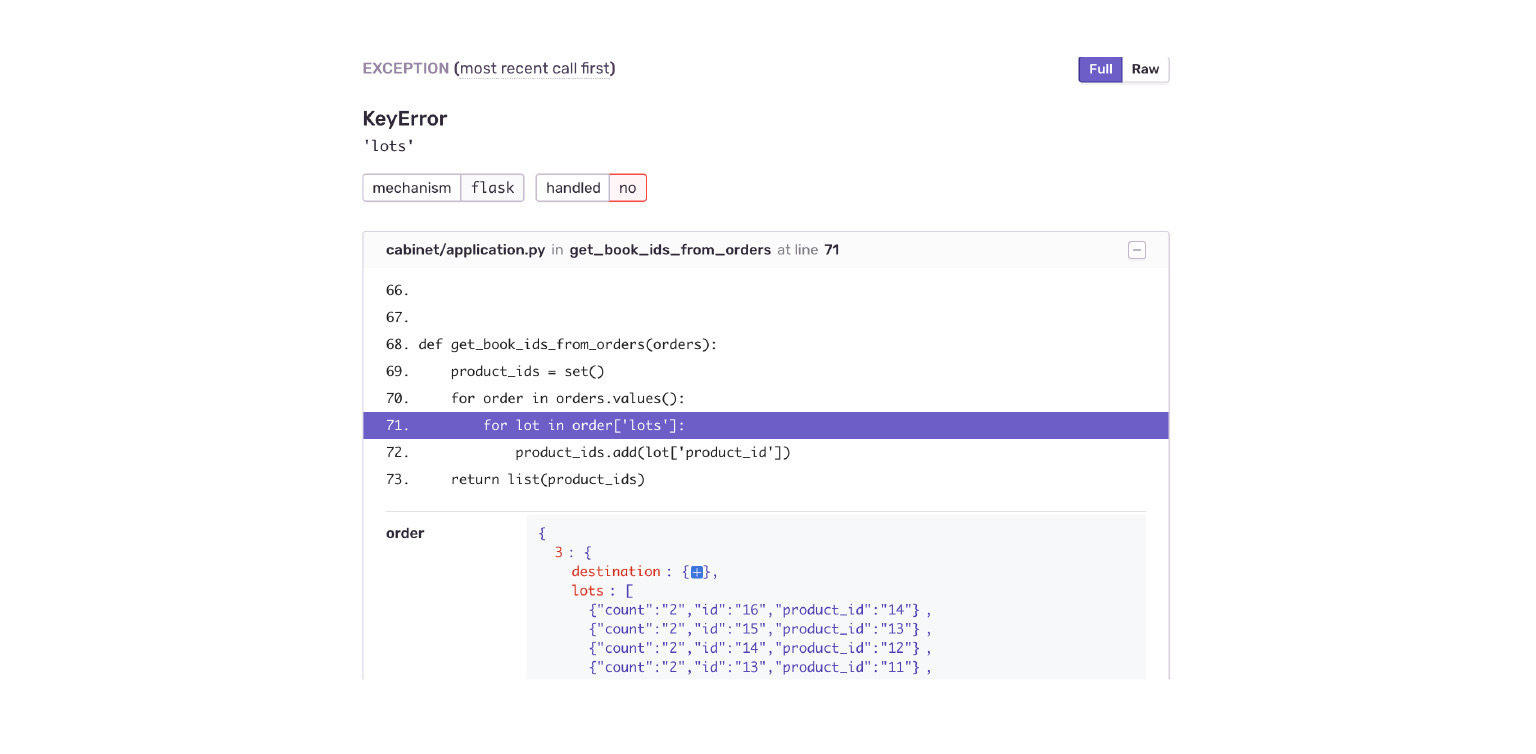
Vejamos nosso exemplo. Caindo em um KeyError. Vemos imediatamente o contexto do erro, o que estava no objeto do pedido, o que não estava lá. Percebo imediatamente por engano que o aplicativo Delivery me deu uma nova estrutura de dados. O gabinete simplesmente não está pronto para isso.

O que o Sentinela oferece além do que listei? Vamos formalizar.
Este é o armazenamento de erros onde você pode procurá-los. Existem ferramentas úteis para isso. Existe um agrupamento de erros - por projetos, por similaridade. Sentry fornece integrações com diferentes rastreadores. Ou seja, você pode monitorar seus erros, trabalhar com eles. Você pode simplesmente adicionar a tarefa ao seu contexto e pronto. Isso ajuda no desenvolvimento.
Estatísticas de erro. Novamente, é fácil compará-lo com o lançamento de uma versão. O Sentinela irá ajudá-lo com isso. Eventos semelhantes que aconteceram ao lado do erro também podem ajudá-lo a encontrar e entender o que o levou a ele.

Vamos resumir. Escrevemos um aplicativo que é simples, mas atende às necessidades. Ajuda a desenvolvê-lo e mantê-lo em seu ciclo de vida. O que nos fizemos? Coletamos logs em um repositório. Isso nos deu a oportunidade de não procurá-los em lugares diferentes. Além disso, agora temos uma pesquisa por registros e recursos de terceiros, nossas ferramentas.
Rastreamento integrado. Agora podemos monitorar visualmente o fluxo de dados em nosso aplicativo.
E adicionou uma ferramenta útil para lidar com erros. Eles estarão em nosso aplicativo, não importa o quanto tentemos. Mas vamos corrigi-los mais rápido e melhor.
O que mais você pode adicionar? O próprio aplicativo está pronto, tem um link, você pode ver como é feito. Todas as integrações são levantadas lá. Por exemplo, integração com Elasticsearch ou rastreamento. Entre e veja.
Outra coisa legal que não tive tempo de abordar é o request_id. Quase não é diferente de trace_id, que é usado em rastreios. Mas somos responsáveis por requests_id, este é seu recurso mais importante. O gerente pode vir até nós imediatamente com o requests_id, não precisamos procurá-lo. Começaremos imediatamente a resolver nosso problema. Muito legal.
E não se esqueça de que as ferramentas que implementamos são indiretas. Esses são problemas que precisam ser resolvidos para cada aplicativo. Você não pode implementar sem pensar todas as nossas integrações, tornar sua vida mais fácil e depois pensar no que fazer com uma aplicação inibidora.
Confira. Se isso não afeta você, legal. Você só tem os prós e não resolve os problemas com os freios. Não se esqueça disso. Obrigado a todos pela atenção.